Machine Learning
1.Grid Search와 Random Search 정리

Grid Search는 머신러닝 모델의 최적의 하이퍼파라미터를 찾기 위한 방법 중 하나이다. 하이퍼파라미터는 모델 학습 전에 설정되는 파라미터로, 모델의 성능에 큰 영향을 미친다. Grid Search는 지정된 하이퍼파라미터의 모든 조합을 시도하여, 가장 좋은 성능을
2.Feature Engineering

Feature Engineering이란 머신 러닝 모델의 성능을 향상시키기 위해 데이터의 특성(Feature)을 생성, 선택, 변환하는 과정이다. 이 과정은 모델이 데이터로부터 학습할 수 있는 유용한 정보를 최대한 추출하고 이해하기 쉬운 형태로 변환한다. 기존 데이터에
3.머신러닝 분류모델 평가: 정확도, 평가지표, 정밀도와 재현율, 임계값

정확도는 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표이다. 직관적으로 모델의 예측 성능을 나타내는 평가 지표이다.정확도 = (예측 결과가 동일한 데이터 건수) / (전체 예측 데이터 건수) = (TN + TP) / (TN + FP + FN + TP)오차
4.머신러닝: 비지도 학습과 지도 학습 정리
컴퓨터가 명시적으로 프로그래밍되지 않아도 데이터로부터 스스로 결정을 내릴 수 있게 하는 과정이다.예시스팸 분류: 이메일의 내용과 발신자를 바탕으로 스팸인지 아닌지를 예측도서 클러스터링: 책에 포함된 단어를 기반으로 다양한 카테고리로 책을 분류하고, 새 책을 기존의 클러
5.분류(Classification) - KNN(k-Nearest Neighbors)
미지의 데이터의 라벨을 분류하는 과정은 다음과 같다.모델 구축: 데이터 분류를 위한 알고리즘을 기반으로 한 모델을 만든다.학습: 모델은 제공된 레이블이 붙은 데이터(학습 데이터)로 부터 학습한다.미지의 데이터 입력: 레이블이 없는 데이터를 모델에 입력으로 제공한다.라벨
6.분류 모델 성능 측정하기
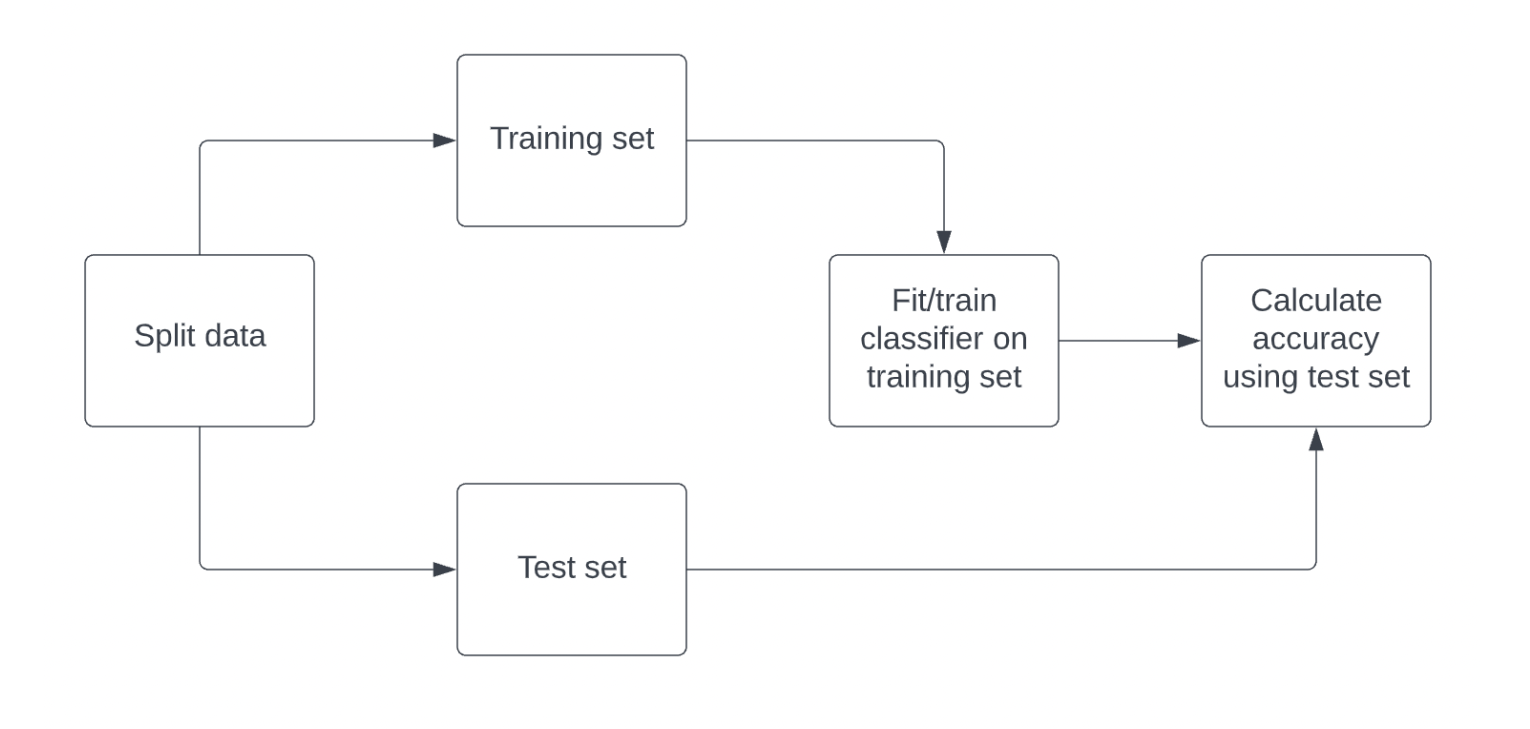
일반적으로 모델의 성능을 측정할 때 정확도를 사용한다.정확도 = 올바른 예측 수 / 전체 관측 수데이터를 학습 세트와 테스트 세트로 나눈다.학습 세트를 사용하여 분류기를 학습시킨 후, 테스트 세트의 레이블에 대해 모델의 정확도를 계산한다.출처: DataCampoutpu
7.회귀: 선형회귀, 릿지(Ridge), 라쏘(Lasso)
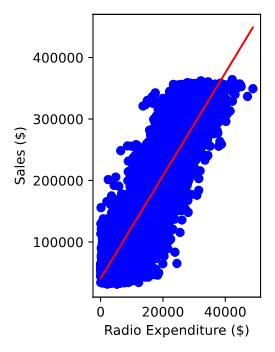
회귀 기본 features 생성 "radio"열로부터 X를, "sales"열로부터 y를 생성하고, X를 2차원 배열로 재구성한다. sales_df tv radio social_media sales 1 13000.0 923