논문리뷰(구현)
1.[논문 구현] ResNet(2015) 파이토치로 구현하기
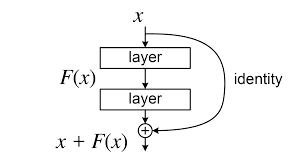
안녕하세요! 그동안 논문을 리뷰만 노션에 정리해왔고 코드로는 따로 구현을 못하고 있었는데, 이제부터 찬찬히 Pytorch를 다시 익혀보면서 논문 리뷰에 코드 리뷰를 곁들여 해보려고 합니다.제가 첫번째로 리뷰할 논문은 2015년 마이크로소프트에서 발표한 'Deep Res
2.[논문 구현] Faster R-CNN(2015) 파이토치로 구현하기
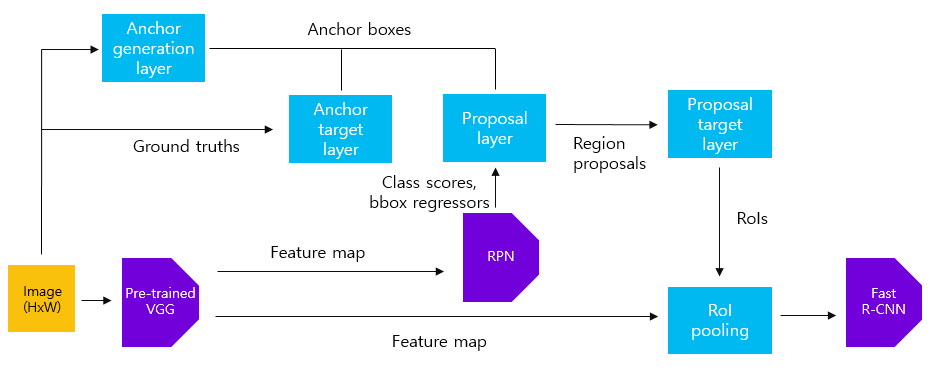
안녕하세요! 오늘은 Object Detection을 수행하는 2-stage model 중 기본이 되는 모델인 Faster R-CNN에 대해서 리뷰해보고 코드로 구현해보겠습니다. 전체적인 코드는 제 깃허브에 올려둘 예정이니 참고 부탁드립니다. Paper Review 지
3.[논문 구현] You Only Look Once(YOLO)(2015) 파이토치로 구현하기

안녕하세요! 오늘은 당시 two stage Object Detection 모델이 성행할 때 혜성같이 single netowork detection 모델로 등장해 지금까지 다양한 버전이 발전되어 온 YOLO(You Only Look Once)모델에 대해서 살펴보겠습니다.
4.[논문 구현] Vision Transformer(ViT)(2020) 파이토치로 구현하기

안녕하세요! 오늘은 2020년 구글에서 발표한 Vision Transformer(ViT)에 대해서 논문리뷰와 코드 구현을 해보겠습니다. 이 논문은 NLP 분야에서 강력한 성능으로 이젠 가장 대표적인 base module이 된 Transformer를 vision 분야에
5.[논문리뷰] Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation (DeepLabv3+)

Semantic Segmentation 프로젝트를 진행중에, DeepLabv3+ 모델을 사용하게 되어 논문 정리를 하며 사용성을 높이고자합니다.DeepLabv3+는 2가지 핵심 구조를 가지고 있습니다. 기존의 DeepLabv3에서 활용됐던 Atrous Spatial P
6.[논문 리뷰] Masked-attention Mask Transformer for Universal Image Segmentation

Masked attention Mask Transformer는 어떠한 image segmentation task에도 좋은 성능을 보이는 model architecture로서 개발 되었다. 특히 cross attention을 mask region으로 제약을 두어 loca
7.[논문 리뷰] Efficient and Degradation-Adaptive Network for Real-World Image Super-Resolution

안녕하세요! 오늘은 오랜만에 논문리뷰를 해보려 합니다. 요새 회사에서 온보딩 프로젝트로 Super Resolution 모델 개발 과제를 맡게되어 다양한 SuperResolution 관련 논문들을 읽어보고 있습니다. 그 중 오늘은 Real-World SuperResolu
8.[논문 리뷰] Dynamic Contrastive Knowledge Distillation for Efficient Image Restoration

안녕하세요. 오늘은 Super Resolution 모델에 Knowledge Distillation을 통해 경량화를 시도한 연구 중, 가장 최근에 이뤄진 것으로 보이는 Dynamic Contrastive Knowledge Distillation 논문을 리뷰해보겠습니다.본
9.Depth Anything 3: Recovering the Visual Space from Any Views 리뷰

최소한의 모델링으로, visual inputs의 수나 camera poses에 구애받지 않고 일정하게 공간적 정보를 예측 (depth estimation, pose estimation) 할 수 있는 모델 개발하나의 트랜스포머(vanilla DINO encoder) 만을
10.[논문 리뷰] Multi-View Foundation Models: 2D 파운데이션 모델을 3D-Aware 모델로 변환하기

안녕하세요 그루비한입니다. 오늘 읽어볼 논문은 12월에 발표되어 따끈따끈한 논문인 Multi-View Foundation Models 입니다.논문링크: arXiv그동안 2D Foundation Model에 대한 연구는 비약적으로 발전해 왔으나, 3D 분야는 상대적으로