이전 포스트에선 CNN을 이용하여 이미지를 효과적으로 처리할 수 있는 방법에 대해 알아보았습니다. 이로써 우리는 일반적인 1차원의 데이터와 3차원의 이미지 데이터를 처리할 수 있는 방법을 알게 되었습니다. 그렇다면 이제 남은 2차원 데이터를 다루는 방법을 배우면 기초는 배웠다고 할 수 있겠네요. 이번 시간에는 2차원 데이터에 대해, 그리고 이를 처리하는 방법에 대해 알아봅니다.
2차원 데이터
그렇다면, 어떤 데이터들이 2차원으로 저장되는 것일까요? 2차원 데이터는 대부분 연속되는 데이터, 즉 시계열 데이터들에 해당합니다. 예를 들어 최근 30일동안의 최고기온, 최저기온, 습도라는 세가지 데이터들을 1일 단위로 저장한다고 가정하겠습니다. 그렇다면 이는 다음과 같은 2차원 데이터로 저장할 수 있습니다.
시계열 데이터의 저장방식
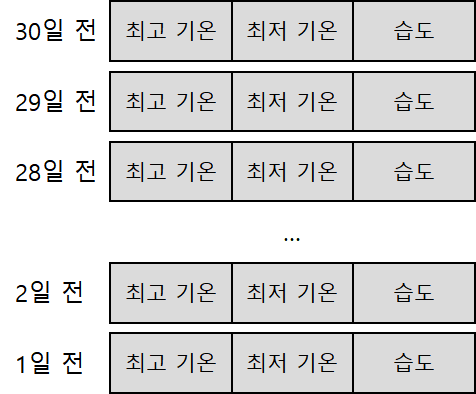
날씨 데이터 외에도 주가 데이터등 연속되는 데이터들은 대부분 2차원의 시계열 데이터에 해당합니다.
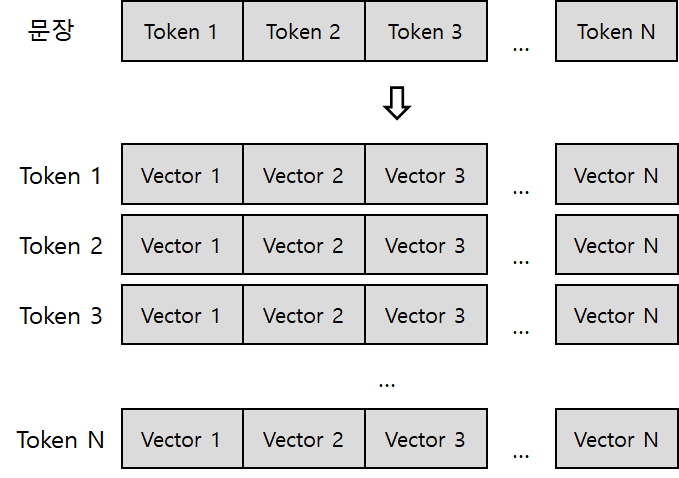
한편, 자연어처리 분야에서도 2차원 데이터가 사용됩니다. 자연어처리에서 문장은 토큰이라는 작은 단위로 분리되어 사용합니다. 이때 토큰 단위로 분리하는 과정을 토큰화tokenization이라고 칭합니다. 토큰화를 진행한 데이터는 아직 1차원의 데이터에 불과하지만, 딥러닝 기반의 자연어처리 태스크에선 임베딩embedding이라는 추가적인 작업을 통해 하나의 토큰을 다차원의 벡터로 저장합니다. 이때 임베딩된 문자는 2차원의 데이터로 저장되게 됩니다.
임베딩된 텍스트 데이터의 저장방식
RNN이란?
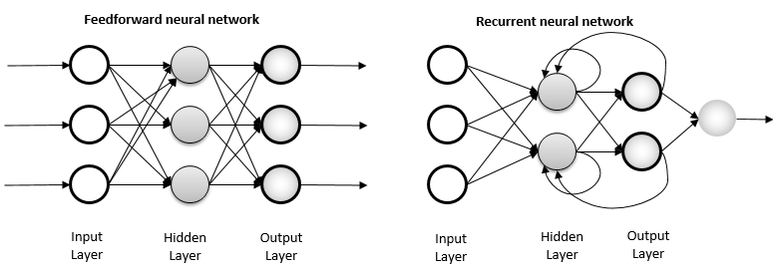
이러한 2차원 데이터를 다루는 방법이 바로 Recurrent Neural Network, 순환 신경망 입니다. 순환 신경망은 지금까지 우리가 사용했던 그 다음 레이어로 넘어가는 순방향 신경망과는 달리 자신의 출력결과를 다시 자신의 입력값으로 사용하는, 즉 순환하는 신경망입니다.
순방향 신경망과 순환 신경망의 차이
RNN은 각 시퀀스별로 연산을 진행하고, 이전 시퀀스는 현재 시퀀스를 연산하는데 영향을 끼칩니다. 이때 이전 시퀀스를 연산한 결과, 즉 현재 시퀀스로 보내는 값을 은닉 상태hidden state라고 합니다. 그리고 이러한 값을 저장하는 노드를 메모리 셀memory cell 혹은 RNN 셀RNN cell이라고 표현합니다.
RNN은 위 2가지 방법으로 표현할 수 있습니다.
오른쪽 그림에서 다음 시퀀스로 넘어가는 화살표가 바로 은닉 상태입니다.
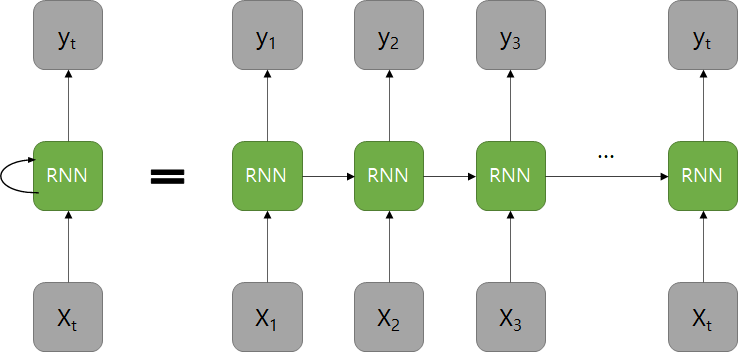
다음 셀로 상태를 넘기는 과정에서 드롭아웃, 활성화 함수 등을 거친 값을 출력하게 됩니다.
RNN은 시퀀스 별로 사용하는 가중치가 있기 때문에 다른 레이어에 비해 연산량과 가중치가 많다는 특징이 있습니다. 대표적인 RNN 레이어로 장단기 메모리LSTM, Long Short Term Memory와 게이트 순환 유닛GRU, Gated Recurrent Unit이 있습니다.
이렇게 간단히 RNN에 대해 알아보았습니다. 그렇다면 이제 이를 한번 사용해 봐야겠지요?
데이터 설명

이번 시간엔 IMDB라는 데이터셋을 사용합니다. IMDB는 영어로 작성된 영화 리뷰 데이터셋입니다. 1 ~ 10점 사이의 별점 중 6점 미만의 점수는 부정(0), 6 이상의 점수는 긍정(1) 레이블로 구성된 자연어처리 2진 분류 과제입니다.
또한 IMDB 데이터는 데이터가 영어 그대로 주어지는 것이 아니라 이미 전처리 과정을 거치고, 토큰화되어서 정수 리스트 형태로 주어지게 됩니다. 귀찮게 전처리를 할 필요는 없겠네요.
실습
바로 시작하겠습니다. 우선 사용할 라이브러리를 임포트합니다.
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras import layers
from tensorflow.keras.datasets import imdb
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.sequence import pad_sequences바로 이어서 이번 시간에 사용할 IMDB 데이터셋을 가져옵니다.
vocab_size = 6400 # 사용할 단어사전의 크기
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=vocab_size) # 사전 개수에 맞춰서 로드
num_classes = max(y_train) + 1
print('훈련용 리뷰 개수 : {}'.format(len(X_train))) # 25000
print('테스트용 리뷰 개수 : {}'.format(len(X_test))) # 25000
print('카테고리 : {}'.format(num_classes)) # 2vocab_size는 모델이 인식할 수 있는 단어의 개수를 나타냅니다. 모델은 문자를 원문(이번 시간엔 영어) 그대로 인식하는 것이 아니라, 각 단어들을 숫자로 바꿔서 인식을 합니다.
이 인식할 수 있는 단어를 정해야 하는데, 이 숫자가 너무 크면 모델은 별로 중요하지 않는(잘 사용하지 않는) 단어까지 모두 인식을 하고, 모델의 크기도 커지게 됩니다.
반대로 너무 작다면 자주 등장하는 중요한 단어들을 인식하지 못해서 성능 역시 떨어지게 되겠죠? 이번시간엔 적당하게 6400개 정도만 사용하겠습니다.
데이터를 한번 훑어보겠습니다.
word_to_index = imdb.get_word_index() # {문장: 숫자} 로 구성된 딕셔너리
index_to_word = {value: key for key, value in word_to_index.items()} # {숫자: 문장} 으로 바꿔주기
# <pad>: padding, 길이를 맞출때 사용하는 비어있는(사용x) 토큰
# <sos>: start of sentence, 문장의 시작을 알리는 토큰
# <unk>: unknown, 모델이 인식할 수 없는 토큰
for index, token in enumerate(("<pad>", "<sos>", "<unk>")):
index_to_word[index] = token
print(' '.join([index_to_word[index] for index in X_train[0]]))
print(X_train[0])
print(y_train[0])
# <sos> as you with out themselves powerful ...
# [1, 14, 22, 16, 43, 530, 973, 1622, 1385 ... ]
# 1get_word_index()를 사용해 문장과 숫자가 연결된 딕셔너리를 가져와서, 이를 뒤집었습니다. 이후 이를 사용해 숫자로 인코딩된 데이터를 다시 문자로 디코딩했습니다.
디코딩하는 과정에서 <pad>, <sos>, <unk> 라는 이상한 토큰 몇개를 추가한 것을 볼 수 있습니다. 하나씩 알아볼까요?
<pad> 토큰은 풀네임으로 padding이고, 길이를 맞출때 사용하는 비어있는(사용x) 토큰을 뜻합니다. 각 문장의 길이가 다르니 상대적으로 짧은 문장에 얘를 넣어 길이를 맞춰주는거죠.
<sos> 토큰은 풀네임으로 start of sentence이고, 문장의 시작을 알리는 토큰을 뜻합니다. 모든 문장은 <sos> 토큰으로 시작하게 됩니다.
<unk> 토큰은 풀네임으로 unknown이고, 모델이 인식할 수 없는 토큰을 뜻합니다. 앞서 데이터를 가져올 때 vocab_size를 지정했었죠? 원래 번호가 6400 이상인 숫자는 모델이 인식하지 못하고 해당 토큰으로 바꿔 인식하게 됩니다.
레이블 데이터는 1인걸로 보아 상당히 긍정적인 데이터라는 것을 알 수 있네요. 그렇다면 데이터의 분포는 어떻게 될까요?
len_result = [len(s) for s in X_train]
print('리뷰의 최대 길이 : {}'.format(np.max(len_result)))
print('리뷰의 평균 길이 : {}'.format(np.mean(len_result)))
plt.figure(figsize=(10, 4))
plt.subplot(1,2,1)
plt.boxplot(len_result)
plt.subplot(1,2,2)
plt.hist(len_result, bins=50)
plt.show()
unique_elements, counts_elements = np.unique(y_train, return_counts=True)
print("각 레이블에 대한 빈도수")
print(np.array((unique_elements, counts_elements)))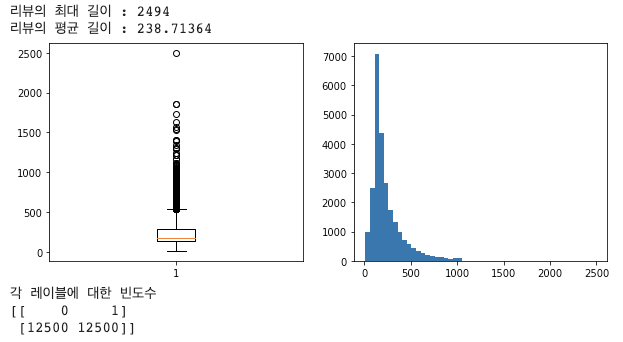
데이터의 길이가 되게 제멋대로인게 많군요. 그래도 레이블은 0, 1이 1:1의 비율로 잘 섞여있습니다. 데이터의 길이가 다르면 모델이 데이터를 인식할 수 없으니, 길이를 동일하게 맞춰줘야겠죠?
max_len = 512
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
print(X_train.shape, X_test.shape)
# (25000, 512) (25000, 512)제멋대로인 데이터의 길이를 512로 맞춰줍니다. 너무 긴 문장은 잘라내고, 짧은 문장은 앞서 살펴본 <pad>토큰을 이어붙여줍니다.
이제 데이터가 준비됐으니, 모델을 설계해봅시다!
model = Sequential()
model.add(layers.Embedding(vocab_size, 128, input_length=max_len))
model.add(layers.LSTM(128))
model.add(layers.Dropout(0.1))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.1))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
model.summary()하나씩 보겠습니다. 가장 첫번째 층, Embedding 레이어입니다. 임베딩 레이어는 1차원의 벡터 데이터를 2차원의 매트릭스 데이터로 바꿔줍니다.
우리의 모델에선 (batch_size, 512)의 데이터를 (batch, 512, 128)로 바꿔주네요. 이제 RNN 네트워크에서 사용할 수 있는 2차원의 데이터가 구성되었습니다.
두번째 층인 LSTM 레이어입니다. 하나의 데이터를 512번에 걸쳐(이전 층의 shape[1]의 수만큼 처리) 처리하는 레이어로군요. 각 출력값의 길이는 128개이며, 파라미터로 return_sequence=True를 넣어주지 않으면 항상 마지막 은닉 상태의 출력값만 다음 레이어로 보냅니다. 대개 RNN 층을 연속해서 여러번 쌓을때 해당 파라미터를 사용합니다. 우린 1개만 사용하니, 디폴트값인 False 그대로 두겠습니다.
그 다음부턴 이전에 배웠던 내용 그대로입니다! Dense 레이어와 Dropout 레이어를 적절히 섞어 과적합을 방지하고, 마지막 층은 출력갑을 1로 정하고 시그모이드 함수를 사용해 이진분류에서 사용할 수 있는 모델을 만들었습니다.
이후 binary_crossentropy를 loss로 넣어주었고, accuracy까지 알 수 있도록 매트릭을 포함시켰습니다.
컴파일까지 마쳤으니 바로 학습을 해보죠!
history = model.fit(X_train, y_train, epochs=3, batch_size=64, validation_split=0.2)
loss, accuracy = model.evaluate(X_test, y_test) # 학습 완료 후 검증
print("손실률:", loss) # 0.39541223645210266
print("정확도:", accuracy) # 0.8531200289726257손실은 약 0.4, 정확도는 85% 정도로 나왔네요. 나쁘지 않습니다. 그래프를 그려 확인해볼까요?
plt.figure(figsize=(14, 5))
# 에포크별 정확도
plt.subplot(1, 2, 1)
plt.plot(history.history["accuracy"], label="accuracy")
plt.plot(history.history["val_accuracy"], label="val_accuracy")
plt.legend()
# 에포크별 손실률
plt.subplot(1, 2, 2)
plt.plot(history.history["loss"], label="loss")
plt.plot(history.history["val_loss"], label="val_loss")
plt.legend()
plt.show()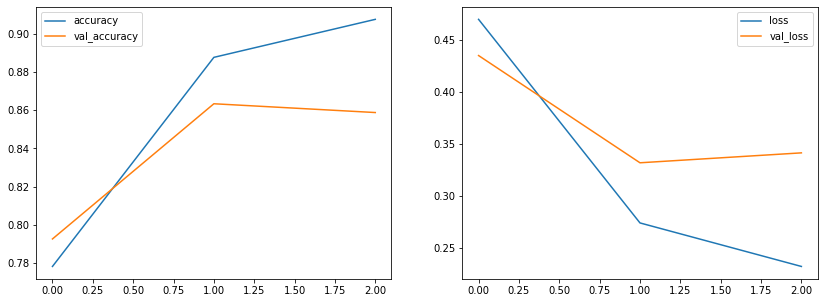
학습 지표는 계속 나아지는데, 테스트 지표는 3에포크째에서 나빠지네요. 미세하긴 하지만 조금 과적합된 모델인 것 같습니다. 그래도 이정도면 나쁘지 않은 성능이라는 것을 확인해볼 수 있습니다.
이렇게 최대한 간결하게 RNN 모델에 대해서 알아봤습니다. RNN 모델부터 조금씩 헷갈리실 수 있는데, LSTM이나 GRU 등 RNN 모델의 내부 연산 과정 등에 대해서 더욱 자세히 알고싶으신 분은 이곳을 확인해보시면 좋을 것 같습니다.
여기까지 알면 대충 딥러닝 모델을 맛만 봤다고 할 수 있겠네요. 다음 시간엔 자연어처리에 엄청난 혁명을 일으킨 Attention 구조에 대해서 포스팅해보겠습니다. 부족한 글이지만 읽어주셔서 감사합니다. 오탈자, 잘못된 정보에 대한 교정은 언제나 환영입니다 :)
