정확도(Accuracy)
- 일반적으로 모델의 성능을 측정할 때 정확도를 사용한다.
- 정확도 = 올바른 예측 수 / 전체 관측 수
정확도 측정 방법
- 데이터를 학습 세트와 테스트 세트로 나눈다.
- 학습 세트를 사용하여 분류기를 학습시킨 후, 테스트 세트의 레이블에 대해 모델의 정확도를 계산한다.
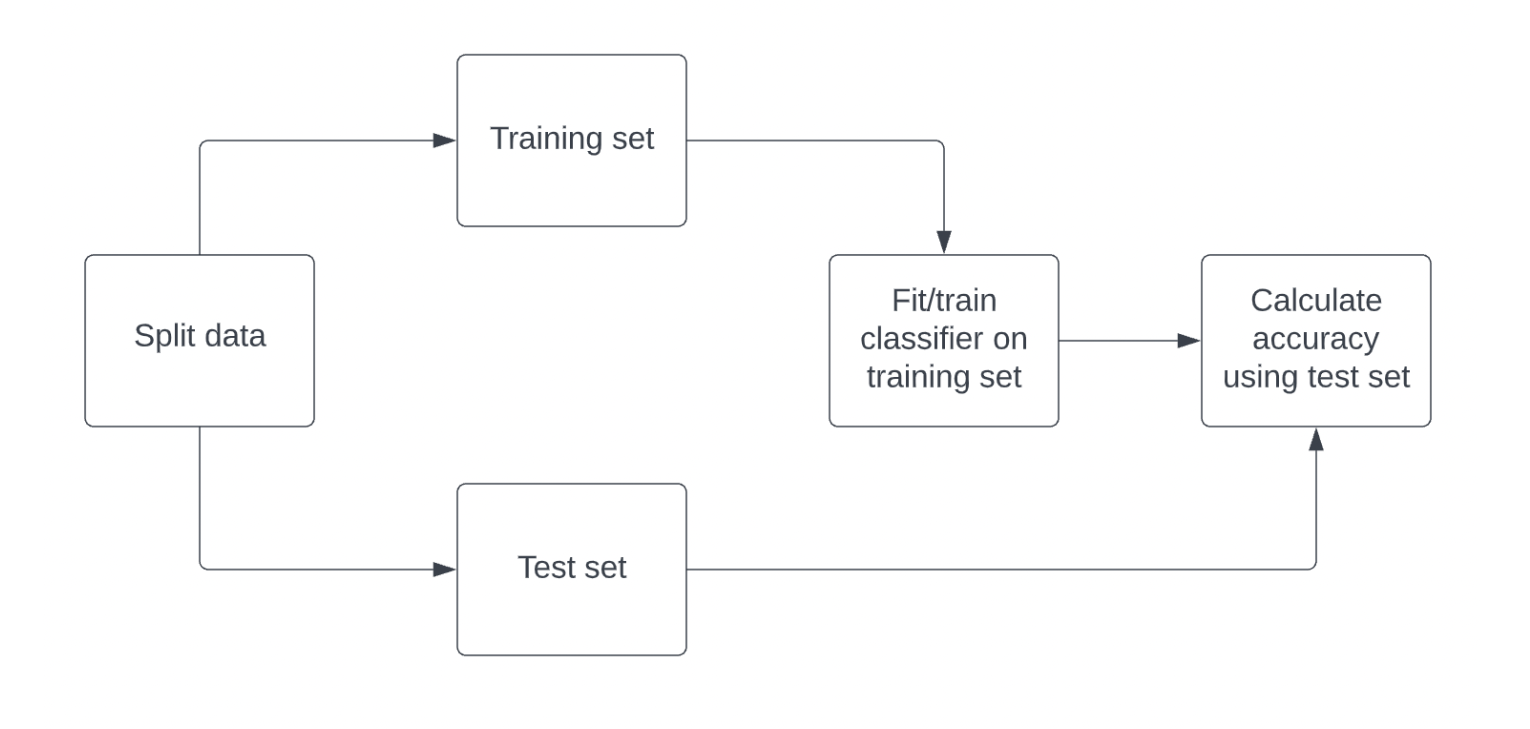
출처: DataCamp
Train/test split + 정확도 계산
# 모듈 불러오기
from sklearn.model_selection import train_test_split
X = churn_df.drop("churn", axis=1).values # 'churn' 열을 제외한 값
y = churn_df["churn"].values # 'churn' 열의 값
# 훈련 세트와 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
knn = KNeighborsClassifier(n_neighbors=5) # 이웃의 수가 5인 KNN 분류기
# 분류기를 훈련 데이터에 적합시키기
knn.fit(X_train, y_train)
# 정확도 출력
print(knn.score(X_test, y_test))output:
0.8740629685157422
과대적합과 과소적합
- 더 큰 k값: 덜 복잡한 모델을 의미하며, 과소적합을 유발할 수 있다.
- 더 작은 k 값: 더 복잡한 모델을 의미하며, 과대적합을 초래할 수 있다.
# 이웃 생성
neighbors = np.arange(1, 13)
train_accuracies = {} # 훈련 정확도 저장
test_accuracies = {} # 테스트 정확도 저장
for neighbor in neighbors:
# KNN 분류기 설정
knn = KNeighborsClassifier(n_neighbors=neighbor)
# 모델 적합
knn.fit(X_train, y_train)
# 정확도 계산
train_accuracies[neighbor] = knn.score(X_train, y_train) # 훈련 데이터 정확도
test_accuracies[neighbor] = knn.score(X_test, y_test) # 테스트 데이터 정확도
print(neighbors, '\n', train_accuracies, '\n', test_accuracies)output:
[ 1 2 3 4 5 6 7 8 9 10 11 12]
{1: 1.0, 2: 0.887943971985993, 3: 0.9069534767383692, 4: 0.8734367183591796, 5: 0.8829414707353677, 6: 0.8689344672336168, 7: 0.8754377188594297, 8: 0.8659329664832416, 9: 0.8679339669834918, 10: 0.8629314657328664, 11: 0.864432216108054, 12: 0.8604302151075538}
{1: 0.7871064467766117, 2: 0.8500749625187406, 3: 0.8425787106446777, 4: 0.856071964017991, 5: 0.8553223388305847, 6: 0.861319340329835, 7: 0.863568215892054, 8: 0.8605697151424287, 9: 0.8620689655172413, 10: 0.8598200899550225, 11: 0.8598200899550225, 12: 0.8590704647676162}
모델 복잡도 시각화하기
# 제목 추가
plt.title("KNN: Varying Number of Neighbors")
# 훈련 정확도 그리기
plt.plot(neighbors, train_accuracies.values(), label="Training Accuracy")
# 테스트 정확도 그리기
plt.plot(neighbors, test_accuracies.values(), label="Testing Accuracy")
plt.legend()
plt.xlabel("Number of Neighbors")
plt.ylabel("Accuracy")
# 그래프 표시
plt.show()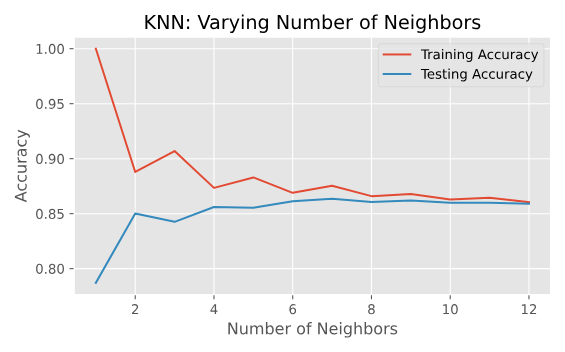

데이터 분석 공부중:)