[Paper Review] (2014, RecSys) Beyond Clicks Dwell Time for Personalization
Recommender_System

작성자: 이원도
1. Introduction
추천시스템에서 개인화는 유저의 서비스 이용시간을 늘려 수익 창출로 이어집니다. 전통적으로 많이 사용된 유저의 feedback 정보는 user-item rating과 click through rate(CTR)이 있습니다.
user-item rating은 사용자의 선호 정보를 알수있는 explicit feedback 이지만, 이러한 explicit feedback 정보가 제공되지 않을때가 있습니다. CTR은 유저의 선호에 대해 보다 제한된 정보를 제공하는 implicit feedback입니다. 이 때문에 CTR을 유저의 아이템에 대한 선호 지표로 사용하기에 어려움이 있습니다. 유저가 아이템을 실수로 클릭할수도 있고, 아이템을 클릭했지만 아이템을 마음에 들어하지 않을 수도 있기 때문입니다.
따라서 유저의 선호를 보다 정확히 파악할 수 있는 지표가 필요한데, 본 논문은 유저가 아이템에 머문 시간(dwell time)을 유저의 아이템에 대한 만족도를 나타내는 지표로 사용합니다. 나아가 논문은 이런 dwell time의 수집 방법, 정규화 방법, learning to rank 및 collaborative filtering 에서의 적용 방법을 논의합니다.
논문의 제시하는 contribution은 다음과 같습니다.
-
유저의 아이템 단위 컨텐츠 소비시간(dwell time)을 측정해 유저의 선호를 파악하는 새로운 방법을 제시
-
사용기기(pc, 핸드폰, 태블릿)에 따라 차이나는 아이템 dwell time의 정규화 방법 제시
-
content recommendation 상황에서의 dwell time에 대한 empirical 분석
-
dwell time을 이용한 learning to rank 과제
-
dwell time을 이용한 collaborative filtering 과제
2. Related Work
Dwell Time in Other Domains
post-click dwell time은 IR(information retrieval), 웹 검색(web search) 영역에서 주로 검색어와 결과 컨텐츠의 관련성을 분석하고, 검색엔진의 성능을 높이는 용도로 연구되었습니다.
한편 논문에 따르면 dwell time을 개인화된 추천 시스템에 적용한 선행연구는 없다고 합니다.
Learning to Rank in Web Search
정보검색(information retrieval) 영역은 검색(query)에 대한 검색결과의 'relevance'를 높이는 것을 목표로 합니다. 'relevance'는 다소 추상적 개념으로, query와 검색결과의 관계에 대한 객관적 수치입니다.
한편 논문은 개인화된 정보검색을 위해서 이러한 객관적 relevance를 정확히 예측하는 것보다 dwell time를 정확히 높일 것을 주장합니다. 기존 IR 영역의 machine learning to rank(MLR) framework의 gradiented boosted decision trees, 또는 pairwise models(RankBoost, AdaRank), listwise models(RankNet, ListNet)를 사용해 relevance 대신 dwell time을 정확히 예측하는 식으로 적합합니다.
Collaborative Filtering
Collaborative Filtering 알고리즘은 대개 user의 explicit feedback를 사용하거나, binary implicit feedback을 사용합니다.
한편 논문과 같이 dwell time을 이용하는 선행연구는 드뭅니다.
3. Measuring Item Dwell Time
3.1 Dwell Time Computation
유저의 item 단위 dwell time 을 측정하는 것은 쉽지 않습니다. 예를들어 요즘의 브라우저는 여러개의 탭을 활용할 수 있고, 여러개의 탭 중에 유저가 주의를 기울인 아이템이 무엇인지 파악하기 쉽지 않습니다.
유저의 아이템 dwell time을 측정하는 두가지 보편적 방법은 client-side logging과 server-side logging입니다. client-side logging은 유저의 세밀한 행동과 주의를 측정할 수 있지만 브라우저에 따라 데이터 손실의 위험이 있습니다. client-side logging 정보를 이용할 수 없을때 server-side logging의 정보를 통해 dwell time에 대해 근사를 해 계산해야합니다.
Client-Side Dwell Time
client-side logging은 다음과 같은 Javascript/DOM events를 활용합니다.

위의 예에서 DOM-ready는 페이지 body의 준비시간을 나타내며 dwell time의 시작시간입니다. Focus는 user가 주의를 기울임을, Blur는 user가 주의를 기울이지 않음을 의미합니다. BeforeUnload는 페이지가 꺼지기 직전 시간을 나타냅니다.
이로부터 client-side dwell time은 로 계산됩니다. client-side logging은 탭이 여러개인 상황에서도 유저의 dwell time을 정확히 파악할 수 있습니다.
하지만 Javascript가 정확히 작동하지 않거나, client-side 정보가 server-side로 정확히 전달되지 않는다면 정보 손실이 있을 수 있습니다. 예를들어 유저가 Javascript를 해제하거나, 인터넷 연결이 끊기는 경우가 있을 수 있습니다.
Server-Side Dwell Time
client-side logging 정보가 제공되지 않으면 server-side logging 정보를 통해 user의 dwell time을 파악해야 합니다. 이때 휴리스틱에 의한 근사를 해야합니다.
다음과 같은 로그 정보가 있을때,
2가지 방법으로 dwell time을 계산할 수 있습니다. FB(Focus/Blur)과 LE(Last Event) 방법입니다.
FB(Focus/Blur) : 에 대한 dwell time은 로 계산됩니다. 아이템에 대해 주의를 기울인 시간(Focus)과 그렇지 않은 시간(Blur) 시간을 로그를 통해 추정하는 것입니다.
LE(Last Event) : 에 대한 dwell time은 입니다. 이 방법은 에 대한 첫 행동과 마지막 행동의 시간차를 통해 dwell time을 계산합니다.
FB는 dwell time에 대한 추정이기 때문에 실제 dwell time과 오차가 있을 수 있습니다. 마찬가지로 LE 방법은 한 아이템에 대한 시작 행동과 끝 행동 사이의 전기간을 dwell time으로 추정하기에 dwell time을 실제보다 크게 과대추정할 수 있으며, 반면 마지막 행동의 시작시간을 dwell time 계산의 끝 시간으로 계산하기 때문에 dwell time을 과소추정할수도 있습니다.
실제 이틀간의 client-side logging과 FB, LE에 따라 계산한 dwell time의 평균은 다음과 같습니다.
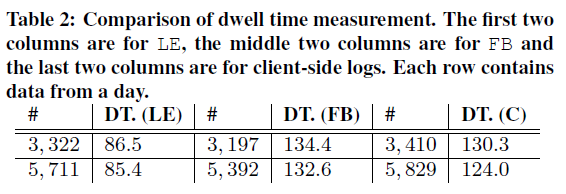
1, 3, 5 열은 아이템의 개수, 2, 4, 6 열은 평균 dwell time입니다. 같은 데이터에 대해서 수집과정의 차이 때문에 1, 3, 5 열의 아이템 개수가 차이가 납니다. 또한 실제 client side log와 FB 방법의 dwell time이 유사한 것을 확인할 수 있으며 FB dwell time을 client side dwell time의 추정값으로 사용하는 것이 적절해 보입니다.
3.2 Dwell Time Analysis
dwell time 에 대한 그래프를 그려 그 특징을 더 분석해봅니다.
사용하는 데이터는 다음과 같은 야후의 뉴스기사 검색 로그 데이터입니다.
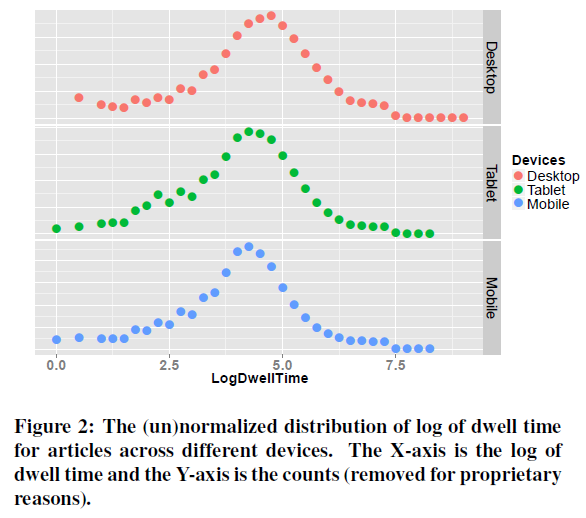
서로 다른 기기에서 아이템에 대한 log - dwell time을 그려보면 다음과 같은 정규분포 모양이 나옵니다(Figure2).
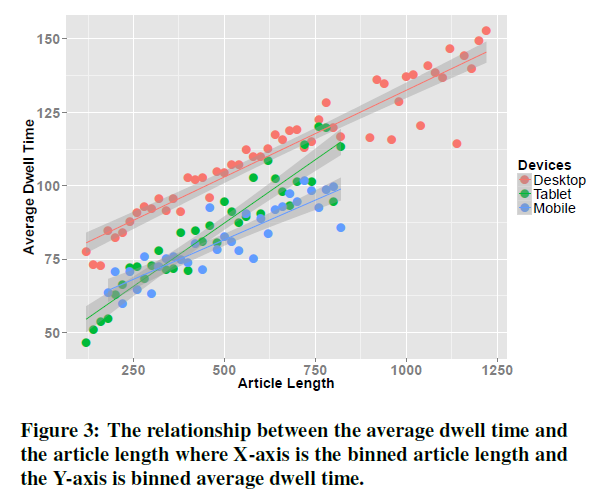
뉴스기사의 길이와 dwell time이 비례하는지 확인하기 위해 그래프를 그려봅니다(Figure3). x축은 뉴스의 길이, y축은 해당 뉴스에 대한 유저들의 평균 dwell time 입니다. 대체로 선형적 관계를 띄고, 뉴스기사 길이가 지나치게 길어지면 관계가 약해집니다.
몇가지 특징으로 뉴스기사마다 평균을 내지 않고 모든 유저, 모든 아이템의 dwell time을 그리면 선형관계가 분명하지 않았습니다. 그리고 긴 dwell time에 대해 기사의 길이 이외에 유저의 관심도를 함께 고려해야 합니다.
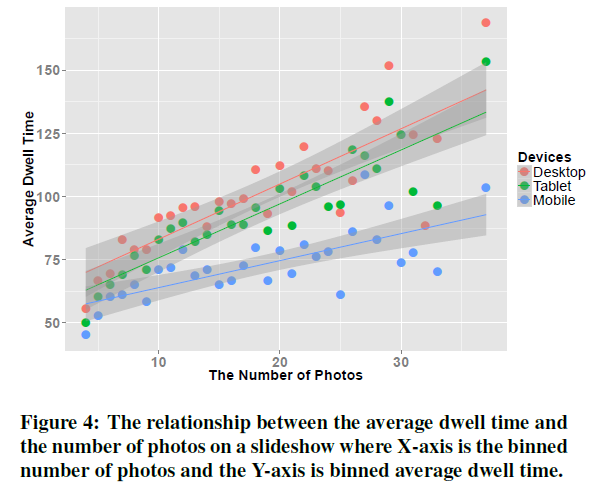
사진으로 구성된 slideshow에 대해 사진 개수(x축)에 대한 유저의 평균 dwell time(y축)을 그린 그래프는 다음과 같습니다(Figure4). 마찬가지로 선형적 관계를 보입니다.
3.3 Normalized Dwell Time
서로 다른 기기(pc, 핸드폰, 태블릿)에 따른 dwell time, 그리고 서로 다른 아이템 유형(글, 사진, 영상)에 따른 dwell time에 차이가 있습니다.
다음은 slideshow(사진)에 대한 log - dwell time(Figure 5), 그리고 영상에 대한 log - dwell time(Figure 6)의 그래프입니다.
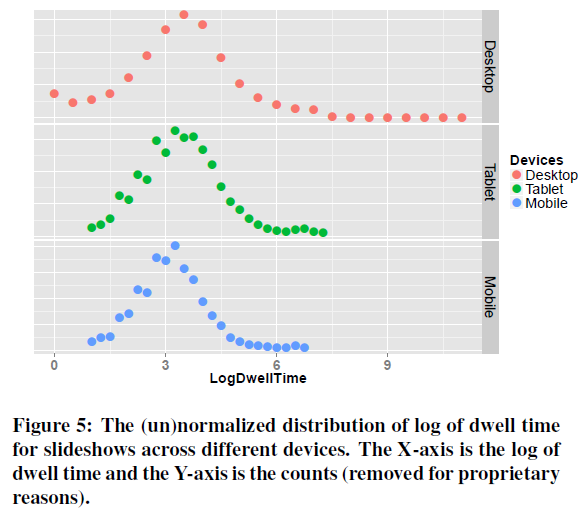
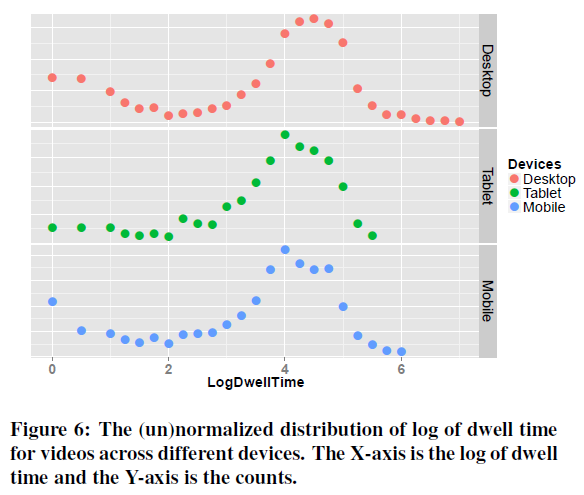
서로 다른 context(기기와 아이템 유형)에 따라 아이템 dwell time이 다르므로, dwell time의 비교를 위해 이러한 차이를 표준화할 필요가 있습니다. 표준화는 다음의 과정을 따릅니다.
- 각 context 에 대해, log - dwell time의 평균 과 표준편차 를 구합니다.
- context 의 새로운 아이템 에 대해 표준화된 log dwell time 를 다음과 같이 구합니다: .
- 새로운 context 예를 들어 article context에서의 아이템 의 dwell time을 다음과 같이 구합니다: .
3.4 Predicting Dwell Time
아이템의 dwell time 정보가 없을때 이를 예측하기 위한 모형을 구성할 수 있습니다.
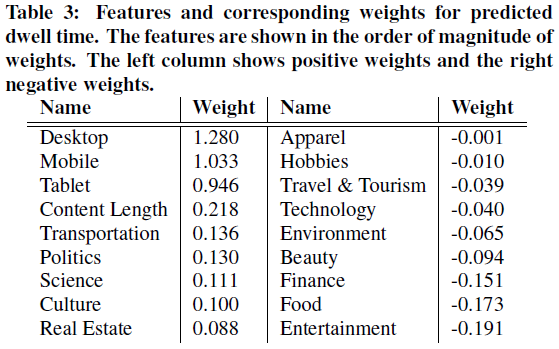
Support Vector Regression(SVR)을 이용합니다. log - dwell time 이 목표변수이며, feature로 기사의 context, 길이, 주제 카테고리 등을 사용합니다. 적합한 SVR 모형의 feature에 대한 weight 값은 다음과 같습니다. 대략적으로 weight는 dwell time에 영향을 미치는 정도를 나타냅니다.
4. Use Case I : Learning to Rank
아이템 dwell time을 machine learning to rank(MLR)을 이용한 추천시스템 모델에 사용하는 법에 대해 논의합니다.
The Basic MLR Setting
전통적 IR 세팅에서 query 와 document 가 있고, 이 둘을 파라미터로 받는 response 가 있습니다. 는 query에 대한 document의 relevance와 관련됩니다. MLR은 머신러닝 모델을 사용해 값을 정확히 예측하는 모형을 만듭니다.
논문의 저자는 위의 과정을 content recommendation 에 적용합니다. user의 관심을 query로, 아이템(ex 기사)를 document로 봅니다. 이를 위해 user의 관심을 정량적인 변수로 나타내야 하고, query-document relevance를 user의 활동으로부터 추론해야 합니다. 논문은 첫번째 문제 대신 두번째 문제에 집중해 설명합니다.
기본적으로 user가 아이템에 click한 행동을 이용해, 와 같이 binary 변수를 설정하고 를 예측하는 모델을 만들 수 있으며 이것은 논문의 도입부에 나온 CTR 예측과 일치합니다.
논문은 Gradient Boosted Decision Tree(GBDT) 알고리즘을 이용하며 알고리즘에 대한 설명은 다음과 같습니다.
GBDT 알고리즘은 트리 앙상블의 합으로 이루어진 회귀모형입니다. 모형은 각 시점에서 현재 시점의 오차와 로스 함수의 그라디언트에 추가적으로 적합하는 식으로 순차적으로(step wise)하게 구성됩니다. 다음과 같은 형태의 additive 모형이 적합됩니다.
Dwell Time for MLR
Dwell Time을 위의 GBDT 알고리즘에 적용하는 몇가지 방법이 있습니다. 를 아이템 의 평균 dwell time이라고 한다면, 1) 와 같이 목표변수를 dwell time에 관한 함수로 바꿀 수 있습니다. 2) 그외에 아이템 GBDT를 학습하는 과정에서(로스와 그라디언트에 추가적으로 적합하는 과정), 각 아이템에 대한 weight를 dwell time에 비례한 함수로 줄수있습니다.
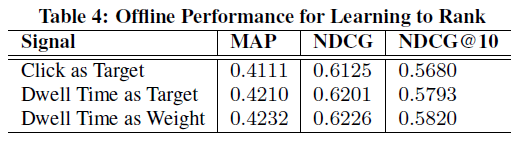
이와 같은 세팅으로 야후 사이트에서 직접 수집한 데이터에 대한 모델의 offline evaluation 성능 결과는 다음과 같습니다. train, test 데이터는 7:3으로 나누었습니다. 앞서 dwell time을 이용하는 2가지 방법 중, dwell time을 학습과정에서 아이템의 weight로 사용하는 것이 가장 성능이 좋았음을 알 수 있습니다.
다음으로 모델의 online 상황에서의 성능을 확인하기 위한 실험을 진행했습니다. A는 click 여부(binary)를 로 두고 적합한 선형 모델, B는 click 여부를 로 두고 적합한 GBDT 모델, C는 dwell time을 목표변수로 두고 적합한 GBDT 모델입니다. A, B, C 세 모델을 online 추천 상황에서 사용했을 때, CTR 지표와 user engagement 지표를 비교함으로써 online 상황에서 성능이 좋은 모델을 보는 것입니다.
처음 3일은 같은 baseline 모델을 이용했고, 이후 A, B, C의 모델을 나누어 이용했을때 성능 차이를 볼 수 있습니다. Dwell time을 정확히 예측하는 모델을 이용해 추천을 하면, CTR, user engagement 등의 지표의 성능도 올라갑니다.
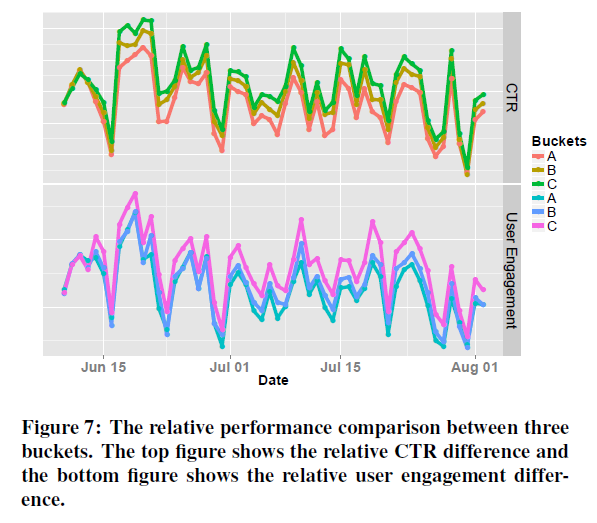
한편, 아쉽게도 학습한 MLR 모형을 추천에 정확히 어떻게 적용하는지 논문에 자세히 설명되어있지 않으며, user engagement 지표가 정확히 어떤 것인지에 대해서 기업 내부적 내용이라는 이유로 설명하지 않습니다.
5. Use Case II : Collaborative Filtering
Collaborative Filtering 방법을 통해 유저와 유사한 취향을 가진 사람의 소비 정보를 이용해 유저에게 아이템을 추천할 수 있습니다. 이때 주로 사용되는 것은 Matrix Factorization 방법입니다.
저자는 기존 MF 방법에서 사용된 user-item rating 혹은 user-item click 정보 대신, user-item dwell time 정보를 이용하는 방법을 제안합니다.
Setting
Matrix Factorization의 세팅은 다음과 같습니다:
-
User feedback 행렬
-
의 성분 는 dwell time이고, 또는
-
를 , 로 분해
objective 함수는 다음과 같습니다:
-
-
는 positive example, 는 negative example 이며 rank-based optimization이 사용됨
* 위 내용은 논문의 표기를 그대로 쓴것이지만, 표기된 대로라면 가 negative examples, 가 positive examples가 되어야 할 것 같습니다.
Dataset
3개월간의 Yahoo 데이터를 이용해 데이터셋을 구성합니다. 10개 클릭 미만의 user / item 을 제거한 결과 총 147,069 user와 11,535 아이템이 있었으며, train set는 4,358,066 개의 event, test set는 199,420 개의 event로 구성되었습니다.
Evaluation Method and Metrics
전체 데이터를 여러 시간대로 쪼개어 시간대에 따른 모델을 만듭니다. 또 절대적 click / non-click의 수치를 예측하기보다 MAP(Mean Average Precision), NDCG(Normalized Discounted Cumulative Gain)의 ranking 기반 metric으로 모델의 성능을 평가합니다.
Experimental Results
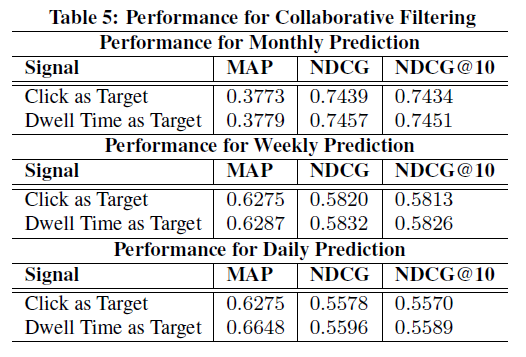
3개월의 데이터 중 앞 3개월의 데이터를 train set, 마지막 1개월의 데이터 일부를 test set으로 놓고 실험을 하는 것과, 하루, 일주일을 test 단위로 해 실험을 진행하는 것입니다. 그 결과는 다음과 같으며 두 경우 모두 click을 타겟으로 한 것보다 dwell time을 타겟으로 했을때 성능이 더 좋은 것을 확인할 수 있습니다.

5개의 댓글

[15기 이성범]
추천 시스템을 만들기 위해서는 유저의 선호도를 표현할 수 있는 데이터가 필요하다. 대부분의 추천 시스템에서는 이러한 데이터를 유저의 아이템에 대한 평점, CTR 등으로 나타냈다. 그러나 본 논문에서는 이러한 유저의 선호도를 표현하는 데이터를 dwell time이라는 유저가 아이템에 머문 시간으로 나타냈다.
dwell time의 경우 사용기기에 따라서 분포의 차이가 발생하기 때문에 이러한 차이를 제거해주기 위해서 각 사용기기의 log-dwell time의 평균과 표준편차를 구해서 정규화를 해줄 필요가 있다.
그리고 dwell time의 정보가 없을 때는 dwell time을 예측할 수 있는 모델을 만들 수 있다. 기사의 길이, 주제, 카테고리 등을 feature로 활용하여 Support Vector Regression 모델을 구축하면 된 다.
dwell time을 이용하여 Machine Learning to Rank 추천 시스템 모델을 구축하기 위한 알고리즘으로 본 논문에서는 크게 Gradient Boosted Decision Tree와 Matrix Factorization을 제시했다.
Gradient Boosted Decision Tree을 이용할 경우에는 목표변수를 각 아이템의 평균 dwell time으로 둘 수 있으며, 각 아이템에 대한 weight를 dwell time으로 활용할 수 있다.
Matrix Factorization을 이용할 경우에는 목표 변수를 user-item dwell time으로 두어 물음표 부분을 추론하는 방식으로 활용할 수 있다.

[15기 권오현]
추천의 개인화는 유저의 서비스 이용시간을 늘려 수익 창출로 이어진다. User-rating이나 CTR을 이용하여 유저의 선호도에 대해 연구하였지만, user-item rating은 explicit feedback 정보가 제공되지 않을 때 사용할 수 없고, CTR의 경우 유저의 실수 혹은 선호도를 제대로 반영하기 어렵다. 이에 논문 저자는 유저가 아이템에 머문시간, dwell time을 통하여 유저의 선호도를 구하고자 하였다.
유저의 dwell time을 측정하기는 쉽지 않다. 일반적으로 dwell time을 측정하는 방법은
client-side logging과 server-side logging이 존재하는데, client-side logging은 유저의 행동을 세밀하게 측정할 수 있지만 브라우저에 따라 데이터 손실의 위험이 있다. 이러한 경우 server-side logging의 정보를 통해 dwell time을 근사하여 계산해야한다.
유저들이 컨텐츠를 다양한 기기를 사용하여 소비하기 때문에 dwell time은 기기에 따라 차이가 난다. 논문 저자는 기기에 따른 dwell time을 정규화하는 방법을 제시하였는데, log dwell time의 평균과 표준편차를 통해 정규화를 하였다. 새로운 context에 대하여는 역연산을 통해 context의 dwell time을 구하였다. 또한 아이템의 dwell time 정보가 없을 때 Support Vector Regression을 이용하여 dwell time을 예측하였다.
Machin learning to rank을 위하여 Gradient Boosted Decision Tree를 이용하여 dwell time에 관한 모델을 구성하였다. 저자가 실험해 본 결과 좋은 성능을 냄을 볼 수 있다.
또한 user-item rating , user-item click 정보 대신 user-item dwell time을 이용하는 Matrix Factorization을 이용하여 학습을 해본 결과 click 정보를 이용했을 때 보다 dwell time을 이용했을 때 성능이 더 좋은 것을 확인할 수 있었다.
[15기 장아연]
본 논문에서는 유저가 아이템에 머문 시간(dwell time)으로 유저의 아이템에 대한 만족도를 나타내는 지표로 사용함. Client - side logging와 server-side logging을 이용해 dwell time을 측정함. client-side logging은 유저의 행동을 자세하게 측정가능하지만 브라우저에 따라서 훼손가능성이 있음. 그래서 client-side logging 사용이 어려울 때 server-side logging를 휴리스틱에 의한 근사해 dwell time를 구함.
사용기기(pc, 핸드폰, 태블릿)에 따라 아이템에 대한 dwell time에서 나는 차이에 대한 정규화 방법을 제시함. context(사용기기/아이템종류)에 대한 평균과 표준편차를 구하고, dwell time에 log를 씌워 정규화함. 새로운 context에서 대해서는 역으로 계산함.
Machine Learning to Rank의 추천 시스템 모델을 위한 알고리즘으로 dwell time을 이용하여 Gradient Boosted Decision Tree와 Matrix Factorization을 이용함. Gradient Boosted Decision Tree은 dwell time을 평균 또는 아이템에 대한 가중치로 사용함. 또, 실험 해본 결과 우수한 성능을 보임. Matrix Factorization을 user-item dwell time을 이용해 학습을 진행한 결과 우수한 성능을 보임

[Paper Review] (2014, RecSys) Beyond Clicks Dwell Time for Personalization
15기 류채은
유저가 아이템에 머문 시간(dwell time)을 유저의 아이템에 대한 만족도를 나타내는 지표로 사용
머문 시간 연산:
- client-side logging
- server-side logging
머문 시간 특징 분석:
- 정규분포 모양
Normalized Dwell time (표준화과정):
1. 각 context C에 대해, log - dwell time의 평균 μC과 표준편차 σC를 구합니다.
2. context C의 새로운 아이템 i에 대해 표준화된 log dwell time zi를 다음과 같이 구합니다: zi=σCilog(ti)−μCi.
3. 새로운 context 예를 들어 article context에서의 아이템 i의 dwell time을 다음과 같이 구합니다: ti,article=exp(μarticle+σarticle×zi).
머문시간 예측:
- SVR 사용
- 목표 변수 : log-머문시간
활용 방법:
- Learning to rank(content recommendation 에 적용)
- Dwell Time for MLR
- Collaborative Filtering 방법(Matrix Factorization 사용)
추천시스템에서 유저의 관심도를 보는 지표로 CTR, 클릭수를 많이 사용한다. 그러나 이는 실수로 클릭할 수도 있고 충분한 정보를 제공하지 못할 때가 있다. 그렇기에 본 논문에서는 유저가 특정 아이템에 머문 시간인 dwell time을 사용한다.
Measuring Item Dwell Time
지금까지 리뷰한 논문들은 추천 모델에 집중했다면 여기서는 dwell time 데이터를 어떻게 정제할 지 집중한다.
client-side logging에서 수집된 정보를 ground truth로 해서 server side logging에서 수집된 정보를 정제하는 두가지 방법을 비교한다.
FB방법: 아이템에 focus가 시작된 시간과 끝난 시간 사이의 간격들을 더해서 dwell time을 계산
LE방법: 아이템에 관심을 둔 첫시간과 마지막 시간 사이의 간격을 계산
비교한 결과 FB 방법이 더 client-side logging dwell time과 유사했다.
사용기기(태블릿, 핸드폰, pc)와 아이템의 종류(이미지, 텍스트)에 따라서 dwell time의 분포가 다르기 대문에 정규화를 한다.
정규화 방법은
Use Case I : Learning to Rank
클릭수를 타겟으로 한 선형 모델 / dwell time을 타겟으로 하는 그레디언트부스팅 모델/ dwell time을 weight으로 하는 그레디언트부스팅 모델을 구성하고 오프라인 지표(MAP, NDCG)에서의 성능과 online 성능을 비교했다. 오프라인에서와 온라인에서 모두 dwell time을 weight으로 하는 그레디언트부스팅 모델 성능이 가장 좋았다.
Use Case II : Collaborative Filtering
collaborative filtering에서 rating대신 dwell time을 예측하는 모델을 만들었다. 실험결과 클릭수를 타겟으로한 모델보다 dwell time을 타겟으로 한 모델이 성능이 좋았다.