머신러닝
- 컴퓨터가 명시적으로 프로그래밍되지 않아도 데이터로부터 스스로 결정을 내릴 수 있게 하는 과정이다.
- 예시
- 스팸 분류: 이메일의 내용과 발신자를 바탕으로 스팸인지 아닌지를 예측
- 도서 클러스터링: 책에 포함된 단어를 기반으로 다양한 카테고리로 책을 분류하고, 새 책을 기존의 클러스터 중 하나에 할당
비지도 학습
- 비지도 학습은 레이블이 지정되지 않은 데이터를 사용하여 숨겨진 패턴, 구조 또는 지식을 추출하는 머신러닝의 한 분야다.
- 주로 데이터 내 잠재적인 구조를 이해하고자 할 때 활용된다.
비지도 학습 기법
1. 클러스터링(Clustering)
비슷한 특성을 가진 데이터 포인트들을 그룹으로 묶는 과정이다. 클러스터링을 통해 데이터 내 숨겨진 패턴이나 그룹을 발견할 수 있다.
온라인 쇼핑몰은 클러스터링을 활용하여 고객을 여러 그룹으로 나눌 수 있다. 예를 들어, 구매 이력, 방문 빈도, 구매 선호도 등 다양한 기준을 바탕으로 고객을 세분화하여 각 그룹에 맞는 마케팅 전략을 수립할 수 있다. 이 과정에서는 고객의 구매 행동에 기반하여 사전에 정의된 카테고리 없이도 고객들을 여러 그룹으로 분류하게 된다.
2. 차원 축소(Dimensionality Reduction)
- 고차원의 데이터에서 중요한 정보를 유지하면서 차원의 수를 줄이는 과정이다.
- 데이터를 시각화하거나, 노이즈를 줄이며, 계산 효율성을 높이는 데 도움이 된다.
PCA(주성분 분석)는 가장 널리 사용되는 차원 축소 기법 중 하나로, 데이터의 분산을 최대한 보존하면서 차원을 축소한다. 예를 들어, 수천 개의 픽셀로 이루어진 이미지 데이터에서 중요한 특성을 추출하여 이미지를 분류하는 데 사용할 수 있다.
3. 연관 규칙 학습(Association Rule Learning)
- 대규모 데이터셋 내에서 아이템 간의 흥미로운 관계를 찾아내는 기법이다.
- 주로 물건들이 함께 구매될 가능성이 높은 패턴을 식별할 때 사용된다.
장바구니 분석은 연관 규칙 학습의 한 예로, 소매업에서 고객이 특정 상품을 구매할 때 다른 상품도 함께 구매할 가능성을 분석한다. 예를 들어, 사람들이 빵을 구매할 때 우유를 함께 구매하는 경향이 있다는 규칙을 찾아낼 수 있다.
4. 이상치 탐지(Anomaly Detection)
- 데이터에서 비정상적인 패턴인 이상치를 식별하는 과정이다.
- 보안, 의료, 금융 등 다양한 분야에서 중요하다.
신용카드 사기 탐지 시스템은 이상치 탐지의 한 예로, 정상적인 거래 패턴과 크게 다른 거래를 식별하여 사기 의심 거래를 탐지한다.
5. 자기 조직화 맵(SOMs, Self-Organizing Maps)
- 경쟁 학습을 기반으로 하는 인공 신경망의 일종으로, 고차원 데이터를 저차원(주로 2차원)의 그리드로 매핑한다.
- 패턴 인식, 특성 추출 등에 유용하다.
시장 세분화에서 SOM을 사용하여 고객을 비슷한 구매 패턴을 가진 그룹으로 시각적으로 분류할 수 있다. 이를 통해 기업은 타겟 마케팅 전략을 개발할 수 있다.
지도 학습
- 지도 학습은 입력 데이터와 그에 대응하는 레이블을 모델에 제공하여, 모델이 이 데이터를 학습함으로써 새로운 데이터에 대해 정확한 예측이나 분류를 수행하게 한다.
- 모델이 데이터의 패턴을 인식하고 이를 일반화하여 미지의 데이터에 대해 예측값을 제공한다.
의료 분야에서 환자의 임상 데이터(나이, 성별, 검사 결과 등)를 사용하여 특정 질병의 유무를 예측하는 모델을 구축할 수 있다. 이 경우, 임상 데이터는 입력 변수(특징)가 되고, 질병의 유무는 예측하려는 대상(레이블)이 된다.
지도 학습의 워크 플로우
1. sckit-learn 라이브러리에서 모델 클래스를 임포트 한다. 여기서 'Model'은 사용할 특정 모델의 이름이다. (예를 들어, 'LinearRegression', 'DecisionTreeClassfier' 등)
from sklearn.module import Model
2. 모델 인스턴스를 생성한다. 이때 'model'은 생성된 모델의 인스턴스를 참조하는 변수다.
model = Model()
3. 모델을 훈련시키는 과정이다. 'fit' 메서드를 사용해, 훈련 데이터셋(X)과 해당 레이블(y)을 모델에 전달한다.
model.fit(X, y)
4. 훈련된 모델을 사용해 새로운 데이터 셋(X_new)에 대한 예측을 수행한다. 'predict' 메서드는 X_new에 대한 예측된 레이블을 반환한다.
model.predict(X_new)
지도 학습의 유형
1. 분류(Classification)
- 분류는 입력 데이터를 사전에 정의된 여러 클래스 또는 카테고리 중 하나로 할당하는 학습 과정이다.
- 이진 분류와 다중 분류로 나뉜다. 이진 분류는 두 가지 범주 중 하나를, 다중 분류는 세 가지 이상의 범주 중 하나를 예측한다.
의료 진단에서는 환자의 검사 결과를 바탕으로 특정 질병을 가지고 있는지 여부(이진 분류)를 결정하거나, 여러 유형의 암 중 어떤 것에 해당하는지(다중 분류)를 예측할 수 있다.
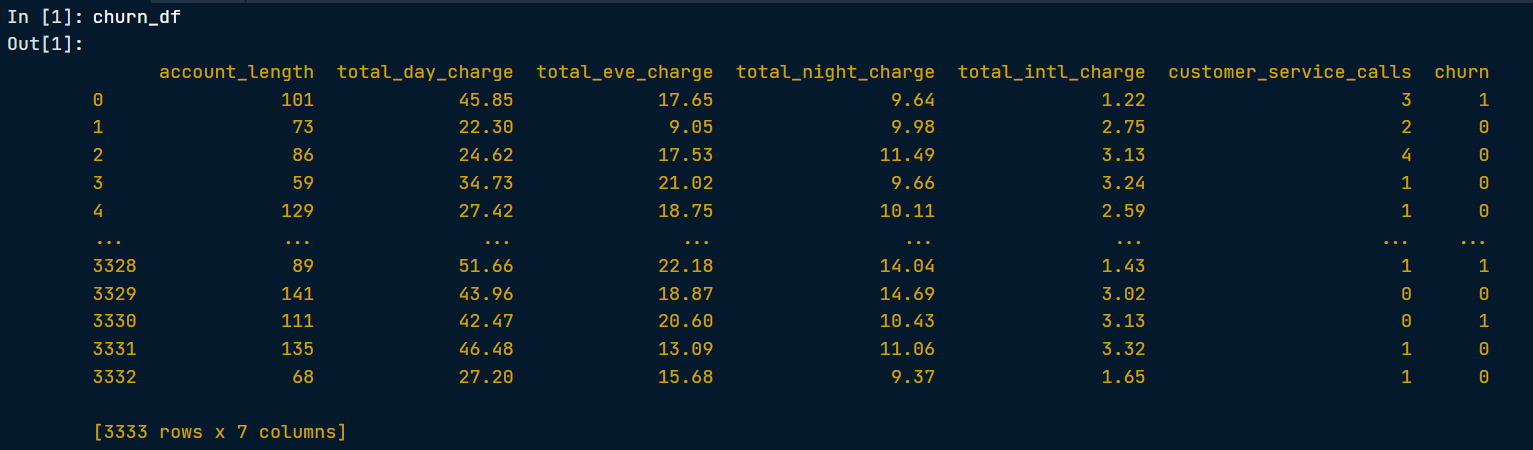
다음 열들 중에서 이진 분류의 대상 변수로 사용될 수 있는 열은?
- churn열은 0과 1의 value를 가지고 있어, 이진 분류의 대상변수로 사용될 수 있다.
2. 회귀(Regression)
- 회귀는 입력 변수들과 연속적인 수치 값을 가진 출력 변수 사이의 관계를 모델링 하는 과정이다.
- 회귀 분석을 통해 변수 사이의 관계를 이해하고, 하나 또는 그 이상의 독립 변수에 대한 종속 변수의 값을 예측할 수 있다.
부동산 시장에서는 주택의 위치, 크기, 방의 개수, 건축 연도 등의 정보(입력 변수)를 사용하여 주택 가격(출력 변수)을 예측할 수 있다. 이때 사용되는 모델은 주택 가격에 영향을 미치는 요소들 간의 복잡한 관계를 학습하여, 새로운 주택에 대한 가격을 예측한다.
명명 규칙
머신러닝에서 데이터와 모델을 다룰 때 일관된 명명 규칙을 사용해야 한다. 이는 분석의 명확성을 보장하고, 다른 연구자나 개발자와의 소통을 용이하게 한다.
-
특징(Feature):
- 정의: 입력 데이터의 개별적인 속성이나 변수를 의미한다. 이는 모델이 학습하는 데 사용되는 독립 변수들로, 예측의 기반이 된다.
- 동의어: 예측 변수(Predictor Variable), 독립 변수(Independent Variable)
-
목표 변수(Target Variable):
- 정의: 예측하고자 하는 주요 관심사로, 모델의 출력으로 생성된다. 지도 학습에서는 이 변수의 실제 값을 모델 학습에 사용한다.
- 동의어: 의존 변수(Dependent Variable), 반응 변수(Response Variable)
지도 학습을 사용하기 전에
지도 학습을 효과적으로 수행하기 위해서는 올바른 데이터의 준비 과정이 필요하다.
1. 결측값 처리
모델 학습 전 데이터 셋에는 결측값이 없어야 한다. 결측값은 제거하거나, 통계적 방법이나 예측 모델을 사용하여 채워야 한다.
2. 숫자 형식
대부분의 머신러닝 모델은 숫자 형식의 데이터를 필요로 한다. 따라서, 범주형 데이터는 숫자로 인코딩 되어야 하며, 모든 데이터는 적절히 스케일링 되어야 한다.
3. 데이터 저장 형식
pandas의 DataFrame이나 Series, NumPy 배열과 같은 형식으로 데이터를 저장해야 한다. 이는 데이터 핸들링과 모델링 과정을 용이하게 한다.
4. 탐색적 데이터 분석(EDA)
데이터의 구조, 분포, 관계 등을 이해하기 위해 탐색적 데이터 분석을 수행해야 한다. 이 과정에서 pandas의 기술 통계 메서드, 데이터 시각화(히스토그램, 산점도 등)를 활용하여 데이터의 특성과 패턴을 파악할 수 있다.
