Introduction
이 논문은 naverlabs에서 나온 논문으로 2이미지를 사용하여 이미지의 depth를 추정하고 association을 찾는 논문입니다.
이미지의 매칭은 2D에서 pixel을 매칭하는 것인데 이미지는 결국 3D 공간을 찍은 것인데 2d로 매칭을 할 경우
정확한 association을 할 때 정확도가 떨어집니다.
이것을 해결하기 위해 DUSt3R은 이미지를 포인트 맵으로 만들어 depth를 추정하려는 시도를 하였지만 정확성의 한계가 있었습니다. 이것을 보완하여 MASt3R은 더 높은 정확도와 depth추정을 할 수 있게 해줍니다.
주요 contribution은 3가지로 설명합니다.
1. 3d-aware matching
2. Coarse-to-fine matching
3. pose localization 정확도 증가
저는 point cloud에서도 이것을 활용하면 ICP를 사용하는 association문제를 더 정확하게 풀 수 있지 않을까 하여 이것을 읽어보았습니다.
The DUSt3R framework
MASt3R은 DUSt3R을 발전시킨 논문이라 먼저 DUSt3R framework에 대해 설명합니다.
설명을 하자면 두개의 image를 같은 encoder에 넣어 각각의 representation vector를 얻습니다. 
이렇게 얻은 vector 2개를 cross-attention을 통해 학습하여 서로와의 관계를 가지고 있는 vector를 출력합니다.
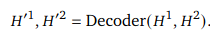
representation vector와 decoder에서 나온 추가 vector를 쌓아서 prediction head에 넣어 point map과 camera pose를 출력하게 됩니다.
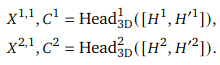
Regression Loss
DUSt3R은 supervised learning을 사용하기 때문에 간단한 regression loss를 사용합니다.
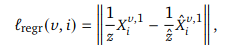
z는 scale 불변을 위해 normalize factor로 사용되었습니다.
metric prediction
scale 불변의 경우 항상 좋은게 아닐 수도 있습니다.
scale을 알아서 regression해야할 경우에는 loss를 수정해줘야합니다.
confidence 개념을 넣고 normalization을 무시하도록 loss를 설정해주는데
이 loss를 DUSt3R에서 가져왔다고 말하고 있습니다.
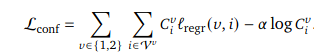
matching prediction head and loss
regression이 noise에 영향을 많이 받고 DUSt3R이 matching을 위한 학습이 안되었기 때문에
MASt3R에서는 matching head를 도입합니다.
matching head
이 head는 dense한 feature map을 출력합니다.
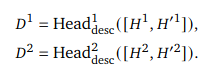
descriptor를 만드는 network라고 생각하면 편하겠습니다. 이렇게 추출된 feature의 거리를 사용하여 유사한 pixel을 찾습니다.
Matching Objective
이 feature들은 infoNCE가 가장 작도록 최적화 됩니다. 유사성을 판단하는 loss term이라고 생각하시면 됩니다.
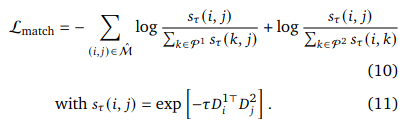
matching loss와 아까 정의한 confidence loss로 total loss를 정의하여 이것을 최소화하는 방향으로 학습합니다.
Fast reciprocal matching
feature map의 descriptor를 비교하여 가장 가까운 부분을 찾습니다.
하지만 모든 pixel에 대하여 비교를 하면 너무 계산량이 많기 때문에 빠른 matching을 위하여 새로운 방식을 제안합니다.
먼저 초기 샘플링을 통해 픽셀 초기 집합을 생성합니다. 이 초기 세트의 픽셀을 두번 째 이미지에서 가장 가까운 픽셀로 매핑하여 두번째 이미지의 픽셀 집합 V1을 얻습니다. 또 이것을 첫 번째 이미지에 매칭하고 이것을 수렴할 때까지 반복하면 모든 픽셀을 계산하는 것보다 빠르게 계산할 수 있다고 합니다.
제 생각엔 그냥 샘플링해서 반복하여 매칭한 것 같습니다.
이렇게 하면 계산 복잡도도 줄어들고 샘플링을 했기 때문에 아웃라이어를 필터링하는 효과도 있다고 말합니다.
Coarse-to-fine matching
MASt3R은 픽셀에 대하여 계산을 진행하기 때문에 너무 픽셀량이 많은 고해상도 이미지는 사용하지 못합니다. 그렇다고 고해상도를 제한하지말고 coarse-to-fine matching을 통해 고해상도 이미지도 매칭할 수 있도록 할 것입니다.
먼저 다운 샘플링을 통해 이미지 해상도를 낮추고 대충 matching을 시킵니다. 그 후
이미지를 512 x 512로 만들 수 있도록 하는 조각으로 쪼갭니다. 이 조각은 50%가 겹치도록 만들어집니다.
이 조각끼리 대충 matching 시킨 것은 토대로 두 쌍을 골라서 matching 합니다.
이 때 Fast reciprocal matching을 사용합니다. 이렇게 매칭된 쌍들을 고해상도의 이미지에 다시 대응하면 고밀도 매칭이 완성이 됩니다.
주요한 방법은 겹쳐있는 조각으로 잘라서 그냥 다운 샘플링했을때보다 더욱 정교하게 매칭을 할 수 있다는 것이었습니다.
Conclusion
이미지를 3d 정보를 활용하여 매칭한다길래 point cloud로 projection시키고 매칭을 시킬 줄 알았는데 transformer기반 방식을 사용하는거 보니 제가 사용하기는 힘들 것 같습니다.
transformer는 너무 무거워요. 언젠가 가벼워지면 이걸 쓸 수 있는 날이 올 것 같습니다.
이미지를 매칭하는 다양한 기법을 알게 되어 약간의 수확도 있었네요.
3줄 요약
1. transformer기반 attention을 이용하여 두 이미지 사이의 관계를 학습함.(3d로 본다)
2. Fast reciprocal matching을 통해 모든 pixel에 대하여 matching하지 않아 빠른 matching 가능
3. coarse-to-fine matching을 통해 고해상도 이미지에도 활용할 수 있다.
