
세로 방향으로 통합하기 - concat()
- 예전에는
append()를 사용했으나 pandas 1.4.0버전 이후로는 지원하지 않는다고 합니다.
import pandas as pd
import numpy as np
df1 = pd.DataFrame({
'Class1': [95, 92, 98, 100],
'Class2': [91, 93, 97, 99]})
df2= pd.DataFrame({
'Class1': [87, 89],
'Class2': [85, 90]})
result = pd.concat([df1, df2])
result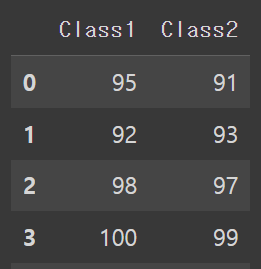
index 정렬하기
df3 = pd.DataFrame({
'Class1' : [96, 83]
})
pd.concat([result, df3], ignore_index=True)가로 방향으로 통합하기 - join()
df4 = pd.DataFrame({
'Class3' :[93, 91, 95, 98]
})
df1.join(df4)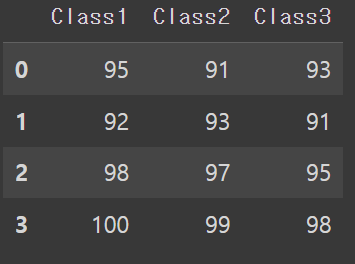
index 라벨을 지정한 DataFrame의 경우에도 index가 같으면 join을 이용해 가로 방향으로 데이터를 추가 할 수 있습니다.
df_A_B = pd.DataFrame({'판매월': ['1월', '2월', '3월', '4월'],
'제품A': [100, 150, 200, 130],
'제품B': [90, 110, 140, 170]})
df_C_D = pd.DataFrame({'판매월': ['1월', '2월', '3월', '4월'],
'제품C': [112, 141, 203, 134],
'제품D': [90, 110, 140, 170]})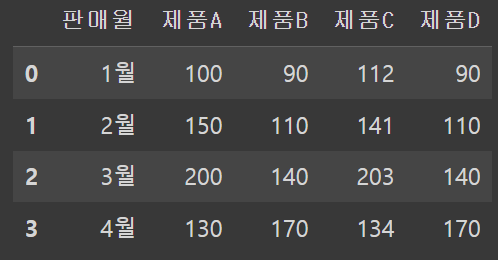
특정 열을 기준으로 통합하기
두 개의 DataFrame에 공통된 열이 있다면 이 열을 기준으로 두 데이터를 다음과 같이 통합할 수 있습니다.
DataFrame_left_data.merge(DataFrame_right_data)
df_A_B = pd.DataFrame({'판매월':['1월', '2월', '3월', '4월'], '제품A': [100, 150, 200, 130], '제품B': [90, 110, 140, 170]})
df_C_D = pd.DataFrame({'판매월':['1월', '2월', '3월', '4월'], '제품D': [90, 110, 140, 170], '제품B': [90, 110, 140, 170]})
print(df_A_B)
print(df_C_D)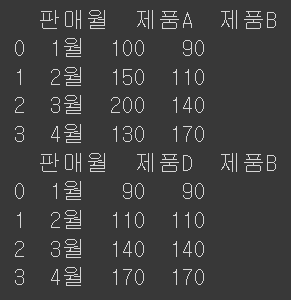
df_A_B.merge(df_C_D)
how 인자 변경
두 개의 데이터에서 특정 열의 일부 데이터는 공통이고 나머지는 한쪽에만 있습니다. how인자에 따라 어떻게 달라지는지 살펴보겠습니다.
df_left = pd.DataFrame({'key':['A','B','C'], 'left': [1, 2, 3]})
df_right = pd.DataFrame({'key':['A','B','D'], 'right': [4, 5, 6]})
df_left.merge(df_right, how='left', on = 'key')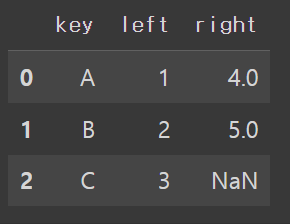
df_left.merge(df_right, how='right', on='key')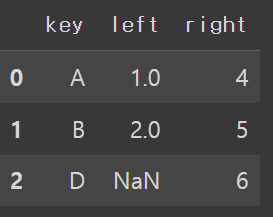
# Full Join
df_left.merge(df_right, how='outer', on='key') 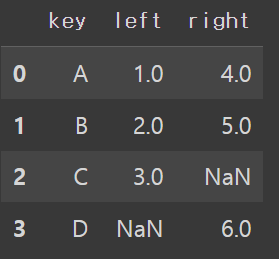
# 교집합
df_left.merge(df_right, how='inner', on='key') 
데이터 분석 공부중:)