Introduction
Depth 정보를 추정하는 것이 매우 중요합니다.
그런데 현재 센서들의 depth를 보면 camera는 dense한 반면 depth 추정이 덜 정확합니다.
LiDAR는 depth의 정보가 훨씬 정확하지만 sparse하여 depth 정보가 부족합니다.
그래서 현재는 딥러닝 기반으로 dense한 정확한 정보를 추정하는 dense depth completion기법들이 사용됩니다. 보통 이미지 depth의 정보를 비교적 정확한 lidar depth 정보를 convolution여 dense한 depth 정보들을 추정합니다. 이 때 image의 depth map이 너무 부정확하면 문제가 되는데 그냥 image를 바로 사용하면 그림자나 빛 반사 등으로 많은 문제가 발생할 수 있습니다. 이것을 방지하기 위해 depth, color, semantic 세가지 정보를 모두 사용하는 방식을 활용할 수 있다고 이 논문은 말합니다.
이 논문의 주요 contribution은 다음과 같습니다.
1. image guided method의 빛 문제를 방지하기 위해 3가지 정보를 모두 활용하는 backbone을 제안
2. 3가지 정보를 융합하는 SAMMAFB를 제안
3. 많은 실험결과에서 Kitti depth completion에서 SOTA를 달성
METHODOLOGY
Image-guide depth completion 문제를 two-stage task로 수식화하였습니다.
3가지 branch를 이용하여 depth,color,semantic 정보를 활용한 dense depth map을 처음 stage에 사용하고 두 번째 stage는 CSPN++을 활용하여 refine depth를 만듭니다.
A. Semantic-aware multi-modal attention-based fusion block
RGB, Semantic depth feature를 결합하기 위해서 semantic-aware multi modal attention-based fusion block을 제안합니다. 줄여서 SAMMAFB는 합쳐지 feature map을 정제하는데 사용됩니다. 이것은 두가지 세팅에서 사용되는데 첫번째는 RGB와 semantic guided map을 결합할 때 사용하고 두번째로 그 결합된 map과 depth map을 결합하는데 사용됩니다.
SAMMAFB은 두가지 attention을 사용하는데 첫번쨰는 channel-wise attention 두번째는 spatial wise-attention입니다. channel-wise attention은 전체적인 performance를 증가시키는 방향으로 channel관련 weigt를 할당하면서 중요한 channel을 학습합니다.
비슷하게 spatial-wisee attention의 경우 학습된 채널이 어느 위치에 있는지 학습합니다. 두 모듈은 서로를 보완하며 정제된 fusion depth map을 생성합니다.
channel wise attention의 경우 weight 계산은 이렇게 진행됩니다.
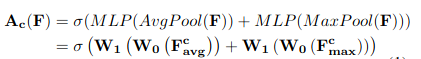
channel wise attention으로 만들어진 weight는 feature에 적용되어 F'을 만들고 spatial wise attention에 보내집니다. 그 후 spatial-wise attention weight가 적용되면 마지막 refined fusion feature map이 출력됩니다.
B. The Three-Branch Backbone
1) color guided Branch
color guided branch 줄여서 CG branch는 color 단서들을 학습하는 것이 목표입니다.
color image와 sparse depth map을 넣어 dense depth map을 추정하는 branch입니다.
CG branch는 connection 생략 encoder-decoder 구조를 가지고 있습니다.
encoder는 10개의 ResNet으로 구성되어 있고 decoder는 5개의 transpose convolution layer로 구성되어 있습니다. 이 네트워크의 출력은 dense depth map과 confidence map입니다.
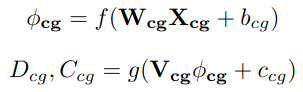
encoder와 decoder의 수식은 이렇게 나타낼 수 있고 weight와 bias를 적절하게 선택하여 gt depth와의 loss가 가장 작아지도록 만들 것입니다. 이러한 방식으로 color guided branch가 작동합니다.
2) Semantic-guided branch
Semantic은 scene에서 그 부분의 의미를 파악하는 것입니다.
이러한 정보를 이용하여 depth completion을 진행합니다.
이 branch에서는 color depth, semantic image, sparse depth map을 곂쳐 input으로 네트워크에 넣습니다. semantic image와 color image가 잘 곂쳐진 dataset이 없기 때문에 이 논문은 WideResNet38로 학습시켜서 semantic 정보를 image에 잘 결합시켜 학습합니다.
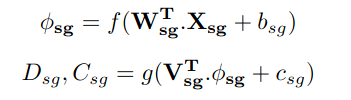
앞 CG branch와 마찬가지 방식으로 encoder와 decoder를 학습합니다.
3) Depth-guided Branch
DG branch는 앞에서 학습한 SG,CG정보와 sparse depth map을 input으로 하여 학습합니다.
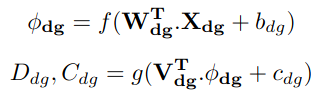
형태는 앞선 두 branch와 같습니다.
4)Multi-modal Depth Fusion
각 branch에서 나온 depth map을 fusion합니다.
학습한 weight를 활용하여 새로운 depthmap을 만듭니다.
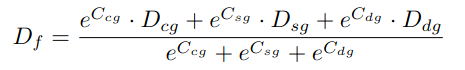
depth map과 나온 confidence map을 적절히 조합해 fusion된 depth map을 형성합니다.
5)Loss Function
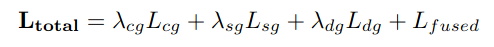
각각의 branch의 training loss를 weighted sum하여 전체 loss를 정의합니다.
