SK네트웍스 Family AI캠프 10기 11주차 회고록 (25.03.17 ~ 25.03.21)
기간: 25.03.17 ~ 25.03.21
학습 내용 요약
※ GRU
GRU(Gated Recurrent Unit)는 순환 신경망(RNN) 모델의 한 종류로, LSTM(Long Short-Term Memory)과 유사한 성격을 가진 모델이다. GRU는 LSTM보다 더 간단한 구조로 설계되었으며, 그럼에도 불구하고 비슷한 성능을 보여준다. GRU는 기본적으로 RNN의 한계를 해결하고자 하여, 긴 시퀀스를 처리하는 데 있어서 더 효율적이고 빠른 성능을 제공한다.
GRU의 주요 특징
-
게이트(gates) 구조
GRU는 LSTM처럼 내부적으로 게이트 구조를 갖고 있다. 이 구조는 모델이 중요한 정보를 기억하고, 불필요한 정보를 잊어버리도록 도와준다. GRU는 두 가지 주요 게이트인 업데이트 게이트와 리셋 게이트를 사용한다.- 업데이트 게이트: 이전 상태를 얼마나 기억할지를 결정한다.
- 리셋 게이트: 현재 입력에 대한 기억을 얼마나 새롭게 업데이트할지를 결정한다.
-
구조가 간단함
LSTM은 세 가지 게이트(입력 게이트, 출력 게이트, 망각 게이트)를 사용하지만, GRU는 두 개의 게이트만 사용하여 모델이 더 간단하고 계산적으로 효율적이다. -
성능
GRU는 LSTM보다 더 적은 파라미터를 가지고 있지만, 비슷한 성능을 낸다. 특히 데이터가 적거나 계산 리소스가 제한된 환경에서는 GRU가 더 유리할 수 있다. -
장점
- 빠른 학습 속도
- 메모리 사용이 적고 계산 비용이 적다
- 긴 시퀀스를 처리하는 데 효과적이며, 장기 의존성 문제를 해결하는 데 도움을 준다
-
단점
- 더 복잡한 문제나 정밀한 모델링이 필요한 경우 LSTM보다 성능이 떨어질 수 있다.
GRU의 구조
- 업데이트 게이트: 이전 출력 값과 현재 입력을 바탕으로, 얼마나 많은 정보를 과거로부터 보존할지 결정한다.
- 리셋 게이트: 이전 상태의 정보를 얼마나 잊을지를 결정한다.
GRU 예시 코드
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense
model = Sequential()
model.add(GRU(128, input_shape=(100, 1))) # GRU 레이어, 100 타임스텝, 1 특성
model.add(Dense(1, activation='sigmoid')) # 출력 레이어※ AWS 예산 설정
내 프로필 선택 -> 결제 및 비용 관리 -> 왼쪽 메뉴들 중 예산 선택 -> 예산 생성 선택 -> 템플릿 사용 선택 -> 월별 비용 예산 선택 -> 예산 이름, 이메일 수신자 선택하여 생성
※ UV : 파이썬 가상환경/종속성/패키지/프로젝트 관리 툴
-
uv는 패키지 설치 및 관리부터 패키지 빌드 및 배포까지 모든 것을 처리할 수 있는 궁극의 파이썬 종속성, 패키지, 프로젝트 관리 툴이다. 기존의 pip, pip-tools, pipx, poetry, pyenv, twine, virtualenv 등 여러 도구들을 모두 대체할 수 있다.
-
Rust로 개발된 프로그램답게 uv는 매우 빠르다. 특히 이미 다운로드한 패키지들은 기본적으로 하드 링크를 사용하여 설치되므로 설치 속도가 매우 빠르며 추가적인 저장 공간도 필요하지 않다.
설치 방법
- Windows
PowerShell에서 아래 명령어를 실행 [참고 사이트]:
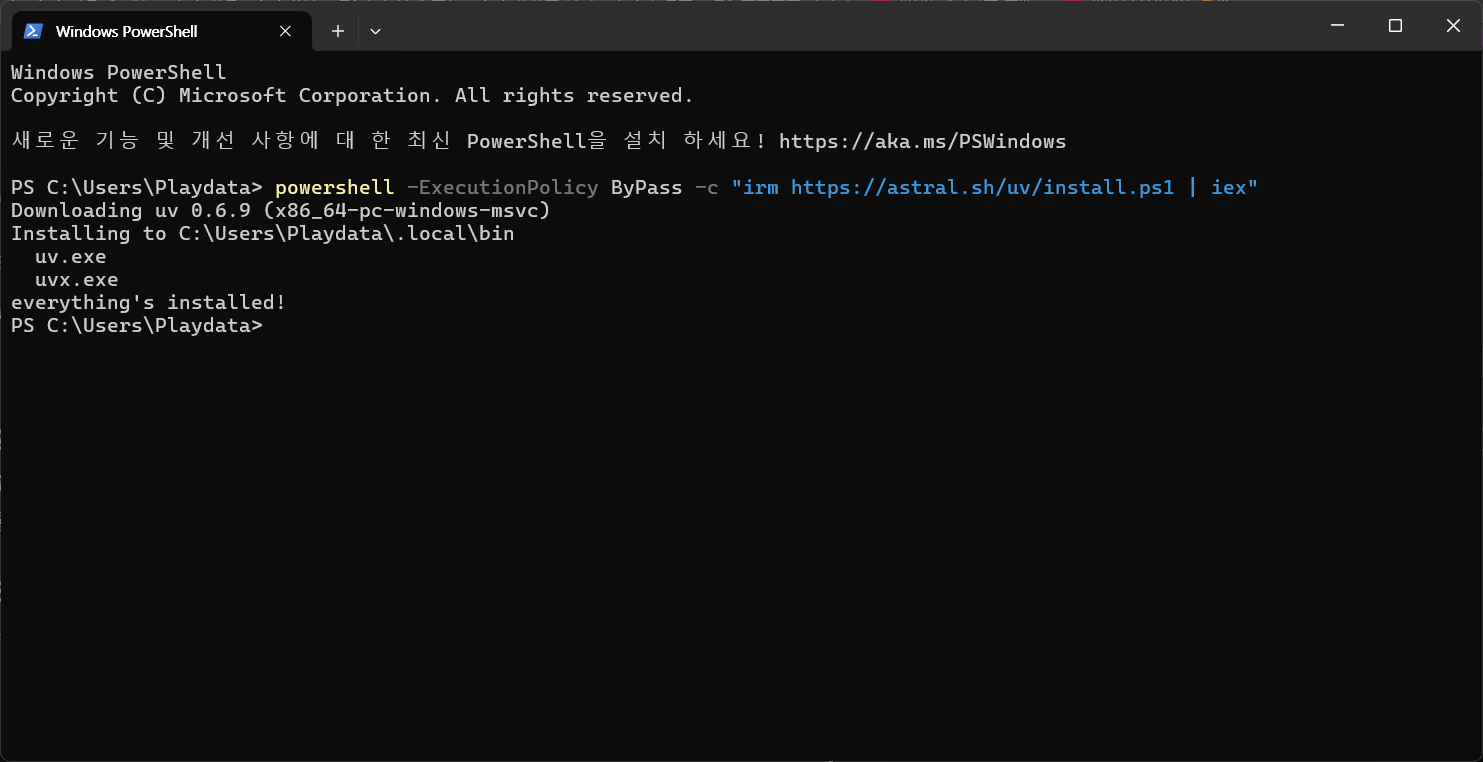
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
파이썬 설치 및 조회
- 설치된 파이썬 버전 조회
uv python list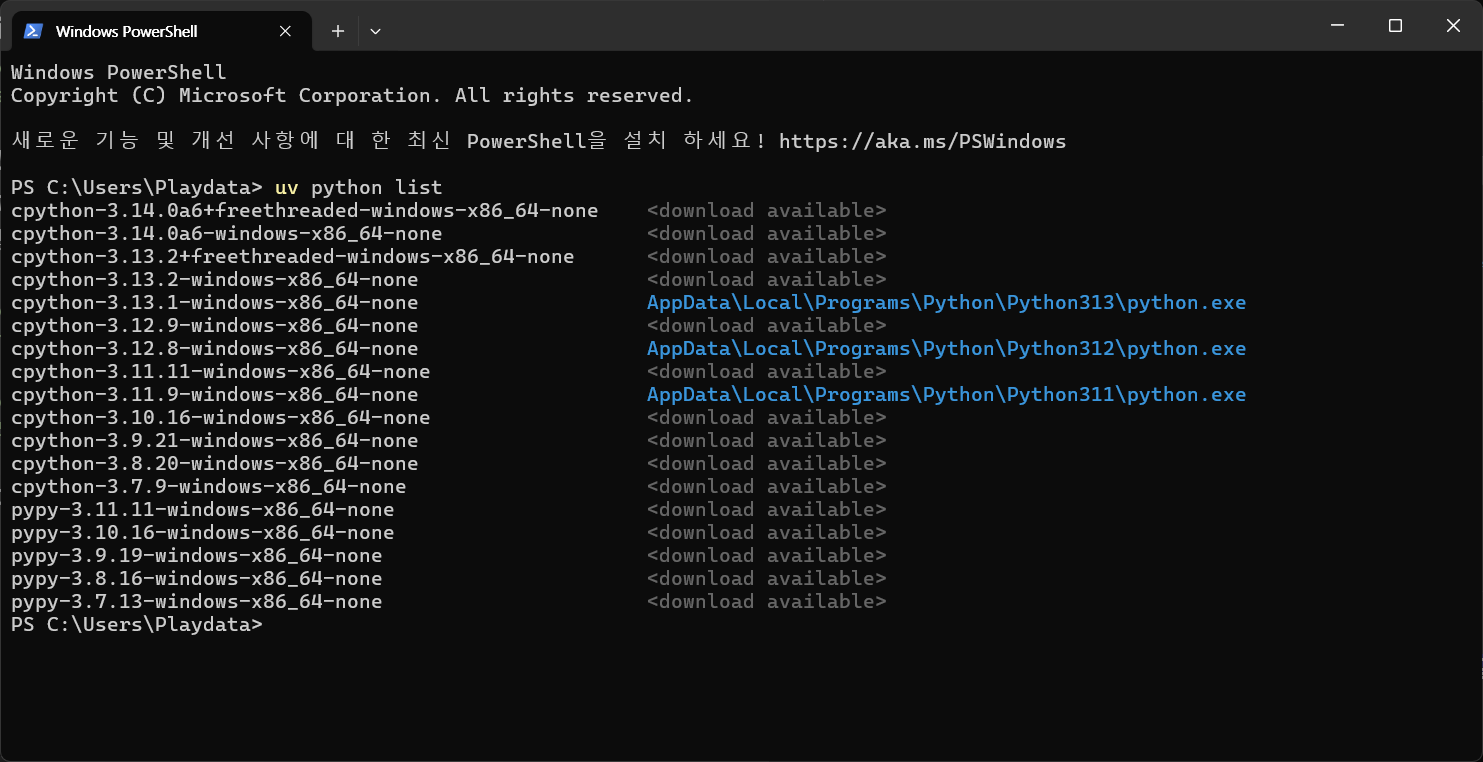
특정 파이썬 버전 설치 (예: 3.12)
uv python install 3.12가상환경
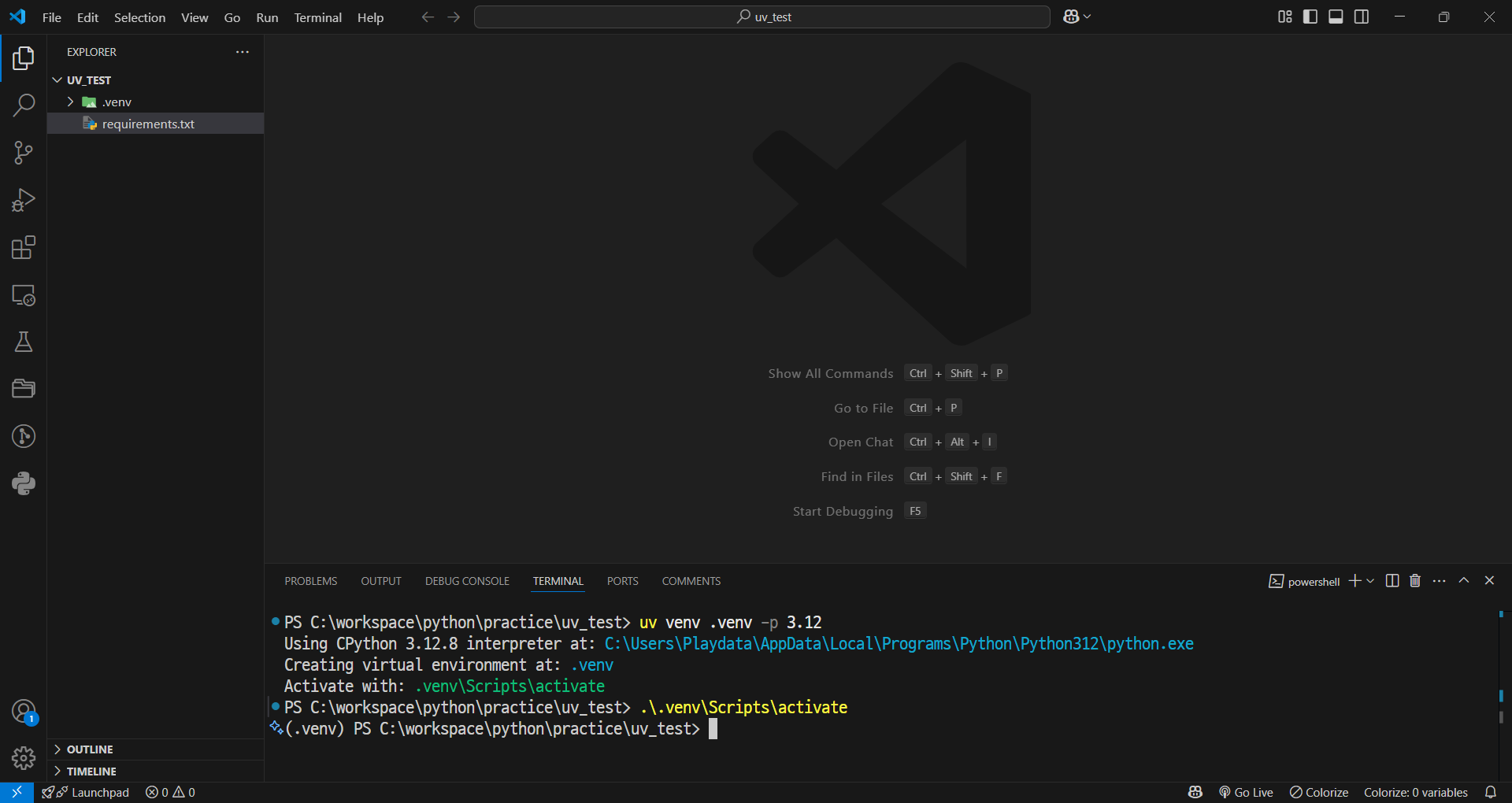
- 가상환경 생성
uv venv .venv -p 3.12- 가상환경 접속 (Windows)
.venv\Scripts\activate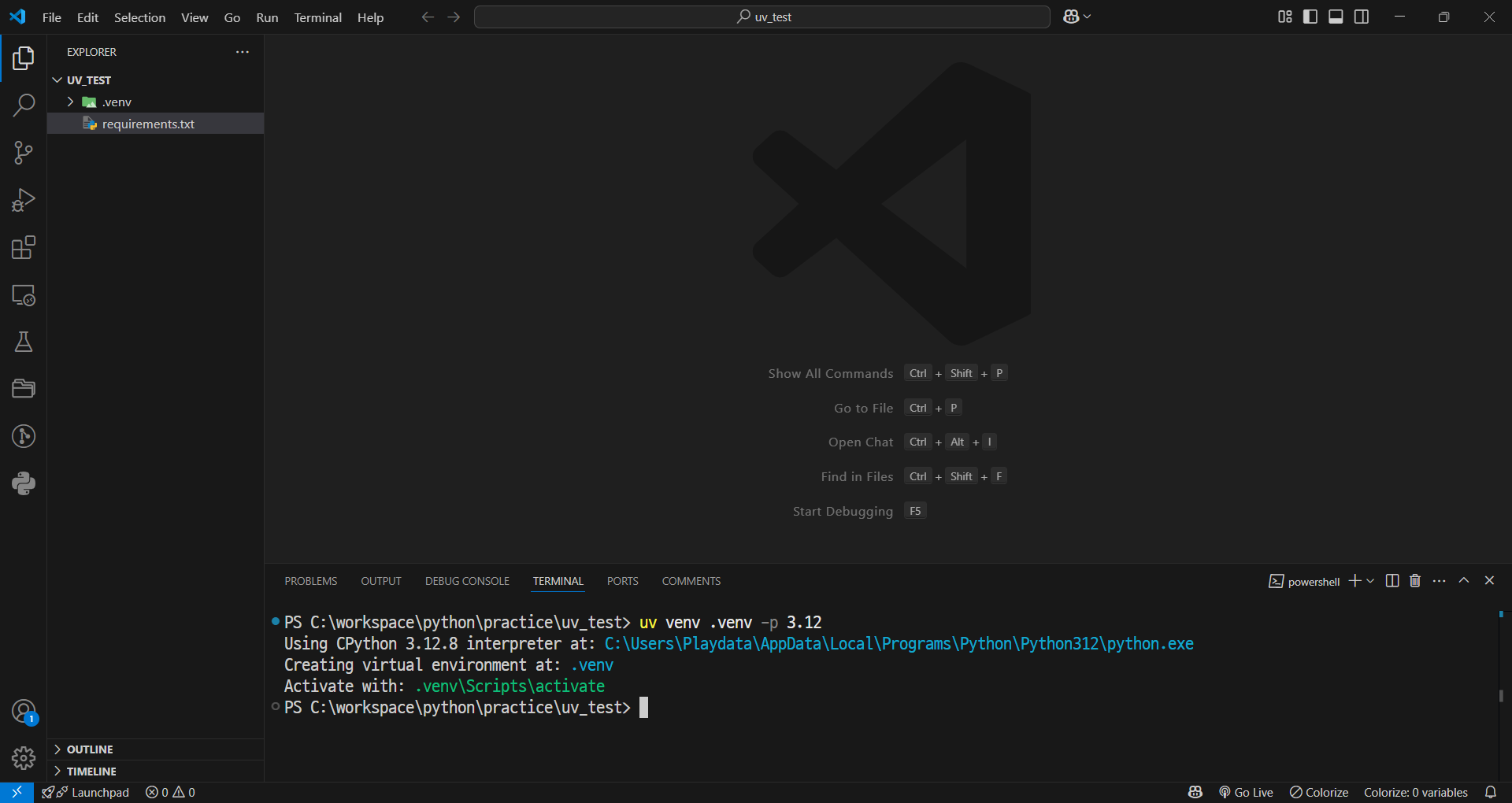
가상환경 활성화
- 의존성 라이브러리 설치
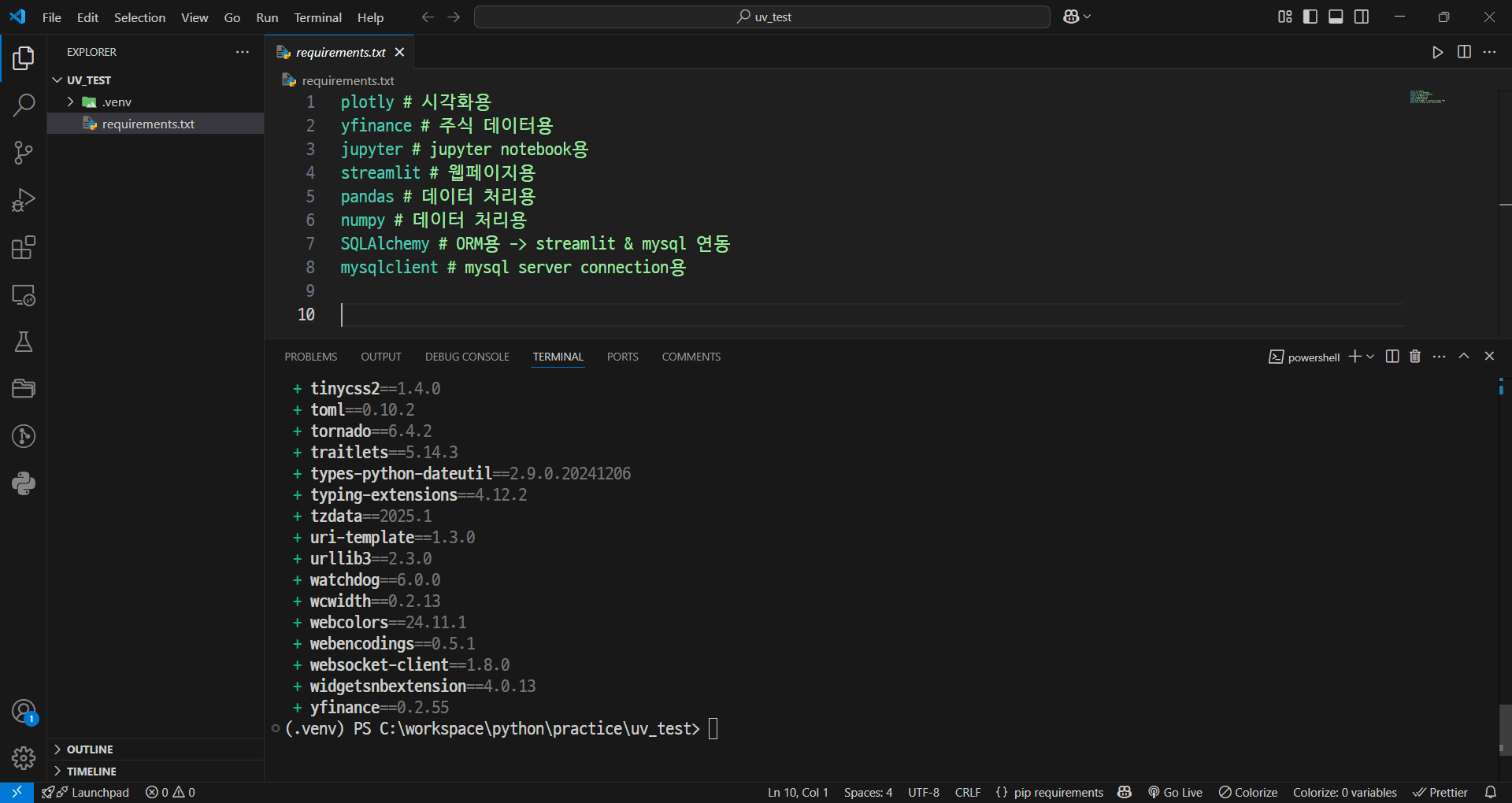
uv pip install -r requirements.txt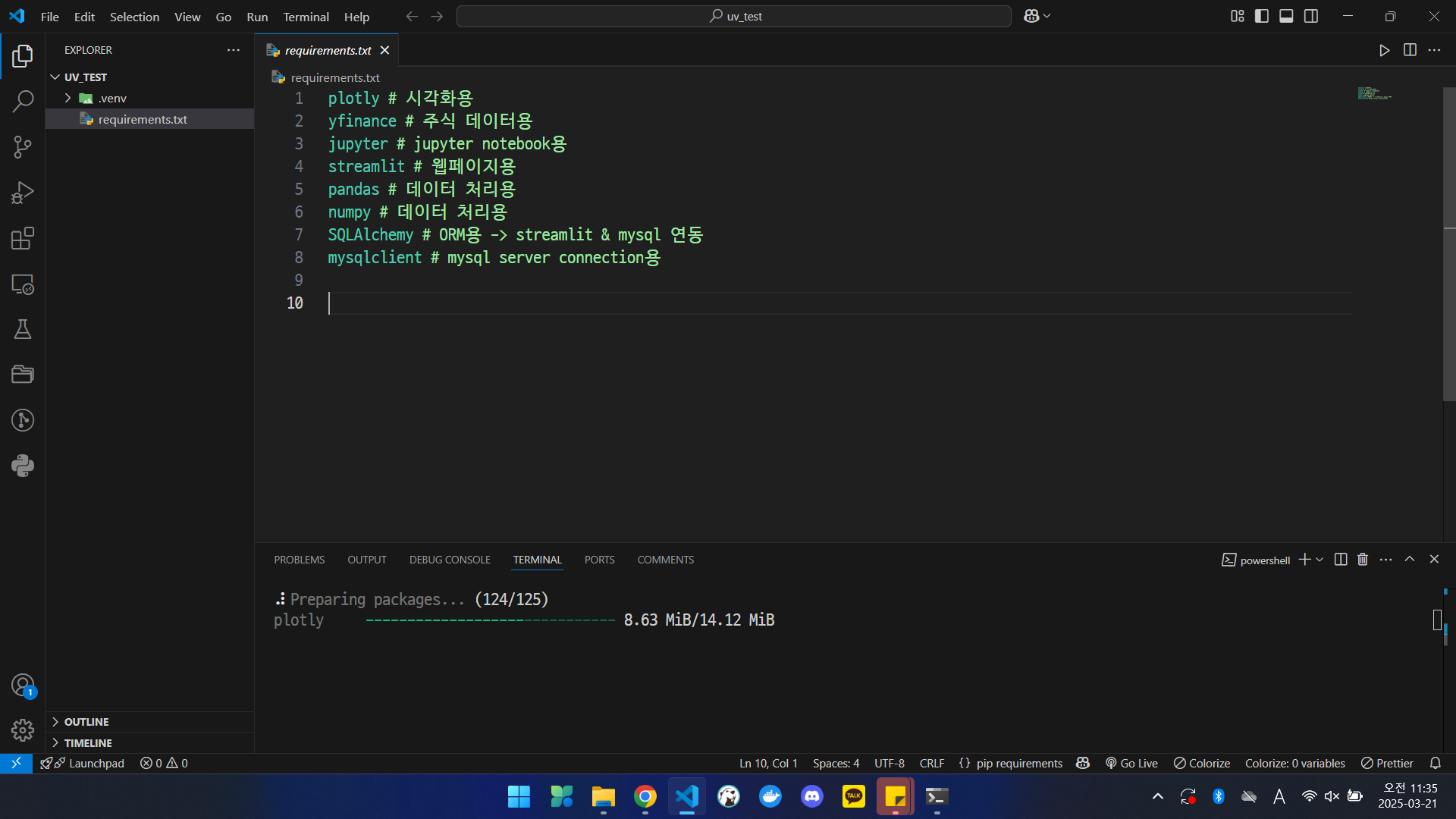
- 설치 완료
- 기존 가상환경과 같은 방식인 pip로 모듈 설치
uv pip install jupyter pandas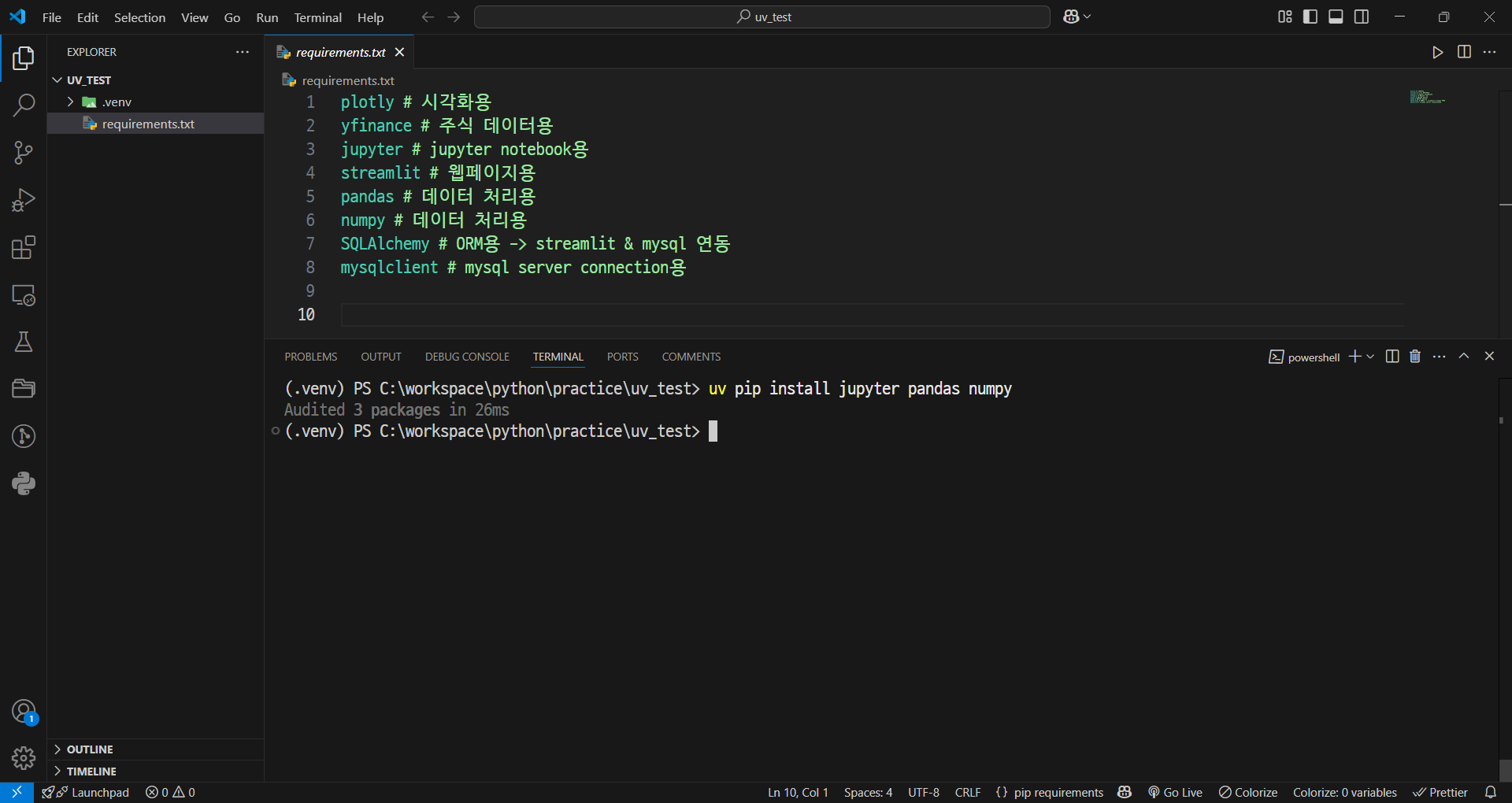
※ Large Language Model (LLM)
OpenAI API를 활용하여 간단한 챗봇 만들기
- 스트림 모드로 챗본 생성
import streamlit as st
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
st.title("Chatbot")
# OpenAI 객체 생성
client = OpenAI()
model = "gpt-4o-mini"
prompt = st.chat_input("입력해주세요.")
if prompt:
messages = [
{"role": "system", "content": "당신은 AI 개발자입니다."},
{"role": "user", "content": prompt}
]
# 사용자 입력 출력
st.write(f"사용자: {prompt}")
# OpenAI API 호출
completion = client.chat.completions.create(
model=model,
messages=messages,
stream=True, # 스트림 모드 활성화
)
# 실시간 답변을 위한 빈 공간 설정
final_answer = ""
answer_placeholder = st.empty()
# 스트림 모드에서는 completion.choices 를 반복문으로 순회
for chunk in completion:
# chunk 를 저장
chunk_content = chunk.choices[0].delta.content
# chunk 가 문자열이면 final_answer 에 추가
if isinstance(chunk_content, str):
final_answer += chunk_content
# 실시간으로 답변 이어서 출력
answer_placeholder.text(f"chatbot : {final_answer}") # 텍스트를 동적으로 업데이트
트러블 슈팅
- Embedding Layer
자연어 처리(NLP)에서는 Embedding Layer가 주로 모델의 첫 번째 레이어로 사용된다. 그 이유는 자연어 데이터를 처리할 때, 텍스트는 숫자가 아닌 단어의 시퀀스 형태로 되어 있기 때문에, 텍스트 데이터를 숫자로 변환해야 한다. Embedding Layer는 각 단어를 고차원 벡터 공간에 매핑하여, 단어의 의미를 포착할 수 있는 방식으로 변환한다.
따라서 일반적으로 순차적인 신경망 모델을 설계할 때, 텍스트 입력을 처리하려면 Embedding Layer가 첫 번째 레이어로 배치된다. 그 이후에 RNN, LSTM, GRU, Transformer 등의 레이어가 나온다.
예를 들어:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
model = Sequential()
# Embedding Layer가 먼저 오고, 그 뒤로 LSTM 레이어가 옵니다
model.add(Embedding(input_dim=10000, output_dim=128, input_length=100)) # Embedding Layer
model.add(LSTM(128)) # LSTM 레이어
model.add(Dense(1, activation='sigmoid')) # 출력 레이어Embedding Layer는 텍스트 데이터를 벡터 형태로 변환하는 중요한 역할을 하기 때문에, 일반적으로 모델의 첫 번째 레이어로 배치되는 것이 맞다.
네, Embedding Layer의 입력은 정수형이어야 한다. 그 이유는 Embedding Layer가 각 정수(주로 단어의 인덱스)에 대해 고차원 벡터를 매핑하는 방식으로 작동하기 때문이다. 각 단어를 고유한 정수로 변환한 후, 이 정수들을 Embedding Layer에 입력으로 넣으면, Embedding Layer가 해당 정수에 대응하는 벡터를 반환한다.
Embedding Layer 입력 과정
- 정수로 변환된 단어 인덱스: 텍스트 데이터는 단어 집합(vocabulary)을 기반으로 각 단어를 고유한 정수로 변환해야 한다. 예를 들어,
["apple", "banana", "cherry"]라는 단어 집합이 있다면, 이를[1, 2, 3]과 같은 정수 시퀀스로 변환할 수 있다. - Embedding Layer: 이 정수 인덱스를 입력으로 받아, 각 정수에 해당하는 고차원 벡터를 반환한다.
예시
from tensorflow.keras.layers import Embedding
# 단어 집합 크기: 10000, 임베딩 차원: 128
embedding_layer = Embedding(input_dim=10000, output_dim=128, input_length=10)
# 정수형 시퀀스를 입력으로 넣음
input_data = [[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]] # 정수 인덱스 시퀀스
output = embedding_layer(input_data)
print(output.shape) # (1, 10, 128) -> (배치 크기, 시퀀스 길이, 임베딩 차원)위 예시에서 input_data는 정수로 변환된 시퀀스이고, Embedding Layer는 각 정수 인덱스를 128차원 벡터로 변환한다.
따라서 Embedding Layer의 입력은 반드시 정수형이어야 하며, 이 정수는 모델 학습 전에 단어 인덱스(예: 토큰화 및 벡터화 과정)를 통해 얻어야 한다.
- .view(1, -1)
- view() 함수는 PyTorch에서 텐서의 크기를 바꿀 때 사용된다.
- view(1, -1)은 텐서의 크기를 변경하는데, -1은 자동으로 그 차원의 크기를 계산하도록 지정한다. 즉, encoded의 길이가 15라면, view(1, -1)은 (1, 15) 형태로 텐서를 변환한다.
- 여기서 1은 배치 차원을 추가하는 것이다.
- 배치 차원(batch dimension)은 모델에 입력을 제공할 때 여러 개의 샘플을 한 번에 처리하기 위한 차원이다.
- 만약 하나의 샘플만 처리하는 경우에도 view(1, -1)을 사용하여 크기를 (1, 15)로 설정하여 배치 차원을 추가한다. 이로 인해 모델은 하나의 샘플을 처리하는 경우에도 일관된 차원을 유지하게 된다.
KPT 회고 (11주차)
Keep (계속 유지할 점)
- 지금처럼 주에 2~3회 운동을 하자.
- 분명 힘들겠지만, 버티며 하루하루를 의미있게 보내려 노력하자.
Problem (개선이 필요한 점)
- 데이콘 사이트를 통해 공부를 진행하는 시간을 늘려, 앞으로의 LLM 학습에 있어, 기본 개념 및 복습을 진행해야겠다.
- 딥러닝 코드를 이해하는 시간이 추가적으로 필요하다고 생각한다.
- 코드를 분석하는 능력을 길러야겠다.
Try (앞으로 시도할 것)
- 어제보다 더 나은 생활을 하려고 노력할 것이다.
- 데이콘 사이트를 꾸준히 활용하여 복습에 활용하여 코드를 분석하는 능력을 향상시킬 것이다.
- 쉴 때는 휴대폰을 하거나, 컴퓨터를 만지며 쉬는 것이 아니라 오로지 나의 피로도 회복을 위해 잠을 자거나, 전자기기를 멀리하는 생활을 하겠다. 하루 30분이라도
마무리
-
이번 주는 GRU, LSTM과 같은 모델들에 대해 학습했으며 텍스트를 이미지로, 이미지를 텍스트로 변환하는 과정에 대해 학습했다.
-
또한, 파이썬 패키지 관리 도구인 UV에 대해서도 실습을 통해 설치와 환경 설정 방법을 익혔다. UV는 기존의 가상환경에서 모듈을 설치하고 활용하는 코드 자체에는 큰 변화가 없기에 사용하기 편했고, 병렬로 처리가 되기 때문에 속도 또한, 빨라서 좋았다.
-
다만, GRU와 같은 딥러닝 모델을 설계하고 최적화하는 데 시간이 걸렸고, 개념을 완전히 이해하는 데 어려움이 있었다. 이에 따라 코드 구현과 관련된 부분을 좀 더 연습하고, 자연어 처리 및 딥러닝 관련 개념을 체계적으로 복습해야겠다고 느꼈다.
-
또한, 데이콘 사이트를 활용하여 딥러닝 모델에 대한 복습과 코드를 분석하는 능력을 향상시키고, 그 과정에서 새로운 학습 자료를 통해 더 깊이 있는 학습을 진행할 계획이다.
-
공부 외에도 휴식의 중요성을 느끼며, 잠을 자거나 전자기기를 멀리하는 방식으로 피로도를 회복하는 시간이 필요하겠다는 생각을 했다.
