Feature Engineering이란?
Feature Engineering이란 머신 러닝 모델의 성능을 향상시키기 위해 데이터의 특성(Feature)을 생성, 선택, 변환하는 과정이다. 이 과정은 모델이 데이터로부터 학습할 수 있는 유용한 정보를 최대한 추출하고 이해하기 쉬운 형태로 변환한다.
Feature Engineering의 주요 과정
1. Feature 생성
기존 데이터에서 새로운 특성을 만들어 내는 과정이다. 이를 통해 새로운 통찰력을 얻고, 데이터의 유용성을 증가시켜 모델의 예측 성능을 향상시킨다.
- "키"와 "몸무게" 특성을 조합하여 "체질량지수(BMI)"라는 새로운 특성 생성
- "구매일자" 데이터에서 구매가 이루어진 "요일"을 새로운 특성으로 추가하여, 요일별 구매 패턴 분석 가능
- "차량 모델" 데이터에서 차량의 "브랜드", "모델명", "출시년도" 등을 분리하여 별도의 특성으로 생성
- 사용자 리뷰 텍스트에서 긍정적인 단어의 수를 세어 "긍정 단어 개수"라는 새로운 특성으로 추가
2. Feature 선택
머신 러닝 모델의 성능을 최적화하기 위해 가장 유의미한 특성을 선택하고, 불필요하거나 잡음을 일으키는 특성을 제거하는 과정이다. 과적합을 방지하고, 불필요한 특성을 제거해 학습 시간을 단축시키며 중요한 특성만을 사용해 모델 해석을 용이하게 한다.
- 상관 계수가 높은 "주택 크기"와 "주택 가격" 사이의 관계를 분석하여 "주택 크기" 특성을 선택
- 랜덤 포레스트 모델을 사용하여 각 특성의 중요도를 평가하고, 가장 중요도가 높은 특성들을 선택
- 순차적 특성 선택 알고리즘을 사용하여 특성을 점진적으로 추가하거나 제거하며, 모델 성능이 최적화되는 특성 조합을 찾음
3. Scaling (Feature 변환)
Feature 변환은 데이터를 모델이 더 잘 이해할 수 있는 형태로 변경하는 과정이다. 데이터의 스케일 조정, 비선형 관계의 선형화 등을 통해 모델의 학습 효율성과 성능을 개선한다.
1) 정규화 (Normalization)
데이터의 범위를 통일화하여 모든 값을 동일한 스케일로 조정한다. 최소-최대 값의 차이가 큰 경우 유용하다.
[150, 200, 250]의 데이터를 정규화하면 [0, 0.5, 1]로 변환된다. 이는 모든 데이터 포인트를 0과 1 사이의 값으로 조정하여 모델이 데이터를 동일한 중요도로 처리하도록 한다.
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
# 샘플 데이터 생성
data = {'Score': [150, 200, 250]}
df = pd.DataFrame(data)
# 정규화
scaler = MinMaxScaler()
df_normalized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print(df_normalized)Score
0 0.0
1 0.5
2 1.0
2) 표준화 (Standardization)
데이터에서 평균을 제거하고, 각 데이터 포인트를 표준편차로 나누어 데이터의 분포가 평균 0, 분산 1이 되도록한다. 데이터의 분포가 정규 분포를 따르지 않을 때 유용하다.
평균이 100이고 표준편차가 20인 데이터 세트 [80, 100, 120]를 표준화하면 [-1, 0, 1]로 변환된다. 이는 데이터의 상대적인 위치를 보존하면서 스케일을 조정한다.
from sklearn.preprocessing import StandardScaler
# 샘플 데이터 생성
data = {'Score': [80, 100, 120]}
df = pd.DataFrame(data)
# 표준화
scaler = StandardScaler()
df_standardized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print(df_standardized)Score
0 -1.224745
1 0.000000
2 1.224745
3) 로그 변환 (Log Transformation)
데이터의 분포가 심하게 치우쳐 있을 때 이를 완화시켜 모델이 정보를 더 잘 인식할 수 있도록 한다. 특히, 큰 값들의 차이를 줄이는데 효과적이다.
[10, 100, 1000]의 데이터에 로그 변환을 적용하면 [1, 2, 3] 으로 변환된다. 이는 데이터의 범위를 줄여 모델이 큰 값의 차이에 의해 지나치게 영향을 받지 않도록 한다.
import numpy as np
import pandas as pd
# 샘플 데이터 생성
data = {'Income': [10, 100, 1000]}
df = pd.DataFrame(data)
# 로그 변환
df['Log_Income'] = np.log(df['Income'])
print(df)Income | Log_Income
0 10 | 2.302585
1 100 | 4.605170
2 1000 | 6.907755
스케일링 차이점 정리
| 변환 기법 | 설명 | 사용 사례 | 장점 | 단점 |
|---|---|---|---|---|
| 정규화 (Normalization) | 데이터의 범위를 [0, 1] 또는 [-1, 1] 등 특정 범위로 조정 | 범위가 서로 다른 데이터를 동일한 스케일로 조정할 때 | 모든 데이터 포인트를 동일한 스케일로 조정하여 비교 가능 | 이상치에 민감하며, 데이터의 분포가 변형될 수 있음 |
| 표준화 (Standardization) | 데이터에서 평균을 제거하고, 표준편차로 나눔 | 데이터의 분포가 정규 분포를 따르지 않을 때 | 데이터의 분포를 평균 0, 분산 1로 조정하여 다루기 쉽게 함 | 데이터의 최소/최대 범위를 제한하지 않음 |
| 로그 변환 (Log Transformation) | 데이터에 자연로그를 취함 | 데이터의 분포가 심하게 치우쳐 있을 때 | 큰 값들의 차이를 줄이고, 분포를 더 정규 분포에 가깝게 변형 | 음수 값을 가진 데이터에는 적용할 수 없음 |
4. Feature 인코딩
Featrue 인코딩은 범주형 데이터를 모델이 처리할 수 있는 수치형 데이터로 변환하는 과정이다. 대부분 머신러닝 알고리즘은 수치형 데이터를 기반으로 작동하기 때문에, 범주형 데이터를 적절히 변환해야 한다. 이를 통해 모델은 범주형 데이터를 이해하고, 예측을 수행할 수 있다.
1) 원-핫 인코딩 (One-Hot Encoding)
- 설명: 각 범주를 대표하는 새로운 이진 특성(열)을 생성한다. 해당 범주에 속하면 1, 아니면 0으로 표시한다.
- 장점: 범주 간의 순서나 중요도를 고려하지 않아 모델이 범주를 임의로 가중치하는 것을 방지한다.
- 단점: 범주의 수가 많을 때 특성의 차원이 급격히 증가할 수 있다 .
"색상" 특성에 "빨강", "녹색", "파랑"이 있을 경우, 각각을 대표하는 세 개의 열을 생성하고, 각 데이터 포인트는 해당되는 색상의 열에서만 1 값을 가지게 된다.
# Pandas 사용 예시
import pandas as pd
# 예시 데이터프레임 생성
df = pd.DataFrame({'color': ['red', 'green', 'blue']})
# 원-핫 인코딩 적용
one_hot_encoded = pd.get_dummies(df['color'], prefix='color')
print(one_hot_encoded)
# Scikit-learn 사용 예시
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
# 예시 데이터프레임 생성
df = pd.DataFrame({'color': ['red', 'green', 'blue']})
# 원-핫 인코더 생성 및 적용
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(df[['color']])
print(one_hot_encoded)
2) 레이블 인코딩 (Label Encoding)
- 설명: 각 범주에 고유한 정수를 할당한다. 이 방식은 순서형 데이터에 적합하다.
- 장점: 범주의 수에 관계없이 특성의 차원을 증가시키지 않는다.
- 단점: 숫자의 크기나 순서가 모델에 잘못된 가중치를 줄 수 있어, 순서가 중요하지 않은 범주형 데이터에는 부적합할 수 있다.
"빨강", "녹색", "파랑"을 각각 0, 1, 2로 인코딩한다.
# Scikit-learn 사용 예시
from sklearn.preprocessing import LabelEncoder
import pandas as pd
# 예시 데이터프레임 생성
df = pd.DataFrame({'color': ['red', 'green', 'blue']})
# 레이블 인코더 생성 및 적용
encoder = LabelEncoder()
label_encoded = encoder.fit_transform(df['color'])
print(label_encoded)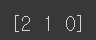
3) 이진 인코딩 (Binary Encoding)
- 설명: 레이블 인코딩을 적용한 후, 각 정수 값을 이진 숫자로 변환한다. 그리고 이진 숫자를 개별 비트로 나누어 각 비트를 별도의 특성으로 처리한다.
- 장점: 원-핫 인코딩에 비해 훨씬 적은 특성으로 범주를 표현할 수 있다.
- 단점: 이진 변환 과정이 추가되므로 처리 과정이 복잡해질 수 있다.
"빨강", "녹색", "파랑"을 0, 1, 2로 레이블 인코딩 한 후, 이를 이진수 "00", "01", "10"으로 변환한다. 각 비트는 별도의 특성으로 처리된다.
# Category_encoders 사용 예시
import pandas as pd
from category_encoders import BinaryEncoder
# 예시 데이터프레임 생성
df = pd.DataFrame({'color': ['red', 'green', 'blue']})
# 이진 인코더 생성 및 적용
encoder = BinaryEncoder(cols=['color'], return_df=True)
binary_encoded = encoder.fit_transform(df)
print(binary_encoded)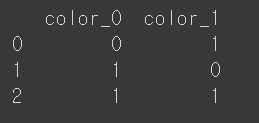
4) 카테고리 인코딩 (Category Encoding)
- 설명: 각 범주를 고유한 숫자로 매핑하지만, 원-핫 인코딩이나 레이블 인코딩과는 다르게 추가적인 차원이나 순서의 가정 없이 데이터를 변환한다.
- 장점: 유연하며, 다양한 데이터 유형에 적용할 수 있다.
- 단점: 특정 모델이나 상황에 따라 최적화가 필요할 수 있다.
고급 기법을 사용하여 "빨강", "녹색", "파랑"을 특정 규칙에 따라 숫자로 변환, 모델의 요구사항에 맞게 조정한다.
# Scikit-learn 사용 예시
from sklearn.preprocessing import OrdinalEncoder
import pandas as pd
# 예시 데이터프레임 생성
df = pd.DataFrame({'color': ['red', 'green', 'blue']})
# 순서 인코더 생성 및 적용
encoder = OrdinalEncoder()
ordinal_encoded = encoder.fit_transform(df[['color']])
print(ordinal_encoded)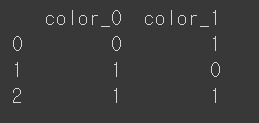
인코딩 차이점 정리
| 인코딩 방식 | 설명 | 장점 | 단점 |
|---|---|---|---|
| 원-핫 인코딩(One-Hot Encoding) | 각 범주를 대표하는 이진 특성 생성. 해당 범주 1, 아니면 0 | 범주 간 순서/중요도 무시, 가중치 방지 | 범주 많을 시 특성 차원 급증 |
| 레이블 인코딩(Label Encoding) | 각 범주에 고유한 정수 할당. 순서형 데이터 적합 | 특성 차원 증가 없음 | 순서 중요치 않을 때 모델에 잘못된 가중치 가능 |
| 이진 인코딩(Binary Encoding) | 레이블 인코딩 후, 정수를 이진 숫자로 변환. 각 비트를 별도 특성으로 | 원-핫 대비 적은 특성으로 표현 가능 | 처리 과정 복잡 |
| 카테고리 인코딩(Category Encoding) | 각 범주를 고유 숫자로 매핑, 추가 차원/순서 가정 없음 | 유연성, 다양한 유형 적용 가능 | 모델/상황 따라 최적화 필요 |
