저번 포스트에선 오버피팅을 방지하는 방법을 알아보고, 이를 MNIST 손글씨 분류에 적용해보았습니다. 이때, 이미지의 픽셀값들을 1차원으로, 즉 일렬로 이어붙인 데이터를 사용했습니다.
본래 2차원(가로, 세로)이었던 데이터를 1차원으로 바꾸게 되면 2차원일때 가지던 지역적 특성, 즉 어떤 한 구역에서만 얻을 수 있는 정보가 사라지게 됩니다. 이러한 데이터의 특성을 살려 더 높은 성능을 낼 수 있는 방법이 바로 CNNConvolution Neural Network, 합성곱 신경망 입니다. 이번 포스트에선 바로 이 CNN에 대해서 알아보겠습니다!
CNN이란?
이전 실습때 사용했던 Dense layer, 완전연결층은 앞의 레이어의 노드와 현재 레이어의 노드를 모두 연결해 연산을 진행했습니다.
반면 합성곱 층은 커널의 크기를 정하고, 이 커널의 크기만큼의 노드만 연결을 합니다. 두 레이어의 차이를 그림으로 보면 다음과 같습니다.
Dense Layer VS Colvolution Layer
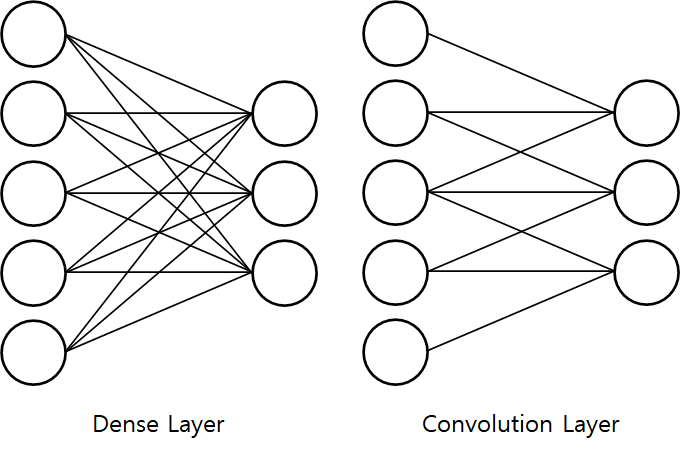
그림에서 합성곱 층은 커널의 크기를 3으로 정의했네요. 이전 층의 노드 3개만 연결됐습니다.
2차원의 이미지 데이터에선 다음과 같이 처리를 합니다.
CNN이 처리되는 과정

CNN의 구성 요소
이번에는 CNN의 구성 요소에 대해서 간단하게 알아보겠습니다.
여러 요소가 있지만, 본문에선 몇가지만 알아보도록 하겠습니다.
kernel, filter, padding, stride
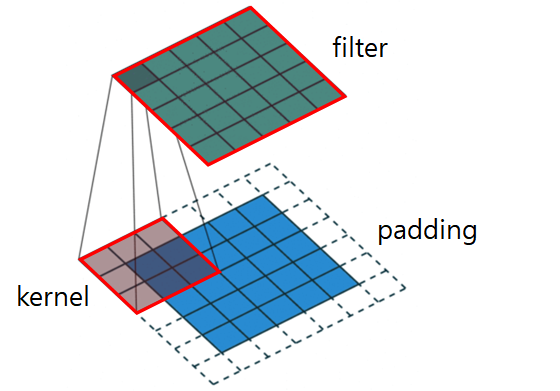
그림에는 stride는 나오지 않았지만, 이는 하나하나 알아보도록 하죠!
우선 커널kernel은 앞서 설명드린것처럼, 한번에 처리할 노드의 크기를 말합니다. 위 그림에서 커널의 크기는 (3, 3)이네요. 이러한 커널들이 연산한 결과를 모아놓은 출력값을 필터filter라고 합니다. 필터는 각 층마다 여러개를 가지고 있으며, 이 필터의 개수까지 포함해 CNN 층은 배치를 제외하고 3차원의 데이터를 다루게 됩니다.
패딩padding은 입력 이미지의 테두리에 추가할 가상의 값(0)의 크기입니다. 위 그림에서 패딩값은 1이며, tensorflow 2.0에서는 padding='same'이라는 파라미터를 줌으로써 입출력 데이터의 크기를 똑같게 설정할 수 있습니다. 패딩값이 커질수록 출력값은 커집니다.
마지막으로, 스트라이드stride는 커널이 이동하는 거리입니다. 아까 움직이는 그림에서 커널은 한칸씩 이동하면서 필터를 완성하고 있습니다. 이때 스트라이드는 1입니다. 스트라이드의 값이 커질수록 출력값의 크기는 작아집니다.
kernel_size(3, 3), padding='same', stride=1 -> output_size=(5,5)
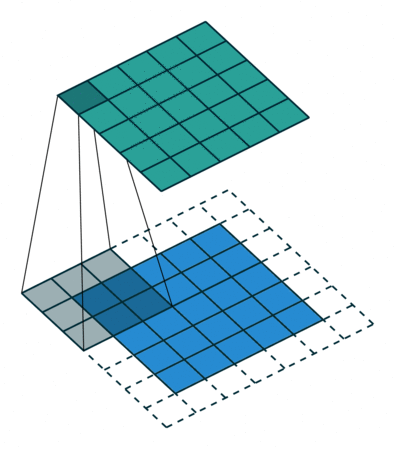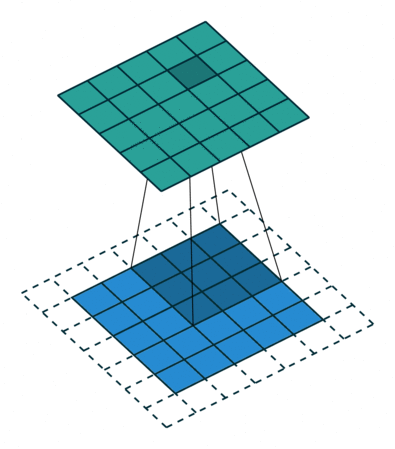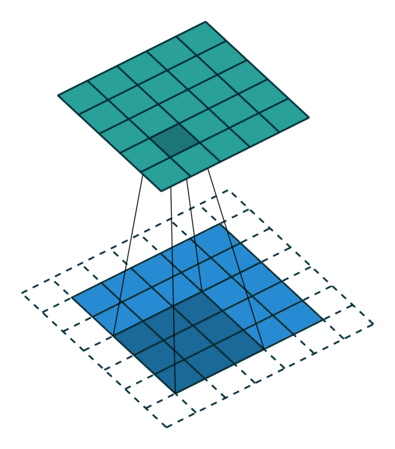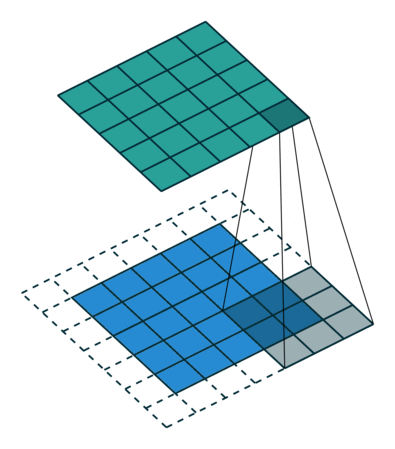
자 이제 좀 이해가 가시나요? 그럼 CNN에 사용되는 다른 레이어를 하나 알아보도록 하겠습니다.
Pooling layer
풀링 레이어는 데이터의 크기를 줄여주는 역할을 합니다. 단, 단순하게 그냥 축소가 아니라 데이터의 특징점만을 뽑아내 축소한다고 생각하시면 됩니다.
풀링 층은 합성곱 층처럼 커널의 크기를 정하고 그 안에서 연산을 진행합니다. 이 연산이 가장 큰 값을 출력하는 Max라면 MaxPooling 층이 되는것이고, 평균값을 구한다면 AveragePooling 층이 됩니다.
그런데, 여기서 합성곱 층과는 분명히 다른 사실이 있는데, 바로 커널들이 서로 겹치지 않는다는 것입니다. 그림으로 보시면 빠르게 이해가 가실 겁니다.
MaxPooling2D 레이어
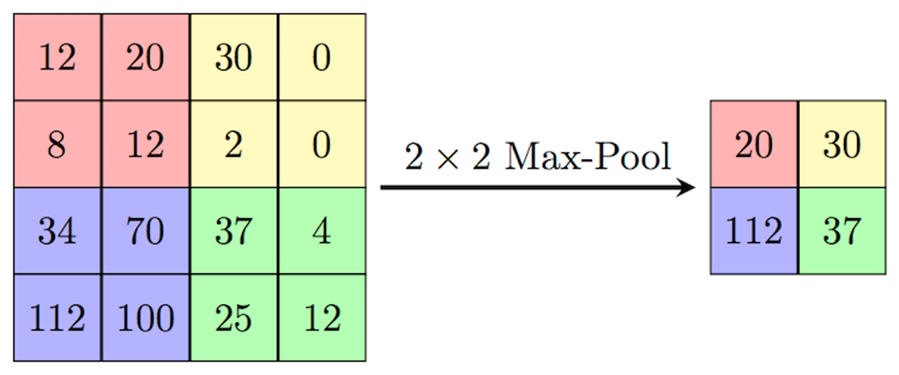
그림을 보시면, 4개의 커널들이 모두 겹치지 않고 자신의 영역에서만 연산을 진행합니다. 커널의 크기가 (2, 2) 가 되니까 데이터의 크기가 절반이 되었네요! 풀링 레이어는 모델의 크기가 너무 커지지 않도록 조정하는 역할을 합니다.
이제 기초적인건 배웠으니 이를 실습해보겠습니다.
데이터 설명

오늘 사용할 데이터는 CIFAR 10 데이터셋입니다. CIFAR 10 은 32*32 사이즈의 이미지 60000개로 구성되며, 이미지들은 10개의 클래스로 레이블링 되어있습니다. 이전에 사용했던 mnist 데이터셋과 같이 머신러닝 예제에 많이 사용되는 데이터셋입니다.
실습
그러면 본격적으로 실습을 진행하겠습니다. 우선 필요한 라이브러리를 먼저 임포트합니다.
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras import backend, layers
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical임포트를 완료했다면 데이터를 불러옵니다. 이후 데이터에 맞는 레이블을 지정해주고, 랜덤으로 5개의 이미지를 불러와서 확인해봅시다.
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
s = np.random.choice(np.arange(x_train.shape[0]), 5)
plt.figure(figsize=(20, 100))
for cnt, i in enumerate(s):
plt.subplot(1, 5, cnt+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_train[i])
plt.xlabel(class_names[y_train[i][0]])
plt.show()
이미지 해상도가 낮지만, 그래도 나름 알아볼 수는 있을 정도네요.
이제 데이터를 255로 나눠서 전처리를 해주고, 데이터 shape와 클래스 개수를 설정해줍시다.
input_shape = x_train.shape[1:]
num_classes = len(np.unique(y_train)) # 정답(label) 의 클래스 갯수
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
print(input_shape) # (32, 32, 3)
print(num_classes) # 10그런데, 데이터 차원이 뭔가 이상합니다. 분명 사진 크기는 (32, 32)인데, 데이터의 차원은 (32, 32, 3)이네요. 이는 데이터가 컬러 이미지이기 때문입니다. 컬러 이미지는 한 픽셀(feature)당 RGB 3개의 값을 가집니다. 마지막 차원은 이 RGB값이며, 딥러닝 문제에선 이를 채널이라고 부릅니다.
자 이제 데이터를 불러왔으니, 모델을 설계해야겠죠. 바로 코드로 넘어가겠습니다.
model = Sequential()
model.add(layers.Conv2D(32, (3,3), activation='relu', input_shape=input_shape))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.2))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()이번엔 층이 꽤나 많아보입니다. 하나하나 알아보겠습니다.
layers.Conv2D 층은 앞서 살펴보았던 컨볼루션 레이어입니다. 2D는 2차원, 즉 이미지를 처리할때 사용한다는 뜻입니다. 2D가 있다면 당연히 1D도 존재하겠죠? 이는 나중에 다시 알아보도록 하겠습니다.
다시 돌아와서 파라미터로 들어가는 첫번째 인수는 필터의 개수를 의미합니다. 첫번째 레이어에선 32개의 필터를 사용하네요. 각각의 필터들은 각자 다른 특성들을 인식할 것입니다.
두번째 파라미터는 커널의 크기를 의미합니다 여기선 (3, 3)의 크기를 가지네요.
패딩과 스트라이드는 지정해주지 않으면 각각 0, 1의 기본값을 가지게 됩니다. 패딩은 없고, 커널은 한칸씩 움직이겠네요.
마지막으로 Sequentail의 첫번째 층에선 input_shape를, 활성화 함수는 relu를 사용했습니다.
두번째 층에선 맥스 풀링을 사용하네요. 여기선 풀링 사이즈가 (2,2)이므로 각 필터의 가로세로는 절반씩 줄어들어, 1/4의 크기가 됩니다.
위의 결과를 몇번 반복한 이후, 이번엔 Flatten()이라는 레이어가 등장합니다. 이 레이어는 n차원의 출력을 1차원으로 쭉 늘려줍니다. np.reshape(x, (-1))과 동일하겠네요.
이렇게 펴준 출력을 가지고 이전에 살펴보았던 Dropout 층을 이용해 오버피팅을 완화했습니다.
이후 Dense 레이어로 어느정도 분석을 하고, 마지막 층에선 num_classes, 즉 10개의 출력값을 가진 Dense 레이어에 Softmax 함수를 활성화함수로 사용했습니다. 여기에 대해 이해가 어려우신 분은 이 글을 참고해주세요 :)
이후 컴파일을 마치고, 모델을 요약해서 확인해봅니다.
history = model.fit(x_train, y_train, batch_size=32, epochs=15, validation_split=0.2)
loss, accuracy = model.evaluate(x_test, y_test) # 학습 완료 후 검증
print("손실률:", loss) # 손실률: 0.9327947497367859
print("정확도:", accuracy) # 정확도: 0.705299973487854학습을 진행합니다! 이정도면 음... 나쁘진 않네요. 그래프로 학습 추이를 확인해보겠습니다.
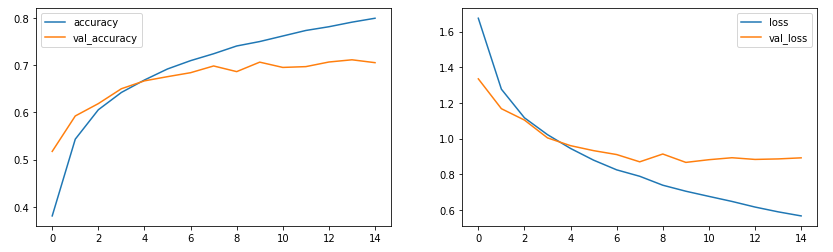
학습셋만 지나치게 학습된게 보이긴 하나, 검증셋에는 영향을 미치진 않네요. 적정선 이내입니다.
이제 모델이 어떻게 예측을 하는지 간단히 확인해보겠습니다.
s = np.random.choice(np.arange(x_test.shape[0]), 5)
preds = model.predict_classes(x_test[s]) # 다중분류이므로, predict_classes
plt.figure(figsize=(20, 100))
for cnt, i in enumerate(s):
plt.subplot(1, 5, cnt+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_test[i])
plt.ylabel("predict: " + class_names[preds[cnt]])
plt.xlabel("label: " + class_names[y_test[i].argmax()])
plt.show()
아래쪽이 y값, 왼쪽이 모델이 예측한 값입니다. 정확하게 다 예측하고 있네요. 만족스럽습니다.
자 이렇게 하여 CNN을 이용한 이미지 처리를 진행해보았습니다. 다음 글에선 이미지가 아닌 시계열 데이터를 처리해보도록 하겠습니다.
어려운 점이나 궁금한 점은 댓글로 남겨주시면 성심성의껏 답변해드리겠습니다. 오탈자, 잘못된 정보 교정은 언제나 환영입니다!
