[Code Review] (2018, IEEE) Self-Attentive Sequential Recommendation (SASRec)
Recommender_System

작성자: 고유경
앞선 논문 리뷰 게시물에 이어서 이번에는 SASRec을 Pytorch로 구현한 코드를 리뷰하겠습니다. 구현된 코드는 이 깃헙에서 보실 수 있습니다. 참고로 Tensorflow로 구현된 코드는 논문 저자의 github에 업로드되어 있으며, 파이토치와 텐서플로우 버전 모두 모델링 부분을 제외하면 동일한 코드와 구성을 이루고 있기 때문에 해당 리뷰에서는 파이토치 버전을 다루고자 합니다.
Overview
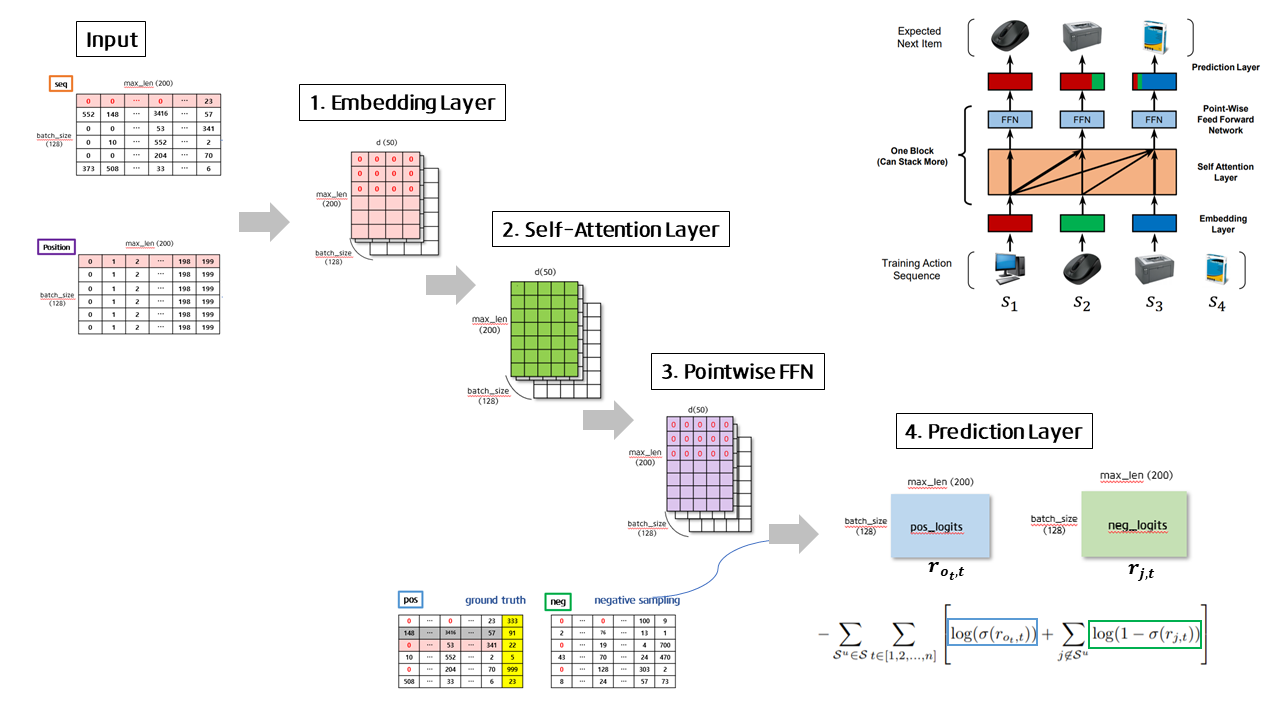
전체적인 SASRec의 구조는 다음과 같습니다.
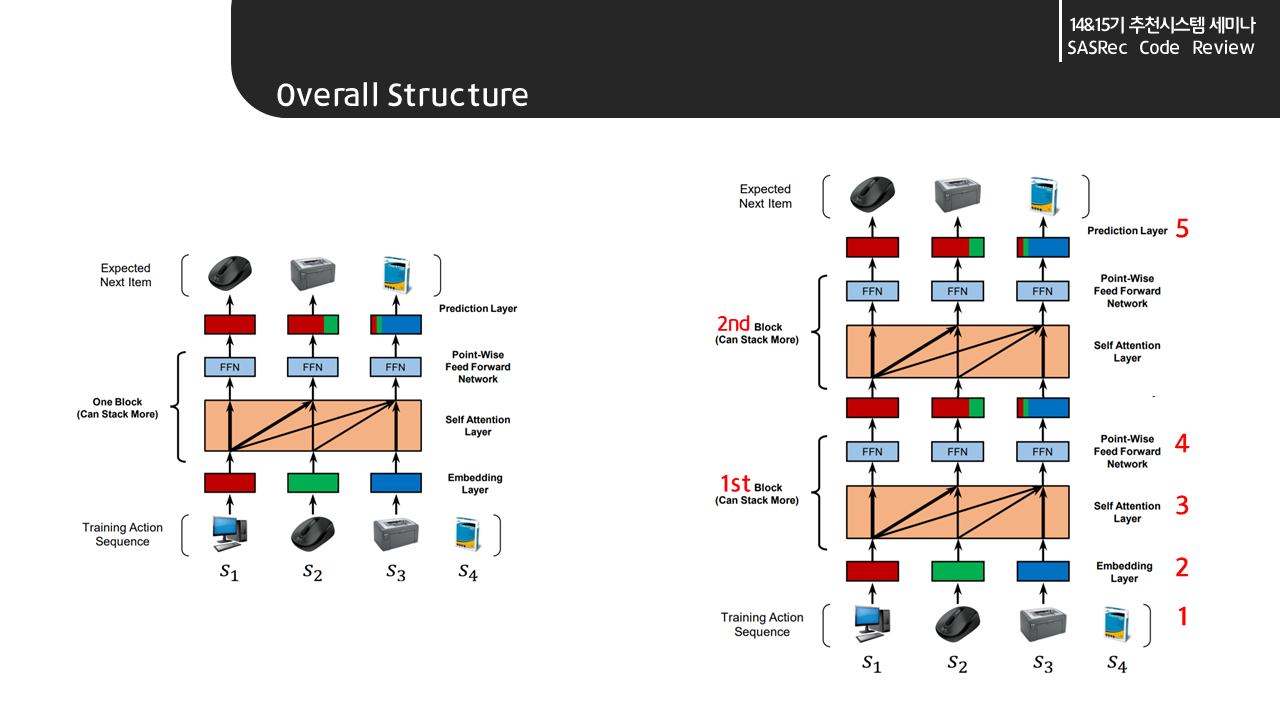
input 시퀀스는 Embedding Layer를 거치고 Self Attention Layer(S-A layer)와 Point-Wise Feed Forward Network(P-W FFN)로 이루어진 블럭을 거쳐 최종 Prediction Layer를 거친 이후, 유저가 다음에 선택할 아이템을 예측하게 됩니다. 본 코드에서는 오른쪽 그림과 같이 총 2개의 블럭이 쌓여있어 S-A layer와 P-W FFN을 각각 2번씩 지나게 됩니다.
지금부터 하나의 예시 데이터를 가지고 input에서부터 output이 나오는 과정을 1~5번까지 코드와 함께 차례로 살펴보겠습니다.
1. Input Action Sequence
저희가 살펴볼 데이터는 영화 평점 데이터 Movie Lens Dataset입니다.
 본 데이터셋은
본 데이터셋은 User ID, Movie ID, Ratings, Timestamps로 이루어져 있으며 각 유저의 관람 영화와 평가 점수, 관람 시각 등의 정보가 담겨있습니다.
SASRec은 이 중 Implicit information인 유저의 관람 영화 시퀀스만을 필요로 하기에 데이터 txt 파일에서 User ID와 Movie ID만을 불러와 User 딕셔너리를 구성하게 됩니다. 이때 User ID는 key, Movie ID는 각 key에 해당하는 value가 됩니다.
또한 유저의 관람 시퀀스 리스트에서 후반 2개의 영화는 각각 valid와 test set을 구성하는데 활용됩니다.
이 과정에 해당하는 코드는 utils.py에 구현되어 있으며 아래와 같습니다.
def data_partition(fname):
usernum = 0
itemnum = 0
User = defaultdict(list)
user_train = {}
user_valid = {}
user_test = {}
# assume user/item index starting from 1
f = open('data/%s.txt' % fname, 'r')
for line in f:
u, i = line.rstrip().split(' ')
u = int(u)
i = int(i)
usernum = max(u, usernum)
itemnum = max(i, itemnum)
User[u].append(i)
for user in User:
nfeedback = len(User[user])
if nfeedback < 3:
user_train[user] = User[user]
user_valid[user] = []
user_test[user] = []
else:
user_train[user] = User[user][:-2]
user_valid[user] = []
user_valid[user].append(User[user][-2])
user_test[user] = []
user_test[user].append(User[user][-1])
return [user_train, user_valid, user_test, usernum, itemnum]이어서 각 유저마다 관람한 영화 개수는 모두 다르기 때문에 input data를 구성하기 위해서는 시퀀스의 길이를 통일하여 하나의 텐서로 구성해야합니다.
 1번 유저(pink)처럼 시퀀스 최대 길이인
1번 유저(pink)처럼 시퀀스 최대 길이인 max_len(200)보다 짧은 시퀀스는 남은 자리를 0으로 채우는 zero-padding 과정을 거치고, 6040번 유저(gray)처럼 max_len(200)보다 긴 경우에는 200개를 초과하는 초반 영화들을 모두 삭제하게 됩니다. 이 과정을 통해 batch_size(128)xmax_len(200) size를 가진 seq 인풋 텐서(orange)가 만들어지고, 동시에 동일한 사이즈의 pos(blue)와 neg(green)텐서가 만들어집니다.
pos는 유저들이 가장 처음으로 관람한 영화 ID를 제거하고 마지막으로 관람한 영화 ID를 추가한 텐서로 ground truth를 나타냅니다. 반면, neg의 경우, 유저가 관람하지 않은 영화 목록에서 랜덤으로 한개씩 뽑아 pos와 동일한 사이즈로 구성합니다. pos와 neg는 후에 Prediction Layer에서 loss를 계산하는 과정에 쓰일 예정이며, Embedding Layer로 들어갈 input은 seq 텐서가 됩니다.
이 과정에 해당하는 코드는 utils.py에 구현되어 있으며 아래와 같습니다.
def random_neq(l, r, s):
t = np.random.randint(l, r)
while t in s:
t = np.random.randint(l, r)
return t
def sample_function(user_train, usernum, itemnum, batch_size, maxlen, result_queue, SEED):
def sample():
user = np.random.randint(1, usernum + 1)
while len(user_train[user]) <= 1: user = np.random.randint(1, usernum + 1)
seq = np.zeros([maxlen], dtype=np.int32)
pos = np.zeros([maxlen], dtype=np.int32)
neg = np.zeros([maxlen], dtype=np.int32)
nxt = user_train[user][-1]
idx = maxlen - 1
ts = set(user_train[user])
for i in reversed(user_train[user][:-1]):
seq[idx] = i
pos[idx] = nxt
if nxt != 0: neg[idx] = random_neq(1, itemnum + 1, ts)
nxt = i
idx -= 1
if idx == -1: break
return (user, seq, pos, neg)2. Embedding Layer
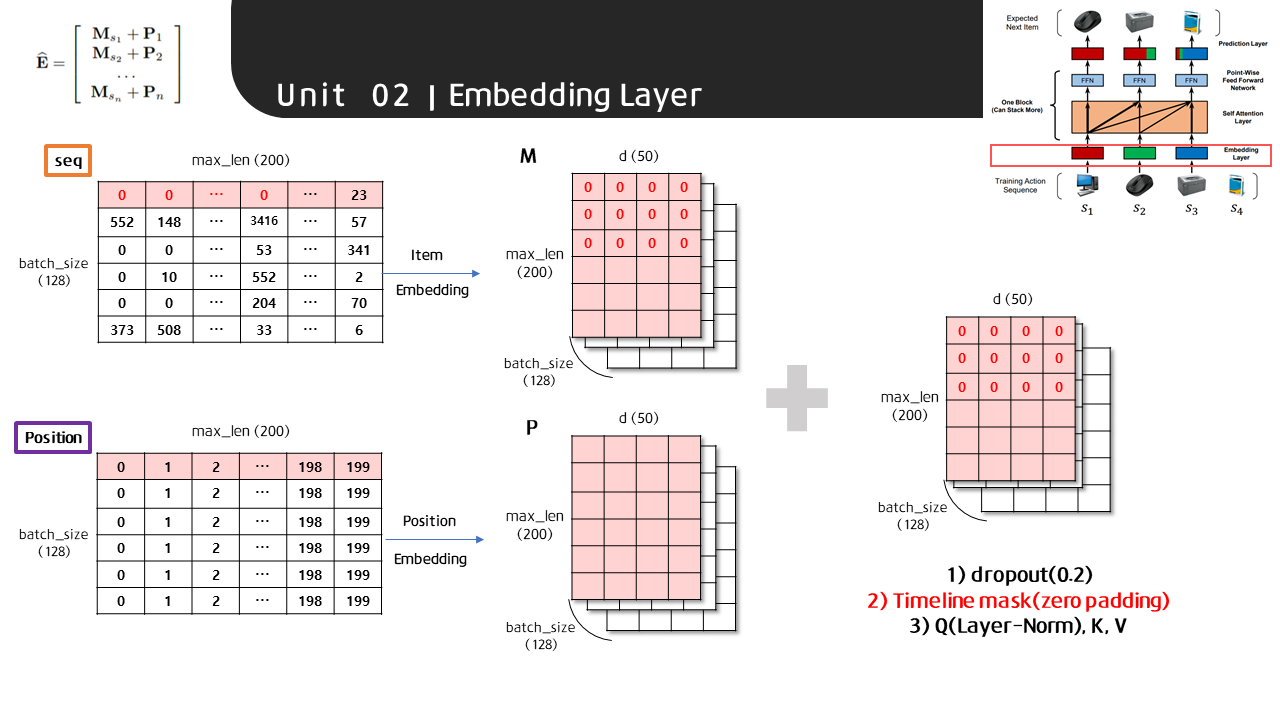 1) Item Embedding
1) Item Embedding
input으로 들어온 seq텐서는 Item Embedding을 거쳐 batch_size(128) x max_len(200) x d(50) 사이즈의 텐서로 변환됩니다.
2) Position Embedding
초기 위치값을 나타내는 텐서는 max_len(200)에 맞춰 0~199 사이의 값으로 batch_size(128)만큼 채워집니다. 이 텐서는 Position Embedding을 거쳐 아이템 임베딩 행렬과 마찬가지로 batch_size(128) x max_len(200) x d(50) 사이즈의 텐서로 변환됩니다.
이후, 두 텐서의 값은 더해지고, dropout 과정을 거치게 됩니다. 이어서 다시 한 번 zero-padding 과정을 거치게 되는데, 이 이유는 position embedding의 결과가 zero-padding 정보를 담고 있지 않기 때문입니다. 이렇게 완성된 텐서는 이어지는 Self-Attention Layer의 input인 Key와 Value가 되고, Layer normalization을 한 번 더 거친 텐서는 Query로 활용됩니다.
이 과정에 해당하는 코드는 아래 Self-Attention Layer와 Pointwise Feed Forward Network에 대한 설명 이후 한 번에 보여드리도록 하겠습니다.
3. Self-Attention Layer

Embedding Layer를 통해 만들어낸 Query, Key, Value 텐서는 각 가중치 행렬과의 선형결합 연산 이후 Self-Attention Layer을 거치게 됩니다. 해당 식은 위 슬라이드 수식을 참고해주시기 바랍니다. 이 때 주의해야할 점은 Query와 Key의 행렬곱 연산 이후 이전 시점에 대해 이후 시점의 영향력을 배제하기 위한 Attention Masking 과정이 추가된다는 점입니다. 이후 시점의 영화에 해당하는 값들을 모두 0으로 마스킹해주어 뒤이어올 Value와의 행렬곱 연산에서 이후 시점들의 값을 반영하지 않도록 해줍니다. 이렇게 완성된 텐서(skyblue)는 input과 동일한 차원인 batch_size(128) x max_len(200) x d(50) 사이즈로 이루어져 있으며, 이후 Residual Connection과 Layer Normalization을 차례로 거쳐 output(green)을 내보내게 됩니다.
4. Pointwise Feed Forward Network
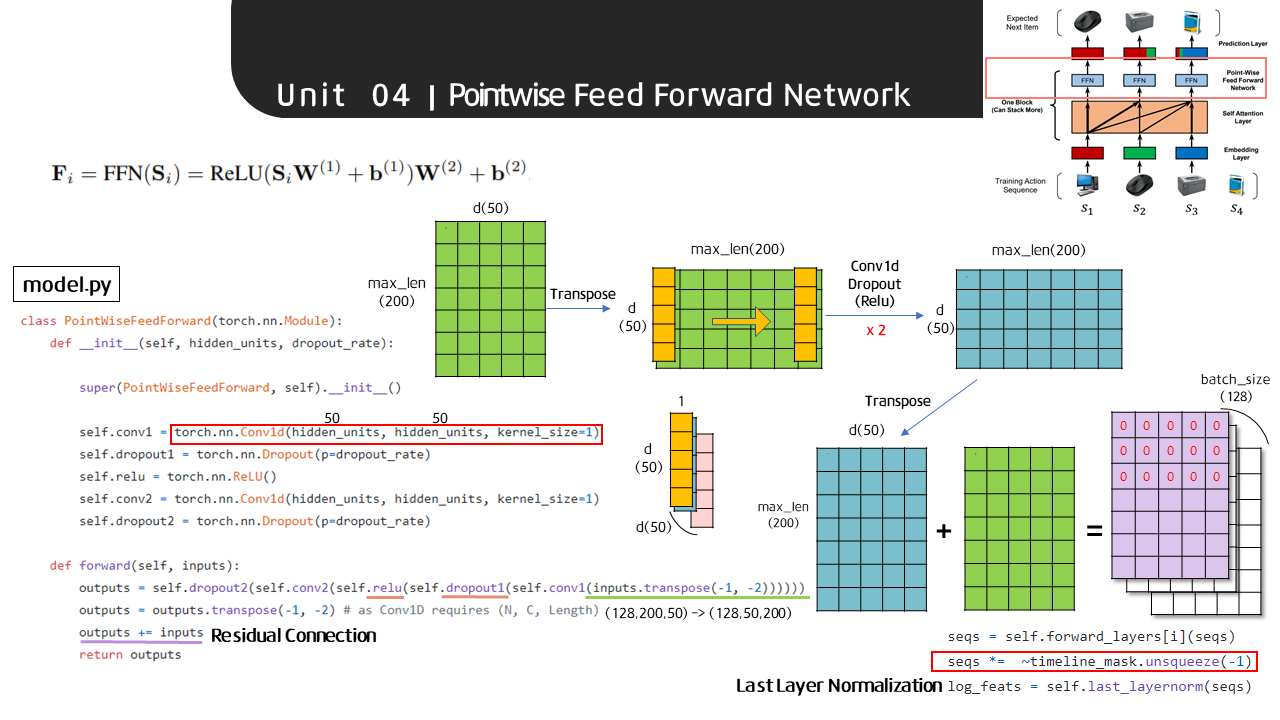
Pointwise Feed Forward Network(이하 P-W FFN)은 선형결합 연산이 두 번 반복되는 것과 동일합니다. 해당 코드에서는 1d Convolution Layer를 통해 본 연산을 구현하였는데, 이때 주의할 점은 input으로 들어갈 텐서를 transpose(전치)시켜야 한다는 점입니다. 이는 1d Conv 연산의 특징에서 비롯하는데, 시퀀스의 time-step별로 kernel size 만큼 옆으로 이동하기 때문에 time step별로 input 텐서를 스캔하기 위해서는 전치를 해주어야 합니다.
위 그림처럼 노란색 커널이 관람 영화를 순서대로 스캔하면서 각 결과값을 내게 되고, 총 50개의 커널이 각 연산 과정을 거쳐 최종적으로 (transpose 이후의) input size와 동일한 batch_size(128) x d(50) x max_len(200) 사이즈의 텐서가 나오게 됩니다. 이후 dropout과 Relu(비선형 함수)를 거친 후 다시 한 번 1d Conv 연산과 dropout을 반복하게 됩니다.
다시 원래 형태로 돌리기 위해 transpose를 해주면 batch_size(128) x max_len(200) x d(50) 사이즈의 텐서로 돌아오게 되고, 여기에 초반 input 텐서(green)를 더해주는 Residual Connection 과정을 거치게 됩니다.
Self-Attention Layer와 P-W FFN을 거치면서 zero-padding의 정보는 또 한 번 유실되었기 때문에 이를 다시 유효화하기 위해 Embedding Layer에서 활용했던 timeline-mask를 다시 불러와 해당하는 위치에 0값을 채우게 됩니다.
이렇게 해서 완성된 텐서는 2번째 Block의 Self-Attention Layer의 input으로 들어가게 되고 동일한 과정을 반복하여 최종적으로 2개의 block(S-A Layer+P-W FFN)을 거친 output 텐서(purple)를 배출하게 됩니다.
2. Embedding Layer, 3. S-A Layer, 4. P-W FFN에 해당하는 코드는 model.py에 구현되어 있으며 아래와 같습니다.
class SASRec(torch.nn.Module):
def __init__(self, user_num, item_num, args):
super(SASRec, self).__init__()
self.user_num = user_num
self.item_num = item_num
self.dev = args.device
self.item_emb = torch.nn.Embedding(self.item_num+1, args.hidden_units, padding_idx=0)
self.pos_emb = torch.nn.Embedding(args.maxlen, args.hidden_units) # TO IMPROVE
self.emb_dropout = torch.nn.Dropout(p=args.dropout_rate)
self.attention_layernorms = torch.nn.ModuleList() # to be Q for self-attention
self.attention_layers = torch.nn.ModuleList()
self.forward_layernorms = torch.nn.ModuleList()
self.forward_layers = torch.nn.ModuleList()
self.last_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)
for _ in range(args.num_blocks):
new_attn_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)
self.attention_layernorms.append(new_attn_layernorm)
new_attn_layer = torch.nn.MultiheadAttention(args.hidden_units,
args.num_heads,
args.dropout_rate)
self.attention_layers.append(new_attn_layer)
new_fwd_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)
self.forward_layernorms.append(new_fwd_layernorm)
new_fwd_layer = PointWiseFeedForward(args.hidden_units, args.dropout_rate)
self.forward_layers.append(new_fwd_layer)
def log2feats(self, log_seqs):
seqs = self.item_emb(torch.LongTensor(log_seqs).to(self.dev))
seqs *= self.item_emb.embedding_dim ** 0.5
positions = np.tile(np.array(range(log_seqs.shape[1])), [log_seqs.shape[0], 1])
seqs += self.pos_emb(torch.LongTensor(positions).to(self.dev))
seqs = self.emb_dropout(seqs)
timeline_mask = torch.BoolTensor(log_seqs == 0).to(self.dev)
seqs *= ~timeline_mask.unsqueeze(-1) # broadcast in last dim
tl = seqs.shape[1] # time dim len for enforce causality
attention_mask = ~torch.tril(torch.ones((tl, tl), dtype=torch.bool, device=self.dev))
for i in range(len(self.attention_layers)):
seqs = torch.transpose(seqs, 0, 1)
Q = self.attention_layernorms[i](seqs)
mha_outputs, _ = self.attention_layers[i](Q, seqs, seqs,
attn_mask=attention_mask)
seqs = Q + mha_outputs
seqs = torch.transpose(seqs, 0, 1)
seqs = self.forward_layernorms[i](seqs)
seqs = self.forward_layers[i](seqs)
seqs *= ~timeline_mask.unsqueeze(-1)
log_feats = self.last_layernorm(seqs) # (U, T, C) -> (U, -1, C)
return log_feats
5. Prediction Layer
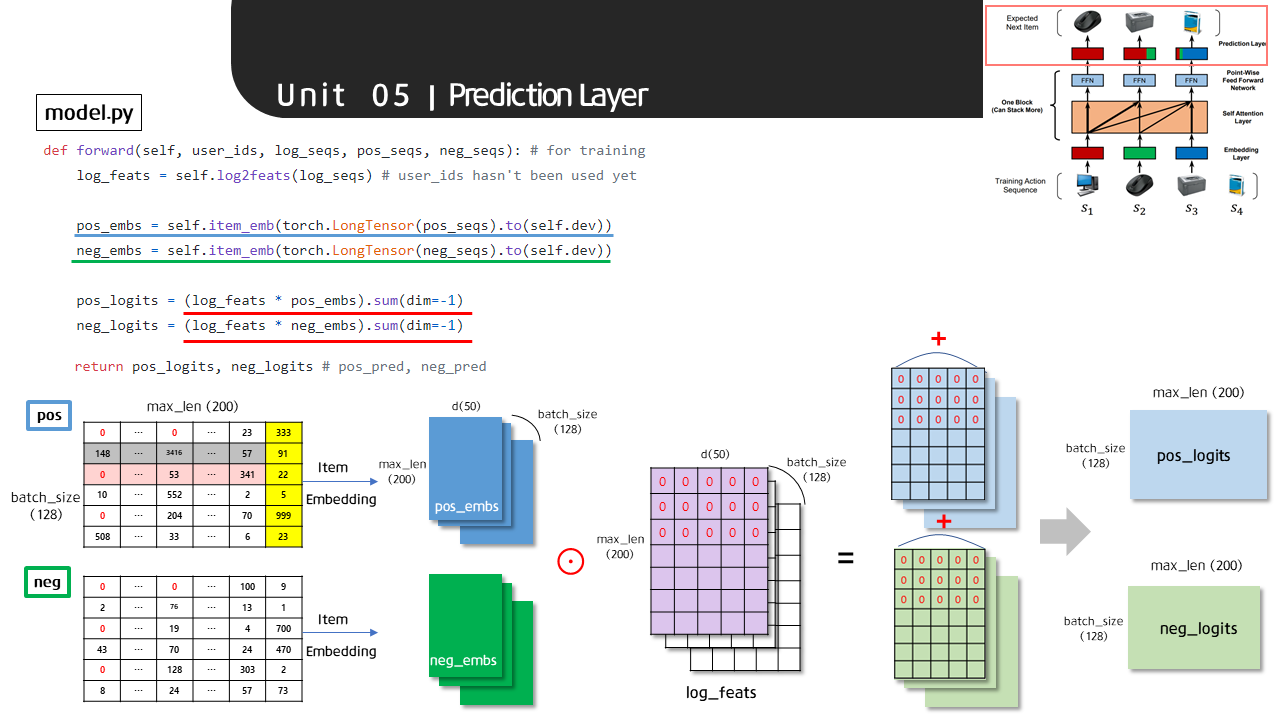
1. Input Action Sequence에서 생성한 pos와 neg 텐서를 동일한 item embedding layer에 태워 P-W FFN을 거친 output(purple)과 동일한 사이즈(batch_size(128) x max_len(200) x d(50))의 텐서로 변환합니다. 변환된 텐서들을 P-W FFN을 거친 output(purple)과 Element-wise product 연산을 진행하여 같은 위치의 값들이 서로 곱해지도록 하여 새로운 pos와 neg 텐서를 생성합니다. 이어서 두 텐서들을 마지막 차원인 d(50)을 기준으로 모두 더하여 batch_size(128) x max_len(200) 사이즈의 텐서로 축소합니다.
이 과정에 해당하는 코드는 model.py에 구현되어 있으며 아래와 같습니다.
def forward(self, user_ids, log_seqs, pos_seqs, neg_seqs): # for training
log_feats = self.log2feats(log_seqs) # user_ids hasn't been used yet
pos_embs = self.item_emb(torch.LongTensor(pos_seqs).to(self.dev))
neg_embs = self.item_emb(torch.LongTensor(neg_seqs).to(self.dev))
pos_logits = (log_feats * pos_embs).sum(dim=-1)
neg_logits = (log_feats * neg_embs).sum(dim=-1)
return pos_logits, neg_logits # pos_pred, neg_pred 이렇게 해서 완성된
이렇게 해서 완성된 pos_logits과 neg_logits 텐서는 위 그림과 같이
이전 영화들을 고려했을때 다음 영화의 관련성 점수를 나타내는 로 구성됩니다. P-W FFN을 거친 output(purple)은 zero-padding이 반영된 상태이기 때문에 이 텐서에서 파생된 pos_logits과 neg_logits 텐서 역시 유저가 영화를 관람하지 않은 시퀀스는 0값으로 채워져 있게 됩니다. 실제로 유저가 관람한 영화 시퀀스 정보를 담고 있는 pos_logits는 각 값이 최대한 커야 이 값에 시그모이드를 취한 값이 1에 가까워져 log loss가 최소가 되고, 반대로 유저가 관람하지 않은 영화 목록을 통해 구성한 neg_logits의 경우 각 값이 최대한 작아야 시그모이드를 취한 값이 0에 가까워져 log loss가 최소가 되게 합니다.
이 과정에 해당하는 코드는 main.py에 구현되어 있으며 아래와 같습니다.
for step in range(num_batch):
u, seq, pos, neg = sampler.next_batch() # tuples to ndarray
u, seq, pos, neg = np.array(u), np.array(seq), np.array(pos), np.array(neg)
pos_logits, neg_logits = model(u, seq, pos, neg)
pos_labels, neg_labels = torch.ones(pos_logits.shape, device=args.device), torch.zeros(neg_logits.shape, device=args.device)
adam_optimizer.zero_grad()
indices = np.where(pos != 0)
loss = bce_criterion(pos_logits[indices], pos_labels[indices])
loss += bce_criterion(neg_logits[indices], neg_labels[indices])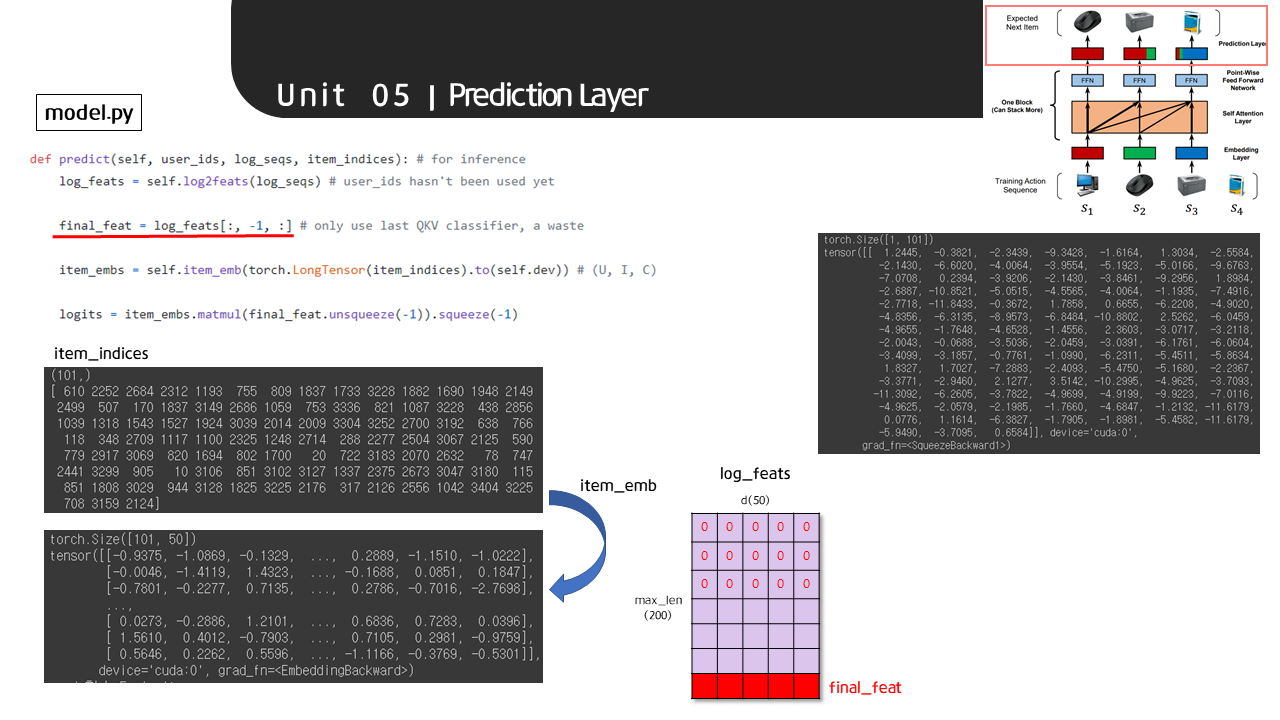 학습이나 추론 과정에서 loss를 구하는 것 외에도 다음 시점에서 관람할 영화를 예측하는 작업을 수행합니다. 유저가 다음에 관람할 영화 ID(ground truth)와 유저가 관람하지 않은 영화 100개로 이루어진 item_indices 벡터를 item embedding layer에 태워
학습이나 추론 과정에서 loss를 구하는 것 외에도 다음 시점에서 관람할 영화를 예측하는 작업을 수행합니다. 유저가 다음에 관람할 영화 ID(ground truth)와 유저가 관람하지 않은 영화 100개로 이루어진 item_indices 벡터를 item embedding layer에 태워 101 x d(50) 차원의 텐서로 변환합니다. 이 텐서를 P-W FFN의 output(purple)에서 마지막 행의 데이터만 추출한 final_feat와 내적 연산을 수행하여 101 x 1 차원의 output을 반환합니다. 해당 벡터에서 가장 높은 값을 가진 인덱스에 해당하는 영화를 유저가 다음 시점에 관람할 영화로 예측하게 됩니다.
이 과정에 해당하는 코드는 model.py에 구현되어 있으며 아래와 같습니다.
def predict(self, user_ids, log_seqs, item_indices): # for inference
log_feats = self.log2feats(log_seqs) # user_ids hasn't been used yet
final_feat = log_feats[:, -1, :] # only use last QKV classifier, a waste
item_embs = self.item_emb(torch.LongTensor(item_indices).to(self.dev)) # (U, I, C)
logits = item_embs.matmul(final_feat.unsqueeze(-1)).squeeze(-1)
return logits # preds # (U, I)Summary

In log2feats function, can you explain the following two code lines? I do not quite understand what is the meaning behind.
timeline_mask = torch.BoolTensor(log_seqs == 0).to(self.dev)
seqs *= ~timeline_mask.unsqueeze(-1) # broadcast in last dim