[Paper Review] (2019, ACM) BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representation from Transformer
Recommender_System

작성자: 박지은
1 | Introduction

추천시스템에서 쓰이는 NLP 모델 중 Transformer 등의 기존의 Unidirectional Model은 시퀀스를 왼쪽에서 오른쪽의 순서로 읽어가며 빈 칸을 예측합니다. 그러나 추천시스템의 경우에는 자연어와 달리 natural order가 존재하지 않고, 품사 등의 제한이 없습니다. 또한 관측할 수 없는 다양한 외부 요인 때문에 사용자의 행동 순서에서 숨겨진 representation이 제한됩니다. 예를 들어 위의 그림을 보면, '오늘은'으로는 뒤의 '하늘에'를 예측하기가 굉장히 어렵습니다. 그러나 만약 양방향으로 '하늘에'와 '많네요'를 둘 다 참조한다면 더 예측하기가 수월해지기 때문에, 논문의 저자들은 Deep한 양방향 Self-Attention 모델로서의 BERT를 추천시스템에 제안했습니다.
BERT
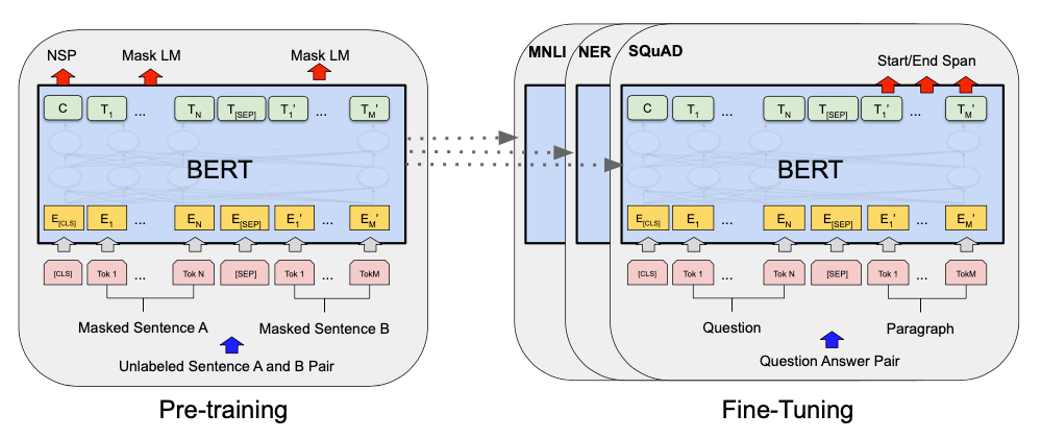
우선 BERT의 모델에 대해서 간단하게만 살펴보겠습니다. BERT는 Bidirectional Encoder Representation from Transformers를 줄인 이름으로, 문맥을 양방향으로 이해해서 숫자의 형태로 바꾸어주는 딥러닝 모델입니다. Transformer를 기반으로 문장 전체를 모델에 알려주고 [MASK]에 해당하는 단어를 예측하게 되는데, 크게 Pre-training 부분과 Fine-tuning 부분으로 나뉘어져 있습니다. 먼저 대용량으로 unlabeled 데이터로 모델을 pre-training 한 후, fine-tuning을 통해 특정 태스크를 가지고 있는 labeled 데이터로 전이학습을 하여 다양한 자연어처리 태스크를 수행합니다.
1) Input Representation
그럼 BERT에 input이 어떻게 입력되어 처리되는지 순서대로 보도록 하겠습니다. 먼저 Input Representation에서는 3가지 임베딩이 쓰이게 됩니다.
WordPiece Embedding
첫 번째는 Word Embedding으로, 문장을 토큰 단위로 분리하게 됩니다. 만약 'playing'이라는 단어가 있다면, 이를 'play'와 '##ing'으로 분리하여 두 가지 의미를 명확하게 전달합니다. 덕분에 신조어나 오탈자 등의 흔치않은 단어가 있는 input도 학습할 수 있습니다. 추가적으로 2개의 스페셜 토큰이 쓰입니다.
- [CLS] : Classification Label Token, 문장의 맨 처음에 등장하여 모든 벡터를 참고한 뒤에 context vector로 쓰임
- [SEP] : 두 문장을 구분하는 토큰
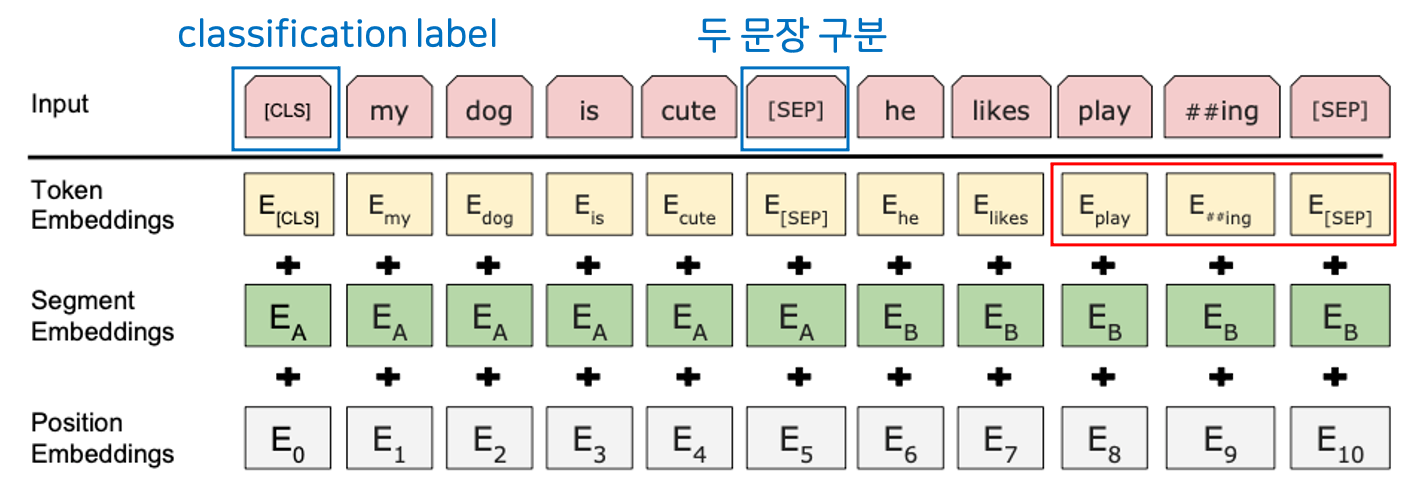
Segment Embedding
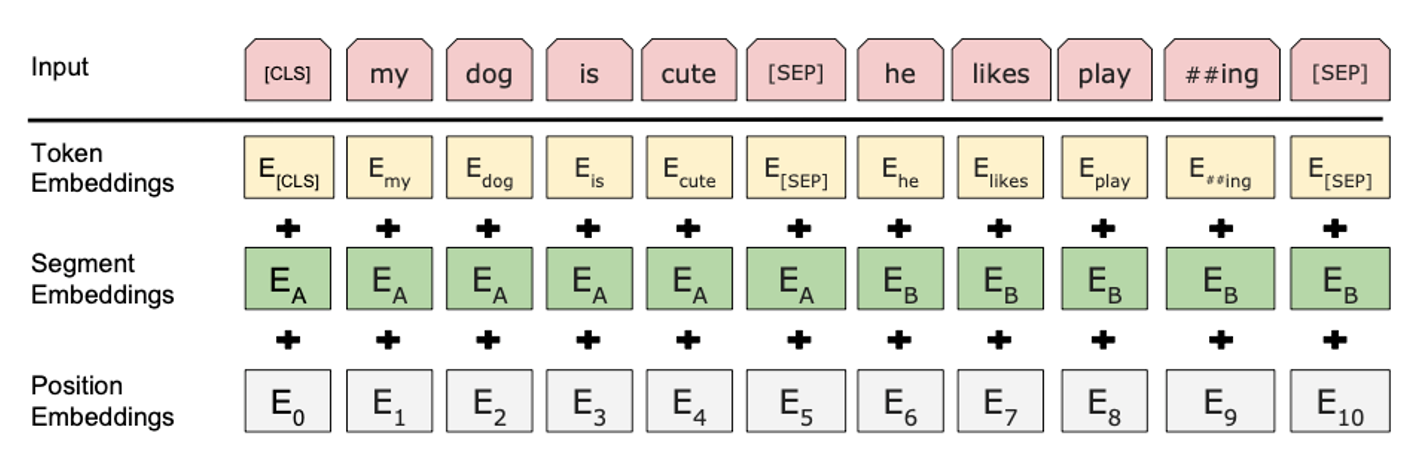
Segment Embedding에서는 두 개의 다른 문장을 구분합니다. 이는 두 개의 문장이 입력될 때 각각의 문장에 서로 다른 숫자를 더하여, 모델로 하여금 두 개의 서로 다른 문장이 있다는 것을 쉽게 알려줍니다.
Positional Embedding
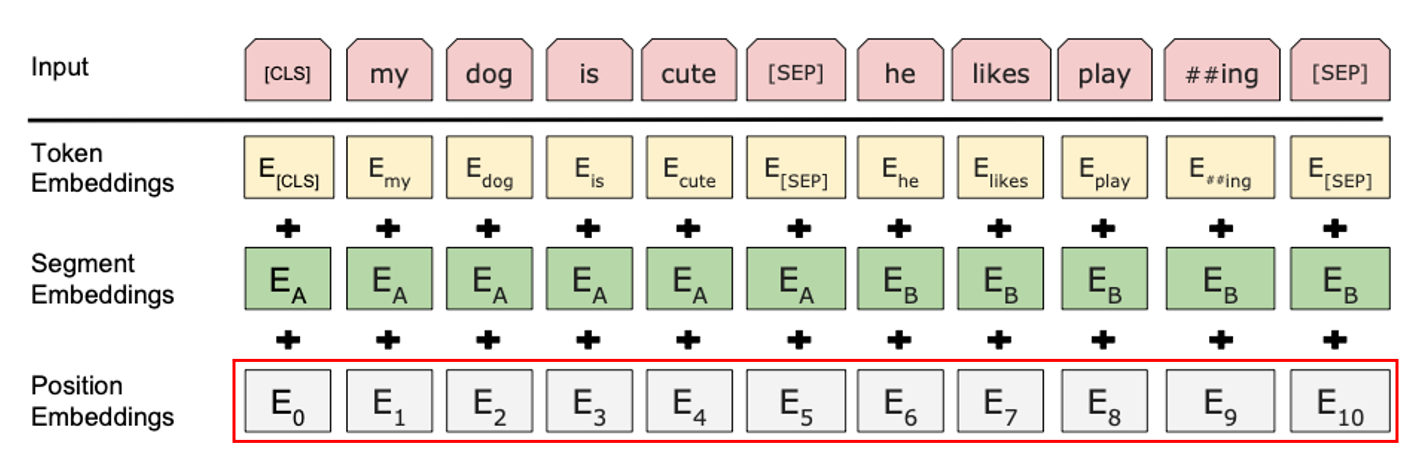
마지막으로 Positional Embedding은 sin, cos 함수를 이용하여 토큰들의 상대적 위치 정보를 알려줍니다. Transformer를 기반으로 하는 모델이기에, 따로 토큰들에 위치 정보가 포함되어있지 않기 때문에 이렇게 상대적 위치를 더 쉽게 계산 가능하게 합니다.
2) Pre-training
Masked Language Model
이제 input이 준비되었으니 Pre-training 모델에 들어가게 됩니다. Pre-training은 크게 두 가지 기능을 하게 됩니다. 첫 번째는 Masked Language Model을 통하여 단어 중 일부를 [MASK] 토큰으로 바꾸고, 이를 예측하는 태스크를 수행하는 것입니다. 이를 통해 모델이 문맥을 파악하는 능력을 기를 수 있습니다.
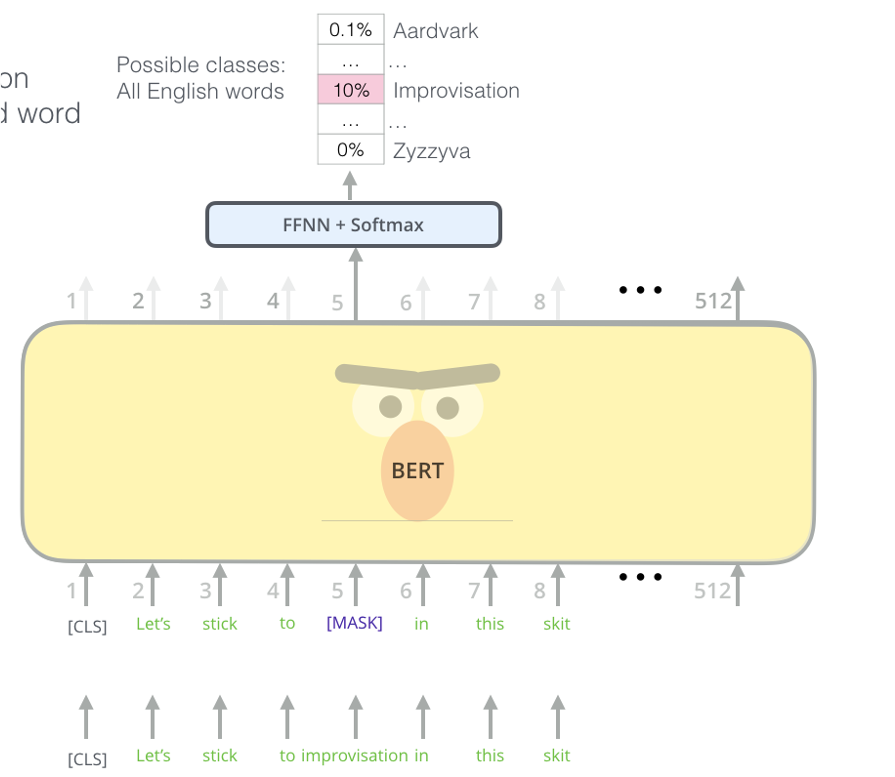
Next Sentence Prediction
다음은 앞의 문장과 뒤의 문장이 이어지는지 판별하는 Next Sentence Prediction입니다. 이는 binary classification으로 [CLS] 토큰의 final hidden state에서 판별하는데, 이를 통해 모델이 두 문장 사이의 관계를 이해하도록 합니다.
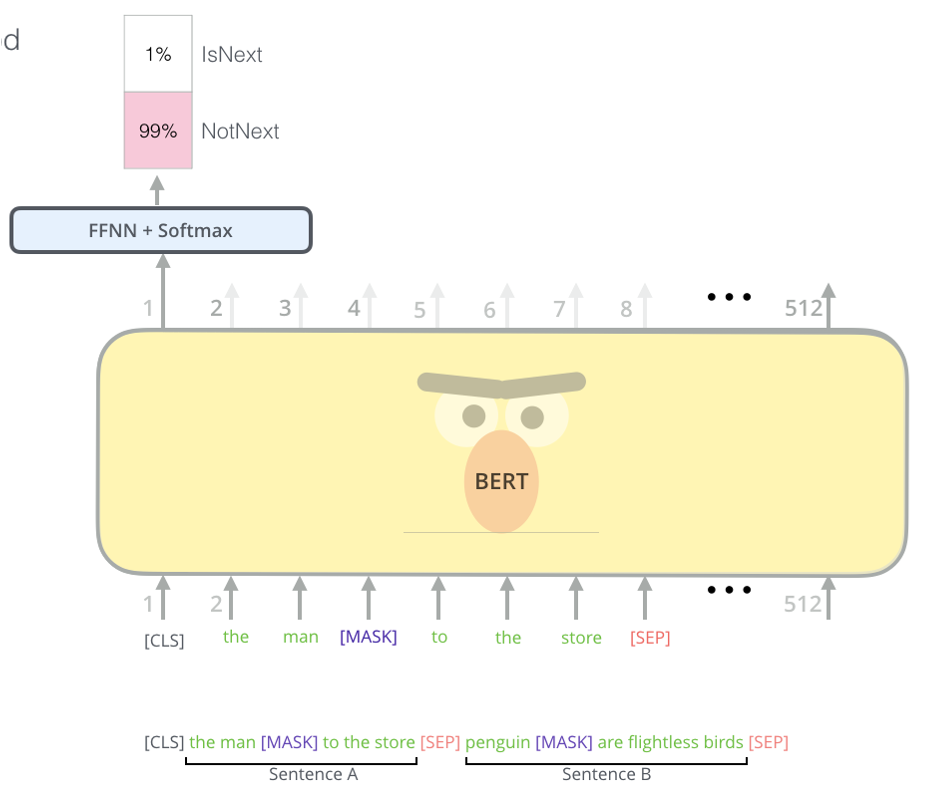
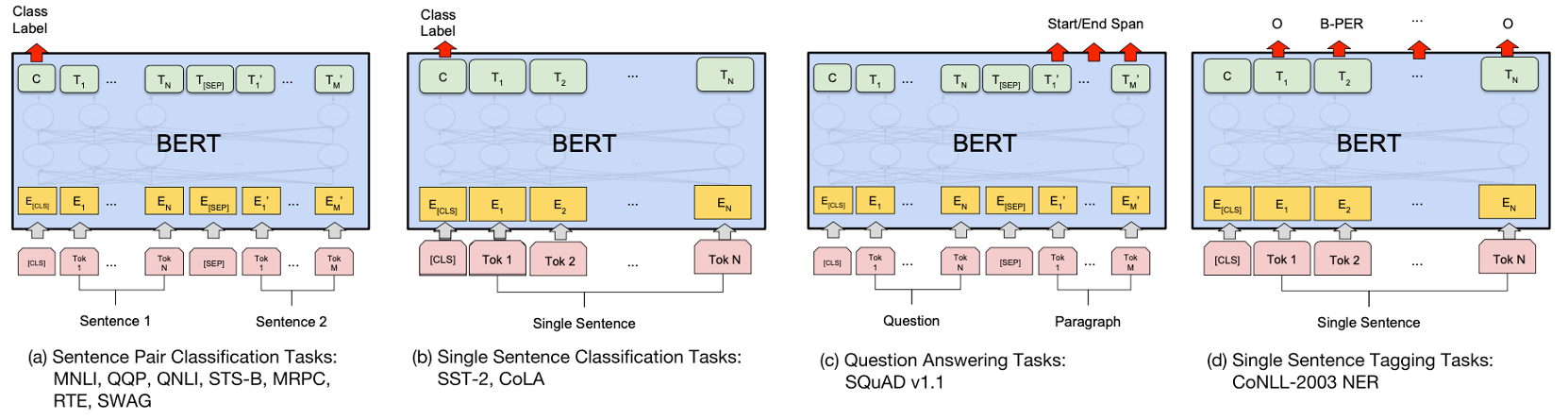
3) Fine-tuning
이제 pre-training된 모델에 사용자의 태스크에 맞게 layer를 쌓아 fine-tuning을 합니다. 이 부분은 생략하도록 하겠습니다.
BERT4Rec 제안
앞서 언급했듯 일방향의 모델은 한계점이 있으므로 양방향의 context를 통해 맥락을 파악하고, data leakage를 막고 data augmentation도 활용하고자 Masked Language Model를 사용하여 다음 아이템을 예측하고자 추천시스템에 BERT를 활용하게 되었습니다. 단어가 들어갈 위치에 아이템을 넣고 random하게 마스킹하여 주변 맥락으로 아이템의 ID를 예측합니다.
2 | Model Structure
Problem Statement
그럼 이제 수식으로 문제를 정의해보겠습니다. 무엇을 상호작용으로 잡을지는 도메인과 태스크에 따라 달라집니다. 예측은 유저가 선택할 수 있는 모든 가능한 아이템들의 확률을 구하여 모델링합니다.

Model Architecture
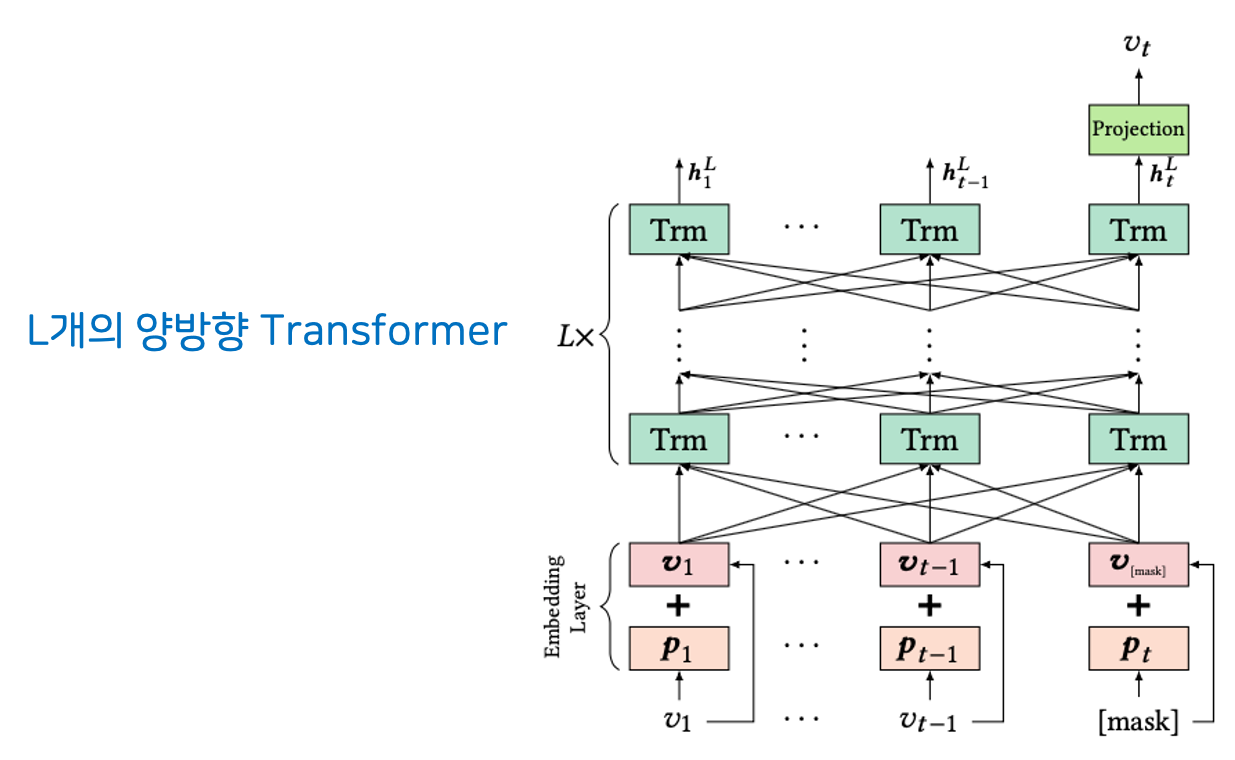
전체 모델 구조를 보시면 앞으로만 정보를 전달하는 기존의 RNN 기반 방법과 달리 Self-Atttention을 활용하여 거리가 멀어져도 의존도를 반영할 수 있습니다. 또한 이전 글에서 다룬 SASRec과 비교해보자면, SASRec은 마지막 1개에만 [MASK]를 하는 반면 BERT는 다른 곳에 더 여러 개의 [MASK]를 쓰게 됩니다. 이 밖에도 SASRec은 Single-head Attention, BERT는 Multi-head Attention을 씁니다.
Transformer Layer
Multi-head Self-Attention
① h개의 subspace에 projection 후 concatenate
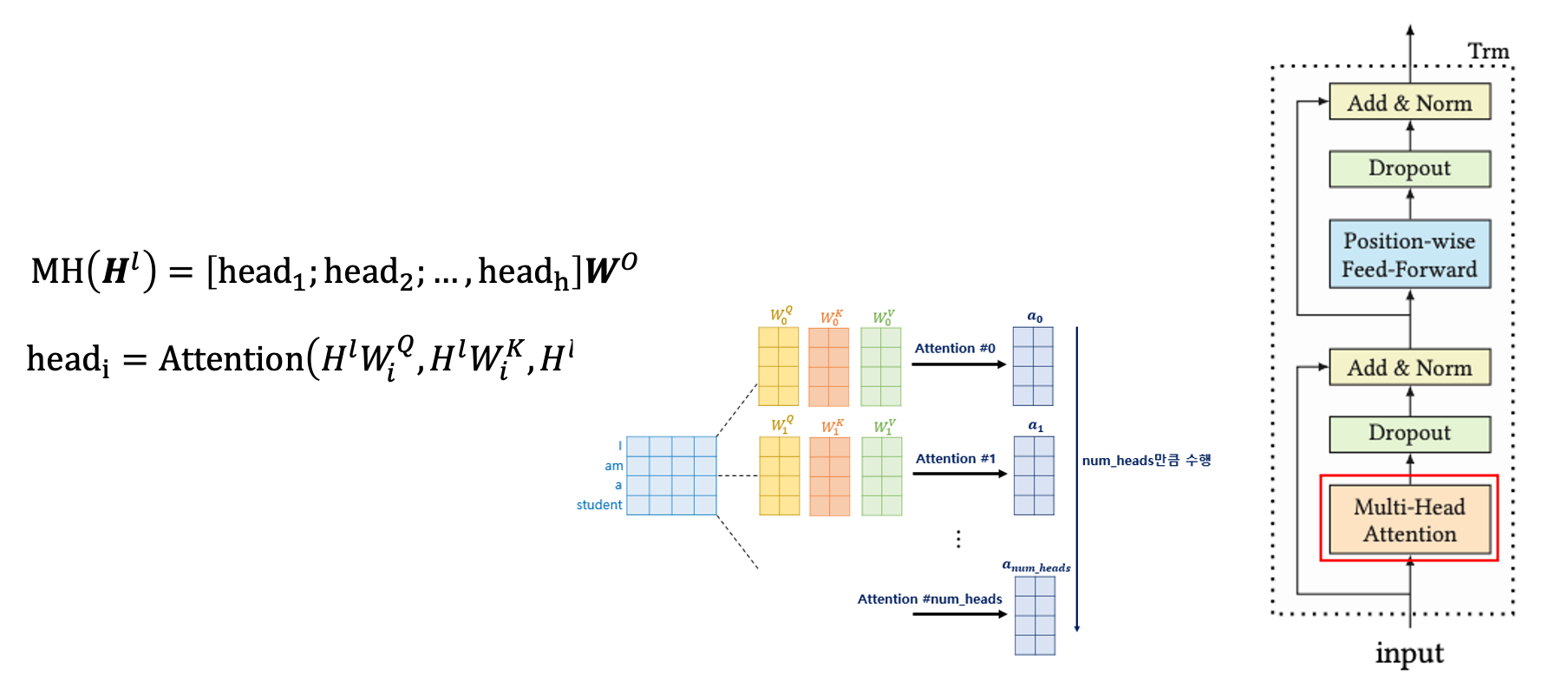
각 l 레이어에서 hidden representation h를 계산한 후, 이걸 모두 쌓아서 Attention 함수에 넣습니다. Multi-head로 각각의 input sequence에 서로 다른 가중치행렬을 곱하여 더 작은 사이즈의 Q, K, V 행렬을 만듭니다. 이 가중치행렬을 학습이 되며, 레이어 간에 변수는 공유하지 않습니다.
② Scaled Dot-Product Attention

여기서 사용되는 Attention Map은 key와 query의 관계 행렬을 사용하게 됩니다. 더 좋은 어텐션 분포를 위해 scaling도 합니다. 이후 각각의 head들의 contextual vector를 합쳐 Multi-head Self-Attention이 나옵니다.
Position-wise Feed-Forward Network
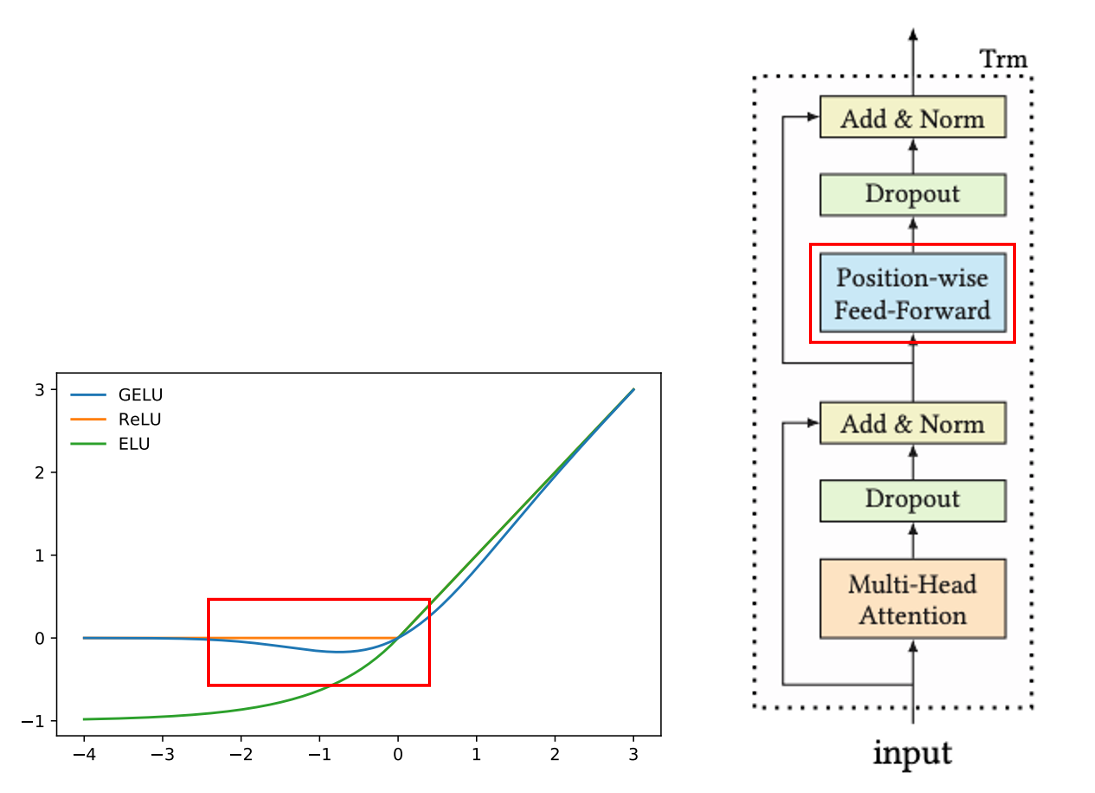
앞서 얻은 Multi-Head Self-Attention은 linear projection이기 때문에 비선형성을 주어야합니다. 이를 위해 FC Layer에 GeLU 함수를 활성화 함수로 사용합니다. GeLU는 Gaussian Error Linear Unit으로 BERT에서 제안된 함수인데, ReLU와 달리 음수에 대해서도 미분이 가능해 약간의 그래디언트를 더 전달할 수 있습니다. 이렇게 각 Attention Layer를 쌓는데, 너무 깊어지면 학습하기가 어려우므로 Transformer와 마찬가지로 Residual Connection과 Layer Normalization, DropOut을 함께 사용합니다.
Embedding Layer
앞서 언급했듯이, Transformer는 위치 정보가 포함되지 않기 때문에 Positional Embedding Layer를 추가합니다. 이때, sinusoid로 고정하지 않고 더 나은 성능을 위해 학습 가능한 Embedding Layer를 사용하여 Input Embedding Layer를 고정된 look-up table로 활용합니다.
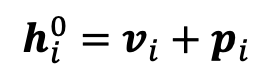
Output Layer
최종 Output Layer의 수식입니다.
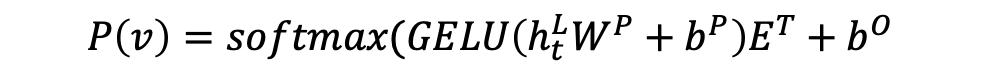
3 | Model Learning
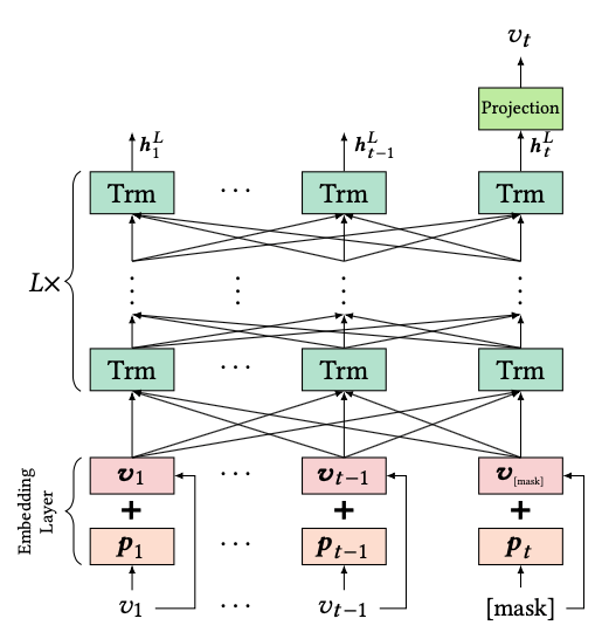
모델을 학습할 때는 BERT처럼 [MASK]를 씌우고 이를 맞히게 하는 Cloze Task를 진행합니다. [MASK]가 여러 개인 경우네는 순차적으로 진행합니다. 구체적으로는 t 시점의 아이템 v를 마스킹하고, h를 기반으로 예측합니다.
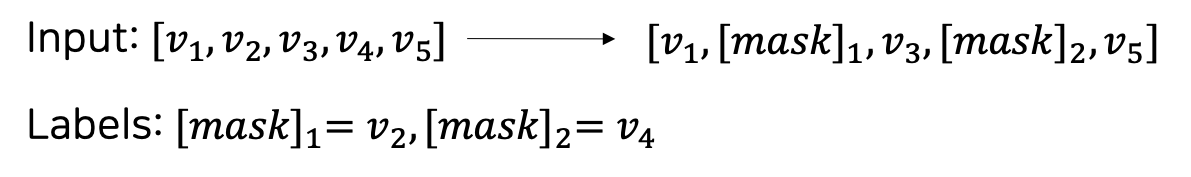
Negative Log Likelihood를 이용하여 label과 예측값 간의 loss를 정의합니다. 원래 자리가 ground truth가 되고, 나머지는 negative sample이 됩니다. 그리고 이 loss fuction을 통해 ground truth는 점수가 높게, negative samples는 점수가 낮게 나오도록 합니다.
마지막으로, BERT는 학습할 때와 실제로 테스트할 때의 태스크가 다릅니다. 기존 자연어처리 분야에서 제안된 BERT 모델은 pre-training 용도이기도 하고, representation learning이 목적이기 때문에 end-to-end 모델이 아닙니다. 그러나 BERT4Rec에서는 next item을 예측하는 태스크의 end-to-end 모델이 필요했기 때문에, 모델 학습의 마지막 부분에 fine-tuning 개념으로 마지막 아이템을 마스킹하여 이를 맞히는 태스크를 더 진행합니다.
4 | Experiment & Conclusion
Dataset
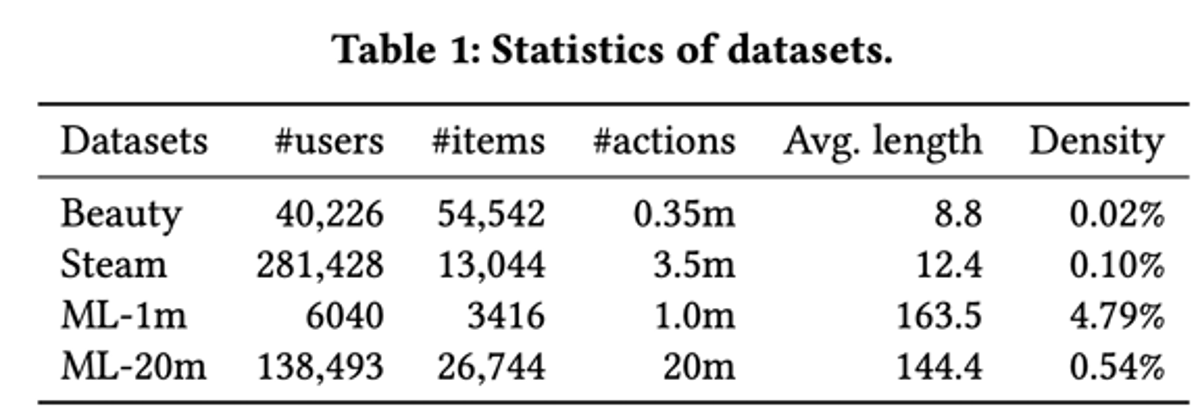
데이터는 Beauty, Steam, ML-1m, ML-20m를 사용하는데, 앞에 2개는 sparse한 데이터, 뒤에 2개는 dense한 데이터입니다. ML 같은 경우에는 영화 평점의 explicit feedback인데 이를 0과 1로 구분하는 implicit feedback으로 바꾸어 사용했습니다. Label은 Ground Truth와 인기순으로 100개를 뽑은 Negative Samples로 이루어져있습니다.
Evaluation
- HR@k: 내가 추천한 상위 k개 아이템 중 다음 아이템이 있는 비율
- NDCG@k: 내가 추천한 아이템들의 순위 점수 / k개 아이템의 이상적 순위 점수
- MRR: Grount Truth가 몇 순위에 있는지 위치 별로 점수 획득

Experiments
Baseline 비교
다음 아이템 맞히기에 대한 성능 비교 결과입니다. 단순 BERT만 사용했음에도 불구하고 다른 모델보다 좋은 성능을 보여줍니다. 추가적으로 POP, BPR-MF, NCF, FPMC는 딥러닝 모델이 아니지만 다른 딥러닝 모델들과 큰 성능 차이는 없는 것으로 나타났습니다.

Self Attention vs. Masked Learning
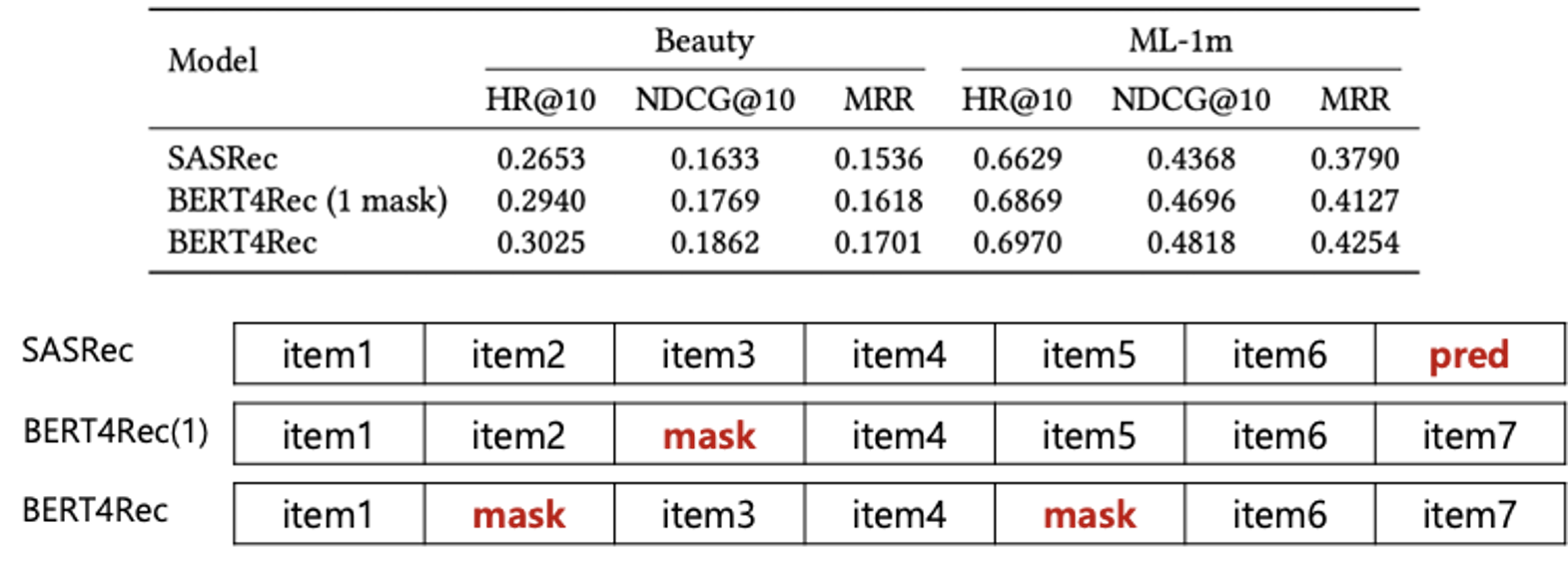
양방향을 사용할 때와, 마스크 수를 조절할 때의 성능을 비교해보았는데 양방향을 통해 유의미하게 성능이 개선되었고, 적당한 마스크 수는 성능 향상에 도움이 된다는 것을 알 수 있습니다.
Transformer의 Hidden Dimension
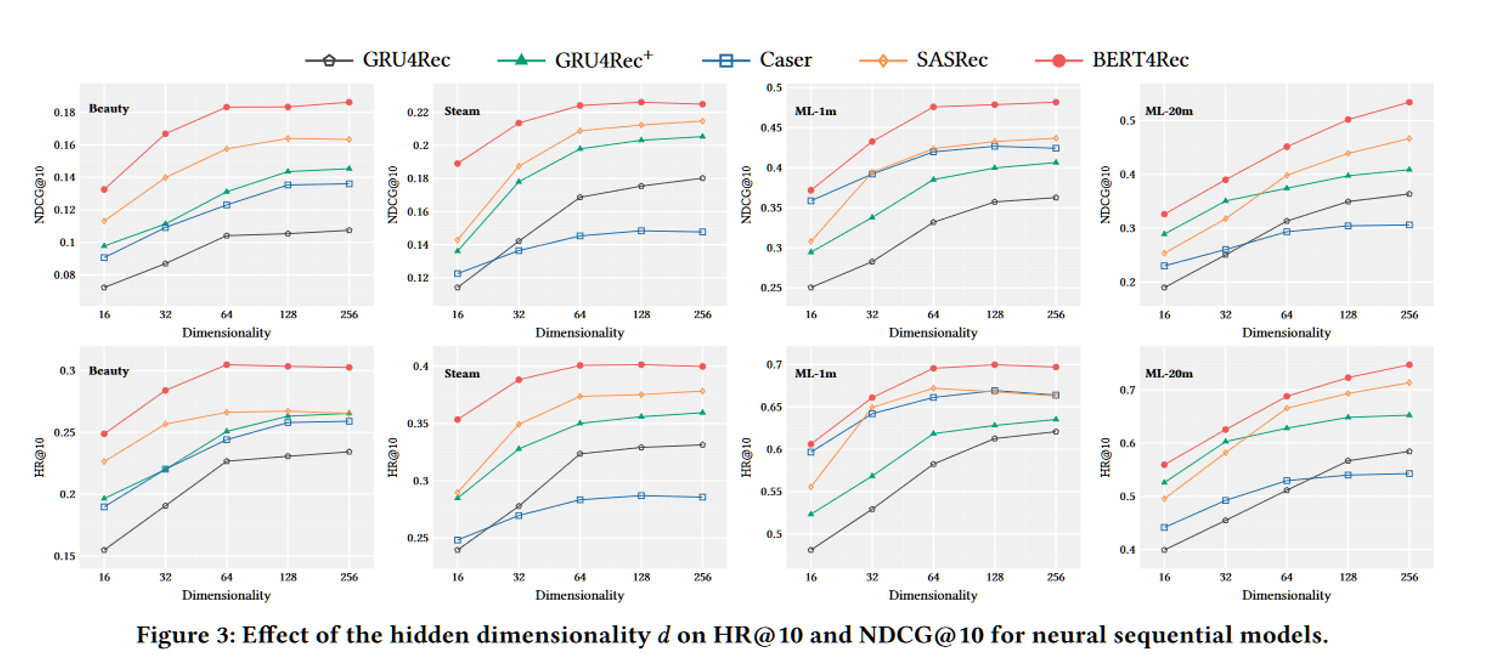
SAS4Rec, BERT4REc으로 갈수록 정보가 많아지고 모델이 커지기 때문에 차원 수도 커져야 할 필요가 있었습니다. 차원은 128차원과 64차원일 때 제일 좋았습니다.
Mask의 비율
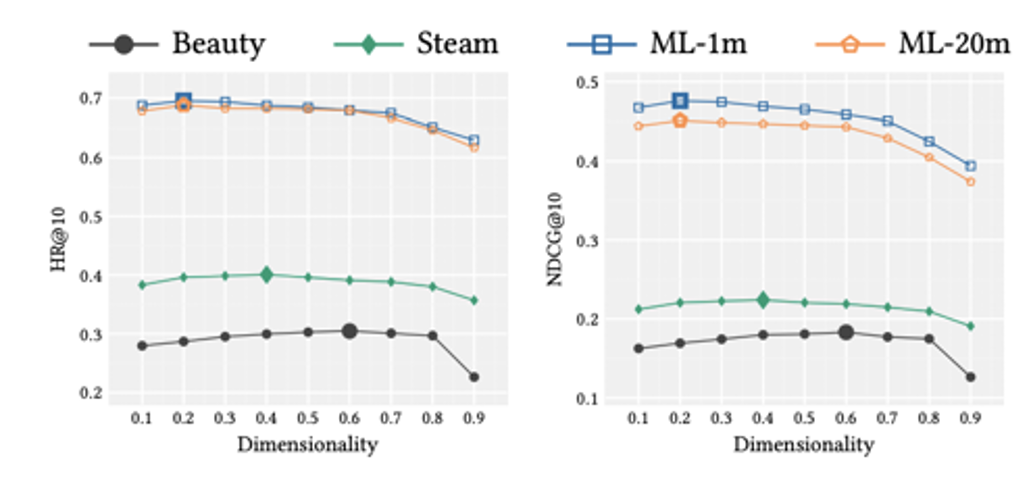
Dataset의 density를 기준으로 마스크의 비율을 비교해보았습니다. Dataset이 적당히 dense 할수록 성능이 향상되었지만, 너무 많이 dense 한 경우에는 성능 저하가 발생했습니다.
Maximum Sequence Length
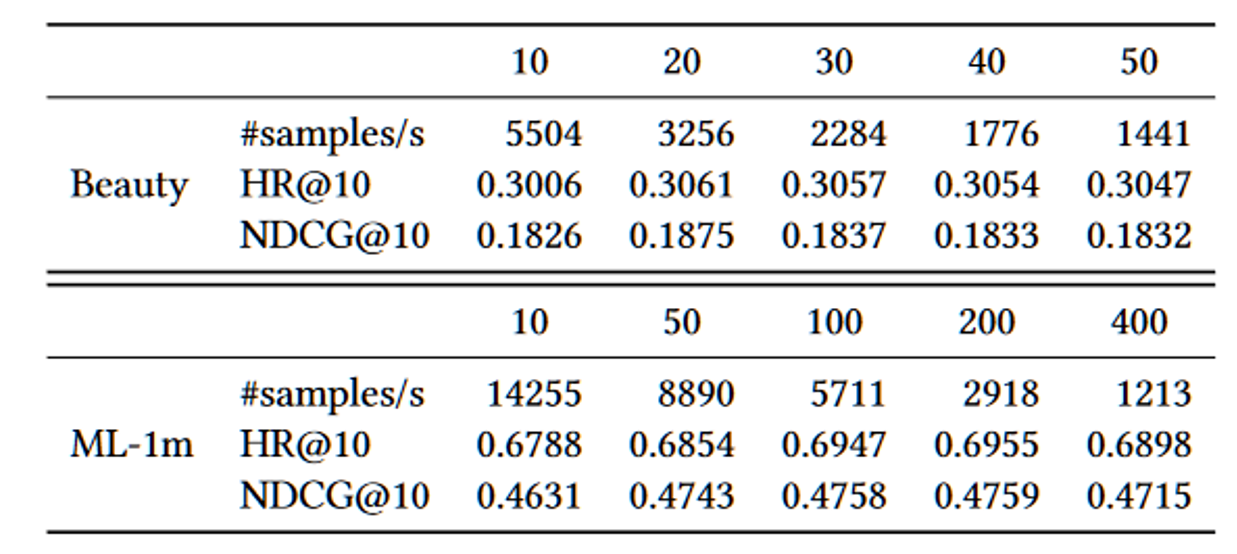
이는 시퀀스 길이를 최대 얼마로 해야되는지에 대하여 알아보기 위함인데, Next Item 예측에서 최신 아이템을 많이 받을수록, 즉 N이 클수록 성능이 향상되었습니다. 너무 많은 정보는 패턴에서 noise까지 학습하기 때문에 성능이 저하됩니다.
Conclusion
의의
- Bidirectional Self-Attention을 추천시스템에 적용하여 좋은 성능을 보임
한계
- 아이템에 항상 순서가 정해져있는 것은 아님
- 아이템과 유저가 정해져있지 않음
- 기술적으로 아이템의 시퀀스를 유저별로 저장하기 어려움
- 도메인에 따라 아이템의 생명주기가 확실
- 외부 요인으로 인하여 Offline Evaluation과 Online Result가 다른 경우가 많음
- 다른 딥러닝을 이용하지 않은 모델에 비해 상대적으로 학습 속도가 느림 (실용적이지 않음)

5개의 댓글

[15기 이성범]
본 논문에서는 기존의 추천시스템에서 쓰이는 NLP 모델 중 Transformer 등의 단방향 모델은 시퀀스를 왼쪽에서 오른쪽의 순서로 읽어가며 빈칸을 예측하기 때문에 사용자의 행동에 대한 representation이 제한된다고 한다. 따라서 본 논문은 사용자의 행동에 대한 representation를 더 잘 캡쳐할 수 있도록 Deep한 양방향 Self-Attention 모델로서 BERT를 추천 시스템에 활용하는 것을 제안했다.
본 논문에서 제안한 BERT4Rec은 단어가 들어갈 위치에 아이템을 넣는다. 양방향의 아이템을 통해 맥락을 파악하고, Random 하게 마스킹 처리를 하여 주변 맥락으로 아이템을 예측한다. 이러한 방식을 통해서 Data leakage를 막고 Data augmentation의 효과도 얻을 수 있었다. 모델은 유저가 선택할 수 있는 모든 가능한 아이템들의 확률을 예측한다. 또한 Self-Attention을 통해서 거리가 먼 아이템의 의존성도 반영할 수 있다. 그리고 Mult-head Self-Attention을 활용하여 조금 더 다양한 아이템의 속성을 반영할 수 있게 된다.
그러나 본 논문에서 제시한 BERT4Rec의 경우 추천 시스템에 BERT를 적용하여 좋은 성능을 보였지만 많은 한계를 가진다. 아이템에 순서가 항상 정해져 있는 것은 아니며, 기술적으로 아이템의 시퀀스를 유저별로 저장하기는 어렵다. 또한 도메인에 따라 아이템의 Cycle이 존재한다. 따라서 BERT를 적용할 수 있는 Task가 매우 한정적이라는 단점을 가진다. 또한 BERT의 경우 다른 모델에 비하여 상대적으로 학습 속도가 느리기 때문에 실용적이지 않다.
BERT4Rec
양방향으로 글을 참조한다면 예측하기가 더 수월해지기에 Deep한 Self-Attention 모델로 BERT가 추천시스템으로서 제안되었다.
BERT
Input Representation에서는 3가지 임베딩이 쓰이게 된다.
1) WordPiece Embedding
문장을 토큰 단위로 분리하며 CLS와 SEP라는 스페셜 토큰이 쓰인다.
CLS는 문장의 맨 처음에 등장하여 모든 벡터를 참고한 뒤에 context vector로 쓰이고 SEP는 두 문장을 구분한다.
2) Segment Embedding
두 개의 다른 문장을 구분한다.
3) Positional Embedding
Transformer를 기반으로 하며 sin함수와 cos함수를 사용하여 토큰들의 상대적 위치 정보를 알려준다.
-
Masked Language Model
단어 중 일부를 MASK 토큰으로 바꾼 후 이를 예측한다. -
Next Sentence Prediction
binary classification으로 두 문장 사이의 관계를 이해할 수 있다. -
Fine-tuning
Bert4Rec을 통해서 단어가 들어갈 위치에 아이템을 넣고 무작위하게 마스킹하여 주변 맥락을 통해 아이템의 ID를 예측한다.
RNN기반 방법과 달리 Self Attention을 활용하기 때문에 거리가 멀어져도 의존도를 반응할 수 있다.
[Transformer Layer]
Multi-head Self-Attention
1. h개의 subspace에 projection 후 concatenate
2. Scaled Dot-Product Attention
Position-wise Feed-Forward Network
FC Layer에서 GeLu 함수를 활성화 함수로 사용한다. Residual Connection, Layer Normalization, DropOut을 함께 사용한다.
Embedding Layer
Transformer은 위치 정보가 없어서 Positional Embedding Layer를 추가한다.
BERT4Rec에서는 next item을 예측하는 태스크의 end-to-end 모델이 필요했기 때문에, 모델 학습의 마지막 부분에 fine-tuning 개념으로 마지막 아이템을 마스킹하여 이를 맞히는 태스크를 더 진행한다.
학습 결과 양방향을 통하고 적당한 마스크 수를 조절하면 성능이 향상되었다.

15기 류채은
BERT4Rec
양방향으로 글을 참조한다면 예측하기가 더 수월해지기에 Deep한 Self-Attention 모델로 BERT가 추천시스템으로서 제안되었다.
BERT
Input Representation에서는 3가지 임베딩이 쓰이게 된다.
1) WordPiece Embedding
문장을 토큰 단위로 분리하며 CLS와 SEP라는 스페셜 토큰이 쓰인다.
CLS는 문장의 맨 처음에 등장하여 모든 벡터를 참고한 뒤에 context vector로 쓰이고 SEP는 두 문장을 구분한다.
2) Segment Embedding
두 개의 다른 문장을 구분한다.
3) Positional Embedding
Transformer를 기반으로 하며 sin함수와 cos함수를 사용하여 토큰들의 상대적 위치 정보를 알려준다.
-
Masked Language Model
단어 중 일부를 MASK 토큰으로 바꾼 후 이를 예측한다. -
Next Sentence Prediction
binary classification으로 두 문장 사이의 관계를 이해할 수 있다. -
Fine-tuning
Bert4Rec을 통해서 단어가 들어갈 위치에 아이템을 넣고 무작위하게 마스킹하여 주변 맥락을 통해 아이템의 ID를 예측한다.
RNN기반 방법과 달리 Self Attention을 활용하기 때문에 거리가 멀어져도 의존도를 반응할 수 있다.
[Transformer Layer]
Multi-head Self-Attention
1. h개의 subspace에 projection 후 concatenate
2. Scaled Dot-Product Attention
Position-wise Feed-Forward Network
FC Layer에서 GeLu 함수를 활성화 함수로 사용한다. Residual Connection, Layer Normalization, DropOut을 함께 사용한다.
Embedding Layer
Transformer은 위치 정보가 없어서 Positional Embedding Layer를 추가한다.
BERT4Rec에서는 next item을 예측하는 태스크의 end-to-end 모델이 필요했기 때문에, 모델 학습의 마지막 부분에 fine-tuning 개념으로 마지막 아이템을 마스킹하여 이를 맞히는 태스크를 더 진행한다.
학습 결과 양방향을 통하고 적당한 마스크 수를 조절하면 성능이 향상되었다.
[15기 장아연]
기존의 추천시스템 NLP 모델은 단방향으로 sequence를 읽으며 예측을 진행하는데 추천 시스템의 경우 문장 속 문법처럼 정해진 순서가 존재하지 않고 공식화 되기 어려운 User의 행동 순서 때문에 그 representation이 제한됨. 따라서 representation을 높일 수 있도록 양방향 self-attention 모델인 BERT를 제안함.
BERT(Bidirectional Encoder Representation from Transformers)는 단방향이 아닌 양방향으로 왼쪽에서 오른쪽으로 문맥을 읽으며 숫자의 형태로 바꿔주는 딥러닝 모델임. Transformer 기반으로 문장 전체를 모델에 제시하고 [MASK]에 해당하는 단어를 예측함. Unlabeled data로 사전학습하고 특정 task를 가진 labeled data로 전이학습을 진행함. WordPiece Embedding, Segment Embedding, Positional Embedding이 Input Representation에서 Embedding으로 쓰임. Masked Language Model과 Next Sentence Prediction인 Pre-training과정을 거쳐 layer를 쌓아 fine-tuning을 진행함.
Bert4Rec는 단어가 들어갈 위치에 아이템을 넣고 Random하게 Masking을 진행하고 양방향의 아이템을 통해 맥락을 통해 아이템의 ID 예측함. 이를 통해 data leakage를 막고 data augmentation도 가능함. 전반적인 구조는 Multi-head Self-Attention, Position-wise Feed-Forward Network, Embeding Layer, Output Layer로 구성됨.
추천시스템에서 BERT4Rec는 BERT보다 우수한 성능을 보이지 않음. 아이템의 순서는 매번 변경되고 이에 따른 유저를 저장하는 데도 한계가 존재함. 게다가 학습 속도가 느려 실용적이라고 하기 어려움.
[14기 이혜린]
기존 추천시스템 NLP 모델
BERT (Bidirectional Encoder Representation from Transformers)
3가지 임베딩
[CLS](문장의 맨 처음 등장. 모든 벡터를 참고한 뒤에 context vector로 쓰임),[SEP](두 문장을 구분)BERT4Rec
유저가 선택할 수 잇는 모든 가능한 아이템들의 확률을 예측
모델 구조
모델 학습
결론