
작성자 : 신민정
Content
0. Intro
1. The Probelm : Graph Generation
2. Machine Learning for Graph Generation
3. GraphRNN : Generating Realistic Graphs
4. Applications and Open Questions
지난 강의에서는 Graph를 vector로 encoding하는 방법을 배웠습니다. Deep Graph Encoders
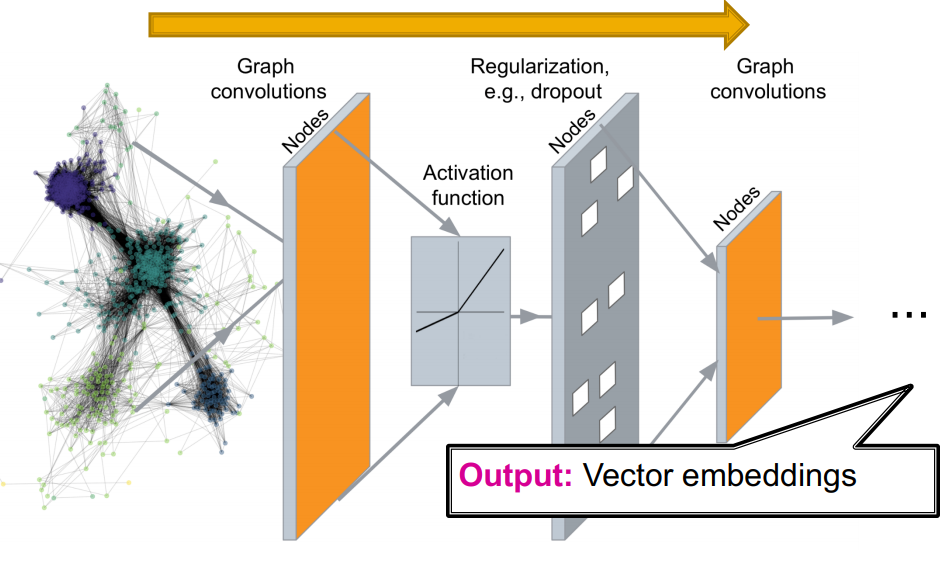
이번 강의에서는 graph를 generate하는 과정을 배우보겠습니다. Deep Graph Decoders
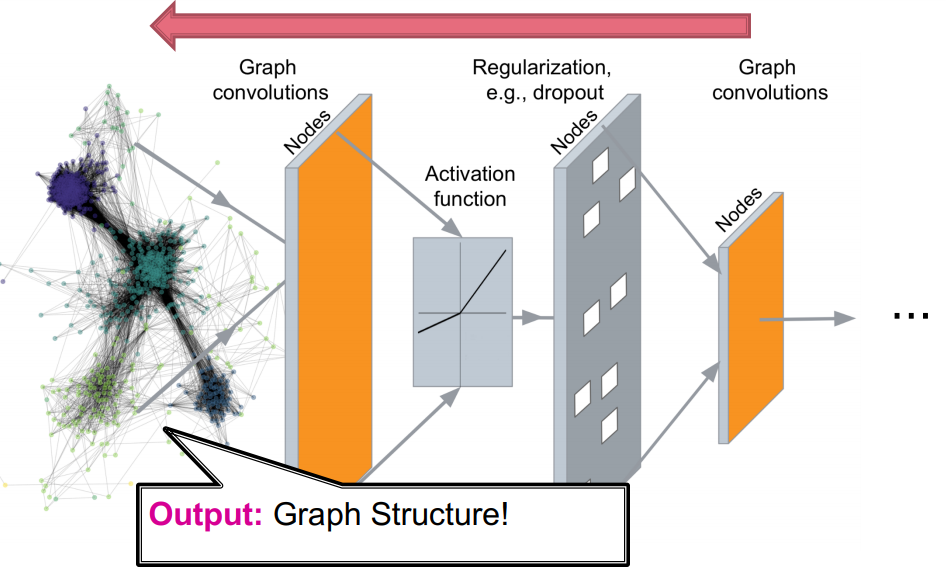
encoding된 vector으로 부터 grpah structure를 생성할 수 있습니다.
1. The Probelm : Graph Generation
graph generation의 목표는 realistic한 grpah를 생성하는 것입니다.

graph generation이 갖는 의의는 다음과 같습니다.
- Generation : graph 형성 과정에 대한 insight를 얻을 수 있습니다.
- Anomaly detection - 비정상적인 부분/동작이 발생하는 이유를 발견할 수 있습니다.
- Predictions - 과거로부터 미래를 예측할 수 있습니다.
- 새로운 구조를 발견할 수도 있습니다.
- Graph completion - many graphs are partially observed
- "What if" scenarios
graph generation의 목표에 따라 모델이 달라 질 수 있습니다.
Task1 : Realistic graph generation
->reference graph와 동일한(유사한) graph를 만들어야 합니다.
Task2 : Goal-directed graph generation
-> 주어진 조건과 제약에 맞게 graph를 만들어야 합니다. (예.Drug molecule generation/optimization)
이번 강의에서는 Task1 : Realistic graph generation에 대한 내용을 주로 다루겠습니다.
Graph Generation을 사용하는 task의 대표적인 예는 Drug Discovery입니다. 기존 분자 구조를 완성하여 desired property에 최적화된 새로운 약물을 발견할 수 있습니다.
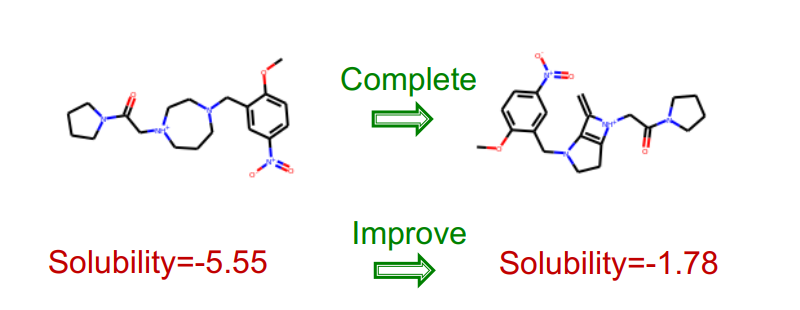
이외에도 Discovering novel sturctures, Network Science(Null momdels for realistic networks) 같은 분야에도 사용됩니다.
하지만, 그래프를 생성하는 작업은 그리 쉽지 않습니다.
Grpah Generation은 왜 어려울까요??
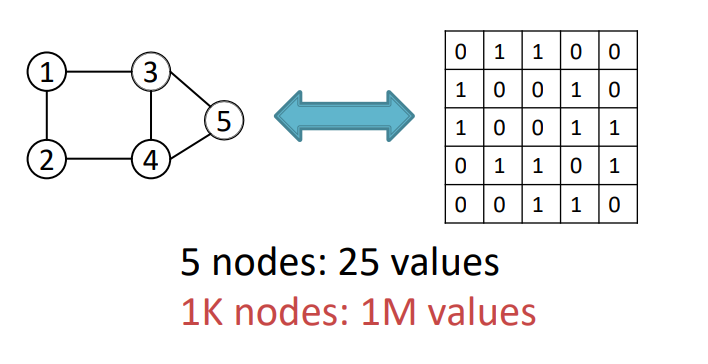
output space가 크고 다양하기 때문입니다. 개의 node를 위해 개의 값을 생성해야합니다. (인접행렬)
또한 7강에서 언급한 바와 같이, Graph의 표현은 고정되어있지 않습니다. 또한 정해진 순서도 없습니다. 같은 그래프이지만, node의 index가 다르면 다르게 표현되고, 이는 objective function으로 최적화하는데 어려움이 있습니다.
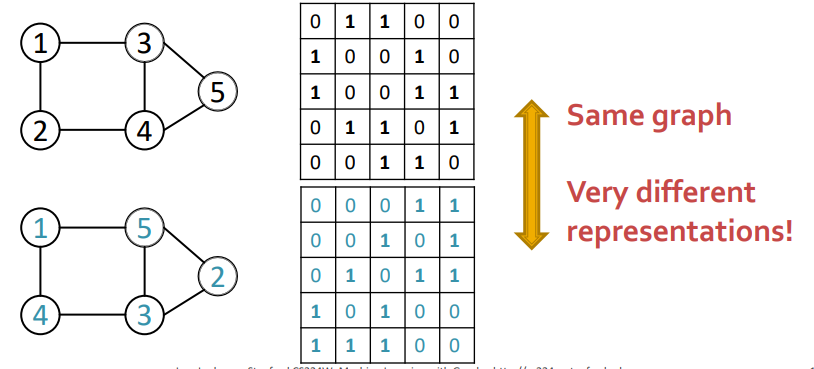
또한 복잡한 의존성(complex dependency)문제도 있습니다.(long-range dependencies) 만약 6개의 node가 있는 링 그래프를 생성하려면, 먼저 node가 있어야하고 그 node를 연결해야합니다. 연결하는 과정에서 우리가 현재 처리하고 있는 node의 수를 기억해야합니다. 그렇지않으면 우리가 원하는 조건을 만족하지 못할 수도 있습니다.
it's hard to generate a graph with respect to some specific conditions.
2. Machine Learning for Graph Generation
Graph Generative Model은 말 그대로 graph를 생성하는 모델입니다. 특정graph의 구조와 특징을 잘 닮은 현실적인 그래프를 생성하려고 합니다. reference graph들의 확률분포 가 있을 때, 와 유사한 을 만들면됩니다. 에서 sampling한 graph들이 주어지고, 이 그래프들로 를 만들면, 에서 generated graph를 sampling합니다.
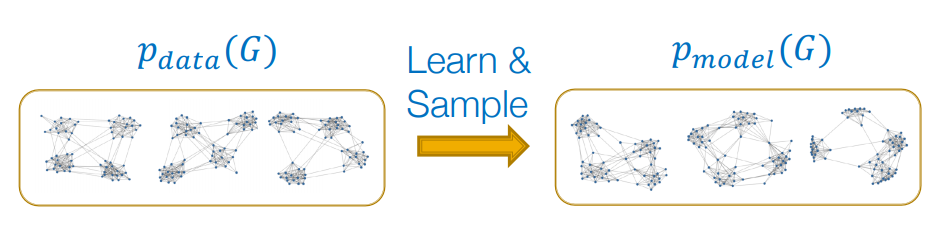
만약 "어떤 특징을 가지고 있는 분자"들의 확률 분포를 라고 하면, 그 확률 분포에서 sampling해온 reference graph들은 동일한 "어떤 특징"을 가지고 있을것입니다. 와 비슷하도록 학습된 에서 sampling한 generated graph들도 "어떤 특징"을 가지고 있도록 하는것이 generation의 목표입니다. graph 도메인에서의 generative model은 graph의 node를 생성하는 것이 아닌, 전체 graph를 생성합니다.
Recap : Generative Model
Generative Model의 개념을 알아보겠습니다.
앞서 말씀드린 바와 같이 Generative Model의 목표는 기존 data의 확률분포 와 유사한 을 만드는 것입니다. 우리는 에서 온 data 만 있을 뿐, 가 무엇인지 모릅니다. 학습 데이터로 모델 분포에 최적으로 근사시키는 변수 를 찾게됩니다. 이는 결합확률 함수 형태로 표현 가능하며, 수치해석이 쉽도록 log 공간으로 변형시켜 maximum likliehood문제로 풀게됩니다.
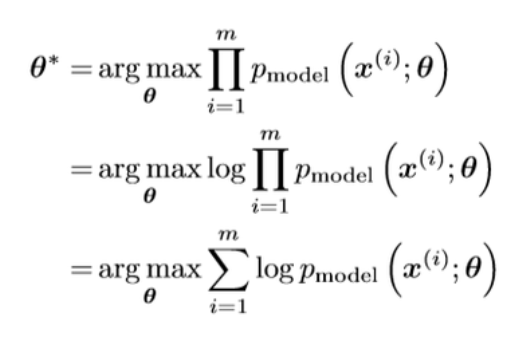
대부분의 생성모델에서는 noise distribution에서 를 sampling해옵니다. ~N(0,1)
Deep Neural Net으로 decoding하여 원하는 data를 생성합니다.
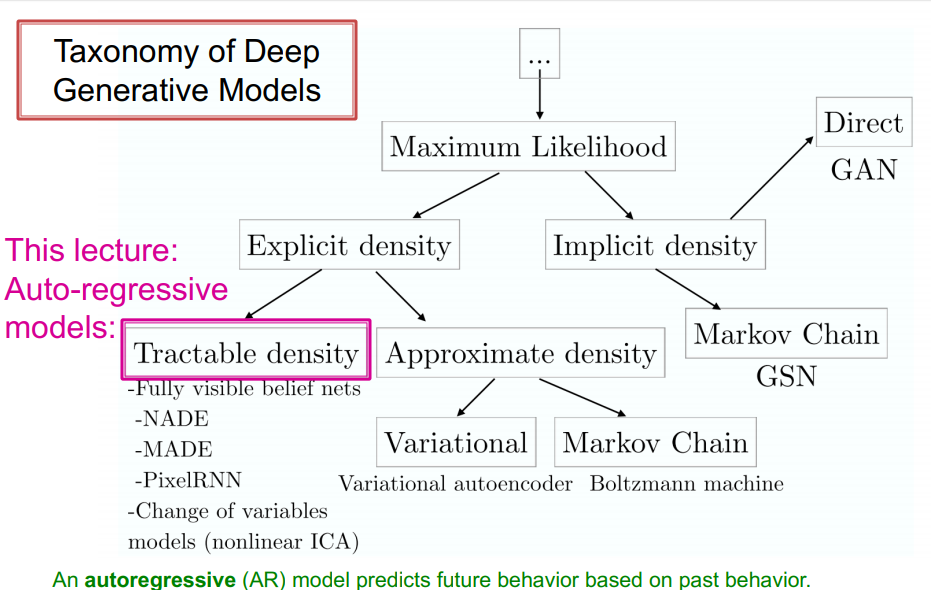
생성모델에는 많은 종류가 있는데, 오늘 배울 Graph Generation은 Auto-regressive model을 사용합니다. Tractable Density를 추정합니다. fully visible brief network의 일종으로, density를 명시하고 시작하며 likelihood 를 모델링합니다.

chain rule을 통해 graph내의 모든 action(add node, add edge)에 대한 joint likelihood는 모든 action의 likelihood의 곱의 형태가 됩니다.
3. GraphRNN : Generating Realistic Graphs
idea : node와 edge를 sequencial하게 추가하면서 graph를 생성합니다.
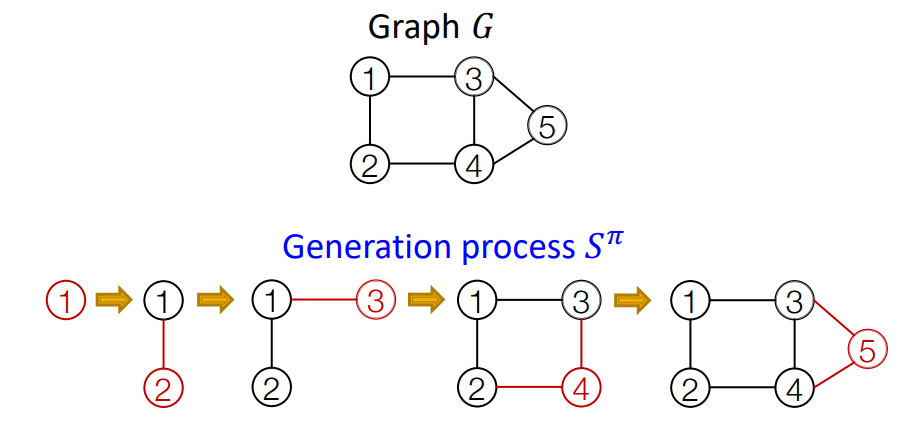
- : node ordering(Graph의 node순서). Random으로 결정됩니다.
- : Graph의 node의 연결 sequence
graph with node ordering can be uniquely mapped into a sequence of node and edge additions
(예. 1~5까지의 숫자를 가진 5개의 node의 sequence)
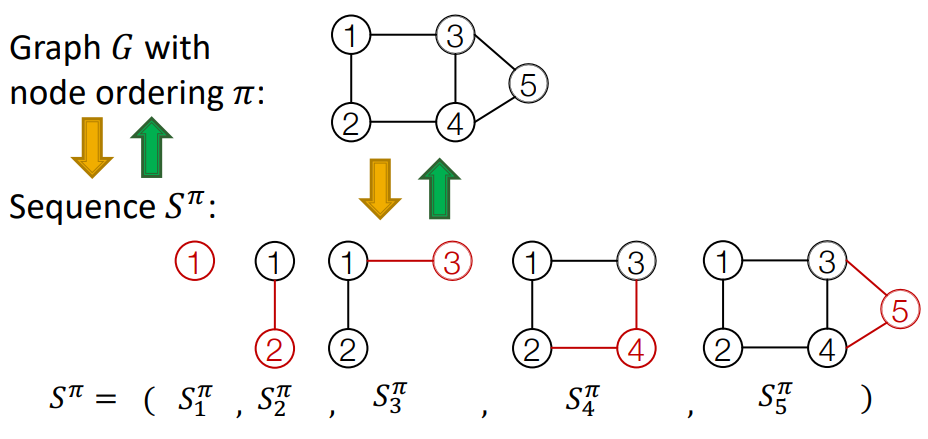
graph 의 node ordering 가 결정되면, sequence 는 unique하게 결정됩니다.
의 원소 은 모두 작은 graph입니다. 노드의 순서가 고정되면 전체 그래프를 생성하는 방법은 하나뿐입니다.
sequence 은 두 가지 level로 나뉩니다.
Node-level: 새로운 node를 하나 추가합니다.
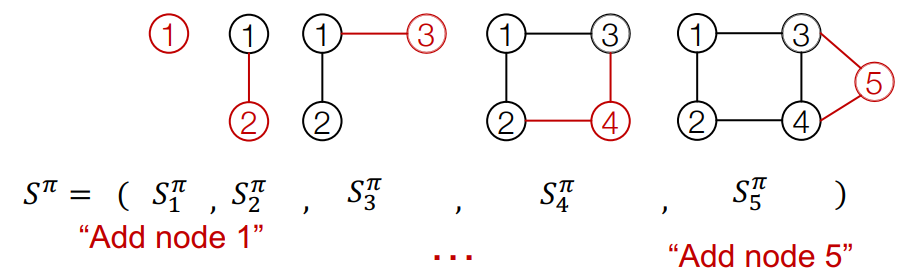
Edge-level: 추가된 node와 기존 node를 잇는 edge(link)를 추가합니다.
node-level을 한번 upedate하면, 그 node에 해당하는 edge-level을 update하고, 그 다음 node를 추가하는 node-level을 update하고 다시 edge-level을 update하는 과정을 반복합니다.
node-level squence의 요소마다 edge-level sequence가 있으므로, squence of sequence라고 합니다.
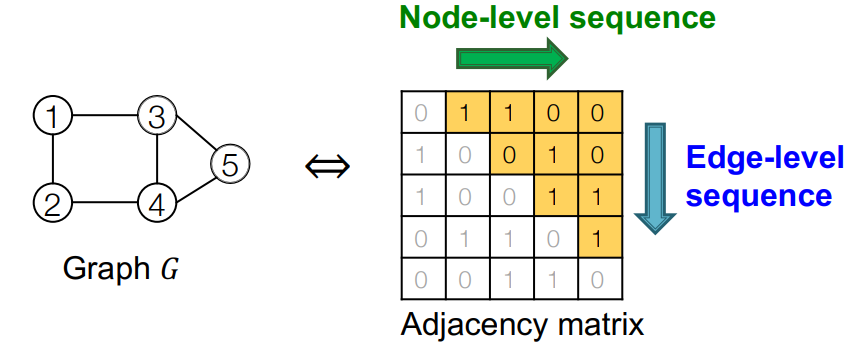
graph generation문제를 sequence generation문제로 볼 수 있습니다. sequence generation은 두 단계로 나뉩니다.
- Generate a state for a new node (Node-level sequence)
- Generate edge for the new node based on its state (Edge-level sequence)
sequence 생성이기 때문에 Recurrent Neural Network로 해결할 수 있습니다.
GraphRNN
GraphRNN은 두단계로 나뉩니다.
node-level RNN: 새로운 node를 만들고, 만들어진 node는 edge-level RNN의 initial state가 됩니다.edge-level RNN: 이전 방법대로 한다면 Node 5를 생성할 때, Node 1~4까지의 모든 연결을 고려해야했습니다. 하지만 이제 새로운 node의 edge를 만듭니다. 만들어진 edge는 node-level RNN의 state를 update합니다.
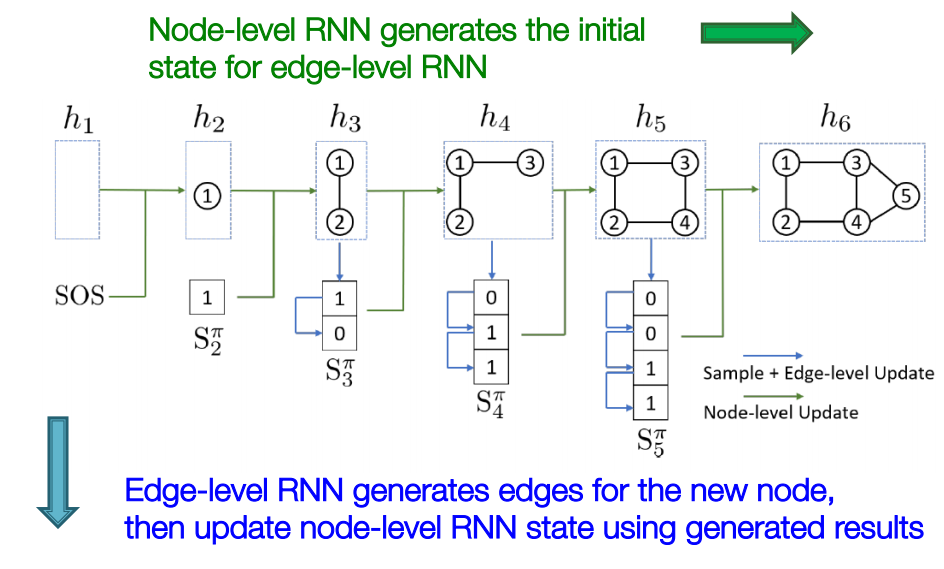
이제 RNN으로 sequence를 만드는 방법에 대해 자세하게 알아보겠습니다. (RNN,LSTM,GRU...)
- : state for RNN after time
- : input to RNN after time
- : output of RNN after time
- : parameter matrices
- : non-linearlity
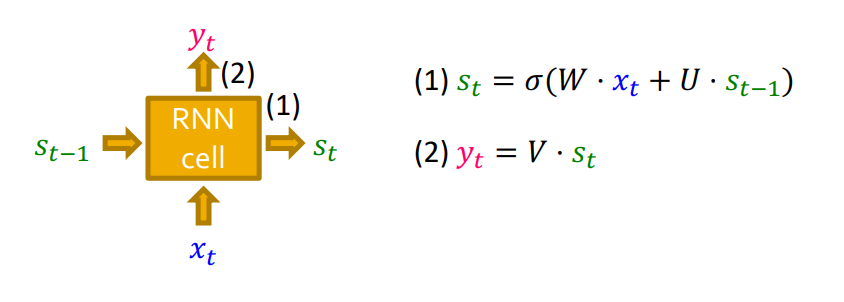
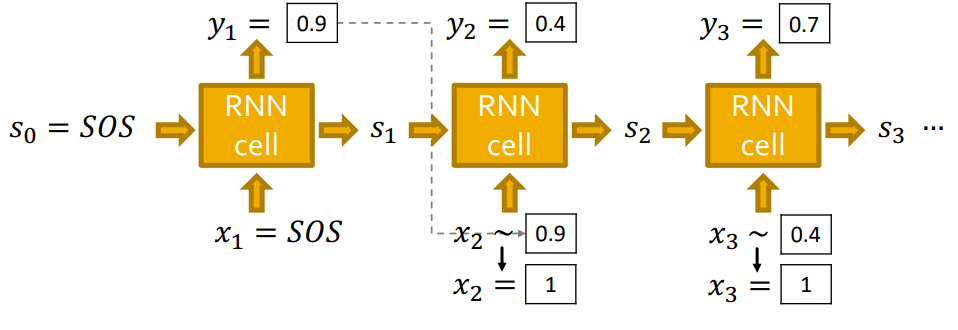
Auto-regressive model이기 때문에 이전 cell의 output이 다음 cell의 input으로 들어가는 구조이므로 입니다.
또한 처음 state와 처음 input인 은 SOS(Start Of Sequence) start tocken으로 지정해주고, end tocken인 EOS(End Of Sequence)로 생성을 멈춰줍니다. (SOS,EOS zero vector)
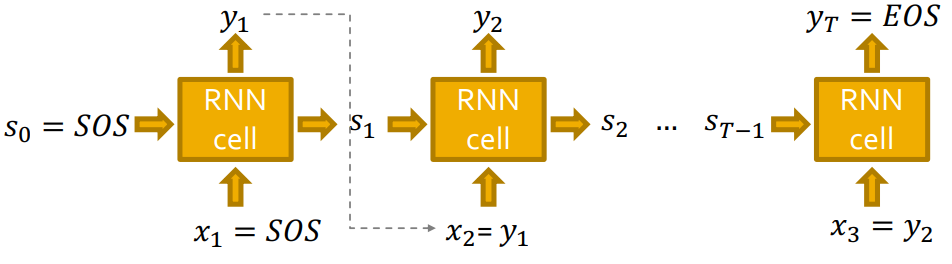
하지만, 이렇게 이라면 모델이 deterministic하여 같은 graph만 생성될 것입니다. (diversity가 없다.)
따라서 이전 cell의 output을 다음 cell의 input으로 바로 넣어주는 것이 아닌, 로 확률을 출력하여, 그 확률 분포에 맞게 을 sampling해줍니다.
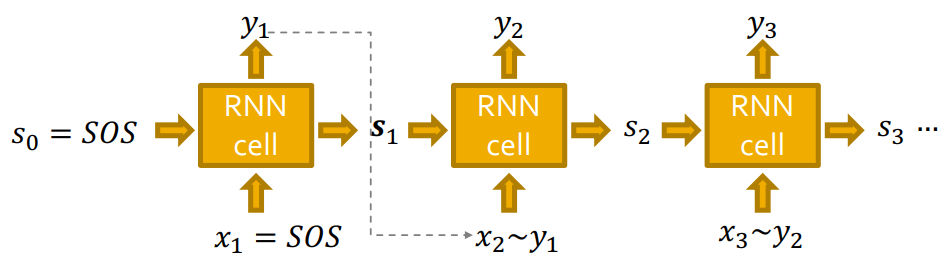 RNN의 각 step의 output 는 확률 vector입니다.
RNN의 각 step의 output 는 확률 vector입니다.
Training
edge에 대한 Ground Truth(Adjacency matrix) 로 teacher forcing을 합니다.
teacher forcing
techer forcing이란, Ground Truth를 디코더의 다음 입력으로 넣어주는 기법입니다.

Loss
로 Binary Cross Entropy를 계산합니다.
BCE를 minimize하는 방향으로 학습합니다.
실제값 =1이면 term을 최소화하고,
실제값 ==0이면 term을 최소화합니다.
training process
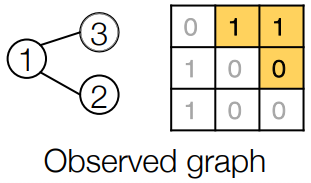
이 graph가 data로 주어졌습니다.

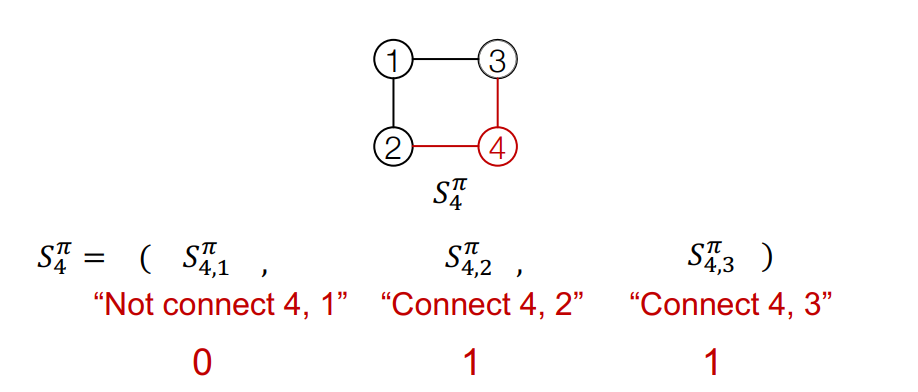
Node 1이 graph에 있다고 가정하고, Node2를 추가해보겠습니다.
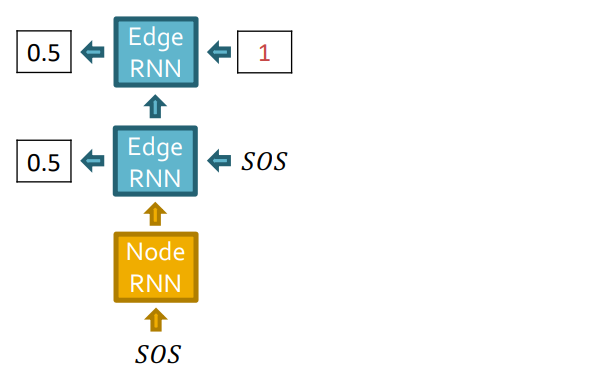
Edge RNN은 Node 1과 Node 2사이의 edge를 예측합니다. 첫번째 Edge RNN cell에서 0.5의 확률을 output으로 출력했고, teacher forcing하기 때문에 실제 GT인 1을 다음 Edge RNN cell의 입력으로 넣어줍니다.
Edge RNN에 GT가 supervision으로 오게됩니다.
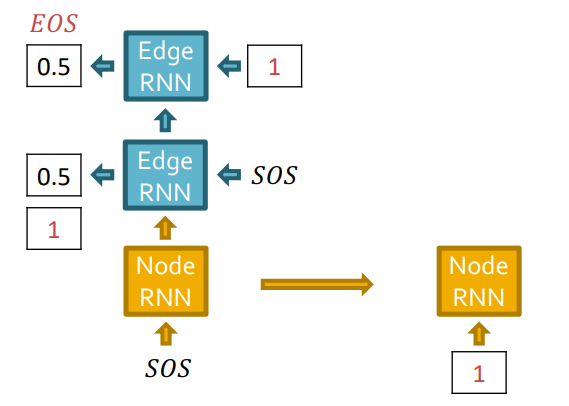
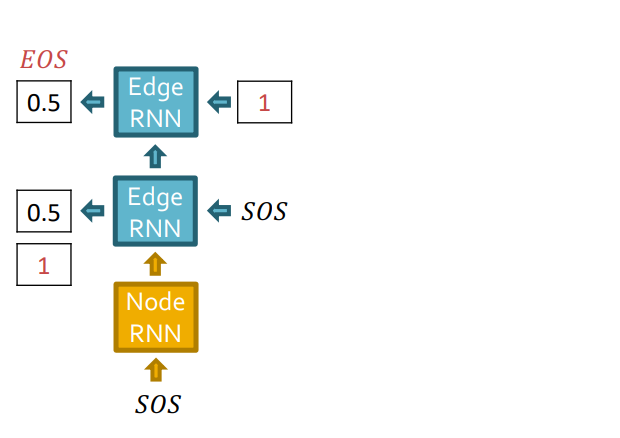
Edge RNN의 최종 output sequence {1}을 Node RNN의 입력으로 주어 다음 node level(Node 3)로 update합니다.
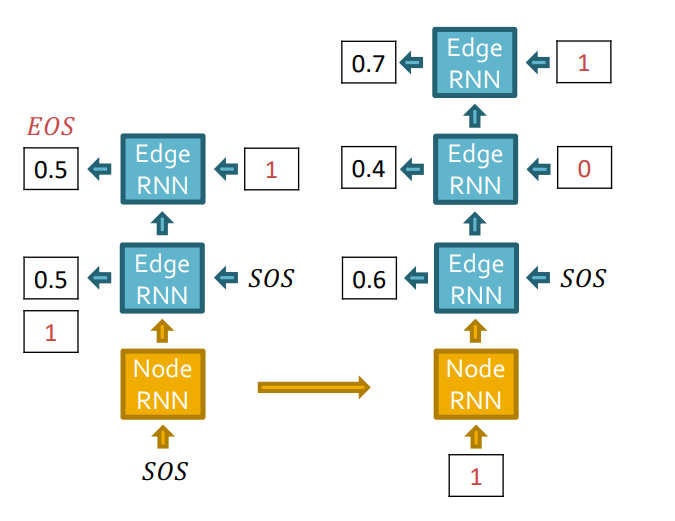
다음으로 Edge RNN은 새로운 노드 Node 3와 기존 Node들이 연결되어있는지 확인합니다. 역시 Edge RNN에서는 teacher forcing을 해줍니다.

다음으로 GT를 supervision으로 줍니다.
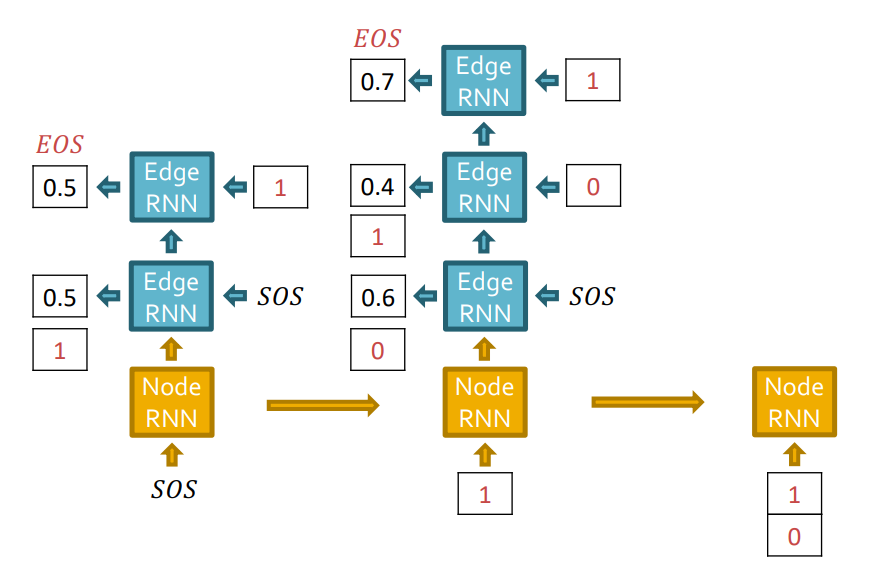
Edge RNN의 output인 결과를 Node RNN의 입력으로 보내줍니다.
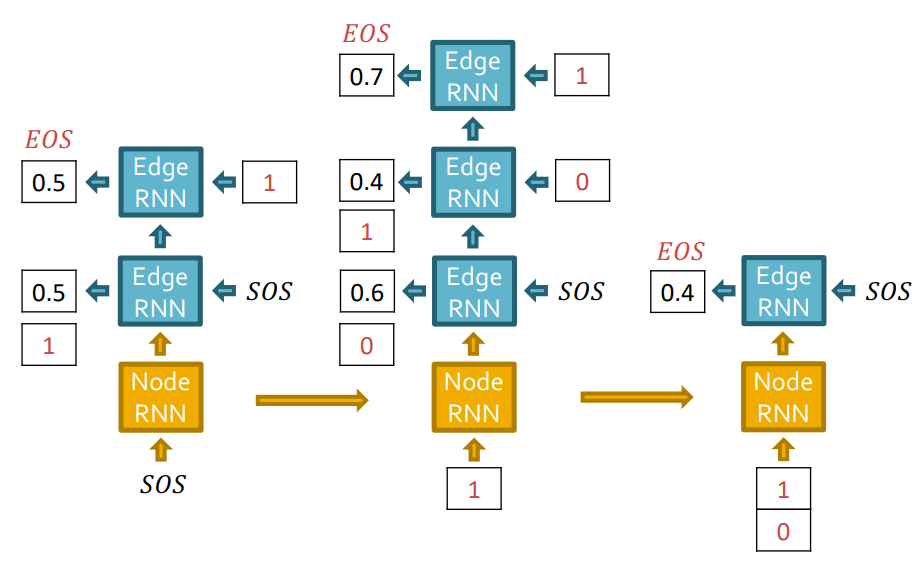
동일하게 Edge RNN에서 edge에 대한 확률값을 예측하는데, Node 4는 아무 node와 연결되어있지 않으므로 graph 생성을 중단합니다.
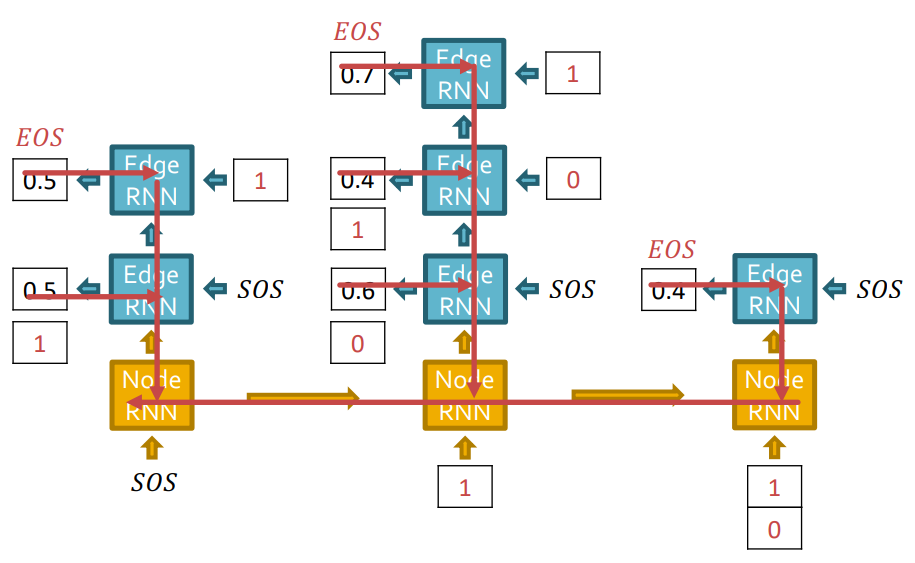
reference graph (GT)를 가지고 BCE loss를 사용하여 전체 RNN layer에 대해 backprob을 진행합니다.
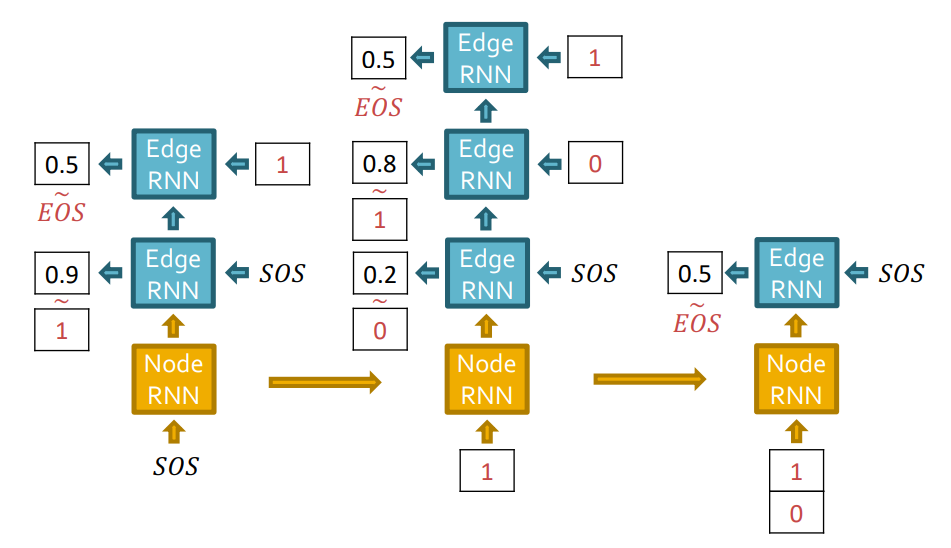
Test
Edge RNN의 output으로 나온 확률이 threshold이상일 경우 1, 반대의 경우에는 0값을 얻을 수 있습니다. GT가 없기 때문에, 이전 Edge RNNcell의 결과인 1 또는 0값이 다음 Edge RNN cell의 input으로 들어갑니다.
GraphRNN을 정리하자면, graph 생성은 node-level sequence과 edge-level sequence 두 단계로 진행되며, RNN을 사용하여 sequnce를 생성합니다.
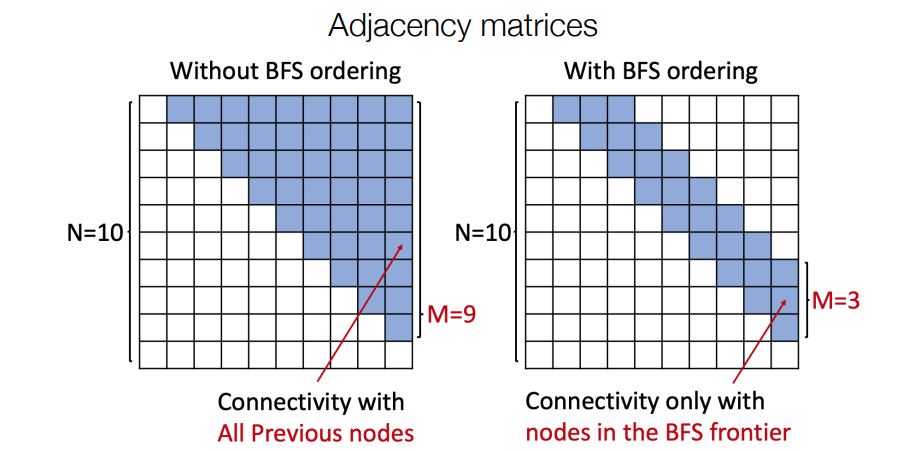
Issue : Tractability
어느 node든지 모든 node와 연결될 수 있습니다. edge generation을 하기에 많은 단계를 거쳐야 합니다. 우선 전체 adjacency matrix가 필요하고, edge의 종속성이 너무 길어져 복잡해집니다. 이러한 한계를 해결하기 위해 BFS를 사용합니다.
기존 Random node ordering
Node 5 may connect to any/all previous nodes
- Node 1을 놓는다.
- Node 2를 놓는다.
- Node 2와 Node 1의 edge를 확률에 따라 생성한다.
- Node 3를 놓는다
- Node 3와 Node 2, Node 1의 edge를 확률에 따라 생성한다.
- Node 4를 놓는다.
......
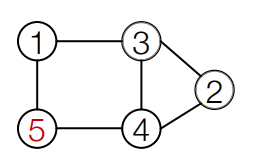
BFS node ordering
- Node 4와 Node 1은 연결되어있지 않기 때문에, 어쩌라고...
BFS node ordering을 적용한 결과 Node ordering과 Edge generation 모두 시간복잡도가 대폭 줄게됩니다.
Evaluating Generated Graphs
GraphRNN같은 graph generative model로 생성한 graph가 reference와 얼마나 유사한지 어떻게 측정할 수 있을까요??

어느 그래프에나 적용할 수 있는 효율성있는 Graph Isomorphism test가 없습니다.
따라서 Visual similarity와 Graph statistics similarity로 두 그래프의 유사한 정도를 판단합니다.
4. Applications and Open Questions
GraphRNN은 앞서 한번 언급한 Drug Discovery에 사용될 수 있습니다.
- 주어진 목적에 따라 모델을 최적화 시켜야 합니다.(High score)
- 주어진 제약 조건을 지켜야합니다.(Valid)
- 실제 그래프 데이로부터 학습을 해야합니다.(Realisitc)
특정 요구 사항, 주어진 화학적 특성의 높은 점수, 화학적 valency와 realistic을 만족하도록, 세가지 다른 방향으로 접근을 했습니다.
- GCN + 강화학습
- adversarial training
- Policy Network in 강화학습
Drug Discovery에 대표적으로 사용되지만, graph generation은 아직 open problem이 많습니다.
- 3D,point cloud,scene graph같은 다른 domain에서의 graph generation
- 큰 그래프 생성
- Anomaly detection (예. real graph vs fake graph)
이번강의에서는 Graph Generation에 의의와 문제, ML으로 Graph를 생성하는 GraphRNN을 배워보았습니다.
Reference
https://zhuanlan.zhihu.com/p/147675627
https://tobigs.gitbook.io/tobigs-graph-study/chapter10.

5개의 댓글

이번 강의에서는 encoding된 vector로 graph를 생성하는 과정에 대해 배웠습니다.
The Problem : Graph Generation
graph generation의 목표는 realistic한 graph를 생성하는 것으로 Anomaly detection, Predictions, Graph completion 등에 이용 가능합니다.
graph generation의 목표에 따라 Realistic graph generation, Goal-directed graph generation으로 나눠지는데 이번 강의에서 주로 다루는 Realistic graph generation는 reference graph와 동일한(유사한) graph를 만드는 것입니다.
그래프를 생성하는 작업에서의 문제점
- output space가 크고 다양합니다. 인접행렬의 경우 n개의 node를 위해 개의 값을 생성해야하기 때문에 크기가 매우 커집니다.
- Graph의 표현은 고정되어있지 않으며 정해진 순서도 없기 때문에 node의 index가 다르면 다르게 표현돼 학습 최적화에 어려움이 있습니다.
- 원하는 조건을 만족하기 위해서 처리중인 node의 수를 기억해야 하는 complex dependency의 문제가 있습니다.
Machine Learning for Graph Generation
"어떤 특징을 가지고 있는 분자"들의 확률분포를 학습한 모델에서 sampling한 generated graph들도 "어떤 특징"을 가지고 있도록 하는 것이 generation의 목표이며, graph의 node 생성이 아닌 전체 graph를 생성합니다.
GraphRNN : Generating Realistic Graphs
GraphRNN은 RNN과 비슷한 원리로 node와 edge를 sequencial하게 추가하면서 graph를 생성합니다.
graph의 node순서는 random으로 결정되며 sequence S는 unique하게 결정됩니다.
sequence generation은 두 단계로 나뉘는데, 새로운 node의 상태를 만드는 Node-level sequence과 상태에 기반해 새로운 node를 위한 edge를 만드는 Edge-level sequence입니다.
- node-level RNN : 새로운 node를 만들고, 만들어진 node는 edge-level RNN의 initial state가 됩니다.
- edge-level RNN : 새로운 node의 edge를 만듭니다. 만들어진 edge는 node-level RNN의 state를 update합니다.
Auto-regressive model이기 때문에 이전 cell의 output이 다음 cell의 input으로 들어가는 구조.
input을 SOS(Start Of Sequence) start tocken으로 넣어주고, end tocken인 EOS(End Of Sequence)로 생성을 멈춰줍니다. 다만, 이전 cell의 output을 바로 넣어줄 경우 같은 graph만 생성되는 문제가 발생해 확률을 출력해 그 분포에 맞게 sampling을 해 넘겨줍니다.
Edge RNN을 통해 node와 node 사이의 edge를 에측하고 Edge RNN의 최종 output sequence를 Node RNN의 입력으로 주어 다음 node level로 update합니다. 위의 과정에서 teacher forcing을 적용해줍니다.
이 과정을 반복하다가 아무 node와 연결되어 있지 않은 node가 나오면 graph 생성을 중단합니다.
좋은 강의 감사합니다!

이전 강의에서는 Graph에서 임베딩값을 얻는 과정이었다면 이번 강의에서는 Graph를 생성하는 내용을 소개합니다.
1. Problem of Graph Generation
- 그래프는 이미지, 텍스트처럼 고정된 사이즈를 가지지 않을 수도 있고 목표와 여러가지 요인으로 인해 모델이 달라질 수 있습니다.
- 가장 먼저 생각할 수 있는 부분은 노드가 N개가 존재한다면 인접행렬을 얻기위해 N^2의 값을 생성해야 합니다.(연산량 증가)
- 복잡한 의존성 문제.
2. Graph Generation Model
- 그래프의 노드를 생성하는게 아닌 전체 그래프를 생성합니다.
- 우리가 잘 알고있는 생성모델(GAN)와 같이 그래프를 이루는 노드의 특징을 찾아내어 해당 특징에 맞는 그래프를 생성하는게 모델의 목표입니다.
- Auto-regressive model : 이러한 모델들의 특징은 다음(미래) 예측값은 이전(과거)에 예측했던 값을 기반으로 정해지는 특징이 있습니다. (ex: WaveNET또한 고정된 필터 크기 내의 이전 값들을 기반으로 다음 값을 예측!)
3. GraphRNN
-
RNN은 텍스트 기반 데이터를 처리하고 예측하는데 강점을 가진 모델으로 이를 그래프에 적용하여 순차적으로 노드와 간선을 추가하며 전체적인 그래프를 생성합니다.
-
먼저 노드를 랜덤하게 정렬하고 순차적으로 노드를 연결합니다. 여기서 순차적으로 생성하는 방법은 node, edge level로 나뉘고 해당 과정마다 graph 전체의 node, edge를 update 합니다.
-
node-level RNN : 새로운 노드가 생성되면 해당 노드는 edge-level RNN의 시작점이 됩니다.
-
edge-level RNN : 새로운 노드의 간선을 생성하고 이를 update합니다.

- 먼저 RNN의 시작은 SOS(Start of Sequence) 토큰으로 지정하고 마지막은 EOS(End of Sequence)로 지정하여 더 이상 RNN 아웃풋을 생성하지 않습니다.
- 여기서 고려해야할 점은 SOS로 시작하여 EOS로 마치는 RNN 모델은 일관된 그래프만 생성할 가능성이 높다는 점입니다. 그래서 다음 RNN cell에 들어가는(아웃풋)은 Edge 연결에 대한 확률 정보를 출력하게 합니다.
- 학습시엔 이전 값 대신 정답 값을 학습에 사용하는 교사 강요방식을 사용합니다.
- 연산량 문제 : 그래프에서 항상 문제가 발생하는 연산량 문제인데 여기서는 BFS로 해결하였다고 한다. RNN에 들어가는 인풋의 순서를 BFS를 바탕으로 접근하면 확실히 수월해지는걸 알 수있다.(그러면 BFS를 거친 값들에 대해서도 전부 기억을 하고 있어야함 + BeamSearch처럼 할 수 없는게 그러면 모든 노드에 대해서 진행하지 않기 때문. 이 메모리 + 연산량이 <<< 전체 노드에 대한 RNN 작업일까? 왠지 그럴듯)
좋은강의 감사합니다 :)

Deep Graph Decoder 를 통해 node vector embedding 값으로부터 Graph Structure 를 생성합니다.
Graph Generation 의 목표는 Realistic 한 Graph 를 생성하는 것입니다.
일반적인 방법을 적용하게 되면, 1. output space 가 크고 다양하기 때문에 연산량 문제가 발생하며, 2. graph 의 표현 및 순서가 고정되어 있지 않기 때문에 objective function 으로 최적화 하는 데에 어려움이 있습니다.
따라서, 생성모델 방법론 중 Auto-regressive model 을 적용하여, graph 를 생성합니다. density 를 명시하고 시작하며 likelihood 를 모델링하는 방법론으로, 시점에서 생성한 그래프로 시점의 그래프를 계속적으로 생성합니다.
Graph RNN
idea : node 와 edge 를 sequential 하게 추가하면서 graph 를 생성합니다.
- : node ordering 을 random 하게 설정하고,
- : sequence 를 설정합니다.
에는 두 가지 level 로 나뉘어지며, sequence of sequence 로 진행됩니다.
- node-level : 새로운 node 를 생성해 나가는 sequence
- edge-level : 생성된 node 에 대해 기존에 생성된 node 와의 edge 유무 여부를 파악하여 생성해 나가는 sequence

Training 단계에서는 ground truth 를 으로 사용하는 Teacher Forcing 방식을 사용하며, Loss 는 Binary Entropy 로 계산됩니다.

위와 같은 RNN 구조를 통해 node 를 생성하고, edge (연결 상태) 를 생성합니다.
넘넘 멋진 ✨민정멋져✨ 님 ~ 띵강 넘넘 감사함니당 ~ (하트) * 100

이번 강의에서는 graph를 생성하는 방법에 대하여 배웠습니다.
목표는 진짜같은 무작위 graph를 생성하는 것으로 생성 anomaly detection predcition 등 다양한 task를 진행할 수 있습니다. 이를 위해 2가지 조건을 충족해야하는데 먼저 진짜 같은 graph여야하며 목적에 맞는 graph를 생성해야한다는 점입니다. 하지만 graph를 인접행렬로 표현해본다면 n^2의 크기를 가지는 graph를 생성하는 일은 어렵습니다. 또한 기하하적으로 고정되어있지 않기때문에 제약이 많습니다. 따라서 우리는 전지전능하신 neural net으로 이 문제를 해결할 수 있습니다. 여기서 오늘 배운 생성모델은 auto-regressive model로 reference graph로부터 학습된 확률분포가 있을 때 이 분포를 따르는 유사한 graph를 생성하면됩니다. 모델을 확률분포에 근사시키는 파라미터를 찾게되고 이는 결합확률 함수 형태로 표현 가능하며 log space로 매핑하여 maximize 최적화로 접근합니다.
GraphRNN은 node와 edge를 sequential하게 생성하는 모델입니다. 먼저 노드 순서를 π, π의 sequence를 S^π라고 했을 때 S^π는 node 개수만큼 π의 set인 (S_1, ..., S_n)으로 정의할 수 있습니다. 여기서 각 π set은 subgraph라고 할 수 있습다. 이를 따라 node level로 매 스텝마다 노드를 추가하는데, 이 node level에서 edge level의 생성이 이루어지게 됩니다. 따라서 graphRNN의 전체적인 생성이 두 단계로나뉜다고 볼 수 있습니다. 기존 RNN과 동일하게 SOS, EOS 토큰 모두 존재하며 edge level의 생성에서 SOS부터 시작하여 EOS가 나타날 때까지 edge를 생성합니다. 순서는 현재 노드부터 시작해서 지금까지 생성된 다른 노드와의 연결여부를 의미합니다. edge level 생성이 진행되면서 실제 output을 그대로 다음 스텝으로 넘기게 되면 deterministic한 모델이 되어 다양성이 사라지게 됩니다. 따라서 출력을 확률로 뽑아서 분포에 맞게 다음 input을 sampling합니다.
graphRNN은 teacher forcing을 사용하며 loss는 binary cross entropy를 채용합니다. 이제 node level에서 학습을 진행하면서 전체 인접행렬을 참고하여 노드를 생성하기에는 computation cost가 크기 때문에 BFS를 사용하여 획기적으로 시간을 줄일 수 있습니다.
띵강 감사합니다~!
Intro
Difficulty of generating the graph
기존의 큰 그래프를 통해 합성된 그래프를 생성하는데에는 크게 두가지 문제점이 발생할 수 있습니다.
첫번째로, 그래프의 크기가 크고 다양하다는 점입니다. 흔히, 인접행렬을 생각해보면, n개의 노드가 있다면 n^2의 사이즈의 인접행렬이 요구되기 때문에 크기가 기하급수적으로 커지게 됩니다.
두번째로, 그래프의 경우, node에 일정한 순서가 없고, 한 node에 대해서 index가 달라질 수 있다는 점에서 학습하기 어렵다는 점입니다.
Background
Generative Model
한마디로 표현하면, 샘플링한 분포을 통해 나타난 분포가 실제 분포와 유사해지도록 생성하는 것이 Generative Model입니다. 그래프에서도 같은 개념으로, sampling한 그래프가 본래 그래프의 특징이 잘 반영될 수 있도록 학습시키는 것 입니다.
Auto-regressive Model
말 그대로, 이전의 자기자신의 상태에 영향을 받은 것입니다. 예를 들어, t시점의 상태는 t-1, t-2, ... 상태들에 영향을 받는다는 말입니다. 이를 통해 각각의 상태들의 곱을 구하게 되면 chain rule에 의해 joint distribution의 형태가 되게 됩니다.
GraphRNN
앞 부분에서 graph를 생성하는 어려움으로 node에 일정한 순서가 없다는 것을 언급하였습니다. 그럼에도 불구하고 RNN을 적용할 수 있는 이유는 node-level-sequence와 edge-level sequence로 바꿔, sequence의 문제로 탈바꿈할 수 있기 때문입니다.

node-level-sequence의 경우, random으로 순서를 정해준 후, 생성합니다.
edge-level-sequence의 경우, 생성된 node에 대해 기존의 생성된 node들과의 연결상태를 파악하여 생성합니다.
기존의 RNN과 다른 점은 graph의 생성의 다양성을 확보하기 위해서, RNN의 input을 확률분포에서 샘플링하여 넣어주었다는 것입니다. 즉, 기존의 예측된 값을 바로 다음 RNN의 input으로 넣는 대신에 예측 분포에서 샘플링을 한 값을 넣어준다는 점에서 다양한 그래프를 생성할 수 있다는 것입니다.
두 그림을 보면 쉽게 이해할 수 있습니다. 노드를 생성하고 연결상태를 생성하는 과정입니다. 노드 생성과 엣지 생성 역시 각각 RNN을 통해 sequential하게 처리하고 있음을 알 수 있습니다.
하지만, 이런 경우, 노드를 생성할 때마다 이전의 노드들을 지속적으로 봐야한다는 종속성의 문제가 발생합니다. 그만큼 계산량이 많아지는 것을 뜻합니다. 따라서, 이를 BFS node ordering을 통해 연산과정을 대폭 줄이는 과정을 거치게 됩니다.
갓민정님 좋은 강의 감사합니다!