기간: 25.01.07 ~ 25.07.03
25.01.09 : 파이썬의 기본 문법 및 변수
25.01.09 일일 회고록
학습내용
- 사칙연산과 문자열 처리
- 리스트
- 튜플
- 딕셔너리
- 집합
- 불리언
- 조건문
- 반복문
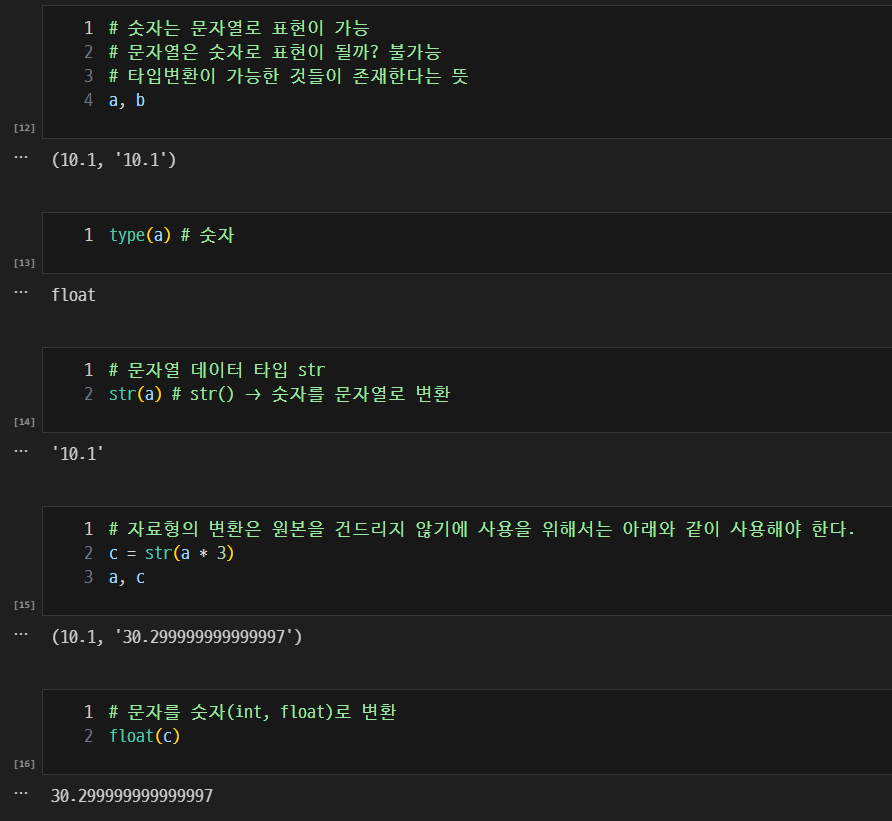
0. 변수의 타입 변환
-
에러가 발생하지 않는 타입 변환
-
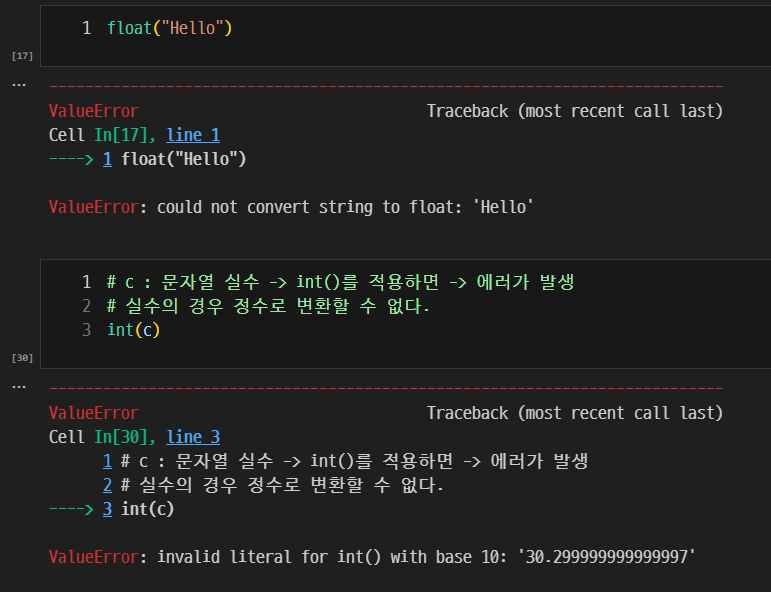
에러가 발생하는 타입 변환
1. 사칙연산과 문자열 처리
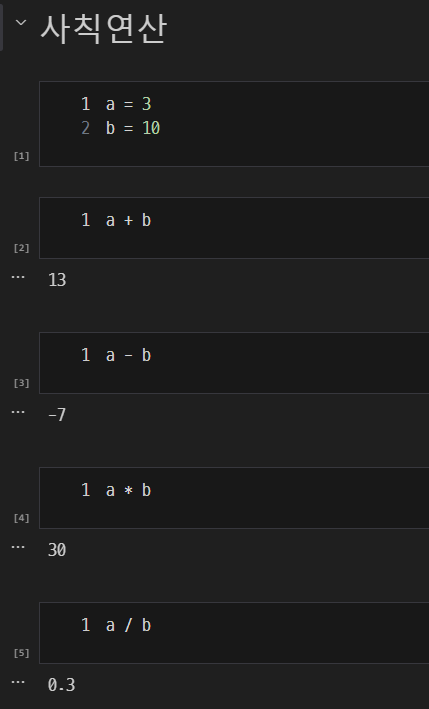
- 사칙연산 (+, -, *, /, **, %, //)의 기본 원리와 활용 방법.
-
사칙연산
-
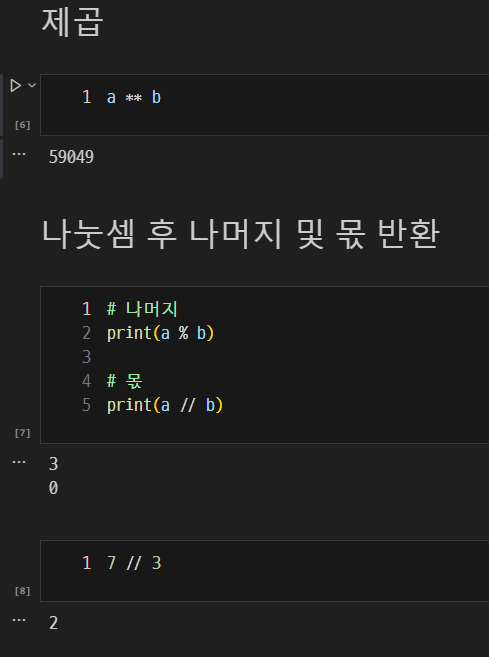
제곱 및 나머지 연산
-
문자열 연결(+) 및 다양한 포맷 방법(f-string, .format()).
-
대표적인 포맷 방법들
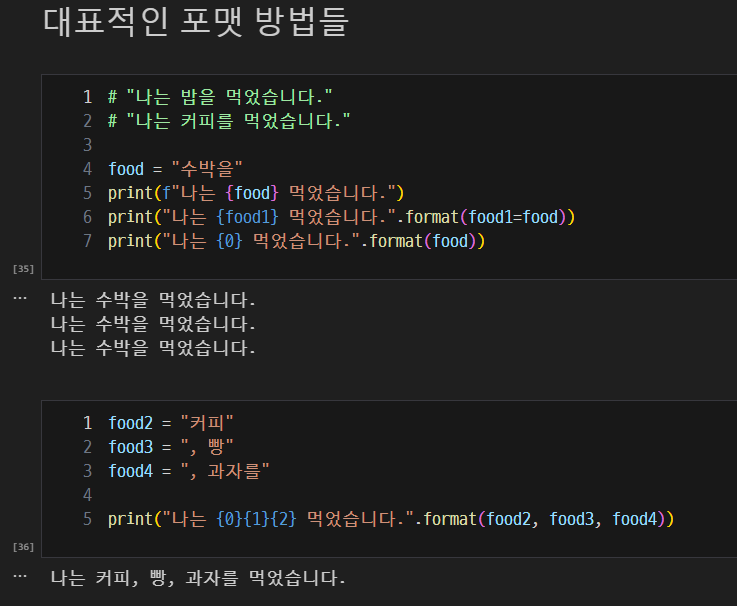
-
기타 포맷 방법들
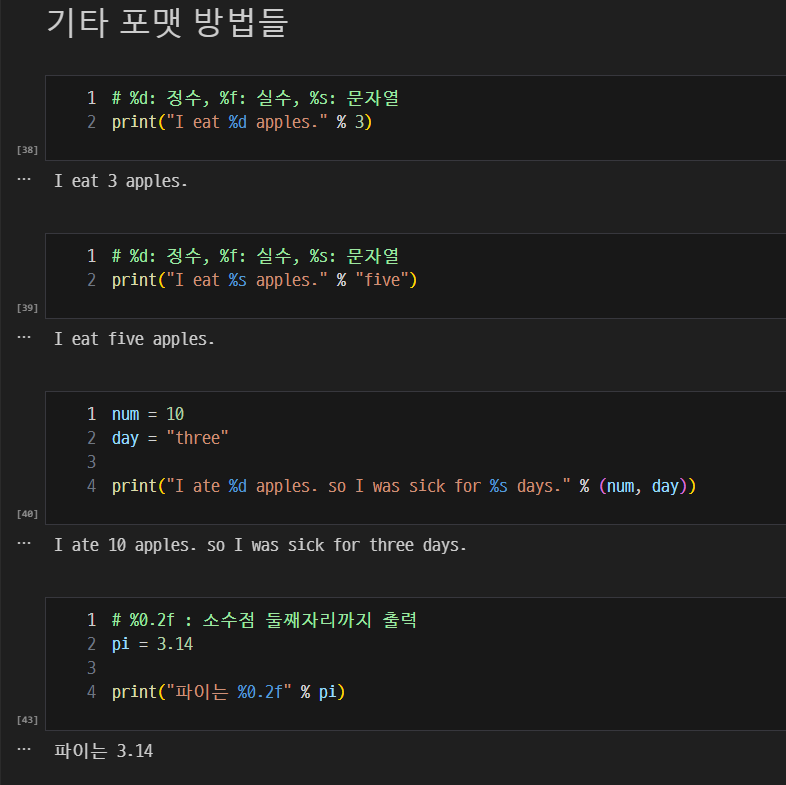
-
문자열에서 사용 가능한 함수들
-
count(): 괄호 안의 문자열이 몇 개 있는지 세어서 반환
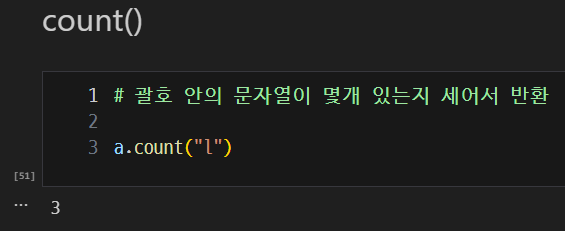
-
find(): 문자열에서 특정 문자의 위치(인덱스)를 찾아주는 함수- 문자열에 존재하지 않는 문자를 찾으려 하면 -1 반환
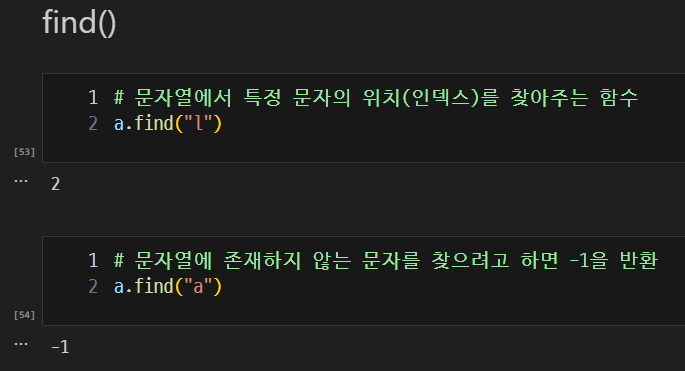
- 문자열에 존재하지 않는 문자를 찾으려 하면 -1 반환
-
split(): 문자열 분리
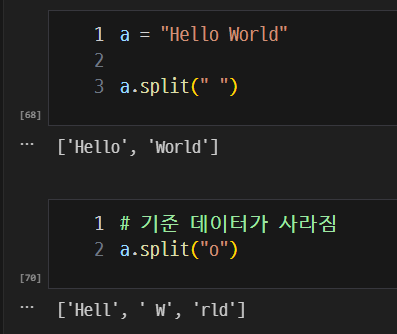
-
대소문자 변환
upper(): 대문자로 변환lower(): 소문자로 변환
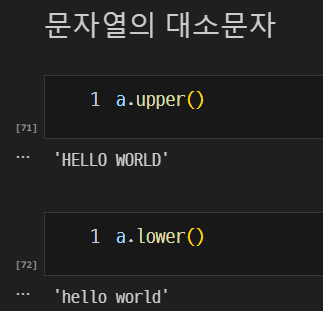
-
strip(): 문자열의 앞뒤 공백을 제거하는 함수
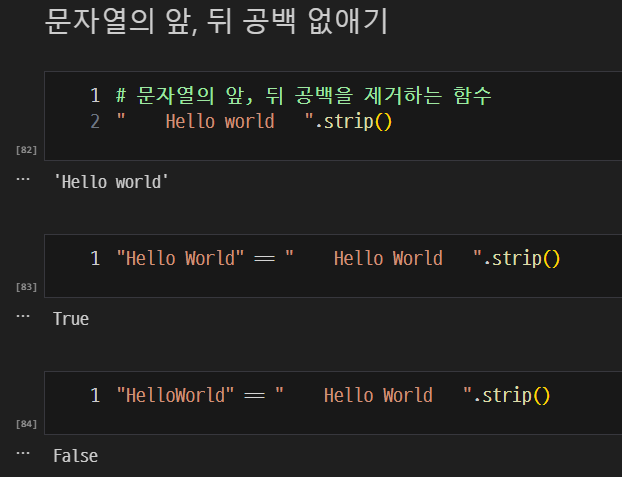
-
replace(): 문자열을 변경하는 함수- 문자열 변경, 대체
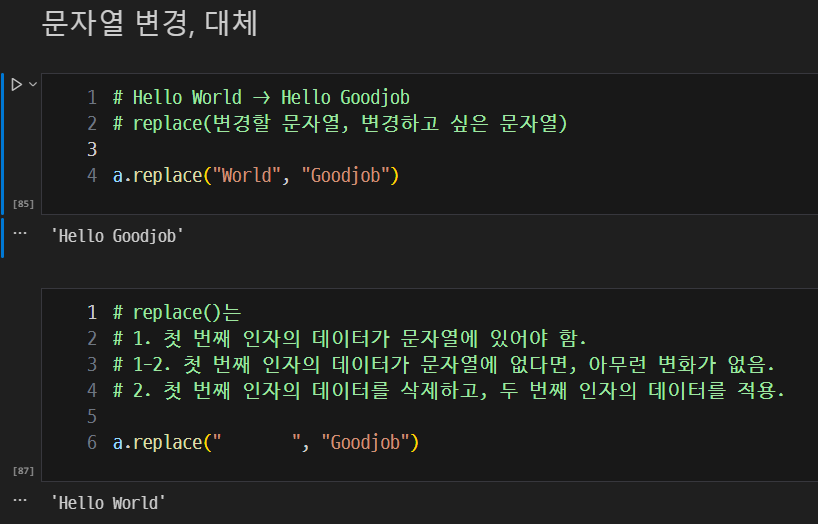
- 문자열 변경, 대체
-
-
2. 리스트
-
리스트의 생성 및 다양한 연산(인덱싱, 슬라이싱).
-
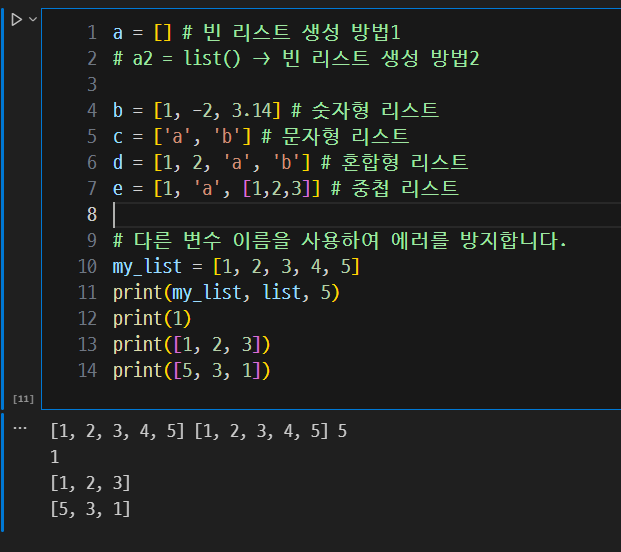
다양한 리스트의 생성
-
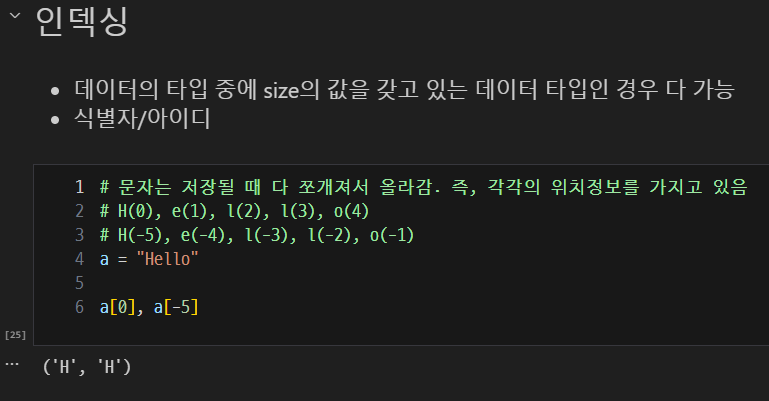
인덱싱
- 데이터의 타입 중에 size의 값을 갖고 있는 데이터 타입인 경우 다 가능
- 식별자/아이디
-
슬라이싱
- 데이터 타입 중 size가 있는 경우에만 사용 가능
- 사용법 :
변수명[시작 인덱스 : 끝 인덱스(x) : 간격]시작 인덱스: 포함됨, 생략가능 (= 시작 인덱스가 자동으로 적용됨(Default))끝 인덱스: 불포함, 생략가능 (= 데이터 타입의 길이 자동으로 적용됨(Default))간격: Default(= 1)- if) 간격 = 1 -> Hello
- a[0::1] -> Hello
- if) 간격 = 2 -> Hlo
- a[0::2] -> Hlo
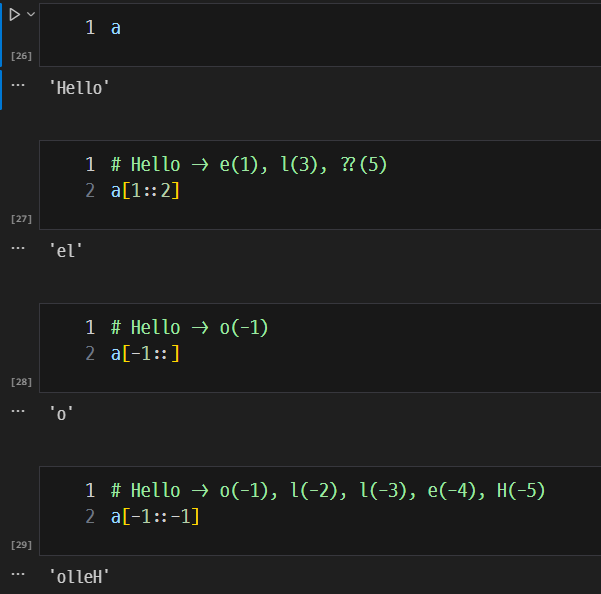
- a[0::2] -> Hlo
- if) 간격 = 1 -> Hello
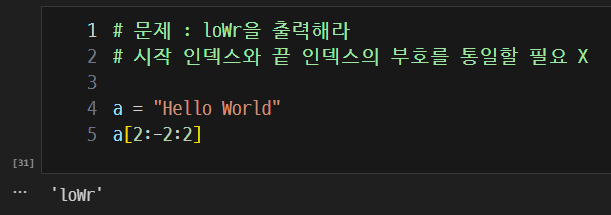
- 슬라이싱 문제
-
-
append()와 extend()의 차이점.
- append()는 괄호 안을 하나의 데이터로 봄
- extend()는 괄호 안의 리스트 요소들을 각각의 데이터로 봄

-
리스트 정렬 및 인덱스 찾기.
sort(): 정렬 함수

-
리스트에서 사용되는 함수들
-
index(): 특정 요소의 인덱스를 반환. (문자열에서의 find()와 유사)
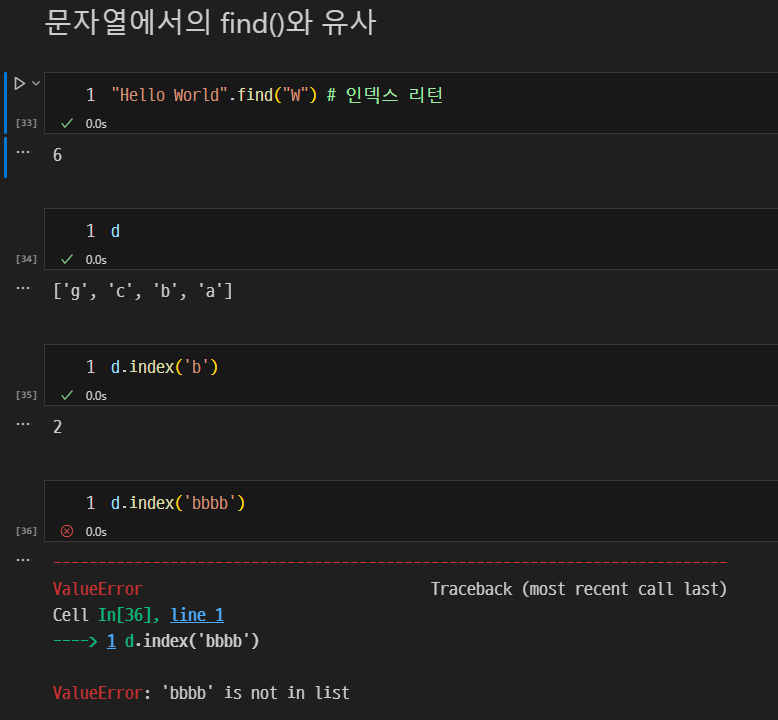
-
count(): 특정 요소의 개수 반환. (문자열에서의 count()와 동일)
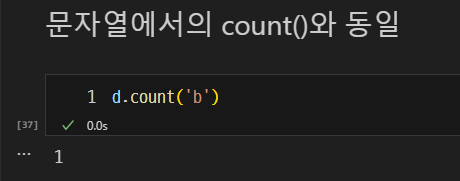
-
3. 튜플
-
튜플의 불변성 및 생성 시 주의점.
- 수정 / 추가 불가능
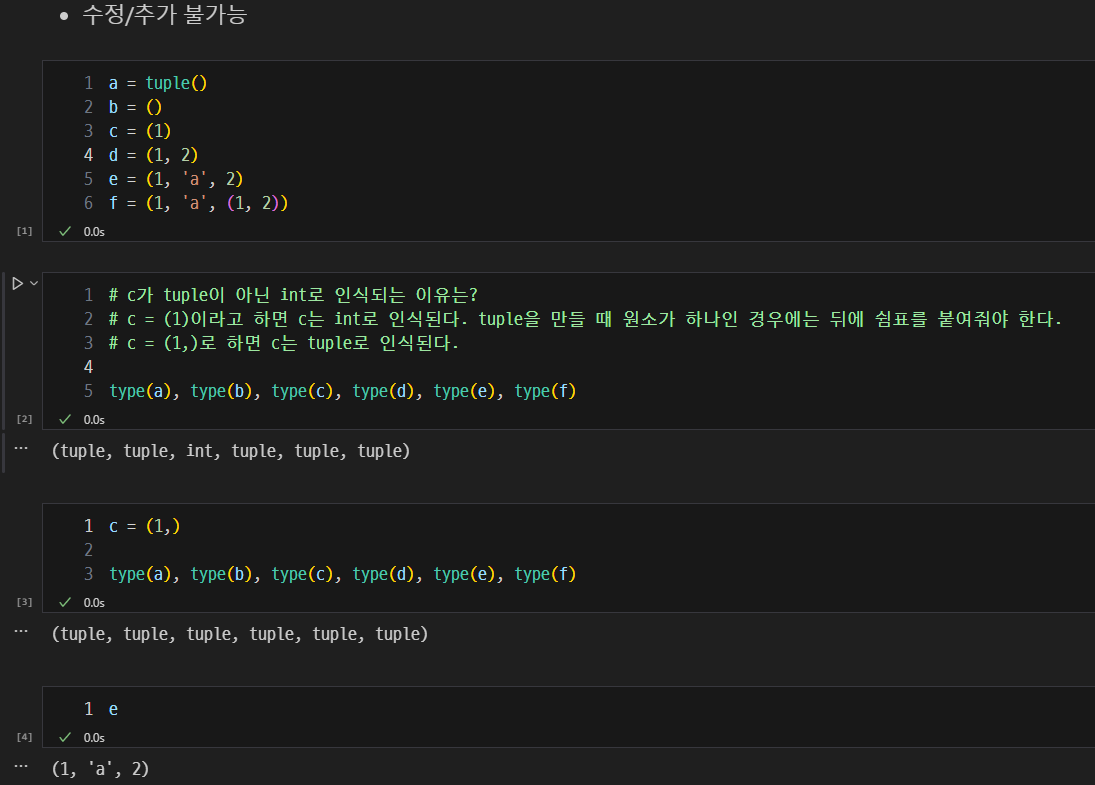
- 수정 / 추가 불가능
-
튜플 간의 연산과 길이 확인.
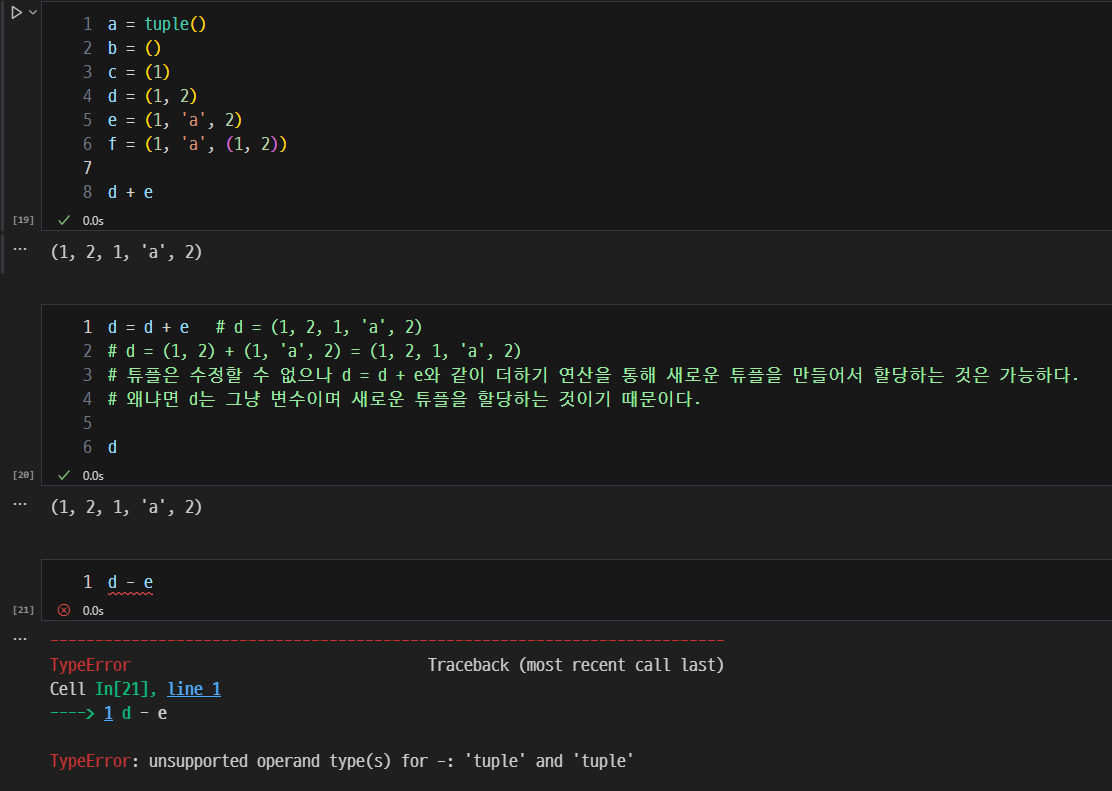
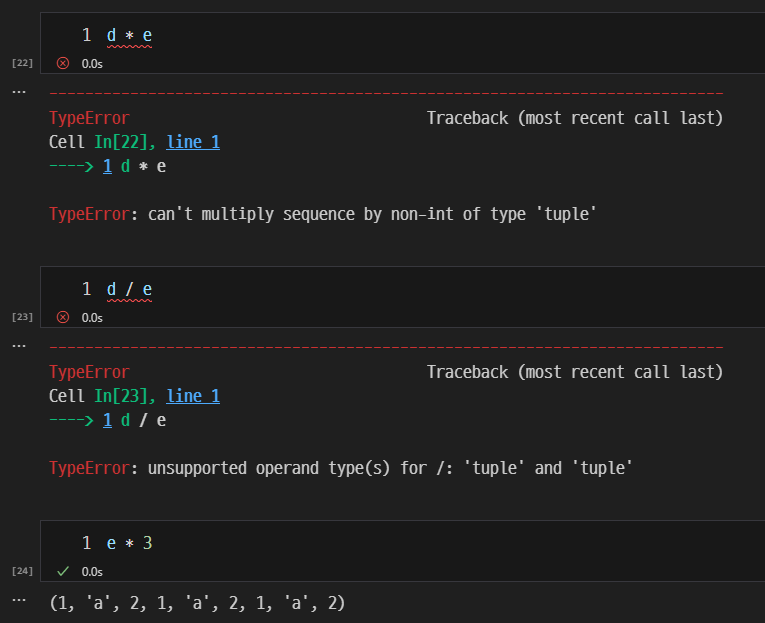
- 튜플의 더하기의 제약조건
- 튜플끼리 더하기 가능
- 튜플에 정수나 실수, 리스트 등을 더하는 것은 불가능
- concatenate = 합치다
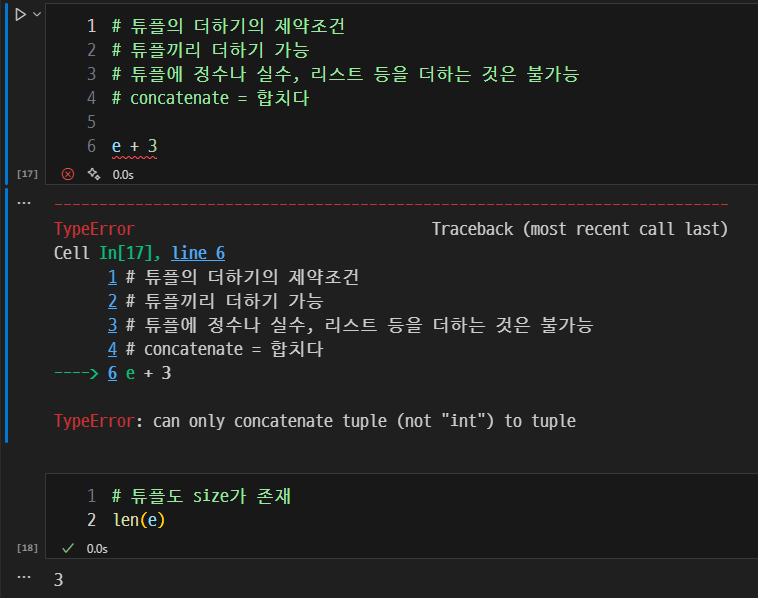
- 튜플의 더하기의 제약조건
4. 딕셔너리
-
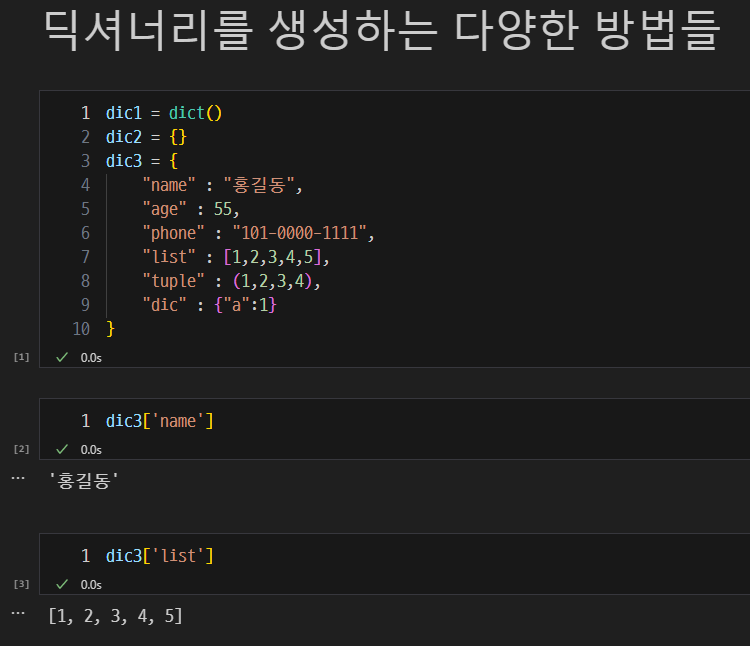
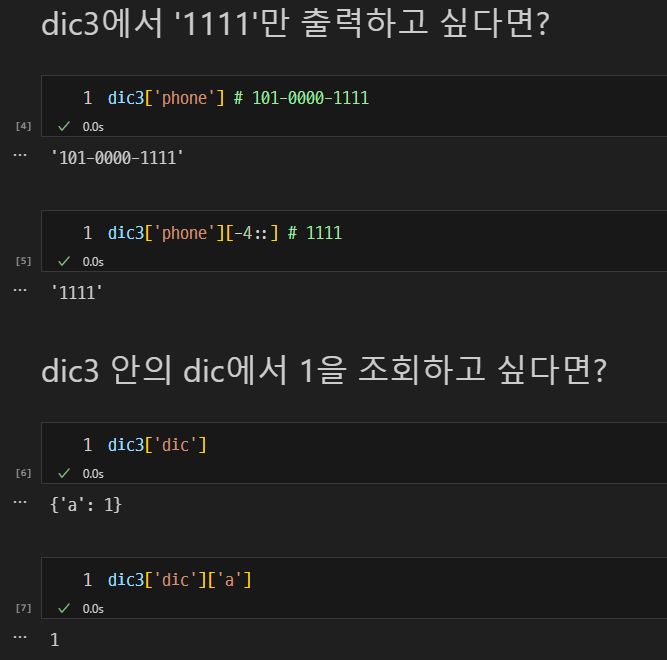
딕셔너리의 생성 방법 및 key-value 접근 방법.
- 딕셔너리 생성
- key-value 접근 방법
- 딕셔너리 생성
-
get() 메서드를 활용하여 값 반환.
- 조건문을 사용하지 않고, value 반환 가능

- 조건문을 사용하지 않고, value 반환 가능
-
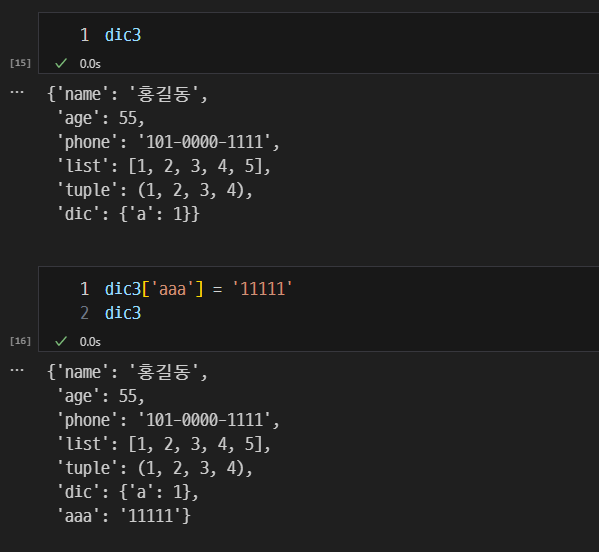
딕셔너리에 key, value 추가
- 기존에 있는 key를 사용하면 -> value 업데이트
- 기존에 없는 key를 사용하면 -> value 추가
-
keys(), values(), items() 메서드의 사용법.
-
keys():

-
values():

-
itmes(): 키 - 값 쌍을 튜플로 반환

-
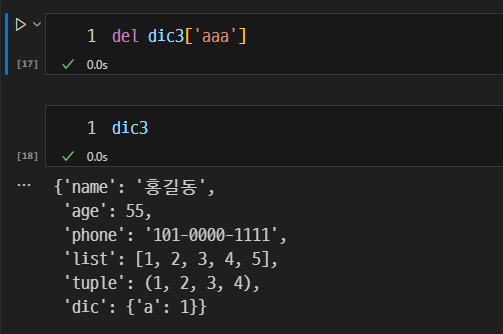
del: 삭제하고 싶은 key를 사용하여 삭제
5. 집합(set)
-
집합의 특징
- 순서가 없음
- 중복을 허용하지 않음
-
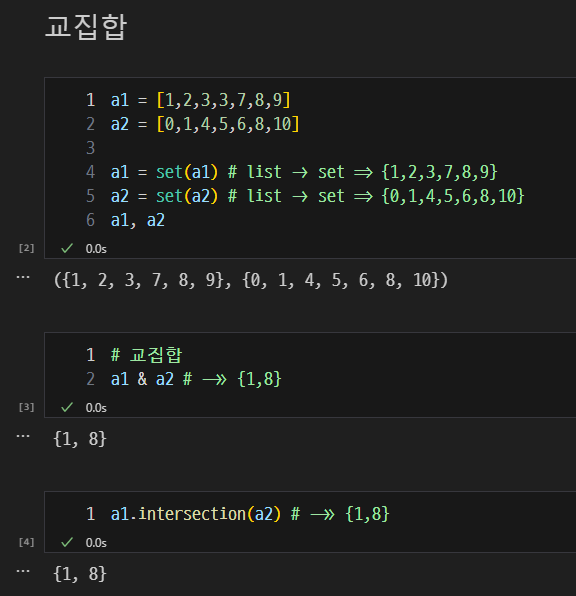
중복 제거 및 집합 연산(교집합, 합집합, 차집합).
-
intersection(),union(),difference()메서드 활용. -
교집합
-
합집합

-
차집합

-
6. 불리언(Boolean)
-
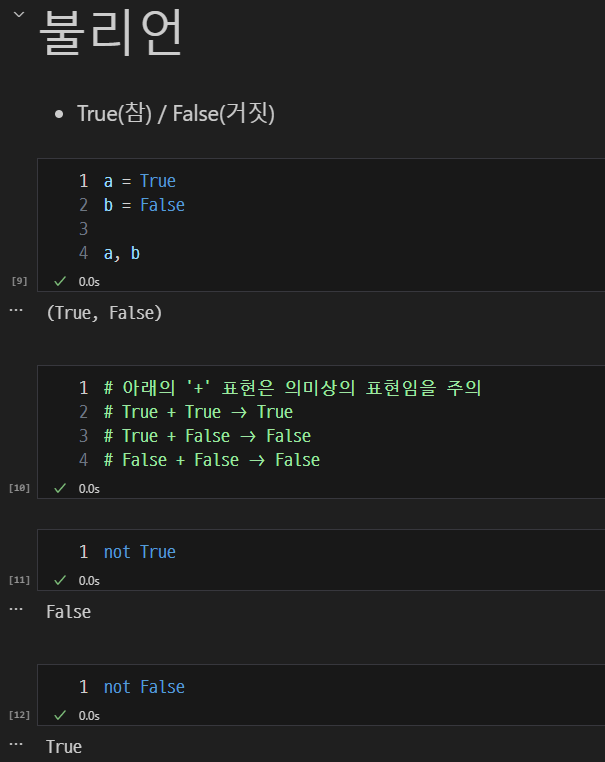
True, False 및 자료형과의 변환 원리 (bool() 함수).
-
문자열을 불리언으로
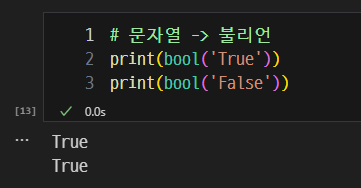
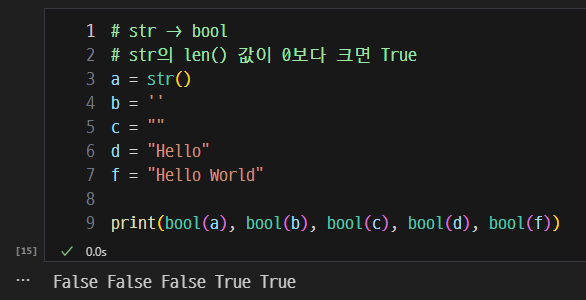
-
숫자를 불리언으로
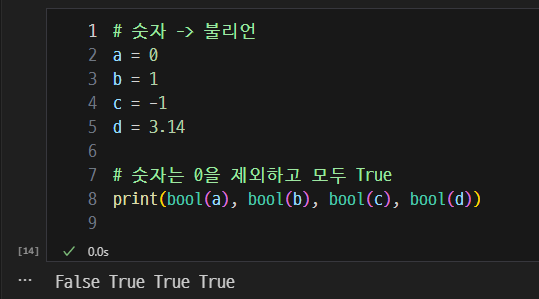
-
7. 조건문
- if, elif, else와 불리언을 활용한 논리적 조건 처리.
- if / else
- if : 만약 ~ 라면, ~ 한다.
- else : 그렇지 않으면, ~ 한다.
- elif : 그렇지 않고 만약 ~ 라면, ~ 한다.
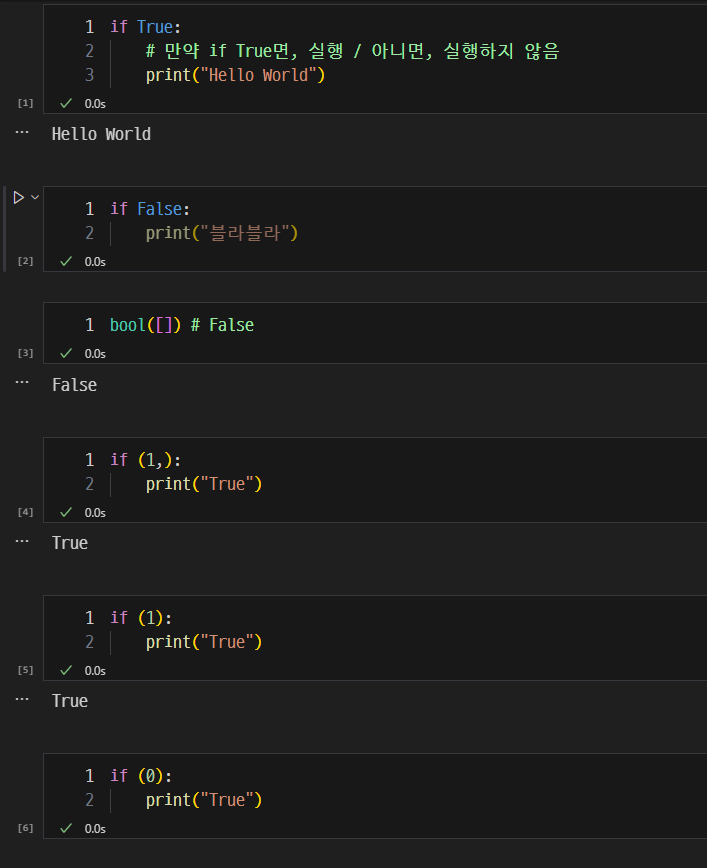
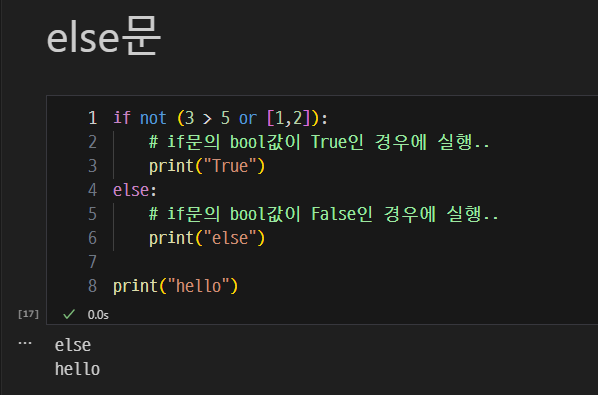
- if / else
-
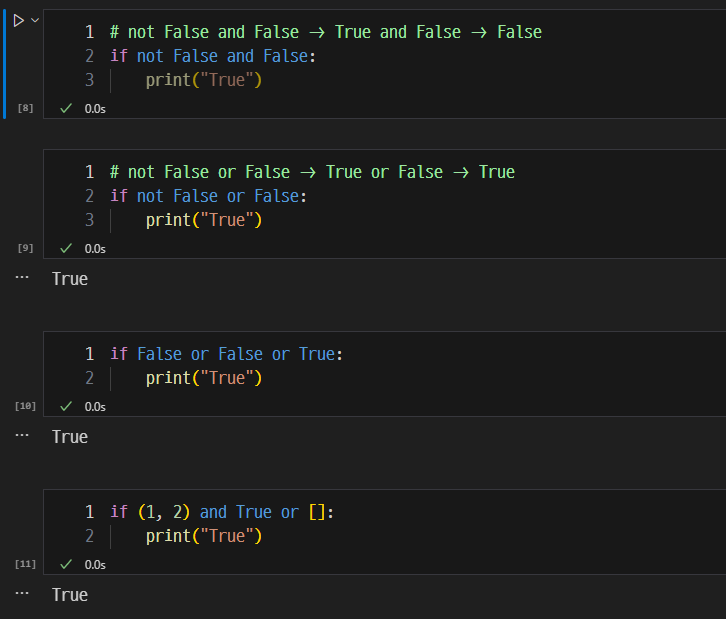
and, or, not 연산자의 활용.
-
AND : 둘다 True(1) 이어야 함.
-
OR : 둘 중 하나라도 True(1) 이어야 함.
- 코드의 가독성을 위해 아래와 같이 추천
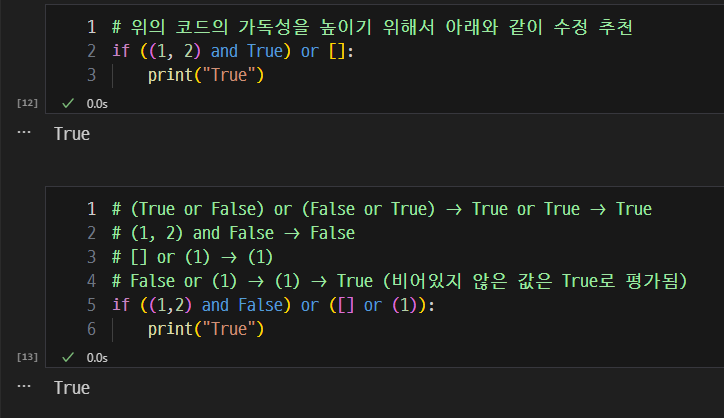
- 좁은 범위부터 넓어지도록 작성
- 좁은 범위부터 넓어지도록 작성
- 코드의 가독성을 위해 아래와 같이 추천
-
8. 반복문
-
for 루프와 집합형 데이터(iterable) 활용.
- for문
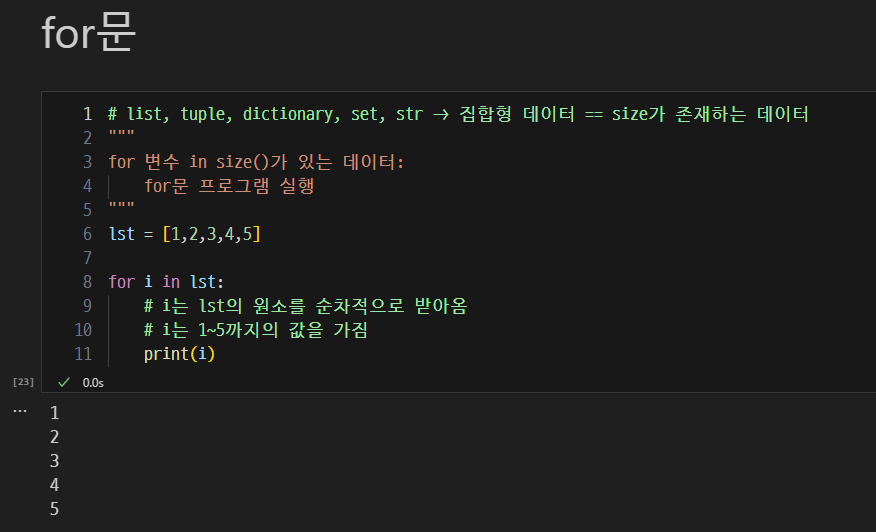
- for문
-
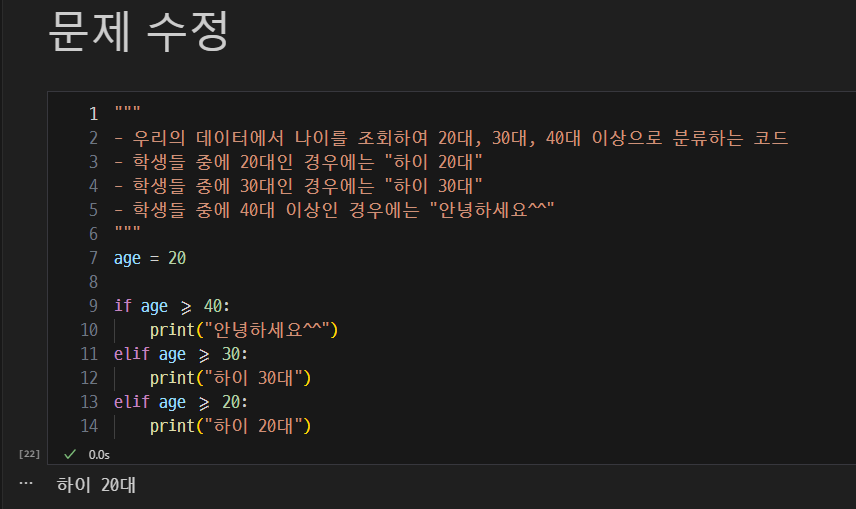
구구단 출력 및 딕셔너리 순회.
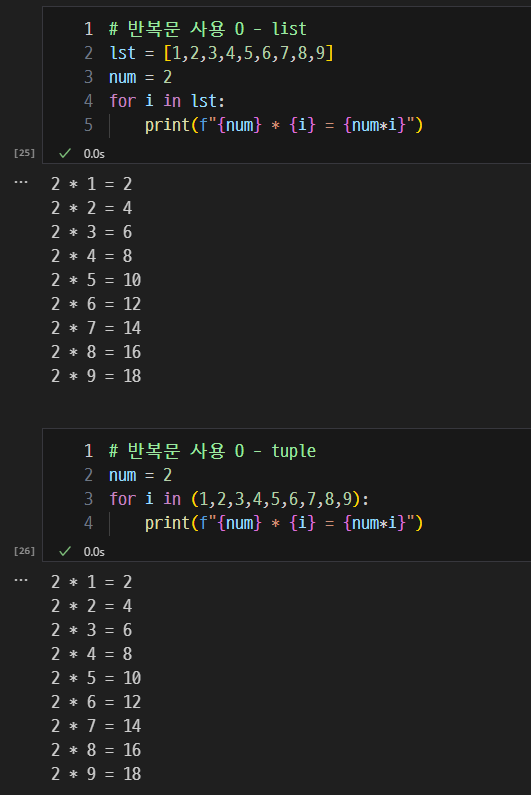
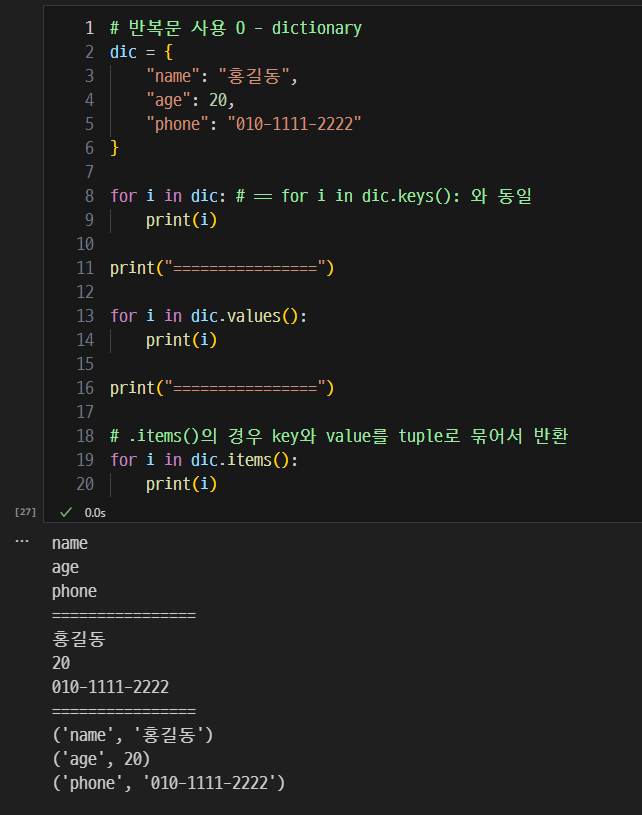
-
반복문으로 딕셔너리 순회 시 발생할 수 있는 문제
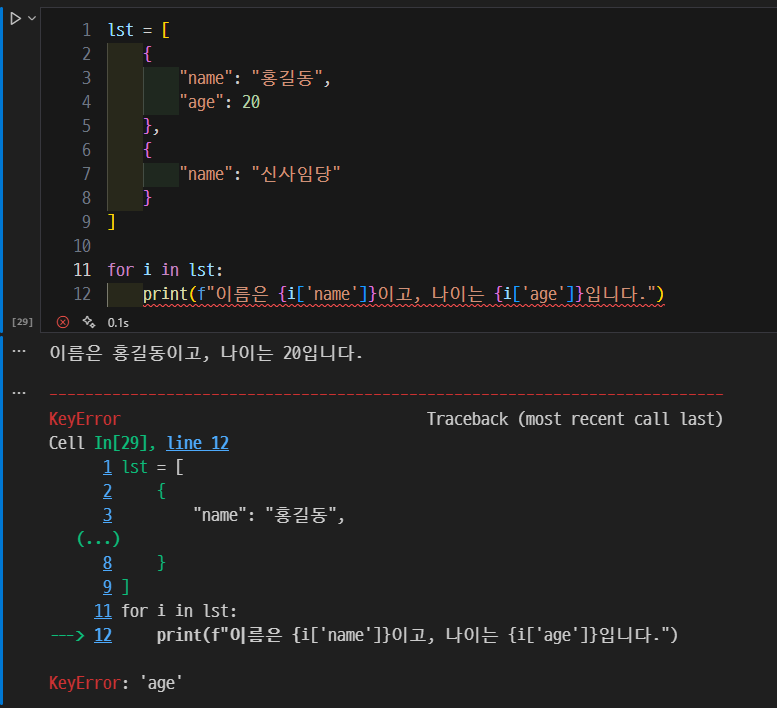
- 위의 문제를 해결하기 위해서는 아래와 같이 작성
get()사용
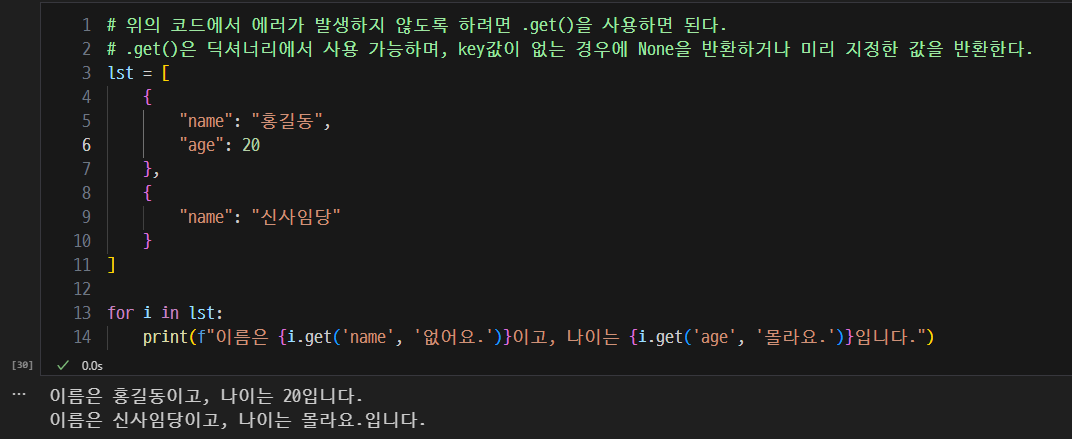
- 위의 문제를 해결하기 위해서는 아래와 같이 작성
-
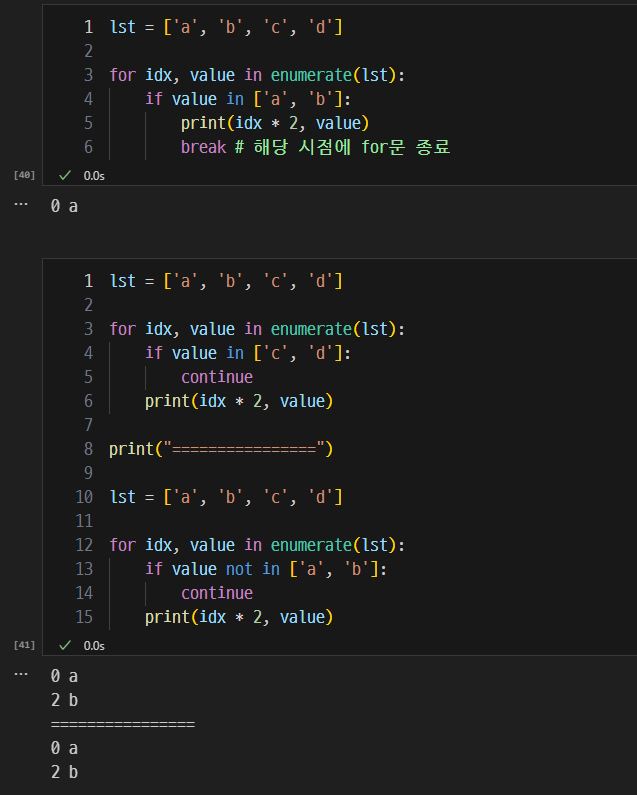
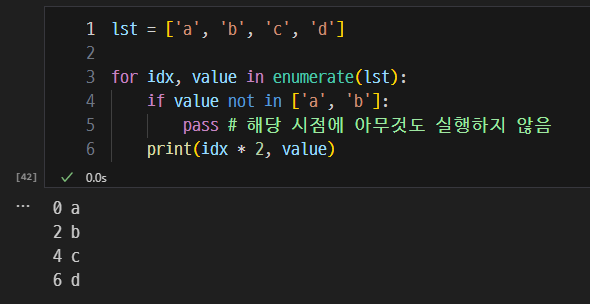
break, continue, pass의 역할.
-
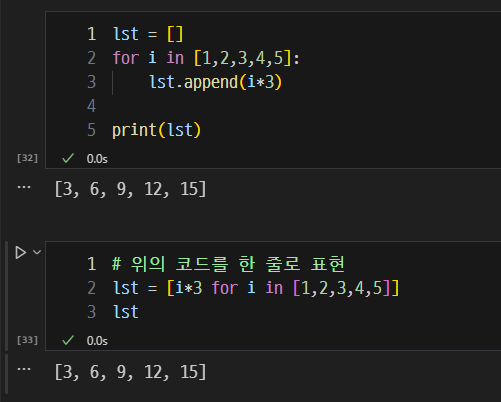
리스트 내포(list comprehension) 사용.
-
for-else 구조와 활용 사례.
- for-else 구문은 for 루프가 정상적으로 완료되었을 때 실행됩니다.
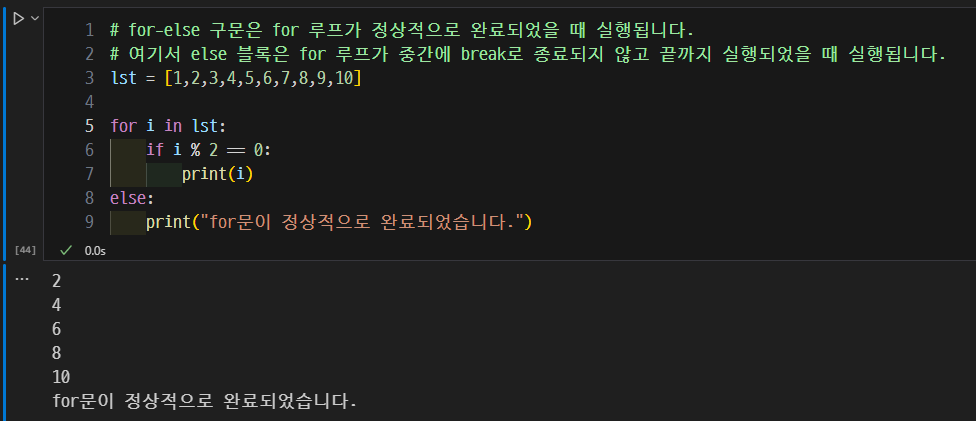
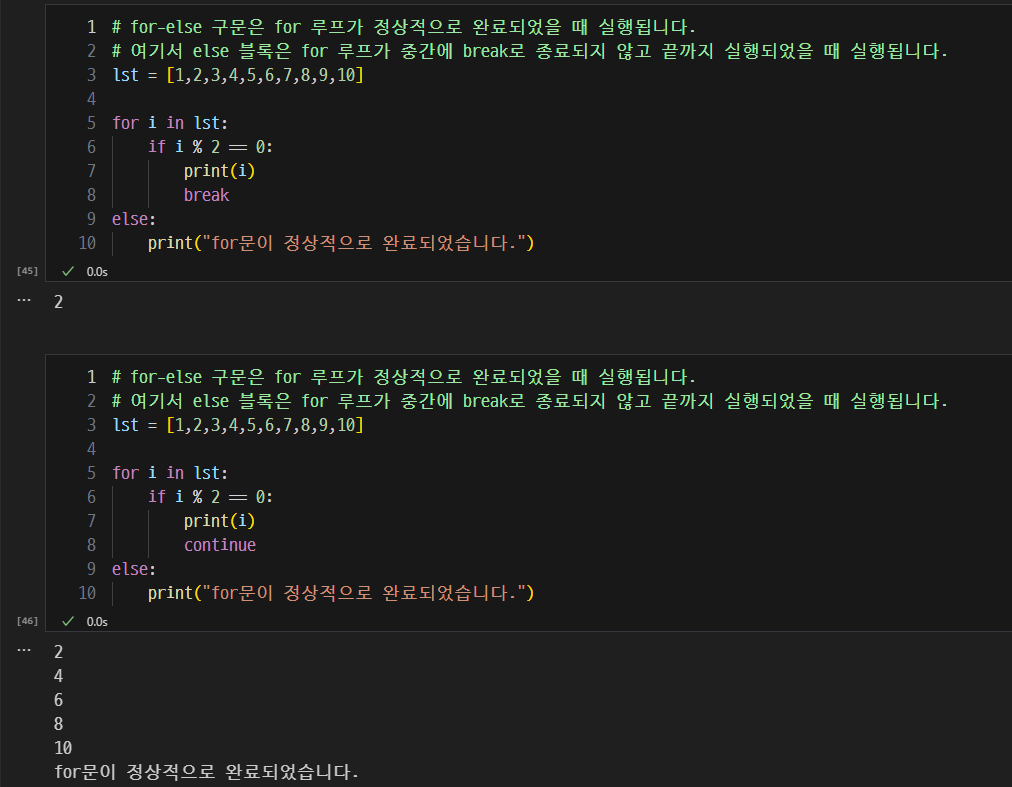
- for-else 구문은 for 루프가 정상적으로 완료되었을 때 실행됩니다.
- type() 대신 데이터 타입 확인을 위해 사용하는 함수
isinstance(변수, 타입)-> 변수가 해당 타입인지 확인
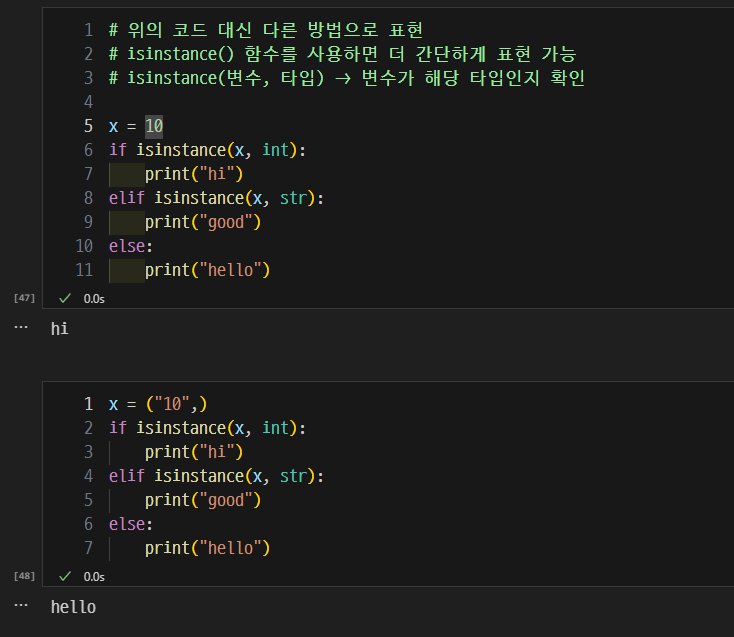
- 반복문에서 사용할 수 있는 함수들
enumerate(): 리스트의 원소를 순서대로 받아오는 함수- index와 value를 tuple로 묶어서 반환
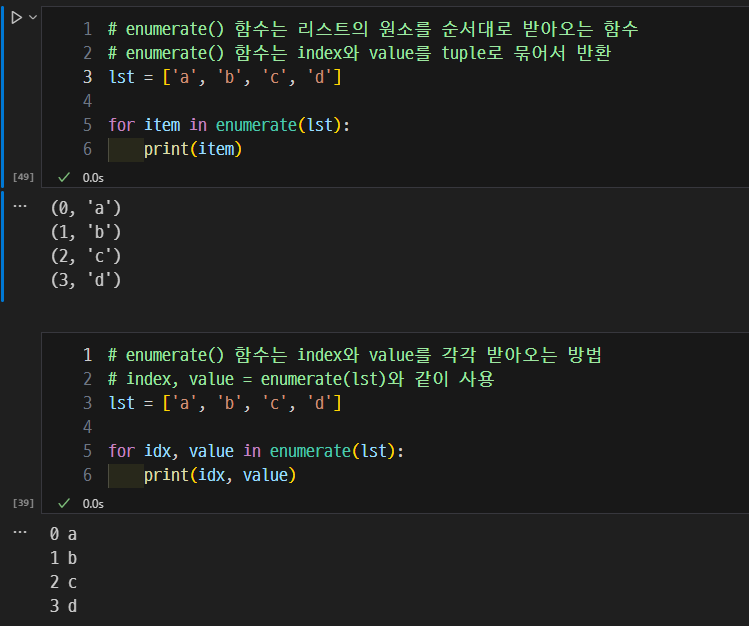
- index와 value를 tuple로 묶어서 반환
느낀 점
- 기본 자료형과 컬렉션 자료구조를 다루는 방법을 체계적으로 복습할 수 있었다.
- 코드 실행 결과를 예측하며 작성하는 습관을 길러야겠다.
부족한 점
- 함수나 메서드 사용 시 동작 원리를 이해하지 않고 결과만 확인하려는 경향이 있다.
- 문제 해결 능력을 기르기 위해 실습을 많이 해야겠다고 느꼈다.
이렇게 두 번째 회고록을 작성해 보았다. 벌써부터 매일매일 회고록을 쓰기 어렵다는 생각이 들지만, 나의 강제적인 복습 시간을 위해서라도 노력해보려 한다.
