안녕하세요! 오늘은 Object Detection을 수행하는 2-stage model 중 기본이 되는 모델인 Faster R-CNN에 대해서 리뷰해보고 코드로 구현해보겠습니다. 전체적인 코드는 제 깃허브에 올려둘 예정이니 참고 부탁드립니다.
Paper Review
지금까지의 2-stage Detection Model들은 Feature extractor과 Detector 사이에 bottle neck 현상이 발생하는 문제점이 있었습니다. 그래서 논문에서는 RPN(Region Proposal Network) 이라는 알고리즘을 통해 image의 convolutional feature들을 detection model과 공유할 수 있게 하면서 모델을 end-to-end로 학습할 수 있는 구조로 만들 수 있었습니다.
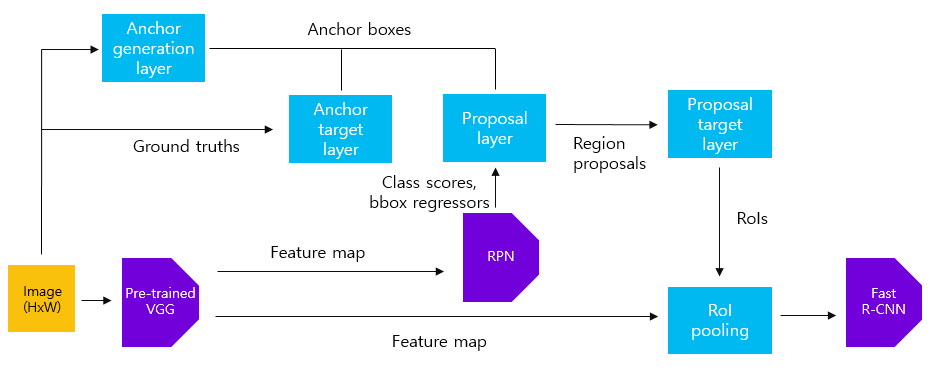
Faster R-CNN의 전체적인 과정은 위의 그림에서 볼 수 있듯이 다음과 같습니다.
1. image를 통해 feature map을 생성합니다.
2. RPN알고리즘을 통해 proposals를 뽑아냅니다.
3. proposal들과 1)의 feature Map을 RoI pooling하여 고정된 크기의 feature map을 생성합니다.
4. Fast R-CNN을 통해 object의 classification과 bounding box regression task를 수행합니다.
Main IDEA1: RPN
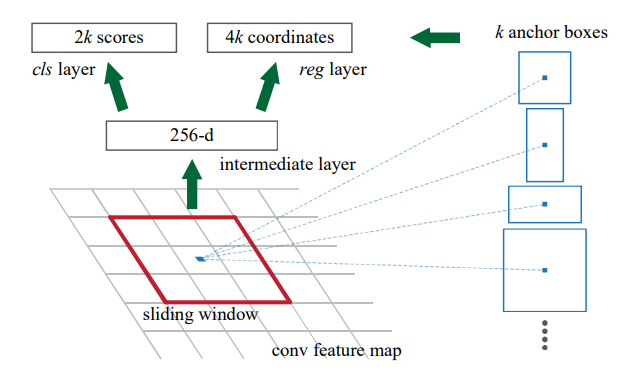
RPN은 원본 이미지에서 Region Proposal을 추출하고 이 proposal을 Detection model에 전달해주는 역할을 합니다. ZF나 VGG-16과 같은 Conv layer를 통해 얻은 Feature map에 Anchor라는 개념을 이용하여 region proposal의 후보군들을 추출하고, 학습을 진행하면서 Anchor들의 위치를 점차 객체가 있을 것으로 예상되는 지점으로 조정해가며 Detection model의 input의 질을 높여주는 역할을 합니다.
Anchor Box
Anchor Box는 오른쪽에 보이는 것과 같이 image에 일정 간격으로 grid를 나누고 이 grid의 가로, 세로로 aspect와 scale을 조절하여 생성된 region proposal의 후보가 될 box들을 의미합니다. 논문에서는 한 grid 당 3가지 aspect와 3가지 scale을 가지는 총 9개의 anchor box를 생성하였습니다.
RPN
RPN은 실제 image의 bounding box와 anchor box 간의 IOU를 기준으로 각 Anchor box들의 objectness와 location을 학습하는 과정으로 본 논문의 가장 핵심이 되는 알고리즘 입니다.
RPN을 학습하기 위해 논문에서는 bounding box와 anchor box 간의 IOU가 0.7이상이면 positive, 0.3이하이면 negative로 하고 그 외의 값을 가지는 box들은 학습하지 않도록 하였습니다.
RPN을 학습하는 과정에는 Image가 Conv-layer를 통과해 추출되는 Feature map을 바탕으로 각 Anchor box에 object가 포함되어 있는지 여부를 예측하는 classifier와 그 object를 더 잘 포함할 수 있는 위치로 box를 조정해주는 regression이 포합됩니다.
Multi-task Loss
RPN에서는 앞서 설명했듯 Classification과 Regression 두 가지의 모델에 대해 예측하게 되므로 두 모델의 loss를 모두 포함하는 loss function이 필요합니다.
저자가 제안한 loss function은 다음과 같습니다.
- : mini-batch 내의 anchor의 index
- : anchor i에 객체가 포함되어 있을 예측 확률
- : anchor가 양성일 경우 1, 음성일 경우 0을 나타내는 index parameter
- : 예측 bounding box의 파라미터화 된 좌표(coefficient)
- : ground truth box의 파라미터화 된 좌표
- : Log loss
- : Smooth L1 loss
- : mini-batch의 크기(논문에서는 256으로 지정)
- : anchor 위치의 수
- : balancing parameter(default=10)
논문에서는 lambda를 통해 regression과 classification 간의 가중치 조절을 해주었으며 classifier loss는 batch size로, regression loss는 anchor location의 수로 normalize 해주었다고 설명합니다.
Training RPNs
앞서 설명했듯 RPN은 end-to-end 구조이기 때문에 back-propagation과 SGD를 통해 학습됩니다. 그러나 anchor box를 학습하는 과정에서 한 image당 bounding box가 많지 않아 positive target과 negative target의 수가 imbalance 하다는 문제점이 발생합니다. 그래서 논문에서는 loss function에 들어가는 mini-batch를 256개의 anchor를 sampling 하는데 그 중 128개는 positive sample로, 나머지는 negative sample로 1:1비율을 맞춰 mini-batch를 구성합니다.
또한 하나의 grid에 anchor box를 9개씩 생성하다보니 Anchor box들이 너무 많아 학습을 방해하는 문제점이 있었습니다. 따라서 본 논문에서는 학습과정에서 image의 boundary에 걸치는 anchor box들은 모두 제거하였고, NMS를 이용하여 하나의 bounding box에 region proposal이 중복적으로 설정되는 것을 방지하여 학습에 활용되는 Anchor box의 수를 크게 줄였습니다.
Main IDEA2: Fast R-CNN
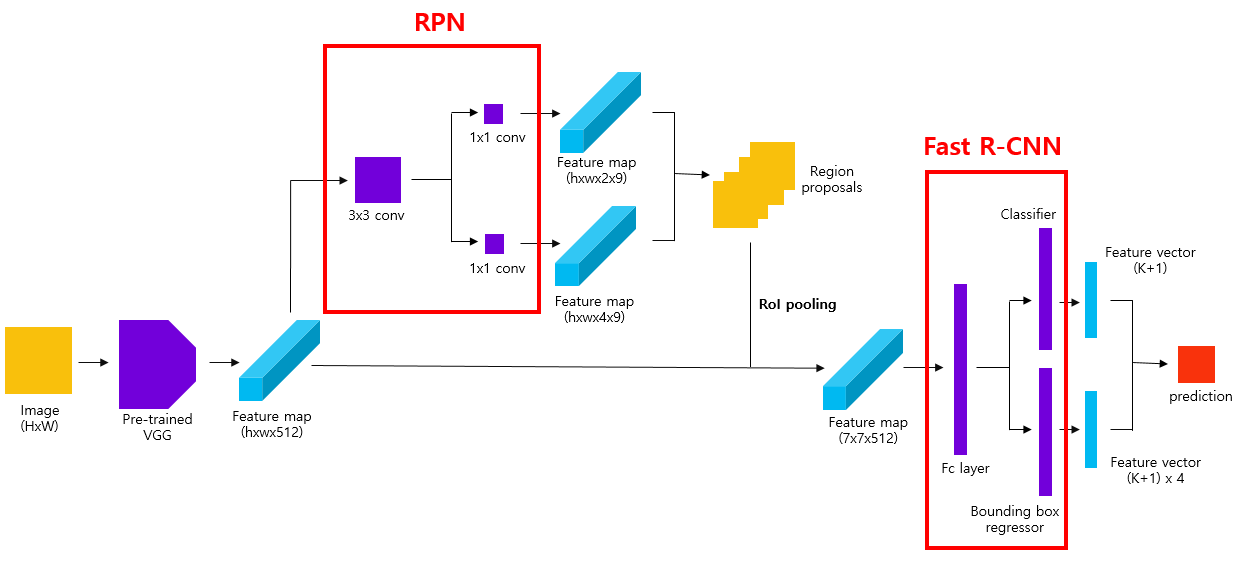
Main IDEA1에서 우리는 Region proposals을 추출했습니다. 이제 RoI Pooling과 Fast R-CNN을 통해 최종적인 Object Detection 과정만을 남겨두고 있습니다.
RoI Pooling
RoI Pooling은 Fast R-CNN 논문에서 제안된 알고리즘으로 region proposal의 크기가 일정하지 않다보니 일정한 비율로만 Pooling 효과를 갖는 Max Pooling을 적용하지 못하는 한계점을 극복하기 위해 제안되었습니다.
위의 그림에서도 볼 수 있듯이 input image에 h,w 비율에 구애받지 않고 pooling 연산을 통해 2*2의 Result를 추출할 수 있습니다. 논문에서는 이 RoI Pooling을 통해 RPN을 통해 추출한 Region proposal들을 일정한 크기로 변환하여 이후 Fast RCNN에 input될 수 있는 Feature Map을 생성하였습니다.
Sharing Features for RPN and Fast R-CNN
RPN을 통해 region proposals를 추출하고, Fast R-CNN을 통해 Detection을 하는 2-stage detection model의 구조 상 training 과정 역시 두번 나눠서 진행될 수 밖에 없었습니다. 그러나 저자는 두 model이 unified된 Network를 발전시키고자 하였고, RPN과 Fast R-CNN의 convolution layer를 공유시킬 수 있는 방법을 고안하였습니다. 저자는 이를 위해 여러 방면의 방법을 고민하였지만 Alternating training 방법을 선택하였습니다.
Alternating training
- RPN을 먼저 학습하고, proposals을 Fast R-CNN 학습에 활용합니다.
- network는 Fast R-CNN에 의해 tuning되고 이 network는 RPN을 initialize하는데 활용됩니다.
Altenating training의 과정은 아래와 같이 4 step으로 이루어져 있습니다.
1. RPN training: region proposal task를 통해 ImageNet을 학습한다.
2. Fast R-CNN training: RPN의 결과를 통해 detection net을 학습한다.
3. Detection net은 fixed, RPN으로 fine-tune
4. RPN은 fixed, Fast R-CNN fine tuning
Conclusion
이렇게 Faster R-CNN은 RPN과 Fast R-CNN을 활용해서 end-to-end Object Detecton 모델로써 제안되었습니다.. 논문로 읽기만 했을 때는 RPN와 Fast R-CNN의 연결부분이나 학습과정이 이해하기 어려웠습니다. 코드 리뷰를 하면서 다시 한 번 이해해보도록 하겠습니다.
Code Review
전체적인 코드는 Github에 올려놓겠습니다. 본 포스트에는 위 paper review에 설명된 주요 알고리즘에 대해서 설명하겠습니다.
구조가 다소 복잡하기 때문에 코드는 크게 7가지 Part로 나누었습니다.
- Dataset
- Feature Extraction
- Anchor Generation layer
- Anchor Target layer
- RPN
- Multi-task Loss
- Proposal layer
- Fast R-CNN
1. Dataset
본 코드를 리뷰할 때는 VOC Detection 2007 Dataset을 활용하였습니다. Dataset 속의 image가 size가 각각 다르기 때문에 이를 800*800의 크기로 resize 하여 Feature extraction에 용이하게 바꿔주었습니다.
VOC Detection 2007 Dataset은 20개의 class를 가지고 있으며 annotation과 image를 분리된 xml 구조로 저장되어 있기 때문에 이를 통합하여 dataset을 생성하였습니다.
Dataset Download
dataset = VOCDetection('.\VOCDetection',year='2007',image_set = "trainval", download=True)Image Resize
Image를 Feature Extraction이 용이하도록 800*800 size로 변환해주었다.
data_transform = transforms.Compose([
transforms.Resize(size=(800,800)),
transforms.ToTensor()
])
Anchor box annotation
Annotation에 저장되어 있는 object와 그 위치를 나타내는 bndbox를 추출한다.
annotations = target['annotation']['object']
bndboxes = np.zeros((len(annotations),4))
for n,obj in enumerate(annotations):
bndboxes[n,0] = int(int(obj['bndbox']['xmin'])*x_scale)
bndboxes[n,1] = int(int(obj['bndbox']['ymin'])*y_scale)
bndboxes[n,2] = int(int(obj['bndbox']['xmax'])*x_scale)
bndboxes[n,3] = int(int(obj['bndbox']['ymax'])*y_scale)
img_clone = np.copy(img_resized)
for i in range(len(bndboxes)):
cv2.rectangle(img_clone, (int(bndboxes[i][0]), int(bndboxes[i][1])), (int(bndboxes[i][2]), int(bndboxes[i][3])), color=(0, 255, 0), thickness=5)
plt.imshow(img_clone)
plt.show()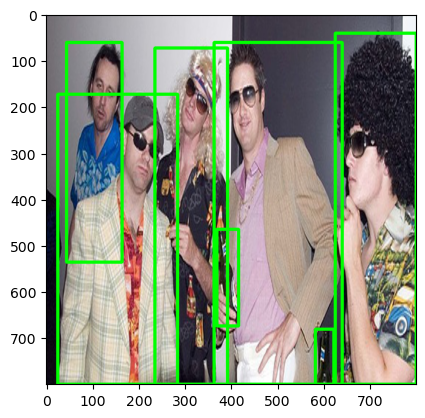
2. Feature Extraction
논문에서 제안한대로 VGG-16을 feature-map extractor로 활용합니다. 그러나 VGG16의 모든 layer를 활용하는 것이 아니라 추후 region proposals을 추출하기 위한 size의 feature-map을 생성할 때 까지의 layer들만 활용합니다. 그 결과, 의 feature-map을 생성하게 됩니다.
model = torchvision.models.vgg16(pretrained=True).to(device)
def vgg16_tuning(model,device):
model = model.to(device)
features = list(model.features)
dummy_img = torch.zeros((2,3,800,800)).float() #image 크기와 동일한 실험용 tensor 생성
output = dummy_img.clone().to(device)
req_features = []
for feature in features:
output = feature(output)
if output.size()[2]<800//16: #VGG16이 50*50 feature map을 만들 때 까지만 학습
break
req_features.append(feature)
return req_features
req_features = vgg16_tuning(model,device)
faster_rcnn_feature_extracter = nn.Sequential(*req_features)
output_map = faster_rcnn_feature_extracter(img_tensor) #50*50 의 image feature map 생성
3. Anchor Generation Layer
각 image에 feature map size에 맞게 의 grid를 생성한 뒤, 각 grid에 aspect와 scale에 따라 9개의 Anchor box를 생성해줍니다.
3가지 scale의 넓이를 3가지 aspect ratio에 따라 box의 가로, 세로를 조절해 9개의 anchor box 생성
aspect ratio: [1:1], [1:2], [2:1]
scale: [128*128], [256*256], [512*512]
def anchor_generate(image_size=800, feature_map_size=50):
anchor_center = np.arange(16, (feature_map_size + 1) * 16, 16) - 16/2
anchor_ratio = [[1,1],[1,2],[2,1]]
anchor_scale = [128*128,256*256,512*512]
anchor_boxes = np.zeros(((feature_map_size * feature_map_size * 9), 4))
index=0
for x in anchor_center:
for y in anchor_center:
for i in anchor_ratio:
for j in anchor_scale:
h,w = np.sqrt(j/(i[0]*i[1]))*i[0],np.sqrt(j/(i[0]*i[1]))*i[1]
anchor_boxes[index, 1] = y - h / 2.
anchor_boxes[index, 0] = x - w / 2.
anchor_boxes[index, 3] = y + h / 2.
anchor_boxes[index, 2] = x + w / 2.
index += 1
return anchor_boxes
anchors = anchor_generate(800,50)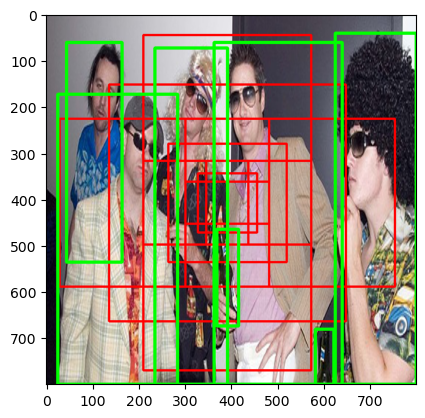
4. Anchor target layer
RPN을 학습하기 전에 Anchor box들에 Target값을 부여해주는 과정입니다. Bounding box와 Anchor box 간의 IOU를 기준으로 0.7 이상이거나 각 bounding box별로 가장 큰 IOU를 갖는 box의 경우 positive, 0.3 이하면 negative, 그 외의 값을 갖는 Anchor box는 학습에서 제외합니다.
IOU 계산
def ious(anchor_boxes,bndboxes):
IOUS = np.zeros((len(anchor_boxes),len(bndboxes)))
boxes=[]
for i,rect in enumerate(anchor_boxes):
rx_min,ry_min,rx_max,ry_max = rect
for j,bndbox in enumerate(bndboxes):
bx_min,by_min,bx_max,by_max = bndbox
x_left = max(rx_min,bx_min)
x_right = min(rx_max,bx_max)
y_bottom = max(ry_min,by_min)
y_top = min(ry_max,by_max)
if x_right < x_left or y_top < y_bottom:
iou = 0.0
pass
else:
intersection_size = (x_right-x_left)*(y_top-y_bottom)
rect_size = (rx_max-rx_min)*(ry_max-ry_min)
bndbox_size = (bx_max-bx_min)*(by_max-by_min)
iou = intersection_size / (rect_size+bndbox_size-intersection_size)
if iou<0:
print(rect,bndbox,iou)
assert iou >= 0.0
assert iou <= 1.0
IOUS[i,j] = iou
boxes.append((rect,bndbox))
return IOUS,boxesClassifier target 라벨링
IOU를 기준으로 Training Anchor Box의 Target 라벨링
def make_label(ious,pos_iou_threshold=0.7,neg_iou_threshold=0.3):
label = np.empty(len(ious),)
label.fill(-1)
#ious에 의해 labeling
label[np.where(ious.max(axis=1)>=pos_iou_threshold)]=1
label[np.where(ious.max(axis=1)<neg_iou_threshold)]=0
label[ious.argmax(axis=0)]=1
return labelRegression target 라벨링
IOU가 0.7 이상인 Anchor Box은 regression 학습 대상이므로 이에 대한 Target 생성
def make_ground_truth(IOUS,pos_iou_threshold=0.7):
gt_box_loc = np.empty((len(IOUS),4))
gt_box_loc.fill(-1)
#ground_truth
gt_box_loc[np.where(IOUS>=pos_iou_threshold)[0]] = bndboxes[np.where(IOUS>=pos_iou_threshold)[1]]
gt_box_loc[IOUS.argmax(axis=0)] = bndboxes[IOUS[IOUS.argmax(axis=0)].argmax(axis=1)]
return gt_box_locRPN input 생성
RPN에는 Image와 Anchor Box들의 위치 정보, Anchor Box들의 Label, Object를 포함하는 Anchor Box들의 위치정보가 활용됩니다.
def make_rpn_input(anchor_boxes,valid_anchor_boxes,index_inside,label,gt_box_loc):
# anchor label
anchor_labels = np.empty((len(anchor_boxes),), dtype=label.dtype)
anchor_labels.fill(-1)
anchor_labels[index_inside] = label
# anchor location
anchor_locations = np.empty((len(anchor_boxes),) + anchor_boxes.shape[1:], dtype=valid_anchor_boxes.dtype)
anchor_locations.fill(0)
anchor_locations[index_inside, :] = valid_anchor_boxes
# ground_truth
ground_truth_locations = np.empty((len(anchor_boxes),) + anchor_boxes.shape[1:], dtype=gt_box_loc.dtype)
ground_truth_locations.fill(0)
ground_truth_locations[index_inside, :] = gt_box_loc
return anchor_labels,anchor_locations,ground_truth_locations5. RPN(Region Proposal Network)
RPN은 VGG-16으로 Image에 대해 학습된 Feature-map에 Anchor Box를 활용해 object가 있을 것으로 추정되는 후보 box들을 정해주는 알고리즘입니다. Feature-map에는 개의 grid가 있으며 각 Grid에는 9개의 Anchor Box가 있기 때문에 총 22500개의 Anchor box에 대한 연산을 진행합니다.
RPN은 해당 Anchor Box에 object가 들어있는지에 대한 classification에 대해서 2개의 output(y/n), object가 들어있는 위치로 조정하는 Regression에서는 4개의 output(x,y,h,w) 총 6개의 output을 예측하게 됩니다.
class RPN(nn.Module):
def __init__(self):
super(RPN,self).__init__()
in_channels = 512
mid_channels = 512
n_anchor=9
self.conv1 = nn.Conv2d(in_channels, mid_channels, kernel_size=3, stride=1, padding=1).to(device)
self.conv1.weight.data.normal_(0,0.01)
self.conv1.bias.data.zero_()
self.reg_layer = nn.Conv2d(mid_channels, n_anchor*4, kernel_size=1, stride=1, padding=0).to(device)
self.reg_layer.weight.data.normal_(0,0.01)
self.reg_layer.bias.data.zero_()
self.cls_layer = nn.Conv2d(mid_channels, n_anchor*2, kernel_size=1, stride=1, padding=0).to(device)
self.cls_layer.weight.data.normal_(0,0.01)
self.cls_layer.bias.data.zero_()
def forward(self,output_map):
x = self.conv1(output_map.to(device))
pred_anchor_locs = self.reg_layer(x)
pred_class_score = self.cls_layer(x)
return pred_anchor_locs, pred_class_scoreRPN 학습 이후에는 loss function 계산을 위한 형태로 변환시켜준다.
def after_RPN(pred_anchor_locs,pred_class_score):
pred_anchor_locs = pred_anchor_locs.permute(1,2,0).contiguous().view(1,-1,4)
pred_class_score = pred_class_score.permute(1,2,0).contiguous().view(1,50,50,-1)
objectness_score = pred_class_score.view(1, 50, 50, 9, 2)[:, :, :, :, 1].contiguous().view(1, -1)
pred_cls_scores = pred_class_score.contiguous().view(1, -1, 2)
pred_rpn_loc_full = pred_anchor_locs[0]
pred_rpn_score_full = pred_cls_scores[0]
return pred_rpn_loc_full,pred_rpn_score_full,objectness_score
rpn = RPN()
pred_anchor_locs, pred_class_score = rpn(output_map)
pred_rpn_loc_full, pred_rpn_score_full,objectness_score = after_RPN(pred_anchor_locs,pred_class_score)
an_rpn_loc_full = torch.from_numpy(anchor_locations)
an_rpn_score_full = torch.from_numpy(anchor_labels)
gt_rpn_loc_full = torch.from_numpy(ground_truth_locations)6. Multi-task loss
classification은 Cross Entropy loss 를 이용하고, regression은 SmoothL1 loss를 이용하여 연산합니다. 두 loss에 대해서는 학습하고자 하는 방향에 따라 가중치(lambda)가 주어지는데, 이 때 저자는 Lambda=10으로 제안합니다. 논문에서 classification은 모든 Anchor box에 대해 연산하지만 Regression에서는 object가 있는 것으로 예상되는 Positive한 Anchor box들만을 이용하여 Loss를 계산하도록 제한을 두었습니다.
class multi_task_loss(nn.Module):
def __init__(self,label):
super(multi_task_loss,self).__init__()
self.label = label
def forward(self,pred_loc,pred_score,an_loc,an_score,gt_loc,index_inside):
pos_index = np.where(self.label == 1)[0]
loss_index = np.where(self.label != -1)[0]
lamb = 10
#cls_loss
rpn_cls_loss = F.cross_entropy(pred_score[loss_index], an_score[loss_index].to(device), ignore_index = -1)/len(loss_index)
#reg_loss
pred_rpn_loc = xyhw(pred_loc)[index_inside]
an_rpn_loc = xyhw(an_loc)[index_inside]
gt_rpn_loc = xyhw(gt_loc)[index_inside]
tx,ty,tw,th = reg_loss(pred_rpn_loc,an_rpn_loc)
tx_star,ty_star,tw_star,th_star = reg_loss(gt_rpn_loc,an_rpn_loc)
x_reg = smooth_l1(tx[pos_index],tx_star[pos_index])
y_reg = smooth_l1(ty[pos_index],ty_star[pos_index])
w_reg = smooth_l1(tw[pos_index],tw_star[pos_index])
h_reg = smooth_l1(th[pos_index],th_star[pos_index])
rpn_reg_loss = np.sum([sum(y_reg),sum(x_reg),sum(w_reg),sum(h_reg)])/len(pos_index)
rpn_loss = rpn_cls_loss + (lamb*rpn_reg_loss)
return rpn_loss
mtl = multi_task_loss(label)
mtl(pred_rpn_loc_full, objectness_score,an_rpn_loc_full,an_rpn_score_full,gt_rpn_loc_full,index_inside)7. Proposal layer
RPN에서 Object가 있을 것으로 예상한 Box들이 최종적인 Detection을 위해서 다음 Stage로 이어지는 과정입니다. 논문에서는 Anchor Box들이 너무 많으면 학습에 방해를 줄 수 있다고 설명하며 Objectness와 IOU를 기준으로 NMS를 적용하여 Image 당 2000개의 Box들을 선정합니다. Box가 image 밖으로 벗어난 경우엔 학습에서 제외하고 test에서만 활용한다고 설명합니다.
NMS(Non-Maximum Suppression)
각 Object 당 가장 가능성이 높은 Detection Box만을 제외하고 나머지는 제거하는 알고리즘으로, 본 논문에서는 Objectness가 가장 높은 Box를 순으로 IOUS가 0.7 이상인 Box들은 제거하였다.
def nms(boxes, probs, threshold):
# 내림차순으로 정렬
order = probs.argsort()[0].cpu().data.numpy()
# 개수 대로 true 리스트 생성
keep = [True]*len(order)
for i in range(len(order)-1):
# IOU 검출
ovps = batch_iou(boxes[order[i+1:]], boxes[order[i]])
for j, ov in enumerate(ovps):
if ov > threshold:
# IOU가 0.7d 이상인 box를 False로 세팅
keep[order[j+i+1]] = False
return keep
k = nms(pred_rpn_loc_xywh,objectness_score,0.7)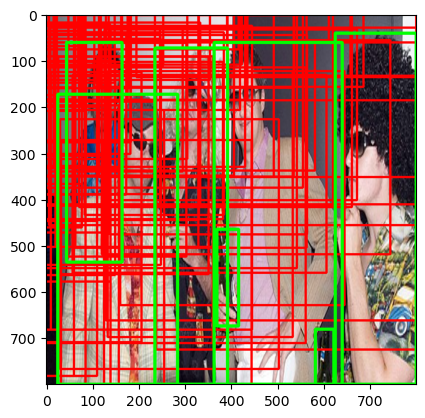 논문에서는 NMS를 거친 뒤 2000개 정도의 Box만이 남는다고 합니다. 비록 본 코드에서는 학습이 제대로 이뤄지지 않아 많이 부족한 Box들만 있지만, 학습을 하게 되면 더 많은 Box들이 Object와 가깝게 위치하고 있을 것입니다.
논문에서는 NMS를 거친 뒤 2000개 정도의 Box만이 남는다고 합니다. 비록 본 코드에서는 학습이 제대로 이뤄지지 않아 많이 부족한 Box들만 있지만, 학습을 하게 되면 더 많은 Box들이 Object와 가깝게 위치하고 있을 것입니다.
8. Fast R-CNN
RPN을 통해 얻은 Region proposal에 RoI Pooling과 Feature-map을 이용하여 Fast R-CNN을 적용합니다.
ROI Pooling은 50 50 feature map에서 예측된 ROI를 77 feature map에 projection 해주는 과정에서 정보의 손실을 최소화 해주기 위하여 고안되었습니다.
실제로는 RoI Pooling의 과정에서 RoI의 크기에 소수점이 발생해 반올림을 진행하는 과정에서 정보의 손실이 발생하게 되었습니다. 이는 추후에 RoI Align이라는 알고리즘을 통해 보완됩니다. RoI Pooling 이후에는 7*7 feature map을 펼쳐 Fast RCNN의 FC layer에 통과시킨 뒤, Classifier과 Regressor layer를 통해 Detection이 진행됩니다. 이 과정에서의 Loss는 Fast RCNN 논문에서 제안된 Multi task loss를 이용하여 학습이 진행되겠습니다.
RoI Pooling
class RoI_Pooling(nn.Module):
def __init__(self,output_size):
super().__init__()
self.output_size = output_size
self.maxpool = nn.AdaptiveMaxPool2d(self.output_size)
def forward(self,feature_map,rois):
pred_roi = xyxy(rois)
#RPN 이 예측한 값에는 float(소수점)이 발생하기 떄문에 quantization(소수점 반올림을 진행한다.)
ROI = np.clip(np.round(pred_roi/16),0,50).astype(int)
res=[]
for i in range(ROI.shape[0]):
f = feature_map[:,ROI[i][0]:ROI[i][2],ROI[i][1]:ROI[i][3]].unsqueeze(0)
max_f = self.maxpool(f)
res.append(max_f)
res = torch.cat(res,dim=0)
return res
roi_pool = RoI_Pooling(output_size=(7,7))
roi_pool_output = roi_pool(output_map,pred_boxes_2000)
# Reshape the tensor so that we can pass it through the feed forward layer.
k = roi_pool_output.view(roi_pool_output.size(0), -1) 
Fully Connected Layer
Fast R-CNN의 마지막 부분은 FC-layer로 class number는 데이터 특성 상 20개이며, 각각의 class로 분류해주는 분류기와 그 location을 예측하는 regression으로 나뉘어져 있다.
class fast_rcnn(nn.Module):
def __init__(self, class_num=22):
super().__init__()
self.class_num = class_num
self.fc_layer = nn.Sequential(
nn.Linear(25088,4096),
nn.Linear(4096,4096)
)
self.classify_model = nn.Linear(4096,self.class_num+1)
self.regression_model = nn.Linear(4096,4*(self.class_num+1))
self.cls_loss = nn.CrossEntropyLoss()
self.reg_loss = nn.SmoothL1Loss()
def forward(self,x):
x = self.fc_layer(x)
c = self.classify_model(x)
r = self.regression_model(x)
return c,rConclusion
이상으로 Faster R-CNN의 paper review와 code review를 해보았다. 사실 Code Review의 경험이 많지 않아 아직 전체적인 training 과정을 연결하거나, batch를 짜는 과정에서 분명 놓친 부분들이 있지만, Faster R-CNN이라는 구조를 이해하고 IOU나 NMS와 같은 알고리즘을 직접 구현해본 것에도 큰 의미가 있다고 생각한다. 다음 번엔 1-stage Detection model의 대표적인 모델인 YOLO를 구현해보며 Detection model에 대한 익숙함을 키워나갈 예정입니다.
긴 글 읽어주셔 감사합니다.
