SK네트웍스 Family AI캠프 10기 5주차 회고록 (25.02.10 ~ 25.02.14)
기간: 25.02.10 ~ 25.02.14
본격적인 회고록 작성에 앞선 나의 이야기
이번주는 어떠했지?
- 몸 컨디션을 많이 회복해서 운동도 다니고, 스터디도 진행했으며 계획했던 공부들을 진행했다.
- 머신러닝 경진대회 순위권을 해보고 싶어서 시간이 있을 때마다 모델을 훈련, 검증 테스트하는 과정을 시도하고 실험하며 코드에 대한 해석을 하였다.
- 토익 공부는 머신러닝 경진대회에 집중하다 보니 만족스러울 만큼 공부를 하지는 못했다.
나의 계획
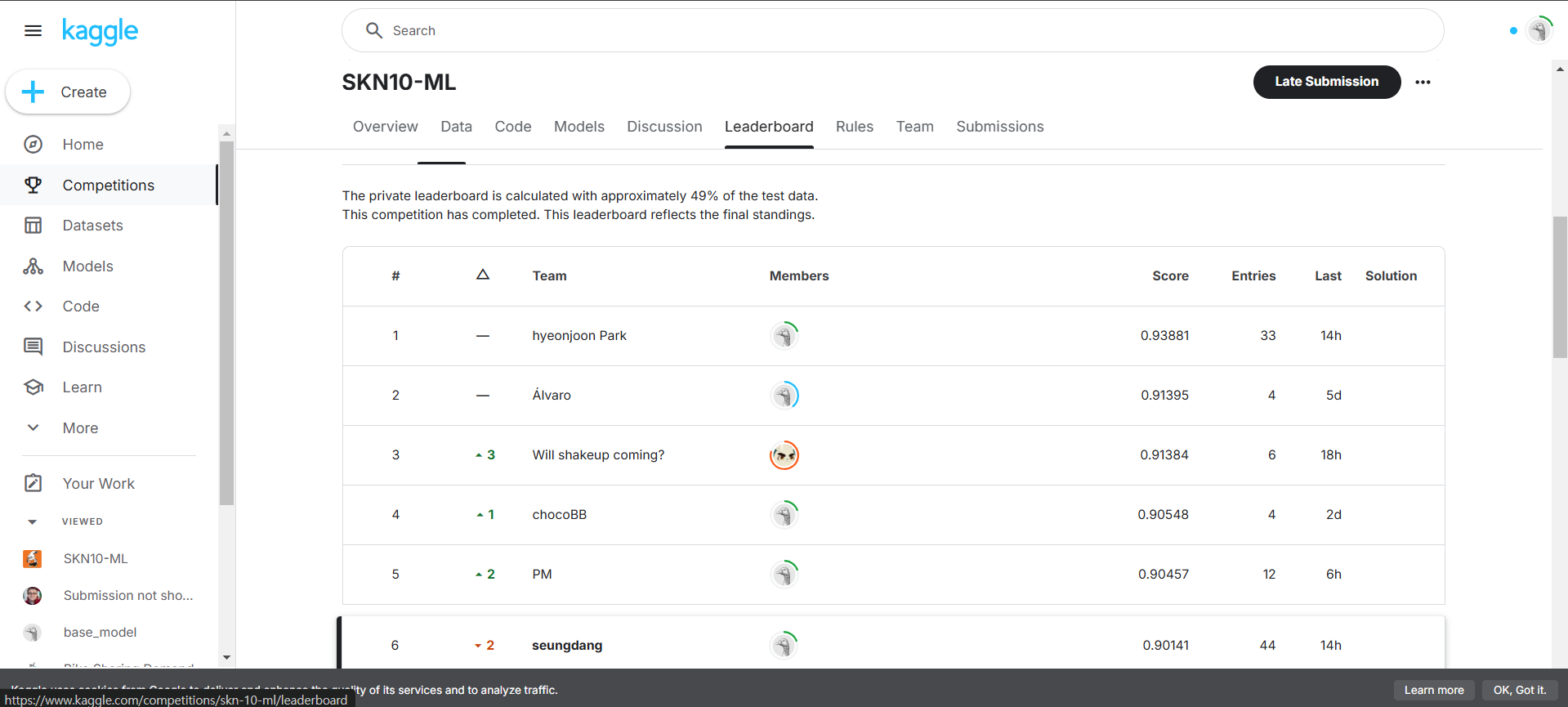
- 이번 주 머신러닝 경진대회에 3위 안에 들지는 못했으나 6위라는 순위권에 들어가서 만족스러운 결과로 마무리 했으니, 데이콘 사이트에 있는 대회를 이것저것 시도하며 앞으로의 딥러닝 학습과 지금까지의 머신러닝 학습에 도움이 되도록 할 생각이다.
- 데이콘 대회에서 매일 1개씩이라도 제출하는 것을 목표로 하고 있으며 그 과정에서 EDA를 하고, 분석을 하며 추가적인 인사이트를 얻는 것을 목표로 하고 있다.
- 앞으로도 주 3회 운동과 주 2회 토익 공부를 진행하겠다.
이번 주에 한 활동들
머신러닝 경진대회
- 데이터 전처리 과정을 진행했고, 충분하다 생각하여 모델을 바꿔가며 학습, 검증, 테스트 및 제출을 진행했다.
- 생각보다 ROC-AUC 점수가 금방 높이지지 않는다는 것을 느꼈다.
- 머신러닝 프로세스를 다시 이해하고 수정을 진행했으나 점수를 올리기까지 시간이 좀 걸리기 때문에 하루 이틀 남은 시간으로는 3위 안에 들 수 없었다.
나의 경진대회 머신러닝 코드 분석
1. 데이터 로드 및 환경 설정
먼저 필요한 라이브러리를 설치하고 가져온 후, Google Drive를 연결하여 데이터를 불러왔다.
import os
import random
import pytz
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import koreanize_matplotlib
import lightgbm as lgb
import torch
from tqdm import tqdm
from datetime import datetime
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_curve, auc, confusion_matrix
from imblearn.over_sampling import SMOTE
from google.colab import drive
drive.mount('/content/drive')또한, 재현성을 확보하기 위해 난수 시드를 설정하였다.
def reset_seeds(seed=42):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True2. 데이터 로드 및 기본 분석
타이타닉 데이터셋을 불러온 후 기본적인 정보를 확인하였다.
ori_train = pd.read_csv("train.csv")
ori_test = pd.read_csv("test.csv")
default_submission = pd.read_csv("submission.csv")데이터의 구조를 확인한 결과, survived 열은 train.csv에만 존재하였으며, test.csv에는 포함되지 않았다.
3. 데이터 전처리
3.1 결측값 처리
age,fare의 결측값은 같은pclass와gender그룹 내 평균으로 대체embarked는 최빈값(mode)으로 대체cabin값이 있는지 여부를 새로운 컬럼has_cabin으로 생성
train['age'].fillna(train.groupby(['pclass', 'gender'])['age'].transform('mean'), inplace=True)
test['age'].fillna(test.groupby(['pclass', 'gender'])['age'].transform('mean'), inplace=True)
ori_te['age'].fillna(ori_te.groupby(['pclass', 'gender'])['age'].transform('mean'), inplace=True)
train['embarked'].fillna(train['embarked'].mode()[0], inplace=True)
test['embarked'].fillna(test['embarked'].mode()[0], inplace=True)
ori_te['embarked'].fillna(ori_te['embarked'].mode()[0], inplace=True)3.2 새로운 특성 생성
새로운 특성을 추가하는 경우, train, test, ori_te 데이터셋 모두에 동일한 방식으로 반영하였다.
- 객실 등급별 평균 나이 및 요금
for df in [train, test, ori_te]:
df['avg_age_by_pclass'] = df.groupby('pclass')['age'].transform('mean')
df['avg_fare_by_pclass'] = df.groupby('pclass')['fare'].transform('mean')- 가족 수 계산
for df in [train, test, ori_te]:
df['family_size'] = df['sibsp'] + df['parch'] + 1
df['is_alone'] = (df['family_size'] == 1).astype(int)- 유아 여부 추가
for df in [train, test, ori_te]:
df['infant'] = (df['age'] < 5).astype(int)- 카테고리형 변수 조합
for df in [train, test, ori_te]:
df['gender_infant'] = df['gender'] + '_' + df['infant'].astype(str)
df['gender_pclass'] = df['gender'] + '_' + df['pclass'].astype(str)4. 모델 학습 및 평가
4.1 모델 성능 평가
reset_seeds()
# Light GBM 모델 평가
score_tr_lgb = model_lgb_V10.score(X_tr_scaled, y_tr)
score_te_lgb = model_lgb_V10.score(X_te_scaled, y_te)
print(f'{model_lgb_V10} : {score_tr_lgb}, {score_te_lgb}')
# AUC 점수 평가
y_pred = model_lgb_V10.predict_proba(X_te_scaled)[:,1]
fpr, tpr, thresholds = roc_curve(y_te, y_pred)
auc_te = auc(fpr, tpr)
print(f'{model_lgb_V10}: {auc_te}')
# 혼동 행렬 시각화
y_pred_class = model_lgb_V10.predict(X_te_scaled)
norm_conf_mx = confusion_matrix(y_te, y_pred_class, normalize="true")
plt.figure(figsize=(7, 5))
sns.heatmap(norm_conf_mx, annot=True, cmap="coolwarm", linewidth=0.5, fmt=".2f")
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix (Normalized)')
plt.show()4.2 Public과 Private 점수 차이를 최소화하는 모델 선택
df_results = pd.DataFrame(args.results).assign(
score_diff=lambda df: abs(df['score_tr'] - df['score_te']),
auc_diff=lambda df: abs(df['score_te'] - df['auc_te']),
total_diff=lambda df: abs(df['score_tr'] - df['score_te']) + abs(df['score_te'] - df['auc_te'])
).sort_values(by=['total_diff', 'auc_te'], ascending=[True, False])
df_results이 방법을 활용하여 가장 일반화 성능이 좋은 모델을 최종적으로 선택하였다.
경진대회 결과
발생했던 문제들 및 트러블 슈팅
1. 결측치 처리 오류 발생
- 결측치를 처리했다고 생각했으나, 그룹화(
groupby)를 진행하는 과정에서 기준 컬럼에 결측치가 존재하여 처리가 완벽하게 이루어지지 않았다.
문제 상황
# pclass와 gender로 그룹화하여 그룹별 평균값으로 결측치 대체
age_mean = train.groupby(['pclass', 'gender'])['age'].transform(lambda x: x.fillna(x.mean()))
fare_mean = train.groupby(['pclass', 'gender'])['fare'].transform(lambda x: x.fillna(x.mean()))
# embarked와 cabin에 대해 mode()를 사용하는 이유는 두 열이 범주형 데이터이기 때문
embarked_mode = train['embarked'].mode().values[0]
enc_tr.isnull().sum().sum(), enc_te.isnull().sum().sum(), enc_ori_te.isnull().sum().sum()- 위의 코드 실행 결과
(0, 0, 0)이 되어야 하지만, 일부 결측치가 여전히 존재했다. age와fare컬럼의 결측치를 그룹별 평균값으로 채우는 과정에서 그룹화 기준 컬럼 자체(pclass,gender)에 결측치가 있는 경우, 대체가 제대로 이루어지지 않았다.
해결 방법
- 그룹별 평균으로 대체한 후에도 결측치가 남아있는 경우, 전체 평균값으로 추가 대체를 진행했다.
# 그룹별 평균으로 결측치 대체 후에도 남아있는 경우, 전체 평균값으로 대체
age_mean = train.groupby(['pclass', 'gender'])['age'].transform(lambda x: x.fillna(x.mean()))
age_overall_mean = train['age'].mean()
fare_mean = train.groupby(['pclass', 'gender'])['fare'].transform(lambda x: x.fillna(x.mean()))
fare_overall_mean = train['fare'].mean()
# embarked는 최빈값으로 대체
embarked_mode = train['embarked'].mode().values[0]
enc_tr.isnull().sum().sum(), enc_te.isnull().sum().sum(), enc_ori_te.isnull().sum().sum()- 위 방식 적용 후
(0, 0, 0)으로 결측치가 완전히 제거되었다.
2. 원핫 인코딩(One-Hot Encoding) 적용 여부 판단
- 데이터셋에서 원핫 인코딩을 적용하면 특성이 많아지기 때문에, 희소 행렬(Sparse Representation) 문제가 발생할 수 있다고 생각했다.
- 하지만 강사의 피드백을 통해 단순히 특성 개수만 보는 것이 아니라 데이터 샘플 수 대비 특성 수의 비율을 고려해야 한다는 점을 알게 되었다.
문제 상황
ori_train = pd.read_csv(args.train_csv)
ori_test = pd.read_csv(args.test_csv)
default_submission = pd.read_csv(args.default_submission)
ori_train.shape, ori_test.shape, default_submission.shapetrain.csv데이터가(916, 12)인 경우, 원핫 인코딩을 하면 80개 이상의 특성이 생성된다.- 초기에는 특성 수가 많아져 과적합이 발생할 가능성이 있다고 판단했지만, 데이터 샘플 대비 특성 수 비율이 더 중요한 요소라는 점을 깨달았다.
해결 방법 및 결론
- 916개의 샘플에서 80개 특성은 샘플 대비 특성이 많지 않음 (약 11:1 비율)
- 따라서, 원핫 인코딩을 적용해도 문제되지 않을 가능성이 크다.
- 다만, 300개 이상의 특성이 생성될 경우 과적합 가능성이 커지므로, 아래의 방법을 고려할 필요가 있다.
대안적인 인코딩 기법
1) 빈도 기반 인코딩(Frequency Encoding)
- 범주형 값을 해당 값의 등장 빈도로 변환
- 예:
'A' → 100,'B' → 50,'C' → 10
2) 타겟 인코딩(Target Encoding)
- 특정 카테고리의 목표 변수(예: 생존률) 평균값을 사용
- 예:
"A" 그룹의 생존률이 0.8→"A": 0.8
3) 임베딩(Embedding) 활용
- 신경망을 이용해 범주형 변수를 연속적인 벡터로 변환
- 대규모 데이터셋에서 유용함
결론
- 현재 데이터에서는 원핫 인코딩을 사용해도 괜찮다.
- 다만, 특성이 300개 이상 증가하면 빈도 인코딩 또는 타겟 인코딩을 고려해야 한다.
3. 머신러닝 경진대회 성능 평가 및 최적화
문제 상황
- 모델의 성능을 평가할 때, Public Score(공개 점수)와 Private Score(비공개 점수)의 차이가 컸다.
- 즉, 특정 모델이 Public Score에서 높은 점수를 얻었지만, Private Score에서는 낮은 점수를 기록하는 문제가 발생했다.
해결 방법
- 모델의 일반화 성능을 고려하여 최적의 모델을 선택했다.
- Public과 Private 점수 차이를 최소화하는 모델을 선택하도록
score_diff와auc_diff를 계산하여 비교했다.
df_results = pd.DataFrame(args.results).assign(
score_diff=lambda df: abs(df['score_tr'] - df['score_te']),
auc_diff=lambda df: abs(df['score_te'] - df['auc_te']),
total_diff=lambda df: abs(df['score_tr'] - df['score_te']) + abs(df['score_te'] - df['auc_te'])
).sort_values(by=['total_diff', 'auc_te'], ascending=[True, False])
df_resultstotal_diff값이 가장 작은 모델을 선택하여 최종 제출 모델로 결정했다.- 일반화 성능을 고려하는 방향으로 모델을 선택함으로써 과적합 문제를 방지하고 점수 차이를 최소화했다.
4. 머신러닝 학습 과정 시각화 필요성
- AI 경진대회 및 이력서 작성 시 그래프를 활용한 모델 성능 개선 과정을 시각적으로 표현하는 것이 중요하다고 느꼈다.
- 특히, 모델을 개선할 때 어떤 변화가 있었는지 기록하는 것이 필요하다.
해결 방법 및 적용 방안
import matplotlib.pyplot as plt
# 예제 데이터
experiments = ['Base Model', 'Feature Engineering', 'Hyperparameter Tuning', 'Final Model']
scores = [0.78, 0.82, 0.85, 0.87]
plt.figure(figsize=(8, 5))
plt.plot(experiments, scores, marker='o', linestyle='-')
plt.xlabel('Experiment Steps')
plt.ylabel('Model Score')
plt.title('Model Improvement Over Experiments')
plt.grid(True)
plt.show()- 각 모델 개선 과정에서 점수가 어떻게 변했는지 그래프화했다.
- 어떤 기법이 성능 향상에 기여했는지 추적 가능하게 했다.
- 이후 이력서 및 포트폴리오 작성 시 활용할 예정이다.
5. 머신러닝에서 차원 개념 부족
- 머신러닝 및 딥러닝을 학습하면서 스칼라(Scalar), 벡터(Vector), 행렬(Matrix) 등의 개념 부족으로 이해가 어려웠다.
해결 방법 및 학습 계획
import numpy as np
# 벡터 (1차원)
vector = np.array([1, 2, 3])
print(vector.shape) # (3,)
# 행렬 (2차원)
matrix = np.array([[1, 2], [3, 4]])
print(matrix.shape) # (2,2)- 차원 개념을 코드로 직접 연습하며 이해도를 높이는 방향으로 학습할 계획이다.
KPT 회고 (6주차)
Keep: 현재 만족하고 있는 부분, 계속 이어갔으면 하는 부분Problem: 불편하게 느끼는 부분, 개선이 필요하다고 생각되는 부분Try: Problem에 대한 해결책, 실행 가능한 것
Keep
-
머신러닝 경진대회에 적극적으로 참여하면서 실전 경험을 쌓았다.
- 데이터 전처리, 모델 변경, 하이퍼파라미터 튜닝 등을 시도하며 머신러닝 실력을 키웠다.
- 단순히 점수를 올리는 것뿐만 아니라 모델의 일반화 성능을 고려하는 방법까지 배울 수 있었다.
-
꾸준한 학습 습관을 유지하고 있다.
- 매일 머신러닝 모델을 개선하며 실험하고 분석하는 과정을 반복했다.
- 토익 공부와 운동도 일정대로 진행하면서 균형 잡힌 생활을 유지했다.
-
코드 분석 능력을 키우기 위해 노력했다.
- 단순히 코드를 실행하는 것이 아니라, 각 코드의 의미를 파악하고 개선점을 찾아가는 과정이 의미 있었다.
- ChatGPT와 구글링을 활용하여 다양한 접근 방식을 학습했다.
Problem
-
머신러닝 모델 성능 개선에 많은 시간을 투자하면서 토익 공부 시간이 부족했다.
- 토익도 일정 목표를 가지고 있었지만, 머신러닝 대회에 집중하다 보니 계획했던 만큼 공부하지 못했다.
- 시간 배분을 좀 더 효율적으로 할 필요가 있다.
-
머신러닝 개념 중 수학적인 이해가 부족한 부분이 있었다.
- 선형대수, 확률 및 통계 개념이 부족하여 일부 개념을 직관적으로만 이해하고 넘어갔다.
- 특히 차원(스칼라, 벡터, 행렬) 관련 연산에서 직관적으로 이해하지 못한 부분이 있었다.
-
머신러닝 경진대회에서 상위권을 목표로 했으나, 최종적으로 6위에 머물렀다.
- 목표했던 3위 안에 들지 못한 것이 아쉬웠다.
- 모델을 개선하는 데 시간이 부족했고, 하이퍼파라미터 튜닝 과정에서 더 다양한 시도를 하지 못했다.
Try
-
토익 공부 시간을 좀 더 체계적으로 배분하겠다.
- 머신러닝 대회에 집중하느라 소홀했던 토익 공부 시간을 다시 일정에 맞춰 균형 있게 진행할 것이다.
- 매주 최소 두 번은 확실히 공부 시간을 확보할 계획이다.
-
머신러닝 모델 개선 전략을 좀 더 체계적이고, 구체적으로 세우겠다.
- 단순히 모델을 변경하는 것뿐만 아니라, 성능 개선 과정을 문서화하여 어떤 방법이 효과적인지 기록하고 분석할 것이다.
- 각 실험 결과를 그래프화하여 성능 변화를 확인할 계획이다.
마무리
- 이번 주도 여러 가지 시도와 활동들을 했고, 그 과정에서 배운 점도 많았다. 아직 부족한 부분들이 많은만큼 최선을 다해 맡은 일에 대한 책임을 다하고, 수정하고 학습하며 성장하겠다.

AI 모델을 개발하여 이를 활용한 서비스를 개발하고 운영하는 개발자가 되기 위해 꾸준히 노력하겠습니다!