boostcamp
1.네이버 부스트캠프 AI tech 5기

맛있는 김밥맛있는 초밥초밥드실?
2.네이버 부스트캠프 5기 1일차

첫 포스팅입니다
3.네이버 부스트캠프 5기 2일차

test_array = np.array(1,2,3,4,float)test_array = np.array(1,2,3,4,1,2,3,4).reshape(2,4)test_array = np.array(1,2,3,4,1,2,3,4).flatten()test_array = np
4.네이버 부스트캠프 5기 3일차

경사하강법(Gradient descent)란 주어진 점에서의 접선의 기울기(미분)을 구하여 어느 한 방향으로 점을 움직여 함수값을 계속해서 감소시킨다. 만약 기울기가 0인 극값에 도달할 경우 움직을 멈추며 수렴하게 된다.선형회기일 경우 목적식 $$\\left| y-x\
5.네이버 부스트캠프 5기 4일차

딥러닝에서 확률론이 쓰이는 이유는 딥러닝 자체가 확률론 기반의 기계학습 이론과 loss function에서 데이터 공간을 통계적으로 해석해서 유도해내기 때문이다.위의 사진을 보게될 경우 단순하게 보면 이산확률변수는 점수로 나오는 반면 연속확률변수는 거리로 나오게 된다.
6.네이버 부스트캠프 5기 5일차

주로 이미지 데이터를 처리할때 사용한다컨볼루션은 일종의 필터라고 볼 수 있다. input_image를 슬라이딩하면서 새로운 Feature Map을 만들게 된다.만약 컨볼루션 레이어를 컬러이미지에 적용하게 된다면 위의 사진과 같이 3개의 필터를 만들고 각각 Feature

8.네이버 부스트캠프 5기 14~16주차 주간 회고(ODQA 대회)

1\. 프로젝트 개요 2\. 프로젝트 팀 구성 및 역할 3\. 프로젝트 수행 절차 및 방법 원활한 협업을 위해서는 GitHub 을 사용할 때 반복적으로 수행되는 내용을 자동화하여 시간을 절약해야 한다고 생각했기 때문에 , 프
9.[GPT-2 논문 리뷰](Language Models are Unsupervised Multitask Learners)
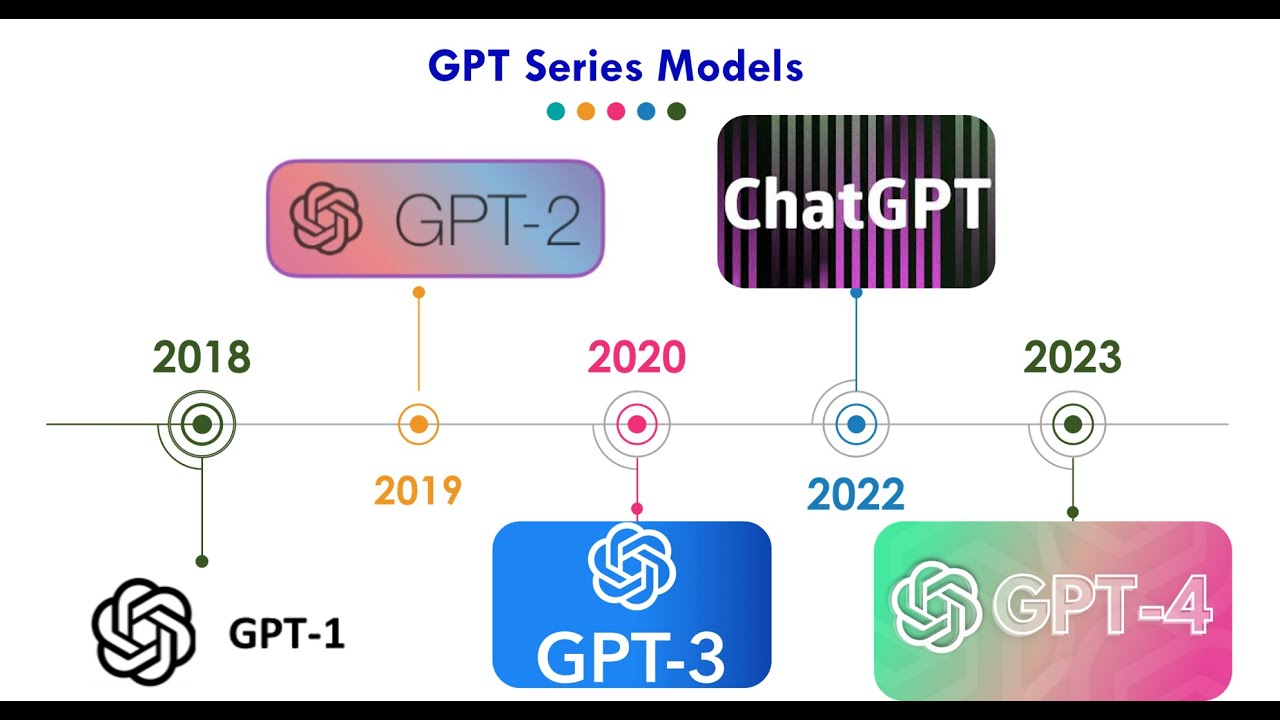
[GPT-2] Language Models are Unsupervised Multitask Learners 1. 논문이 다루는 Task Task: Text Generation Input: Text Output:Text Text Generation : 단순한 텍스트
10.네이버 부스트캠프 5기 Final Project 마지막 회고

법률 GPT 제작기
11.[RetNet 논문 리뷰](A Successor to Transformer for Large Language Models)
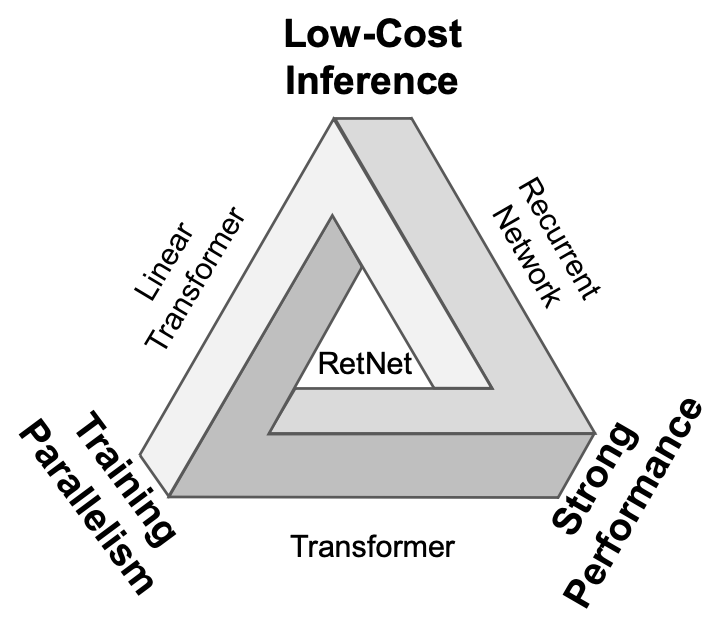
RetNet(A Successor to Transformer for Large Language Models)
12.kfkas/Llama-2-ko-7b-Chat 출시!

Huggingface에 LLama-2-ko-Chat을 업로드 하였습니다!많은 이용 부탁드립니다.
13.[BERT 논문 리뷰](Pre-training of Deep Bidirectional Transformers for Language Understanding NAACL 2019)

BERT 논문 리뷰
14.KLUE-YNAT 대회 관련 모델 제작 및 배포
KLUE-YNAT의 데이터는 연합뉴스 기사 제목으로 구성된 데이터이다.부스트캠프 Data-Centric에서는 데이터의 일부가 P2G데이터로 구성되있으며 임의로 label을 다르게 추가하였다.이를 원상으로 복구하기 위한 모델을 개발하고 오픈소스로 배포하였다. 또한 데이터
15.네이버 부스트캠프 5기 12~13주차 주간 회고(KlUE TC 대회)

프로젝트 개요 프로젝트 팀 구성 및 역할 프로젝트 수행 내용 EDA(Exploratory Data Analysis) 데이터 전처리 및 증강 이전 주어진 데이터의 feature를 파악하여 모델 성능 향상을 위한 방향성 확립을 위해 진행 데이터 중복 및 결측치 존재 여부
16.BERT 두 문장 관계 분류 Task
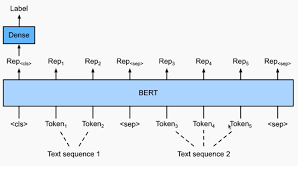
주어진 2개의 문장을 SEP토큰을 기준으로 입력으로 넣어 최종으로 나온 CLS 토큰으로 두 문장의 관계를 분류하는 Task이다.언어모델이 자연어의 맥락을 이해할 수 있는지 검증하는 task전체문장(Premise)과 가설문장(Hypothesis)을 Entailment(함
17.BERT 문장 토큰 관계 분류 task
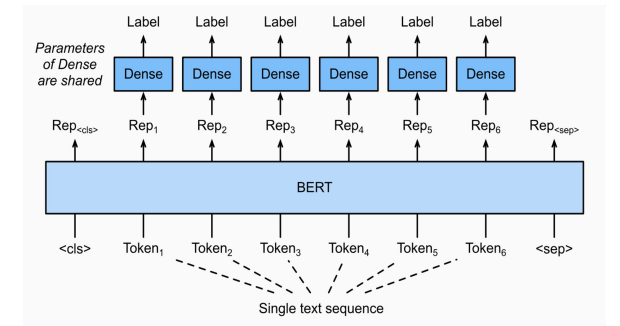
주어진 문장의 각 token이 어떤 범주에 속하는지 분류하는 task개체명 인식은 문맥을 파악해서 인명,기관명,지명 등과 같은 문장 또는 문서에서 특정한 의미를 가지고있는 단어 또.는 어구(개체)등을 인식하는 과정을 의미한다.품사란 단어를 문법적 성질의 공통성에 따라
18.네이버 부스트캠프 5기 9~11주차 주간 회고(KlUE RE 대회)

업로드중..\- 모더레이터 외에도 Github 관리자를 두어 베이스라인 코드의 버전 관리를 원활하게 하고, 같은 분야라도 다른 작업을 진행할 수 있도록 분업을 하여 협업을 진행하였다.팀 협업을 위해 개선점 파악을 위해 지난 NLP 기초 프로젝트 관련한 회고를 진행하였다
19.[GPT-1 논문 리뷰](Improving Language Understanding by Generative Pre-Training)
GPT > GPT는 현재 LLM인 ChatGPT와 GPT-4의 근간이 되는 모델로 OpenAi에서 개발하였다. GPT는 언어 생성 모델로 NLP의 대부분 task에서 사용이 가능하다. 아직 GPT2와는 다르게 특정 task를 위해 fine-tuning이 필요하며 특정
20.BERT 언어모델
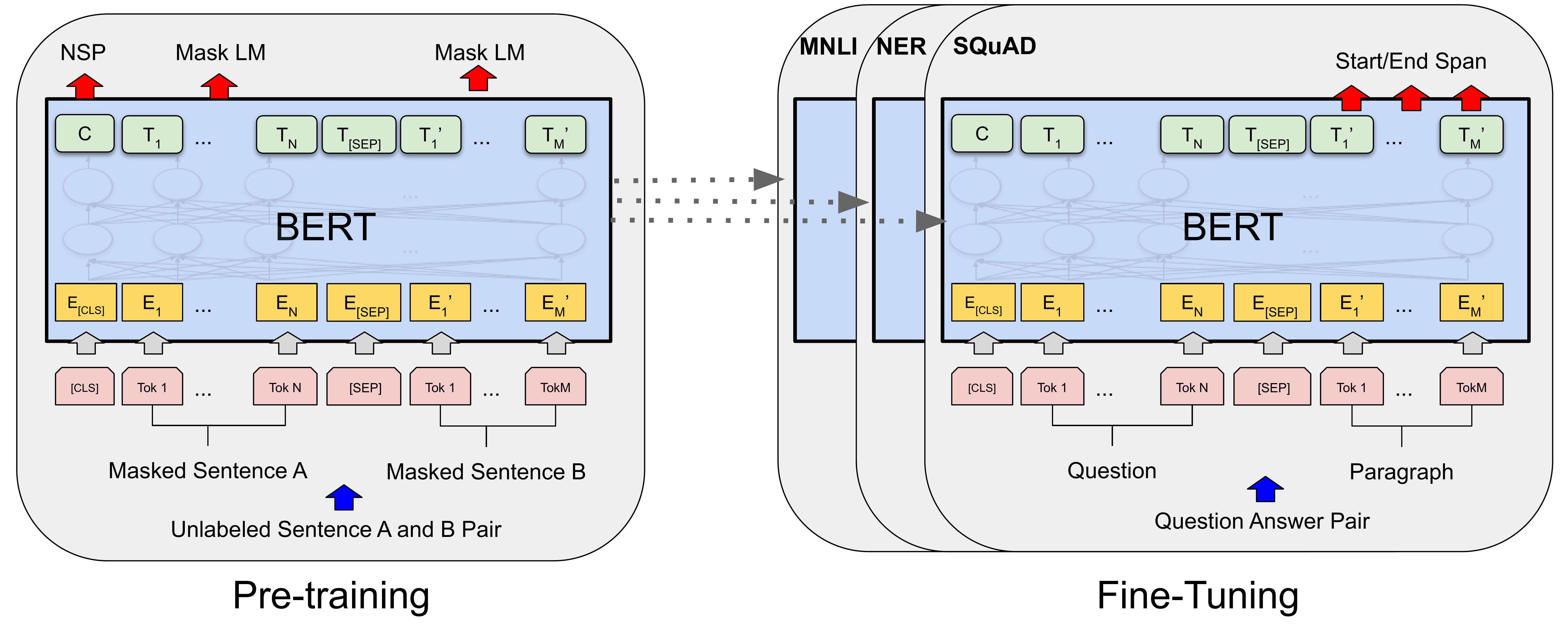
BERT(Bidirectional Encoder Representations from Transformers)는 구글에서 2018년에 발표한 언어 모델로, Transformer 아키텍처를 기반으로 하고 양방향(bidirectional) 학습을 사용하여 이전의 모델보다
21.KLUE 데이터셋

한국어 자연어 벤치마크(Korean Language Understanding Evaluation,KLUE)KLUE 링크 https://klue-benchmark.com/문장분류관계 추출문장 유사도자연어 추론개채명 인식품사 태깅질의 응답목적형 대화의존 구문 분석
22.BERT 단일 문장 분류 Task
BERT 문장 분류 Task 감정 분석 주제 라벨링 언어 감지 의도 분류
23.네이버 부스트캠프 5기 6,7주차 Semantic Textual Similarity Paper

논문버전 대회 Paper입니다.
24.네이버 부스트캠프 5기 6,7주차 주간 회고(STS 대회)

대부분의 팀원들이 첫 NLP 도메인의 프로젝트인만큼 명확한 기준을 가지고 업무를 구분한 것보다 다양한 인사이트를 기르기 위해 데이터 전처리부터 모델 튜닝까지 End-to-End로 경험하는 것을 목표로 하여 협업을 진행했다. 따라서 각자 튜닝할 모델을 할당하여 하이퍼 파
25.네이버 부스트캠프 5기 8주차 주간 회고

각 모듈이 서로 영향을 주지 않고 쉽게 교체가능하게끔 독립적으로 설계하는 것을 의미한다. (함수의 집합 == 모듈)각 모듈내의 함수가 서로 엮여서 동작한다. 각 모듈의 구성요소가 목적을 달성하기 위한 정도각 모듈들의 상호 의존성을 나타낸다.응집도 ↑ 모듈성 ↓ 소프트웨
26.[Transformer 논문리뷰](Attention is all you need)
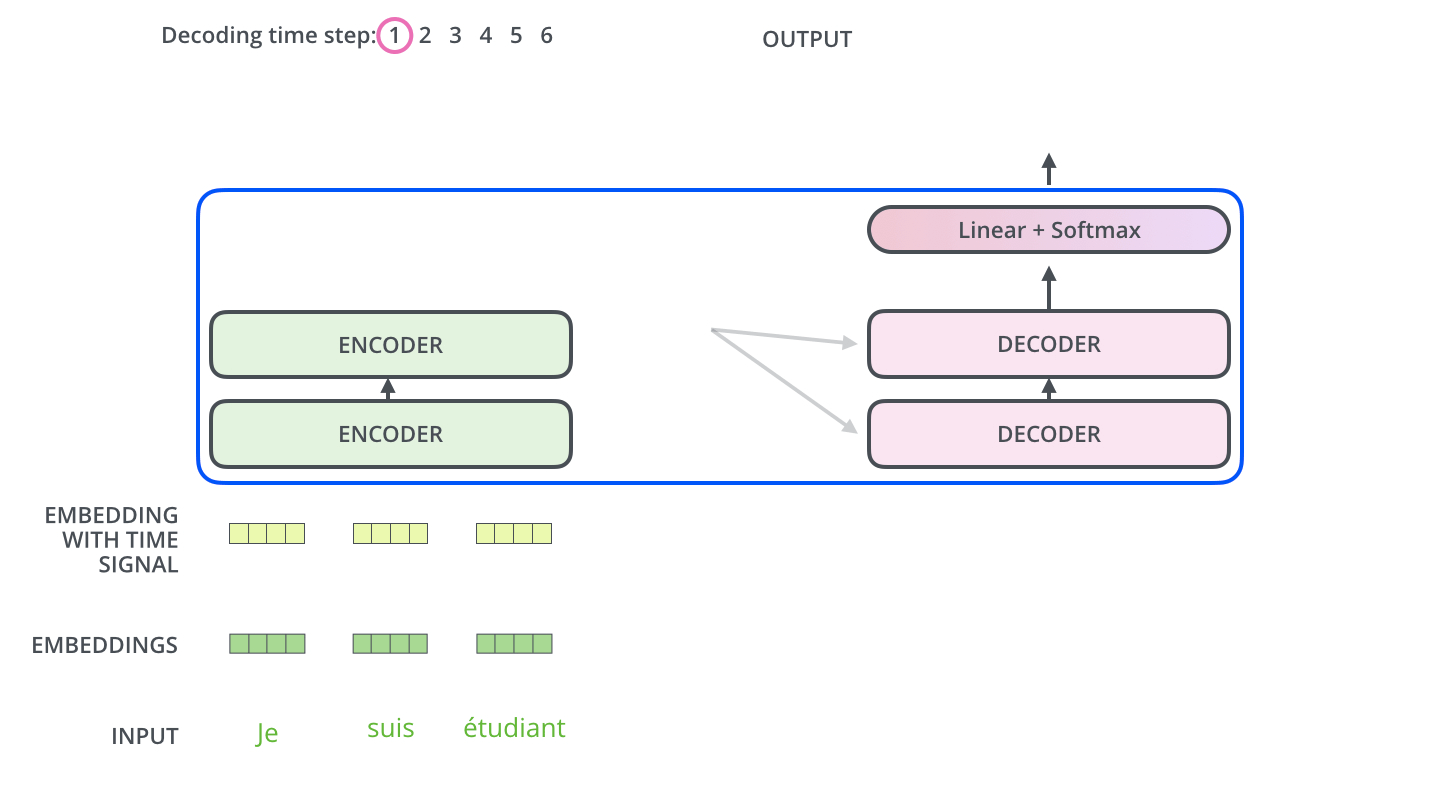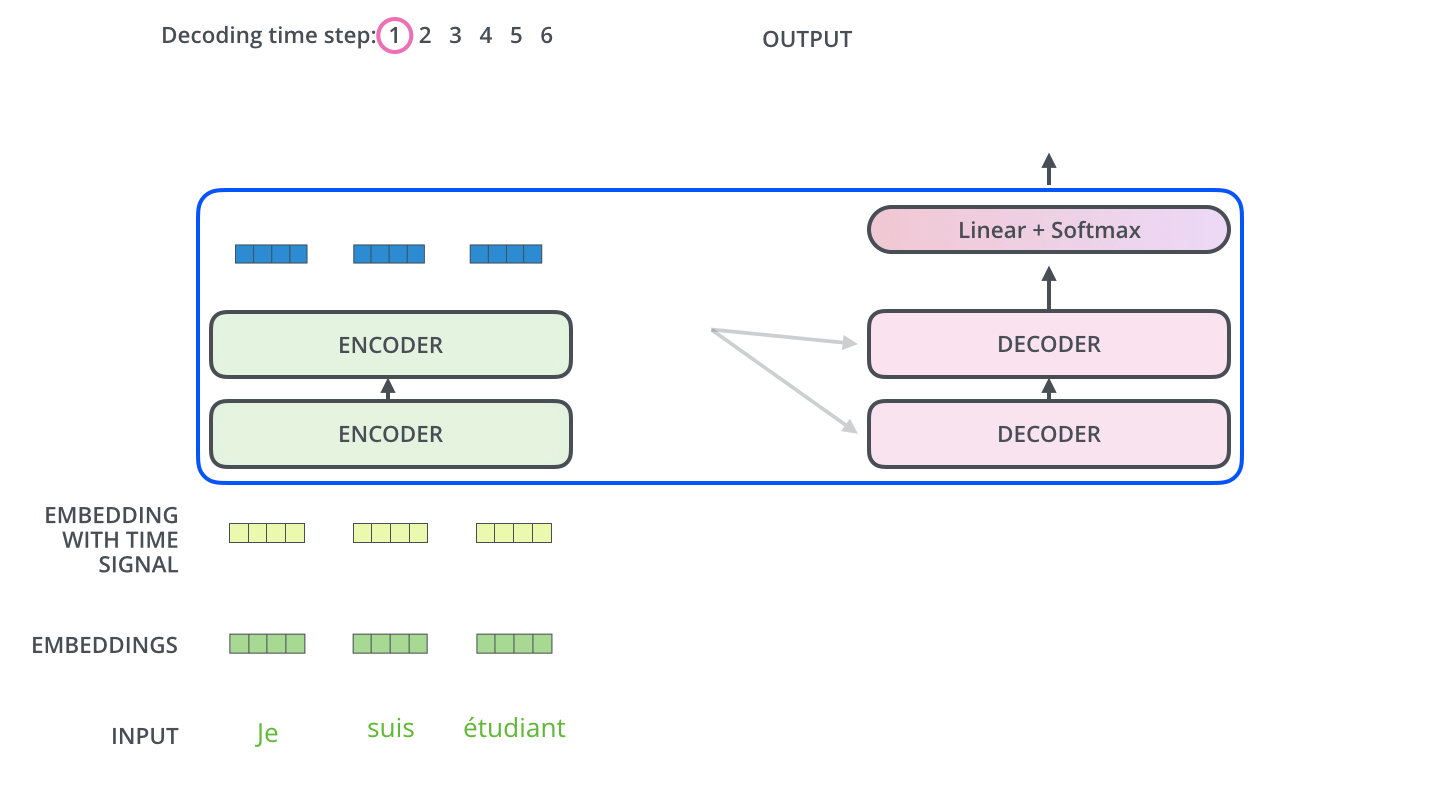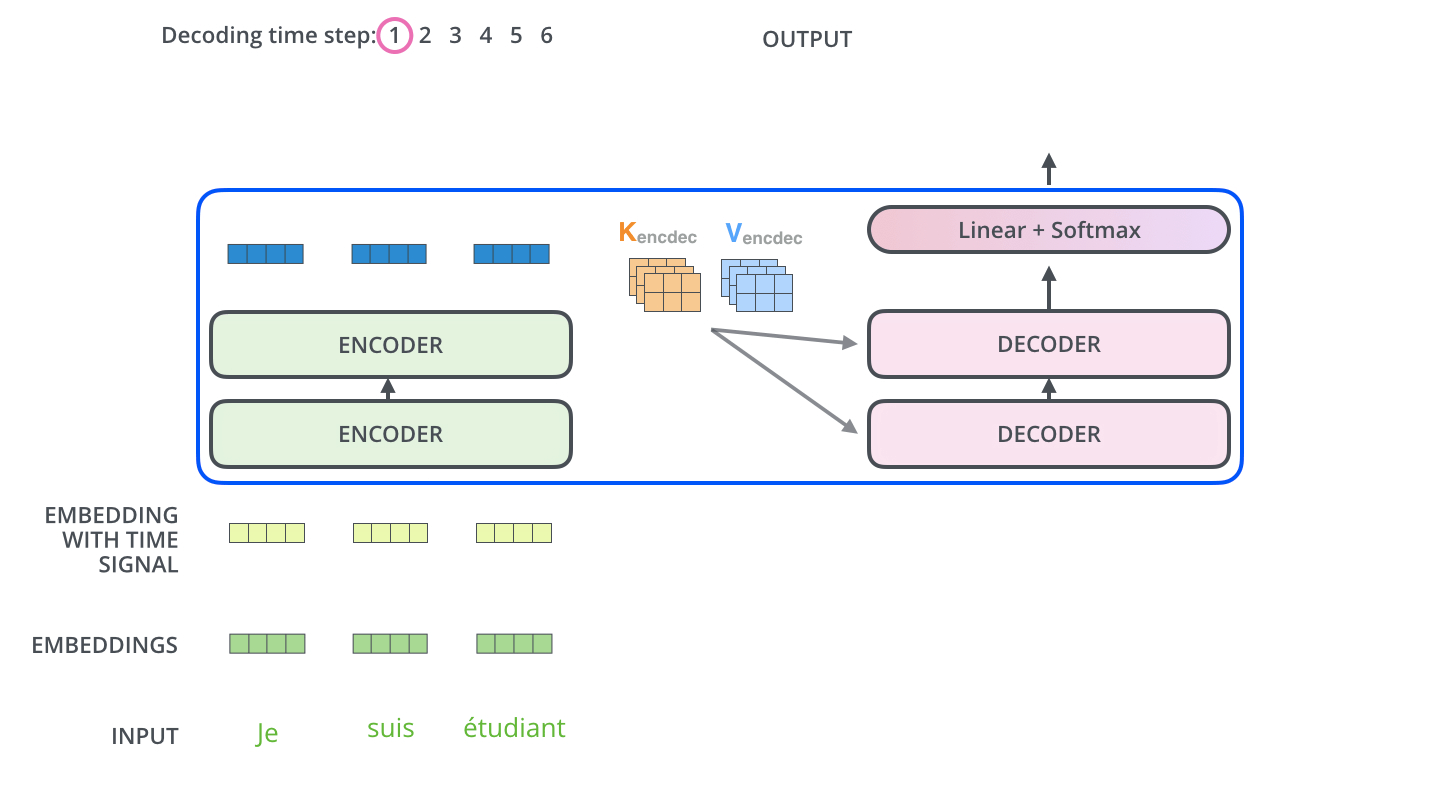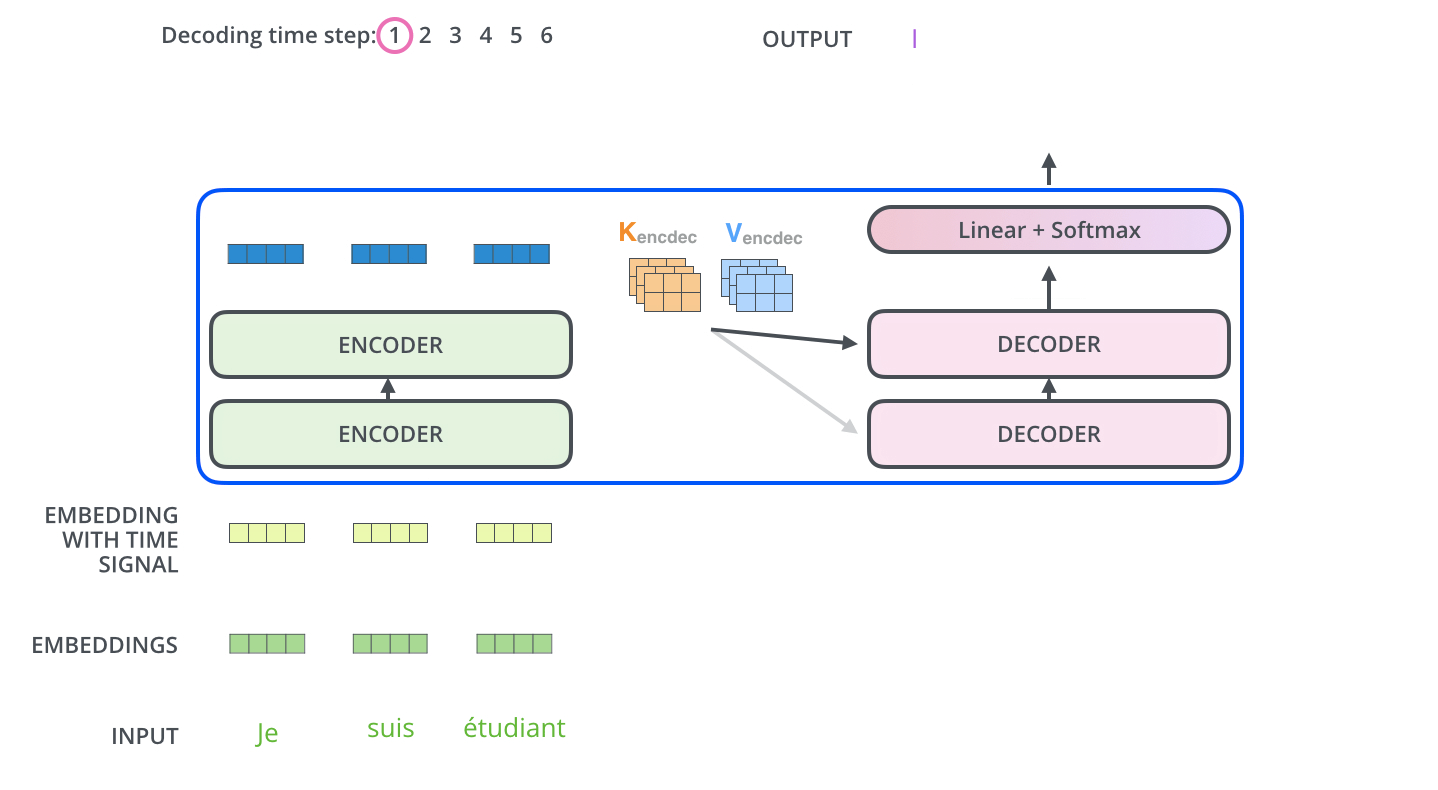
\*본 템플릿은 DSBA 연구실 이유경 박사과정의 템플릿을 토대로 하고 있습니다. Task: Recurrent와 Convolution을 배제한 Attention 메커니즘 모델 Transformer이전의 시퀀스 변형 모델은 RNN과 CNN을 기반으로 인코더와 디코더를
27.네이버 부스트캠프 5기 5주차 주간 회고

NLP Word Embedding One-hot vector >각 Token을 자기 자신을 1로 만들고 나머지를 0으로 만든다. 이떄 각 Token의 길이는 전체 Vocab size가 됨으로 각 token간의 차원이 매우 커짐으로써 차원의 저주에 걸리게 된다. Wo
28.[Seq2Seq with Attetnion 논문리뷰](Effective Approaches to Attention-based Neural Machine Translation)
Seq2Seq with Attetnion 논문리뷰를 진행하였습니다. 링크로 첨부하겠습니다.Seq2Seq with Attention Githubppt 버전도 있습니다.
29.네이버 부스트캠프 5기 15일차

위와 같은 데이터셋으로 0~9까지의 글씨 사진과 라벨로 0~9까지의 라벨이 그려져 있음위와 같은 모델을 구성할 경우 mnist의 이미지 shape (28,28,1)이 들어올때 이를 view함수로 먼저 (-1,28\*28)로 변환 시켜주고Linear층을 통하여 선형결합을
30.네이버 부스트캠프 5기 16일차

시퀀스 모델인 LSTM으로 Mnist를 분류 해보자우선 LSTM의 인풋은 총 3개이다 cell state와 h-1 state 이때 배치별로 처음 데이터가 들어올경우 t-1의 cell state와 h-1 state가 없음으로 단순히 torch.zeros를 통해 만들어주고
31.네이버 부스트캠프 5기 17일차

직사각형 막대를 이용하여 데이터의 값을 표현 주로 수직,수평으로 분류수직x값 : 범주 y값 : Value수평x값 : Value y값 : 범주각 그룹을 표시하는데 stack하여 표현하는 Plot이다.각 그룹의 순서는 항상 유지되어야 한다.물론 이 또한 barh를 이
32.네이버 부스트캠프 5기 19일차 ViT 코드리뷰
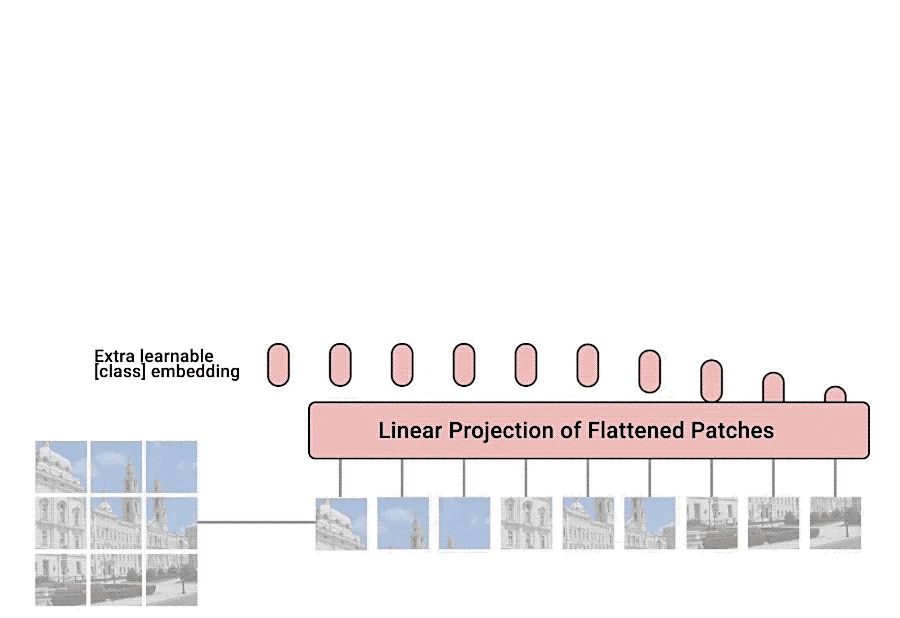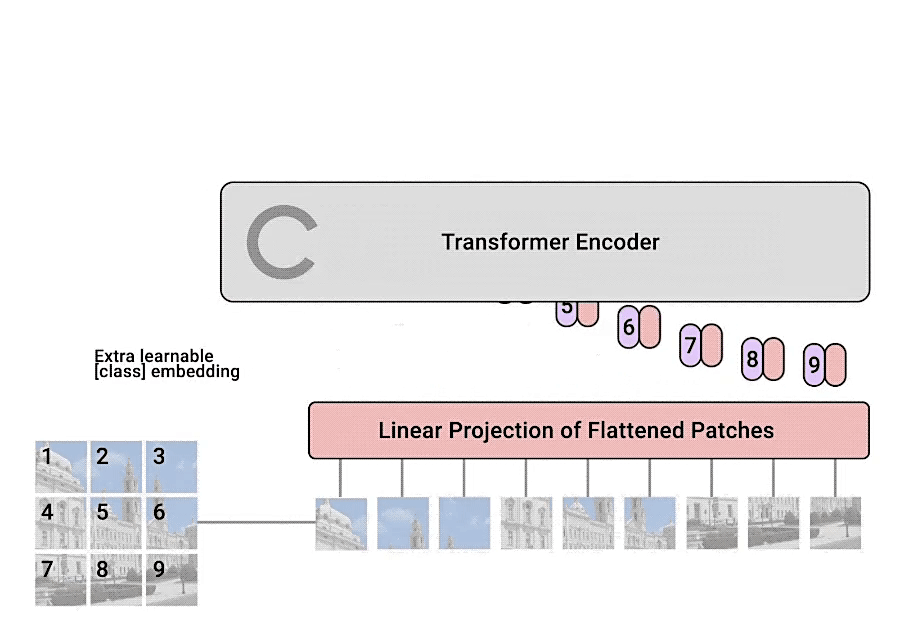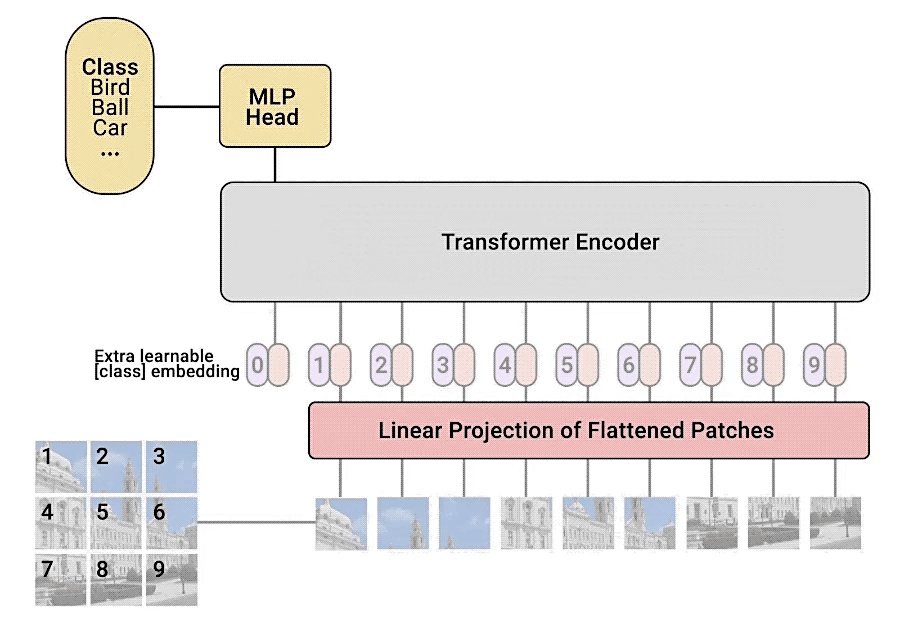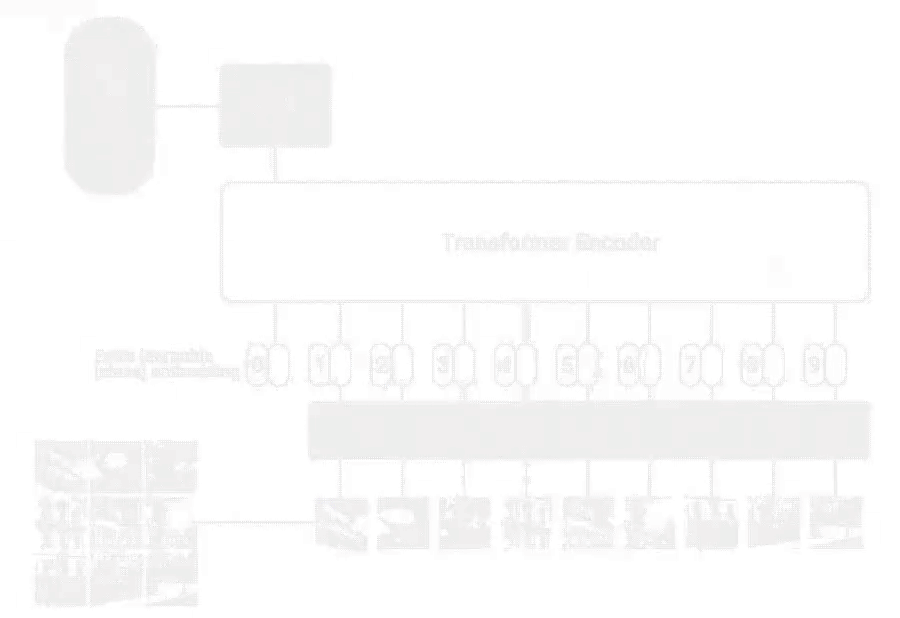
Vistion Transformer은 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale으로 구글에서 2020년 10월 20일날 발표된 논문이다 이미지 분류에 Transformer을 사용
33.[Seq2Seq 논문리뷰](Sequence to Sequence Learning with Neural Networks)

Seq2Seq에 대한 논문 리뷰입니다. 다만 PDF파일이라 첨부가 불가하여 Github링크를 첨부했습니다.
34.네이버 부스트캠프 5기 6일차

파이토치는 Fackbook에서 만든 딥러닝 프레임 워크로 Tensorflow와 양대산맥을 이루다 최근 주요 딥러닝 프레임 워크로 자리 잡은 라이브러리다.파이토치는 기본적으로 numpy + AutoGrad 즉 행렬연산과 미분기를 합친 것이라고 볼 수 있다.넘파이는 기본적
35.네이버 부스트캠프 5기 7일차

Pytorch Dataset > 우리가 일반적으로 딥러닝 모델을 사용 시 Mini batch를 사용함에 따라 모델에 데이터를 계속 N개씩 넣어줄 필요가 있다. 이때 넣어주기 전에 어디에서 꺼낼껀지 정의를 해줘야 하는 부분이 Pytorch Dataset 이라고 할 수
36.네이버 부스트캠프 5기 8일차

model의 가중치를 담아내고 있으며 딕셔너리 형태로 저장된다.학습 결과를 저장하기 위한 함수로 모델의 architecture와 모델의 weight를 저장한다.모델의 state_dict(파라미터)를 pt파일의 형식으로 저장한다.모델의 아키텍쳐까지 함께 저장하는 코드모델