딥 러닝은 이전 글에서 찾아보았던 것 처럼 데이터들간의 규칙성을 파악합니다. 그렇기 때문에 픽셀 하나하나를 특성으로 가지는 이미지처리나 무수히 많은 경우를 가진 자연어처리 등에서 강한 모습을 보여줍니다.
이번에는 그중 MNIST라는 데이터셋으로 직접 분류를 진행하겠습니다.
개발 환경
앞으로 딥러닝 튜토리얼은 구글에서 제공하는 Colaboratory, 코랩이라는 개발환경을 사용하겠습니다.
딥러닝을 개발하기 위해선 많은 양의 벡터 연산을 빠르게 진행할 수 있는 GPU가 필요합니다. 물론 CPU로도 학습은 가능하지만, GPU보다 몇십배는 느리게 학습이 진행됩니다. 코랩을 통해 구글에서 제공하는 CPU와 GPU 등을 사용할 수 있습니다.
Colaboratory을 클릭해 코랩에 들어가신 후, 좌상단의 파일탭을 선택하고 새 노트를 선택해 새로운 ipynb 파일을 만들어주세요.
데이터 설명
MNIST 데이터셋은 28x28 사이즈의 손글씨 데이터셋입니다. 0~9까지 총 10개의 클래스를 가지
고 있으며, 색상 채널이 없는 흑백 이미지입니다. 비교적 단순한 예제이기 때문에 머신러닝, 딥러닝 기초 예제로 많이 사용됩니다.

실습
우선, 이번 실습을 위해 필요한 라이브러리를 임포트해줍니다.
import matplotlib.pyplot as plt # 그림으로 보기 위한 matplotlib 라이브러리 import
from tensorflow.keras.datasets import mnist # 라이브러리가 기본으로 제공하는 mnist 데이터셋
from tensorflow.keras.utils import to_categorical # one-hot encoding 을 위한 함수
from tensorflow.keras.models import Sequential # 레이어를 층층히 쌓아가는 연쇄 모델
from tensorflow.keras.layers import Dense # 완전연결층
from tensorflow.keras.models import load_model # 저장된 모델 불러오기데이터 불러오기
필요한 라이브러리를 모두 불러왔다면, 가장 중요한 데이터를 불러옵니다.
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 데이터셋 차원 확인
print(f"X_train_shape: {X_train.shape}") # X_train_shape: (60000, 28, 28)
print(f"y_train_shape: {y_train.shape}") # y_train_shape: (60000,)
print(f"X_test_shape: {X_test.shape}") # X_test_shape: (10000, 28, 28)
print(f"y_test_shape: {y_test.shape}") # y_test_shape: (10000,)
plt.imshow(X_train[0])
plt.show()모델에 들어가는 입력 데이터, 즉 손글씨 이미지 파일을 X_train과 X_test에 각각 60000개, 10000개씩 저장하였고, 이에 대응하는 레이블 데이터를 y_train과 y_test에 60000개, 10000개씩 저장하였습니다.
이중 train 데이터는 모델을 학습시킬때 사용하며, test 데이터는 모델의 성능을 테스트할 때 사용합니다. 데이터를 이처럼 학습셋과 테스트셋으로 분류하는 이유는 이미 풀었던 문제로 시험을 보는 것은 의미가 없기 때문입니다.
문제집에 나오는 문제(학습셋)만 열심히 공부했는데, 이미 풀어봤던 문제가 시험에 나온다면 당연히 100점이 나오겠지요. 그래서 한번도 풀어본 적이 없는 문제들(테스트셋)을 통해 주어진 주제의 문제를 얼마나 잘 풀 수 있는가를 알아보는 것 입니다.
데이터 전처리
이렇게 학습셋과 테스트셋으로 나눈 데이터들을 전처리해줍니다. 모델이 아무리 많은 데이터를 사람처럼 처리해도, 결국은 숫자로 된 데이터를 연산을 통해 해결하는 것 입니다. 또한 모델은 단순한 정수를 처리하는것보다 0~1 사이의 실수를 처리할 때 더 좋은 성능을 보입니다. 따라서 0~255의 픽셀값으로 이루어진 이미지에 255를 나눠줘 전처리를 해줍니다.
또한 현재의 모델은 2차원 데이터를 받아들이기 힘들기 때문에, 이를 1차원으로 쭉 펴줍니다
input_shape = X_train.shape[1] * X_train.shape[2] # 그림의 크기: 28 * 28
number_of_classes = len(set(y_train)) # 레이블의 종류. 0~9로 10개
X_train = X_train / 255.0
X_test = X_test / 255
X_train = X_train.reshape(-1, input_shape) # 3차원 -> 2차원
X_test = X_test.reshape(-1, input_shape)
print(f"X_train_shape: {X_train.shape}") # X_train_shape: (60000, 784)
print(f"X_test_shape: {X_test.shape}") # X_test_shape: (10000, 784)입력 데이터를 모두 전처리했다면, 출력 데이터도 전처리해줍니다.
출력 데이터는 단일 값, 즉 스칼라값으로 정해져있지만, 이를 1차원의 벡터값으로 바꿔줍니다. 이때, 이 벡터는 해당 클래스에 해당하는 값만 1로 두고, 나머지는 모두 0으로 채워줍니다.
예를 들면 5라는 클래스는 [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]로 만들어주고, 1이라는 클래스는 [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]로 바꿔줍니다.
tf에서 제공하는 to_categorical이라는 함수를 이용합니다.
y_train = to_categorical(y_train, number_of_classes) # 원-핫 인코딩. 1차원 -> 2차원
y_test = to_categorical(y_test, number_of_classes)
print(f"y_train_shape: {y_train.shape}") # y_train_shape: (60000, 10)
print(f"y_test_shape: {y_test.shape}") # y_test_shape: (10000, 10)이와 같은 방법을 원 핫 인코딩one-hot-encoding이라고 합니다.
원 핫 인코딩은 이와 같은 클래스 분류 문제나 자연어 처리 분야에서도 사용되니 꼭 알아놓읍시다.
모델 정의 및 컴파일
데이터를 전처리했으니, 이를 분석할 모델을 만들어봅시다. 간단히 층 두개를 이을 모델이므로 Sequential 모델로 층층히 쌓아가도록 하겠습니다.
model = Sequential() # 모델 선언첫번째 층은 128개의 출력값을 가지는 완전연결층입니다. 완전연결층은 입력갑과 가중치들 간의 dot 연산을 진행한 후, 여기에 편향을 더한 값으로, 일차함수 y = wx + b로 나타낼 수 있습니다. 텐서플로우 2.x에선 Dense로 사용할 수 있습니다.
단순히 완전연결층을 많이 쌓으면 이는 하나의 완전연결층과 동일한 기능을 하며, 쓸데없는 연산만 많아질 뿐입니다. 그래서 활성화함수로 많은 층을 사용할 수 있도록 합니다. 은닉층의 활성화 함수로 가장 많이 사용되는 relu 함수를 첫번째 층의 활성화 함수로 사용하겠습니다.
relu 함수의 수식은 x = max(x, 0)입니다.
또한 첫번째 층에는 모델에 들어가는 데이터의 차원을 반드시 넣어주어야 합니다.
# 완전연결층 추가. 처음 쌓는 레이어는 input_shape: 데이터 차원(개수 제외)을 적어줘야함.
model.add(Dense(128, activation="relu", input_shape=X_train.shape[1:]))두번째 층이자 마지막 층을 쌓아보겠습니다. 분류 문제에선 마지막 층의 출력값을 클래스 개수와 동일하게 맞춰줍니다. mnist데이터는 0~9 총 10개의 클래스가 존재합니다.
또한 우리는 3개 이상의 다중 클래스 분류 문제이므로 softmax 함수를 활성화 함수로 사용합니다.
softmax 함수는 출력값의 합이 항상 1이며, 이는 각 클래스가 정답일 확률을 나타냅니다.
softmax 함수의 수식은 y = exp(x) / sum(exp(x))입니다.
# 출력하는 완전연결층 추가. 다중분류이므로, softmax 활성화함수 사용
model.add(Dense(y_train.shape[1], activation="softmax"))모델을 모두 작성하였으니, 이를 컴파일해줍니다. 모델의 손실함수를 정의하고, 정한 손실함수로 얻은 손실값을 통해 모델의 파라미터를 조정하는 옵티마이저 등을 정의합니다.
우리는 다중 클래스 분류 문제를 풀고있기 때문에, categorical_crossentrpy를 손실함수로 사용합니다. 이 손실함수는 앞서 사용한 softmax 활성화함수랑 짝을 이루는 손실함수 입니다.
옵티마이저로는 Adam을 사용하며, 정확도를 구하는 매트릭인 acc을 추가합니다.
# 모델 컴파일. 다중분류이므로 categorical_crossentropy, 정확도 표기
model.compile(loss="categorical_crossentropy",
optimizer="adam",
metrics=["acc"])
model.summary() # 간단하게 요약해 출력모델 학습 및 검증
모델을 정의하고 컴파일도 완료했으니, 이제 학습을 시켜봅시다.
입력 데이터로 X_train을, 정답 데이터로 y_train을 넣어줍니다.
에포크epochs는 주어진 데이터가 문제집이라고 가정했을때, 이 문제집을 몇 번 풀것인가를 나타냅니다.
배치 사이즈batch_size는 문제집을 풀 때, 몇문제를 풀고 채점을 할 것인지를 나타냅니다.
validation_split은 학습 데이터와 검증 데이터를 나누는 비율을 나타냅니다.
모델을 학습할 땐 위에서 말한 테스트 외에도 에포크가 끝날때마다의 학습 지표를 알아야 하는데요, 이를 검증단계라고 합니다. 검증 단계에서도 테스트와 마찬가지로 학습때 사용하지 않은 데이터를 검증 데이터로 사용합니다.
검증 단계의 지표를 통해 모델이 올바르게 학습중인지를 확인할 수 있습니다.
이렇게 학습을 마친 후, evaluate함수로 테스트를 진행합니다.
history = model.fit(X_train, y_train, batch_size=32, epochs=10, validation_split=0.2)
loss, acc = model.evaluate(X_test, y_test) # 학습 완료 후 검증
print("손실률:", loss) # 손실률: 0.08662549406290054
print("정확도:", acc) # 정확도: 0.9779999852180481손실 0.08에 정확도 97%라는 좋은 결과가 나왔네요! 이 결과는 모델마다 다를 수 있으니, 다르다고 허둥지둥하지 않으셔도 됩니다.
학습 시각화
plt.figure(figsize=(18, 6))
# 에포크별 정확도
plt.subplot(1,2,1)
plt.plot(history.history["acc"], label="accuracy")
plt.plot(history.history["val_acc"], label="val_accuracy")
plt.title("accuracy")
plt.legend()
# 에포크별 손실률
plt.subplot(1,2,2)
plt.plot(history.history["loss"], label="loss")
plt.plot(history.history["val_loss"], label="val_loss")
plt.title("loss")
plt.legend()
plt.show()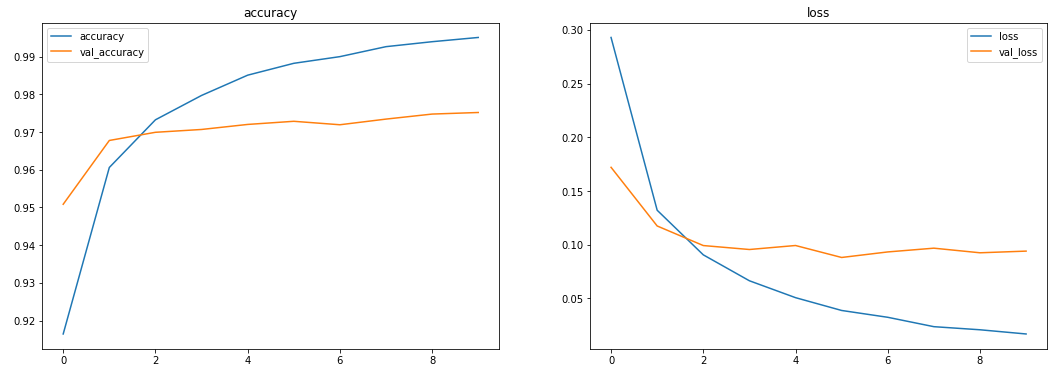
에포크별 학습 지표를 그래프로 나타냅니다.
학습 정확도는 점점 올라가고 손실은 내려가는데 비해 검증 단계에서는 어느 한 구간에서 정체되어있네요. 여기서 정확도가 떨어지며 손실은 계속 늘어나게 되면 그 모델은 학습셋에면 너무 과하게 학습한 과적합 상태라고 할 수 있습니다.
한마디로 문제집의 문제만 너무 익숙해져서 비슷한 다른 문제를 못 푼다는 것이죠. 사용이 불가능한 모델입니다.
이때는 에포크를 줄여 과적합을 피하던가, 다른 방법을 통해 이를 과적합을 피합니다. 이는 다음 포스팅에서 알아보도록 하죠 :)
모델 저장 및 불러오기
model.save("저장할 모델의 위치.h5")
loaded_model = load_model("저장한 모델의 위치.h5")save 함수를 통해 모델을 .h5확장자로 저장할 수 있습니다.
또한 load_model함수로 저장된 모델을 불러올 수 있습니다.
예측해보기
학습에 사용하지 않은 테스트 데이터로 예측을 해보겠습니다.
1차원으로 펴진 데이터를 다시 2차원으로 바꿔 입력값을 확인해보고, 이를 예측합니다.
분류 문제에서는 predict_classes로 한번에 클래스를 예측할 수 있습니다.
잘 작동하는것 같네요.
plt.imshow(X_test[0].reshape(28, 28)) # 데이터 일자로 펴주기
plt.show()
pred = model.predict_classes(X_test[:1])[0] # 다중분류이므로, predict_classes
print("real:", y_test[0].argmax()) # 7
print("predict:", pred) # 7이렇게 간단하게 손글씨를 분류해보았습니다. 어려운 점이나 궁금한 점은 댓글로 남겨주시면 성심성의껏 답변해드리겠습니다.
오탈자, 잘못된 정보 교정은 언제나 환영입니다!

15개의 댓글





안녕하세요 ! 구글링하던 중 너무나 친절한 자료를 찾아서 기쁩니다,, 도움 많이 받고 가요 ㅠㅠ 혹시 fashion mnist 데이터도 외부이미지로 테스트하고 싶을 경우, 아래 답글 달아주신 코드 그대로 실행하면 되나요? 자꾸만 오류가 생기네요...
진짜 최고입니다.. 다른 자료들보다 훨씬 직관적이고 각 코드가 무얼 의미하는지 이해하기 쉽게 작성되었네요.