[BEiT](BEiT: BERT Pre-Training of Image Transformers)
1. 논문이 다루는 Task
Task: Computer Vision
- Input: Image
- Output: Image Representation
2. 기존 연구 한계
2-1. Vision Transformers의 데이터 의존성 문제
- 컴퓨터 비전에서의 Transformer 모델들은 CNN에 비해 더 많은 학습 데이터를 필요로 한다.
- 이 문제를 해결하기 위해 contrastive learning, self-distillation 등 여러 방법이 탐구되었으나, 이미지 데이터에 대한 BERT 스타일의 사전 학습은 충분히 연구되지 않았다.
3. 제안 방법론
3-1. Image Patch
- 이미지는 두 가지 형태로 표현됩니다: 이미지 패치와 시각적 토큰
- 이미지는 에서 개의 패치 로 나누어지게된다
- 실험에서는 224×224 이미지를 16×16 패치의 14×14 그리드로 분할한다.
- 시각적 토큰은 이미지를 에서 로 변환하는 이미지 토크나이저에 의해 생성된다.
3-2. Visual Token
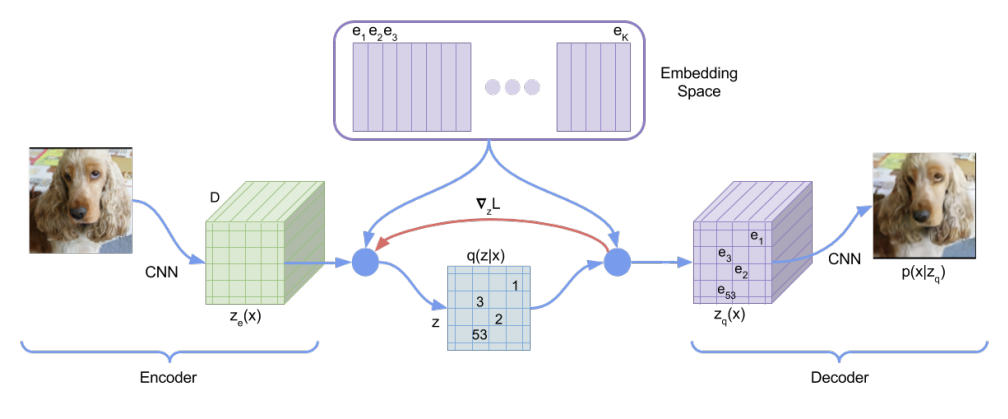
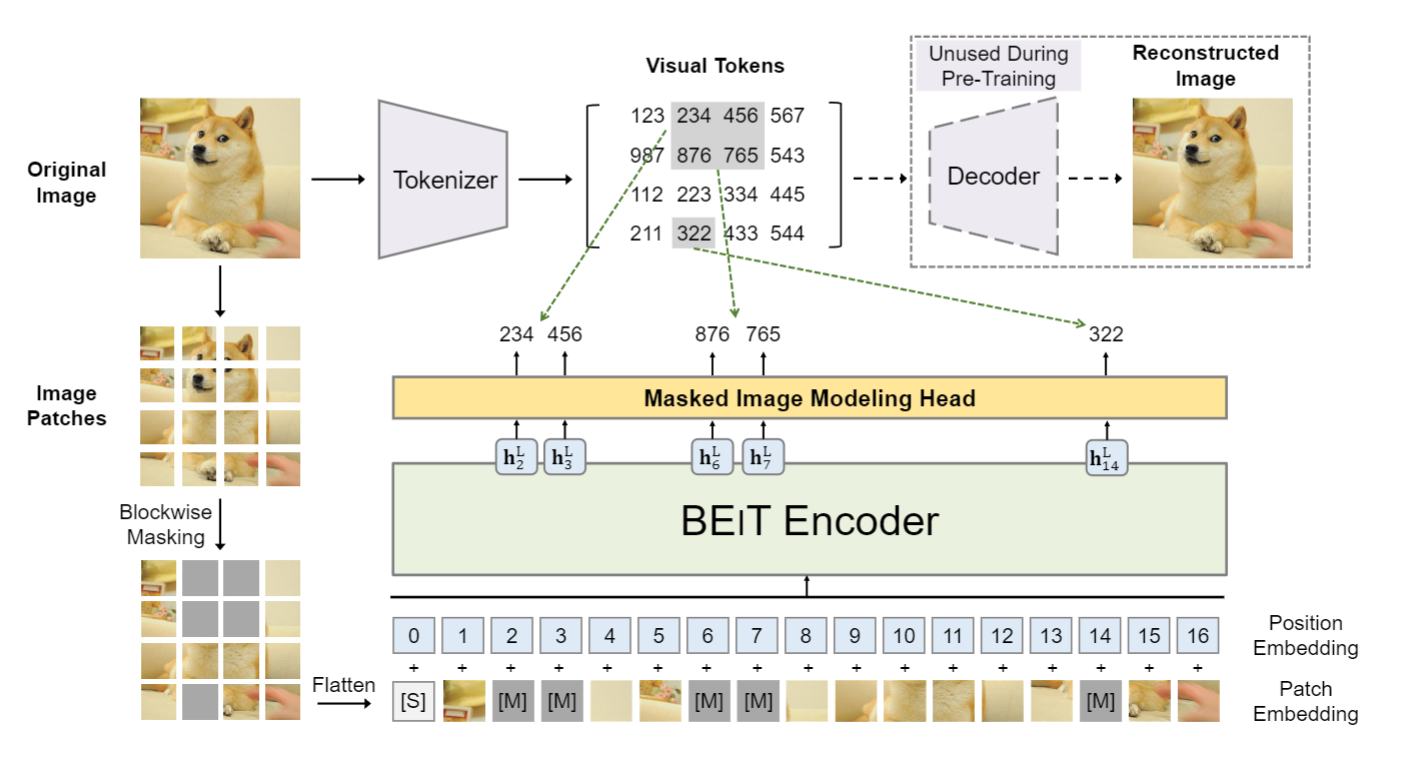
Visual Token은 이미지의 원시 픽셀 대신에 이미지를 디스크릿한 토큰 시퀀스로 표현하는 개념이다. 이는 자연어 처리에서 텍스트를 토큰 시퀀스로 변환하는 것과 유사하게 진행된다.
-
이미지 토크나이징: 이미지 x는 에서 이미지 토크나이저에 의해 디스크릿한 토큰 시퀀스 로 변환되며 여기서 Vocab 은 디스크릿한 토큰 인덱스를 포함하게 된다.
-
dVAE 사용: dVAE(discrete variational autoencoder, dVAE)를 사용하여 이미지를 시각적 토큰으로 변환하게되는데 이때 토크나이저 는 이미지 픽셀 를 코드북(어휘집)에 따라 디스크릿한 토큰 로 매핑하게되며 디코더 는 시각적 토큰 를 기반으로 입력 이미지 를 재구성하게 된다.
-
Loss: Loss의 경우 와 같이 정의 되는데 코드북 토큰을 통해 복구하는것이므로 미분이 불가하여 Gumbel-softmax를 사용하여 학습을 진행한다.
3-3. Pre-Training BEIT: Masked Image Modeling
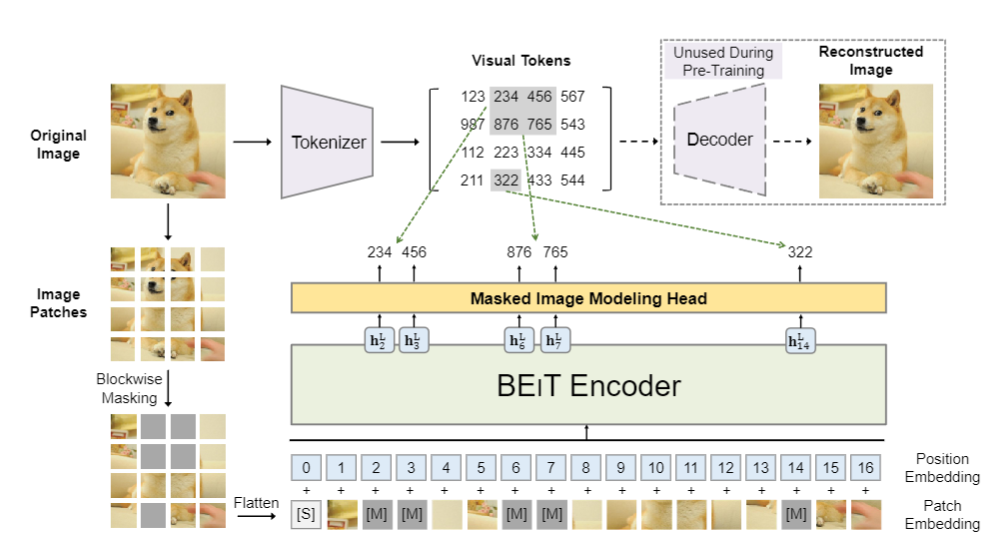
- MIM: 입력 이미지 에서 무작위로 약 40%의 이미지 패치를 마스킹하고, 이 마스킹된 패치에 해당하는 시각적 토큰을 예측하는 것이 목표이다. 마스킹된 패치 위치는 으로 표시되며, 로 정의가 되며
마스킹된 이미지 패치 는 학습 가능한 임베딩 로 대체되어 Transformer에 입력되고 최종적인 아웃풋은 은 입력 패치의 인코딩된 표현으로 간주되어 각 마스킹된 위치에 대해 소프트맥스 분류기는 해당 시각적 토큰을 예측한다.
최종 훈련 목표는 아래와 같다.
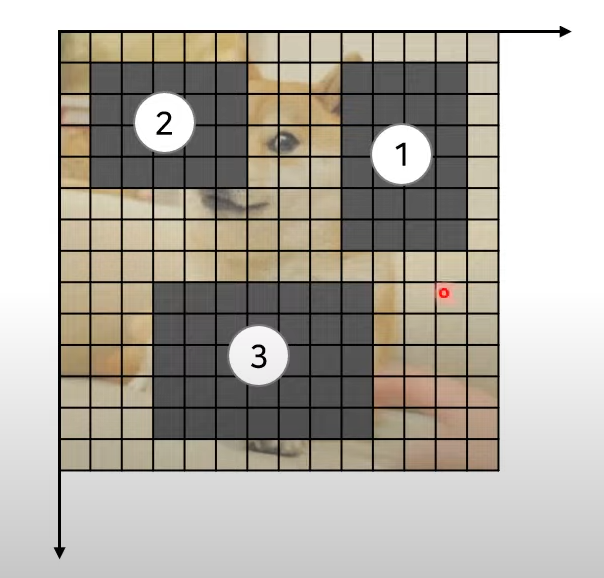

- Blockwise Masking: SpanBERT에서 영감을 받아 마스킹은 블록 방식(또는 n-gram)으로 수행되며 이는 마스킹된 부분을 연속적인 영역으로 만들어, 모델이 이미지의 구조적인 특징을 더 잘 이해하도록 돕게된다.
4. 실험 및 결과
4-1. Image Classification
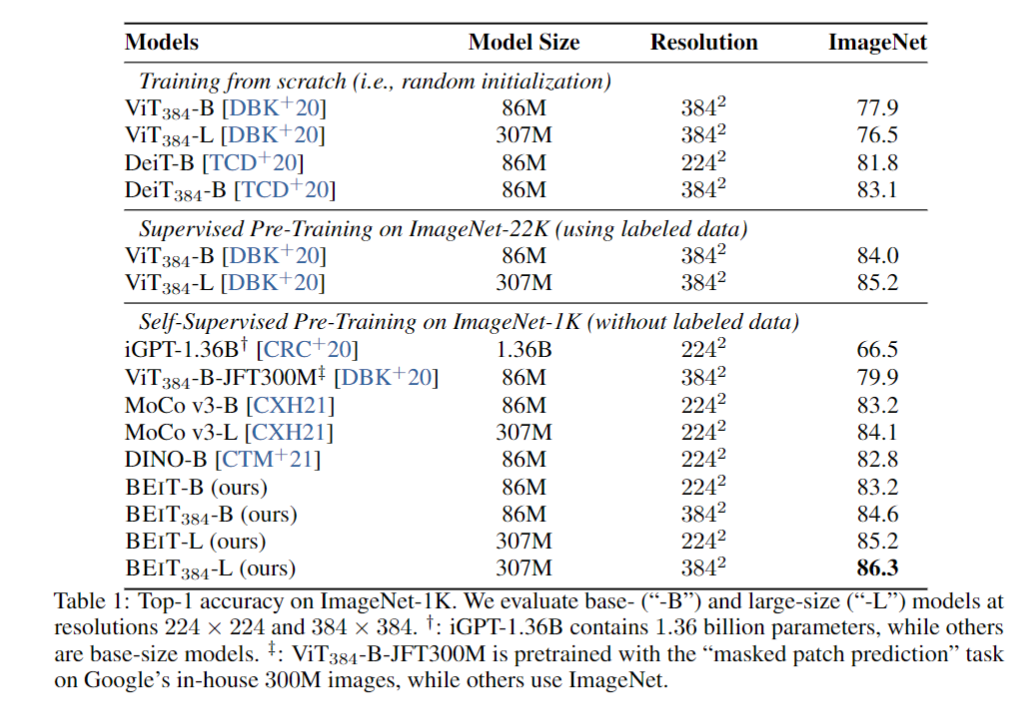
- ILSVRC-2012 ImageNet 데이터셋에서 이미지 분류 작업을 평가하였을때 가장 높은 성능을 달성하였다.
- 또한 BEIT는 기존의 self-supervised 방법보다 우수한 결과를 보여주었다.
4-2. Semantic Segmentation

- Semantic Segmentation에서도 우수한 성능을 보여주었다.
4-3. Self Attention map

사람의 주석 없이도 중요한 물체의 경계 부분을 잘 학습하게된다.
4-4. Ablation Studies
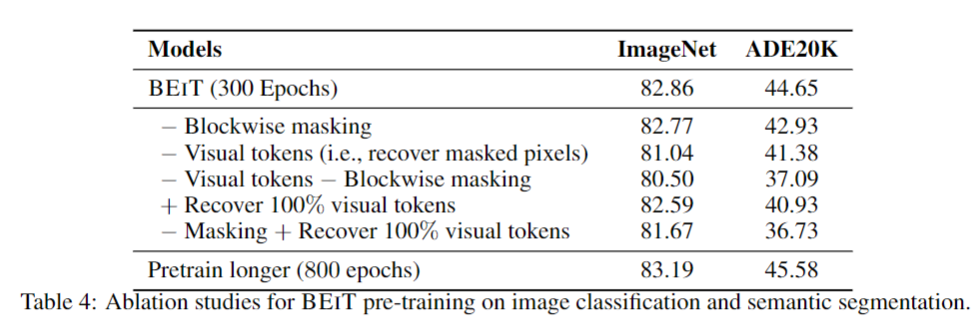
절제적으로 임의의 기능을 제외하고 훈련하였을때 성능이 점차 감소하여 결국 모든것을 쓴것이 제일 좋다
5. Conclusion
- Vision Transformer에 대한 self-supervised pre-training 방법을 BERT에서 영감을 받아 제시하였다.
- Self attention map을 보았을 때 사람의 라벨링 없이도 어텐션을 잘 수행하는 모습을 보여준다.
- 추후 텍스와 함께 동일 아키텍처를 유사한 목표로 훈련을 진행하고 싶다.
6. 회고
시간이 없어 약간 대충 쓴 느낌이 나지만 회사일 때문에 어쩔수 없는 것 같다. 보다 시간을 관리해야겠다.
그래도 MIM에 대해서 감이라도 잡을 수 있어 다행이다.

한성대학교 네이버 AI Tech 5기 NLP