
작성자: 13기 고유경
1. Introduction
1.1 Long-tail
이커머스 등 온라인 서비스에서 중요한 롱테일(Long-tail) 법칙
: 80%의 사소한 다수가 20%의 핵심 소수보다 뛰어난 가치를 창출한다.
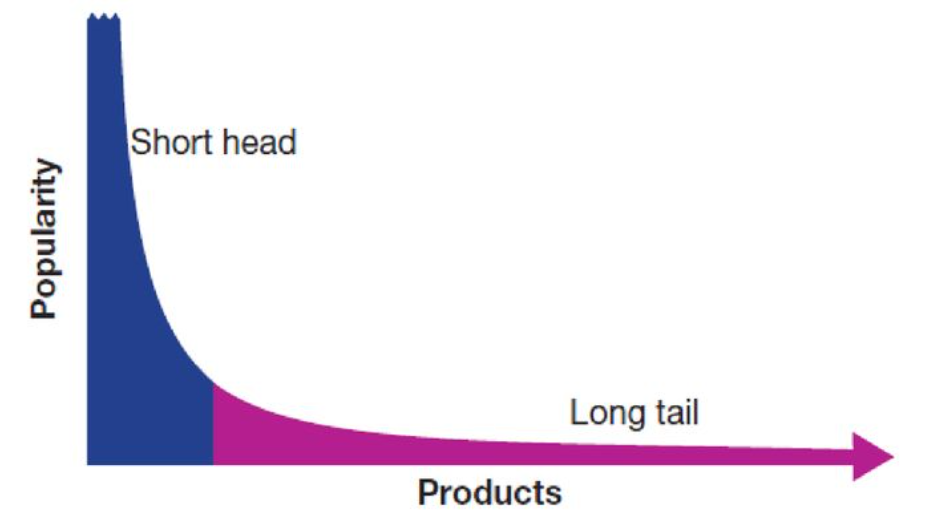 각 상품들의 총 판매량을 더해보면 인기있는 상품들의 집합이 아닌 긴 꼬리 부분의 합이 더 크다.
각 상품들의 총 판매량을 더해보면 인기있는 상품들의 집합이 아닌 긴 꼬리 부분의 합이 더 크다.
- User 관점
- 인기 아이템(short-head)만 추천하는 것은 유저에게 지루함을 유발할 수 있다.
- 롱테일 아이템이 유저에게 더 적절할 수 있고 선택에도 다양성을 줄 수 있다.
- one-stop shopping convenience: 인기아이템과 롱테일아이템을 동시에 구매하도록 유도할 수 있다.
- Business 관점
- 매출 증진(large marginal profit than short-head items)
1.2 Difficulties in Long-tail SRS
SRS: Session-based Recommendation System
[기존 추천 모델들]
Data sparsity -> popular item에 치우치는 bias 존재
[기존 롱테일 추천 연구]
- 추천의 정확도를 희생시키거나,
(2012) Improving aggregate recommendation diversity using ranking-based techniques
(2013) Trading-off among accuracy, similarity, diversity, and long-tail: a graph-based recommendation approach
(2017) Enhancing long tail item recommendations using tripartite graphs and Markov process
- data sparsity 문제를 완화하기 위해 SRS의 data limit에서 벗어난 side information(e.g., user profile)을 활용하기도 한다.
(2017) DLTSR: A deep learning framework for recommendation of long-tail web services
(2017) Two birds one stone: on both cold-start and long-tail recommendation
[Long-tail SRS 의 3가지 어려움]
-
Lack of side info. in sessions -> 기존 롱테일 추천 방식이 적용되기 어렵다.
-
기존 롱테일 추천 모델은 sequential한 데이터를 잘 처리하지 못한다. -> 정확도 급락
-
각 유저의 여러 세션들이 각각 독립으로 처리되기 때문에 상당히 많은 세션 데이터가 sparse하다. 이는 롱테일 추천에서 모델 성능을 악화시킨다.
1.3. TailNet
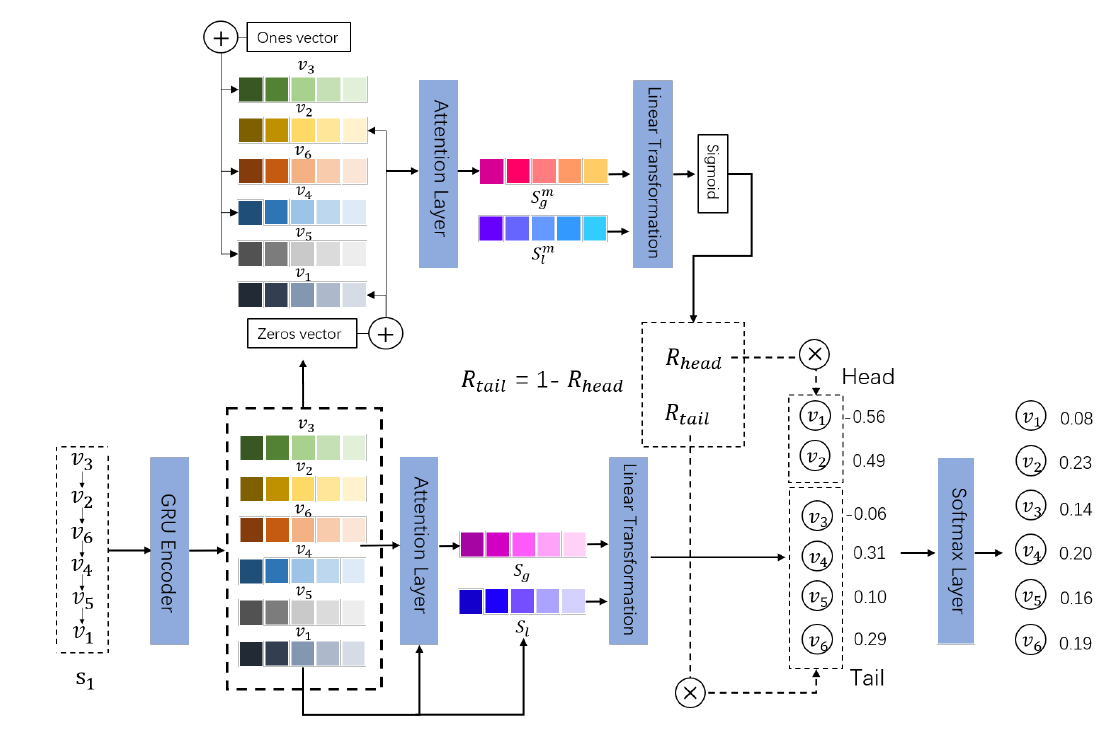
- SOTA 모델과 비슷한 결과를 내면서 롱테일 추천의 성능 향상
- 각 세션을 latent representation으로 인코딩
- Preference mechanism
- short-head 아이템과 long-tail 아이템 사이 유저의 선호도를 결정
- session representation을 학습하고 rectification factors 생성
- end-to-end로 학습
2. Model
Aim of SRS: 유저의 현재 세션 데이터를 가지고 다음에 클릭할 아이템을 예측
2.1. Notations
: unique items in all sessions
: short-head items, : long-tail items (Pareto Principle - 2대8 법칙)
: 시간순으로 item을 정렬한 session
: session encoder layer를 통해 인코딩된 session의 latent representation
2.2. GRU Encoder
 -->
-->
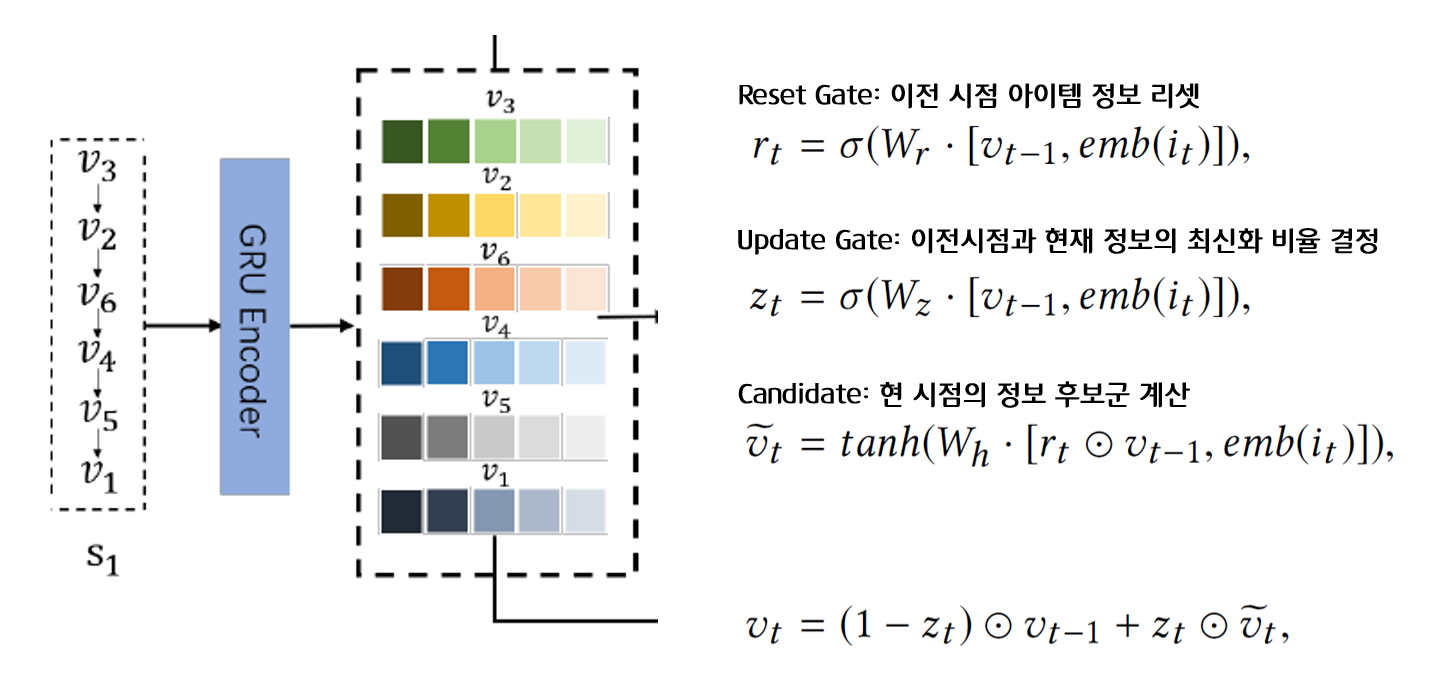
세션 가 인풋으로 들어가면 GRU Encoder를 거쳐 각 아이템별로 차원의 벡터 로 이루어진 세션의 latent representation 가 나온다.
- GRU Encoder
- Reset Gate: 이전 시점의 아이템 정보와 현재 시점의 아이템이 인풋으로 들어오며 얼마만큼의 정보를 리셋할지 비율이 결정된다.
- Update Gate: reset gate와 반대로 얼마만큼의 정보를 업데이트할지 비율이 결정된다.
- Candidate: reset gate의 아웃풋인 벡터 와 이전 시점 정보인 를 곱한 결과를 이용하여 현 시점의 정보 후보군을 계산한다.
- update 결과와 candidate 결과를 결합하여 현재 시점의 아이템 정보를 담은 벡터를 반환한다.
2.3. Preference Mechanism
: softly adjust the recommendation mode of the model
: 유저의 선호도에 따라 long-tail을 더 추천해주거나, short-head를 더 추천해준다.
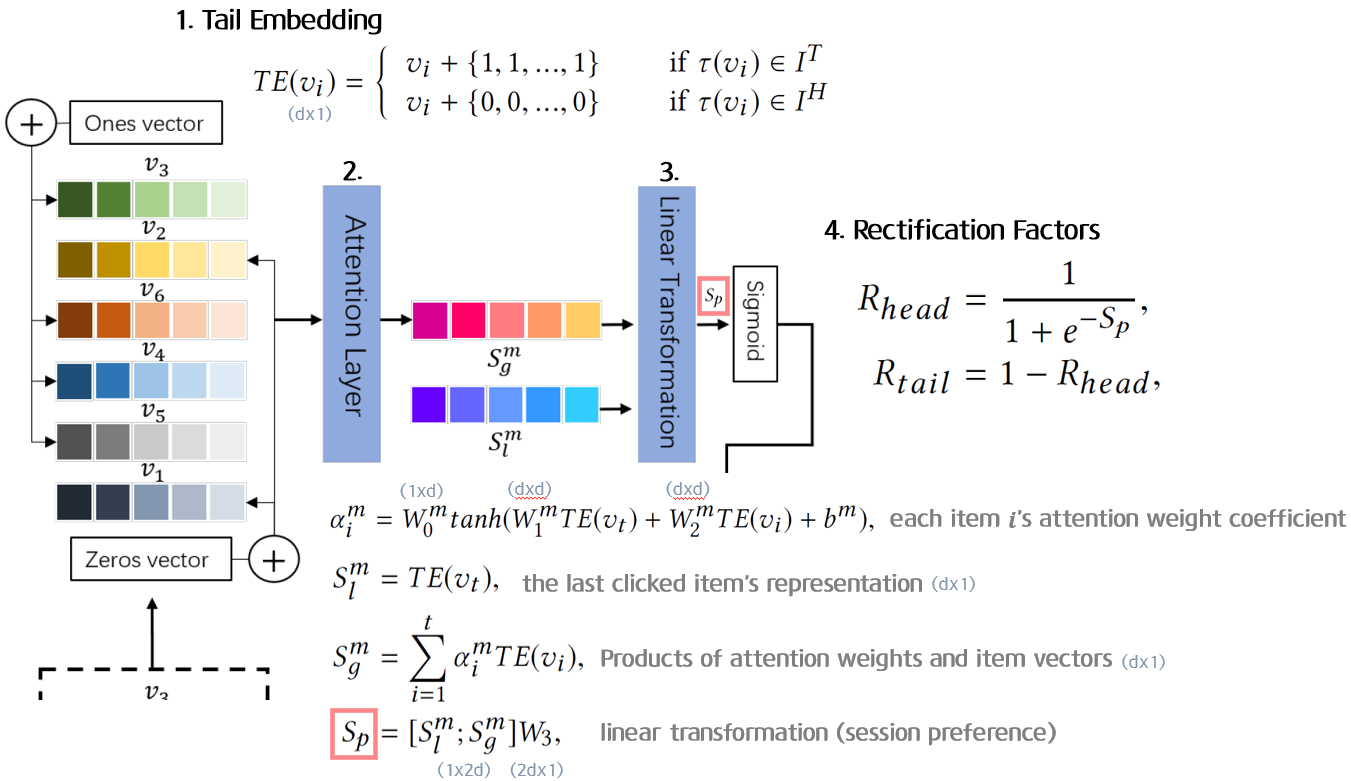
1. Tail Embedding
: i번째 아이템이 long-tail인지 short-head인지 나타내는 mapping function
long-tail=1, short-head=0으로 채워진 input과 동일한 차원의 벡터를 각 아이템 벡터에 더해준다.
2. Attention
: i번째 아이템과 마지막 t번째 아이템 사이의 관계를 나타내는 attention weight (scalar)
: 각 아이템 별 attention weight를 Tail Embedding을 거친 아이템 벡터에 곱한 ( x ) 벡터
3. Linear Transformation
마지막으로 클릭한 아이템의 tail embedding 벡터()와 Attention layer를 거쳐 나온 벡터를 이어붙여 ( x ) 차원의 가중치 벡터와 선형결합하여 해당 세션의 선호도를 나타내는 점수 를 반환한다.
4. Rectification Factors
시그모이드 함수를 이용하여 session preference 에서
short-head의 rectification factor 값을 구하고,
long-tail의 rectification factor 값을 구한다.
와 은 후에 Soft Adjustment 단계에서 각각 short-head와 long-tail 아이템 점수들에 곱해지는 가중치로 활용된다.
2.4. Session Pooling and Soft Adjustment
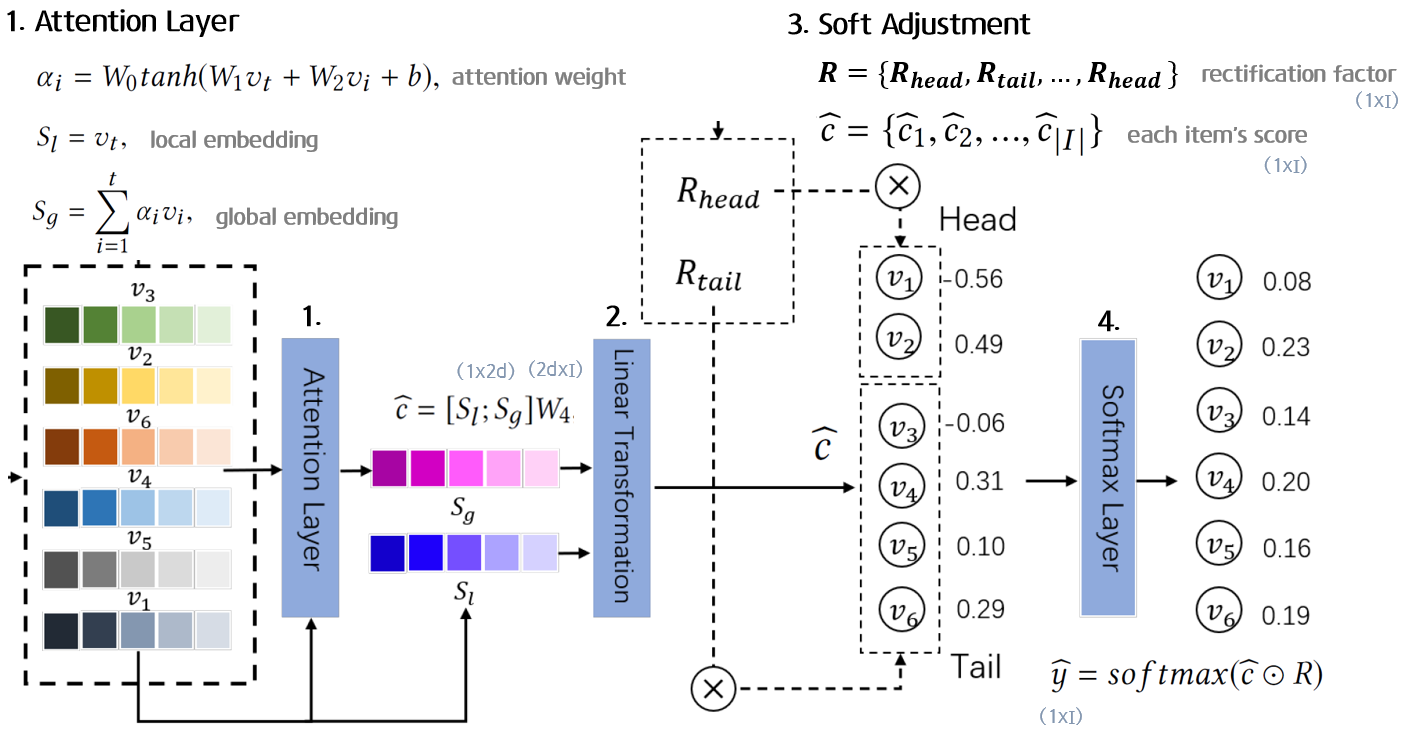
1. Attention
다시 GRU Encoder로 돌아와서 해당 결과로 나온 를 또 다른 Attention layer에 태운다.
Preference Mechanism과 마찬가지로 각 아이템별로 마지막 아이템과의 관계를 나타낸 attention weight (scalar)를 구해 각 시점의 아이템 임베딩 벡터에 곱하여 global embedding 벡터 를 생성한다.
마지막 t번째 시점의 아이템이 GRU Encoding을 거쳐 나온 를 local embedding 벡터 로 둔다.
2. Linear Transformation
과 를 이어붙인 ( x )벡터와 ( x ) 차원의 가중치 벡터 를 선형결합하여 전체 아이템 개수와 동일한 차원의 벡터를 반환한다.
:score of corresponding item before softmax
3. Soft Adjustment
Preference mechanism을 통해 구한 rectification factor 와 으로 구성된 차원의 벡터 를 동일한 차원의 아이템 점수 벡터 와 element-wise product 연산을 진행한다.
이를 통해, 각 아이템 점수는 long-tail인지 short-head인지에 따라 해당 가중치가 곱해져 유저가 선호하는 종류의 아이템의 점수가 더 커지도록 한다.
4. Softmax
를 softmax layer에 태워 각 아이템이 다음에 올 확률값으로 이루어진 차원의 벡터 를 반환한다.
이 중 Top-K values들이 다음에 올 아이템으로 추천된다.
5. Cross-Entropy loss
Sum of the cross-entropy of each item's pred. and the ground truth
: one-hot encoding vector of ground truth items
3. Experiments
3.1. Datasets
-
YOOCHOOSE: sequences of click events (recent fractions 1/4)
-
30MUSIC: listening and playlists data retrieved from Internet radio stations
3.2. Baseline
Traditional methods
-
Frequency based methods : POP, S-POP
-
Neighborhood based method: Item-KNN
-
Traditional matrix factorization, Markov Chain approaches: FPMC, BPR-MF
Neural network based methods
-
RNN-based methods: GRU4REC, NARM
-
Repeat-explore method: RepeatNet
-
Attention-based method: STAMP
-
GNN-based method: SR-GNN
3.3. Evaluation Metrics
[정확도 측정]
Recall@K: 전체 relevant한 아이템 중 추천된 아이템이 속한 비율
MRR@K: (Mean Reciprocal Rank) 사용자가 선호하는 아이템이 리스트 중 어디에 위치해 있는지 평가
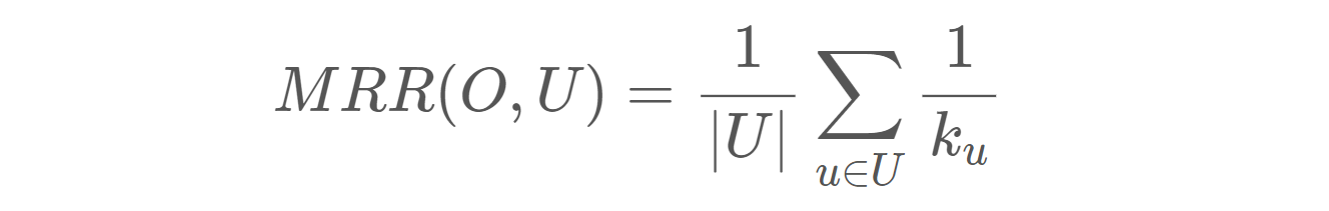
[Long-tail 추천 평가]
Coverage@K: 전체 아이템 중 top-K 추천 목록에 있는 고유한 아이템 개수의 비율
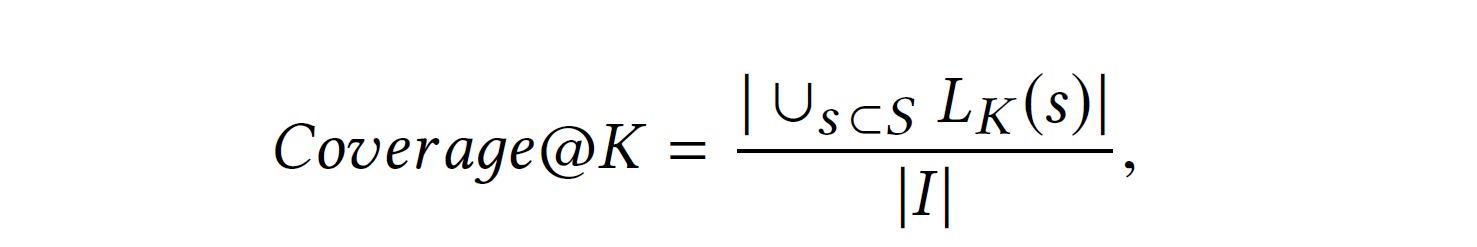 : list of top-K recommended items for session
: list of top-K recommended items for session
Tail-Coverage@K: 전체 롱테일 아이템 중 top-K 추천 목록에 있는 고유한 롱테일 아이템 개수의 비율
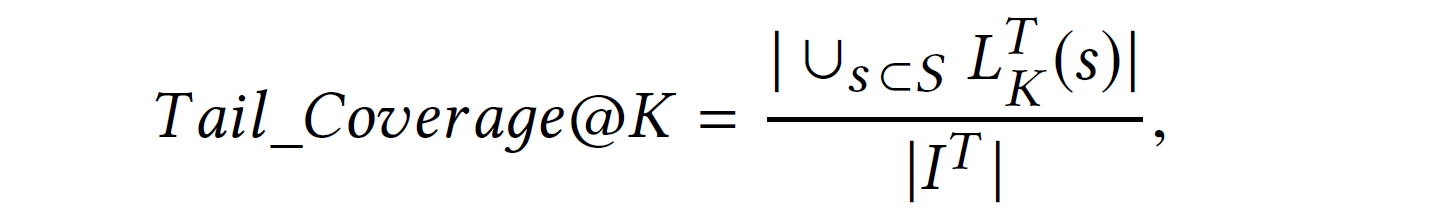 : 중 롱테일 아이템에 속한 아이템으로 이루어진 하위집합
: 중 롱테일 아이템에 속한 아이템으로 이루어진 하위집합
Tail@K: 각 추천 목록에 얼마나 많은 롱테일 아이템이 포함되는지 나타낸 비율
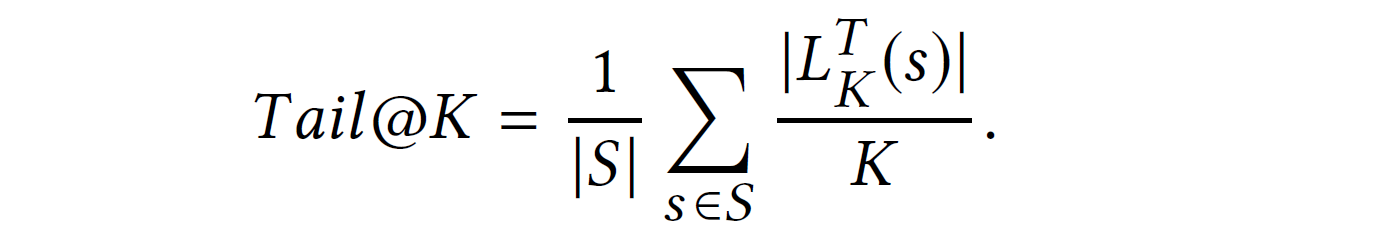
4. Result and Analysis
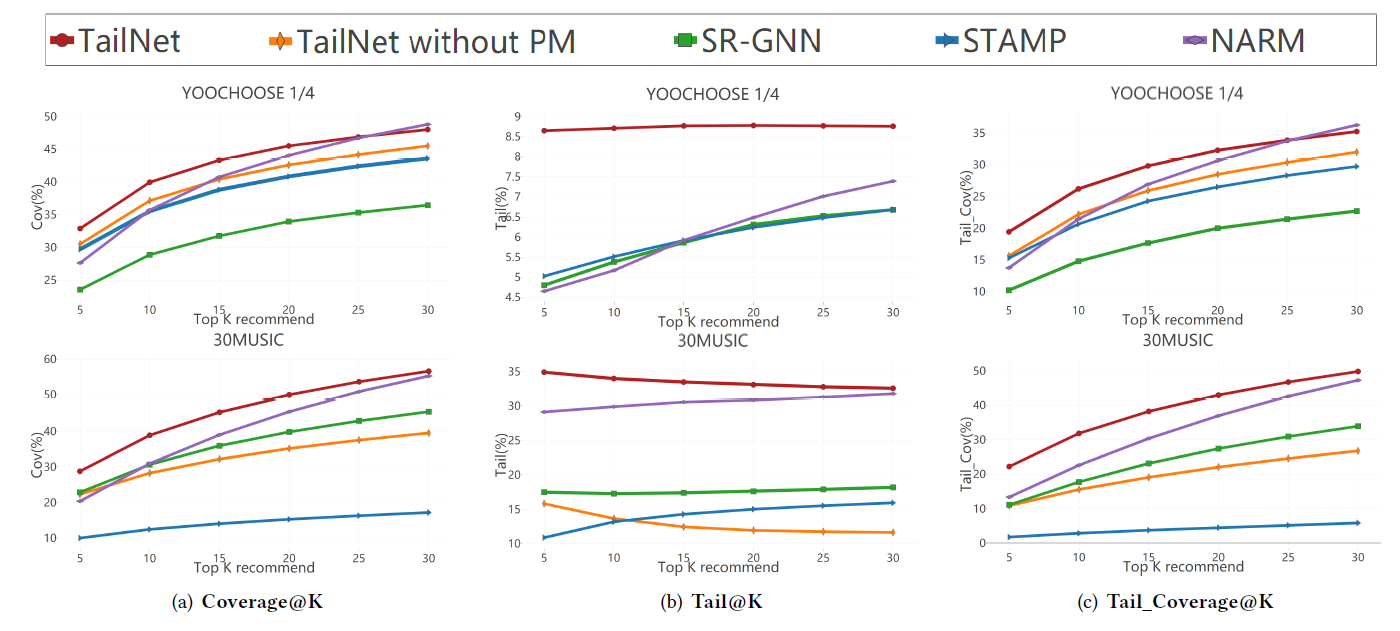
The performance of TailNet with other baseline methods on two datasets
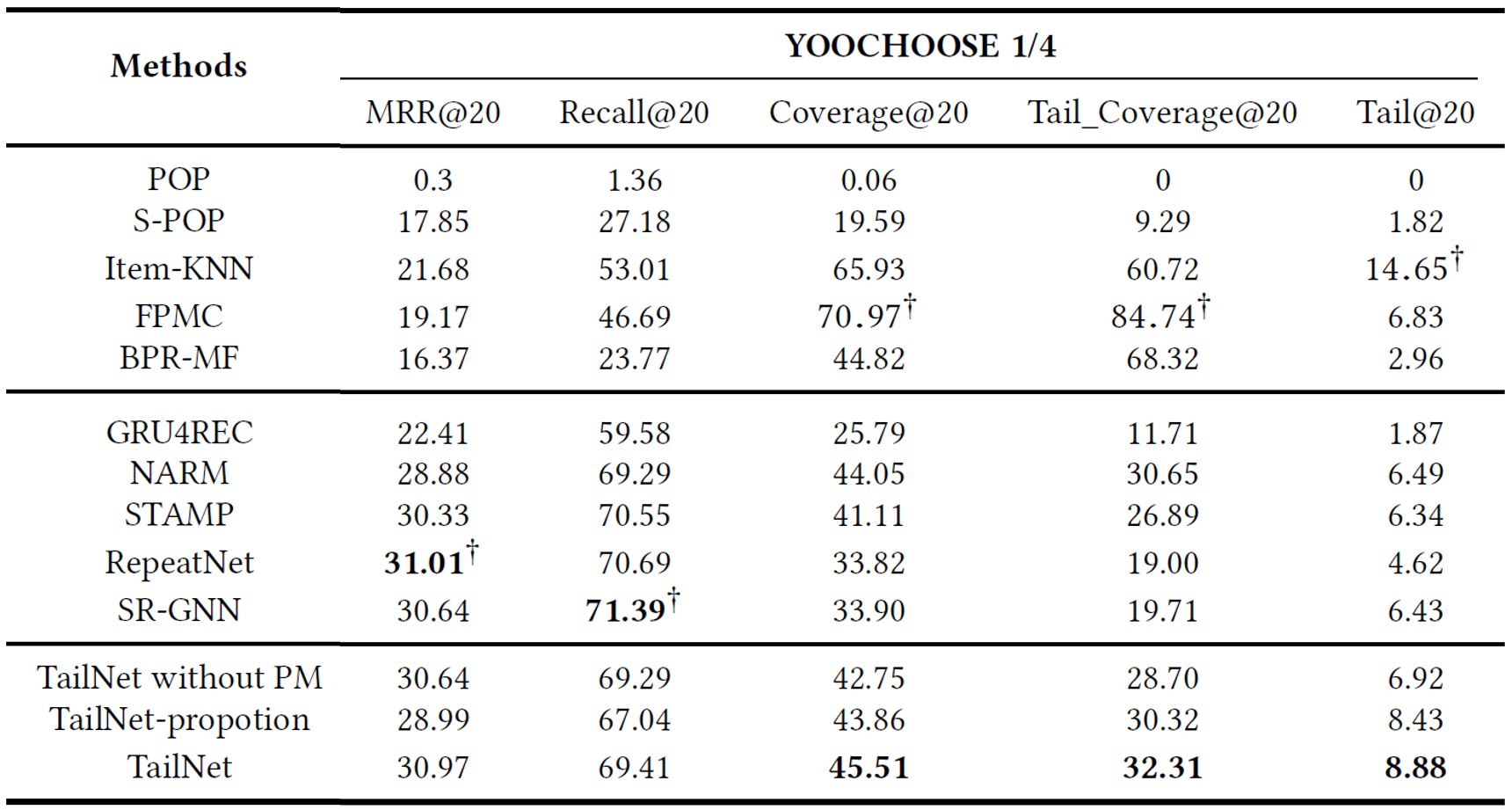
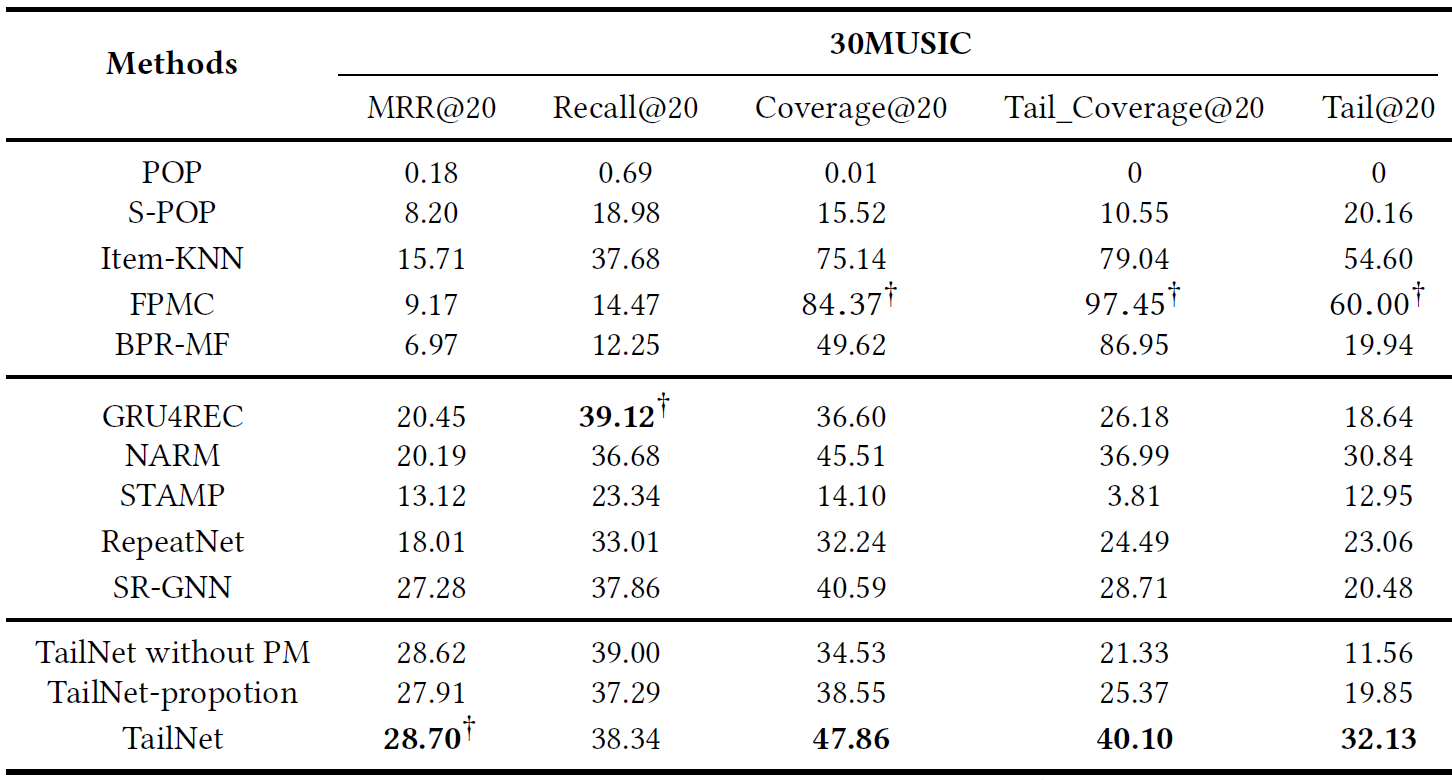
- 초기 추천 모델들이 정확도 측면에서는 뉴럴넷 기반 추천모델들 보다 성능이 낮지만, long-tail 추천 성능에서는 앞선다.
-> 정확도 만으로 추천 모델을 평가하는것은 충분하지 않다.
-> Trade-off btw accuracy and long-tail recommendation
-
반면, TailNet은 초기 추천 모델들보다 정확도는 높으면서, 뉴럴넷기반 Sota 모델들보다 높은 long-tail 추천 성능을 낸다.
-> balance long-tail recommendations and accurate recommendations -
TailNet은 long-tail 추천에 포커스를 두고 있음에도 불구하고, long-tail와 short-head 아이템 사이 유저의 선호도를 적절하게 파악하여 Preference mechanism이 정확도에 큰 변동을 유발하지 않는다.
-
Application of Preference Mechanism in Other Models
- Preference Mechanism(PM)은 다른 뉴럴넷 기반 모델과도 결합하여 롱테일 추천 성능을 향상시킬 수 있다.
- 세션의 latent representation만 있으면 PM을 통해 rectification factor 와 를 생성할 수 있다.
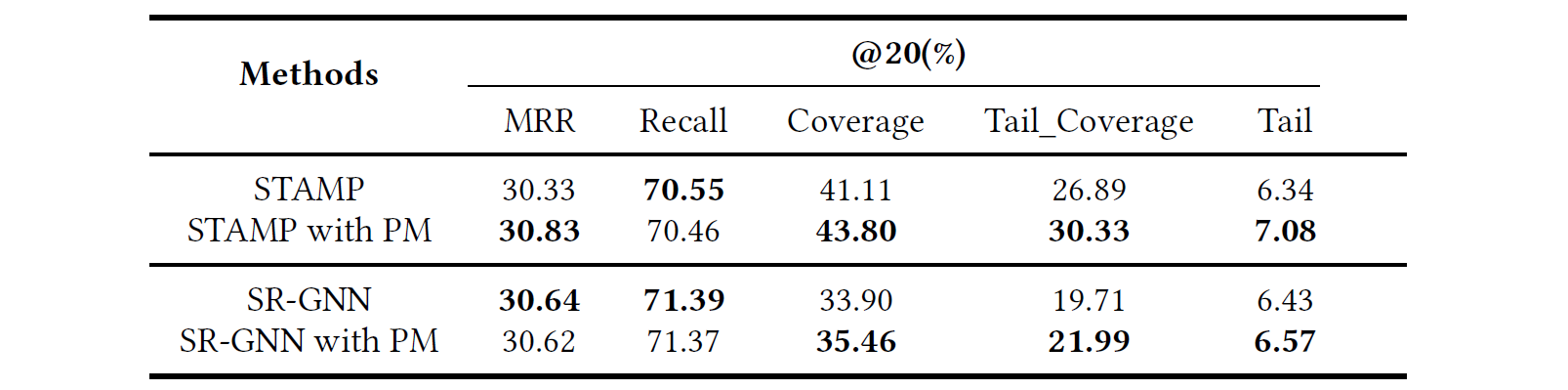
- 실제로 attention 계열의 모델 STAMP와 GNN 계열 모델인 SR-GNN에 각각 PM을 적용한 결과, 정확도에 큰 변동 없이 long-tail 성능이 향상되었음을 확인할 수 있다.
- PM을 통해 뉴럴넷 기반의 모델이 long-tail 추천에서 정보 부족 문제를 극복하는데 도움이 될 수 있다.

2개의 댓글

[15기 이성범]
e-커머스 산업에서는 상위 20% 고객도 중요하지만 하위 80% 고객으로부터 더 많은 이윤을 얻을 수 있다는 롱테일 법칙이 존재한다. 이를 추천시스템에 적용하면 상위 20%의 아이템에서 얻는 이윤보다 하위 80%의 아이템에서 얻을 수 있는 이윤이 더 높다고 할 수 있다. 따라서 하위 80%의 아이템을 잘 추천해준다면 기업의 이윤을 더 높일 수 있을 것이다. 하지만 하위 80% 아이템은 관심이 적은 만큼 데이터 측면에서 바라볼 때 매우 sparse 할 것이다. 이러한 sparse한 데이터는 모델의 성능을 떨어트리기 때문에 하위 80%의 아이템을 추천해주기 위한 추천 시스템을 만드는 것은 매우 어렵다고 할 수 있다. 이러한 문제를 해결하고자 제안된 모델이 바로 본 논문에서 제시하는 TailNet이다.
TailNet은 크게 전체 세션을 기반으로 학습시키는 부분과 Tail을 임베딩하여 학습시키는 부분으로나뉘어져 있다. 전체 세션을 학습시키는 부분은 GRU Encoder, Attention Layer, Linear Transformation 이루어져 있다. GRU Encoder를 통해서 각 아이템별로 d차원의 Latent Representation 벡터를 구하고, 해당 벡터를 Attention Laye를 통과시키고, Linear Transformation 통해서 해당 세션의 선호도를 나타내는 점수를 반환한다. 후에 Tail을 임베딩하여 학습시키는 부분과 합쳐서 Softmax Layer를 거쳐서 각 아이템 들에 대한 확률 값을 구하는 방식으로 모델이 구성된다. 본 모델은 Tail 부분을 학습시키기 위해서 long-tail과 short-head를 구분하여 0과 1의 원핫벡터를 Tail 임베딩에 더한다. 이러한 방식을 통해서 TailNet은 long-tail 부분에 조금 더 집중할 수 있는 모델을 만들 수 있었다.
14기 박지은
기존의 session-based 추천시스템과 달리, 해당 연구는 TailNet을 고안하여 long-tail 추천 성능을 개선하여 다양한 추천과 세렌디피티를 선보였습니다. TailNet은 우선 session encoder layer를 통해 인코딩된 latent representation을 GRU 인코더를 통해 인코딩합니다. 다음으로 preference mechanism에서 유저의 선호도에 따라 long-tail이나 short-head를 더 추천해줍니다. 마지막으로 Attention, Linear Transformation, Soft Adjustment를 거친 아웃풋이 softmax를 취한 후 cross-entropy loss로 학습됩니다. 이렇게 학습된 TailNet은 초기 추천시스템보다 높은 정확도를 가지며, NN 기반 SOTA 모델보다 높은 long-tail 추천 성능을 낸다고 합니다. Long-tail 추천에 대하여 관심이 있어서 궁금했는데, 친절하고 자세한 설명 덕분에 너무너무 유익한 시간이었습니다. 감사합니다!