추론 전략 강화 (Reasoning Strategies)
LLM이 스스로 더 나은 추론 과정을 거치도록 돕는 기법들
Preview
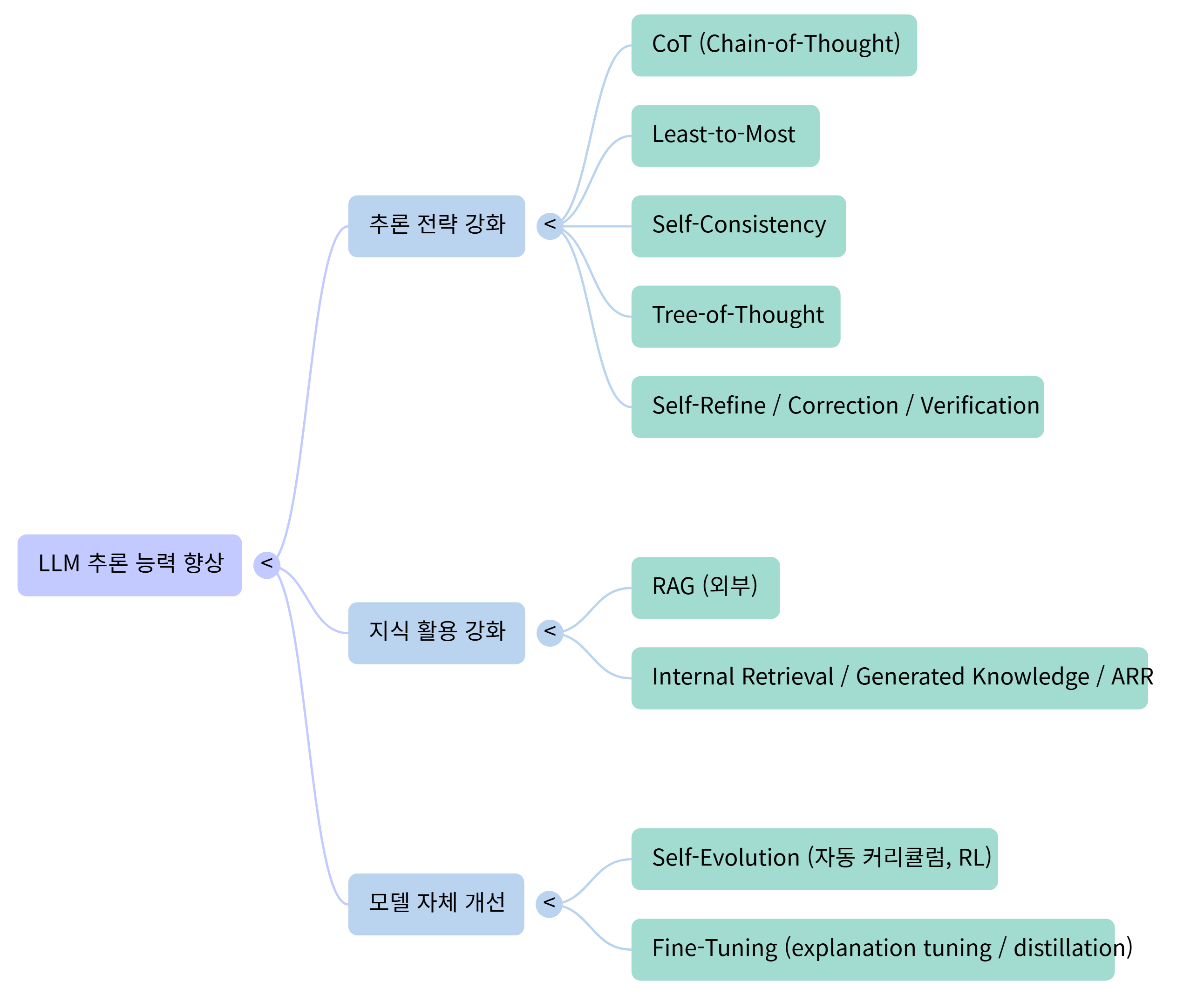
1. 추론 전략 강화 (문제 해결 방식 개선)
➡️ Chain-of-Thought (CoT)
- 핵심 아이디어: 중간 추론 과정을 모델이 출력하도록 유도 ("Let’s think step by step")
- 대표 논문: Jason Wei, Xuezhi Wang, Dale Schuurmans, et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS.
추가 사례: Takeshi Kojima, Shixiang Shane Gu, Machel Reid, et al. (2022). Large Language Models are Zero-Shot Reasoners. NeurIPS. - 적용 영역: 산수, 논리, 다단계 추론
- 장점: 간단한 텍스트 힌트만으로 효과적
- 한계: 복잡 문제에서는 중간 오류 가능
➡️ Least-to-Most (문제 분해)
- 핵심 아이디어: 어려운 문제를 작은 하위 과제로 나누어 순차 해결
- 대표 논문: Andy Zhou, Jiaming Song, Yilun Du, et al. (2023). Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. ICLR.
- 장점: 복잡한 추론 가능
- 한계: 분해 설계 필요, 프롬프트가 길어짐
➡️ Self-Consistency
- 핵심 아이디어: 여러 CoT 추론 경로를 생성하고 다수결로 정답 선택
- 대표 논문: Xuezhi Wang, Jason Wei, Dale Schuurmans, et al. (2023). Self-Consistency Improves Chain of Thought Reasoning in Language Models. ICLR.
- 장점: 안정된 정답 도출
- 한계: 비용 증가, 지속적으로 오답 추론 시 모델 개선 가능성 떨어짐
➡️ Tree-of-Thought (ToT)
- 핵심 아이디어: 사고의 분기와 백트래킹을 통한 탐색 기반 추론
- 대표 논문: Shunyu Yao, Dian Yu, Jeffrey Zhao, et al. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv preprint.
- 장점: 복잡한 문제에 유리함, 탐색적 사고가 가능함
- 한계: 탐색 비용, 탐색 정책 설계 필요
➡️ Self-Refine / Self-Correction / Self-Verification
□ Self-Refine: 모형이 초기 답을 재평가해 수정하도록 유도
대표 논문: Prakhar Madaan, Mohit Bansal, et al. (2023). Self-Refine: Iterative Refinement with Self-Feedback. arXiv preprint.
□ Self-Correction: "내 답이 맞는지 다시 생각해봐" 프롬프트로 오류 수정 시도
□ Verifier 모델: 별도 모델이 정답 검증
대표 논문: Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, et al. (2021). Training Verifiers to Solve Math Word Problems. arXiv preprint.
□ Self-Verification: 작성한 내용의 논리 간 정합성 검토
- 장점: 오류 감소, 신뢰도 증가
- 한계: 자기 오류 인식 부족, 잘못된 수정 가능성 존재
2. 지식 활용 강화 (정보 기반 증강)
➡️ Retrieval-Augmented Generation (RAG)
- 핵심 아이디어: 외부 문서에서 정보를 끌어와 답변 생성
- 대표 논문: Patrick Lewis, Ethan Perez, Aleksandra Piktus, et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS.
- 장점: 최신/정확 정보 활용 가능
- 한계: 불필요 정보 혼입 시 오류 발생
➡️ Internal Retrieval / Generated Knowledge
- 핵심 아이디어: 모델 내부 지식에서 정보를 생성하거나 끌어오기
- 대표 기법: Generated Knowledge Prompting
- 추가 사례: Yuwei Yin, Giuseppe Carenini (2025). ARR: Question Answering with Large Language Models via Analyzing, Retrieving, and Reasoning. arXiv preprint.
- 장점: 외부 연결 없이 정보 활용
- 한계: 내재 지식 오류 발생 가능성 존재
3. 모델 자체 개선 (학습 기반 접근)
➡️ Self-Evolution / RL 기반 개선
- 핵심 아이디어: 모델이 스스로 데이터 생성 및 스스로 학습 (curriculum training, self-training, RL 학습)
- 대표 사례:
1) Shuo Chen, et al. (2025). Self-Evolution of Large Language Models. arXiv preprint.
2) Chaofan Guan, et al. (2025). rSTAR-Math: Self-Training for Mathematical Reasoning in Large Language Models. arXiv preprint. - 장점: 모델 스스로 성능 향상
- 한계: 고비용, 잘못된 방향으로의 진화 위험 존재
➡️ 지도학습에 기반한 Fine-Tuning
- 핵심 아이디어: 설명 포함 데이터로 학습하거나 증류
대표 사례:
1) Jason Wei, et al. (2022). Finetuned Language Models Are Zero-Shot Learners (FLAN). arXiv preprint.
2) Andrew Lampinen, Ishita Dasgupta, et al. (2022). Can Language Models Learn from Explanations? A Formal Framework for Explanation-Based Learning. arXiv preprint. - 장점: 프롬프트 없이도 CoT 흉내 가능
- 한계: 일관성 없는 설명 가능성 존재
Main Content
1. 추론 전략 강화 (문제 해결 방식 개선)
① Chain-of-Thought (CoT)
② Least-to-Most (문제 분해)
③ Self-Consistency
④ Tree-of-Thought (ToT)
⑤ Self-Refine / Self-Correction / Self-Verification
1️⃣ Chain-of-Thought (CoT)
개념: 문제를 단계별로 풀도록 모델을 유도하는 기법
동작 원리: 프롬프트에서 “Let’s think step by step”과 같은 지시어를 주면, 모델이 답변을 도출하는 과정을 단계별로 나열
간단한 예시
- 프롬프트
Q: 철수에게 사과가 3개 있고, 영희가 2개를 더 주었습니다. 철수는 총 몇 개의 사과를 갖게 될까요?
Let's think step by step - 모델 응답 (CoT 출력)
1. 철수는 처음에 사과 3개를 갖고 있음.
2. 영희가 사과 2개를 줌.
3. 따라서 3 + 2 = 5.
Answer: 5 2️⃣ Least-to-Most (문제 분해)
개념: 어려운 문제를 작은 하위 문제로 나누어 단계적으로 해결
동작 원리: 프롬프트에서 모델이 먼저 문제를 나누고, 각 부분 문제를 푼 뒤 종합하도록 지시
간단한 예시
- 프롬프트
Q: 철수는 하루에 사과 2개를 먹습니다. 5일 동안 몇 개의 사과를 먹을까요?
문제를 작은 단계로 나누어 풀어보세요. - 모델 응답
1. 하루에 먹는 사과 개수 = 2개
2. 5일 동안의 총 일수 = 5일
3. 2 × 5 = 10개
Answer: 철수는 5일 동안 사과 10개를 먹습니다. 3️⃣ Self-Consistency
개념: CoT 추론을 여러 번 실행한 후, 다수결로 최종 답을 선택하는 기법
동작 원리:동일한 문제를 여러 번 프롬프트에 넣어, 여러 CoT 경로를 얻고 가장 많이 나온 답을 정답으로 결정.
간단한 예시
- 프롬프트 (동일한 질문을 여러 번 반복 실행)
Q: 35를 5로 나눈 값은 얼마입니까?
Let's think step by step. - 모델 응답 (예시 3회 실행)
[응답 1] 35 ÷ 5 = 7 → Answer: 7
[응답 2] 35 ÷ 5 = 7 → Answer: 7
[응답 3] 35 ÷ 5 = 8 (오답) → Answer: 8 - 최종 선택 (다수결)
Answer: 7 (1)사용자(또는 알고리즘)가 동일한 질문을 여러 번 모델에게 프롬프트로 넣음
즉, 샘플링(seed, temperature)을 달리해서 여러 Chain-of-Thought 응답을 얻음
(2) 그 결과를 모아서 각 응답이 낸 최종 정답을 카운트함
(3) 가장 많이 나온 정답을 최종 답으로 선택
"여러 CoT reasoning 경로를 돌려본 후 → 다수결"이라는 절차를 외부에서 알고리즘적으로 구현하는 방식
🔑 중요 포인트
▷ 프롬프트는 한 번, 여러 번 실행(샘플링) → 모델은 항상 CoT 방식으로 사고 경로를 보여줌
▷ Self-Consistency 기법은 "여러 응답을 수집하고 투표하는 절차"까지 포함된 프레임워크
▷ 따라서 단일 모델 호출로는 불가능하고, 반드시 여러 번 호출 후 집계하는 과정이 필요
4️⃣ Tree-of-Thought (ToT)
개념: 문제 해결 과정을 트리 구조로 확장하면서 여러 경로를 탐색하는 기법
Chain-of-Thought(CoT)가 직선적(Linear) 추론이라면,
Tree-of-Thought(ToT)는 분기(branching)와 탐색(search)을 결합한 기법
사람의 사고처럼 "한 문제에 대해 여러 가능성을 동시에 탐색하고, 불필요한 길은 버리고 유망한 길을 계속 확장"하는 아이디어
동작 원리: 답을 한 번에 고정하지 않고, 분기(branch)와 백트래킹을 통해 최적의 답을 탐색
간단한 예시
- 프롬프트
Q: 숫자 3을 두 번 더하고, 결과에 다시 2를 곱하면 얼마입니까?
사고 경로를 여러 가지로 탐색해보세요. - 모델 응답
경로 A: (3 + 3) = 6 → 6 × 2 = 12
경로 B: (3 × 2) = 6 → 6 + 3 = 9
→ 여러 경로를 탐색한 후, 문제 조건에 맞는 경로 A를 선택
Answer: 12 🔑 중요 포인트
-
비선형적 사고
CoT는 한 줄 추론 → ToT는 여러 후보 경로를 동시에 고려 -
탐색 알고리즘 필요
단순 모델 출력이 아니라, "탐색 정책"과 함께 돌아감
Ex: Beam Search, BFS, DFS, MCTS(Monte Carlo Tree Search) -
효율성과 비용 트레이드오프
분기를 많이 두면 해답 정확도 ↑, 하지만 비용 ↑
따라서 "가지치기(Pruning)"와 "휴리스틱 평가"가 핵심 -
적용 분야
수학 문제, 계획 수립, 게임 플레이(체스, 퍼즐), 경로 탐색 등 복잡한 다단계 추론에 강력
5️⃣ Self-Refine / Self-Correction / Self-Verification
개념: 모델이 스스로 자신의 답을 재검토·수정·검증하는 기법
LLM이 스스로 자신의 답변을 검토하고 개선하는 메타추론(meta-reasoning) 기법
동작 원리
(1) 답을 먼저 생성
(2) “내 답이 맞는지 다시 생각해봐” 같은 프롬프트를 통해 자기 검토
(3) 오류를 수정하거나 별도 검증 단계를 거쳐 최종 정답 도출
간단한 예시
- 프롬프트
Q: 12 ÷ 4 + 2 = ?
먼저 답을 구한 후, 다시 검토해보세요. - 모델 1차 응답
12 ÷ 4 = 3
3 + 2 = 5
Answer: 5 - 모델 자기검토 (Self-Refine)
검토: 12 ÷ 4는 3이 맞음.
그 후 3 + 2 = 5 → 최종 답은 5가 맞음.
Answer: 5 (검증 완료) Self-Refine = "내 답변을 더 다듬어 보자"
Self-Correction = "내 답이 틀렸을 수도 있으니 다시 계산해 보자"
Self-Verification = "내 답이 맞는지 제3자의 눈으로 검증하자"
🔑 중요 포인트

2. 지식 활용 강화 (정보 기반 증강)
① Retrieval-Augmented Generation (RAG)
② Internal Retrieval / Generated Knowledge
1️⃣ Retrieval-Augmented Generation (RAG)
개념:
LLM 한계: 사전 학습 데이터에 의존 → 최신 정보나 특정 도메인 지식 부족
RAG 아이디어: 외부 지식 베이스(예: DB, 검색엔진, 벡터스토어)에서 관련 문서를 검색 → LLM 입력에 결합 → 답변 생성
즉, **“검색(Search) + 생성(Generation)”**의 결합
특징
- 최신성 보장 (업데이트된 지식 반영 가능)
- 특정 도메인 지식 (법률, 의학, 기업 내부 문서)에도 적용 가능
- 검색 품질이 모델 성능을 좌우
동작 원리:
(1) 사용자가 질문 입력
→ "What is the capital of Canada?"
(2) Retriever: 외부 지식 베이스에서 관련 문서 검색
→ "Canada’s capital is Ottawa."
(3) LLM Input: 원래 질문 + 검색된 문서 결합
→ "Question: What is the capital of Canada?"
→ "Context: Canada's capital is Ottawa."
(4) LLM Output: "The capital of Canada is Ottawa."
즉, 질문 → 검색 → 문맥 주입 → 답변 생성 흐름
간단한 예시
사용자 질문: "Explain what ARR method is in QA with LLMs."검색 단계: DB에서 관련 논문 초록 검색 → "ARR: Analyzing, Retrieving, and Reasoning for QA (Yin & Carenini, 2025)."LLM 응답: "ARR is a framework that first analyzes the query, retrieves relevant information, and then reasons over it to generate accurate answers."2️⃣ Internal Retrieval / Generated Knowledge
개념: 외부 지식 검색 대신, 모델이 내부 지식(파라미터에 저장된 정보)이나 생성된 중간 지식을 스스로 활용하는 방법
즉, LLM이 스스로 아는 내용을 꺼내거나 만들어내서 답변에 활용하는 전략
동작 원리
(1) 사용자 질문 입력
→ "Why is the sky blue?"
(2) 분석 단계: 질문에서 필요한 개념 식별 → "light scattering, atmosphere"
(3) 내부 검색/생성: 모델이 자체적으로 관련 지식 생성
→ "Rayleigh scattering occurs when light interacts with small particles in the atmosphere."
(4) 최종 답변: "The sky looks blue because shorter wavelengths (blue light) scatter more than longer wavelengths."
즉, 질문 → 내부 지식 생성/검색 → 답변 조합 흐름
간단한 예시:
사용자 질문: "What is ARR in question answering?"[LLM 내부 단계]
분석: "ARR = Analyze, Retrieve, Reason"
지식 생성: "It was proposed in 2025 as a new framework for QA."최종 응답: "ARR is a framework (Yin & Carenini, 2025) that improves QA by analyzing the query, retrieving relevant knowledge, and reasoning over it."3. 모델 자체 개선 (학습 기반 접근)
① Self-Evolution / RL(Reinforcement Learning) 기반 개선
② 지도학습에 기반한 Fine-Tuning
1️⃣ Self-Evolution / RL(Reinforcement Learning)기반 개선
개념:
[Self-Evolution]
- 모델이 스스로 새로운 학습 데이터를 생성하여 점진적으로 성능을 높이는 방식
- 전통적 지도학습은 외부 데이터에 의존하지만, Self-Evolution은 모델이 자신의 오류나 약점을 보완하는 새로운 학습 샘플을 직접 생산
- 학습 과정에서 모델은 스스로 문제를 변형하거나 새로 변형된 문제-해답 쌍을 만들어 학습 효율을 높임
[RL 기반 개선(Reinforcement Learning)]
- 보상 신호를 통해 모델의 출력을 조정하는 방식
- RLHF(Reinforcement Learning from Human Feedback): 인간 평가자가 모델 출력에 대해 보상/벌점을 주어 학습
- RLAIF(Reinforcement Learning from AI Feedback): 보상 신호를 인간 대신 다른 모델(예: 평가 모델)이 제공
- 최근에는 Curriculum RL, Direct Preference Optimization(DPO) 등 안정화된 대체 기법이 제안됨
※ cf
Curriculum RL: Curriculum Learning + Reinforcement Learning을 결합한 개념
사람도 어려운 문제를 한 번에 배우지 않고 → 쉬운 것부터 점차 난이도를 올리듯이, 모델에게도 난이도를 점진적으로 높이는 학습 순서(커리큘럼)를 주는 방식Direct Preference Optimization(DPO): RLHF(PPO 기반)의 복잡한 학습 과정을 단순화한 신규 방법론(2023 Stanford 제안)
“굳이 RL 보상 모델 + 샘플링 → PPO 업데이트” 같은 복잡한 파이프라인 말고,
선호도 데이터만으로 직접 모델 파라미터를 업데이트하자는 것
→ 데이터 준비: 같은 질문에 대해 "좋은 답변(A)"과 "나쁜 답변(B)"을 페어로 수집
→ 선호 비교: 보상 모델 없이 직접 "A는 B보다 더 낫다"라는 Preference 데이터만 사용
→ Loss 함수 정의: 모델이 "좋은 답변"의 확률을 높이고 "나쁜 답변"의 확률을 낮추도록 최적화
RLHF = 전체 프로세스
PPO = 그 안에서 쓰이는 강화학습 기법(알고리즘)
PPO(Proximal Policy Optimization)는 RLHF 안에서 사용되는 최적화 알고리즘
RLHF 내부 단계:
→ Supervised Fine-Tuning (SFT) – 사람이 직접 쓴 답변으로 기본 모델 학습
→ Reward Model 학습 – 사람이 선택한 선호 데이터를 학습해 "채점기" 구축
→ RL 최적화 – 정책(LLM)을 보상 모델 점수에 맞게 조정
이 단계에서 쓰이는 알고리즘 중 하나가 바로 PPO
PPO (Proximal Policy Optimization)
→ OpenAI가 만든 정책 경사 강화학습 알고리즘
→ 기존 RL 알고리즘들(예: TRPO)에 비해 안정적이고 계산 효율성이 높아서 RLHF에서 사실상 표준(default)처럼 쓰임동작 원리
-
[Self-Evolution 흐름]
문제 입력: 모델이 새로운 입력(예: 수학 문제, 논리 문제)을 받음
기존 모델 출력: 모델이 초기 답안을 생성
성능 평가: 정답 데이터 또는 보상 모델이 해당 답변을 평가
데이터 증강: 모델이 스스로 새로운 문제 변형, 추가 힌트, 단계적 풀이를 생성
재학습: 기존 모델 파라미터를 업데이트 → 점차 강인한 모델로 진화. -
[RL 기반 흐름]
질문 입력: 사용자가 프롬프트를 입력
정책 모델(policy LLM)이 응답을 생성
보상 평가: 인간 피드백(HF) 또는 AI 평가(AIF)에 따라 점수화
정책 업데이트: PPO(Proximal Policy Optimization) 등 RL 알고리즘을 활용해 파라미터 조정
성능 향상: 반복 학습을 통해 바람직한 응답 패턴이 강화됨
간단한 예시
질문: "What is 23 × 47?"초기 출력: "1081" (오답)- Self-Evolution:
(1) 모델이 "23×40 + 23×7"과 같은 새로운 풀이 경로를 스스로 제안
(2) 잘못된 결과를 보완하며 재학습
- RL 기반 보상:
(1) 보상 모델이 정답 여부 확인 → 낮은 점수 부여
(2) PPO 학습으로 이후 유사 문제에서 올바른 풀이 경로를 더 자주 출력🔑 중요 포인트
- Self-Evolution은 데이터 부족 문제를 해결하는 핵심적 방법
- RL 기반 학습은 안전성·사용자 선호도 반영에 강점이 있으나, 보상 모델 설계의 어려움과 훈련 비용 증가라는 한계 존재
2️⃣ 지도학습에 기반한 Fine-Tuning
개념: Fine-Tuning은 사전학습된 대규모 언어모델(LLM)에 대해 추가적인 지도학습 데이터를 제공하여 특정 태스크, 도메인, 혹은 추론 방식에 최적화하는 기법
종류:
(1) Task-Specific Fine-Tuning: 특정 작업(예: QA, 요약)에 맞춰 재학습
(2) Instruction Tuning: 다양한 명령어를 학습시켜 제로샷/퓨샷 능력 강화
(3) Explanation/CoT Tuning: Chain-of-Thought 과정이 포함된 데이터로 훈련 → 추론 능력 내재화
동작 원리
(1) 데이터 구축:
→ 입력: 문제 또는 프롬프트
→ 출력: 정답 + 중간 추론 과정(Chain-of-Thought)
예: (문제) "12개의 사과를 4명이 나누면?"
(출력) "12 ÷ 4 = 3, 따라서 3"(2) 모델 학습:
→ Cross-Entropy Loss 기반 지도학습
→ 기존 언어모델 파라미터를 미세 조정
(3) 추론 단계:
→ 새로운 입력에서도 CoT 스타일 응답을 자연스럽게 생성
간단한 예시
학습 데이터:
→ 입력: "If you have 15 candies and you share them equally among 5 friends, how many each?"
→ 출력: "15 ÷ 5 = 3. Each friend gets 3 candies."Fine-tuned 모델 응답:
"Each person gets 3, because 15 divided by 5 equals 3."
👉 프롬프트에 "Let's think step by step"을 붙이지 않아도, 이미 CoT가 내재된 모델이 자연스럽게 추론 경로를 출력한다.
🔑 중요 포인트
- Fine-Tuning은 프롬프트 의존도를 줄이고, 모델 자체에 추론 습관을 내재화할 수 있음
- 하지만 데이터 준비 비용, 도메인 편향 위험이 존재함
- Instruction-Tuned 모델(예: FLAN-T5)은 제로샷에서 성능을 크게 끌어올리며, CoT Fine-Tuning은 수학·논리 문제에서 비약적 성능 향상을 보였음
Conclusion
-
추론 강화 (Reasoning Enhancement)
기법: Chain-of-Thought, Self-Consistency, Tree-of-Thought 기여: 구조적 추론 강화, 복잡한 문제 분해, 안정적인 추론 보장 -
지식 증강 (Knowledge Augmentation)
기법: Retrieval-Augmented Generation (RAG), Internal Retrieval, Generated Knowledge 기여: 외부·내부 지식 통합, 사실성 향상, 환각(hallucination) 완화 -
모델 최적화 (Model-level Optimization)
기법: RLHF (PPO, DPO), Self-Evolution, Fine-tuning 기여: 인간 선호와 정렬, 도메인 적응, 장기적 성능 향상
Final Insight
LLM 고도화는 추론 전략(reasoning strategies), 지식 통합(knowledge integration), 모델 최적화(model optimization) 의 세 가지 상호보완적 축을 통해 바라볼 수 있다.
앞으로의 발전은 세 가지 축을 하이브리드 방식으로 결합하는 데 있으며, 이를 통해 언어 모델은 단순한 응답 생성기를 넘어 신뢰할 수 있고, 적응하며, 지능적인 시스템으로 진화하게 될 것이라고 본다.
