
[SLIP](SLIP: Self-supervision meets Language-Image Pre-training)
1. 논문이 다루는 Task
Task: Vision-Language
- Input: Image, Text
- Output: Image Representation, Text Representation
2. 기존 연구 한계
최근 Computer Vision 분야에서 두 가지 주요한 접근 방식으로 지도 학습과 자기지도 학습이 주목받고 있다. 이들 각각은 Representation 학습에 있어 강력하지만, 여전히 몇 가지 한계점들이 존재하게 된다.
2-1. 지도 학습의 한계
지도 학습은 대규모 레이블된 데이터에 크게 의존한다. 예를 들어, ImageNet이나 Google의 JFT 데이터셋과 같은 대규모 데이터셋을 사용하는 것은 확실한 방법이지만, 이러한 접근법은 데이터의 편향 문제를 포함하게된다. AlexNet 이후, 레이블된 데이터를 이용한 사전 학습은 여전히 레이블이 필요한 한계를 가지고 있으며 SLIP은 이러한 한계를 극복하기 위해 이미지 자기지도 학습(Image Self-Supervision)과 언어 감독(Language Supervision)을 결합하는 새로운 방법을 제안하게 된다.
2-2. Contrastive Learning의 개발
최근 CLIP과 같은 대규모의 Contrastive Learning 방법론이 개발되었으며, 이는 ImageNet과 같은 대규모 데이터셋에서의 성능 향상에 기여했다. 이러한 발전을 바탕으로, 보다 높은 성능을 달성하기 위해 Contrastive Learning과 이미지에 대한 자기지도 학습을 함께 사용하는 방향으로 발전하고 있다.
3. 제안 방법론
3-1. Contrastive Language-Image Pre-training (CLIP)
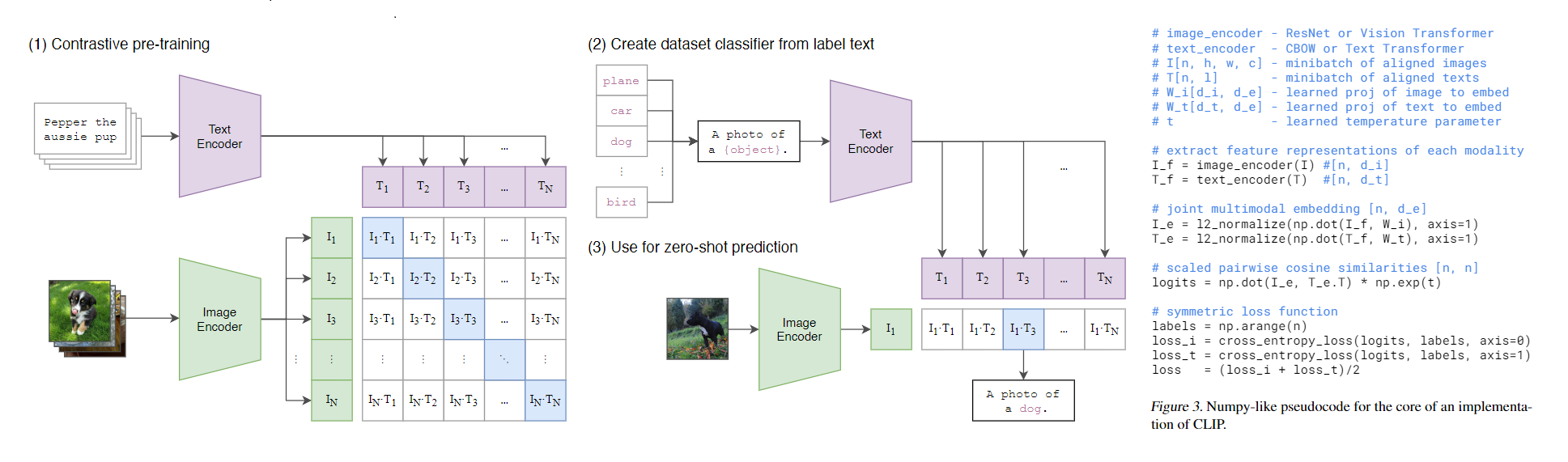
SLIP은 기본적으로 CLIP을 사용하게 된다. 이미지와 캡션간 Contrastive Learning을 통하여 학습이 되며 이미지와 텍스트는 각각의 모델로 임베딩된 후, 공통의 임베딩 공간으로 투영된다.
InfoNCE Loss를 사용하여 임베딩에 대하여 Positive Pair와 Negative Pair를 계산하게 된다.
자세한 사항은 아래와 같이 나타낸다.
CLIP 논문 리뷰 Velog 글
3-2. SimCLR을 활용한 Image Self-Supervision Learning

Pseudocode는 위와 같다 이때 clip은 동일하게 계산하며 아래의 simclr을 분석하면 이와 같다.
- z1,z2의 경우 각각 서로 다른 augmentation이 적용된 이미지 샘플쌍이 들어오게 된다.
- mask는 배치 수 일 경우 x의 매트릭스가 생성되며 대각선 부분은 모두 1e-9 나머진 0인 행렬이 생성된다.
- logit은 동일하게 서로 다른 augmentation된 샘플이 dot product를 진행하게 돼 유사도를 구한다.
- logit1,2의 경우 z1,2 스스로를 dot product하게 되며 이때 mask를 빼주어 대각행렬의 경우는 매우 낮은 값으로 강제하게 된다. 이때 강제하게 될경우 자기 자신의 샘플은 CrossEntropy에서 softmax함수에 의해 고려하지 않는 샘플로 생성된다.
- 이후 logit과, logit1,2를 concat 시키게 되는데 코드를 보니 dim=1로 작성되어 있다. 이렇게 될 경우 만약 일 경우 logit=x의 매트릭스에 logit1,2를 concat시키게 되면 x의 행렬이 만들어진다.
- 이 x의 행렬은 1행을 기준으로 4열까지는 서로 다른 Augmentation을 고려하며 5열~8열까지는 같은 Augmentation이 적용되며 유사도를 고려하게 된다. 이때 1열~4열은 다른 Augmentation이 적용되어 같은 샘플들 끼리의 유사도 완전히 같지 않지만 5열~8열은 같은 Augmentation이 적용되어 대각선의 경우 1의 유사도가 나오므로 이를 마스킹처리를 해준다.
- 이후 각각에 CrossEntropy를 걸어 Return 시켜준다.
4. 실험 및 결과
4-1. ImageNet Classification
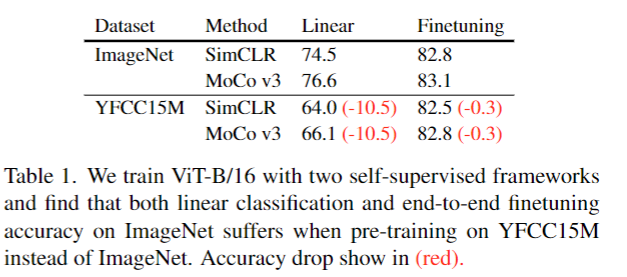
- Pretrain Dataset을 ImageNet과 YFCC15M으로 훈련 후 각각 ImageNet에서 평가하였을때의 결과이다.
Linear(Backbone Model 동결)의 경우 결과가 10%정도 감소하였으며 Finetuning의 경우 모두 성능이 감소하였다.
논문에서 이는 기존까지 보고된 논문과는 다르게 일반적으로 현저하게 성능이 감소하였다.
이 지표를 들고온 이유는 SLIP는 오직 YFCC100M의 하위 데이터세트 집합인 YFCC15M만을 사용하였기 때문이다.
또한 ImageNet의 경우 사람이 선별한 깔끔한 데이터이다. 이는 실제 현실에 데이터와 거리가 있으므로 보다 현실적인 데이터인 YFCC15M을 사용하였다.
실제로는 이러한 정도의 데이터셋의 성능 격차로도 추후 아래의 실험에 대한 결과들이 얼마나 의미있는 결과인지 입증해줄것이다.
4-2. Zero-shot transfer
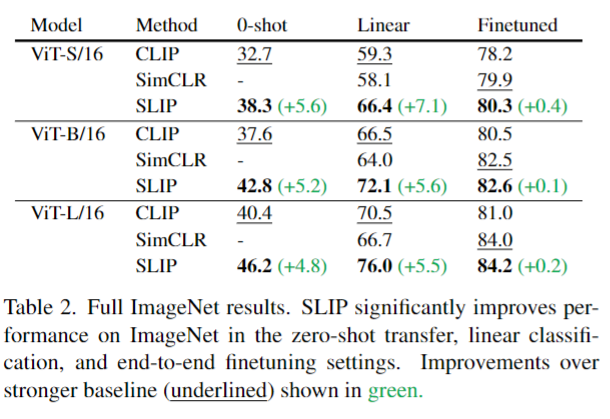
- 논문에서는 0-shot, Linear, Finetuned 모두를 평가하였다. 이때 ViT의 모든 모델들의 Pretrained는 YFCC15M 데이터셋만으로 학습시켰다.
결과적으로는 모두 성능이 올랐다.
Image Self-Supervision Learning으로만 훈련시킨 모델은 zero-shot 평가가 불가능하다.
4-3. Linear Classification, End-to-end Finetuning
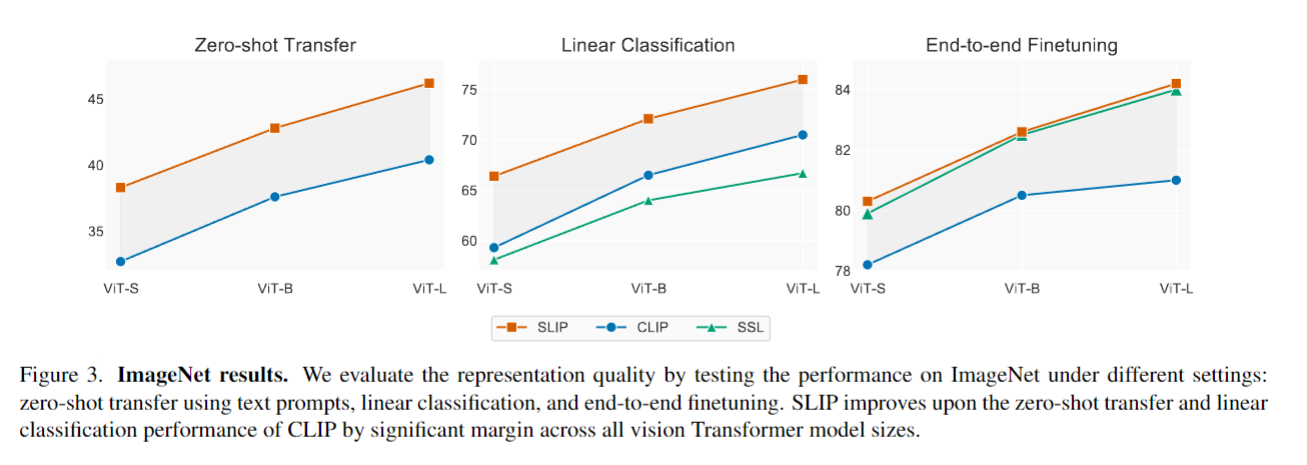
-
Linear Classification에서 특히 ViT-L의 경우 SLIP과 SSL은 10%이상 차이가 나며 그래프 또한 SLIP은 거의 선형적으로 증가하는 반면 SSL은 증가폭이 점점 줄어드는 양상을 보아 SSL은 모델이 이제 과포화 상태지만 SLIP은 더 큰 모델로 확장 가능하다는 부분을 볼 수 있다.
-
End-to-end Finetuning의 경우 Table 1.의 경우에서 크게 점수 하락이 발생하지 않은 점을 고려하여 실제로 YFCC15M의 데이터셋과 연관성이 없지 자체 ImageNet의 데이터 만으로도 모델이 그 분포에 적응할 수 있어 실제로 Figure 3.의 Finetuning의 결과는 직접적으로 비교할 수 없다고 강조한다.
반면 CLIP과 SLIP의 비교 같은 경우 CLIP은 이제 모델의 사이즈를 늘려도 0.5%의 차이밖에 나지 않는다. 이는 Image Self-Supervision Learning의 방법이 실제로 효과가 있다고 증명하고 있다.
4-3. Model and Compute Scaling
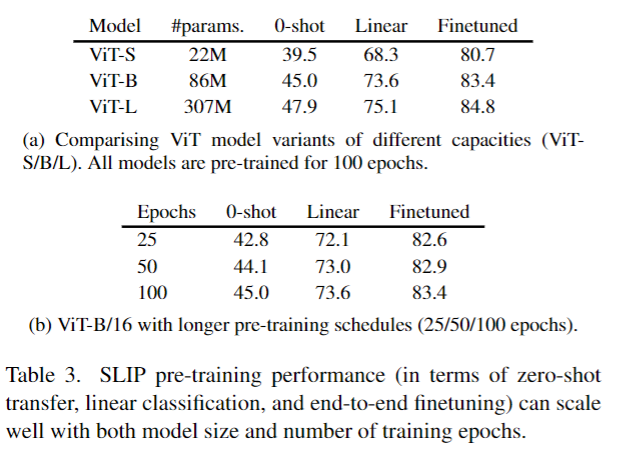
- 이 섹션에선 모델의 사이즈를 키우거나 더 많은 Epoch로 훈련시켰을때의 결과를 보여주게 된다.
보다 싶이 무리 없이 모델의 사이즈와 Epoch에 맞게 성능이 점차 올라가는 것을 볼 수 있다.
4-4. Additional Benchmarks
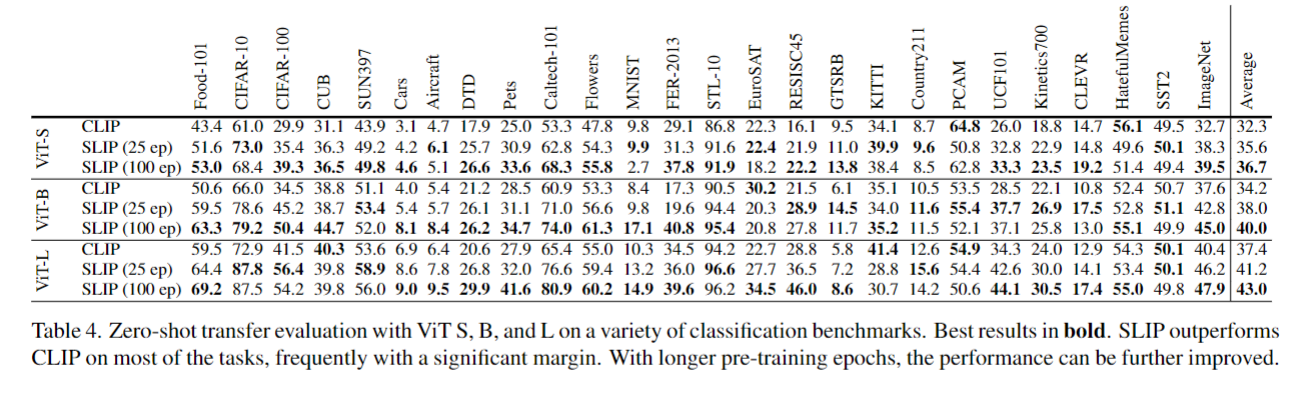
- 대규모의 데이터 셋에서 Zero-shot을 평가하였다 대부분 SLIP의 경우 기존 CLIP 보다 우세한 성능을 나타내면서 잘확장된다는 것을 볼 수 있다.
4-5. Additional Pre-training Datasets
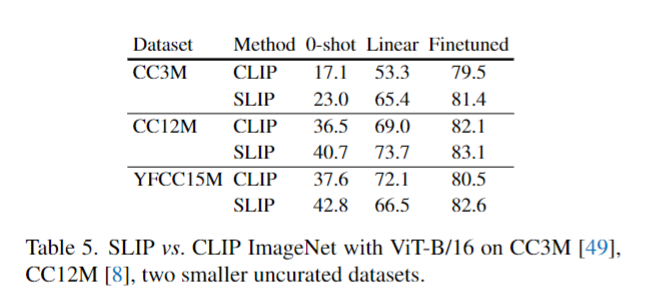
- Pretrain 데이터셋을 위와 같이 변경하였을때의 ImageNet에 대한 평가이다.
YFCC15M의 Linear을 제외한 모든 부분에서 일관된 성능 향상을 관찰할 수 있다.
추가적으로 논문에서는 CLIP의 경우 CC3M과 같은 데이터 셋에서는 극적으로 모델이 과적합되었다고 주장한다.
4-6. Alternative Self-Supervised Frameworks
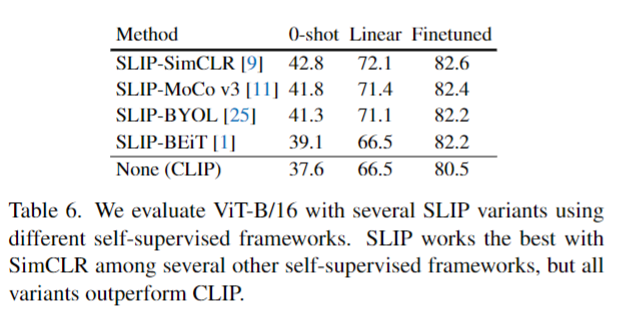
- 여러 Image Self-Supervision Learning 방법을 직접 적용하여 테스트 하였을때 CLIP과 가장 잘맞는 방법은 SimCLR의 방법이 가장 유효하다고 주장하지만 일관적으로 성능이 전부 오른것을 확인 할수 있다.
놀라운 점으로는 가장 최근에 나온 BeiT의 기법이 상당히 높지않다는 점인데 이는 사전학습때와 평가할때의 입력이 조금 불일치한다고 한다.
5. Further Analysis
저자들은 총 3가지의 추가적인 실험을 제안하였다.
5-1. Why not pre-train with SSL and finetune with CLIP?

- SSL로 훈련한 후 이 가중치를 CLIP의 이미지 인코더로 초기화 하는 방법을 시도하였지만 이는 CLIP + SSL 보다 성능이 감소하였다. 초기값의 경우 기존보다 높았지만 추후 성능이 정체되었다고 한다.
5-2. Is SLIP just CLIP with data augmentation?
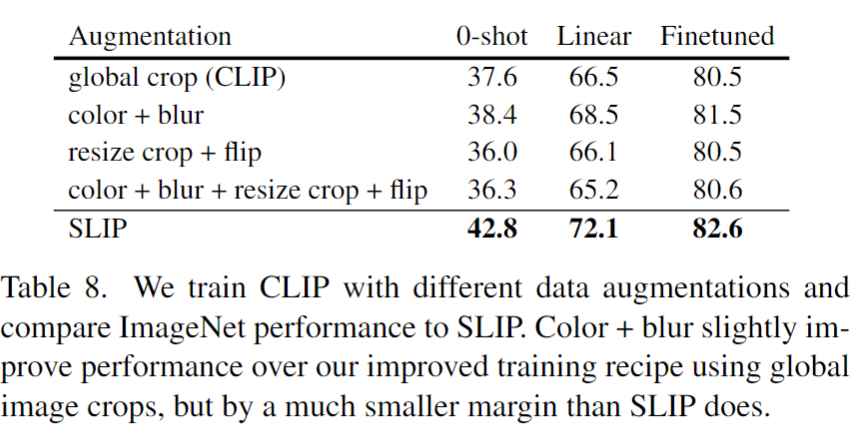
- SLIP이 단순히 CLIP에 데이터 증강을 추가한 것인지에 대한 실험이 이루어 졌다. 그러므로 CLIP에 다양한 데이터 증강 방법을 적용하였지만 성능은 올라가도 SLIP에 도달하지는 못하였다.
5-3. Can we fully decouple self-supervision from language supervision?
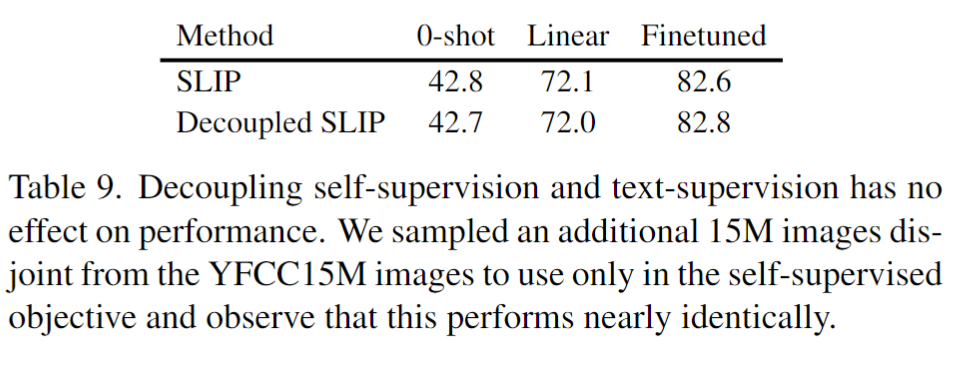
- Language SuperVision과 Image Self-Supervision Learning을 완전히 분리하는 것을 목표로 훈련하였다. 사실 이 부분은 잘 이해를 하지 못하였다.
6. Conclusion
- 기존 CLIP에 다양한 Image Self-Supervised Learning 기법을 적용함으로써 각종 이미지 분류에서 성능향상을 이루었다.
- ImageNet에 대한 편향을 제거하고 보다 현실적인 데이터인 YFCC15M을 사용하여 광범위한 실험을 진행하였다.
7. 회고
SLIP이 마치 이름이 자는거 같지만 그래도 저번에 BeiT를 읽고 이 논문을 읽었는데 나와서 반가웠다.
BeiT가 들어있는지는 몰랐고 이 논문이 Image Self-Supervision Learning 기법과 연관성이 있는지는 모르고 읽었는데 알고보니 Image Self-Supervision Learning에 관해 다루는 내용이라 읽기 굉장히 편했으면 SimCLR도 동시에 공부 할 수 있었다.
