
작성자: 박지은
1. Introduction and Background
1-1. Conversational Recommendation이란?
추천시스템
추천시스템은 상황에 따른 데이터를 토대로 유저가 원하는 아이템을 찾도록 도와주는 시스템입니다. 최근의 연구들은 유저의 과거 행동을 기반으로 선호도를 예측하거나 일련의 제안을 도출하는 일방향의 one-shot interaction paradigm을 가집니다. 그러나 이러한 접근은 잠재적으로 한계가 있습니다.
Conversational Recommendation
Conversational Recommender System (CRS)는 이와 다르게 접근하여 task-oriented의 지원과 유저와의 multi-turn dialogue를 사용합니다. 이를 통하여 대화 중에 시스템은 유저의 구체적인 현재의 선호도를 알 수 있으며, 아이템 추천에 대하여 설명을 제공하거나, 제안한 추천에 대한 유저의 피드백을 처리할 수 있습니다. CRS는 이렇게 추천시스템에 유저와의 natural language dialogue로 접근하여 개인화된 추천을 제공합니다.
① Task-oriented
CRS의 기본적 특징 중 하나는 task-orientation으로 추천에 관련된 구체적 태스크와 목적을 지원합니다. 이 시스템의 주요 태스크는 유저들의 결정 과정을 돕거나 연관 정보를 찾게 하는 것입니다. 부가적으로 CRS는 유저가 자신의 선호를 알게 하거나 설명을 제공할 수도 있습니다.
② Multi-turn
CRS의 다른 주요 특징은 multi-turn conversational interaction입니다. Siri 같은 기존 one-shot Q&A-style 추천은 multi-turn conversation을 유지하기 어렵지만, CRS는 dialogue state management을 활용하여 대화 내역과 현재 상태를 계속 추적합니다.
1-2. Brief History
CRS에 대한 연구는 매년 그 수가 증가하고 있습니다. 주요 연구로는 1987년 "A New Approach to the Design of Document Retrieval Systems"에서 데이터 수집을 위한 유저와 시스템의 상호작용이 연구되기 시작하였고, 1995년에는 "On the Design of Interactive Information Retrieval Systems"라는 논문이 나오며 script-based한 대화형 상호작용으로 데이터를 수집하고자 했습니다. 마지막으로 2000년에는 "A Conversational Recommendation System"이라는 논문에서 Conversational Recommendation이라는 개념이 등장했습니다. 또한 CRS의 발전은 기술적인 측면과 상업적인 측면 모두에서 유저와 시스템 간에 선순환이라고 합니다.
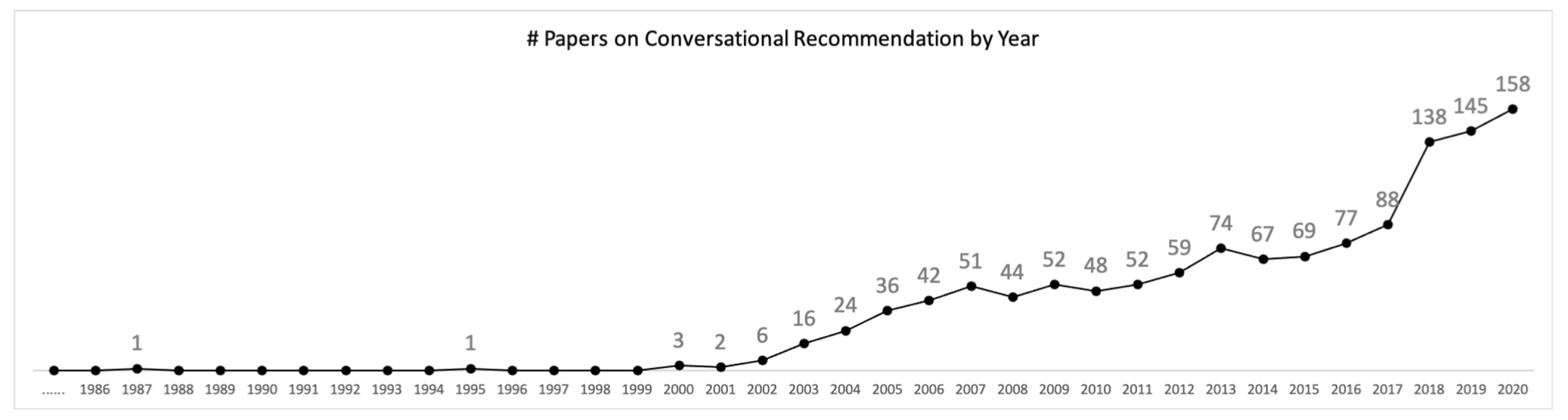
2. Problem Formalization
2-1. Basic Problem Formalization
다음은 CRS의 기본적인 구성입니다. 입력과 출력이 일반 추천시스템과 비슷한 경향은 있지만, 입력으로 마지막 n개의 발언과 출력으로 다음 발언이 포함된다는 점에서 CRS의 multi-turn 대화라는 차별점을 볼 수 있습니다.
Input
- dialogue history: last n utterances
- (optional) user preferences
- (optional) external knowledge of items
Output
- next utterance
- items recommended to user
- (optional) explanations
2-2. Different Types of Utterances in Conversations
대화에서 발언의 종류는 4가지의 패러다임으로 나뉘어집니다. 가장 위의 SAUP는 시스템이 주도권을 가지고, 밑으로 갈수록 유저가 주도권을 가지게 됩니다. 또한 SAUP에서 SAUA로 갈수록 대화가 더 자연스러워집니다. 여기서는 SAUP, SAUE, SAUA까지만 다루도록 하겠습니다.
System is Active, User is Passive (SAUP)
- 시스템이 유저에게 질문을 하며 대화를 주도
- 유저는 질문에 대답만 할 수 있음
System is Active, User Engages (SAUE)
- 시스템이 질문을 하고 유저는 그에 대답을 함
- 시스템과 유저 모두 chit-chat
- 유저는 대답만 하지 않아도 됨
System is Active, User is Active (SAUA)
- 시스템과 유저 모두 질문을 통해 대화 주도 가능
- 시스템과 유저 모두 chit-chat
User is Active, System is Passive (Voice command, QA)
- 유저가 시스템에 질문을 던지며 대화 주도
Paradigm 1: System is Active, User is Passive (SAUP)
Typical Form: System Ask User Respond (SAUR)
- 시스템이 추천되는 후보를 추리기 위하여 아이템에 대한 질문을 함
Input
- dialogue history
Output
- next utterance = question to ask user
- items recommended to user

Paradigm 2: System is Active, User Engages
Typical Form: SAUR + Chit-chat
- 시스템이 아이템에 대한 질문과 함께 유저와 chit-chat도 함
Input
- dialogue history
Output
- next utterance = question + chit-chat
- items recommended to user
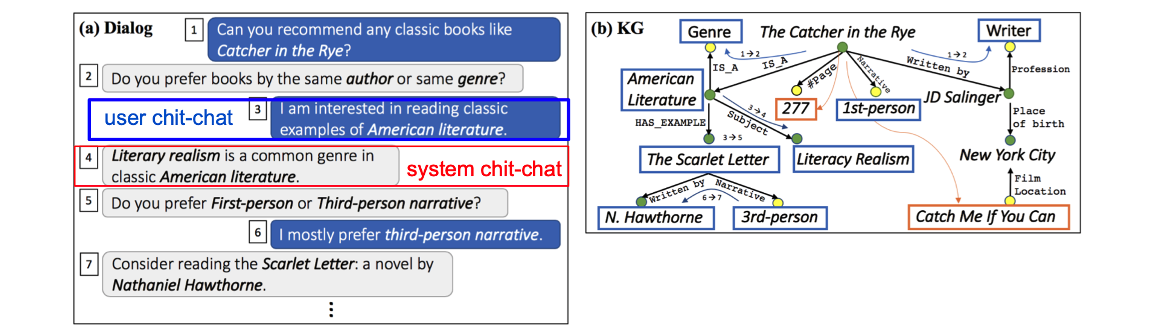
Paradigm 3: System is Active, User is Active (SAUA)
Typical Form: SAUR + Chit-chat + User Ask System Respond
- 유저가 활발하게 질문을 던지고 추천 과정에 참여함
Input
- dialogue history
Output
- next utterance = question or response to user's question
- items recommended to user
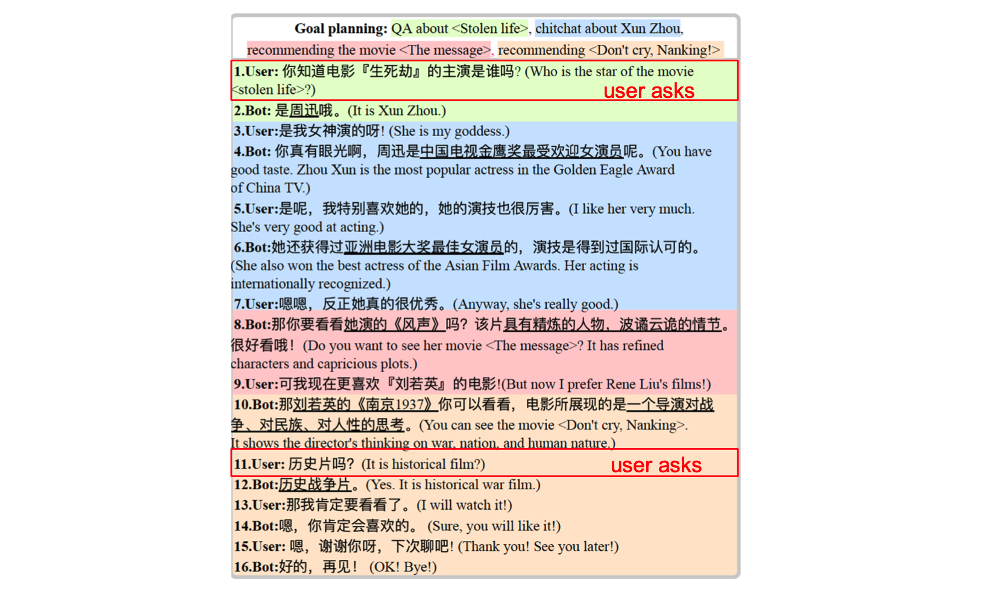
2-3. Challenges in Conversation Recommendation
CRS에서 해결해야 할 문제는 크게 5가지입니다. 특히 이 중에서 유저에게 언제 일반적 반응을 하고, 언제 추천을 할지 시점을 판단하는 것이 중요하다고 합니다.
- How to represent dialogue state?
- How to represent dialogue action, both user action and system action?
- How to understand user preference from dialogue
- When to respond or recommend?
- What to respond to user?
- Which items to recommend?
3. Datasets and Evaluation
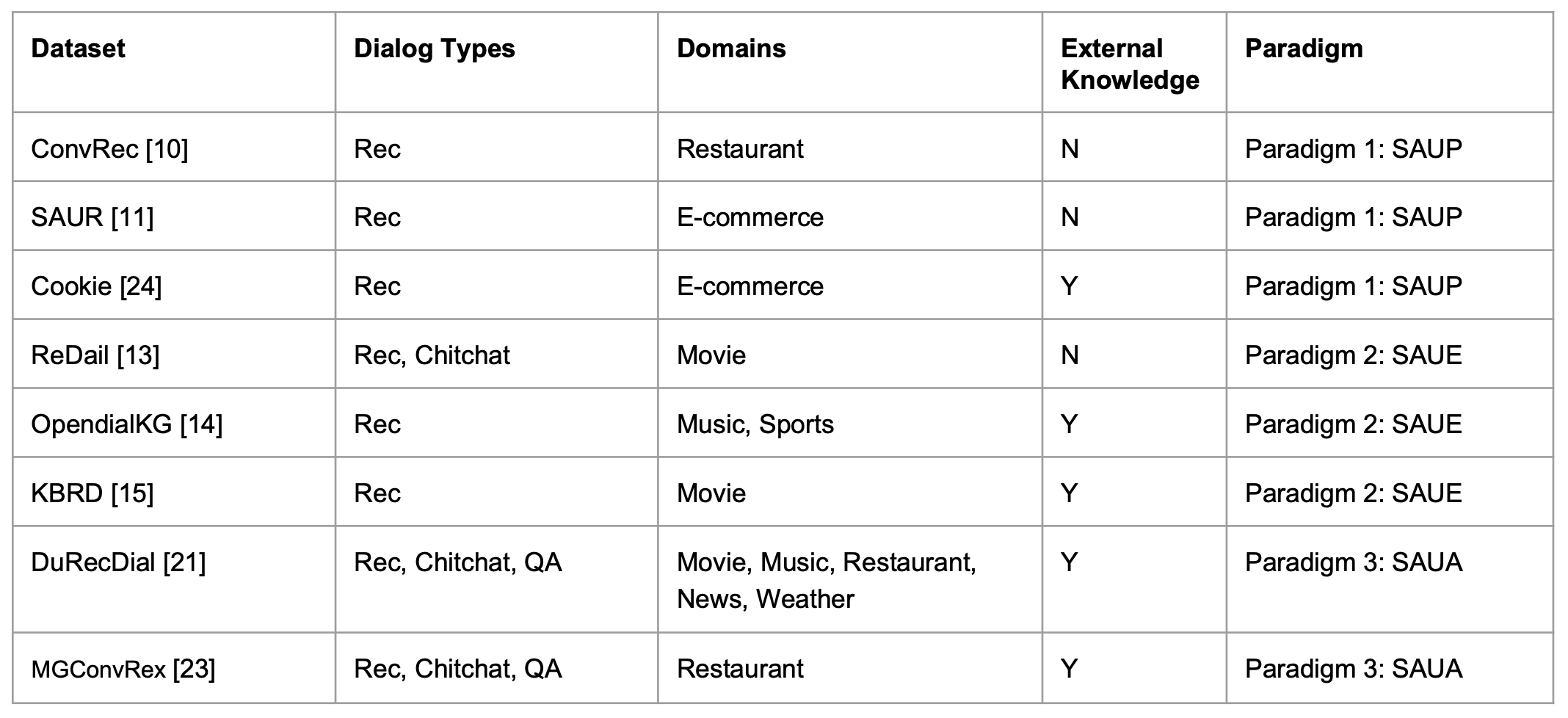
3-1. Frequently Used Datasets
앞서 언급한 3가지 패러다임에 대하여 자주 이용되는 대화형 데이터셋입니다.
3-2. Evaluation Protocol
Common Evaluation Protocol
다음은 대화형 시스템의 유용성 평가를 위한 접근 방식을 분류한 모습입니다. 왼쪽부터 보자면 Usability Expert는 말 그대로 전문가들을 초대하여 정해진 문항에 따라 평가를 하고, User Participation은 대화 전체에 대한 online evaluation으로 A/B 테스트 등을 포함합니다. 마지막으로 Expert Design Models는 대화에서의 유저 행동을 시뮬레이션하는 방식이며, Calculation은 offline metrics를 사용합니다.
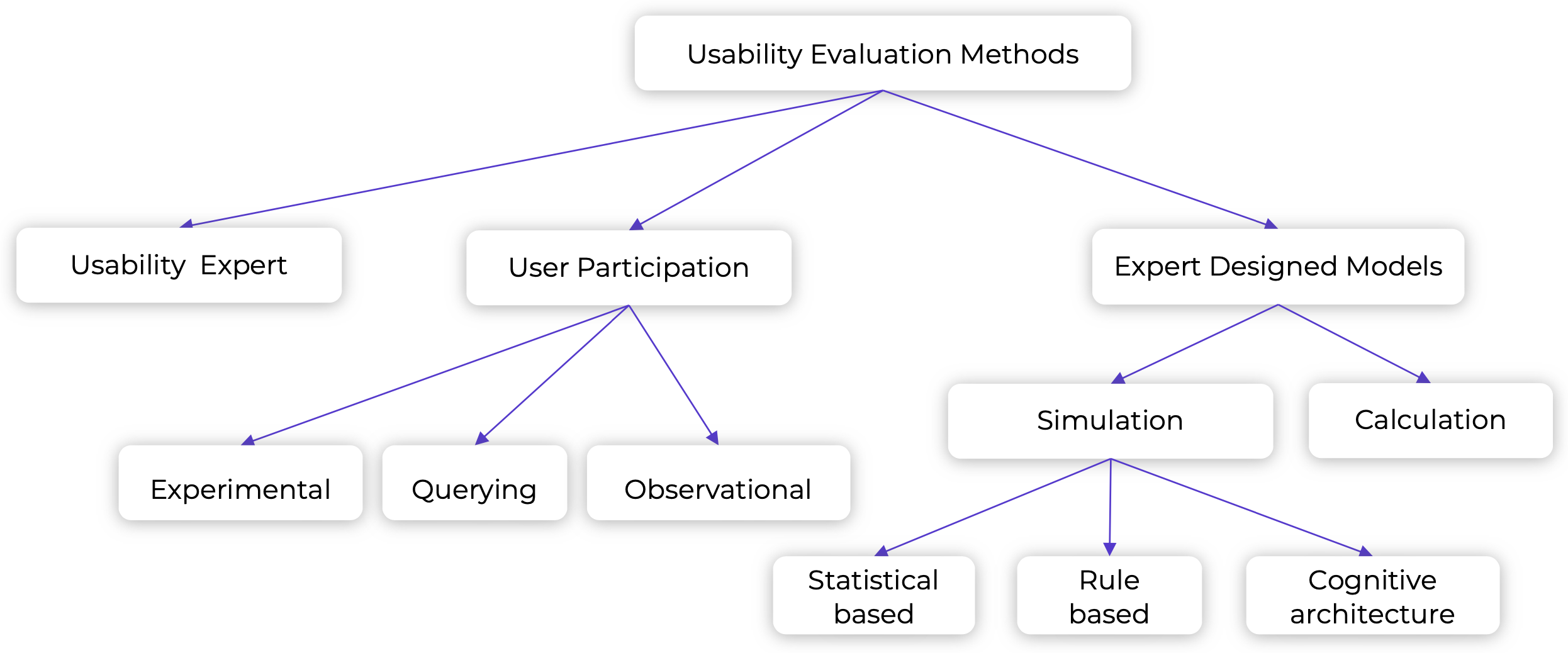
- Offline Evaluation: evaluate on benchmark datsets
- Online Evaluation: evaluate on feedback from real users of the system
- User Study: evaluate based on user's feedback on questionaires
- Simulation-based Evaluation: evaluate based on simulated environments
Evaluation Metrics
CRS의 평가 메트릭은 발언 단위의 Turn-level, 대화 단위의 Dialogue-level, 전체 시행 단위의 Business-level에서의 대화와 추천에 대한 평가로 구성됩니다. 이외에도 둘을 합친 Joint Conversational-Recommendation Evaluation이 있습니다.
- Evaluation of Conversation Quality: Turn-level, Dialog-level, Business-level
- Evaluation of Recommendation Quality: Turn-level, Dialog-level, Business-level
- Join Conversation-Recommendation Evaluation
Evaluation Metrics for Conversation Quality
먼저 대화 자체의 질에 대한 평가 메트릭을 보겠습니다.
Turn-level Metrics
- 시스템이 생성한 문장의 질 자체를 평가 (ex. BLEU, ROUGE, readability)
- 시스템이 생성한 질문 및 또는 응답의 관련성 (ex. accuracy, coverage)
- 대화 행위의 빈도 및 분포 (ex. recommend, ask question, respond)
- 유저 협력
그러나 이러한 turn-level의 척도는 대화의 각 특징만을 평가하므로 대화와 전환율의 일관성을 측정할 수 없다는 한계가 있습니다.
Dialogue-level Metrics
- 대화 길이
- 대화 성공률과 태스크 완료율
Business Metrics
- 세션당 전환율
- 매출
- 그 밖의 유저 만족도 평가, 유저의 유지, 고객 충성도 등
Evaluation Metrics for Recommendation Quality
다음은 얼마나 좋은 추천인지에 대한 평가 메트릭입니다.
Turn-level Metrics
- 각 회당 추천 정확도 (ex. precision, recall, NDCG)
- 추천 행위의 빈도 및 분포
그러나 추천도 마찬가지로 turn-level은 전체 대화의 전반적인 성능을 측정하기는 어렵습니다.
Dialogue-level Metrics
- 한 라운드에서 추천 정확도 (ex. Precision@k, Recall@k, NDCG@k)
- 대화 성공률 (ex. SuccessRate@k)
Business-level Metrics
- 대화당 전환율
- 매출
- 그 밖의 유저 만족도 평가, 유저의 유지, 고객 충성도 등

Evaluation by User Study
User study를 이용한 평가는 유저를 대상으로 usability, bot intelligence, trust, friendliness 등의 항목에 대하여 설문조사를 진행합니다.
4. Conversational Recommendation Methods
4-1. Architectures of Conversational AI Systems
이제 CRS가 어떠한 방식으로 이루어지는지 알아보겠습니다. CRS가 기반을 두는 Conversational AI 시스템은 아래의 그림처럼 크게 3가지 구조가 있습니다.
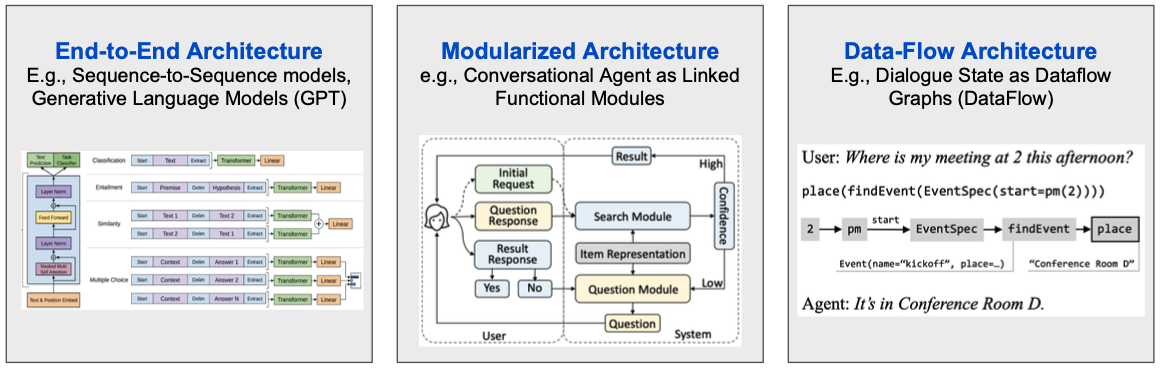
End-to-End Architecture
먼저 End-to-End Architecture의 경우 문제 해결을 위해 하나의 파이프라인을 하나의 신경망 네트워크로 해결하는 구조를 의미합니다. Sequence2Sequence나 GPT 등의 언어 생성모델을 포함합니다.
Data-Flow Architecture
다음으로 Data-Flow Architecture는 말 그대로 대화 상태를 데이터의 흐름 그래프로 나타내는 구조로, 현재는 연구가 많이 진행되어 있지 않고 미래에 많이 쓰일 수도 있다는 가능성이 있습니다.
Modularized Architecture
마지막으로 Modularized Architecture는 크기, 모양 및 기능적 특징이 유사한 별도의 반복 요소를 표준 단위로 하여 구성된 시스템의 설계 및 사용을 기반으로 합니다. 해당 구조가 실제로 많이 이용된다고 하니, 여기서는 이 Modularized Architecture에 집중해보겠습니다.
CRS를 위한 Modularized Architecture에는 크게 4가지의 모듈이 있습니다.
- Natural Language Understanding/Generation
- Dialogue State Management
- Recommendation
- Explanation
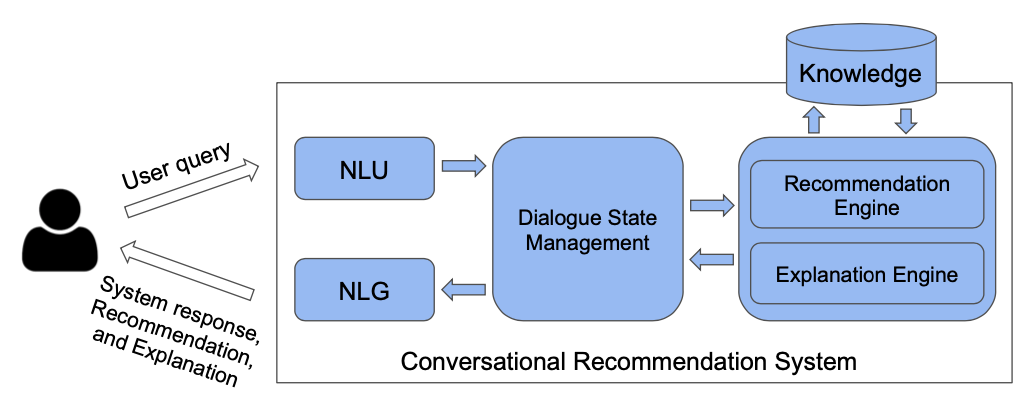
위의 그림을 보시면 CRS는 연결된 기능 모듈로서의 대화형 에이전트가 됩니다. 유저의 query를 받아 NLU를 통해 그 의미를 이해하면, Dialogue State Management에서 현재 취할 행동을 판단하여 추천을 하거나, NLG를 통해 유저와의 상호작용을 지속하여 유저의 반응을 계속 생성합니다. 필요에 따라 추천과 함께 설명을 제공하기도 합니다.
4-2. Natural Language Understanding/Generation
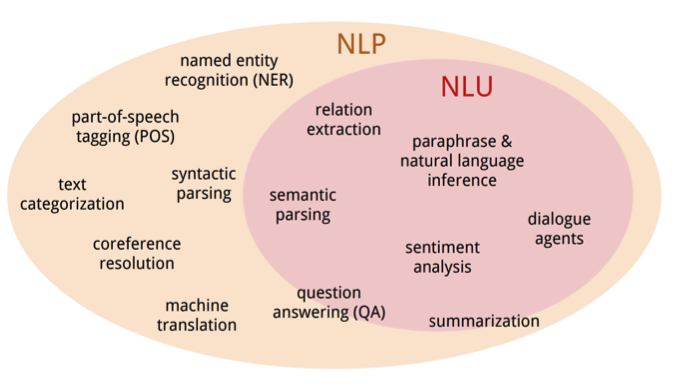
Natural Language Understanding
그럼 CRS에서 NLU, 즉 Natural Language Understanding과 Generation이 어떻게 사용되는지 살펴보도록 하겠습니다. 컴퓨터는 NLP의 첫 번째 주요 컴포넌트인 NLU를 통해 말하는 사람의 말뿐만 아니라 사용자가 실제로 의미하는 바를 추론할 수 있습니다. CRS에서의 NLU는 자유 형식 텍스트 및 모든 유형의 비정형 데이터를 해석하여 맥락을 이해하는 것이 목적입니다. 따라서 CRS에 utterance가 주어졌을 때, 수행해야 하는 태스크는 다음과 같습니다.
- Item Category Detection
- Item Attribute Extraction
- User Intent Extraction
- Slot Value Extraction
- Sentiment Analysis
Natural Language Generation
NLG는 Natural Language Generation으로 머신이 자연어를 출력으로 생성하는 프로세스로 정의할 수 있으며, 이를 어떻게 하면 보다 합리적으로 생성할지 학습시키는 영역입니다. NLG가 텍스트를 생성할 때 몇 가지 어려움이 있습니다. 우선 학습된 데이터를 기반으로 텍스트를 생성하기 때문에 background knowledge가 많아야 하며, 일관성을 유지해야 하고, 유익해야 합니다. 따라서 CRS에서 제안하는 2가지 포맷이 있습니다.
Retrieval-Based
- fluent and informative conversation turns
- less flexible
Generation-Based
- templated-based
- synthesize more flexible and tailored new sentence as reply
- insufficient semantics and informations
대화의 utterance들을 더 통제 가능하게 만들기 위해 template, knowledge, generation을 함께 사용하게 됩니다.
System Ask, User Respond (SAUR)
- Belongs to Paradigm 1 (SAUP)
- Motivation: learn about user preferences on items by asking questions
- NLU: multi-memory network → encode input utterance
- NLG: retrieval-based → select what is most relevant question to ask user

SAUR formalization
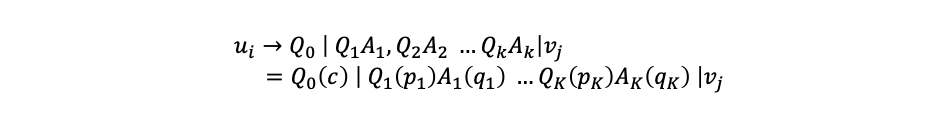
u_i: i-th user
Q_0: initial request of a conversation
Q_k: k-th agent question
A_k: k-th user answer
p_k: aspect asked in Q_k
q_k: value answered in A_k
v_j: recommended j-th itemThe Unified MMN Architecture
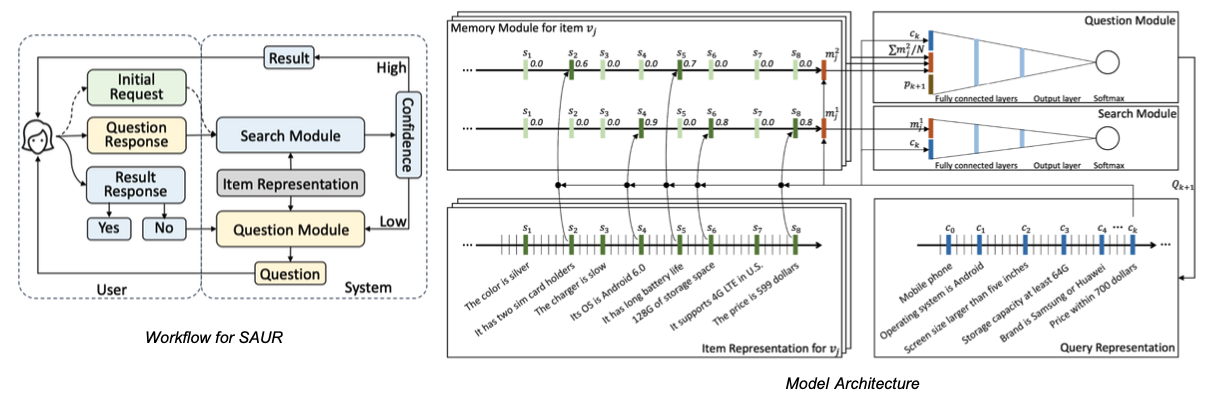
해당 그림은 논문에서 제시된 multi-memory network의 구조입니다. 보시면 Item Representation, Query Representation, Search Module, Question Module을 포함하고 있습니다. 모든 Item Representation이 Search Query와 관련이 있는 것은 아니므로 Attention 메커니즘을 통해 메모리 임베딩을 만듭니다. 이를 통해 모델은 무엇이 중요한 signal인지 알 수 있게 됩니다. 또한 Search Module과 Question Module은 negative sampling을 사용하여 다음 차례에 질문을 더 할지, 최종적으로 아이템을 추천할지 검색합니다.
Advantages of Conversational Recommendation
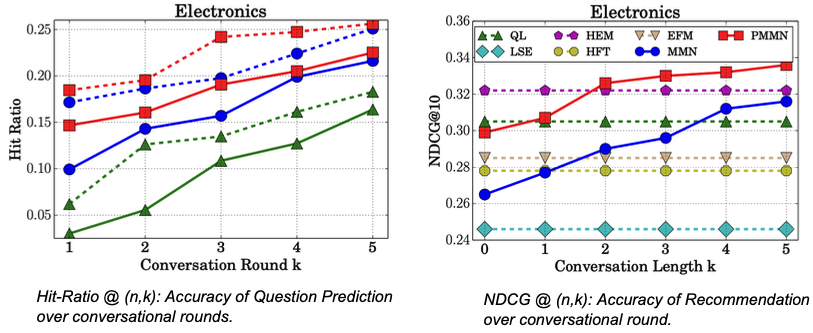
제시된 그래프는 제안된 모델의 실험 결과로, 왼쪽 그래프는 Hit-Ratio로 평가한 question prediction 태스크, 오른쪽 그래프는 NDCG로 평가한 추천 태스크의 성능 평가 결과입니다. 파란 그래프는 논문에서 제안한 MMN(Multi-memory network)고, 빨간 그래프는 이를 유저 개인화를 위해 살짝 조정한 PMMN(Personalized Multi-memory network)인데 둘 다 좋은 성능을 보여주고 있습니다. 또한 대화가 진행될수록 시스템이 유저의 선호를 더 잘 이해할 수 있다는 것을 알 수 있습니다.
Limitations
그러나 이러한 모델은 언제 질문을 하고 언제 추천을 할지에 대하여 confidence score threshold에 기반한 단순한 방법으로 판단하였고, 유저의 구매 이력이나 클릭 이력 등은 반영되지 않는다는 한계가 있습니다.
Question-based Recommendation (Qrec)
- Belongs to Paradigm 1 (SAUP)
- Motivation: enhance conversation model based on user interactions
- NLU: user response is highly structured, can be easily converted into a vector
- NLG: generate question by slot-filling
Framework of Qrec
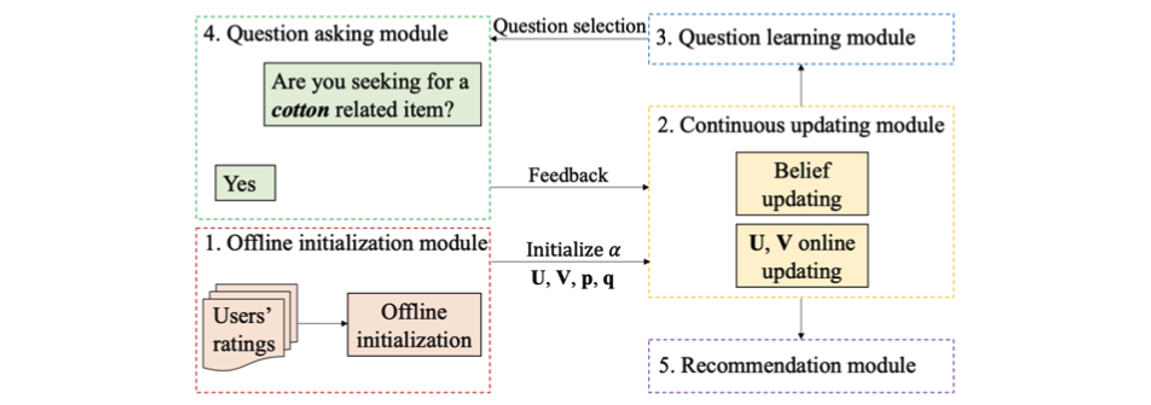
Qrec의 구조를 살펴보면 총 5개의 모듈로 구성되어 있습니다. 가장 먼저 Offline initialization module에서 모델은 유저의 과거 평점 데이터를 이용하여 파라미터를 초기화 후 matrix factorization 알고리즘으로 오프라인 학습을 합니다. 다음으로 Continuous updating module은 유저의 답변을 기반으로 하는 closed-form solution를 이용하여 유저와 아이템의 latent factor를 온라인 학습합니다. 그 후, Question learning module은 question pool에서 다음으로 던질 질문 중 가장 적절한 것을 고르는 것을 학습하면 이에 따라 Question asking module에서 대답이 yes/no로 나오는 질문을 유저에게 하게 됩니다. 온라인으로 질문하는 단계가 끝나면 추천 리스트가 생성됩니다.
Evaluation
이는 유저의 과거 평점 데이터를 통해 과거 선호 사항을 반영하며, 리뷰에 있는 아이템의 특성과 메타데이터에 있는 아이템의 특성에 대하여 모두 질문을 하여 아이템에 관한 정보를 포함할 수 있게 되어 더 좋은 성능을 보인다고 합니다.
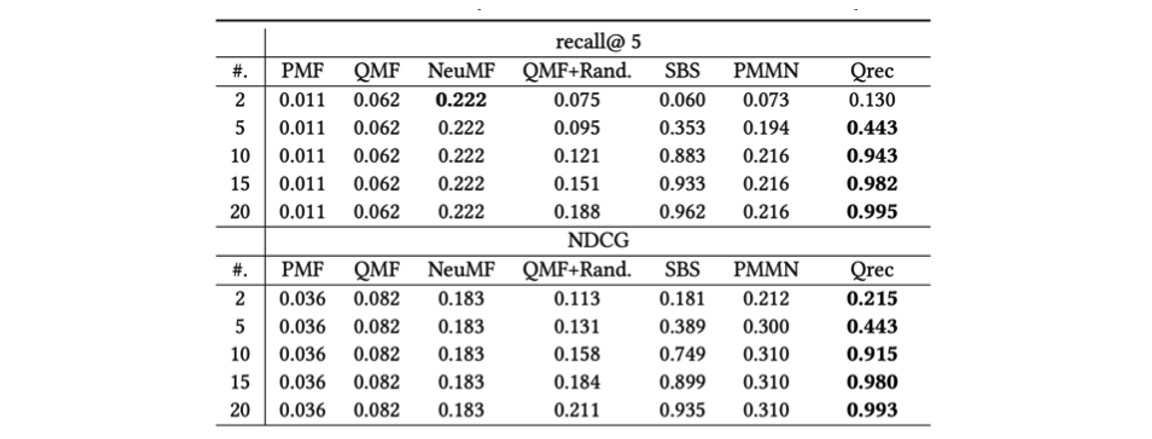
이는 아마존의 상품 추천 관련 데이터 셋을 다루는 실험 결과인데, 앞서 본 PMMN보다 더 결과가 좋았고, 역시 대화를 더 여러 번 할수록 좋은 성능을 나타냈습니다.
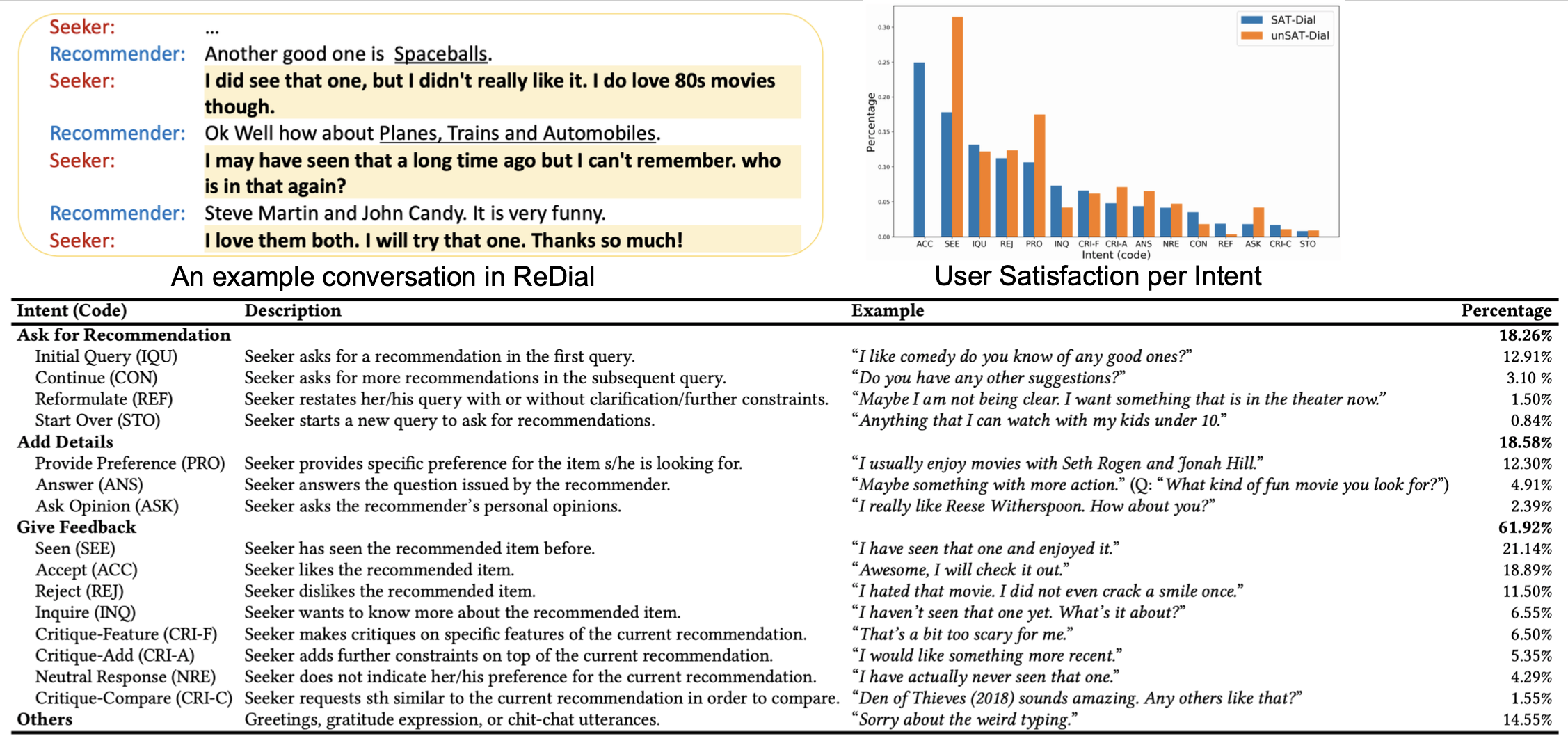
Recommendation through Dialog (ReDial)
- Belongs to Paradigm 2 (SAUE)
- ReDial Dataset
- NLU: hierarchical recurrent encoder-decoder (HRED)
- NLG: switching decoder
- Limitations
- baseline does not consider user historical behaviors
- simple dialog management strategy - realized simple softmax function
ReDial Dataset

Proposed method for ReDial Dataset
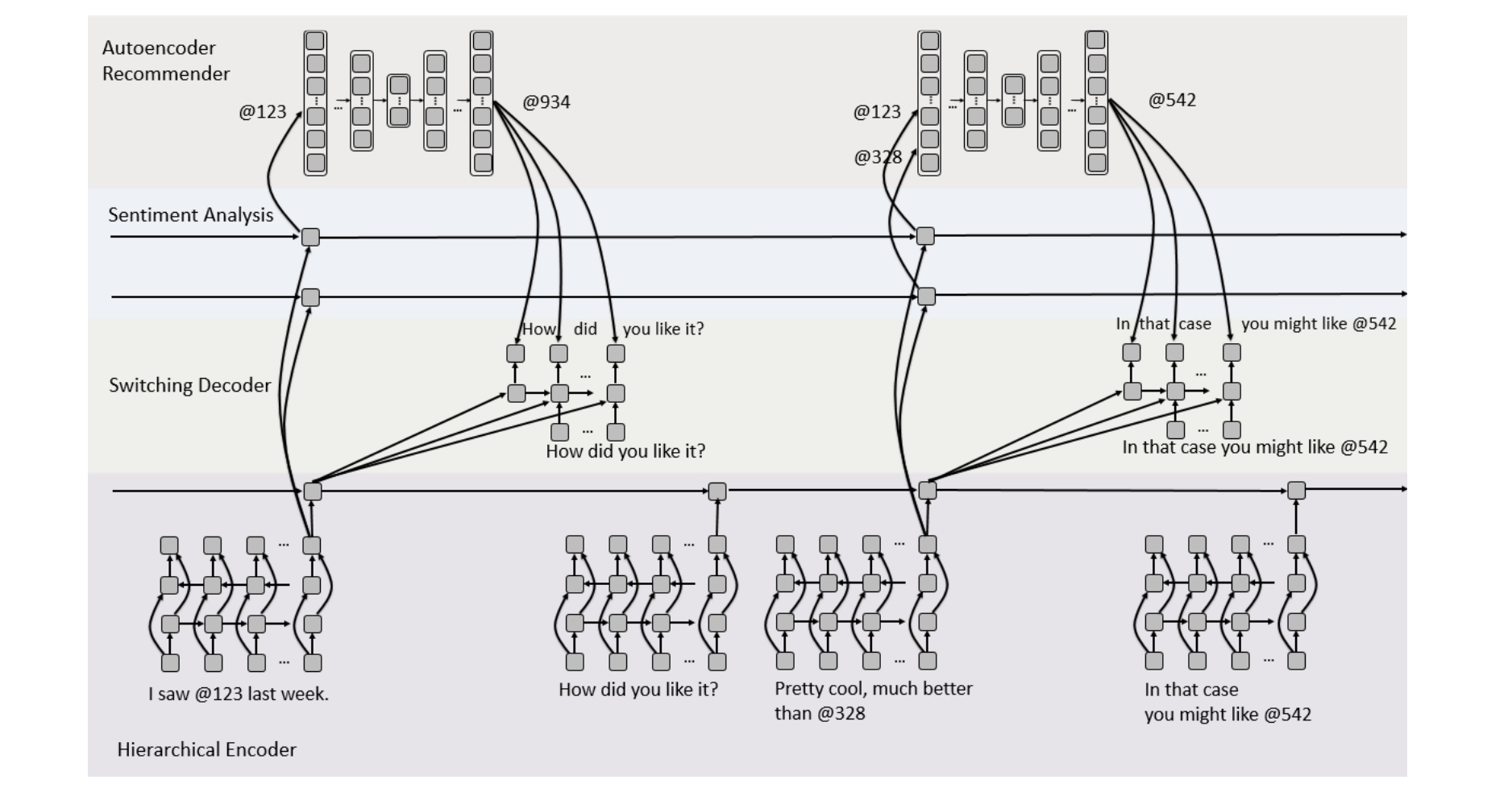
제안된 모델은 유저와 대화를 하며 영화 취향을 물어보고 그에 적절한 영화를 추천하고자 했습니다. 위의 그림처럼 총 4개의 단계로 구성되어 있습니다.
- hierarchical encoder following the HRED architecture (Gensen)
- switching decoder
- sentiment analysis
- autoencoder recommender
Limitations
그러나 베이스라인이 유저의 과거 행동을 고려하지 않고, dialogue management가 단순한 softmax라는 한계를 가지고 있습니다.
Multi-Goal driven Conversation Generation (MGCG)
- Belongs to Paradigm 3 (SAUA)
- Motivation: learn strategies to repurpose the conversation to recommendation when the conversation topic drifts
- NLU
- context-response representation module (C-R Encoder)
- knowledge representation module (Knowledge Encoder)
- NLG: mixture of retrieval-based and generation-based methods
Goal Planning Module
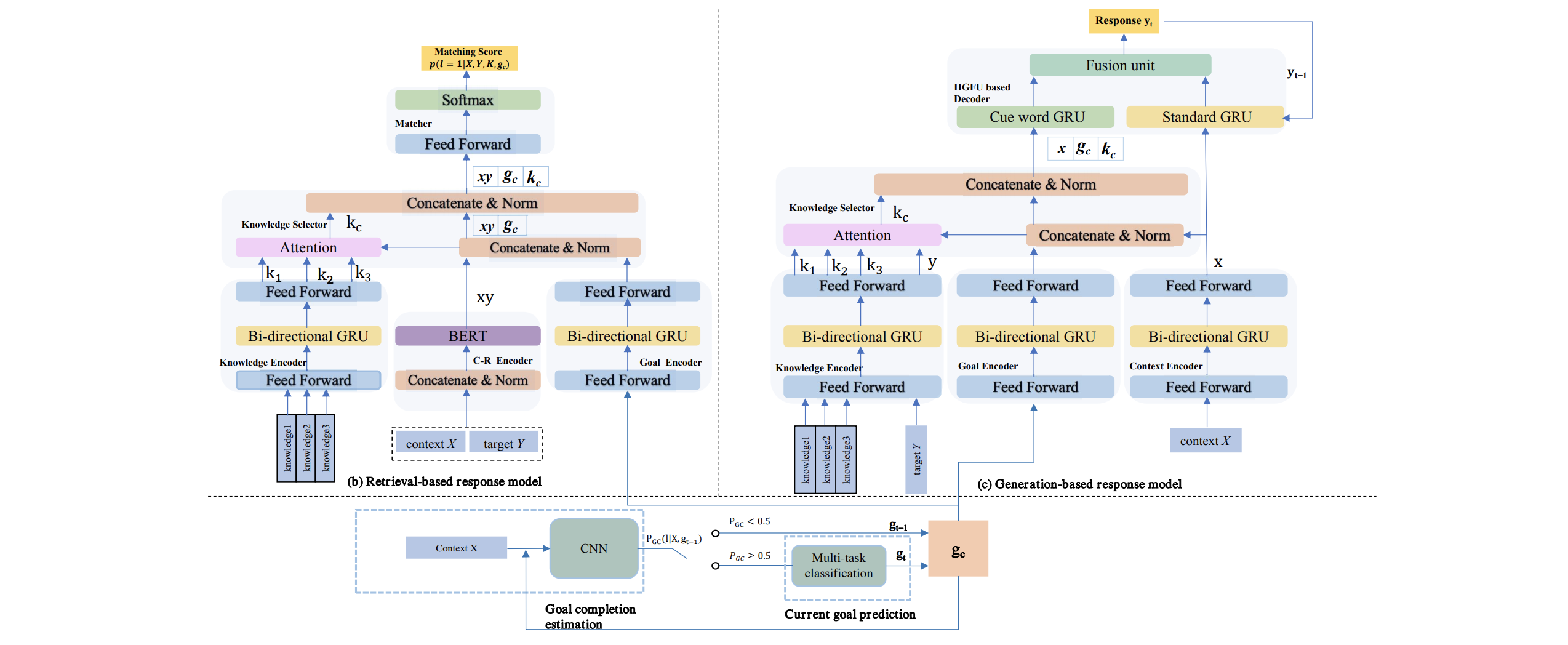
해당 연구에서는 agent의 응답을 생성하기 위해 goal planning module을 사용합니다. 이 goal planning module은 retrieval-based와 generation-based의 포맷을 함께 이용하는데, 각각의 포맷에서 제공하는 threshold를 기준으로 현재 대화의 목표가 명확한지 판단합니다. 만약 임계치를 넘기지 못한다면 generation-based 포맷이 실행되어 아이템의 특성을 다루는 질문을 계속 하게 되고, 넘긴다면 유저의 취향을 명확하게 하게 되는 질문을 합니다.
4-3. Dialogue State Management
Dialogue State Management는 대화의 상태를 계속 추적하여 다음에 어떠한 행동을 취할지, 예를 들어 질문을 할지 추천을 할지 결정하는 것을 돕습니다. 예를 들어 밑의 그림처럼 호텔을 예약하거나 식당을 예약할 때, 대화가 한 차례씩 진행될 때마다 대화의 상태가 기록이 됩니다. 특히 CRS의 경우에는 질문을 할지 추천을 할지 결정하는 것에 더 집중합니다.

Conversational Recommendation Model (CRM)
- Belongs to Paradigm 1 (SAUP)
- Motivation: learn a model to decide when to recommendation and when to ask
- NLU
- deep belief track to analyze user's current utterance
- extract the facet values of the target item
- DSM: RL-based policy network for dialogue state management
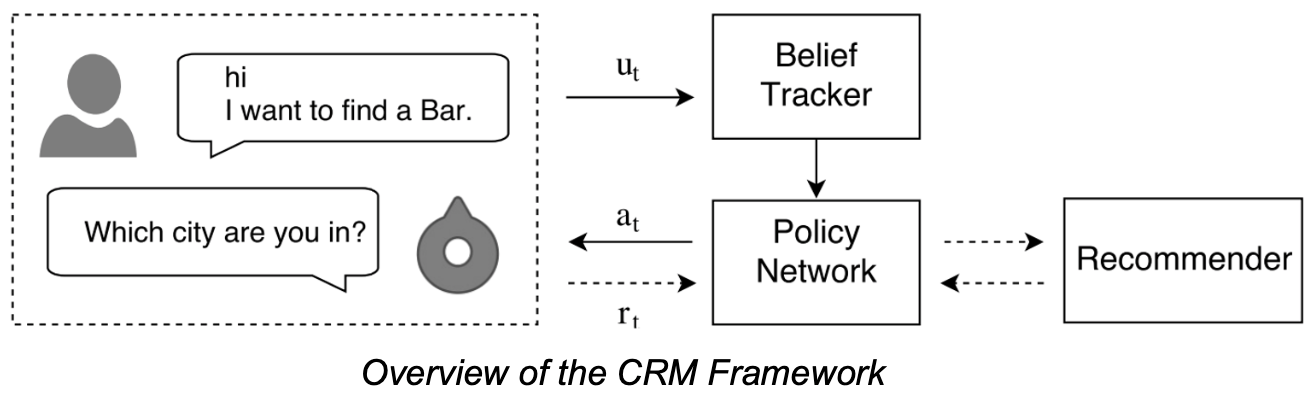
Belief Tracker
Belief tracker는 맥락을 기반으로 유저의 현재 발화를 분석하고, 유저 발화에서 타겟 아이템의 facet value를 추출하기 위해 학습됩니다. Belief tracker의 출력은 현재 유저의 의도를 업데이트하는 데에 사용되며, 대상에 대한 facet-value 쌍의 집합으로 표현됩니다.
Policy Network
Policy network는 현재 유저 쿼리와 장기 유저 선호도를 고려하여 각 차례에서 수행할 행동을 결정하기 위해 학습됩니다. 이를 통하여 전체 대화 세션에서의 보상을 극대화하기 위해 유저의 요구를 식별하기 충분할 때 유저에게 개인화 된 항목 목록을 추천하고, 그렇지 않을 경우 추가 정보를 요청합니다.
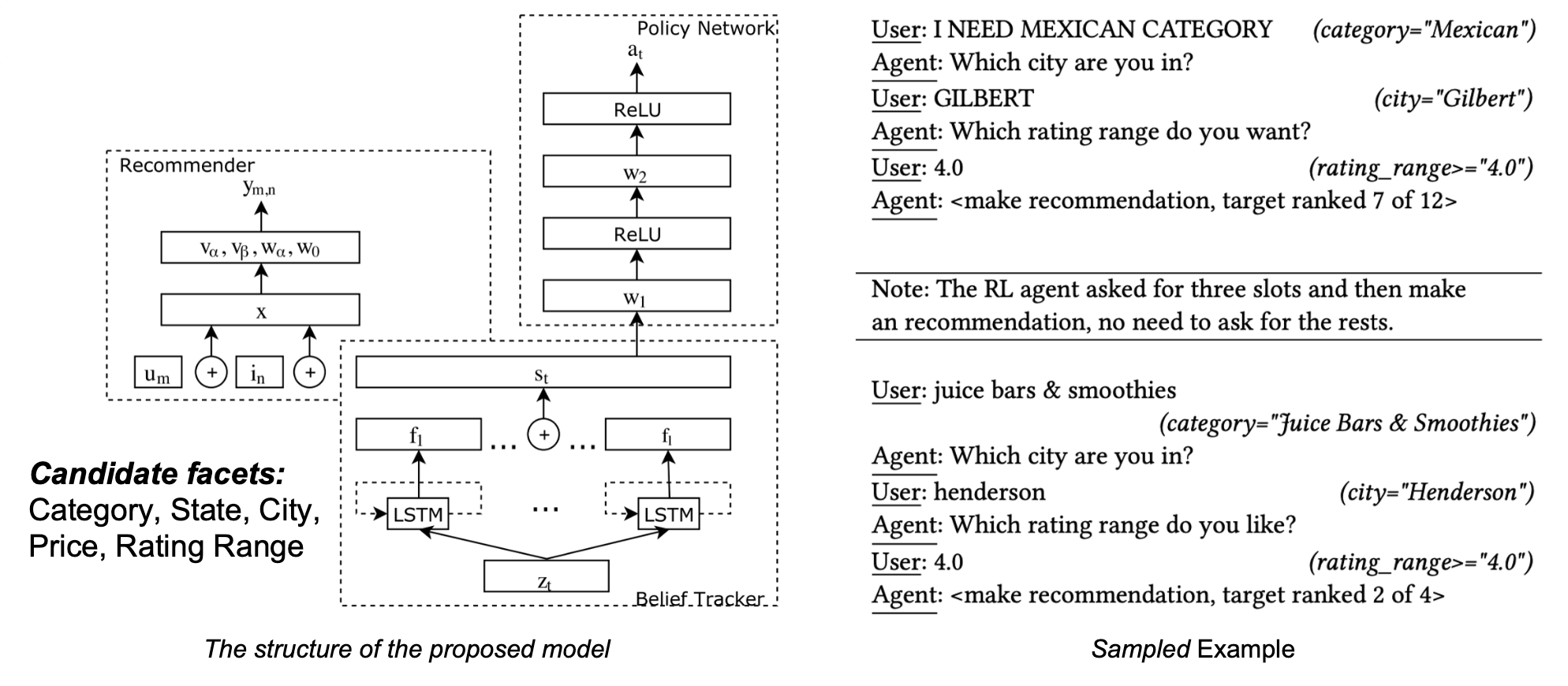
Limitations
CRM은 몇 가지 한계가 있습니다. 먼저 후보 facet을 5개까지만 지원하기 때문에 아이템 특징의 크기가 큰 경우 확장성이 떨어집니다. 또한 유저가 추천에 대하여 부정적인 피드백을 한 경우 반영이 어렵습니다. 5개의 후보에 대하여 모두 질문했음에도 불구하고 유저가 만족하지 못한 경우에도 추천을 무조건 한 번은 해야하기 때문입니다.
Estimation–Action–Reflection (EAR)
- Belongs to Paradigm 1 (SAUP)
- Motivation
- What Attributes to ask?
- When to recommend items?
- How to adapt to user's online feedback?
- DSM: a policy network that integrates conversational component and recommender component
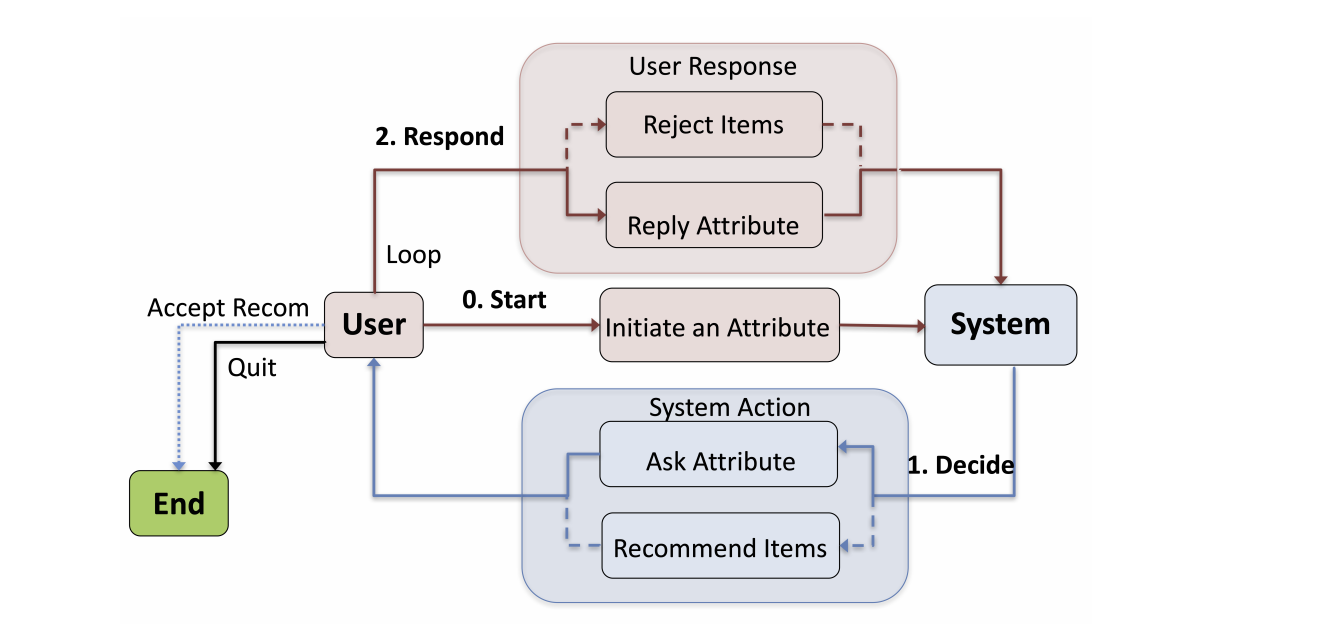
EAR은 각 발화 차례마다 어떤 특성에 대하여 물어볼지, 언제 아이템을 추천할지, 유저의 피드백을 어떻게 반영할지 다루게 됩니다. EAR은 총 3단계로 구성되어 있습니다. 가장 먼저 estimation 단계에서는 예측 모델을 통해 유저가 선호하는 아이템과 그 특징들을 추정합니다. 다음으로 action 단계에서 dialogue policy를 학습하여, 추정 단계와 대화 기록에 따라 특징에 대하여 더 묻거나 항목을 추천합니다. 마지막 reflection 단계에서는 유저가 추천을 거부할 경우 추천 모델을 업데이트합니다.
Limitations
그러나 이 또한 유저가 자신의 선호도를 명확하게 드러낸다는 가정 하에 이루어지고, 역시 부정적인 피드백은 배제합니다.
4-4. Recommendation
Key Differences from Traditional Recommendation Models
- how to make use of the information encoded in the dialogue?
- how to model the user prefernce dynamically during the dialogue?
Make Use of the Information encoded in the Dialogue
- extract structured information from dialogue
- encode dialogue into continous embeddings
Model the User Preference dynamically during the Dialogue
- update user profile based on the structured information from dialogue
- update user embedding based user profiles and/or continuous dialogue embeddings
Many Recommendation Models can be used based on above Information
- content-based, collaborative filtering, matrix factorization, neural networks, knowledge graph reasoning, graph nerual networks, ...
4-5. Explanation
마지막으로 Explanation 부분입니다. Explanation은 유저가 왜 특정 아이템들이 추천되었는지 알고 있다면 더 나은 질문을 통해 더 나은 대화를 주도할 수 있기 때문에 중요하다고 합니다.
Explainable Conversational Recommendation (ECR)
- Belongs to Paradigm 2 (SAUE)
- Motivation
- provide explanations to help users understand the recommendation and dialogue
- collect user feedback from explanations to understand user needs
- NLU: context-aware concept embedding
- NLG: template-based and GRU
- each round, provide generations from a template based format
- Explanation: constrained explanation generation via bidirectional GRU
- provide human readable explanations by a constrained generation through bidirectional GRU

Incremental multi-task learning framework
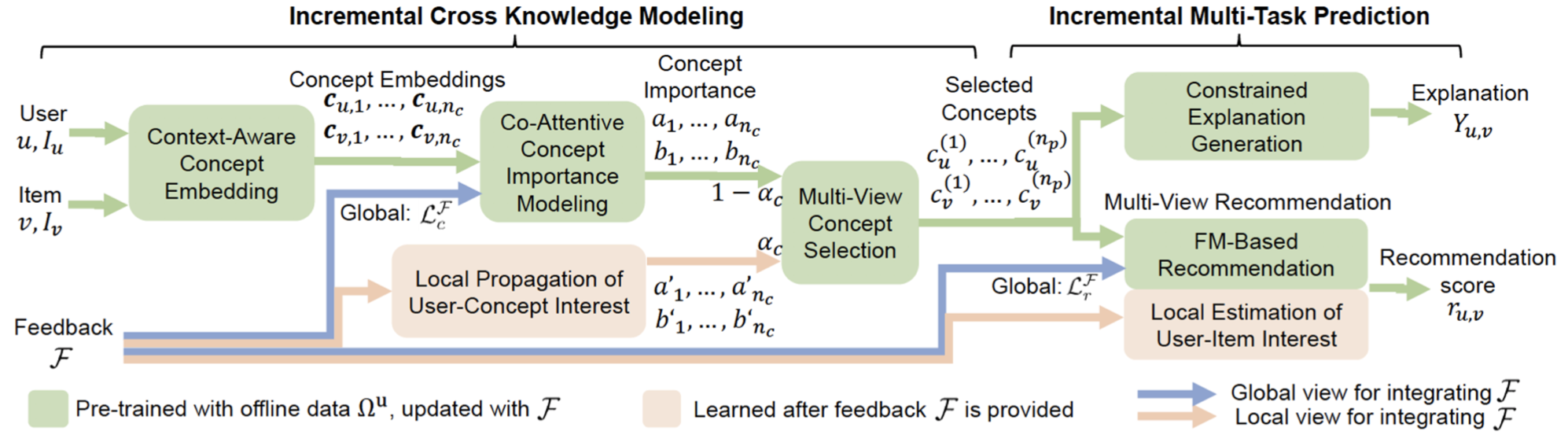
Limitation
그러나 매번 추천을 하기 때문에 DSM이 없으며, 유저가 중립적인 태도는 취하지 않을 것이라 가정하기 때문에 반드시 명백한 피드백을 제공해야만 합니다.
5. Toolkits and Real-world Systems
open source dialogue systems + open source recommender systems
- evison/Conversational
- Dialogue Systems: CMU Olympus, Deeppavlov, Uber Plato, Cisco Mindmeld, Rasa, ...
commercial conversational AI tool kits for developers
- Microsoft Bot framework, Google Dialogflow, Amazon Lex, IBM Watson, ...
- Apple iMessage for business, Facebook messenger bot, ...
commercial all-in-one conversational AI platforms

References
https://www.youtube.com/watch?v=RdGnJSRA0aw&t=1492s
Jannach, Dietmar et al, A Survey on Conversational Recommender Systems, ACM, 2021.
Zou, Jie et al, Towards Conversational Search and Recommendation: System Ask, User Respond, SIGIR, 2020.
Zhang, Yongfeng et al, Towards Conversational Search and Recommendation: System Ask, User Respond, ACM, 2018.
Li, Raymond et al, Towards Deep Conversational Recommendations, NeurIPS, 2018.
Liu, Zeming et al, Towards Conversational Recommendation over Multi-Type Dialogs, ACL, 2020.
Zhang, Jian-Guo et al, Find or Classify? Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking, SEM, 2020.
Lei, Wenqaing et al, Estimation-Action-Reflection: Towards Deep Interaction Between Conversational and Recommender Systems, International Conference on Web Search and Data Mining, 2020.
Chen, Zhongxia et al, Towards Explainable Conversational Recommendation, IJCAI, 2020.

3개의 댓글

CRS(Conversational Recommendation system)에 대해 알아보았다. 고객과 대화를 하며 상품을 추천하는 상호작용이 강조된 추천시스템이다. 여러 산업군에서 서비스되고있는 챗봇서비스를 생각하면 될 것 같다.
CRS의 인풋은 고객의 발화내용 아웃풋은 그 다음 대답할 발화내용이 될 것이다.
CRS의 유형은 유저의 자유도에 따라 구분된다.
- System is Active, User is Passive (SAUP)
시스템이 주도적으로 질문을 던지고, 유저는 답변만 하는 시스템 - System is Active, User Engages (SAUE)
시스템의 주도적인 질문에 유저는 답변 + 유저의 간단한 질문 가능 - System is Active, User is Active (SAUA)
시스템과 유저 모두 주도적으로 질문 가능 - User is Active, System is Passive (Voice command, QA)
유저가 시스템에 질문을 던지면 시스템은 답변(ex. 애플의 시리)
CRS 모델구조의 종류는 End-to-End Architecture, Data-Flow Architecture, Modularized Architecture 등이 있는데, Modularized Architecture가 가장 많이 쓰인다.
해당 구조는 Natural Language Understanding/Generation, Dialogue State Management, Recommendation, Explanation 으로 구성된다.
유저의 발화의 의미를 이해하는 NLU부분, 현재 취할 행동을 판단하는 Dialogue State Management, 이를 받아 적절한 발화를 생성하는 NLG등으로 이루어져있다.
NLP분야에서 챗봇을 만드는 일이 매우 어렵다고 알고 있는데 이와 비슷한 태스크인 CRS도 매우 자연스러운 구현이 어려울 것으로 예상된다. 그만큼 발전이 주목되는 분야라고 생각된다.

[Survey] Conversational Recommender System
15기 류채은
- task-oriented의 지원과 유저와의 multi-turn dialogue를 사용
- natural language dialogue로 접근하여 개인화된 추천을 제공
- task-orientation으로 추천에 관련된 구체적 태스크와 목적을 지원
- multi-turn conversational interaction: 대화 내역과 현재 상태를 계속 추적
< Different Types of Utterances in Conversations>
System is Active, User is Passive (SAUP)
• 시스템이 추천되는 후보를 추리기 위하여 아이템에 대한 질문을 함
System is Active, User Engages (SAUE)
• 시스템이 아이템에 대한 질문과 함께 유저와 chit-chat도 함
System is Active, User is Active (SAUA)
• 유저가 활발하게 질문을 던지고 추천 과정에 참여함
User is Active, System is Passive (Voice command, QA)
<Natural Language Understanding/Generation>
System Ask, User Respond (SAUR)
Question-based Recommendation (Qrec)
Recommendation through Dialog (ReDial)
Multi-Goal driven Conversation Generation (MGCG)
[15기 이성범]
본 논문은 Conversational Recommendation System의 Survey 논문이다. Conversational Recommendation System은 유저와의 대화를 통해서 유저의 선호도를 알아내고 그 데이터를 바탕으로 유저에게 아이템을 추천해주는 System이다. 챗봇과 비슷한 형식으로 유저의 선호도를 알 수 있는 질문을 하고 그 질문에 대한 대답을 바탕으로 유저의 선호도를 파악한 후 추천을 해주는 방식이 바로 CRS이다. 아직 내가 알고 있는 추천시스템 서비스 중에서는 CRS를 활용하는 추천시스템은 없는 걸로 생각된다. 하지만 만약에 CRS가 발전한다면 정말 무궁무진한 Task에서 활용될 수 았다고 생각한다. CRS 가 어떻게 보면 NLP와 추천시스템의 결합이기 때문에 CRS가 발전한다면 전화 상담, 챗봇 등 대화가 가능한 모든 Task에서 활용되어 새로운 고객 경험을 제공해줄 수 있을 것이다.
CRS는 크게 SAUP, SAUE, SAUA, UASP 방식으로 나뉘어진다. SAUP는 시스템이 유저에게 질문을 하며 대화를 주도하는 방식으로 유저는 질문에 대한 대답만 할 수 있다. SAUE는 시스템이 질문하고 유저는 그에 대답을 하지만 유저는 꼭 대답만 하지 않아도 되는 방식이다. SAUA는 시스템과 유저 모두 질문을 통해 대화를 주도할 수 있는 방식이다. UASP는 유저가 시스템에 질문을 던지며 대화를 주도하는 방식이다.
CRS는 유저에게 언제 일반적인 반응을 하고, 언제 추천을 할지 이 시점을 판단하는 것이 매우 중요하기 때문에 CRS의 평가는 대부분 대화에 대한 품질과 대화의 성공률, 추천 정확도를 가지고 이루어진다.
SAUP에 해당하는 모델은 System Ask, User Respond와 Question-based Recommendation, Conversational Recommendation Model, Estimation-Action-Reflection 등이 존재한다. SAUE에 해당하는 모델은 Recommendation through Dialog, Explainable Conversational Recommendation 등이 존재한다. SAUA에 해당하는 모델은 Multi-Goal driven Conversation Generation 등이 존재한다.