[ImageBind](One Embedding Space To Bind Them ALL)

1. 논문이 다루는 Task
Task: Emergent Zero-Shot Classification, Retrieval
- Input: Text, Image, Depth, Video, Audio, Therma, IMU, Depth
- Output: Retrieval, Text, Image
- Emergent Zero-Shot Classification : Pair가 없는 데이터 셋에 대하여 통합적인 Embedding Space를 통한 분류
2. 기존 연구 한계
A single image can bind together many experiences – an image of a beach can remind us of the sound of waves, the texture of the sand, a breeze, or even inspire a poem.
2-1. Required acquiring all types and combinations of paired data
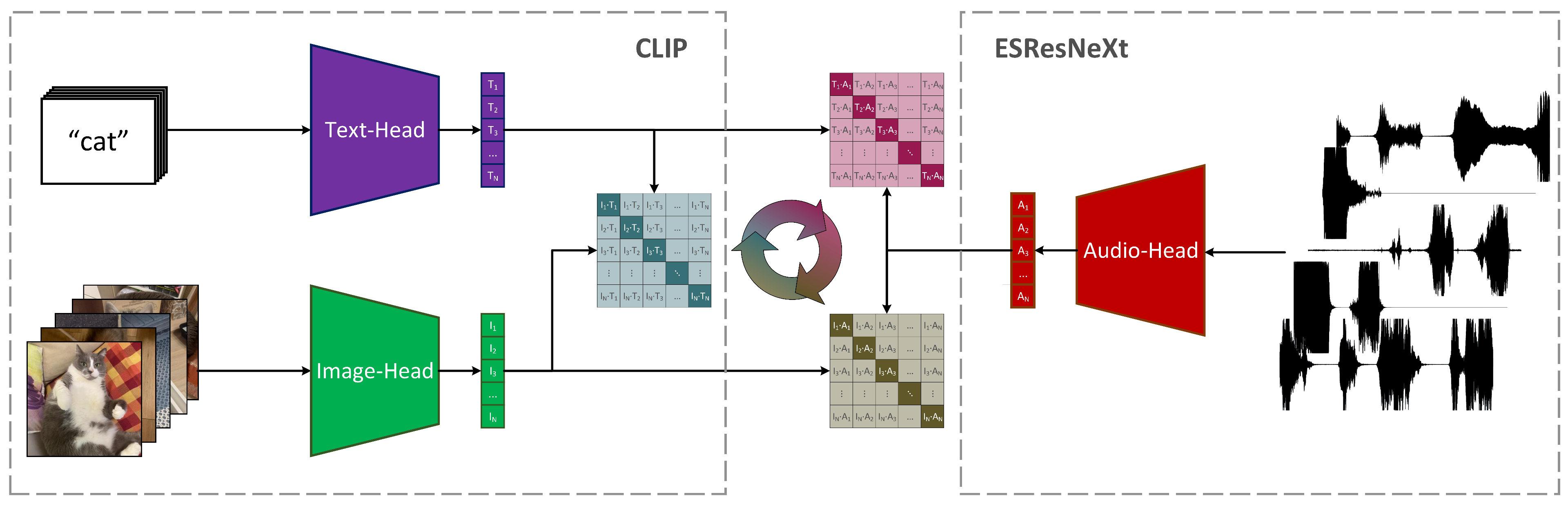
이미지 한장 에는 많은 정보가 포함되어 있다고 말할 수 있다. 이미지를 보면 떠오르는 소리, 글등 많은 정보가 실제로 있지만 이를 활용하지를 못한다. CLIP에서는 Image-Text Pair를 사용하여 이를 텍스트로 이미지를 연결해 Zero-Shot을 훌륭하게 수행하였지만 Text-Audio 등과 같은 데이터는 매우 적고 없는 경우도 있으며 Text-Image에서 얻은 정보를 Text-Audio에서는 활용할 수 없다. 위 그림의 AudioCLIP이란 모델 또한 Text-Audio이며 이런 모델들은 다른 모달리티를 연결하기 위해 해당하는 모달리티의 쌍이 필요함을 의미한다.
3. 제안 방법론

ImageBind를 제안하며 Binding modalities with images를 설명한다. Image-(Pair)을 통해 한 공간에 맵핑되는 Representation Space를 구성하여 학습하자. 이때 논문에서는 각 다른 모달리티의 임베딩을 이미지 임베딩을 통해 정렬한다고 설명한다.
3-1. Binding modalities with images && InfoNCE Loss
ImageBind는 이미지로 모달리티를 바인딩한다. 이때 에서 는 이미지 은 다른 모달리티를 나타낸다. 이때 은 이미지와 연결되는 Audio, Depth, Thermal, IMU등을 이미지와 함께 Pair로 사용하게 된다.
각 서로 다른 모달리티는 우선 임베딩 차원으로 보내는데 각각 모달리티마다의 크기가 다른 ViT인코더가 존재하게 된다.
이후 기존의 CLIP과 다르게 InfoNCE Loss를 사용한다.
일 경우 같은 는 일종의 positive pair이며 일 경우 negatives pair이다. 즉 음의 log이므로 postive pair의 내적값이 1에 가까워질 수록 은 0에 가까워져 Loss가 0에 점차 수렴하게 된다. 이때 는 스칼라값이며 softmax의 분포를 조절하는 값이다.
실제로 Loss는 배치내의 유사한 샘플(CLIP의 CE Loss와 2개인것과 동일하다.)에 대하여 처리하도록 연산을 수행한다.
훈련할 시 실제 Image를 입력받는 ViT와 Text Encoder는 가중치를 동결시키며 결과적으로 과 으로 훈련을 진행하여도 이 작동하는것을 관찰한다고 논문에서 주장한다. 이로써 Image-text, Image-Audio로 훈련을 시켜도 Text-Autio가 가능하게끔 된다. 아래와 같은 예시 이미지가 동작한다.

3-2. Implementation Details
우선적으로 모든 Encoder는 Transformer(ViT) 기반의 아키텍처를 가져온다.
이때 각각의 모달리티마다의 다른 ViT를 사용하며 이미지와 동영상의 경우는 동일한 ViT를 사용한다.
- 동영상의 경우 2frame을 샘플링한다. 이때 동영상은 이미지와 오디오로 나누어지며
- 오디오는 16kHz로 샘플하며 128 mel-spectrogram로 변환시켜 사용하게 된다.
- 추가적으로 열화상 이미지와 Depth이미지의 경우 one-channel이미지로 사용하게 된다. 이때 Depth는 disparity map으로 변환하여 사용한다.
- IMU는 가속도와 자이로스코프로 구성되어 IMU 신호를 X,Y,Z축에 걸쳐 추출하며 추가적인 후처리후에 사용한다.
- Text의 경우 CLIP과 동일하게 사용된다.
추후 모든 모달리티별 ViT 위에 Loss로 보낼 차원을 계산하는 Linear Layer를 추가하며 Image와 Text 인코더의 경우 사전 훈련된 CLIP 또는 OpenCLIP의 가중치를 사용하게 된다.
✨Contribution
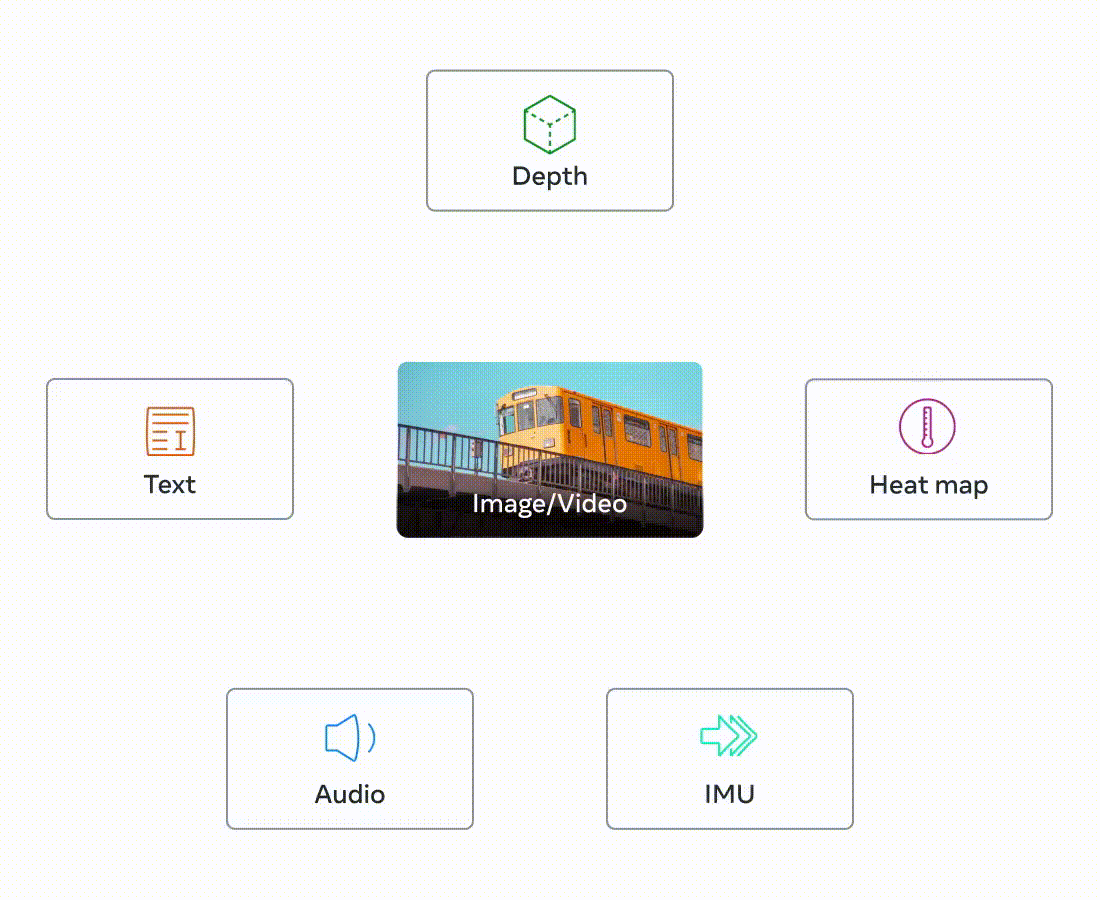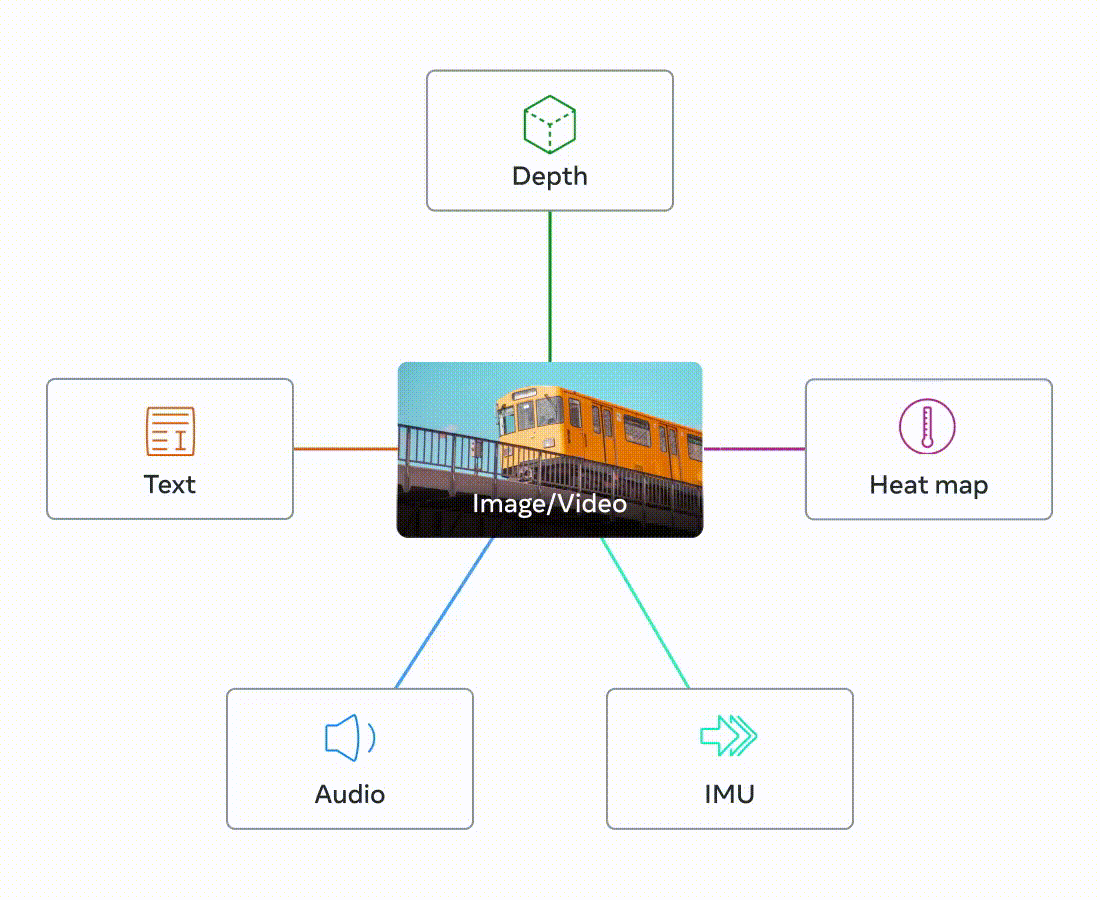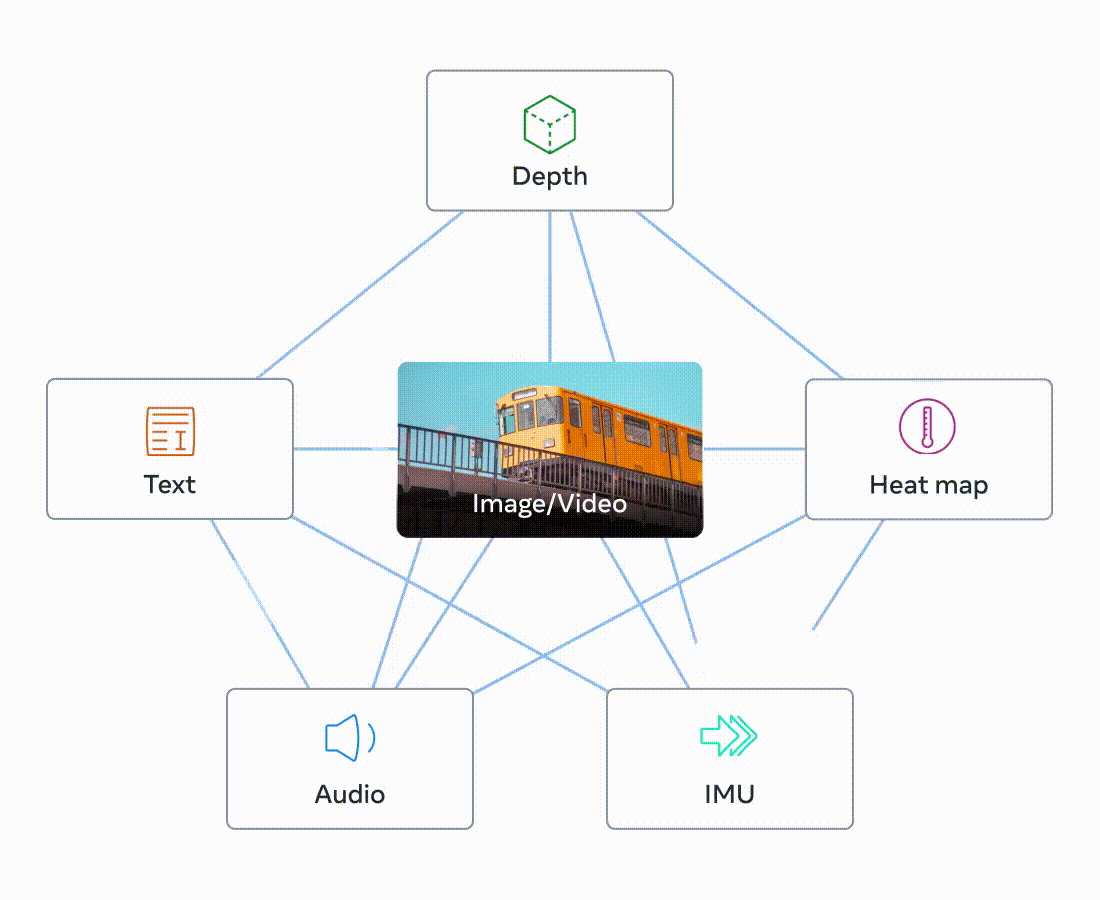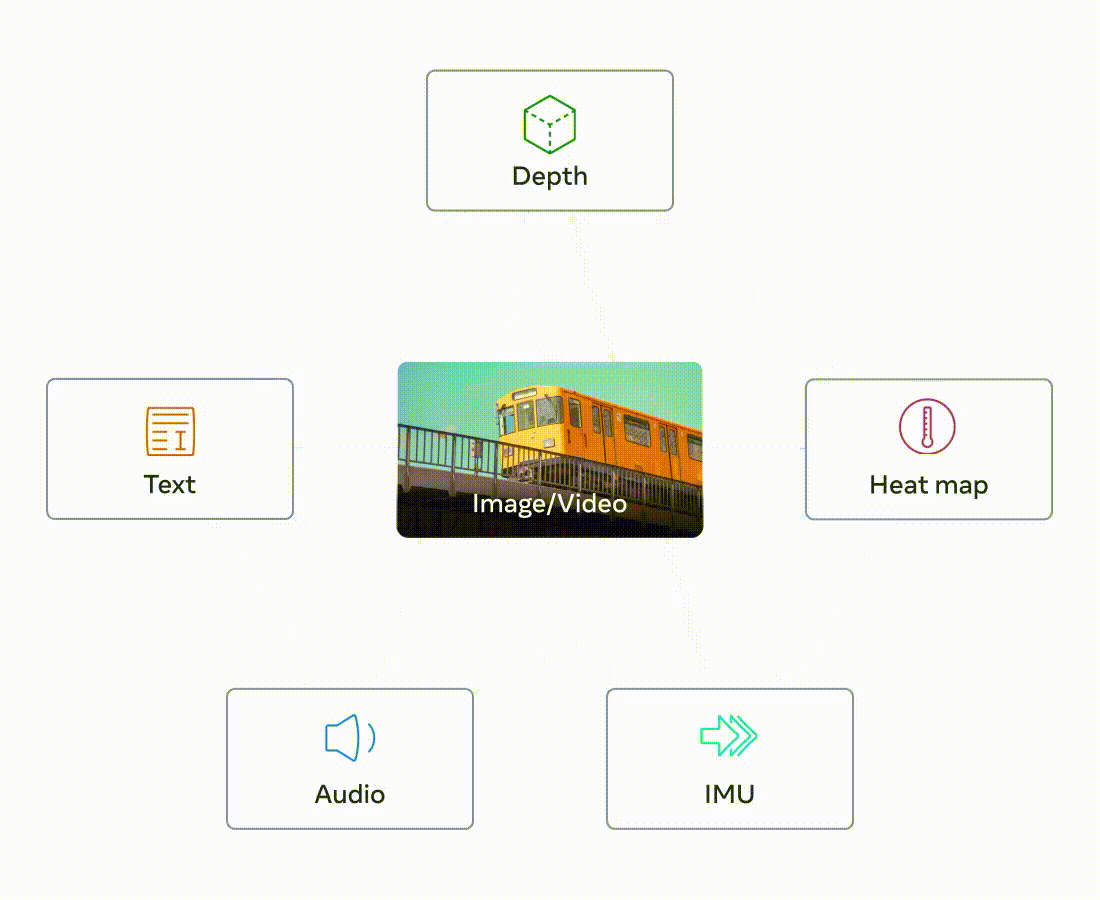
- Emergent alignment : pair가 존재하지 않는 데이터를 이미지를 통해 정렬하여 , 에 대해 가 정렬되어 각각의 모달리티와 이미지를 정렬하는 것이 서로 다른 모달리티도 정렬되는 현상을 발견하였다.
4. 실험 및 결과
Experiments는 Emergent zero-shot classification 위주로 살펴보면 될것이다.
4-1. Emergent zero-shot classification

각 아이콘은 이미지, 동영상, Depth, Audio, Thermal, IMU 순이다.
위 그림에서 파란색으로 색칠된 부분은 pair가 없는 데이터 쌍으로 학습을 시켰을 때이다.
일반적인 zero-Shot과 다르게 Emergent zero-shot이라고 논문에서 설명한다.
이때 특이사항으로 Emergent zero-shot의 경우 대부분 SOTA를 달성하였다.
4-2. Few-shot classification
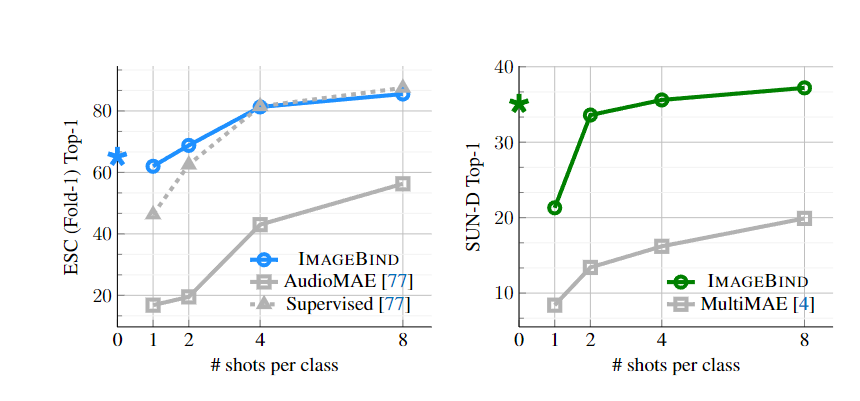
Few-shot의 경우 CLIP과 유사하게 선형 레이어를 부착후 Few-Shot을 진행하게 되는데 ImageBind가 self-supervised로 학습된 AudioMAE보다 높은 성능을 나타낸다. 심지어 논문에서는 일반화가 잘되는 4-shot에서도 보다 높은 성능을 나타낸다는 점을 강조하였다.
MultiMAE의 경우 image,depth,segmentaion mask로 훈련되었지만 모든 구간에서 이보다 훨씬 높은 성능을 달성하였다.
4-3 Object detection with audio queries && Audio Diffusion

Detic의 모델의 경우 CLIP-based의 Detection model인데 이때 CLIP의 'class' embeddings를 ImageBind의 audio embeddings로 교체하면 소리로도 Detection이 된다.
추가적으로 DALLE-2같은 경우 prompt embeddigs을 audio embeddings로 교체할 경우 Diffsion을 Audio로 만들어 낼수도 있다고 한다.
4-4. IMAGEBIND to evaluate pretrained vision model
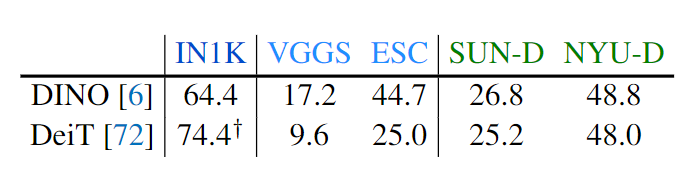
supervised DeiT 모델과 self-supervised DINO 모델을 이미지 인코더로 가져갔을시 DINO 모델이 보다 emergent zero-shot classification이 잘되었다. 이는 ImageNET의 순수 비전 성능과 상관없이 완전히 다른 특성을 관찰한다고 주장한다. 논문에서는 이러한 점을 multimodal applications에서 비전 모델의 성능을 측정하는데 좋은 도구가 될수 있다고 주장한다.
5. Conclusion
Pair가 없는 데이터에 대하여 이미지 인코더를 통해 정렬시켜 Emergent zero-shot classification을 가능하게 하였다. 각각의 모달리티에 대해 필요한 pair 데이터를 확보하지 않아도 같은 Representation Space로 보낼 수 있게 되었다.
6. 회고
일하면서 바쁜데 주말에 관심 분야 논문이라도 읽으니 괜찮은 것 같다.
참고자료
https://arxiv.org/abs/2305.05665
https://www.youtube.com/watch?v=cfU_QPNcl2U&ab_channel=AIBites

많은 노력을 하신게 보이네요. 깔끔하고 좋은 연구같습니다