
Pytorch Dataset
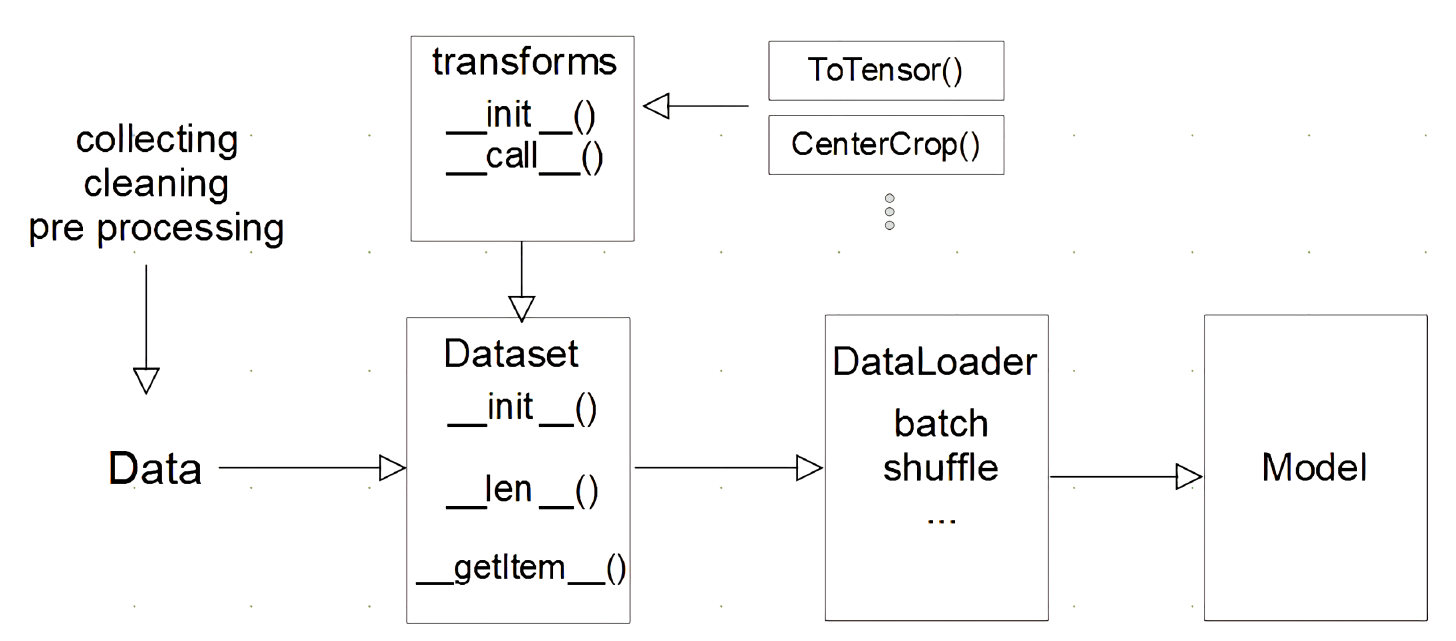
우리가 일반적으로 딥러닝 모델을 사용 시 Mini batch를 사용함에 따라 모델에 데이터를 계속 N개씩 넣어줄 필요가 있다. 이때 넣어주기 전에 어디에서 꺼낼껀지 정의를 해줘야 하는 부분이 Pytorch Dataset 이라고 할 수 있다.
기본적으로 Dataset은 와래와 같은 기본 코드로 시작된다.
import torch
from torch.utils.data import Dataset
class MyCustomDataset(Dataset):
def __init__(self,x_data,y_data):
self.x_data = x_data
self.y_data = y_data
def __len__(self):
return len(self.x_data)
def __getitem__(self,index):
return self.x_data[index],self.y_data[index]MyCustomDataset
import Dataset
기본적으로 Dataset이란 class를 상속을 받게 되는데 실제 Dataset의 일부분 코드를 직접 확인하면 아래와 같다.
class Dataset(Generic[T_co]): r"""An abstract class representing a :class:`Dataset`. All datasets that represent a map from keys to data samples should subclass it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a data sample for a given key. Subclasses could also optionally overwrite :meth:`__len__`, which is expected to return the size of the dataset by many :class:`~torch.utils.data.Sampler` implementations and the default options of :class:`~torch.utils.data.DataLoader`. .. note:: :class:`~torch.utils.data.DataLoader` by default constructs a index sampler that yields integral indices. To make it work with a map-style dataset with non-integral indices/keys, a custom sampler must be provided. """ def __getitem__(self, index) -> T_co: raise NotImplementedError def __add__(self, other: 'Dataset[T_co]') -> 'ConcatDataset[T_co]': return ConcatDataset([self, other])이는 우리가 getitem이란 함수를 오버라이딩 하지 않을 시 오류를 발생시키게 된다.
즉 핵심 함수인 Dataset을 상속을 받는순간 위의 함수들은 필히 작성을 해야한다.
init
기본적인 클래스 개념으로 객체를 생성시 생성되는 멤버변수들이다.
len
일반적으로 우리가 딥러닝을 할며 1Epoch를 돌때 1Epoch의 iter는 전체 데이터 갯수 / Batch_size로 정해진다.
이때 len이란 함수를 오버라이딩 해주지 않을 경우 학습 시 돌아야하는 전체 데이터 갯수를 확인 할 수없음으로 len이란 함수를 오버라이딩 해줌으로써 진행된다. 즉 1Epoch에 몇번 돌껀지 알려주기 위하여 적는 함수이다.
getitem
데이터를 어떻게 반환시켜줄것인가에 대한 함수로 적지 않으면 오류가 발생한다.
getitem의 함수 같은 경우 기본적으로 (self,index) 처리가 되어있다. 이때 index는 어떻게 보면 일종의 한 Epoch내에서의 전역 변수라고 볼 수 있다. 명시적으로는 클래스의 인덱스에 접근할 때 자동으로 호출되는 매직 메서드다.
실제로 메서드의 동작을 확인해보면 아래 코드와 같다.class Mylist: def __init__(self): print('Mylist의 생성자') self.my_list = [i for i in range(1,100)] def __getitem__(self,index): print("__getitem__메서드를 호출합니다") return self._numbers[index] mylist = Mylist() mylist[1] mylist[2] mylist[3] ## 실행결과 # __getitem__메서드를 호출합니다 # __getitem__메서드를 호출합니다 # __getitem__메서드를 호출합니다이를 iter한 객체이면 next(iter(MycustomDataset))시 즉시즉시 뱉어주는 값이 될 것이다. 실제로 이 부분에서 많은 전처리가 이루어진다.
Pytorch DataLoader
파이토치의 데이터 로더는 사용하기가 매우쉽다. 단순히 데이터를 어떻게 꺼내올까? 이게 전부이다. 실제 딥러닝 모델의 미니배치를 리턴해주는 부분이다.
DataLoader Code
from torch.utils.data import DataLoader
dataset = MyCustomDataset()
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)실제 코드는 위와 같다. 단순하게 우리가 만든 Dataset을 넣어주면 끝난다!
주요 쓰이는 파라미터로는 shuffle과 batch_size인데 말 그대로 shuffle=True일 경우 각 epoch마다 데이터를 섞는다.
batch_size는 우리가 몇개의 데이터씩 활용할 것인가를 정한다.
각종 파라미터DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, *, prefetch_factor=2, persistent_workers=False)
sampler
import torch
from torch.utils.data import Dataset, RandomSampler
for data in dataloader:
print(data['input'].shape, data['label'])
class TestDataSet(Dataset):
def __len__(self):
return 10
def __getitem__(self, idx):
return {"input":torch.tensor([idx, 2*idx, 3*idx], dtype=torch.float32),
"label": torch.tensor(idx, dtype=torch.float32)}
test_dataset = TestDataSet()
sampler = RandomSampler(test_dataset)
dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=4, sampler=sampler)
for data in dataloader:
print(data)sampler는 data를 가져올때 섞어서 가져오고 싶다면 index만 섞어도 섞이게 된다 이때 쓰는게 sampler이다.
각종 파라미터
num_workers는 cpu를 몇개를 활용할 것인지 결정하는 파라미터이다. windows기준 ipynb 나 if main 없시 사용할경우 에러
pin_memory는 단순하게 병목현상을 줄여 학습속도를 증가시킨다.
collate_fn 선언하는 방식에 따라 getitem 리턴 값을 변형시킨다고 보면된다.
Basic Image Data preprocessing

딥러닝에 주로 쓰이는 기본적인 이미지의 전처리 기법이다. 데이터의 다양성과 모델의 과적합 방지 그리고 당연히 같은 이미지에 대하여 여러 이미지를 보여줌으로써 모델이 좀 더 Generalization 된다.
torchvision.transforms
torchvision에서 지원해주고 있는 방법이다. 기본적인 주요 메서드만 표기하겠다. 각 기능은 직접 Doc을 참고하도록
torchvision.transforms.Resize(size, interpolation='bilinear', ...) torchvision.transforms.CenterCrop(size) torchvision.transforms.RandomHorizontalFlip(p=0.5) torchvision.transforms.RandomVerticalFlip(p=0.5) torchvision.transforms.RandomRotation(degrees, interpolation='nearest', ...) torchvision.transforms.RandomCrop(size, padding=None, ...) torchvision.transforms.Normalize(mean, std, inplace=False)한번에 블럭으로 묶어서 적용시킬 수 있다.
transform_compose = transforms.Compose([ transforms.RandomResizedCrop(input_size), transforms.RandomRotation(degrees=(-30, 30)) transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ])
Iamaug

개인적으로 굉장히 좋아하는 이미지 데이터 처리 라이브러리이다. 실제로 대회에서도 사용했으며 위의 torchvision보다 기능의 범위와 확장성이 굉장히 뛰어 나다고 볼 수 있다. https://github.com/aleju/imgaug 사용법은 사이트의 Doc를 확인하면 된다.
albumentations

사용해보진 않았지만 굉장히 빠른속도를 자랑하는 라이브러리이다. 같은 동일 기능일지라도 torchvision에 비해 속도가 빠르며 이미지 전처리에 가장 많이 사용되는 라이브러리이다.
회고
점차 velog에 익숙해지는 것 같다. 각종 수식과 기호들을 자연스럽게 쓰게 되어서 편리하다. Dataset과 Dataloader에 대해 배웠는데 이는 절대로 모르면 안되는 부분이라 예전부터 공부해왔던 부분이다. 이미지 전처리에 대해서는 대회에서 주로 Iamaug를 사용했는데 albumentations도 한번 사용해보는 것이 좋을 것같다. 근데 아직 솔직히 collate_fn 이거 쓴다고는 하는데 아직 쓰는걸 보지는 못했다.
