
작성자 : 동덕여자대학교 정보통계학과 김민경!
(OP-GAN) Self-Supervised CycleGAN for Object-Preserving Image-to-Image Domain Adaptation
1. 요약
* 기존 GAN의 I2I에서의 한계
image-to-image translation에서 GAN 기반 방법(ex> CycleGAN, DiscoGAN 등)은 이미지의 object를 보존하는데 실패하는 경향이 있다.
따라서 domain adaptation 등의 task에 어려움이 있다.

- horse → zebra task에서 털 부분이 잘못 변환되거나 눈, 코같은 detail한 특징의 제거, blurry한 결과 등의 결과 발생하는 것을 볼 수 있다.
(출처 : Image-To-Image Translation Using a Cross-Domain Auto-Encoder and Decoder / https://www.mdpi.com/2076-3417/9/22/4780/htm)
(참고)
-
domain adaptation?
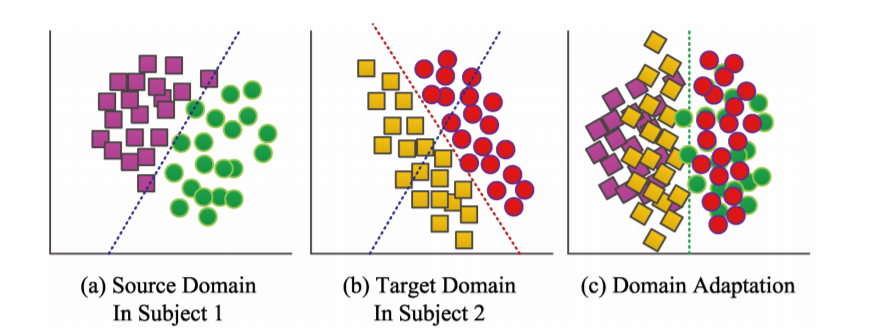
-
source domain : 학습에 사용되는 labeled data가있는 도메인
-
target domain : 분포가 다른 target task가 수행되는 도메인
=> 위 그림의 source domain과 target domain 간의 데이터 분포가 다르다고 가정하면,
domain adaptation은 주로 source 및 target domain에서 공통 특징을 학습하는 데 중점을 둔다.
(출처 : Multi-subject subspace alignment for non-stationary EEG-based emotion recognition)
* 제시된 해결 방안
content의 왜곡을 막기 위해 CycleGAN의 generator 부분에 (semantic) segmentation 네트워크를 적용하자는 아이디어 등장!
(참고)
(semantic) segmentation
: 이미지의 각 pixel이 어느 class에 속하는지 예측하는 것. pixel 단위의 annotation들이 같이 input으로 들어가야 한다.
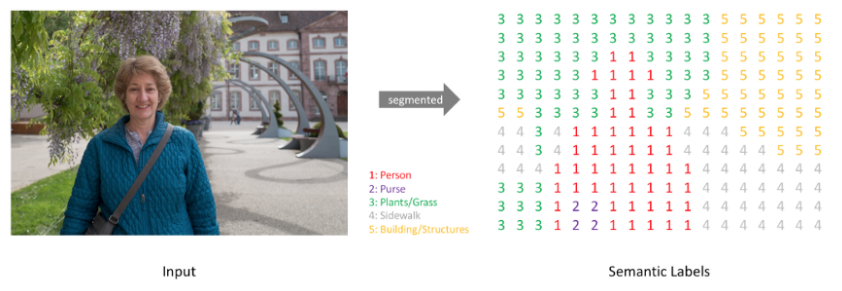
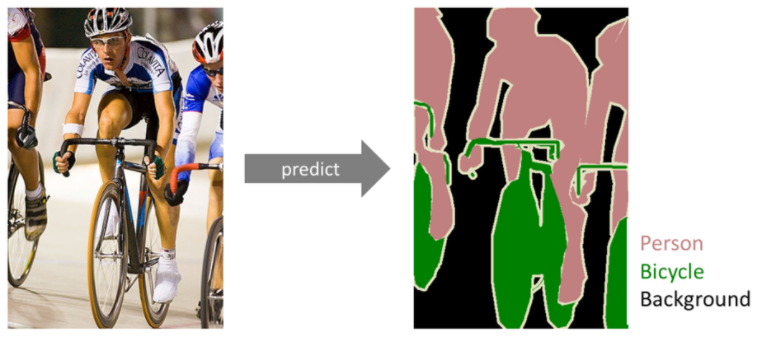
출처: https://bskyvision.com/491
(한계)
CycleGAN이 content 인식 변환을 수행할 수는 있지만 pixel 단위의 annotation이 필요하다. → cost 증가 :(
* OP-GAN 제안
pixel 단위의 annotation 없이 CycleGAN의 content consistency(일관성)를 향상시키기 위해 self-supervised를 포함했다.
2. CycleGAN 의 문제
- CycleGAN의 구조 (night-to-day 예시)
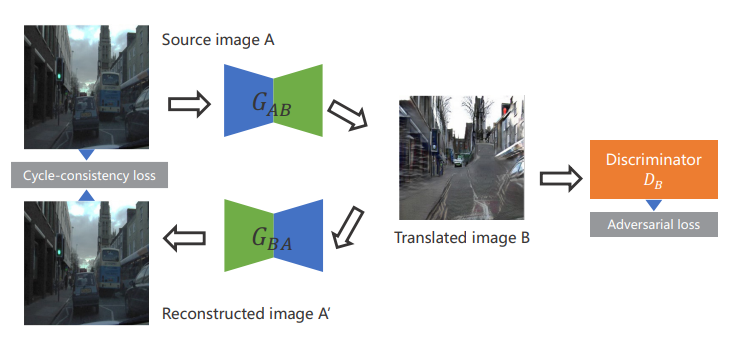
(CycleGAN의 구체적인 내용은 재윤님이 강의를 참고 해주세요ㅎㅎ)
Source image A (저녁 사진) → Translated image B (낮 사진) → Reconstructed image A' (저녁 사진)로 생성할 때,
input인 A와 생성한 A'가 비슷한지를 보는 것이 cycle-consistency loss이다.
덧붙이자면 A 도메인 → B 도메인의 단순 매핑이 아니라, 다시 복구되는 것도 고려해 원본이 유지되게끔 제약을 추가하는 것이다.
이 cycle-consistency loss는 A → B (또는 B → A) 사이의 직접적인 reconstruction loss가 없기 때문에
한 도메인에서 다른 도메인으로 변환할 때 object의 왜곡이 발생한다.
(참고) Translating and Segmenting Multimodal Medical Volumes with Cycle- and Shape-Consistency Generative Adversarial Network
3. OP-GAN
- CycleGAN과 동일하게 unpaired I2I translation 하기 위해 adversarial loss와 cycle-consistency loss를 사용했다.
- CycleGAN과 동일한 generators ()와 그에 상응하는 discriminators () 구조를 가진다.
- 이미지의 content를 보존하기 위해 multi-task self-supervised 샴 네트워크(S)를 추가했다.
- 샴 네트워크(S)의 input으로는 원래 이미지와 생성된 이미지를 받는다.
1) Self-supervised learning
(1) 먼저 원래 이미지와 생성된 이미지를 3 × 3 격자로 나눈다. (하나의 칸을 patch라고 한다.)

(2) training 동안 샴 네트워크의 input으로 할 2개의 patch 쌍을 random으로 선택한다.
- 이 논문에서는 2가지 가정을 한다.
- C1 같이 원래 이미지와 생성된 이미지의 같은 위치에서 나온 patch는 consistent(일관된) content를 가져야 한다.
- D1, D2 같이 같은 이미지에서 나온 patch는 비슷한 도메인 정보(ex> 빛의 밝기)를 가져야 한다.
따라서
두 patch의 상대적인 위치는 content 정보로 특징을 추출해내는 task를 supervision하는데 사용하고 (content registration)
두 patch의 출처 정보는 도메인 분류에 사용한다. (domain classification)
2) Network architecture
(참고)
<Siamese-Network(샴 네트워크) ?>
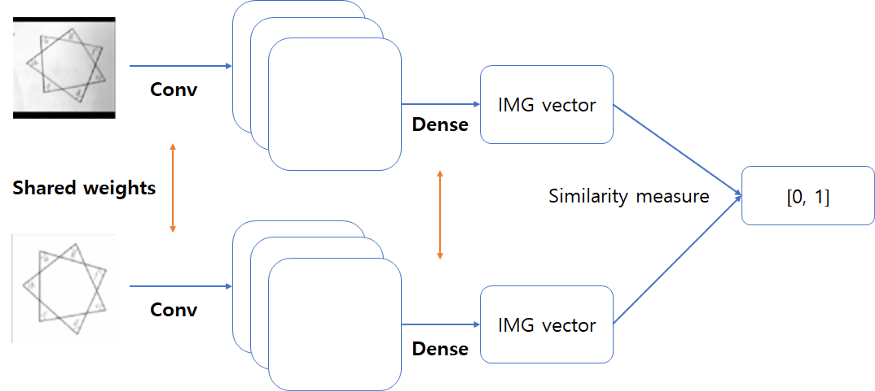
- 두 사진을 입력으로 받아서 두 이미지를 벡터화 시킨 이후, 두 벡터간의 유사도 (similarity in [0, 1]) 를 반환하는 네트워크
- 두 벡터 사이의 유사도는 보통은 유클리드 공간에서의 L2 거리를 이용하여 정의하는 경우가 많다.
- 입력을 받는 layer가 2개이고 각각 다른 이미지를 받는다.
- 특징을 학습하는 것보다는 두 이미지가 얼마나 다른지, 비교할 수 있는 능력을 가지게 됨.
(샴네트워크는 weight를 공유하는 두 네트워크로 구성된다. https://tyami.github.io/deep%20learning/Siamese-neural-networks/)
<이제 진짜 architecture>

- 샴 네트워크는 [weight를 공유하는 2개의 encoder] / [content registration 부분] / [domain classification 부분]으로 구성된다.
- optimization을 위한 2개의 loss가 있다.
- encoder
: input으로 들어간 patch(P)를 latent space(Z)로 임베딩하는 역할
: content와 도메인 정보가 있는 feature들을 분리하는 역할
: content 정보가 있는 disentangled features
: (11×11×512) feature map
: (1 × 1) conv layer를 거치고 content consistency loss 계산을 위해 input patch의 원래 크기로 보간된다.
: 도메인 정보가 있는 disentangled features
: (11×11×512) feature map
: concat되어 (11×11×1024) discriminative feature map이 생성되고 도메인 정보를 추출한다.- content registration 부분
: I2I domain adaptation 과정동안 patch content를 유지하는 것이 목표
: 이미지의 object의 모양과 위치를 나타내는 content attention map
(참고)
- attention ?
사람은 어떤 이미지를 볼 때, 전체를 보지않고 필요한 정보를 빠르게 얻기 위해 선택적으로 인지(selectively perceive)할 수 있는 능력이 있는데, 이를 attention이라고 한다.

- 그림에서 "어떤 게임을 하고있나?"라는 질문에 답을 하기 위해 이미지의 테니스 라켓 부분에 집중하고,
- "지면이 무엇인가?"라는 질문에 답을 하기 위해 이미지의 바닥 부분에 집중하는 것을 볼 수 있다.
- 같은 사진이 주어져도 질문에 따라 필요로 하는 정보가 다르기 때문에 집중하는 부분도 다른 것이다.
(출처 : [논문 요약 11/52] Human Attention in VQA: Do Humans and Deep Networks Look at the Same Regions?|작성자 hist0613)
3) Objective function
- 기존의 CycleGAN loss + self-supervised loss () 추가

1. [Content registration] → content consistency loss ()
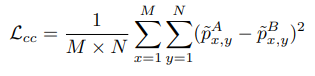
: domain adaptation task에서 content 왜곡을 최소화 즉, object의 모양과 위치를 유지하기 위한 제약
: 2개의 content attention maps 를 L2 norm에 사용
: 원본 이미지와 변환된 이미지 간의 content 불일치에 대해 pixel 단위의 penalty를 부과하므로 OP-GAN이 왜곡 없이 사실적인 결과를 합성할 수 있다.
- M과 N
: 각각 처리중인 patch의 width와 height - (x, y)
: attention maps 에서의 pixel 좌표
2. [Domain classification] → cross-entropy loss ()
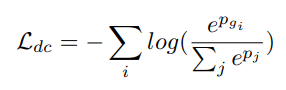

: 3개의 class 로 구성된 1-K classification를 공식화 했다.
: domain classification 부분은 주로 feature로부터 domain 정보를 추출해서 content
feature의 더 나은 disentanglement가 되도록 하는 것이 주 목표이다.
: class scores vecotor의 j번째 원소 (j ∈ [1, K], K는 class 수)
: i번째 input sample의 label
최종 Objective function

- 샴 네트워크 (S)와 는 먼저 를 optimize한다.
- 그 후 를 고정해서 샴 네트워크 (S)와 를 각각 optimize한다.
→ 그러므로 discriminator와 유사하게 샴 네트워크는 이미지 objects에 대한 정보를 generators에 직접 전달할 수 있다.
→ 이는 변환된 이미지의 object 보존이 잘 되게 한다.
4. 비교

- 기존 I2I adaptation frameworks는 원본 이미지와 변환된 이미지 간의 content 불일치에 대해 pixel 단위의 penalty가 없기 때문에 도로, 건물 등의 objects의 모양과 색상을 변경하는 등 이미지 content를 과도하게 수정하려 한다.
- 반면, OP-GAN은 이미지 objects를 보존하면서 cross domain adaptation이 잘 됐다.
5. 결론
- label로부터의 supervision 없이 image-to-image domain adaptation에서 objects를 보존하는 새로운 GAN인 OP-GAN을 제안했다.
MatchGAN: A Self-Supervised Semi-Supervised Conditional Generative Adversarial Network
1. 요약
* 기존 cGAN의 한계
cGAN은 합성 이미지의 생성과 조작 등에 유연함을 보이는 GAN이다.
그러나 많은 양의 annotated dataset이 요구된다. → 많은 cost
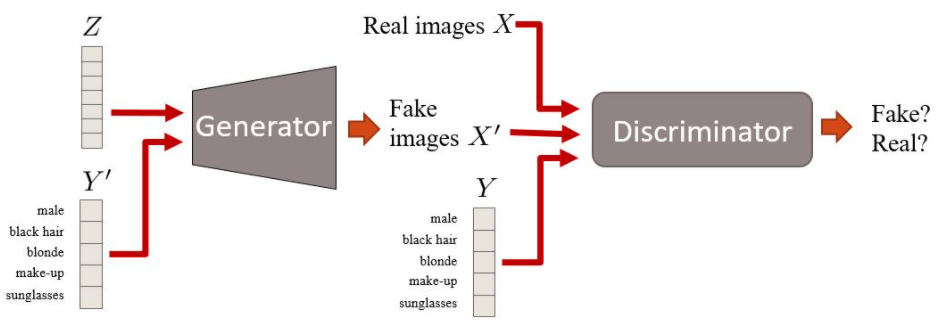
(출처 : https://guimperarnau.com/blog/2017/03/Fantastic-GANs-and-where-to-find-them#cGANs)
* 제시된 해결 방안
cGAN을 training하는데 많은 양의 annotated dataset 요구를 줄이기 위해 많은 연구에서는 pretext task를 설계할 때 self-supervised 방법을 도입했다.
그리고 대부분의 연구는 input image space의 geometric augmentations(기하학적 증강)에 집중했다.

(출처 : https://blog.insightdatascience.com/automl-for-data-augmentation-e87cf692c366 )
(한계)
위의 예시에서처럼 class label은 변경되지 않으면서 data augmentation이 되었다.
즉, 각 class label의 새로운 data들을 만들어낼 수 없다는 한계가 있다.
* MatchGAN 제안
self-supervised learning pretext task에서 data augmentation 방법으로 image space가 아닌 label space를 활용하자!
2. MatchGAN
: labelled data가 아주 적은 semi-supervised 상황에서 많은 cGAN을 training하기 위해 self-supervised learning을 적용한 네트워크
* pretext task
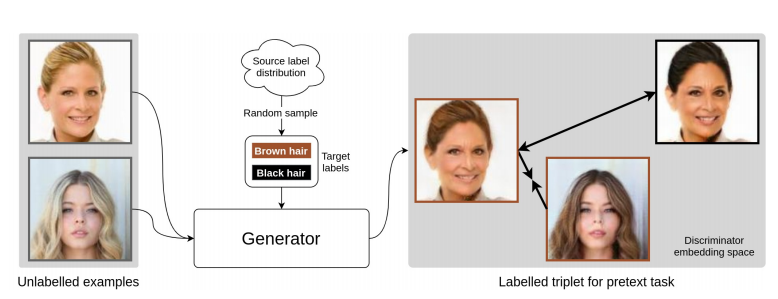
- labelled data의 label space로부터 분별 있는 label들을 랜덤으로 샘플링해서 brown hair, black hair 같은 target labels를 추출했다.
- 이 target labels와 labelled data의 분포와 동일한 분포로부터 나온 unlabelled data를 generator의 input으로 넣어 (합성된) 새로운 이미지를 생성해낸다.
(참고)
labelled data와 동일한 분포로부터 나온 unlabelled data가 주어지면 true source attribute label에 상관없이, 같은 target label이 할당된 경우 generator는 source image를 합성된 이미지 매니폴드의 비슷한 지역에 매핑해야 한다.(다른 target label이 할당된 경우에는 다른 지역으로 매핑한다.)
- generator에서 합성된 이미지는 target labels와 비교하여 동일한 label 정보를 공유하는 positive pairs와 다른 label 정보를 공유하는 negative pairs로 그룹화된다.
- positive, negative pairs 그룹을 분류하는 auxiliary match loss(triplet matching loss)를 최소화하는 것이 pretext task의 목적이다.
(참고)
triplet 같은 제약 조건을 적용하면 generator가 변환된 attributes에 대한 consistency 를 유지하도록하여 궁극적으로 합성된 이미지에서 attributes를 더 잘 유지할 수 있다.
* framework
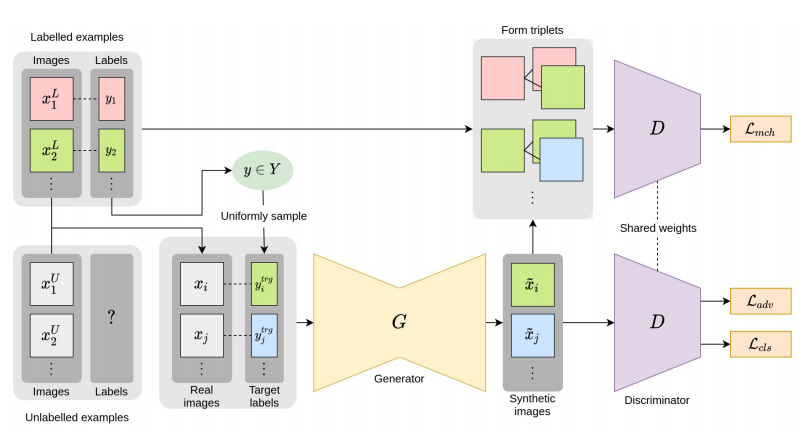
(본 논문에서는 starGAN을 baseline으로 했지만, 모든 cGAN에 적용될 수 있다고 한다.)
* Triplet Matching Objective as Pretext Task
- triplet 같은 제약 조건을 적용하면 generator가 변환된 attributes에 대한 consistency 를 유지하도록하여 궁극적으로 합성된 이미지에서 attributes를 더 잘 유지할 수 있다.
- 따라서 G와 D 모두에 대한 pretext task으로 label 정보를 기반으로 auxiliary match loss를 제안한다.
- triplet은 합성된 data () / 와 동일한 label 정보를 공유하는 positive example () / 와 다른 label을 공유하는 negative example ()로 구성된다.
starGAN의 objective function
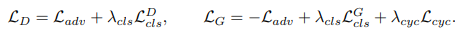
triplet matching objective
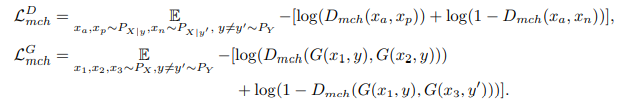
- standard triplet loss와 달리, 각각 channel 축을 따라 positive pair (, )와 negative pair (, )의 discriminator embeddings을 concat한다.
- 그리고 단일 convolutional layer을 통해 그들을 통과하고 각 pair에 대해 일치하는 label이 있는지 여부에 대한 확률 분포 와 을 생성한다.
최종 objective function
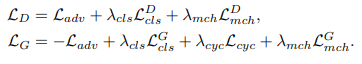
3. 비교

- 4번째 줄 surprised에서 남자 아이의 입 모양을 보면 MatchGAN의 결과가 baseline(starGAN)보다 덜 인위적이다.

- 4번째 줄 baseline(1%)에서 black hair 여성의 머리에 갈색의 점이 보인다.
=> MatchGAN이 덜 nosiy하며 덜 blurry하고 더 일관된 결과를 생성했다.
4. 결론
- MatchGAN은 합성된 이미지와 target labels를 추가적인 annotated data로 활용했고 pretext task로 triplet matching objective를 최소화했다.
Reference
- Self-Supervised CycleGAN for Object-Preserving Image-to-Image Domain Adaptation
- Image-To-Image Translation Using a Cross-Domain Auto-Encoder and Decoder
- https://www.mdpi.com/2076-3417/9/22/4780/htm
- Multi-subject subspace alignment for non-stationary EEG-based emotion recognition
- https://bskyvision.com/491
- Translating and Segmenting Multimodal Medical Volumes with Cycle- and Shape-Consistency Generative Adversarial Network
- https://medium.com/mathpresso/%EC%83%B4-%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC%EB%A5%BC-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EC%9D%B4%EB%AF%B8%EC%A7%80-%EA%B2%80%EC%83%89%EA%B8%B0%EB%8A%A5-%EB%A7%8C%EB%93%A4%EA%B8%B0-f2af4f9e312a
- https://tyami.github.io/deep%20learning/Siamese-neural-networks/
- [논문 요약 11/52] Human Attention in VQA: Do Humans and Deep Networks Look at the Same Regions?|작성자 hist0613
- https://guimperarnau.com/blog/2017/03/Fantastic-GANs-and-where-to-find-them#cGANs

8개의 댓글

14기 김상현
이번 강의는 self-supervised learning 관련 논문 리뷰로 OPGAN, MatchGAN에 대해 투빅스 14기 김민경님이 진행해주셨습니다.
OP-GAN
- cycleGAN의 문제점을 해결하기 위해 segmentation 네트워크를 적용하는 아이디어가 제안되었는데 이 경우 annotation에 비용이 증가하므로 annotation없이 self-supervised를 이용한다.
- cycleGAN 구조에 샴 네트워크를 추가해 patch쌍을 비교하여 content의 일관성을 유지시킨다.
- Loss는 를 추가한다. = + . 는 content attention maps에 L2-norm을 사용해서 계산되고, 는 domain classification으로 cross-entropy를 사용해서 계산된다. 즉, 해당 패치들이 같은 domain에서 나왔는지를 분류한다.
- Self-supervised learning을 이용하여 기존의 image-to-image translation 모델보다 좋은 성능을 갖을 수 있었다.
MatchGAN
- 기존의 cGAN의 경우 dataset이 모두 labeling이 되어있어야 하므로 비용이 많이 들었다. 이의 한계를 극복하기 위해 pretext-task를 통해 unlabelled data와 함께 학습시키는 matchGAN이 제안되었다.
- Pretext-task의 목적은 generator에서 합성된 이미지를 target labels와 비교하여 동일한 정보를 공유하는 positive pair와 다른 정보를 공유하는 negative pair 그룹화 되고, 이 그룹들을 분류하는 보조 auxiliary match loss를 최소화하는 것이다.
- Unlabelled 데이터를 함께 이용해 많은 양의 데이터를 이용해 학습할 수 있어서 기존의 cGAN 모델들 보다 덜 인위적이고, 덜 blury한 이미지를 생성할 수 있다.
Self-supervised learning을 이용한 GAN 모델인 OPGAN과 MatchGAN의 구조와 전반적인 이해를 할 수 있었습니다.
유익한 강의 감사합니다!
투빅스 14기 박지은
- OP-GAN은 Cycle GAN의 content consistency를 향상하기 위해 self-supervised를 포함하기 때문에, annotation이 필요없어서 cost가 증가하지 않습니다. adversarial loss와 cycle-consistency loss를 사용하고, 이미지의 content를 보존하기 위해 멀티 태스크 자기지도 샴 네트워크를 추가했습니다. 여기에 쓰이는 샴 네트워크는 특징을 학습하기보다 두 이미지가 얼마나 다른지 유사도를 비교하도록 학습하는 네트워크입니다.
- MatchGAN은 많은 양의 annotation이 요구되는 기존 CGAN에 pretext task 설계하는 방식을 도입했습니다. 이를 위해 데이터 증강을 하기 위해 이미지 space가 아니라 label space를 활용하였습니다. label이 있는 데이터의 label space에서 무작위로 샘플링한 후, target label을 추출합니다. 그러면 이 target label과 labelled data의 분포 같은 분포로부터 나온 label이 없는 데이터를 생성자에 넣어 새로운 이미지를 생성합니다.
이전에 배웠던 CGAN과 CycleGAN의 연장선으로, 비지도학습을 이용하는 개선안을 배울 수 있어서 유익한 시간이었습니다. 좋은 강의 감사합니다.

투빅스 14기 정재윤
이번 강의는 self-supervised learning에 관한 강의로 투빅스 14기 김민경님께서 진행해주셨습니다.
-
OP-GAN은 CycleGAN에 self supervised를 적용한 모델로 기존의 cycleGAN의 한계인 이미지의 object를 보전하는데 실패하는 경향을 개선하기 위해 만들어진 모델입니다. Content의 왜곡을 막기 위해 segmentation 네트워크를 적용하는 아이디어를 가져왔고, pixel 단위의 annotation없이 content consistency를 향상시키기 위해 self supervised를 제안했습니다.
-
OP-GAN에서 유의미하게 봐야할 부분은 두 patch의 상대적 위치는 content 정보로 특징을 추출하는 task를 supervision으로 사용하고, 출처 정보는 도메인 분류에 사용한다는 점이다. 또한 content consistency loss와 cross entropy loss 가 합쳐진 self supervised loss를 새롭게 제시했다는 점이다.
-
MatchGAN은 self supervised와 semi supervised를 CGAN에 적용한 모델이다. 즉, self supervised learning pretext task에서 data augmentation 방법으로 image space가 아닌 label space를 사용하는 것이다. 여기서 특이한 점은 triplet matching objective라는 loss 식을 제안했다는 점입니다. 기존의 standard triplet loss와 달리, 각각 channel 축을 따라 positive pair와 negative pair의 discriminator embedding을 concat한다는 점이다.
Self supervised learning을 이용한 OPGAN과 MatchGAN의 구조와 loss에 대해서 공부해볼 수 있었던 시간이었습니다. 감사합니다 😊

투빅스 13기 이예지:
이번 강의는 ‘Self-Supervised Learning 관련 논문 리뷰’로, 김민경님이 진행하였습니다.
Image2image translation에서 GAN의 한계
- 이미지의 object를 보존하는데 실패함
- Domain adaptation의 어려움
OP-GAN
- SSL를 사용하여 cycleGAN의 content consistency를 향상 시키고, domain adaptation을 향상시킴
- Source domain 이미지를 target domain 이미지로 생성할 떄, 원본을 유지할 수 있게끔 제약조건을 추가함
- 이를 위해 multi-task self supervised 샴 네트워크를 추가함
MatchGAN
- CGAN의 한계: 많은 양의 annotated dataset이 필요함
- image space가 아닌 label space 활용하여 분별있는 label들을 랜덤으로 샘플링함.
각 도메인의 문제점을 해결하기 위해 SSL을 활용한 연구를 배울 수 있었습니다.
좋은 강의 감사합니다 :)
투빅스 12기 김태한
이번 강의에서는 SSL방법으로 학습을 한 OP-GAN과 MatchGAN에 대하여 김민경님께서 세미나를 진행해 주셨습니다.
-
OP-GAN
기존의 I2I방법은 GAN을 통해 생성된 이미지를 온전히 보존하지 못하는 경향을 보입니다. 이를 보완하기 위하여 Cycle-GAN에서 segmentation 네트워크를 사용하였으나 pixel단위의 학습이 필요하여 OP-GAN이 등장하였습니다.
이러한 OP-GAN은 기존의 Cycle-GAN loss에 SSL loss를 추가하며 샴 네트워크를 사용하여 보다 좋은 성능을 보였습니다. -
Match-GAN
기존의 cGAN의 경우 학습데이터에 모두 label을 붙여주어야하는 수고가 필요했습니다. 그러나 pretext task로 label이 없는 데이터도 같이 학습시키는 방안으로 Match-GAN이 제안되었으며 생성된 이미지를 positive pair와 negative pair로 나눔으로써 보다 많은 양의 데이터를 학습할 수 있었고 이로인해 보다 좋은 성능을 나타낼 수 있었습니다.
어려운 내용임에도 불구하고 쉽세 좋은 강의 해주셔서 정말 감사합니다 :)

투빅스 14기 박준영
이번수업은 self-supervised learning으로 투빅스 14기 김민경님께서 진행해주셨습니다.
-
기존의 GAN은 image-to-image translation에서 object 변환에 문제가 있었다. 그래서 op-gan은 cyclegan 모형에 multi-task self-supervised를 추가하여 object변환 문제를 해결하고자 하였다.
-
op-gan은 패치로 원래의 이미지와 생성된 이미지를 나눈다, 그리고 2개의 패치 쌍을 random으로 input한다. 2개의 패치쌍의 상대적인 위치는 task를 supervision하는데 사용하고 출처정보는 도메인 분류에 사용한다.
-
multi-task self-supervised는 weight를 공유하는 2개의 인코더, content registration 부분, domain classification 부분으로 구성된다.
-
op-gan의 loss는 기존의 cyclegan loss+ self-supervised loss로 이루어지며 self-supervised loss는 content 왜곡을 최소하기 위한 loss와 cross-entropy loss로 이루어진다.
-
이러한 과정을 통해서 label로부터 supervision 없이 image-to-image translation에서 object문제를 해결할 수 있었다.
-
labelled data가 아주 적은 semi-supervised 상황에서 많은 cGAN을 training 하기 위해 self-supervised learning을 적용한 네트워크이다.
-
pretext task단계에서 labelled data의 space로 부터 분별 있는 label을 랜덤 샘플링해서 target label을 추출하고 target label과 labelled data의 분포와 같은 분포에서 나온 unlabelled data를 Generate input으로 넣어 새로운 이미지를 생성한다
-
G, D 모두에 대한 pretext task로 auxiliary match loss를 제안한다.
Self-supervised learning을 이용한 GAN 모델 OPGAN과 MatchGAN에 대해 배울 수 있었던 유익한 강의였습니다. 감사합니다.

투빅스 11기 이도연
Self-Supervised Learning과 관련된 논문 OP-GAN과 MatchGAN에 대한 강의로 기존에 공부했던 CycleGAN, CGAN에서 더 나아가 고민해 볼 수 있는 시간이었습니다. 감사합니다!!
- CycleGAN의 경우 학습 결과에서 detail한 특징이 제거되거나 blurry한 결과가 나타나는 등 content의 왜곡이 발생한다. 이를 막기 위해 CycleGAN의 Generator 부분에 Semantic Segmentation 네트워크를 적용했다. 이미지의 각 픽셀이 어느 class에 속하는지 예측함으로써 content의 왜곡을 줄였지만 pixel 단위의 annotaion이 필요하기 때문에 cost가 증가한다. 이에 OP-GAN은 pixel 단위의 annotation 없이 CycleGAN의 content consistency를 향상시키기 위해 Self-Supervised를 포함했다.
- CycleGAN의 cycle-consistency loss의 경우 A->B, B->A 의 직접적인 reconstruction loss가 없기 때문에 한 도메인에서 다른 도메인으로 변환할 때 object의 왜곡이 발생한다. 이미지의 content를 보존하기 위해 multi-task self-supervised siamese network (S)를 추가했다.
- S는 weight를 공유하는 2개의 encoder, content registration, domain classification으로 구성된다. encoder는 content와 domain을 분리하는 역할을 하고, content registration branch는 I2I domain adaptation 과정동안 content를 유지하는 역할을, domain classification branch는 domain 정보를 추출해서 content feature가 더 잘 disentanglement 되도록 하는 역할을 한다.
- CGAN을 학습시키는데 annotated dataset 요구를 줄이기 위해서 많은 연구에서 pretext task를 설계함에 있어 Self-Supervised 방법을 도입했다. 그리고 대부분은 image space의 augmentation에 집중했다. 그렇지만 이는 label은 변경되지 않으면서 augmentation 되어 각 label의 새로운 데이터를 만들어 낼 수 없다는 한계가 있다.
- MatchGAN에서는 data augmentation 방법으로 image space가 아닌 label space를 활용한다. 적은 labelled 데이터의 label space에서 랜덤으로 target label을 샘플링하고, unlabelled 데이터로부터 generator가 triplets을 생성한다. 생성된 이미지는 target label과 비교하여 동일한 label 정보를 공유하는 positive pairs, 다른 label을 공유하는 negative pairs로 그룹화된다. pretext task로 label 기반의 auxiliary match loss를 제안한다.
투빅스 14기 한유진
Self-Supervised Learning과 관련된 새로운 GAN을 배워볼수 있었던 의미있는 강의였습니다. 중간중간 참고자료들을 많이 적어주셔서 공부하는데 큰 도움이 되었습니다. 좋은 강의 감사합니다!