안녕하세요 그루비한입니다.
오늘 읽어볼 논문은 VLA 학습 과정에서 데이터의 부족함을 해결할 수 있는 힌트를 준 LAPA 모델에 대한 논문입니다. LAPA 모델은 GR00T, Pi 등 다양한 SOTA VLA에서 데이터 증강을 위해 많이 쓰인 방법론이기 때문에 향후 논문을 읽을 때 언급이 자주될 우수한 논문입니다.
arxiv 링크: https://arxiv.org/abs/2410.11758

로봇 공학 분야에서 고성능 VLA(Vision-Language-Action) 모델을 구축할 때 가장 큰 걸림돌은 바로 Action 데이터의 부족입니다. 인터넷에 널려 있는 수많은 영상 데이터와 달리, 로봇의 실제 관절값이나 좌표가 포함된 데이터는 수집하기가 매우 까다롭기 때문입니다.
오늘 소개할 논문은 "Action 정보가 없는 일반 영상만으로 로봇의 행동을 학습시킬 수는 없을까?"라는 질문에서 시작된 LAPA (Latent Action Pre-trained Agent)입니다. LAPA가 어떻게 영상을 행동의 언어로 번역하고, 적은 데이터로도 강력한 일반화 성능을 보이는지 그 핵심 아이디어를 정리해 보았습니다.
1. Main Idea: 영상을 행동으로 바꾸는 '매퍼(Mapper)'
세상에는 무수히 많은 영상 데이터가 존재하지만, 로봇 학습에 바로 활용하기 어려운 이유는 영상 속에 '행동(Action)'에 대한 구체적인 수치 정보가 없기 때문입니다. LAPA는 영상 속 사람이나 로봇의 움직임을 추상적인 Latent Action으로 변환하여 이 문제를 해결합니다.
LAPA의 개발 과정은 크게 세 단계로 나뉩니다.
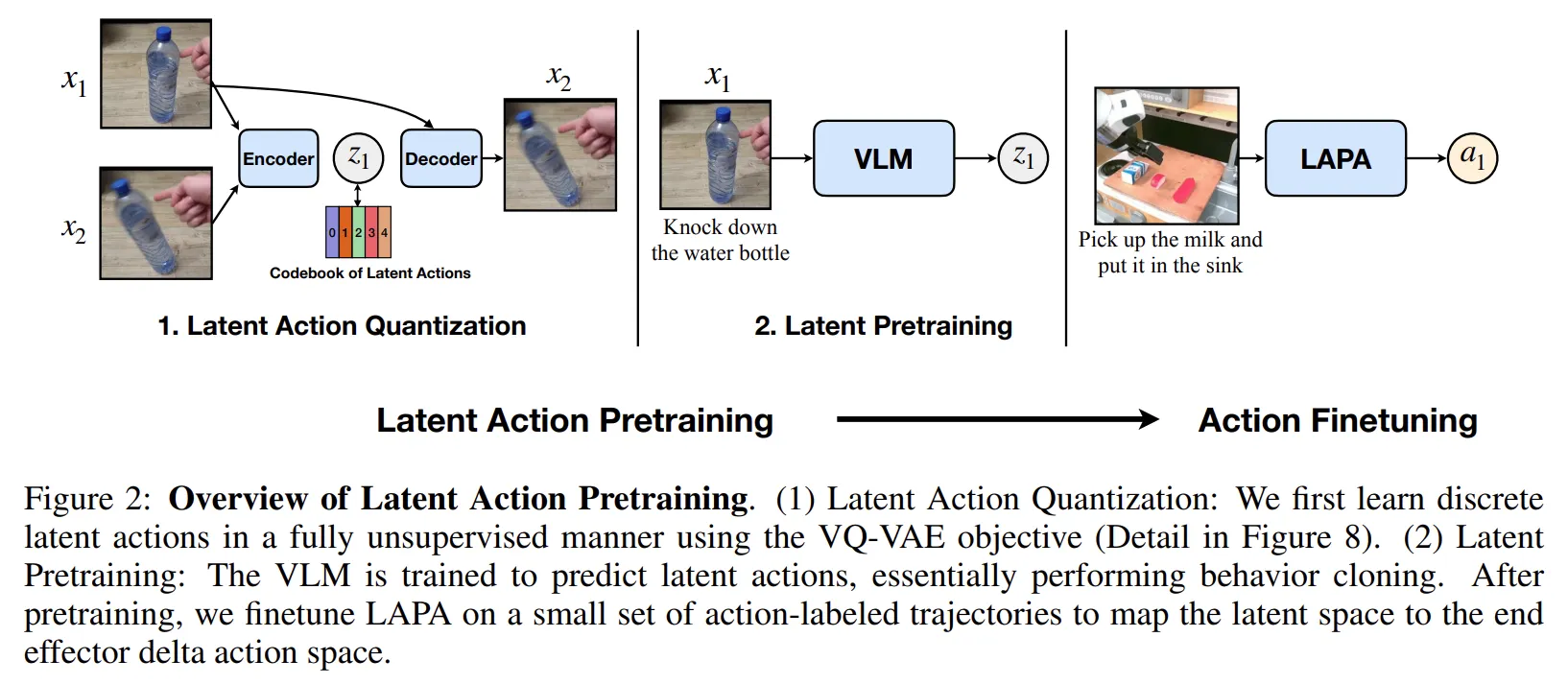
- Latent Action Quantization: 로봇의 움직임을 이산화된 잠재 벡터(Latent Action)로 만드는 모델 학습
- Latent Pretraining: VLM을 활용해 영상과 태스크(Text)로부터 Latent Action을 예측하도록 사전 학습
- Action Finetuning: 실제 적은 양의 로봇 데이터를 사용해 Latent Action을 실제 로봇 제어 값으로 매핑
2. Latent Action Quantization: 행동의 이산화
로봇의 움직임을 학습 가능한 형태로 변환하는 첫 단계는 Latent Action Quantization입니다. 이 과정은 이미지를 작은 코드 조각으로 압축하는 VQ-VAE(Vector Quantized-Variational AutoEncoder)의 메커니즘과 매우 흡사합니다. VQ-VAE가 이미지의 특징을 latent space로 압축한 뒤 다시 복원하며 가장 핵심적인 정보를 추출하듯, 이 모델은 '움직임의 본질'을 압축하여 연속적인 벡터가 아닌 카테고리화된 코드북(Codebook) 형태로 변환합니다.
구조 및 학습 메커니즘
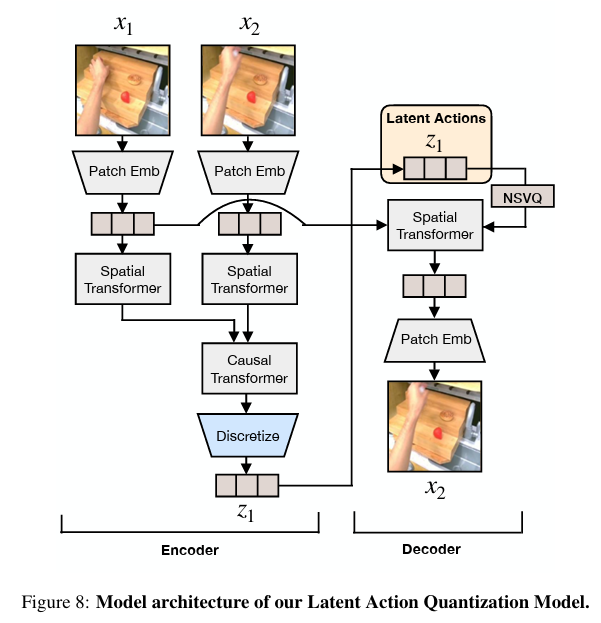 Latent Action Quantization Architecture
Latent Action Quantization Architecture
모델은 초기 프레임인 와 일정 시간()이 흐른 뒤의 프레임인 을 한 쌍으로 묶어 다룹니다. 인코더는 이 두 시점 사이의 시각적 변화를 포착하여 잠재적 행동인 를 생성하고, 디코더는 현재의 상태 에 이 를 조합하여 다시 를 성공적으로 복원(Reconstruction)해내야 합니다. 이 과정을 통해 모델은 "프레임이 이렇게 변하려면 어떤 행동()이 필요했는가"를 스스로 깨닫게 됩니다.
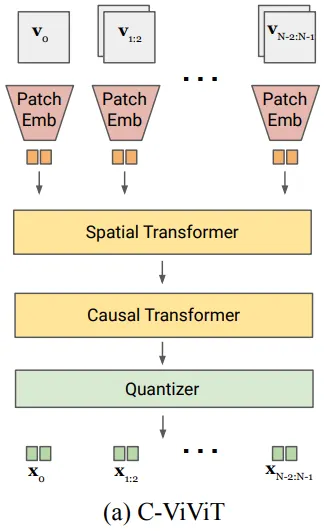
이러한 양자화 모델은 C-ViViT(Continuous Video Vision Transformer) 토크나이저를 영리하게 변형한 구조를 가지고 있습니다.
- 인코더는 시간과 공간의 변화를 모두 읽어내야 하므로 Spatial and Temporal Transformer를 사용하여 복잡한 동역학을 파악합니다.
- 디코더는 인코더가 뽑아낸 행동()을 바탕으로 공간적인 디테일을 복원하는 데 집중하기 위해 Spatial Transformer만을 사용합니다.
특히 주목할 점은 디코더가 와 를 결합하는 방식입니다. 기존의 Genie와 같은 모델이 추가적인 임베딩을 사용했던 것과 달리, 이 모델은 크로스 어텐션(Cross-Attention)을 직접 활용합니다. 이를 통해 별도의 부가 정보 없이도 현재 이미지와 잠재 행동 사이의 관계를 더 정밀하게 파악하고, 훨씬 의미 있는 latent action을 포착해낼 수 있었습니다.
이렇게 완성된 인코더와 디코더는 각각 독립적으로도 높은 가치를 지닙니다. 인코더는 영상의 변화로부터 행동을 유추해내는 역동학 모델(Inverse Dynamic Model)로, 디코더는 현재의 잠재 행동을 통해 미래를 예측하는 월드 모델(World Model)로 활용될 수 있기 때문입니다.
학습 과정에서는 연속적인 피처를 이산화된 코드북(Codebook) 형태로 나누어 VLM이 학습하기 좋은 형태로 변형하기 위해 VQ-VAE Objective를 사용합니다. 이때 발생할 수 있는 그래디언트 붕괴(Gradient collapse)를 방지하기 위해 벡터 양자화 오차 대신 NSVQ에 영감을 받은 Original error와 Normalize noise vector를 혼합하여 사용했습니다. 또한, 모델이 행동()에 집중하지 않고 이미지() 자체를 변형해 문제를 해결하려는 표현 붕괴(Representation collapse)를 막기 위해, 디코딩 과정의 패치 임베딩에는 그래디언트가 흐르지 않도록 설정하는 세밀한 전략을 취했습니다.
3. Latent Pretraining: 태스크로부터 행동 예측하기
이제 앞서 만든 코드북을 활용해, 이미지 와 텍스트 명령(Task Description)만으로 Latent Action 를 예측하는 VLM을 사전 학습합니다.
이 단계가 필요한 이유는 VLA 모델이 시각-언어 정보를 바탕으로 행동을 생성하기 위한 '중간 가교'가 필요하기 때문입니다. VLM의 최종 헤더를 MLP로 구성하여 코드북 사이즈()에 맞는 Latent Action을 생성하도록 합니다. 이때 비전 인코더는 동결(Freeze)하고 언어 모델 파트만 학습시킵니다.
중요한 점은 이 단계에서 특정 로봇의 좌표를 배우는 것이 아니라, 잠재 공간에서의 변화량(Delta)을 최적화하는 것이 목표이기에 다양한 영상 데이터로부터 범용적인 행동 패턴을 학습할 수 있다는 것입니다.
4. Action Finetuning: 실제 로봇 제어로의 매핑
마지막으로 사전 학습된 Latent Action을 실제 로봇의 End-effector 변화량(Delta)으로 매핑하는 파인튜닝을 진행합니다.
이 단계에서는 일반적인 VLA와 마찬가지로 실제 액션을 이산화하고, MLP 헤더 대신 실제 로봇 제어 값을 생성할 Action Head를 추가하여 학습합니다. 사전 학습을 통해 이미 "어떤 상황에서 어떤 종류의 움직임이 필요한지"를 알고 있기 때문에, 매우 적은 데이터로도 실제 로봇 제어 값을 빠르게 학습할 수 있습니다.
5. Result: 적은 데이터로 달성한 압도적 일반화
실험 결과, LAPA는 데이터 효율성과 일반화 측면에서 유의미한 성과를 거두었습니다. 태스크당 단 150개의 궤적(Trajectory)만으로 학습했음에도 놀라운 성능을 보였습니다.
Language Table Results
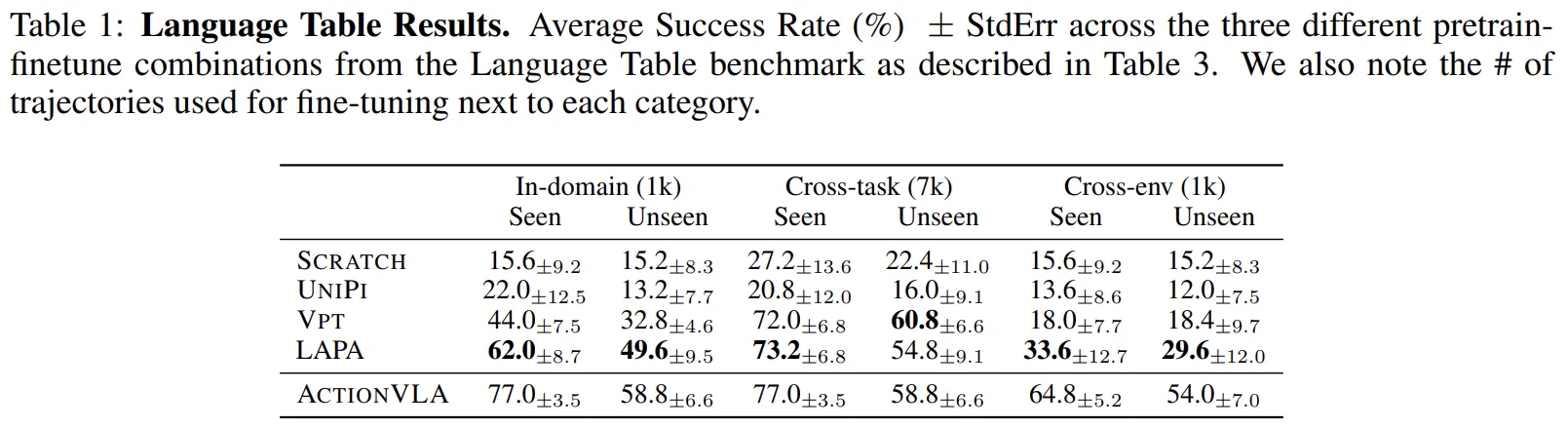 영상으로만 학습했음에도 OpenVLA와 근접한 성능을 기록했다.
영상으로만 학습했음에도 OpenVLA와 근접한 성능을 기록했다.
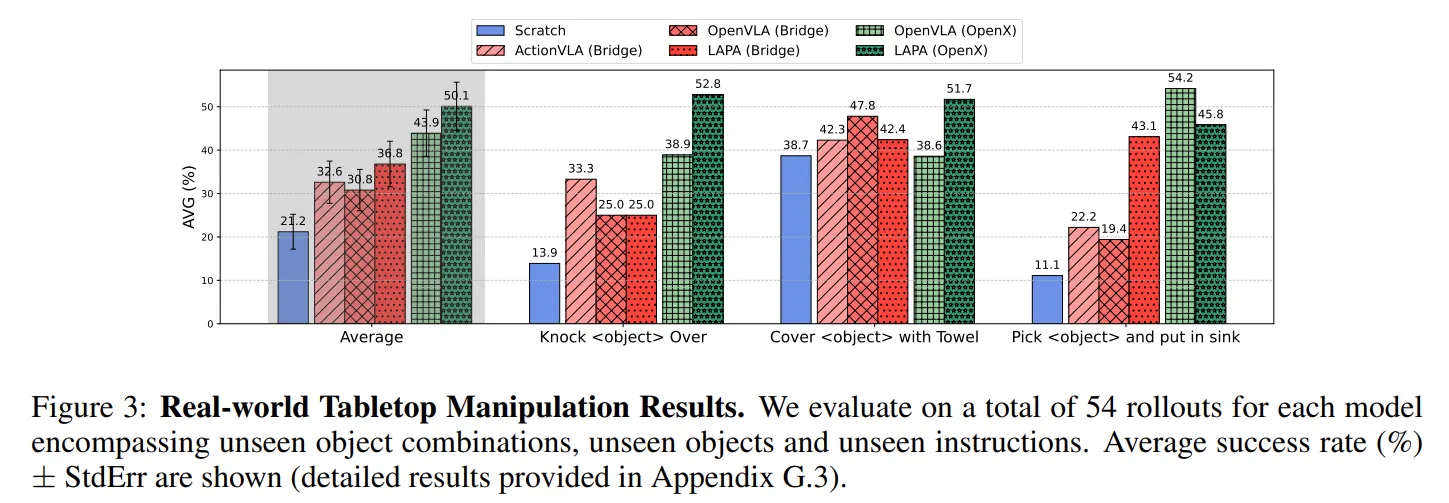 LAPA는 Knock, Cover 등의 task에서는 OpenVLA보다 앞섰지만 Pick and Place에서는 뒤쳐진다.
LAPA는 Knock, Cover 등의 task에서는 OpenVLA보다 앞섰지만 Pick and Place에서는 뒤쳐진다.
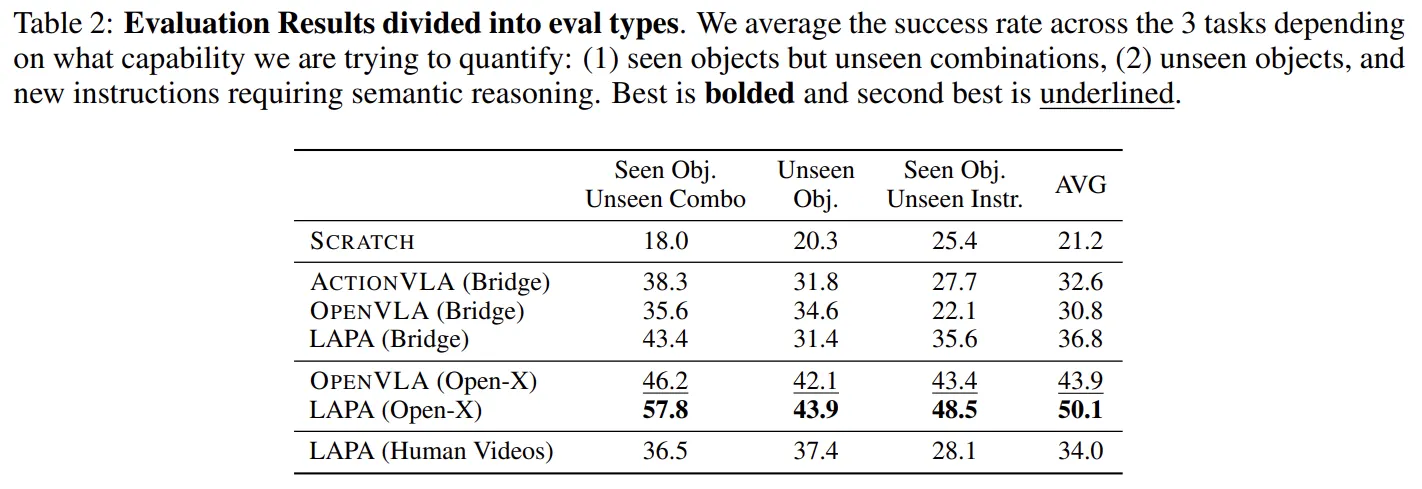 Unseen Situation에서 OpenVLA보다 좋은 성능을 보이며 일반화에 강점을 보였습니다.
Unseen Situation에서 OpenVLA보다 좋은 성능을 보이며 일반화에 강점을 보였습니다.
LAPA는 '처음 보는 물체 조합', '새로운 명령어' 등의 테스트에서 OpenVLA를 앞섰습니다. 이는 Latent Action이 다양한 로봇 영상을 공유하며 학습되었기 때문입니다. 또한 물체에 접근하거나 전체적인 계획을 짜는 태스크에서도 OpenVLA보다 뛰어난 성능을 보였습니다.
하지만 Pick-and-Place와 같이 매우 섬세한 미세 제어(Fine control)가 필요한 작업에서는 아직 다소 부족한 모습을 보입니다. 즉, "무엇을 할지"는 잘 알지만 "아주 정밀하게 움직이는 것"은 향후 과제로 남아 있습니다.
Conclusion
LAPA는 라벨이 없는 대량의 영상 데이터를 로봇 학습의 자양분으로 삼을 수 있는 획기적인 방법론을 제시했습니다. 영상을 통해 '행동의 본질'을 먼저 배우고 로봇에게 이식하는 이 방식은, 앞으로 데이터 기근 문제를 해결하고 더 똑똑한 로봇을 만드는 데 핵심적인 역할을 할 것으로 기대됩니다.
