[Paper Review] (2018, KDD) Real-time Personalization using Embeddings for Search Ranking at Airbnb
Recommender_System

1. INTRODUCTION




 !
!
2. RELATED WORK
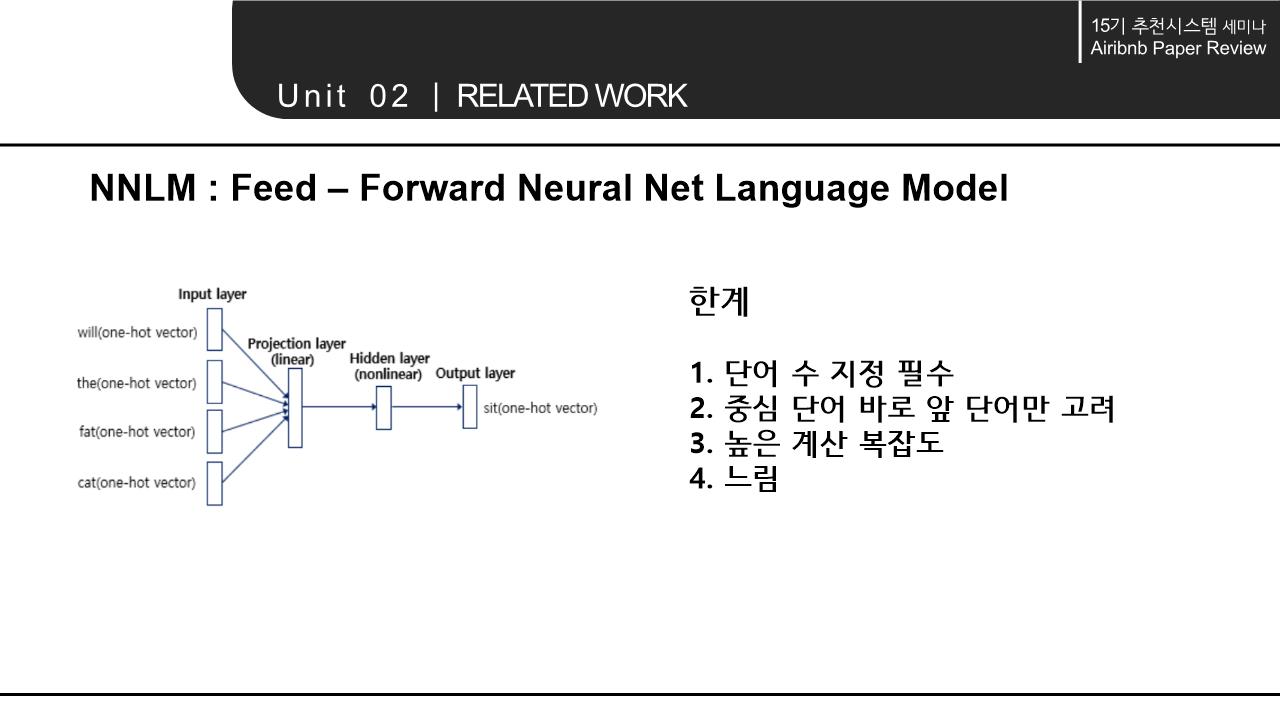
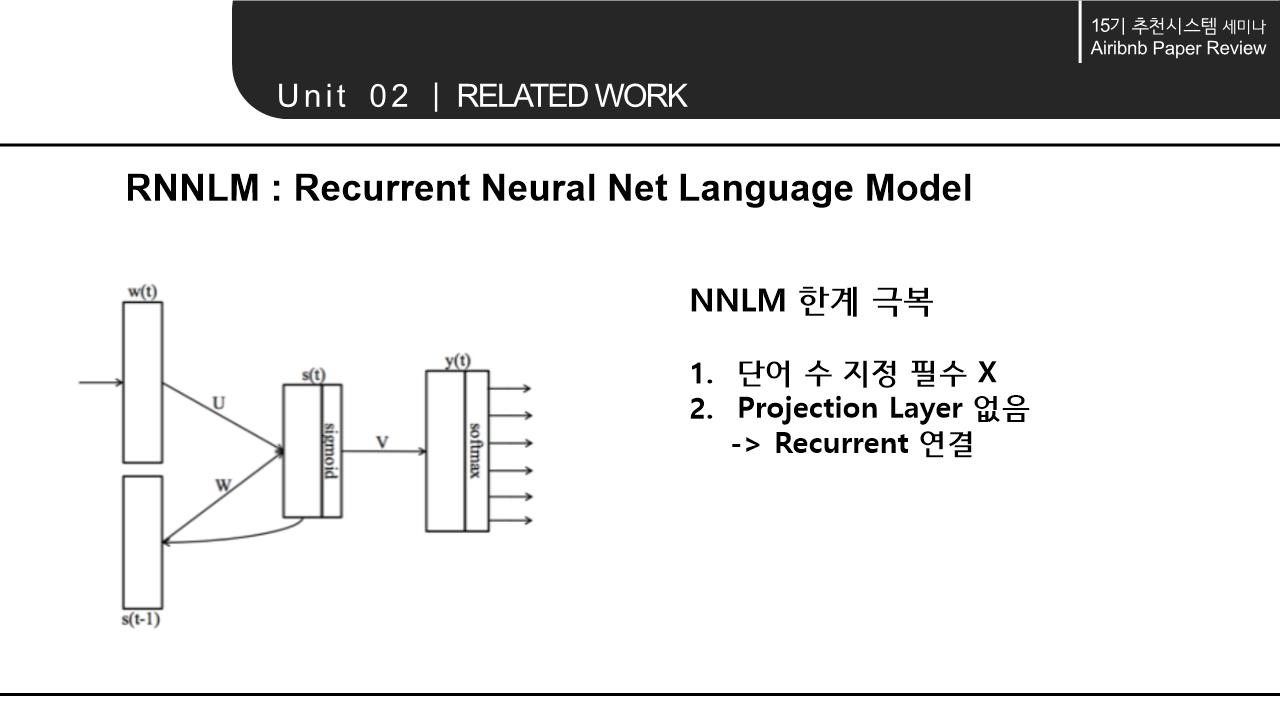
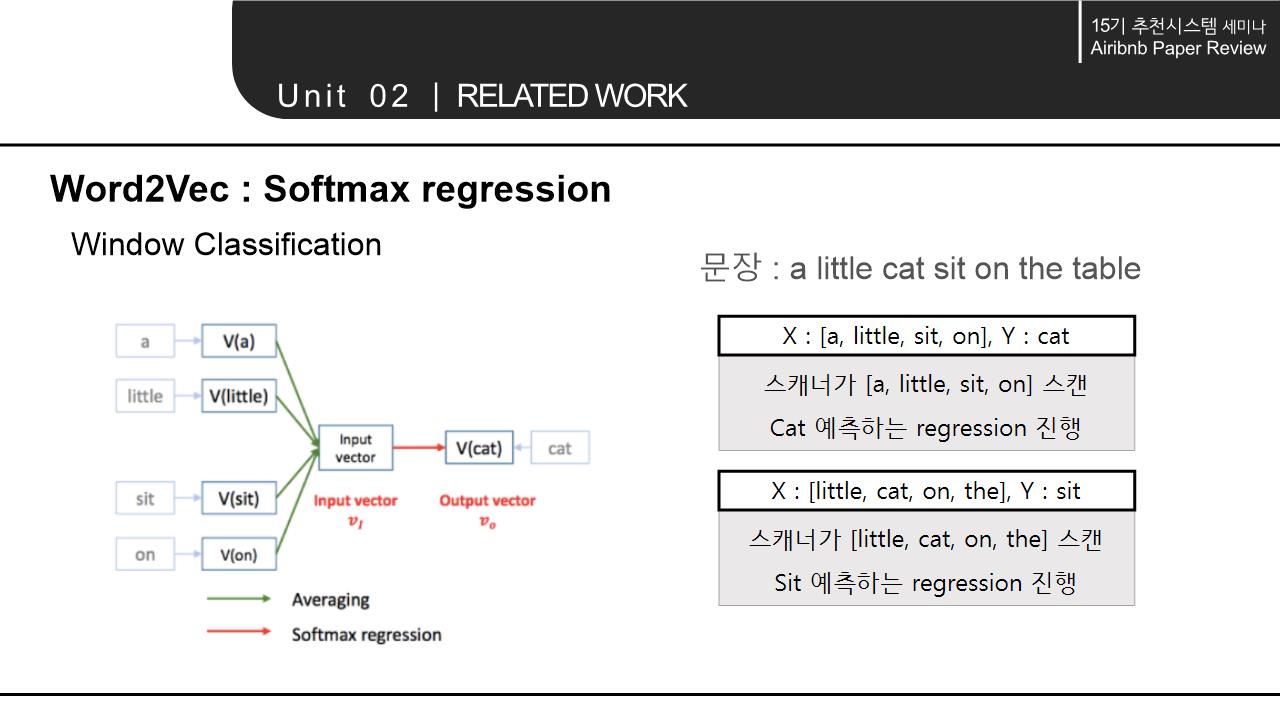
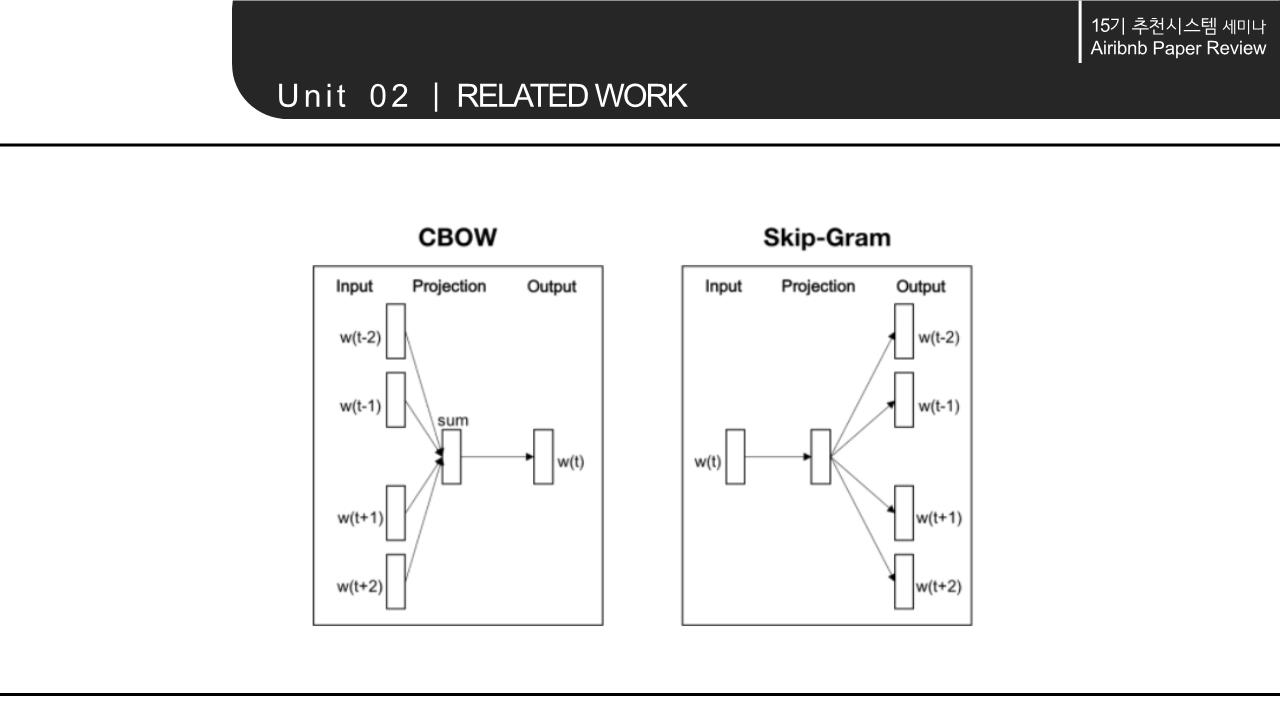
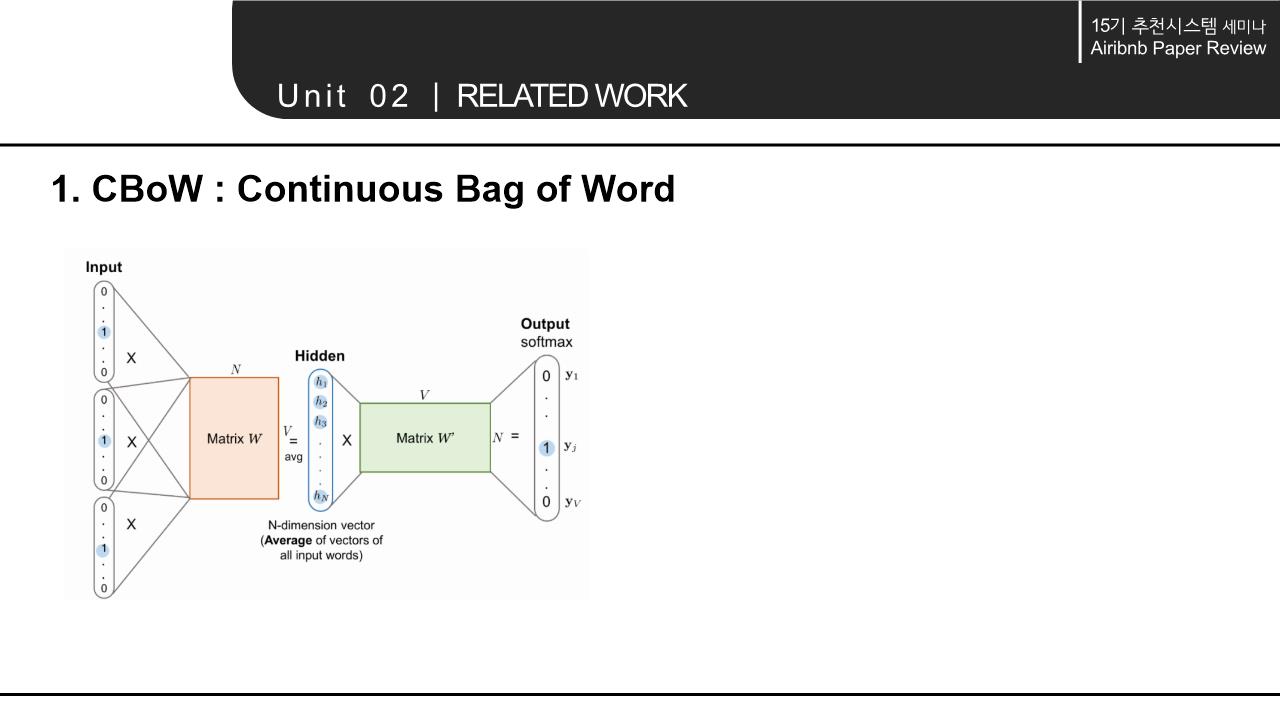
해당 논문의 Related work에서는 word를 Embedding하는 NLP모델의 계속된 향상과 context 속에서 word의 의미를 파악해 vectorization하는 것에서 나아가 다양한 분야에 확장/적용 가능하다는 점을 시사함. 이에 따라 간략하게 NLP 모델의 구조와 NLP 모델의 발전 에 대해 살펴봄.







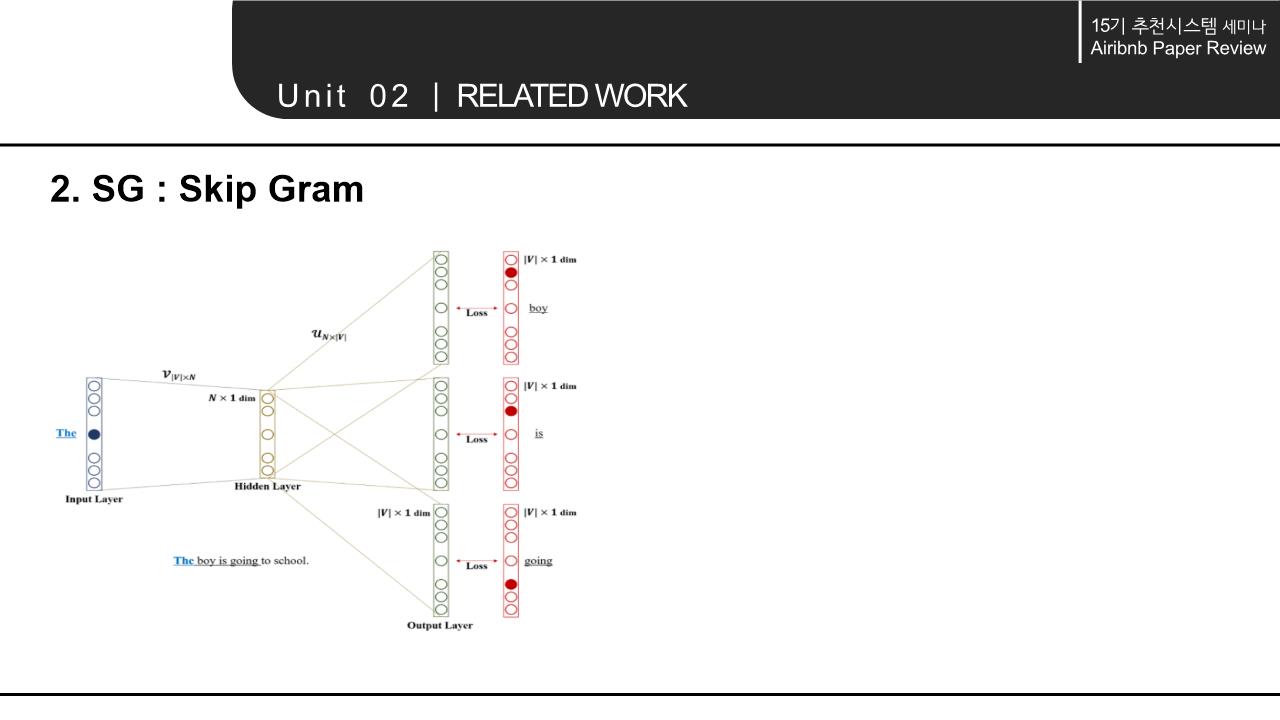

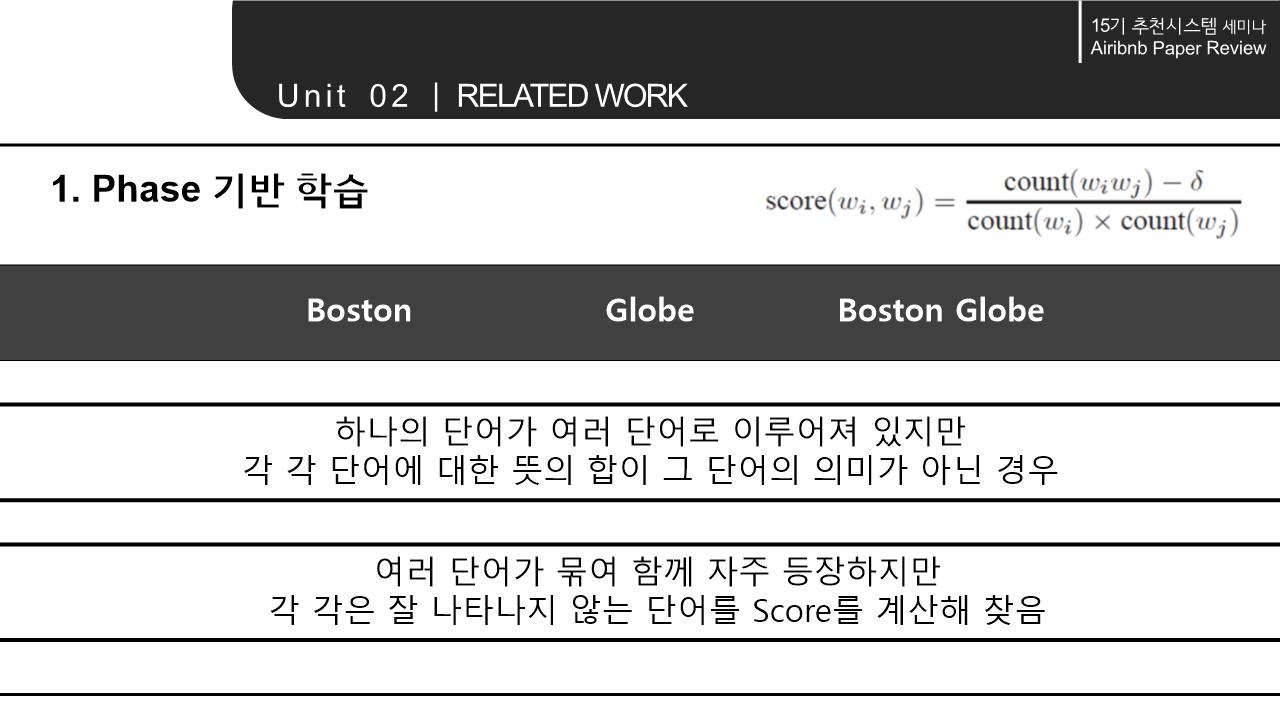
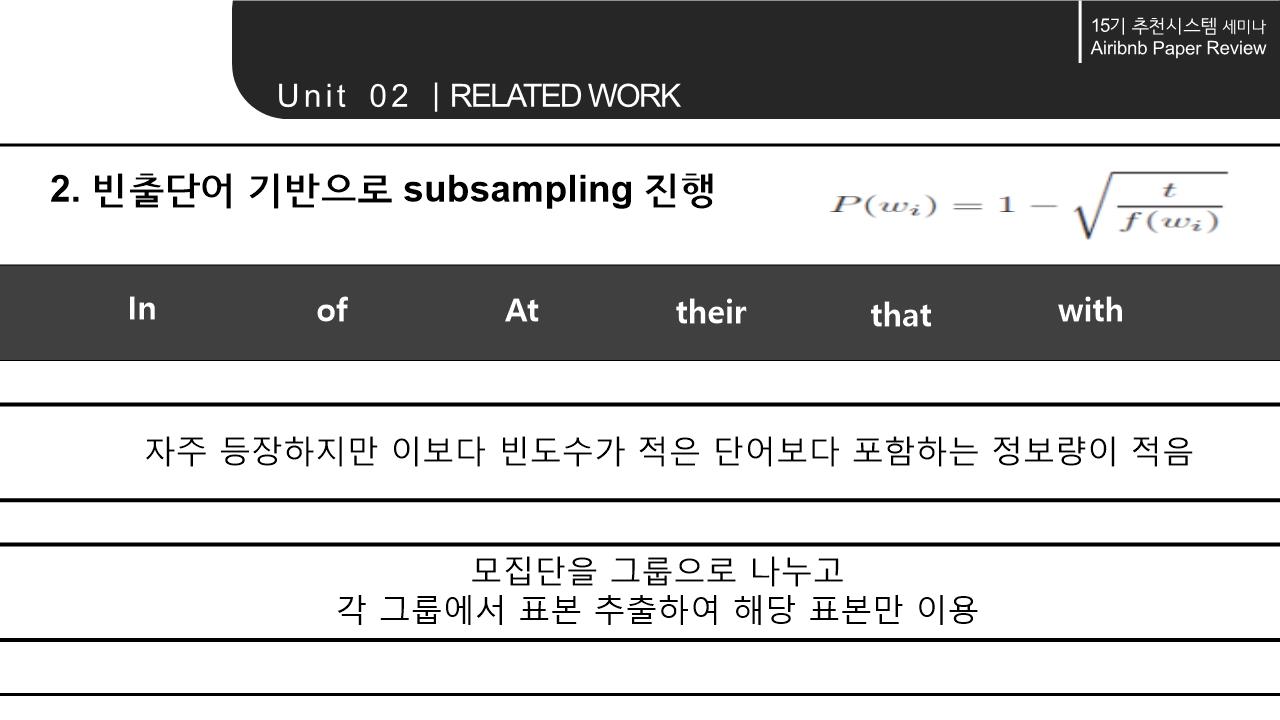
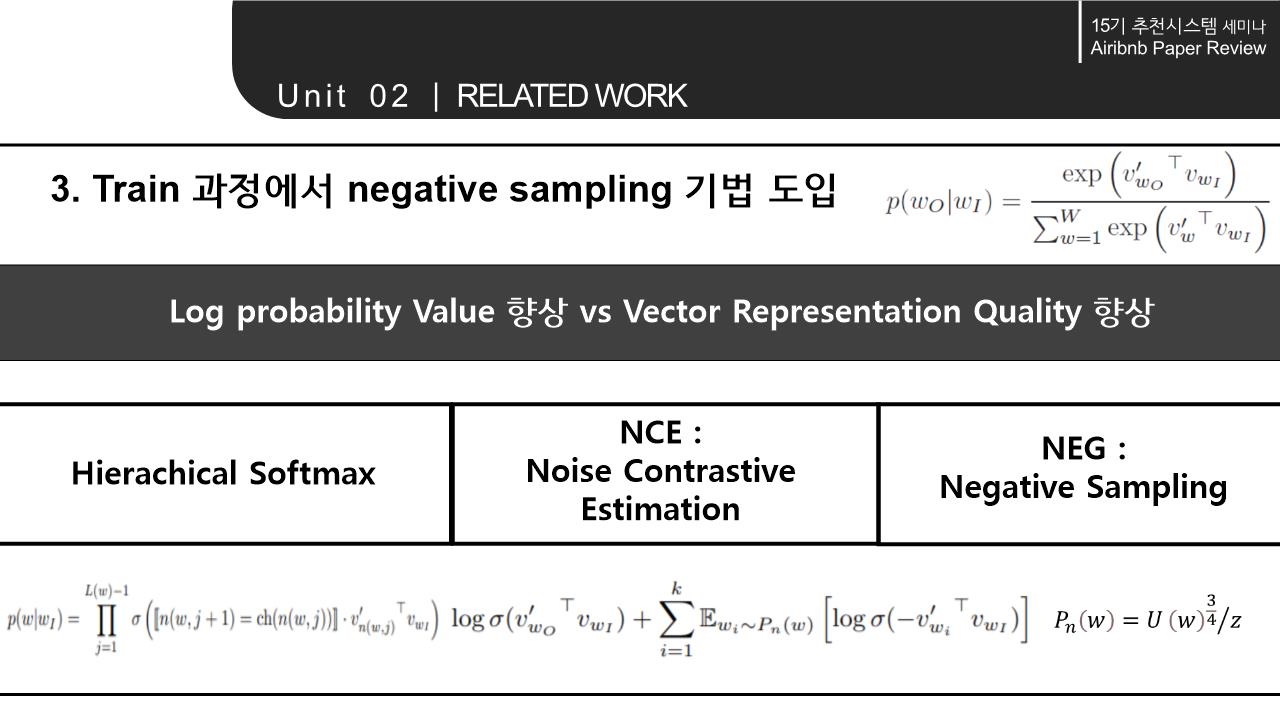

3. METHODOLOGY














4. EXPERIMENTS




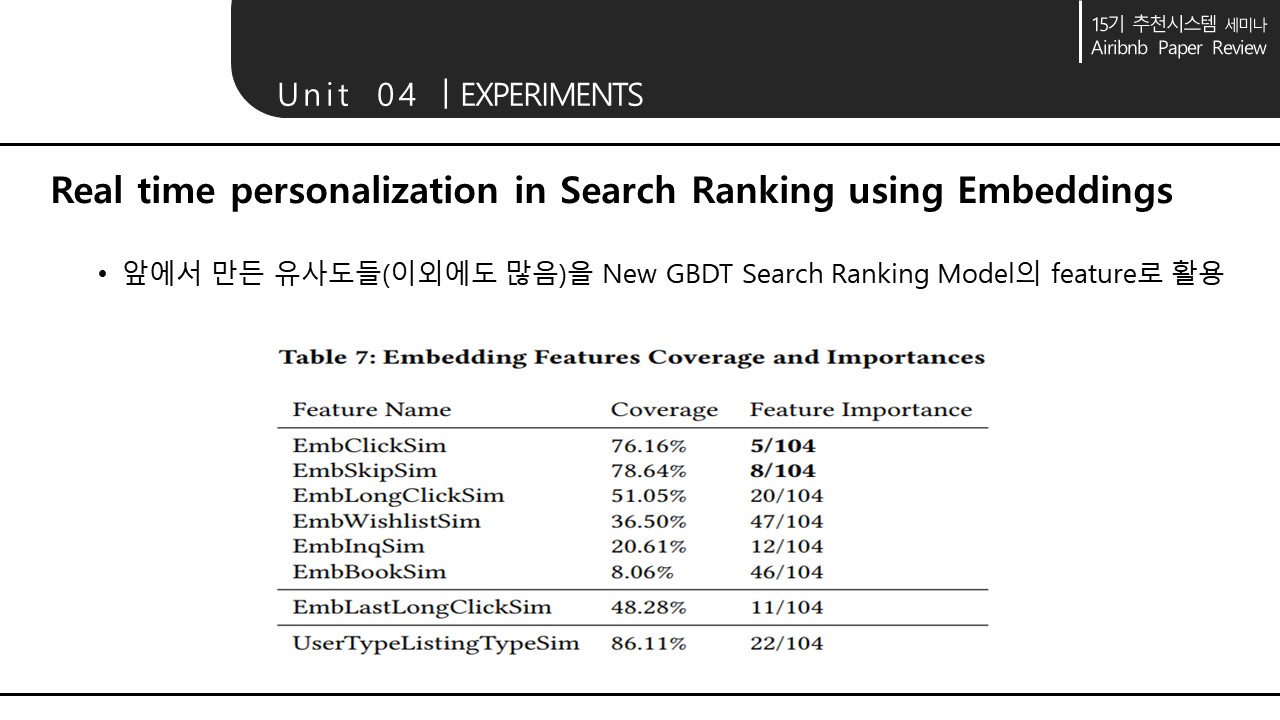
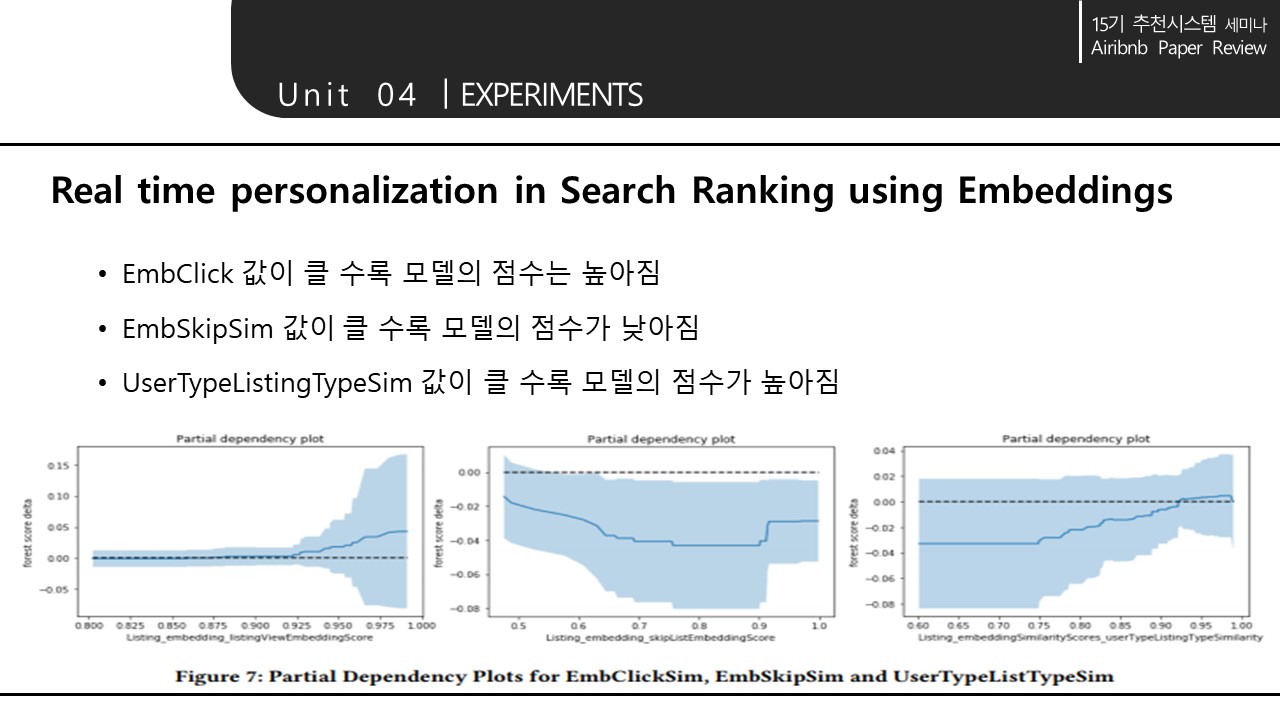
5. CONCLUSION

참고 자료
-
Mihajlo Grbovic & Haibin Cheng. (2018). Real – time Personalization using Embedding for Search Ranking at Airbnb. KDD
-
https://papers.nips.cc/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf
-
https://lovit.github.io/nlp/representation/2018/03/26/word_doc_embedding

2개의 댓글

[15기 강지우]
목적
유저, 호스트에게 적합한 숙소(Listing)을 추천하는 것
[Listing Embedding]
input: 특정 숙소를 클릭한 순간부터 예약하는 순간까지의 클릭 세션
output: 숙소의 임베딩
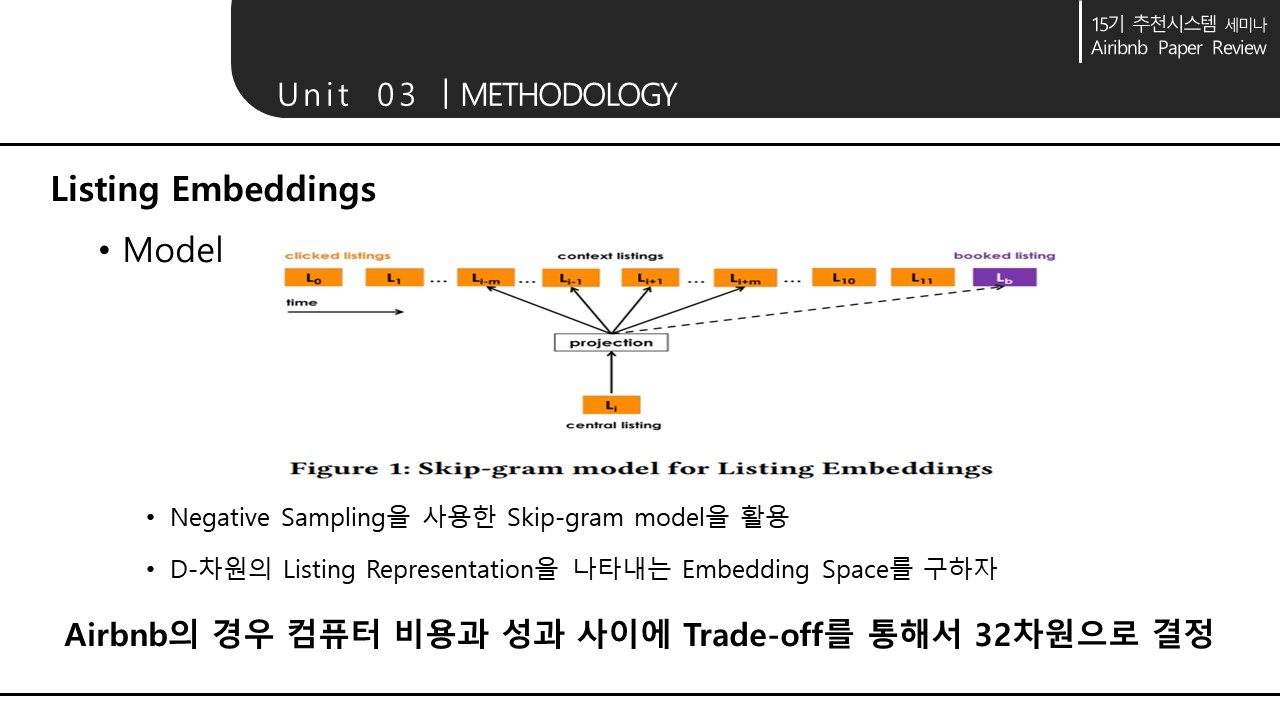
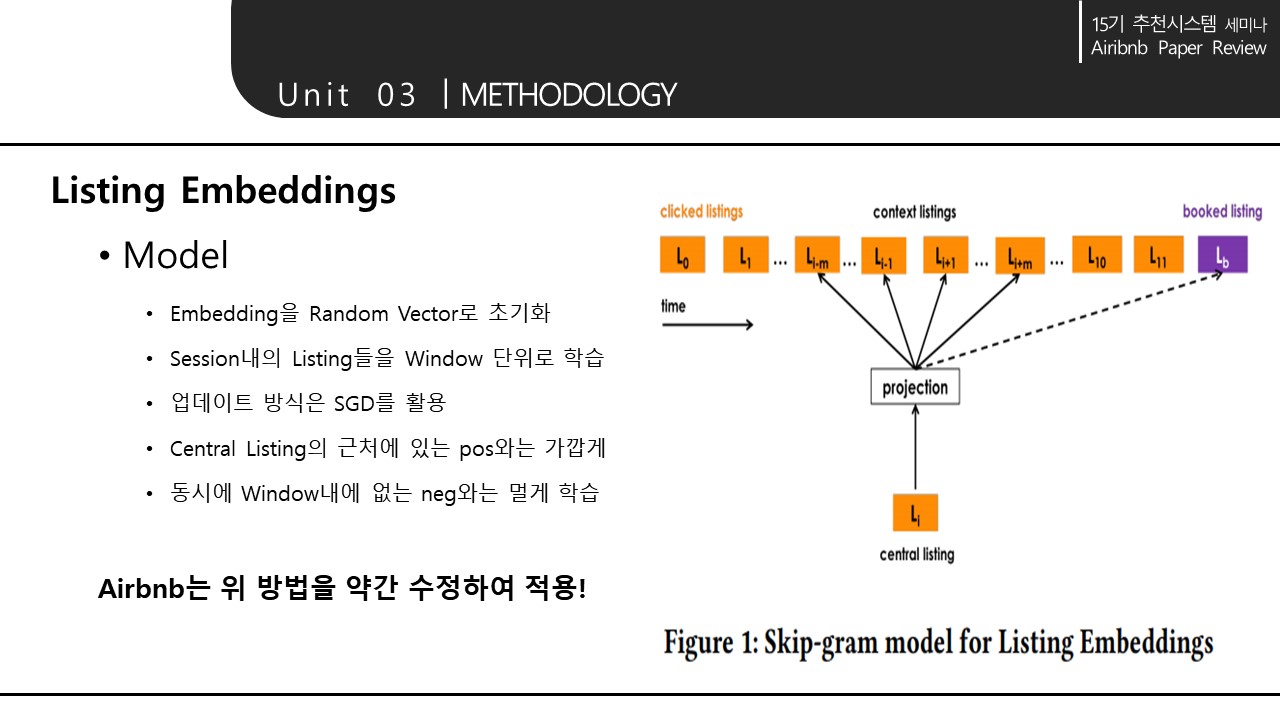
word2vec 모델의 skip gram 사용. -> 가까운 위치에서 자주 클릭된 숙소간은 비슷한 값을 가지게 된다.
Central Listing 근처에 있는 pos와 가깝게, 같은 Window내에 없는 neg와는 멀게 학습함.
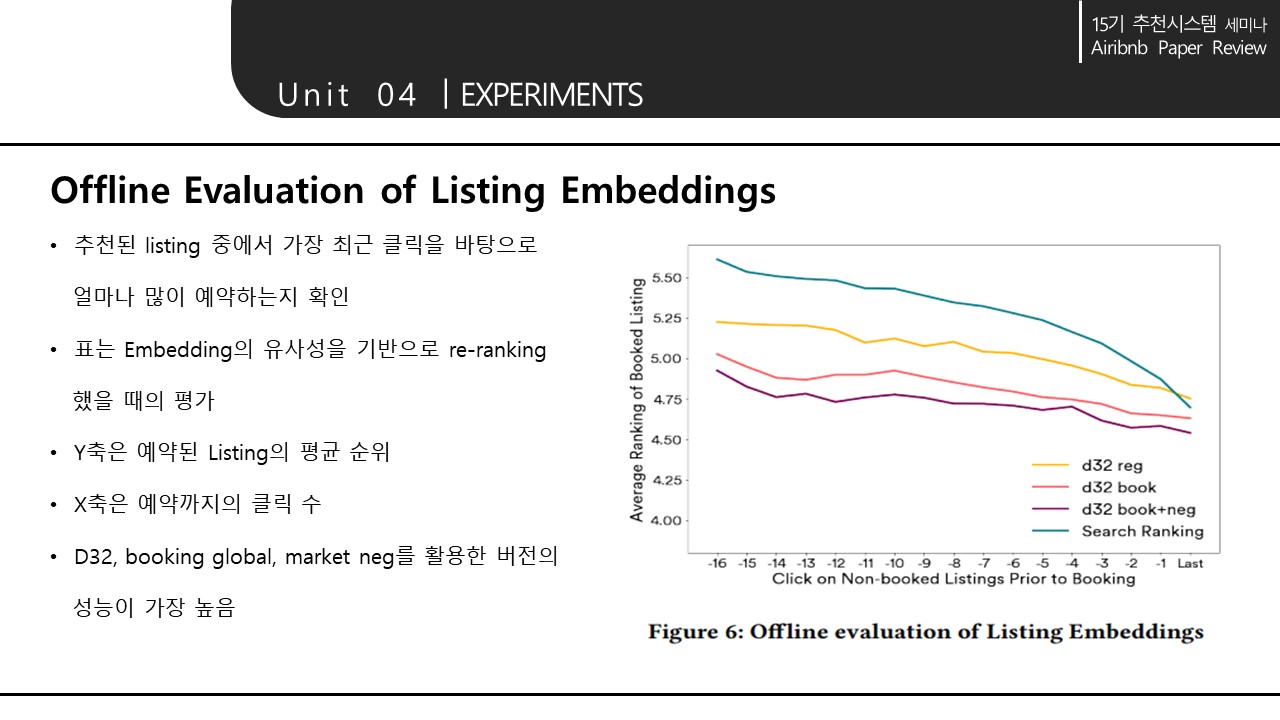
대개 다른 지역의 숙소가 negative, 같은 지역내의 숙소가 positive가 된다. 그러나 대부분 같은 지역의 숙소 sample이 많을 것이므로 data가 imbalance하게 된다. 따라서 같은 지역내의 neg도 추가(neg Dmm set)
[User-type & Listing-type Embeddings]
input: user type과 listing type의 세션
output: user type, listing type의 임베딩
에어비앤비 특성 상 예약을 여러번 하는 사용자는 매우 적음. 세션의 길이가 1이 되버려서 skip gram을 사용할 수 없다.
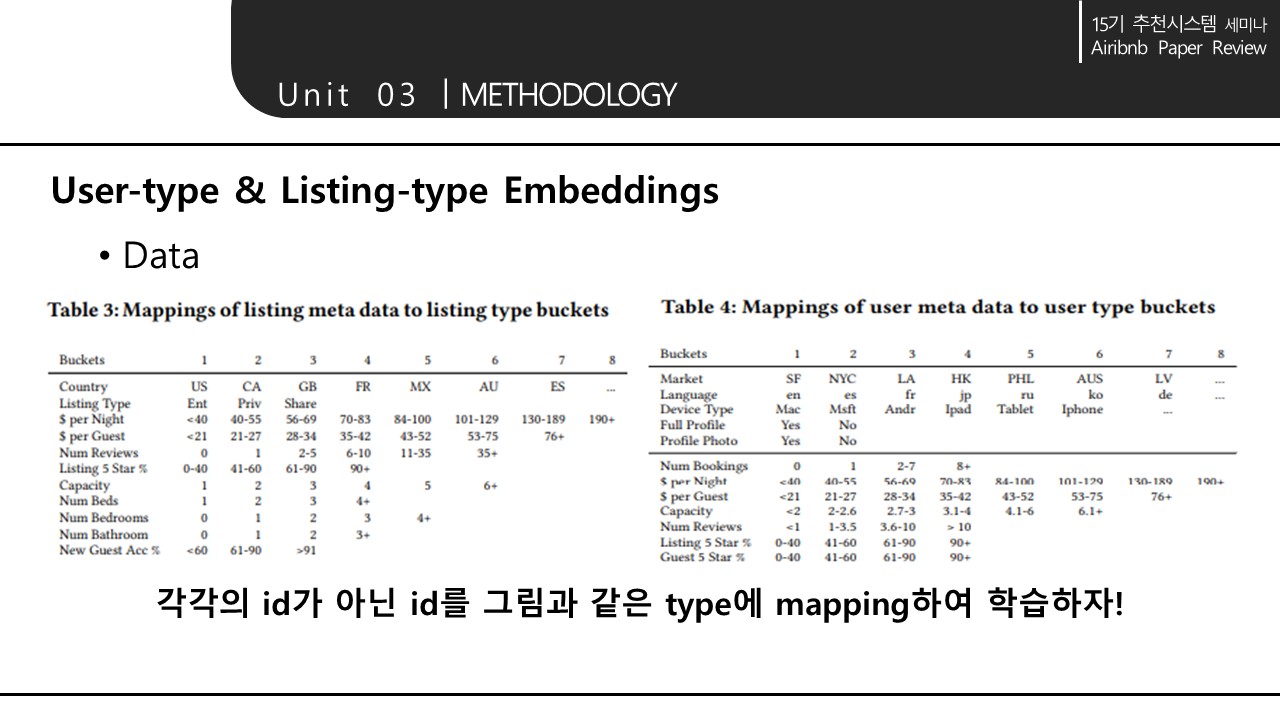
유저와 숙소의 메타데이터를 이용해서 타입을 나눈다.
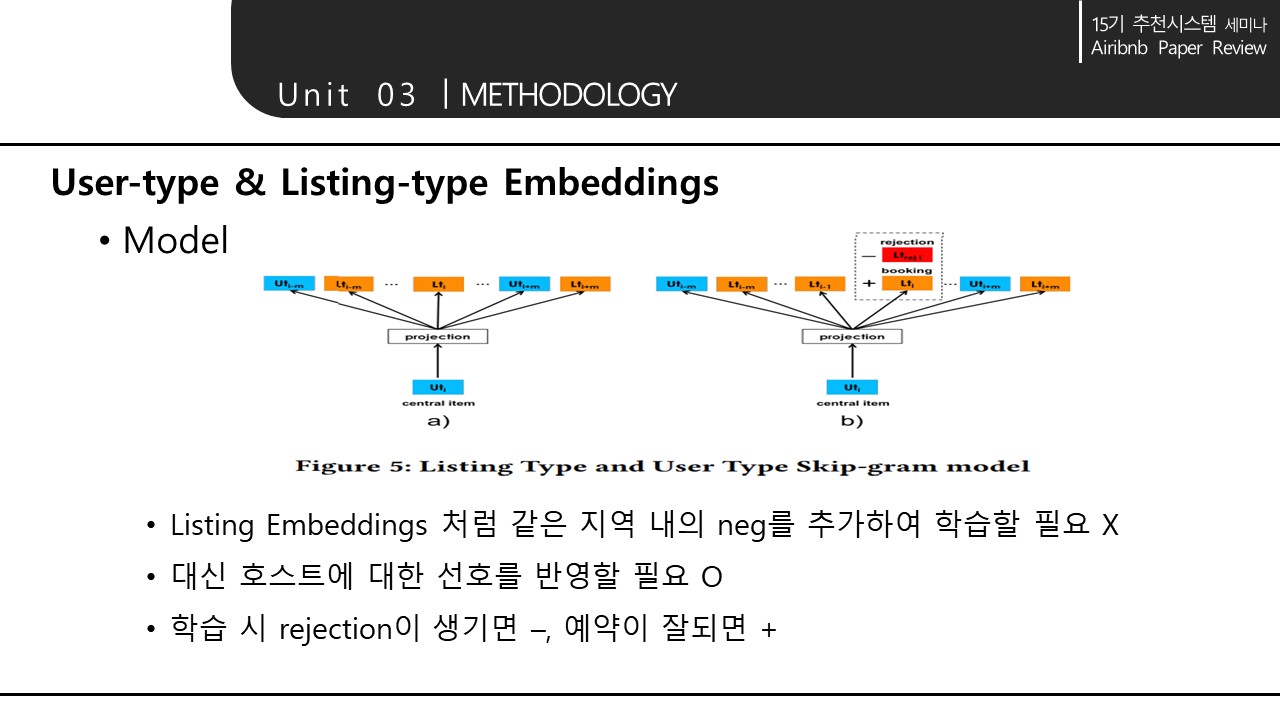
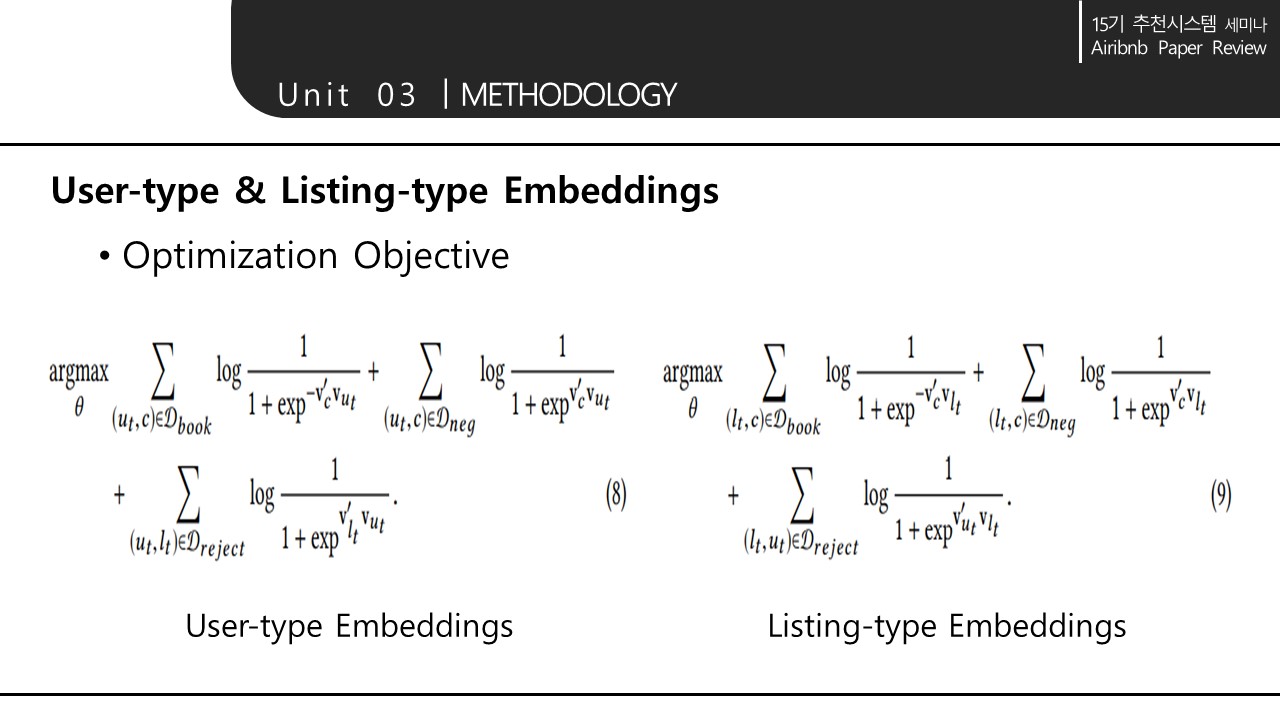
생성한 타입을 기반으로 skip-gram 모델을 적용한다. 학습시 rejection이 생기면 - 예약이 생기면 +를 부여한다.
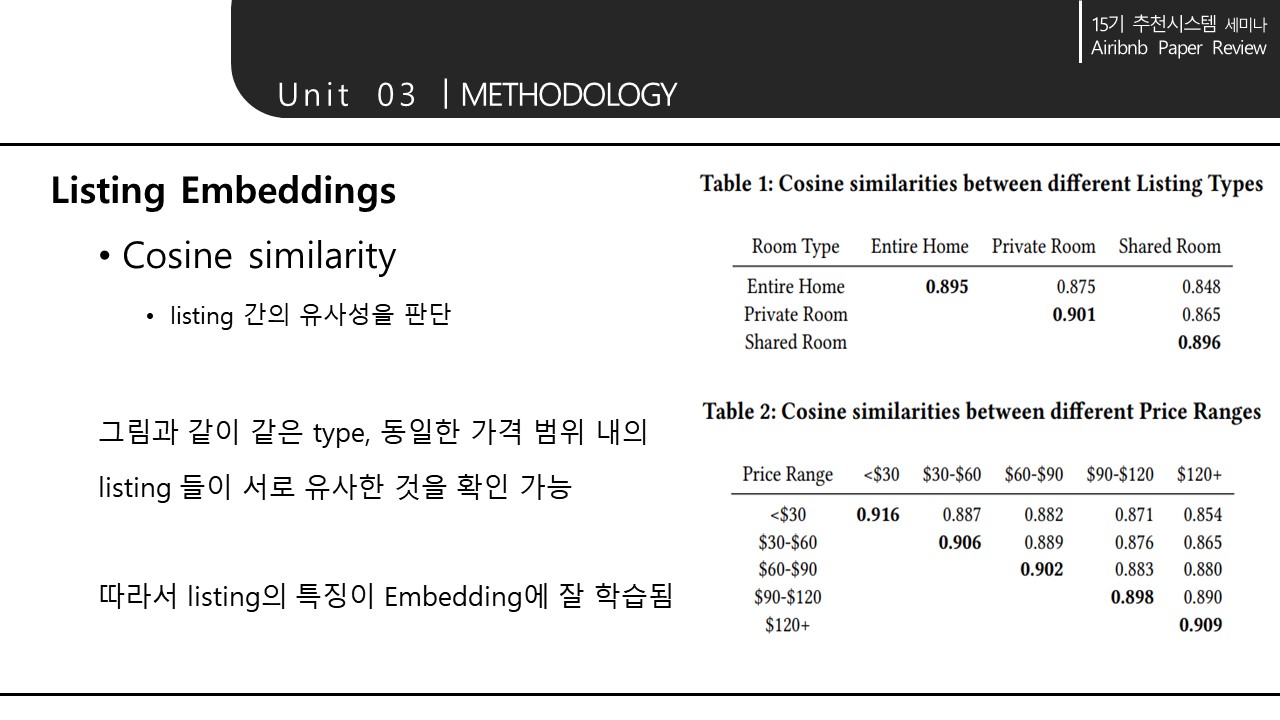
->비슷한 위치의 숙소와 유저는 가까운 값을 가지게 된다.
-> 특정 유저 타입과 가까운 숙소 타입을 알 수 있다.
기업에서 실제로 사용한 모델이라는 점에서 흥미로웠다. word2vec을 약간 변형한 모델이어서 간단해보이지만 현업에서 CTR이 21%, 예약이 4.9% 증가됐다고 하니 놀라웠다.
Real-time Personalization using Embeddings for Search Ranking at Airbnb
15기-류채은
목표: Host와 Guest 모두 만족시키는 search ranking & 추천서비스 제공
Skip-gram: Vector representation quality 높이기
개인화를 위한 embedding:
**클릭이 모인 세션들을 활용하여 embedding
Negative sampling: 각 단어의 빈도수 고려-> 자주 등장하는 단어를 높은 확률로 샘플링