[HyperDreambooth 논문 리뷰](HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models)
Alethio-Intern_2023
[HyperDreambooth](HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models)
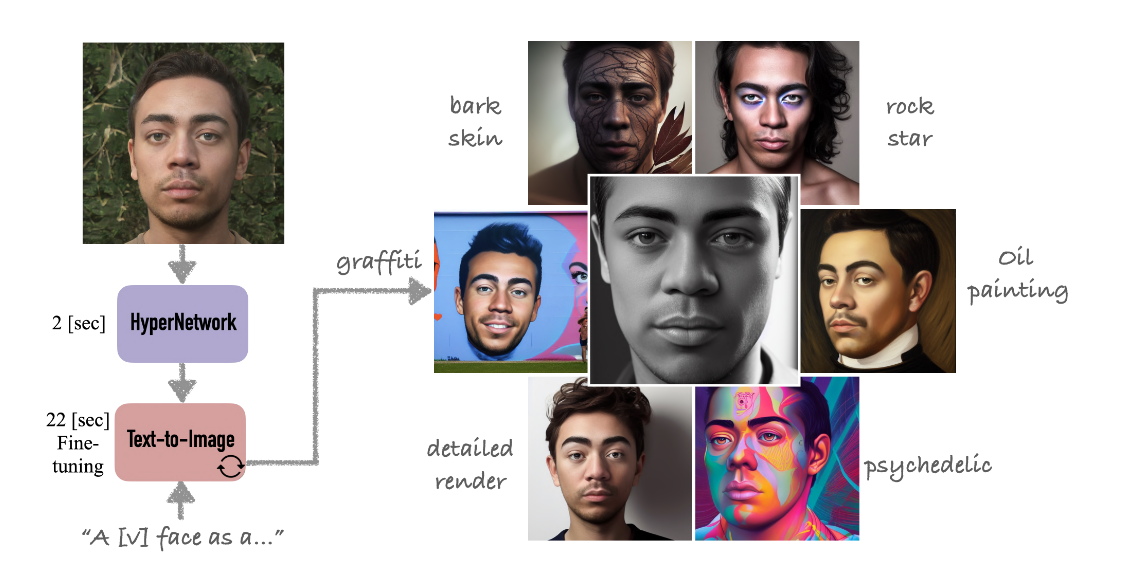
1. 논문이 다루는 Task
Task: Personalization of Text-to-Image Generation
- Input: Text
- Output: Image
- Personalization of Text2Image : 텍스트를 기반으로 이미지를 만드는 개인화된 생성 모델
2. 기존 연구 한계
2-1. Slow Personalization of Generative Models
기존의 DreamBooth의 경우 성공적으로 개인화된 생성 모델을 만들어 내었다. 하지만 하나의 모델을 만드는데 SD(Stability Diffusion)Full Fine-Tuning으로 진행되어 속도가 매우 느린점과 모델을 전체를 저장함으로써 이는 많은 저장공간을 차지한다.
3. 제안 방법론
Dreambooth가 5분이 걸리는 반면 25배(20초) 빠르며 10000배 작은 저장 공간을 차지하는 개인화 Dreambooth를 만드는 방법을 본 논문에서는 아래와 같이 설명한다.
3-1. Lightweight DreamBooth (LiDB)
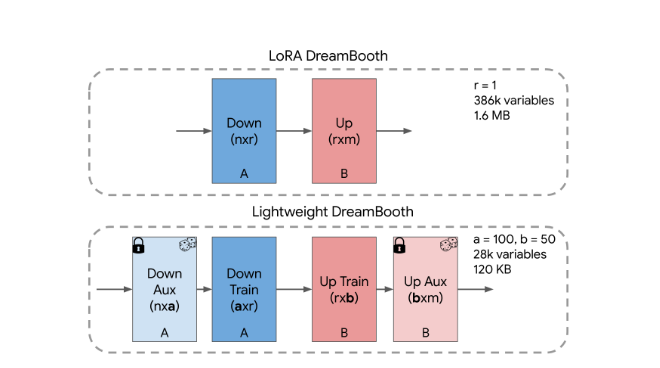
기존에 LoRA를 통한 DreamBooth가 존재하였지만 본 논문에서는 Rank가 1인 LoRA로 실험한 결과 효과적이어서 Rank를 1로 유지하는 대신 한번 더 Decomposed하여 더욱 저차원으로 내렸다.
위 그림 Rank=1 LoRA를 저차원으로 내린 LiDB에서 제일 앞단과 뒷단은 Aux로 무작위 직교 벡터로 초기화 되며 Freeze시킨다. 이후 가운데에 있는 레이어만 Train을 진행하게 된다.
그림에서 나온 a,b는 하이퍼파라미터로써 본 논문에서는 a=100, b=50을 사용하여 30K의 학습 파라미터와 120KB의 용량만으로도 기존 Dreambooth와 비슷한 주제 충실도, 편집, 스타일 다양성을(subject fidelity, editability and style diversity) 유지하였다고 주장한다.
저장공간으로써는 전체 Dreambooth의 0.01%의 크기, LoRA Dreambooth의 7.5% 저장공간을 차지한다.
3-2. HyperNetwork for Fast Personalization of Text-to-Image Models
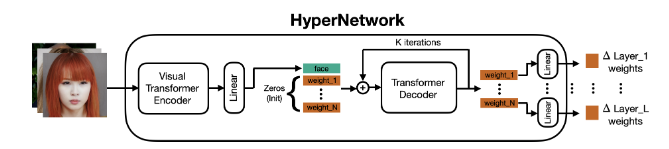
추후 LiDB를 직접학습하진 않고 HyperNetwork에 LiDB 레이어를 학습하여 HyperNetwork를 통해 LiDB 추론을 진행한다. 이때 인코더로는 ViT를 사용하며 디코더로 Transformer Decoder를 사용한다.논문에서는 Text Encoder, Diffusio의 Sequential 하기 때문에 Transformer Decoder가 적합하다고 주장한다. 이때 한번만으로는 예측이 불가한지 K iter를 반복적으로 돌며 학습과 추론을 진행한다.
ViT에서 추출된 Image feature를 Linear에 통과후 zero로 초기화된 Tensor와 concat시킨 후 Decoder를 통과해 각 weight가 LiDB 각각의 으로 들어가게 된다.
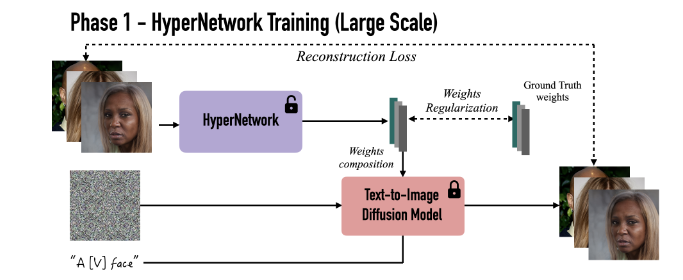
하이퍼네트워크를 훈련방식은 위 그림과 같다.
loss function은 위와 같은 식을 사용하게 되는데 Diffusion loss에 Regularization term을 붙힌 것이다. 는 위 그림의 Ground Truth(pre-optimized weight parameters)이며 이다.
3-3. Rank-Relaxed Fast Finetuning
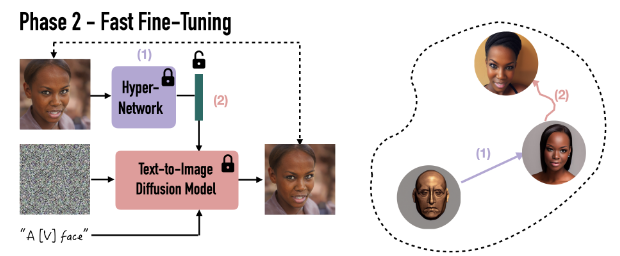
추후 하이퍼네트워크에 이미지를 넣어 LiDB를 추론하게 된다.
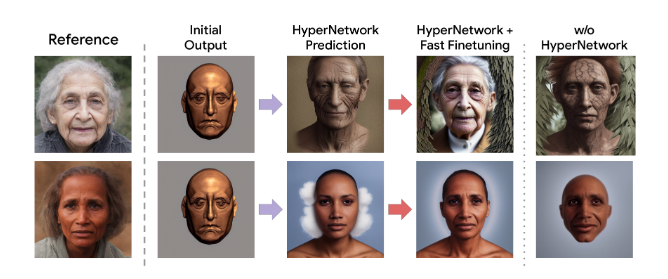
논문에서는 위 이미지와 같이 하이퍼네트워크 만으로도 꽤나 정확한 이미지 생성이 가능하다고 하다. 하지만 세세한 부분까지는 포착하지 못하여 Rank-Relaxed Fast Finetuning 방법을 제안하였다.
우선 을 진행한 후 Diffusion Denoising loss 를 통해 학습을 시킨다. 다만 이때 Rank-Relaxed하게 진행됨으로써 기존의 DiLB를 기존의 가중치와 병합 후 새로운 인 LoRA를 추가하여 학습을 진행한다. 이럴경우 대략 40iter 이면 수렴을 한다고 주장한다.
✨Contribution
- LiDB : 작은 저장용량과 빠른 학습과 추론을 위해 설계하였다.
- HyperNetwork : LiDB를 예측하기 위해 제네럴한 하이퍼네트워크를 설계하여 초기값에 빠르게 도달한다.
- Rank-Relaxed Fast Finetuning : 보다 세밀한 정보를 캡처하기 위해 의 LoRA를 부착시켜 적은 iter만 학습시킨다.
Draembooth의 Full-Finetuning의 저장공간을 축소시키고 보다 빠르게 수렴시키기 위해 초기 값을 HyperNetwork로 추론 시킨다.
4. 실험 및 결과
SD 모델은 Stale Diffusion v1.5를 사용하였으며 Text Encoder와 Unet에 LoRA를 부착시킨다.
데이터로는 CelebA-HQ를 사용하였다.
4-1. Subject Personalization Results && Qualitative Comparisons

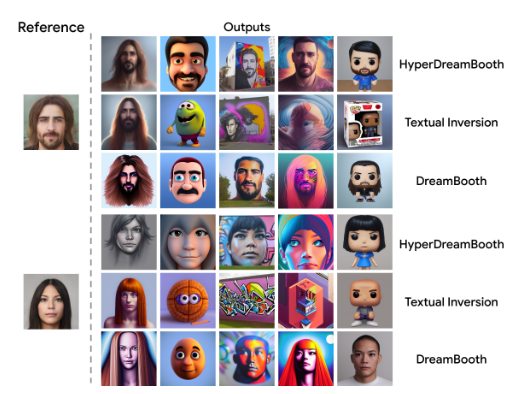
4-2. Quantitative Comparisons and Ablations
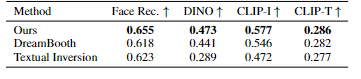
face identity preservation (Face Rec.)(얼굴보존), 및 DINO,CLIP-I(subject fidelity), CLIP-T(rompt fidelity) 모델에서 점수를 측정하여도 속도도 빠르면서 DreamBooth보다 높은 점수를 기록하였다.
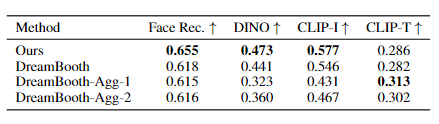
Agg-1,2는 각각 파라미터를 다르게 설정한 Dreambooth이며 각각 400iter, 40iter의 Dreambooth이다. normal Dreambooth는 1200iter이다. 이때도 Dreambooth는 이미지가 왜곡되는 현상이 있었으며 파라미터를 다르게해도 HyperDreambooth보다 낮은 점수를 기록하였다.
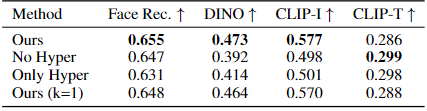
하이퍼네트워크의 여부 및 파라미터 값 조정에 따른 점수이다. 이는 즉 하이퍼네트워크의 k iter와 중요성을 강조한다.
4-3. User Study
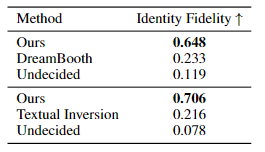
실제 사용자 테스트 결과 60~70%확률로 높은 선택을 받아 기존의 Dreambooth보다 자연스럽고 정확한 이미지를 생성해내는것을 증명하였다.
5. Conclusion
HyperDreamBooth는 다른 개인화된 모델에 비해 HyperNetwork를 통한 LiDB 추론과 fast rank-realaxed finetuning을 통하여 개인화 작업에 크기와 속도를 줄였다.
6. 회고
일하면서 공부하는 논문인데 막상 논문 마지막에 Societal Impact 파트가 존재하였다. 하지만 코드 공개도 안하면서 Societal Impact 파트를 적어두니 웃기긴하다. 얼른 코드가 공개되거나 다른사람이 비슷하게 구현했으면 하는 바람이다.
참고자료
https://hyperdreambooth.github.io/
https://arxiv.org/abs/2307.06949
