인간이 처음 가는 환경에서 길을 찾는 것은 매우 복잡한 일입니다.
이 과정은 관측한 map과 가지고 있는 정보를 활용하여 길을 찾게 됩니다.
가지고 있는 지식은 특정한 물체의 위치나 geometric한 정보를 포함하는 누적된 semantic 정보입니다.
예를 들어, 우리는 변기와 샤워기가 침실 근처 화장실에 있다는 정보를 알고 있습니다. Natural language는 사전 semantic 정보들을 맥락에 따라 강화할 수 있습니다.
로봇도 사람이 이렇게 찾는 것처럼 navigation 업무를 진행하고자 노력합니다. zero-shot 방식으로 알려진 많은 방식들은 이 model들을 task-specific training과 fube tuning없이 사용합니다.
이 논문에서, 우리는 Vision-Language Frontier Maps를 제안합니다.
새로운 환경에서 못본 물체방향으로 target-driven semantic navigation을 위한 zero-shot approach하는 알고리즘입니다. VLFM은 frontier를 확인하기 위해 depth를 관측하고 그것을 사용하여 occupancy map을 만듭니다.
PROBLEM FORMULATION
이 논문에서 이전에서 못 본 환경에서 target object category의 물체를 찾는 ObjectNaV task를 설명합니다.
이 semantic navigation은 robot이 환경을 이해하고 navigate하도록 합니다.
로봇은 egocentric RGB-D camera와 odometry sensor에만 접근할 수 있습니다.
action space는 MOVE_FORWARD(0.25m),TURN_LEFT(30도),TURN_RIGHT(30도),LOOK_UP(30도),LOOK_DOWN(30도), STOP으로 구성되어 있습니다. episode는 stop이 물체 1m이내에서 실행되면 성곡적으로 완료됐다고 합니다.
VISION_LANGUAGE FRONTIER MAPS
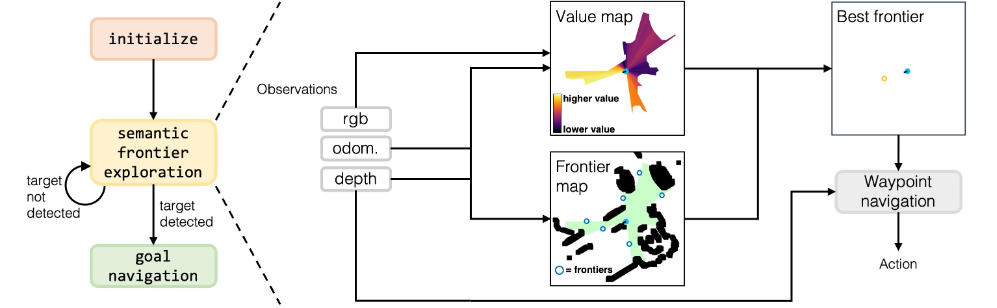
이 논문은 3가지 단계로 이 task를 수행합니다.
1) Initialize: Robot이 frontier와 value map을 set up하는 complete turn을 수행합니다.
2) Exploration: robot은 frontier waypoint를 만들고 가장 가치있는 waypoint를 고르기 위해 frontier와 value map을 업데이트합니다. 여기서 target object를 탐지하면 goal navigation phase로 넘어갑니다.
3) Goal Navigation phase: robot은 탐지된 target object에 가장 가까운 point로 navigate하고 STOP을 유발합니다.
A. Frontier waypoint generation
우리는 depth와 odomentry관측을 top down 2d map을 만드는데 사용됩니다.
관측된 지역은 robot의 위치와 장애물에 따라 update됩니다.
장애물의 위치를 확인하기 위해서 현재 depth map을 point cloud로 바꾸고 너무 짧거나 너무 높은 point는 필터링됩니다. 그리고 관측 지역과 비관측 지역으로 나누고 그 중간을 잠재적 frontier waypoint로 확인합니다. frontier는 비관측지역이 사라질때까지 유지됩니다. 만약 target object를 모든 frontier를 둘로보고도 못찾았다면 stop state로 들어갑니다(탐지 실패)
B. Value map generation
이 논문의 가장 중요한 접근법은 value map입니다.
이 맵은 각각의 pixel의 가치를 할당하고 semantic relevance를 양적화합니다.
이 value map은 각각의 frontier를 평가하는데 사용되고 가장 높은 value의 frontier는 다음 탐험의 첫번째 목적지로 결정.
frontier map과 비슷하게, value map은 depth와 odometry observation을 top-down map을 iterative하게 만드는데 사용됩니다.
그러나 value map은 semantic value score와 confidence score을 표현하는 두가지 channel을 가지고 있습니다.
사람이 semantic cue를 생각하는 것처럼 이 논문에서 pre-trained BLIP-2 vision-language model을 사용합니다. 이 알고리즘은 현재 관측과 target object의 cosine similarity score를 직접적으로 계산합니다. 이 점수는 top-down map에 projection되어 표현됩니다.
Confidence channel은 pixel의 value가 어떻게 업데이트 되어야 하는지를 결정합니다.
이전 시간의 value와 현재 시간의 FOV의 value를 가지고 업데이트를 합니다.
pixel이 현재 시간에 관측되지 않으면 pixel value는 영향을 받지 않습니다. optical axis의 confidence score는 1로 두고 heading 각도에 따라 조금씩 변합니다. (자세한 업데이트 방식은 직접 읽어보시길 바랍니다.)
map update과정을 요약하면
1) camera pose에서 top down 방식 FOV를 묘사하는 cone 모양 mask가 만들어집니다.
이 mask에서 optical axis에 가까울수록 confidence level이 올라갑니다.
2) Depth image를 사용해서, 장애물에의해 방해되는 FOV의 exclude area에 mask를 업데이트합니다.
3) BLIP-2를 사용해서, 현재 RGB image와 text prompt 사이의 similarity score를 계산합니다. 이것을 통해 mask의 value map을 업데이트하게 됩니다.
4) 이전 semantic value와 confidence score가 update됩니다.
C. Object Detection
target object을 robot이 보는지 못보는지 결정하기 위해서, 논문 저자들은 pre training된 object detector를 사용합니다. 만약 target object가 탐지된다면 mobile-sam을 사용하여 그 물체의 등고선을 추출합니다. 이 등고선은 depth 이미지와 함께 현재 로봇 point에서 가장 가까운 물체 포인트를 결정합니다. 로봇과 물체와의 거리가 success radius 이내로 들어오면 stop state로 돌입합니다.
D. Waypoint navigation
initialization이후, 로봇은 항상 frontier waypoint 또는 target way point를 제공받습니다. 현재의 waypoint에 도달하려고 각 step에서의 action을 결정하기 위해서 point goal navigation policy를 활용합니다. 이 알고리즘은 로봇이 온전히 visual 관측과 odometry에 의존하여 waypoint로 향하게 하도록 합니다.
결국 language model의 feature를 활용하여 target object를 찾는 value map 형성하여 navigation합니다.
이것을 통해 task-specific한 임무는 할 수 있지만 더 generative하게 사용할 수 있도록 해야한다고 저자는 언급합니다. frontier map을 활용하여 target object로 좀 더 효율적으로 다가갈 수 있는 것도 인상적이었습니다.
