회귀 기본
features 생성
"radio"열로부터 X를, "sales"열로부터 y를 생성하고, X를 2차원 배열로 재구성한다.
sales_df
tv radio social_media sales 1 13000.0 9237.76 2409.57 46677.90 2 41000.0 15886.45 2913.41 150177.83
import numpy as np
# sales_df의 "radio" 열의 값을 사용하여 X 생성
X = sales_df["radio"].values
# sales_df의 "sales"열의 값을 사용하여 y 생성
y = sales_df["sales"].values
# X의 형태를 변경
X = X.reshape(-1, 1)
# 특성(features)과 타겟(targets)의 형태를 확인
print(X.shape, y.shape)(4546, 1) (4546,)
선형 회귀 모델 구축
특성과 타겟 배열을 생성한 후, 모든 특성과 타겟 값에 대해 선형 회귀 모델을 훈련시킨다. 특성과 타겟 값 사이의 관계를 평가하는 것이 목표이므로, 데이터를 훈련 세트와 테스트 세트로 나눌 필요가 없다.
# LinearRegression을 임포트한다.
from sklearn.linear_model import LinearRegression
# 모델 생성
reg = LinearRegression()
# 데이터에 모델을 적합시킨다
reg.fit(X, y)
# 예측 수행하기
predictions = reg.predict(X)
# 예측값의 처음 5개를 출력
print(predictions[:5])[ 95491.17119147 117829.51038393 173423.38071499 291603.11444202
111137.28167129]
선형 회귀 모델 시각화
모든 관측치를 사용해 선형 회귀 모델을 구축하고 훈련시킨 후, 모델이 데이터에 얼마나 잘 맞는지 시각화할 수 있다. 이를 통해 라디오 광고 지출과 판매 값 사이의 관계를 해석할 수 있다.
# matplotlib.pyplot을 임포트한다.
import matplotlib.pyplot as plt
# 산점도 생성
plt.scatter(X, y, color='blue')
# 선 그래프 생성
plt.plot(X, predictions, color='red')
plt.xlabel("Radio Expenditure ($)")
plt.ylabel("Sales ($)")
# 그래프 표시
plt.show()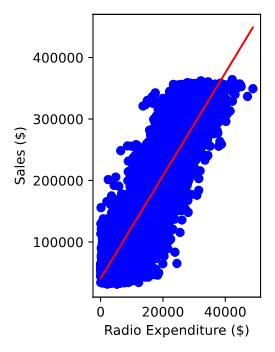
선형 회귀의 기본
단순 선형 회귀(Simple Linear Regression)
- 정의: y = ax + b 형태의 선형 방정식으로 모델링, 여기서 y는 타겟 변수, x는 단일 특성(feature), a는 기울기(slope), b는 y절편(intercept)을 의미한다.
- 예시: 키(x)에 따른 체중(y) 예측, 여기서 a는 키가 1cm 증가할 때 체중이 얼마나 증가하는지, b는 x=0일 때의 y값(체중)을 나타낸다.
파라미터 선택 방법
- 오류 함수(Error Function): 주어진 선에 대한 오류를 측정하는 함수 정의(예: 오차 제곱 합)
- 목표: 오류 함수를 최소화하는 파라미터(a, b) 선택하는 것이다.
- OLS(Ordinary Least Squares): 오차 제곱 합(Residual Sum of Squares, RSS)을 최소화
다중 선형 회귀(Multiple Linear Regression)
- 정의: 여러 개의 특성(x1, x2, ..., xn)을 사용하는 선형 회귀 모델, y = a1x1 + a2x2 + ... + anxn + b 형태로 표현한다.
- 예시: 집의 크기(x1), 방의 개수(x2), 연식(x3) 등 다양한 특성을 사용하여 집값(y)을 예측한다.
R-squared (결정 계수)
- 정의: 타겟 변수의 분산이 특성에 의해 얼마나 잘 설명되는지를 수량화한다.
- 범위는 0~1이다.
- R-squared 값이 1에 가까울수록 모델이 데이터를 잘 설명함을 의미한다.
MSE (평균 제곱 오차)
- 정의: 타겟 변수와 예측 값 사이의 차이의 제곱의 평균, 제곱단위로 측정하는 것이다.
- RMSE (Root Mean Square Error): MSE의 제곱근, 원래 단위로 오차를 측정한다.
- 예시: 집값 예측에서 실제 가격과 예측 가격 사이의 평균 제곱 오차 계산
회귀를 위한 적합 및 예측
테스트 특성의 값에 기반한 판매 예측을 수행한다.
# X, y를 생성
X = sales_df.drop("sales", axis=1).values
y = sales_df["sales"].values
# 데이터를 훈련 세트와 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 모델의 인스턴스화
reg = LinearRegression()
# 데이터에 모델 적합
reg.fit(X_train, y_train)
# 예측 수행
y_pred = reg.predict(X_test)
print("Predictions: {}, Actual Values: {}".format(y_pred[:2], y_test[:2]))Predictions: [53176.66154234 70996.19873235], Actual Values: [55261.28 67574.9 ]
회귀 성능
sales_df의 모든 특성을 사용하여 모델 reg를 적합시키고 판매 값에 대한 예측을 수행한 후, 몇가지 일반적인 회귀 메트릭을 사용해 성능을 평가할 수 있다.
1.4 버전부터
from sklearn.metrics import root_mean_squared_error사용 가능
# mean_squared_error를 임포트한다
from sklearn.metrics import mean_squared_error
# R-제곱 계산
r_squared = reg.score(X_test, y_test)
# RMSE 계산
rmse = mean_squared_error(y_test, y_pred, squared=False)
# 메트릭 출력
print("R^2: {}".format(r_squared))
print("RMSE: {}".format(rmse))R^2: 0.9990165886162027
RMSE: 2942.372219812037
교차 검증
test 세트에서 계산된 R-squared는 데이터 분할 방식에 의존적이기 때문에, 모델의 일반화 능력을 제대로 대표하지 않을 수 있다. 따라서, 이 문제를 해결하기 위해 교차 검증 기법을 사용한다.
교차 검증 기초
- 데이터 셋 분할: 데이터 셋을 5개의 폴드로 나눈다.
- 검증 과정:
- 첫 번째 폴드를 테스트 세트로 사용하고, 나머지를 학습에 사용한다.
- 모델을 학습시키고, 테스트 세트에서 예측 후 R-squared 계산한다.
- 이 과정을 각 폴드에 대해 반복하여, 각 폴드마다 R-sqaured 값을 얻는다.
- 결과 분석: 얻어진 R-squared 값들로부터 평균, 중앙값, 95% 신뢰구간을 계산하여 모델 성능을 평가한다.
교차 검증과 모델 성능
- k-폴드 교차 검증: 데이터셋을 k개의 폴드로 분할하고, 각 폴드를 검증 세트로 사용하는 과정을 k번 반복한다.
- 폴드 수가 많을 수록 계산 비용이 증가한다.
- 성능 평가:
- 평균 점수와 표준 편차는 numpy의
mean과std함수로 계산한다. - 95% 신뢰 구간은
quantile함수를 사용하여 계산한다.
- 평균 점수와 표준 편차는 numpy의
결정계수를 위한 교차검증
선형 회귀 모델을 구축하고, 6-fold 교차 검증을 사용해 소셜 미디어 광고 지출을 사용한 판매 예측의 정확도를 평가할 것이다.
# 필요한 모듈을 임포트
from sklearn.model_selection import KFold, cross_val_score
# KFold 객체를 생성
kf = KFold(n_splits=6, shuffle=True, random_state=5)
# 선형 회귀 모델 생성
reg = LinearRegression()
# 6-fold 교차 검증 점수 계산
cv_scores = cross_val_score(reg, X, y, cv=kf)
# 점수 출력
print(cv_scores)[0.74451678 0.77241887 0.76842114 0.7410406 0.75170022 0.74406484]
교차 검증 메트릭 분석
교차 검증을 했으므로 결과를 분석한다. cv_results에 대한 평균, 표준편차, 95% 신뢰구간을 출력한다.
# 평균 출력
print(np.mean(cv_results))
# 표준편차 출력
print(np.std(cv_results))
# 95% 신뢰구간 출력
print(np.quantile(cv_results, [0.025, 0.975]))
output:
0.7536937416666666
0.012305386274436092
[0.74141863 0.77191915]
평균이 0.75이고 표준 편차가 낮으므로 좋은 결과라고 할 수 있다.
정규화 회귀 분석
정규화 회귀 분석(Regularized regression)은 모델의 과적합을 방지하기 위해 사용되는 기법이다. 이 방법은 모델이 데이터에 너무 정확히 맞춰지는 것을 방지하여, 새로운 데이터에 대한 모델의 일반화 능력을 향상시킨다.
정규화의 필요성
- 목적: 선형 회귀 모델을 적합할 때, 과도하게 큰 계수 값이 생기지 않도록 하여 과적합을 방지한다.
- 방법: 손실 함수에 추가적인 패널티 항을 도입하여, 계수의 크기를 제한한다.
Ridge 회귀
- 정의: 계수의 제곱합에 비례하는 패널티를 손실 함수에 추가한다. 이 때 사용되는 상수를 알파라고 한다.
- 알파의 역할: 알파 값이 크면 클수록, 큰 계수에 대한 패널티가 커져 모델의 복잡도가 감소한다. 알파를 조절함으로써, 모델의 복잡성과 과적합 방지 사이의 균형을 찾을 수 있다.
Lasso 회귀
- 정의: 계수의 절대값 합에 비례하는 패널티를 손실 함수에 추가한다.
- 특성 선택: Lasso 회귀는 계수 중 일부를 정확히 0으로 만들어, 자동으로 변수 선택의 효과를 낸다. 이는 모델을 해석하기 쉽게 만들고, 모델의 복잡성을 줄인다.
- Ridge 회귀: 알파 값 0.5에서 모델을 적합시키면, 큰 계수에 대한 적절한 패널티를 통해 과적합을 방지할 수 있다.
- Lasso 회귀: 중요도가 낮은 특성의 계수를 0으로 줄이며, 중요 특성만을 선택하여 모델의 예측력을 유지하면서도 간결하게 만든다.
Ridge 회귀
다양한 알파 값에 대해 릿지 회귀 모델을 적합하고 점수를 출력한다. sales_df 데이터셋의 모든 특성을 사용하여 "sales"를 예측한다.
# Ridge 임포트
from sklearn.linear_model import Ridge
alphas = [0.1, 1.0, 10.0, 100.0, 1000.0, 10000.0]
ridge_scores = []
for alpha in alphas:
# Ridge 회귀 모델 생성
ridge = Ridge(alpha = alpha)
# 데이터 적합
ridge.fit(X_train, y_train)
# R-squared 얻기
score = ridge.score(X_test, y_test)
ridege_scores.append(score)
print(ridge_scores)output:
[0.9990152104759369, 0.9990152104759373, 0.9990152104759419, 0.9990152104759871, 0.9990152104764387, 0.9990152104809561]
여기서 알파 값이 커져도 R^2은 크게 변하지 않았다. 이는 데이터의 특성들이 판매량의 변동을 잘 설명하고 있으며, 계수에 페널티를 부여하여도 과소적합이 발생하지 않았다는 것을 의미한다.
특성 중요도를 위한 Lasso 회귀
라쏘 회귀 모델을 사용해 데이터셋에서 중요한 특성을 식별하는 방법을 살펴본다. 라쏘 회귀모델을 sales_df에 적합시키도, 모델의 계수를 플롯으로 나타낼 것이다.
# Lasso를 임포트
from sklearn.linear_model import Lasso
import matplotlib.pyplot as plt
# 라쏘 회귀 모델 인스턴스화
lasso = Lasso(alpha = 0.3)
# 데이터에 모델 적합
lasso.fit(X, y)
# 계수 계산 및 출력
lasso_coef = lasso.coef_
print(lasso_coef)
# 계수에 대한 막대 그래프 생성
sales_columns = ['TV', 'Radio', 'Newspaper', 'Social Media', 'Influencers']
plt.bar(sales_columns, lasso_coef)
plt.xticks(rotation=45)
plt.title("Feature Importance in Lasso Regression")
plt.xlabel("Features")
plt.ylabel("Coefficient Magnitude")
plt.show()[ 3.56256962 -0.00397035 0.00496385]
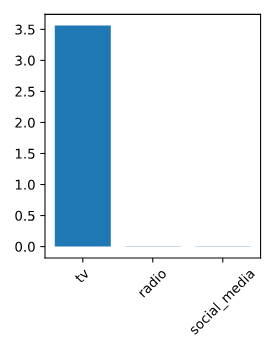
TV 광고 지출이 판매량 예측에 가장 중요한 특성으로 나타날 것으로 기대된다.
