
경사하강법
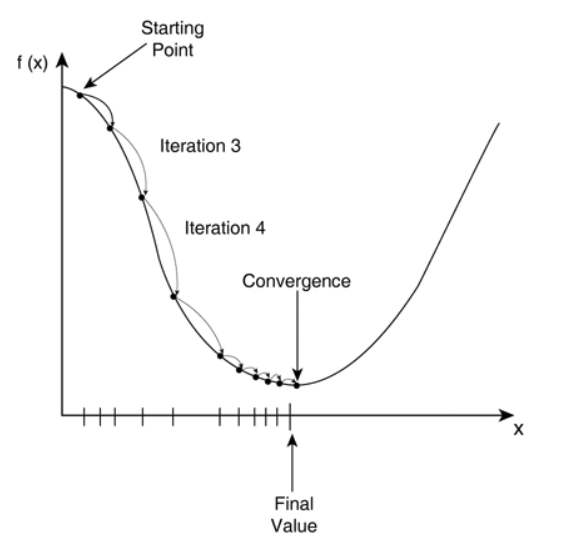
경사하강법(Gradient descent)란 주어진 점에서의 접선의 기울기(미분)을 구하여 어느 한 방향으로 점을 움직여 함수값을 계속해서 감소시킨다. 만약 기울기가 0인 극값에 도달할 경우 움직을 멈추며 수렴하게 된다.
유의 사항
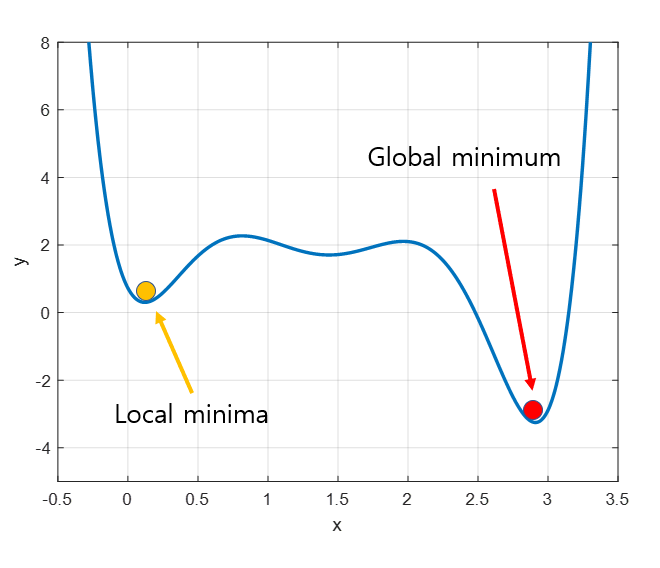
선형회기일 경우 목적식 은 회기계수 에 대해 볼록함수 이므로 무조건 수렴이 되지만 비선형회기일경우 위 그림처럼 수렴 지점이 여러개 이므로 수렴이 항상 보장되진 않는다.
확률적 경사하강법(SGD)
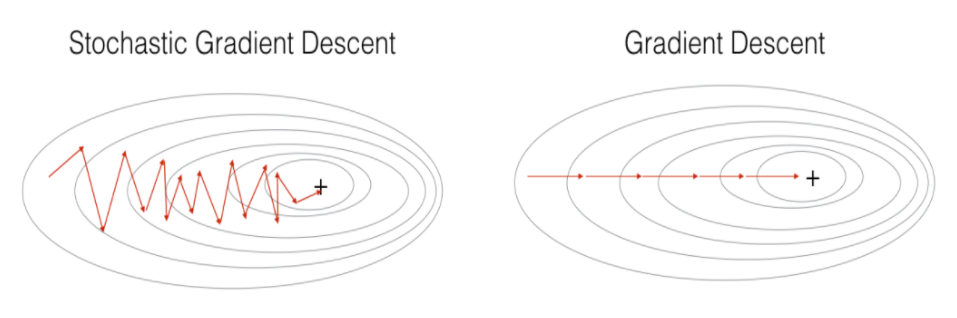
기존의 모든 데이터를 활용하여 업데이트를 하는 대신 데이터 1개 또는 배치 사이즈로 나누어 업데이트를 한다. 딥러닝의 경우 SGD가 경사하강법 보다 실증적으로 낫다고 검증되어있다. 매번 다른 미니배치를 사용함으로 위 사진처럼 곡선 모양이 바뀌게 된다
신경망
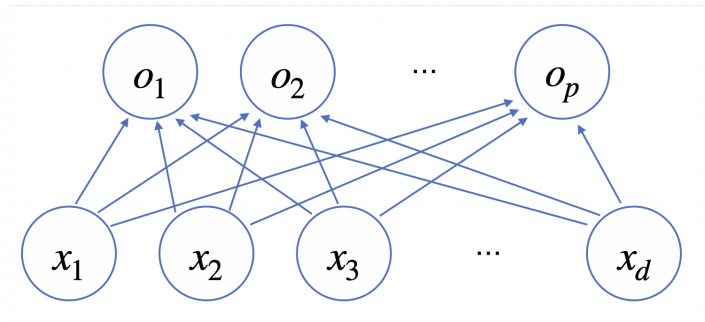
일반적인 선형모델은 위와 같이 구성되며 단순복잡한 선형 결합으로 볼 수 있지만 중간에 비선형 함수들과의 결합으로 아래와 같이 하나의 신경망을 만들어 낸다.
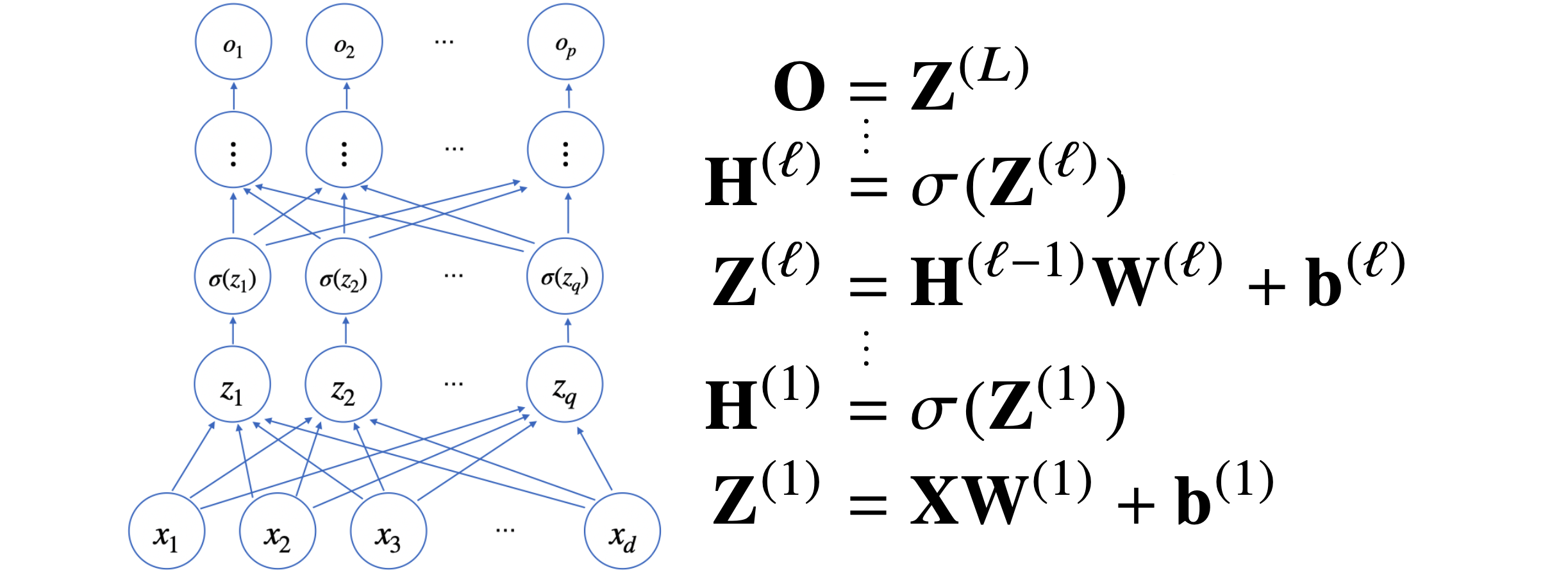
활성화 함수
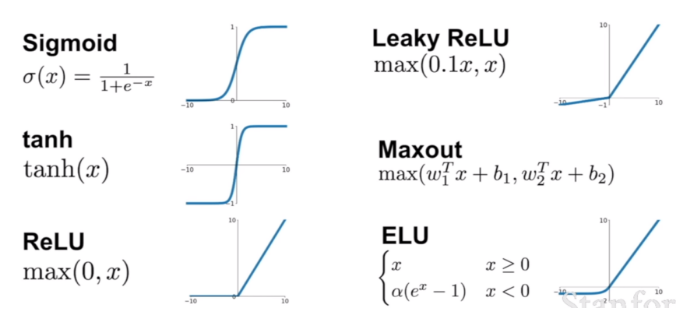
비선형 함수로써 각 노드에서 나온 출력값을 비선형 모델로 바꾸어 준다. 만약 활성화 함수가 없을 경우 일반적인 선형 모델과 다를게 없다. 위와 같은 활성화 함수와 선형모델의 조합으로 신경망이 구성된다.
Softmax
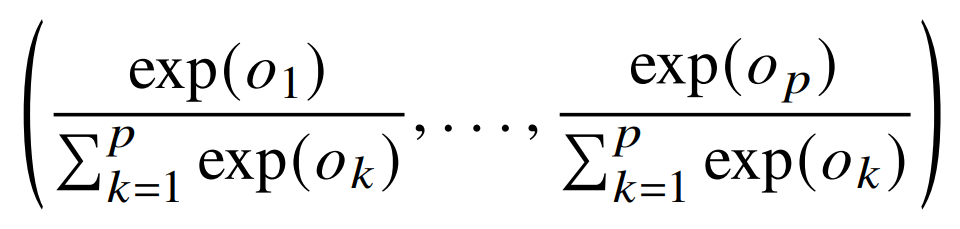
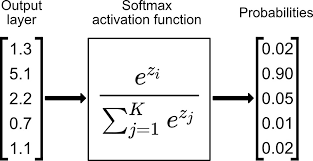
위와 같은 동작으로 입력 변수들에 대해 확률 값으러 변환 시켜준다 일반적인 분류 문제의 마지막 레이어에 쓰이게 되며 softmax를 통과해서 나온 결과 값들의 합은 1이게 된다.
MLP(Multi-Layer Perceptron)
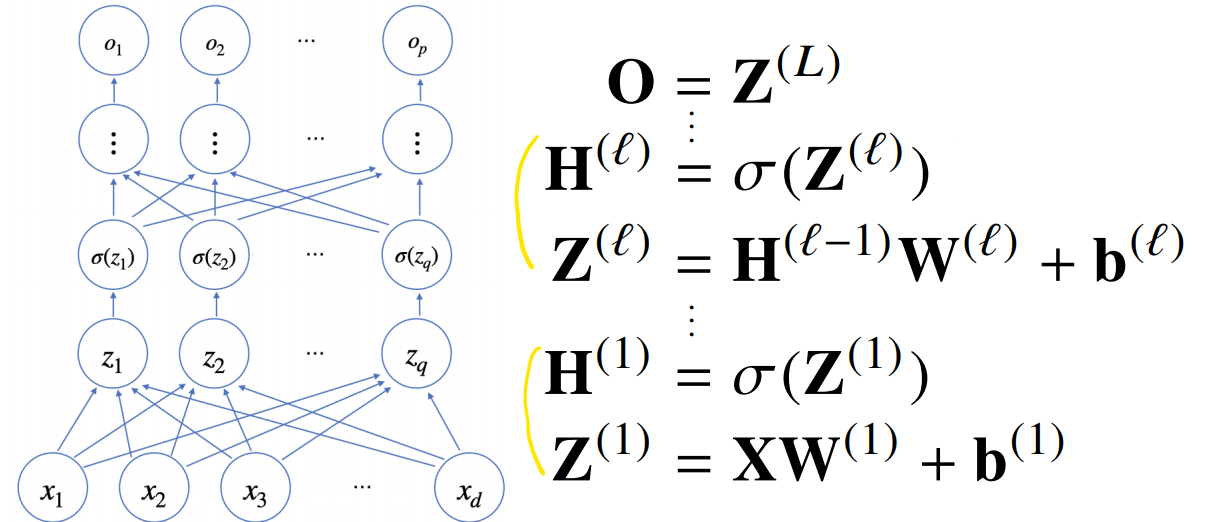
신경망을 여러층 합성한것을 MLP 다층 퍼셉트론이라고 불린다. 신경망 계산 결과를 선형->비선형->선형->비선형 이런식으로 적용하게 된다. 목적함수에 근사하기 위해선 노드가 많고 층을 깊게하면 성능이 대부분 좋다.
역전파(Backpropagation)
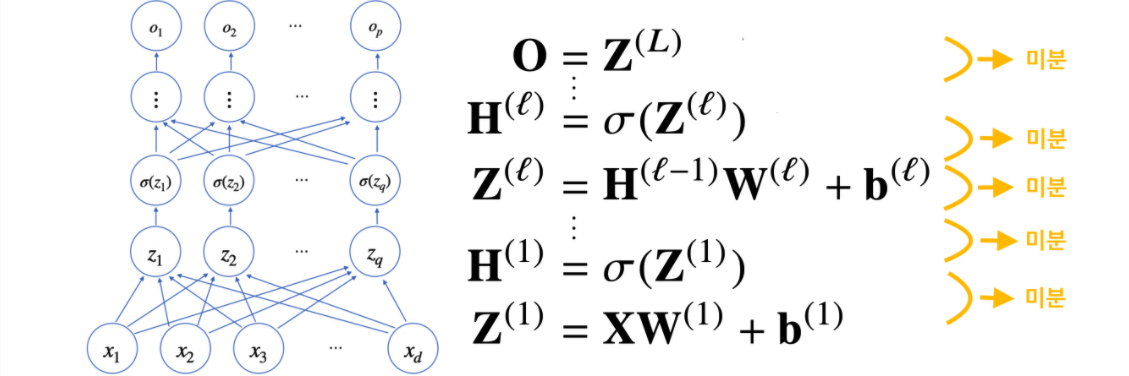
역전파는 기본적으로 순전파에서 기록된 미분값을 사용하게 된다.
연쇄법칙(chain-rule) 자동미분
MLP는 합성함수이므로 합성함수를 미분하기위해 연쇄법칙을 통해 위와 같이 미분이 가능하다.
실제로 MLP를 미분 할 시 아래의 사진과 같이 최종 출력물을 그 아래층으로 미분 하여 가중치를 업데이트 그리고 다시 해당 미분한 값을 아래층으로 점점 전달하여 입력의 가중치를 업데이트한다.
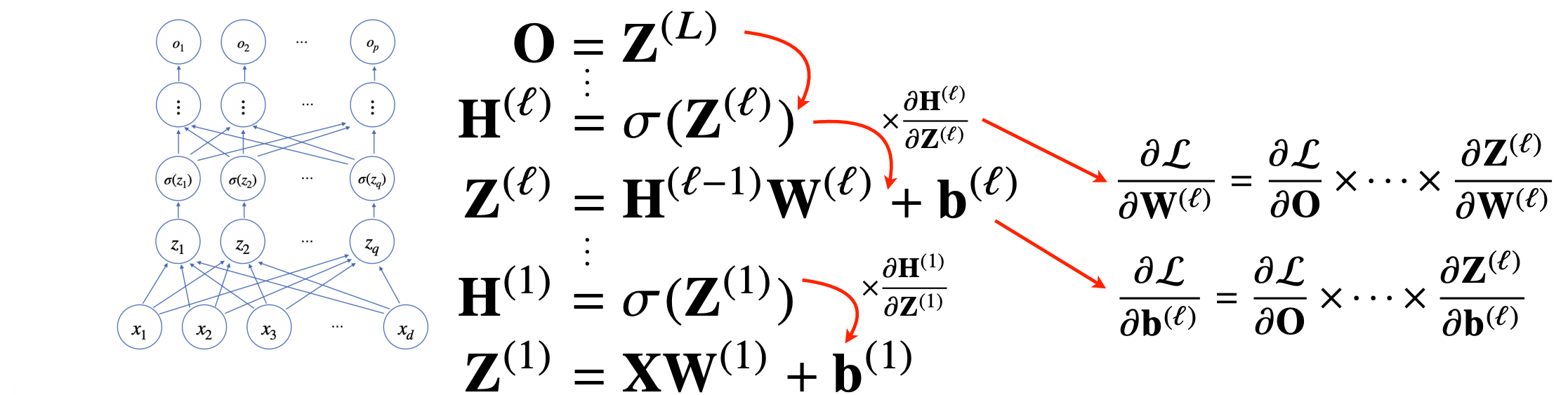
회고
이번 velog는 이미지첨부와 수식을 써보았다 내용은 아직 많이 부실해 보이지만 새로운 기능을 써봤다는 점에서 스스로 발전하는것 같았다. 슬슬 딥러닝 관련 내용이 나오니 집중해야할것 같다.
