
📕 개념
카이제곱 검정을 알기 전, 카이제곱 분포에 대해 알아야 한다.
📎 카이제곱 분포란?
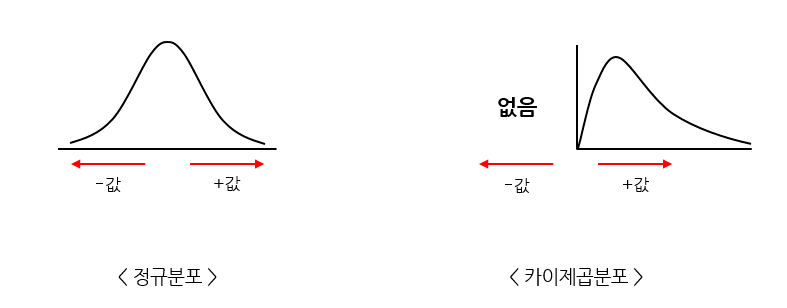
분산이 퍼져있는 모습을 분포로 만든 것이 카이제곱 분포이다.
카이제곱 분포는 집단의 분산을 추정하고 검정할 때 많이 사용하는데, 분산이라는 제곱된 값을 다루기 때문에 -값은 없고 항상 +값만 존재한다. 그렇기 때문에 정규분포와 비교하면 x의 값이 -인곳에는 그래프가 그려지지 않고 오른쪽으로 치우쳐진 모습을 볼수있다.
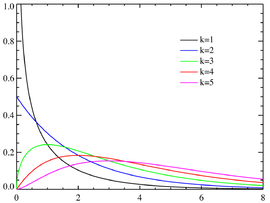
카이제곱 분포는 표본의 수에 따라 그래프의 모양이 달라진다. 여기서 카이제곱 표본 크기에 1을 뺀 값을 자유도(df)라고 한다. 자유도가 증가할수록 카이제곱 분포의 형태는 더 정규분포에 가까워지며, 표본 크기가 증가할수록 분포의 꼬리가 더 얇아지게 된다. 이는 중심극한정리에 따라 큰 표본 크기에서 카이제곱 분포가 정규분포에 수렴하기 때문이다. 위 그래프에서도 k값이 클수록 정규분포 모양에 가까워지는 것(오른쪽 꼬리의 구분이 없어지는 것)을 볼 수 있다.
📎 카이제곱 검정이란?
카이제곱 검정(Chi-squared test)은 카이제곱 분포에 기초한 통계적 방법이다.
카이제곱 검정은 이전 포스팅(클릭하면 이전 포스팅으로 이동)에서 언급했다 싶이, 독립변수로는 범주형, 종속변수로도 범주형변수를 사용하는 분석 방법이다.
카이제곱 검정은 관측된 빈도가 기대되는 빈도와 통계적으로 다른지를 평가하는 검정 방법 중 하나이다. 이 검정은 관측값과 기대값 간의 차이가 우연에 의한 것인지를 판단하는 데 도움된다.
카이제곱 검정의 기본 아이디어는 관측된 빈도와 기대되는 빈도 간의 차이를 검정 통계량으로 계산하고, 이를 자유도가 있는 카이제곱 분포와 비교하여 유의수준에서의 검정을 수행하는 것이다. 검정 통계량이 크면 관측값과 기대값 간의 차이가 크다는 것을 의미하며, 이는 두 변수 간의 관련성이나 분포의 부적합을 나타낼 수 있다.
카이제곱 검정의 목적
1) 독립성 : 두 범주형 변수 간에 관련성이 있는지(두 변수가 서로 독립인지) 여부를 알고자 할 때
2) 적합도 : 관찰된 비율 값이 기대값과 같은지 조사하는 검정 (어떤 모집단의 표본이 그 모집단을 대표하는지 검정)
3) 동질성 : 두 집단의 분포가 동일한지 여부를 알고자 할 때
카이제곱 검정에서 중요한 값
1) 자유도(df, Degrees of freedom) = n - 1 (n : 카이제곱 표본 크기)
2) Alpha level(α) = 0.05 or 0.01 (연구자에 의해 결정됨)
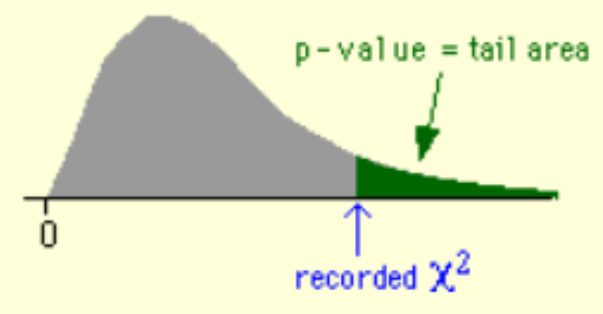
3) p-value = 카이제곱 검정 통계량과 자유도를 사용하여 p-value를 계산한다. 이는 카이제곱 분포의 누적 분포 함수(CDF)를 사용하여 계산할 수 있다.
아래의 그림은 p-value를 그림으로 나타낸 것이다.
p-value가 중요한 이유는 p-value를 통해 귀무가설을 채택할 것인지 기각할 것인지 결정하기 때문이다.
📎 카이제곱 검정의 장단점
장점
1. 유연성과 다양한 응용
카이제곱 검정은 범주형 데이터에 대한 분석에 널리 사용되며, 독립성 검정과 적합도 검정 등 다양한 상황에서 유용하게 적용될 수 있다.
2.비모수적인 특성
카이제곱 검정은 비모수적인 통계 검정 중 하나로, 특정 분포에 대한 가정을 필요로하지 않는다. 이는 데이터의 분포나 크기에 상대적으로 자유롭다는 장점을 제공한다.
3. 해석이 쉽다 검정 결과를 해석하기 쉽고 직관적이며, 통계적인 결과를 비전문가에게도 설명하기 용이하다.
단점
1. 적은 데이터에 대한 한계
카이제곱 검정은 작은 샘플 크기에서는 정확한 결과를 얻기 어렵다. 적은 데이터로는 검정력이 떨어져 통계적으로 유의미한 결과를 얻기 어려울 수 있다.
2. 관측값과 기대값의 제한
카이제곱 검정에서는 관측값과 기대값이 충분히 크고 작아야 하는 제한이 있다. 작은 셀 값이나 0에 가까운 값이 있을 경우 정확한 결과를 얻기 어려울 수 있다.
3. 범주형 데이터에 대한 제약
주로 범주형 데이터에 적용되며, 연속형 변수에 대한 적용이 제한적이다. 연속형 변수에 대한 분석에는 다른 검정 방법이 더 적합하다.
4. 독립성 가정
독립성 검정의 경우, 두 변수 간의 독립성 가정이 만족되어야 한다. 만약 변수 간에 상호작용이 있다면 다른 분석 방법을 고려해야 할 수 있다.
카이제곱 검정은 특히 범주형 데이터에 적용되는 강력하고 유용한 검정 방법이지만, 분석하려는 데이터의 특성과 목적에 따라 다른 통계적 방법도 고려해야 한다.
📕 종류와 실습
일반적으로 그룹이 한 개이면, 일원카이제곱 검정이라고 하고, 그룹이 두개이면 이원카이제곱 검정이라고 한다.
1. 일원카이제곱 검정
일원카이제곱은 범주형 변수가 한 가지로, 관찰도수가 기대도수에 일치하는지 검정한다. 적합도(선호도)를 검정 하며, 교차분할표 사용하지 않는다.
적합도 검정이란? 자연현상이나 각종 실험을 통해 관찰되는 도수들이 귀무가설 하의 분포(범주형 자료의 각 수준별 비율)에 얼마나 일치하는가에 대한 분석을 뜻하며, 관측값들이 어떤 이론적 분포를 따르고 있는지를 판단하는 검정으로 한 개의 요인을 대상으로 한다.
📎 코드 예시
다음 코드는 주사위게임의 기대치와 관찰치가 같을지에 대해 검정하는 코드이다. 가설은 다음과 같다.
귀무 : 기대치와 관찰치는 차이가 없다. 주사위는 게임에 적합하다.
대립 : 기대치와 관찰치는 차이가 있다. 주사위는 게임에 적합하지 않다.
import pandas as pd
import scipy.stats as stats
ob_sdata = [4,6,17,16,8,9]
result = stats.chisquare(ob_sdata)
print(result)
print('검정 통계량 : %.5f, p-value:%.5f'%(result))stats 라이브러리를 사용하여 일원카이제곱 검정을 수행할 수 있다.
이 코드에서 ob_sdata는 각 그룹에서의 관측도수를 포함하는 2차원 배열이다. chisquare 함수를 사용하여 검정을 수행하고, 결과로 관찰값, p-value, 자유도, 진행방향을 얻을 수 있다.
p-value를 통해 가설을 검정할 수 있다. 만약 p-value가 0.05(또는 0.01) 보다 작다면, 귀무가설을 기각하고, p-value가 0.05보다 크다면, 귀무가설을 기각하는것이다. 해석은 다음과 같다.
해석1(카이제곱 분포표) : df :(6-1), c.v : 11.07, chi2 = 14.2이므로 귀무 기각
해석2(p-value) : p-value:0.01439 < 0.05 이므로 귀무 기각
따라서 주사위는 게임에 적합하지 않다.
결국 위 검정은 관찰된 빈도가 기대되는 빈도와 유의한 차이가 있는지를 검증하는 것이다.
2. 이원카이제곱 검정
이원카이제곱검정은 두 개 이상의 집단(범주형 변인)을 대상으로 독립성, 동질성 검정한다.
독립성(관련성) 검정이란? 동일 집단의 두 변인을 대상으로 관련성이 있는가 없는가를 검정하는 방법으로, 두 변수 사이의 연관성을 검정한다.
동질성 검정이란? '두 집단의 분포가 동일한가?', '다른 분포인가?' 를 검증하는 방법이다. 두 집단 이상에서 각 범주(집단)간의 비율이 서로 동일한가를 검정하게 된다. 두 개 이상의 범주형 자료가 동일한 분포를 갖는 모집단에서 추출된 것인지 검정하는 방법이다.
📎 코드 예시
다음 코드는 교육수준과 흡연율 간의 관련성 분석하는 코드이다. 가설은 다음과 같다.
귀무 : 교육수준과 흡연율 간의 관련이 없다. (독립이다)
대립 : 교육수준과 흡연율 간에 관련이 있다. (독립이 아니다)
import pandas as pd
import scipy.stats as stats
data1 = pd.read_csv('../testdata/smoke.csv') # 표본 자료
print(data1.head(3),data1.shape) # (355행, 2열)
print(data1['education'].unique()) # 3개 -> 독립
print(data1['smoking'].unique()) # 3개 -> 종속
# 교차표 작성
ctab = pd.crosstab(index=data1['education'], columns=data1['smoking'])
ctab.index=['대학원졸','대졸','고졸']
ctab.columns = ['과흡연','보통','노담']
print(ctab)
# 결과 출력
chi2, p, dof, _ = stats.chi2_contingency(ctab)
print('chi2:{}, p:{}, dof:{}'.format(chi2, p, dof))이원카이제곱 검정은 일반적으로 교차분할표 사용한다.
scipy 라이브러리를 사용하여 이원카이제곱 검정을 수행할 수 있다.
이 코드에서 data1는 각 csv파일을 읽어온 데이터이다. crosstab을 이용하여 교차표를 작성하고, chisquare 함수를 사용하여 검정을 수행할 수 있다. 결과로 카이제곱 통계량, p-value, 자유도를 얻을 수 있다.
해석은 다음과 같다.
해석 : p 0.0008182 < 0.05 이기 때문에 유의미한 수준(알파=0.05)에서 귀무가설을 기각한다.
발생된 데이터는 우연히 발생된 자료가 아니다.
교육수준과 흡연율 간에 관련이 있다.
카이제곱 분포 이미지 : https://math100.tistory.com/44
카이제곱 분포 이미지 2 : https://ko.wikipedia.org/wiki/%EC%B9%B4%EC%9D%B4%EC%A0%9C%EA%B3%B1_%EB%B6%84%ED%8F%AC
참고 : https://bioinformaticsandme.tistory.com/139
