정확도(Accuracy)
- 정확도는 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표이다. 직관적으로 모델의 예측 성능을 나타내는 평가 지표이다.
- 정확도 = (예측 결과가 동일한 데이터 건수) / (전체 예측 데이터 건수) = (TN + TP) / (TN + FP + FN + TP)

오차행렬(Confusion Matrix)
오차행렬은 머신러닝 모델의 성능을 평가하는 데 사용되는 표로, 모델이 예측한 결과와 실제 값이 얼마나 잘 맞는지를 보여준다. 이 표는 실제 값과 예측 값을 기준으로 네 가지 주요 요소로 구분된다.
| 실제 / 예측 | Positive 예측 | Negative 예측 |
|---|---|---|
| Positive 실제 | True Positive (TP) | False Negative (FN) |
| Negative 실제 | False Positive (FP) | True Negative (TN) |
True Positive (TP)
- 모델이 Positive라고 예측했고, 실제로도 Positive인 경우이다.
- 예를 들어, 실제로 스팸 메일을 스팸이라고 정확하게 예측한 상황이다.
True Negative (TN)
- 모델이 Negative라고 예측했고, 실제로도 Negative인 경우이다.
- 예를 들어, 실제로 중요한 메일을 중요하다고 정확하게 예측한 상황이다.
False Positive (FP)
- 모델이 Positive라고 예측했지만, 실제로는 Negative인 경우이다.
- 이는 잘못된 양성 예측으로, 예를 들어 중요한 메일을 스팸으로 잘못 분류한 경우에 해당한다.
False Negative (FN)
- 모델이 Negative라고 예측했지만, 실제로는 Positive인 경우이다.
- 이는 잘못된 음성 예측으로, 예를 들어 스팸 메일을 중요 메일로 잘못 분류한 경우에 해당한다.
정밀도(Precision)와 재현율(Recall)
정밀도와 재현율은 머신러닝 모델의 성능을 평가하는 중요한 지표다. 이 지표들은 모델이 얼마나 정확하게 긍정적인 결과를 예측하는지를 다루지만, 모델의 성능을 측정하는 관점이 약간 다르다.
정밀도
- 정의: 예측을 Positive로 한 대상 중 실제 값이 Positive로 일치한 데이터의 비율.
- 계산법: 정밀도 = TP / (FP + TP)
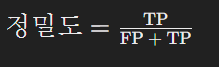
- 예시: 스팸 필터가 100통의 메일 중 90통을 스팸으로 분류했고, 그중 80통이 실제 스팸이었다면, 정밀도는 80/90, 즉 약 88.9%이다.
from sklearn.metrics import precision_score
# 실제 레이블
y_true = [0, 1, 2, 0, 1, 2, 0, 1, 2]
# 모델이 예측한 레이블
y_pred = [0, 2, 1, 0, 0, 1, 0, 2, 2]
# 정밀도 계산
precision = precision_score(y_true, y_pred, average='macro') # 'macro', 'micro', 'weighted', None 중 하나 선택
print(f'Precision: {precision}')Precision: 0.3611111111111111
재현율
- 정의: 실제 값이 Positive인 대상 중에서 예측과 실제 값이 Positive로 일치한 데이터의 비율.
- 계산법: 재현율 = TP / (FN + TP)
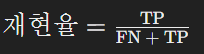
- 예시: 전체 100통의 스팸 메일 중 모델이 80통을 스팸으로 올바르게 예측했고, 실제 스팸 메일이 90통이라면, 재현율은 80/90, 즉 약 88.9%이다.
from sklearn.metrics import recall_score
# 실제 레이블
y_true = [0, 1, 2, 0, 1, 2]
# 예측 레이블
y_pred = [0, 2, 1, 0, 0, 1]
# 재현율 계산
recall = recall_score(y_true, y_pred, average='macro')
print(f'Recall: {recall}')Recall: 0.3333333333333333
재현율과 정밀도의 중요성 비교
보통 재현율이 정밀도보다 상대적으로 중요한 업무가 많지만, 정밀도가 더 중요한 지표인 경우도 있다.
- 재현율이 상대적으로 더 중요한 지표인 경우는 실제 Positive 양성인 데이터 예측을 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우이다.
- 예시: 실제로 질병이 있는 환자를 질병이 없다고 잘못 판단할 경우, 건강에 큰 영향을 미칠 수 있으므로 재현율이 더 중요하다.
- 정밀도가 상대적으로 더 중요한 지표인 경우는 실제 Negative 음성인 데이터 예측을 Positive 양성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우이다.
- 예시: 스팸 메일 분류에서 실제 중요 메일을 스팸으로 분류할 경우, 중요한 정보를 놓칠 수 있으므로 정밀도가 더 중요.
정밀도/재현율 트레이드 오프
정밀도와 재현율 트레이드 오프는 두 성능 지표 간의 균형을 찾는 과정에서 발생하는 현상으로, 한 지표를 개선하려 할 때 다른 지표가 손해를 볼 수 있다는 것을 의미한다. 정밀도와 재현율은 상호 보완적인 평가 지표이기 때문에 어느 한 쪽을 강제로 높이면 다른 하나의 수치는 떨어지기 쉽다.
-
왜 발생하나?: 모델이 예측 결정의 임계값(threshold)을 조정함으로써 정밀도와 재현율의 균형을 조절할 수 있다. 예를 들어, 모델이 긍정적인 예측을 더 쉽게 내리도록 임계값을 낮추면, 더 많은 긍정 예측을 생성하게 되어 재현율이 증가하지만, 이로 인해 실제로는 부정적인 사례들까지도 긍정으로 잘못 분류할 가능성이 높아져 정밀도가 감소하게 된다.
-
반대로, 임계값을 높여 모델이 긍정을 예측하기 위한 기준을 엄격하게 하면, 정밀도는 높아지지만 이 과정에서 일부 실제 긍정 사례들을 놓칠 수 있으므로 재현율이 감소한다.
이런 이유로, 모델을 개발할 때는 단순히 정확도만을 추구하는 것이 아니라, 사용 사례에 가장 중요한 성능 지표가 무엇인지를 고려하여 정밀도와 재현율 사이의 최적의 균형을 찾아야 한다.
참고: 평가 지표와 계산법
- 정분류율(Accuracy)
- 정의: 전체 샘플 중 올바르게 예측된 샘플의 비율
- 계산법:

- 오분류율(Error Rate)
- 정의: 전체 샘플 중 잘못 예측된 샘플의 비율
- 계산법:
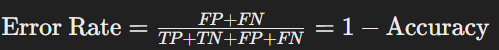
- 특이도(Specificity)
- 정의: 실제 Negative인 샘플을 Negative로 올바르게 예측한 비율
- 계산법:
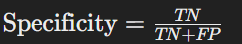
- 민감도(Sensitivity) 또는 재현율(Recall)
- 정의: 실제 Positive인 샘플을 Positive로 올바르게 예측한 비율
- 계산법:
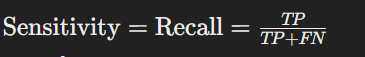
- 정밀도(Precision)
- 정의: Positive로 예측된 샘플 중 실제로 Positive인 샘플의 비율
- 계산법:
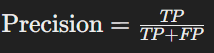
- F1 Score
- 정의: 정밀도와 재현율의 조화 평균
- 클래스가 불균형된 데이터에서 주요 평가지표로 사용함
- 계산법:
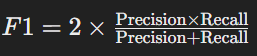
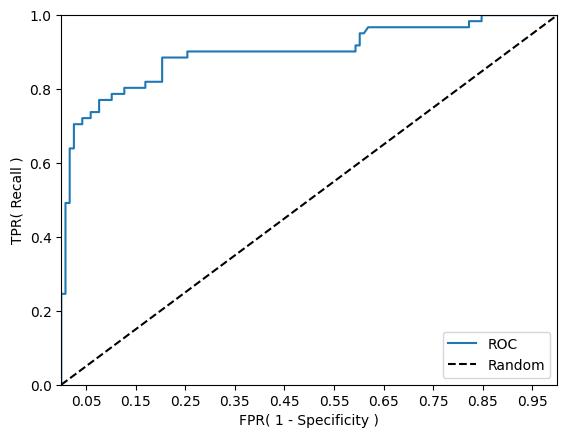
ROC와 AUC
-
ROC(Receiver Operation Characterisstic Curve): FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지를 나타내는 곡선이다.
-
AUC(Area Under the Curve): ROC 곡선 아래의 면적으로 모델이 양성 클래스와 음성 클래스를 구분하는 능력을 나타낸다.
- 일반적으로 1에 가까울수록 좋은 수치이다.
- FPR이 작은 상태에서 큰 TPR을 얻을 수 있어야 1에 가까워진다.
from sklearn.metrics import roc_curve
# 레이블 값이 1일때의 예측 확률을 추출
pred_proba_class1 = lr_clf.predict_proba(X_test)[:, 1]
fprs , tprs , thresholds = roc_curve(y_test, pred_proba_class1)
# 반환된 임곗값 배열에서 샘플로 데이터를 추출하되, 임곗값을 5 Step으로 추출.
# thresholds[0]은 max(예측확률)+1로 임의 설정됨. 이를 제외하기 위해 np.arange는 1부터 시작
thr_index = np.arange(1, thresholds.shape[0], 5)
print('샘플 추출을 위한 임곗값 배열의 index:', thr_index)
print('샘플 index로 추출한 임곗값: ', np.round(thresholds[thr_index], 2))
# 5 step 단위로 추출된 임계값에 따른 FPR, TPR 값
print('샘플 임곗값별 FPR: ', np.round(fprs[thr_index], 3))
print('샘플 임곗값별 TPR: ', np.round(tprs[thr_index], 3))
def roc_curve_plot(y_test , pred_proba_c1):
# 임곗값에 따른 FPR, TPR 값을 반환 받음.
fprs , tprs , thresholds = roc_curve(y_test ,pred_proba_c1)
# ROC Curve를 plot 곡선으로 그림.
plt.plot(fprs , tprs, label='ROC')
# 가운데 대각선 직선을 그림.
plt.plot([0, 1], [0, 1], 'k--', label='Random')
# FPR X 축의 Scale을 0.1 단위로 변경, X,Y 축명 설정등
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1),2))
plt.xlim(0,1); plt.ylim(0,1)
plt.xlabel('FPR( 1 - Specificity )'); plt.ylabel('TPR( Recall )')
plt.legend()
plt.show()
roc_curve_plot(y_test, lr_clf.predict_proba(X_test)[:, 1] )샘플 추출을 위한 임곗값 배열의 index: [ 1 6 11 16 21 26 31 36 41 46]
샘플 index로 추출한 임곗값: [0.94 0.73 0.62 0.52 0.44 0.28 0.15 0.14 0.13 0.12]
샘플 임곗값별 FPR: [0. 0.008 0.025 0.076 0.127 0.254 0.576 0.61 0.746 0.847]
샘플 임곗값별 TPR: [0.016 0.492 0.705 0.738 0.803 0.885 0.902 0.951 0.967 1. ]
분류모델 평가지표 산출 흐름
- 모델 학습
- 모델 예측
- 최적의 임계값 찾기
- 최적의 임계값을 기준으로 오차행렬 생성
- 평가지표 산출, 정확도, 재현율, 정밀도, F1-Score, AUC
예시
이메일이 스팸인지 아닌지를 분류하기 위해 이메일 데이터셋을 사용하여 스팸 필터 모델을 학습시키는 경우
- 최적의 임계값 찾기
- 스팸 필터에서는 스팸으로 분류하기 위한 확률 임계값을 조정하여 잘못 분류된 이메일의 수를 최소화 한다.
- 최적의 임계값을 기준으로 오차행렬 생성
- 스팸 필터 모델에서 실제 스팸 이메일을 스팸으로 정확히 예측한 경우 (TP), 실제 스팸이 아닌 이메일을 스팸으로 잘못 예측한 경우 (FP) 등을 오차행렬로 표현한다.
- 평가지표 산출
- 정확도(Accuracy): 전체 이메일 중 스팸과 비스팸을 정확히 분류한 비율
- 재현율(Recall): 실제 스팸 이메일 중 스팸으로 올바르게 예측된 이메일의 비율
- 정밀도(Precision): 스팸으로 예측된 이메일 중 실제 스팸인 이메일의 비율
- F1-Score: 스팸 필터의 정밀도와 재현율을 조화롭게 고려한 성능 지표
- AUC: 스팸 필터가 스팸과 비스팸을 구분하는 능력을 나타내는 지표
