
2016년, 바둑기사 이세돌과 알파고와의 대국을 통해 딥러닝이라는 단어가 많이 알려지게 되었습니다. 딥러닝이 대체 뭐길래 이렇게 얘기가 나오는 것일까요?
딥 러닝이란?
딥 러닝의 개념
우선, 딥 러닝의 상위 개념인 머신러닝에 대해 알아보겠습니다. 머신러닝Machine Learning 이란 딥 러닝의 상위 개념으로, 컴퓨터가 스스로 학습해 정답을 예측하는 인공지능의 분야입니다.
딥 러닝Deep Learning 은 인간의 신경망의 원리를 모방한 심층신경망 이론을 기반해 고안된 머신러닝 방법의 일종입니다.
딥 러닝이 기존의 통계학이나 다른 머신러닝 방법과 다른 큰 차이점은 인간의 뇌를 기초로하여 설계되었다는 점입니다.
인간은 컴퓨터가 아주 짧은 시간에 할 수 있는 계산도 쉽게 해낼 수 없는 반면, 컴퓨터는 인간이 쉽게 인지하는 사진이나 음성을 해석하지 못합니다.
이는 인간의 뇌가 엄청난 수의 뉴런Neuron과 시냅스Synapse로 이루어져 있기 때문입니다.
각각의 뉴런은 큰 연산을 수행하는 능력이 없지만 수많은 뉴런들이 복잡하게 연결되어 병렬연산을 수행해 컴퓨터가 하지 못하는 음성, 영상인식을 수월하게 할 수 있습니다.
딥 러닝은 이 뉴런과 시냅스의 병렬연산을 컴퓨터로 재현하는 방법이며, 기존의 로직과는 많은 차이를 보입니다.
딥 러닝의 역사
딥러닝의 역사는 크게 3가지 세대로 나누며, 1세대는 최초의 인경신공망인 퍼셉트론, 2세대는 다층 퍼셉트론, 마지막 3세대를 현재의 딥러닝이라고 할 수 있습니다.
1세대 – 퍼셉트론 (Perceptron)
인공신경망의 기원이 되는 퍼셉트론은 1958년에 제안되었는데, n개의 입력을 받아 특정한 연산을 거쳐 하나의 값을 출력하는 방식입니다.
이 연산은 1차함수의 형태f(x) = w * x + b를 띄며, 여기에 활성화 함수Activation Function을 적용하여 최종 값을 출력합니다. 이 출력값은 참인지 거짓인지를 판단합니다. (0 vs 1)
그러나 이런 퍼셉트론은 간단한 xor 연산도 학습하지 못하는 등의 문제가 있어 한동안 발전하지 못하고 표류하게 됩니다.
2세대 - 다층 퍼셉트론 (Multylayer Perceptron)
앞서 살펴본 퍼셉트론의 문제를 해결하는 방법은 의외로 굉장히 단순했는데, 바로 입력과 출력 사이에 하나 이상의 은닉층hidden layer을 추가해 학습하는 것이었으며 이를 다층 퍼셉트론이라고 부릅니다.
아래의 그림은 은닉층의 개수에 따라 모델의 분류력이 좋아진다는 것을 보여줍니다.
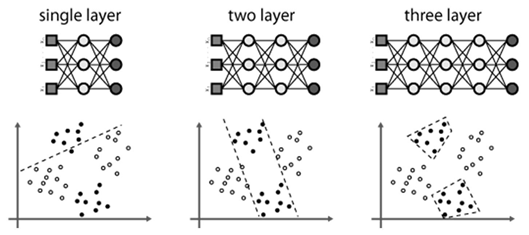
하지만 이런 방법은 은닉층의 개수가 증가할수록 가중치의 개수도 증가해 학습이 어렵다는 단점이 존재했습니다. 이러한 문제를 역전파 알고리즘Backpropagation Algorithm을 통해 다층 퍼셉트론의 학습을 가능하게 하였습니다.
학습은 가능하게 되었어도, 여전히 많은 문제점이 존재했습니다.
- 수많은 레이블
Label이 필요하다. - 과적합
Overfitting으로 인해 성능이 떨어질 수 있다. - 기울기 소실
Gradient Vanishing문제가 발생할 수 있다. - 로컬 미니멈
Local minimum에 빠질 가능성이 있다.
3세대 - 비지도학습 – 볼츠만 머신 (Unsupervised Learning - Boltzmann Machine)
다층 퍼셉트론의 단점으로 인해 인공신경망 이론이 잘 활용되지 못하던 와중, 2006년 볼츠만 머신을 이용한 학습방법으로 인해 딥 러닝이 다시 재조명되기 시작합니다.
볼츠만 머신의 핵심 이론은 바로 비지도학습, 즉 레이블 데이터 없이 미리 충분히 학습을 한 이후 기존의 지도학습을 수행하는 것입니다.
이러한 방법으로 앞서 말한 기울기 소실, 과적합 문제의 극복이 가능하게 되었으며, 지도학습 이전의 비지도 사전학습Unsupervised pre-train을 통한 올바른 초기값 선정으로 로컬 미니멈 문제도 해결이 가능하게 되었습니다.
기존 SW와의 비교
기존 알고리즘과의 방식 차이
기존의 알고리즘은 데이터들이 주어졌을 때, 엔지니어는 컴퓨터에게 문제를 푸는 방법을 가르칩니다. 컴퓨터는 주어진 방식을 통해 해답을 도출하며, 이를 심볼릭 AI라고 부릅니다.
이에 반해 머신러닝 방법은 데이터와 이에 맞는 해답(레이블)이 주어지고, 각각의 데이터들 간의 규칙성을 도출합니다. 이러한 규칙성을 찾는 과정을 학습Training이라고 부릅니다.
딥러닝 역시 머신러닝 방법론 중 하나이므로 위와 같은 방법을 이용합니다.
기존 알고리즘과 머신러닝의 방식을 그림으로 간단하게 표현하면 다음과 같습니다.
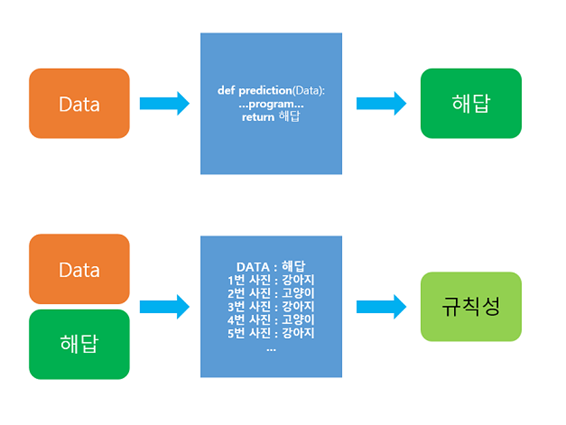
기존 알고리즘과 딥러닝의 성능 비교
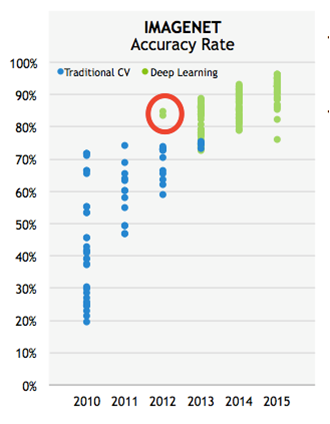
ILSVRC 은 ImageNet Large Scale Visual Recognition Challenge의 약자로 이미지 인식 경진대회입니다. 1000개의 카테고리로 구분되는 대용량의 사진 데이터가 주어지고, 이를 분류하는 알고리즘의 성능을 평가해 순위를 매깁니다.
2012년, CNN기반의 딥러닝 알고리즘 AlexNet이 타 알고리즘보다 압도적으로 높은 정확도로 우승을 차지했습니다. 이를 계기로 딥러닝 방법론이 널리 알려지게 되었으며, 이후 대회에선 딥러닝을 기반으로 한 알고리즘이 대다수를 차지하게 되었습니다.
기존의 알고리즘과 딥러닝 기반 알고리즘의 정확도 차이를 나타낸 그래프입니다.
한편, 자연어처리 분야에서는 딥러닝 기반의 알고리즘 Word2Vec을 시작으로 하여 기존의 알고리즘을 가볍게 뛰어넘는 모델들이 등장하여 자연어처리 분야에서도 딥러닝은 각광받고 있습니다.
최신 동향
최근에는 단순하게 모델이 어떠한 값을 예측하는 것에서 벗어나, 모델이 직접 데이터를 생성하는 단계에 이르렀습니다.
모델이 생성해낸 문장이나 사진은 인간이 구분할 수 없는 단계에 도달했으며, 판단 분야 역시 인간의 판단능력을 뛰어넘었습니다.
또한 머신러닝의 한 분야인 강화학습은 모델이 단순히 판단, 생성만을 하고 그치는 것이 아닌 직접 행동하여 게임등의 활동을 할 수 있습니다.
사람처럼 스스로 생각하고 판단해 행동하는 강한 인공지능은 아직 먼 미래일지 몰라도, 주위를 조금만 둘러보면 인공지능을 발견할 수 있는 때는 근 시일 내에 볼 수 있을지도 모르겠습니다.
오탈자, 잘못된 정보 교정은 언제나 환영입니다!
