디카프리오는 정말 살 수 없었나?
데이터 읽기
titanic_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/titanic.xls"
titanic = pd.read_excel(titanic_url)
titanic.head()
생존 상황
- autopct='%1.1f%%':소수점 첫째자리까지
- ax=ax[0] : 순서
- 0 : 사망 / 1 : 생존
f, ax = plt.subplots(1, 2, figsize=(16, 8))
titanic['survived'].value_counts().plot.pie(ax=ax[0], autopct='%1.1f%%', shadow=True, explode=[0, 0.05])
ax[0].set_title('Pie plot - survived')
ax[0].set_ylabel('')
sns.countplot(x='survived', data=titanic, ax=ax[1])
ax[1].set_title('count plot - survived')
plt.show()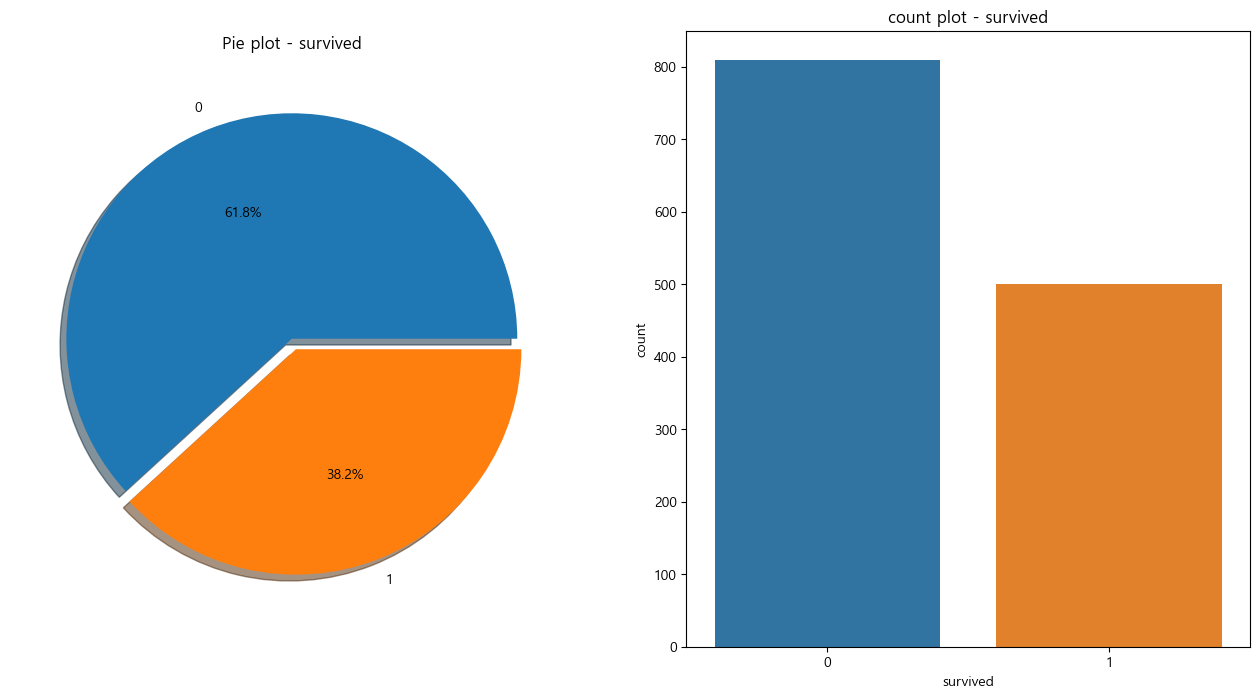
성별에 따른 생존 상황
f, ax = plt.subplots(1, 2, figsize=(16, 8))
sns.countplot(x='sex', data=titanic, ax=ax[0])
ax[0].set_title('Count of passengers of sex')
ax[0].set_ylabel('')
sns.countplot(x='sex', hue='survived', data=titanic, ax=ax[1])
ax[1].set_title('sex : survived')
plt.show()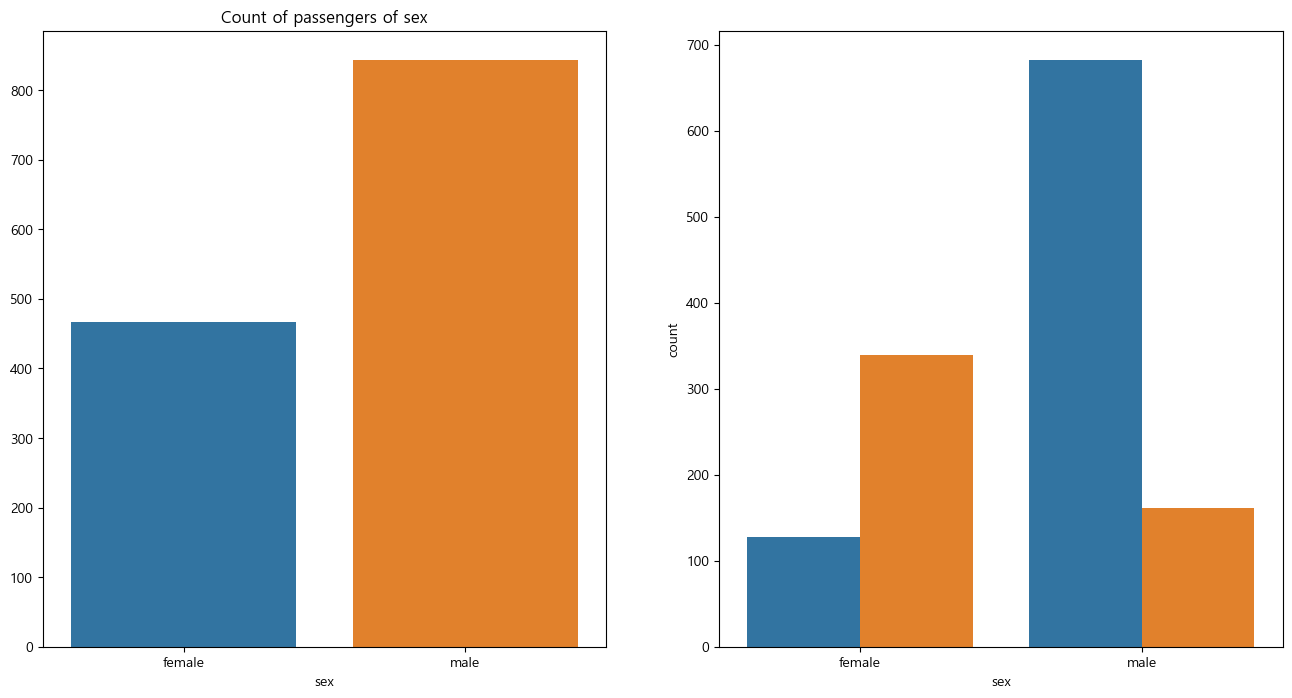
결론 : 남성의 생존 확률이 더 낮다
탑습 객실 등급 대비 생존률
- crosstab : 교차표 만들기
pd.crosstab(titanic['pclass'], titanic['survived'], margins=True)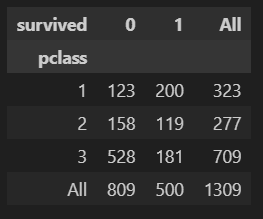
결론 : 객실 등급이 높을수록 생존률이 높다.
선실 등급별 성별 상황
grid = sns.FacetGrid(titanic, row='pclass',col='sex', height=4, aspect=2)
grid.map(plt.hist, 'age', alpha=0.8, bins=20)
grid.add_legend()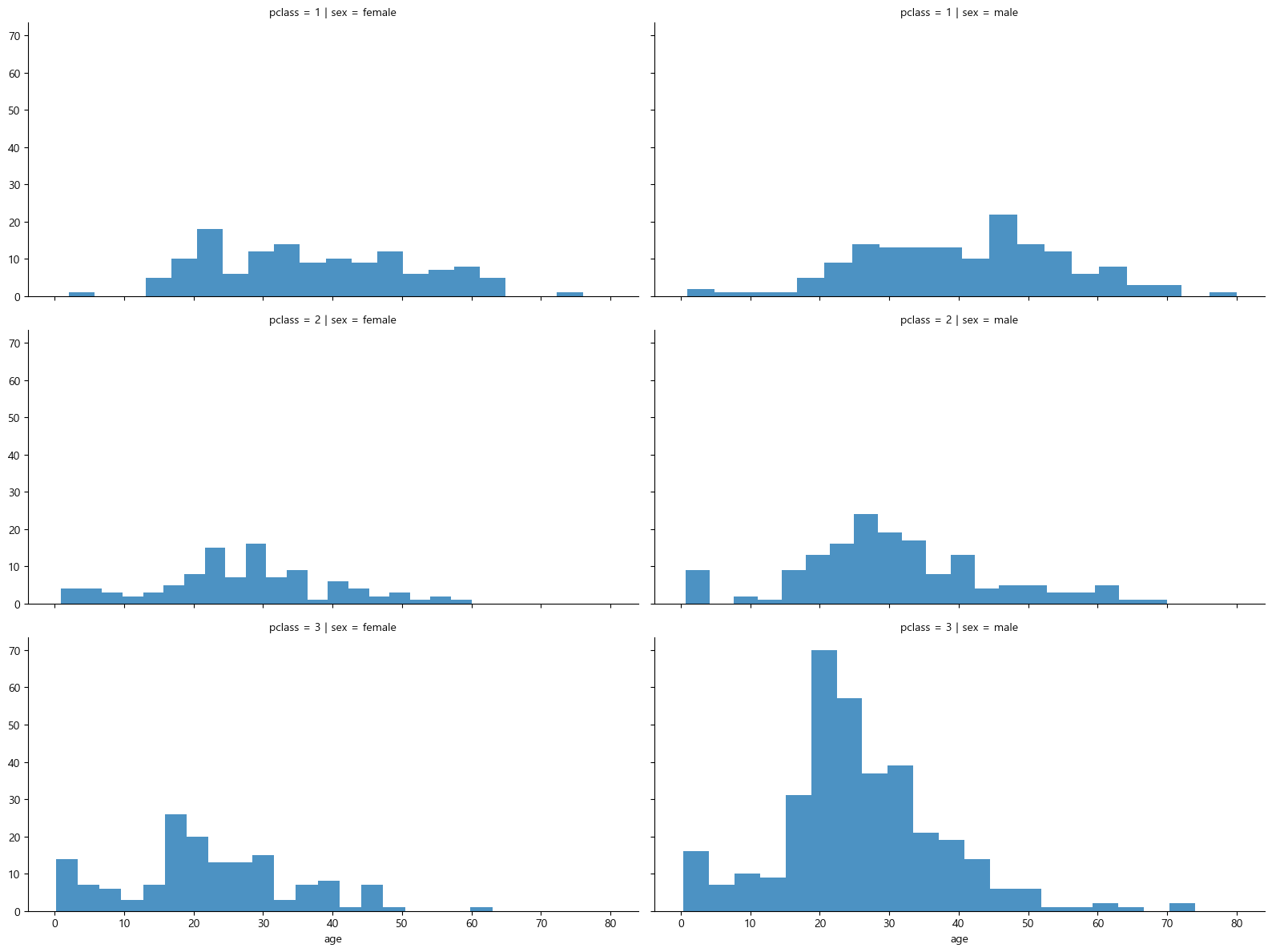
3등실에는 남성이 많았다. 특히 20대
나이별 승객 현황
import plotly.express as px
fig = px.histogram(titanic, x='age')
fig.show()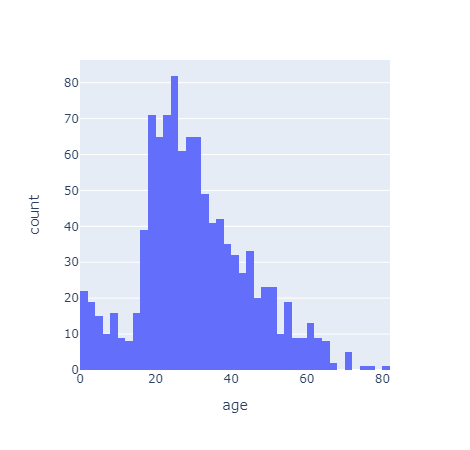
아이들과 20~30대가 많았다.
등실별 생존률을 연령별로 관찰하기
grid = sns.FacetGrid(titanic, row='pclass',col='survived', height=4, aspect=2)
grid.map(plt.hist, 'age', alpha=0.5, bins=20)
grid.add_legend();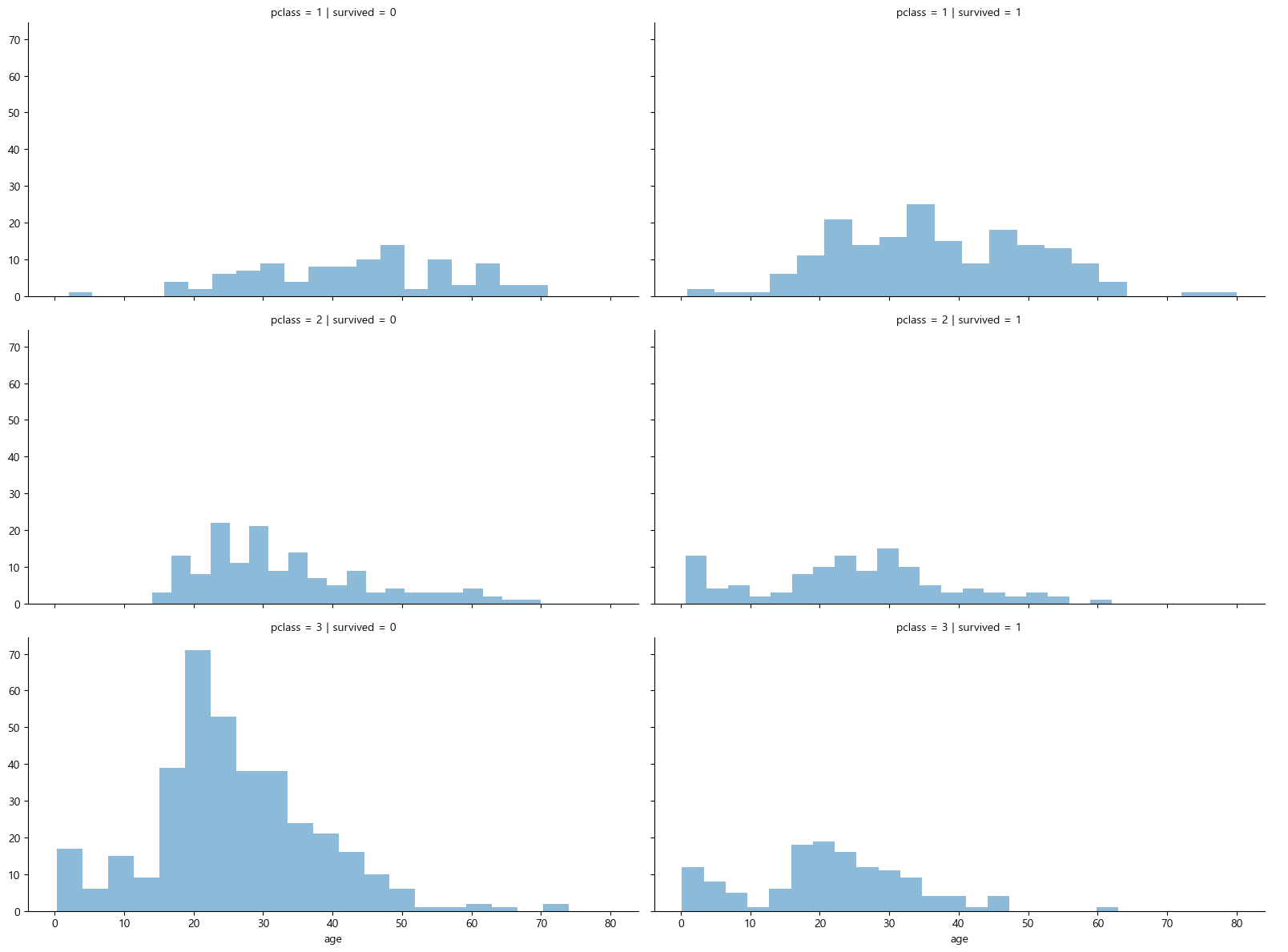
선실 등급이 높으면 생존률이 높은 듯 하다.
나이를 5단계로 정리하기
titanic['age_cat'] = pd.cut(titanic['age'], bins=[0, 7, 15, 30, 60, 100],
include_lowest=True,
labels=['baby', 'teen', 'young', 'adult', 'old'])
titanic.head()
나이, 성별, 등급별 생존자 수를 한 번에 파악하기
plt.figure(figsize=(14, 6))
plt.subplot(131)
sns.barplot(x='pclass', y='survived', data=titanic)
plt.subplot(132)
sns.barplot(x='age_cat', y='survived', data=titanic)
plt.subplot(133)
sns.barplot(x='sex', y='survived', data=titanic)
plt.show();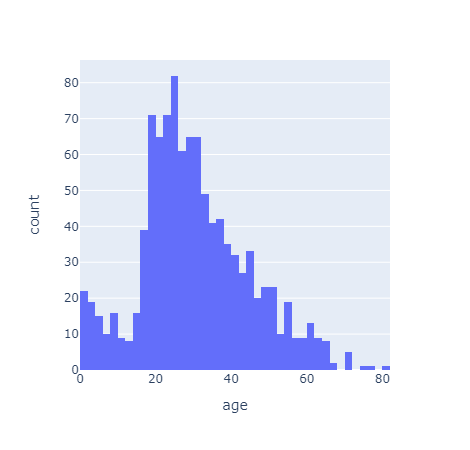
남,여 나이별 생존 상황 보다 더 들여보기
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 6))
women = titanic[titanic['sex'] == 'female']
men = titanic[titanic['sex'] == 'male']
ax = sns.histplot(women[women['survived']==1]['age'], bins=20,
label = 'survived', ax=axes[0], kde=False)
ax = sns.histplot(women[women['survived']==0]['age'], bins=40,
label = 'not_survived', ax=axes[0], kde=False)
ax.legend(); ax.set_title('Female')
ax = sns.histplot(men[men['survived']==1]['age'], bins=20,
label = 'survived', ax=axes[1], kde=False)
ax = sns.histplot(men[men['survived']==0]['age'], bins=40,
label = 'not_survived', ax=axes[1], kde=False)
ax.legend(); ax.set_title('Male')
plt.show()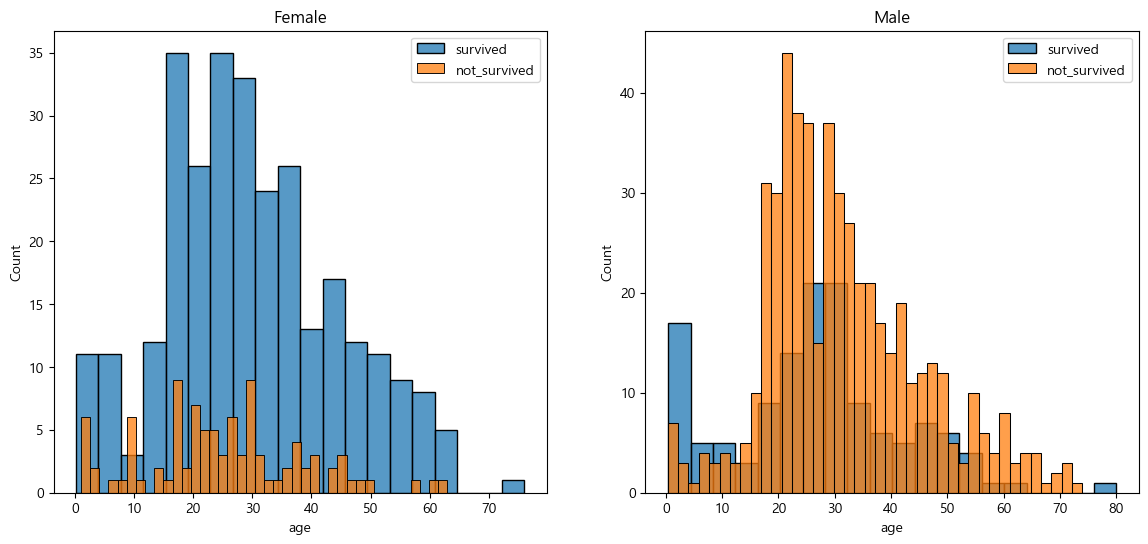
남성보다 여성의 생존률이 더 높고, 20~30대 여성, 남성 사망률이 높은 것으로 볼 수 있다.
탑승객의 이름에서 신분 정리하기
이름 확인하기
for idx, dataset in titanic.iterrows():
print(dataset['name'])
사회적 신분 얻고 데이터프레임에 넣기
- '\,\s\w+(\s\w+)?.' : 정규 표현식 패턴 (\ : 역슬레쉬)
- \, : 쉼표 ,와 일치
- \s : 공백 문자(스페이스, 탭 등)와 일치
- \w+ : 하나 이상의 단어 문자(알파벳 문자, 숫자, 밑줄)와 일치
- (\s\w+)? : 공백 문자 뒤에 하나 이상의 단어 문자가 올 수 있으며, 이 전체 부분은 선택적(있어도 되고 없어도 됨).
- . : 마침표 .와 일치
- ex) ", word." 또는 ", word word.
- group() : 일치하는 부분 문자열로 반환
import re
title = []
for idx, dataset in titanic.iterrows():
tmp = dataset['name']
title.append(re.search('\,\s\w+(\s\w+)?\.', tmp).group()[2:-1])
titanic['title'] = title
titanic.head()
성별별로 본 귀족
pd.crosstab(titanic['title'], titanic['sex'])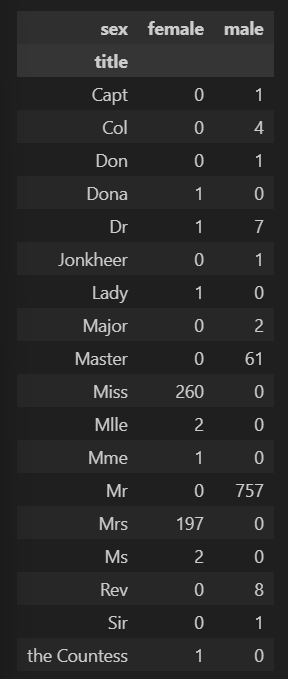
titanic['title'].unique()array(['Miss', 'Master', 'Mr', 'Mrs', 'Col', 'Mme', 'Dr', 'Major', 'Capt',
'Lady', 'Sir', 'Mlle', 'Dona', 'Jonkheer', 'the Countess', 'Don',
'Rev', 'Ms'], dtype=object)
사회적 신분 정리하기
titanic['title'] = titanic['title'].replace('Mlle', 'Miss')
titanic['title'] = titanic['title'].replace('Ms', 'Miss')
titanic['title'] = titanic['title'].replace('Mme', 'Mrs')
Rare_f = ['Dona', 'Lady', 'the Countess']
Rare_m = ['Capt', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Master']for each in Rare_f:
titanic['title'] = titanic['title'].replace(each, 'Rare_f')
for each in Rare_m:
titanic['title'] = titanic['title'].replace(each, 'Rare_m')for each in Rare_f:
titanic['title'] = titanic['title'].replace(each, 'Rare_f')
for each in Rare_m:
titanic['title'] = titanic['title'].replace(each, 'Rare_m')array(['Miss', 'Rare_m', 'Mr', 'Mrs', 'Rare_f'], dtype=object)
titanic[['title', 'survived']].groupby(['title'], as_index=False).mean()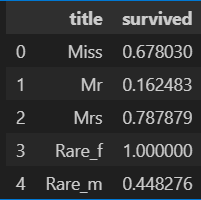
머신러닝을 이용한 생존자 예측
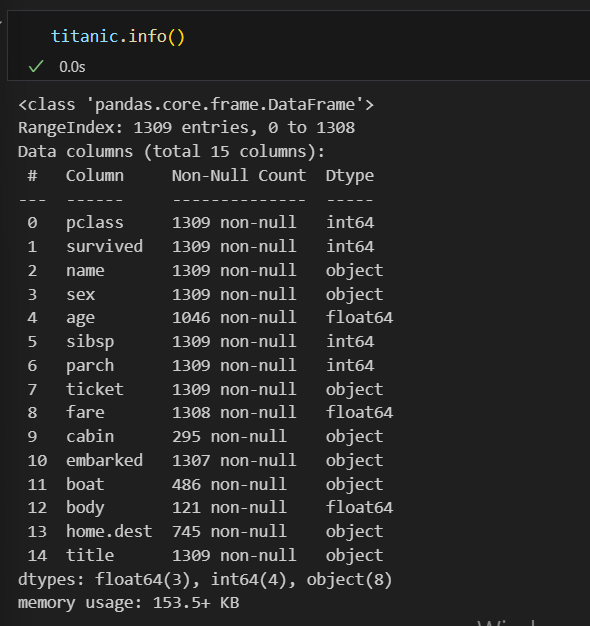
구조 확인하기
머신러닝을 위해 칼럼을 숫자로 바꾸기
- LabelEncoder : 문자를 숫자로 바꿔줌
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(titanic['sex'])le.classes_array(['female', 'male'], dtype=object)
titanic['gender'] = le.transform(titanic['sex'])
titanic.head()
결측지가 있지만 포기하고 notnull()만 추출하기
titanic = titanic[titanic['age'].notnull()]
titanic = titanic[titanic['fare'].notnull()]
titanic.info()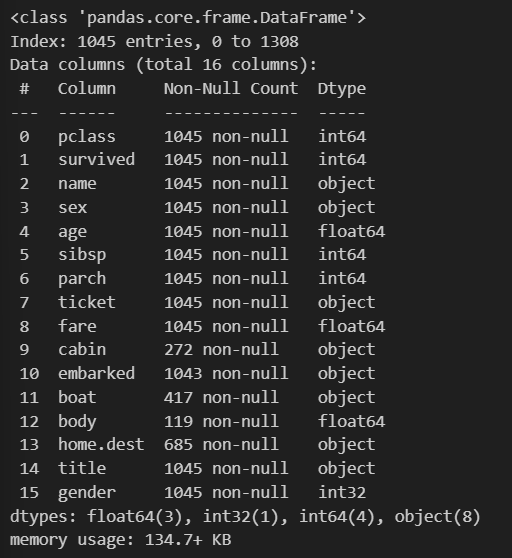
먼저 특성을 선택하고, 데이터 나누기
from sklearn.model_selection import train_test_split
X = titanic[['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender']]
y = titanic['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)decision tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier(max_depth=4, random_state=13)
dt.fit(X_train, y_train)pred = dt.predict(X_test)
print(accuracy_score(y_test, pred))0.7655502392344498
디카프리오 생존률은?
특정짓기
# 디카프리오
dicaprio = np.array([[3, 18, 0, 0, 5, 1]])
print('dicaprio : ', dt.predict_proba(dicaprio)[0, 1])dicaprio : 0.16728624535315986
# 윈슬릿
winslet = np.array([[1, 16, 1, 1, 100, 0]])
print('winslet : ', dt.predict_proba(winslet)[0,1])winslet : 1.0
"이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.”

데이터 공부 기록