
작성자 : 투빅스 13기 조혜원
Contents
- How to represent Words' Meaning
- Word2Vec
- Derivations of Gradient
How to represent Words' Meaning
1. WordNet

1) WordNet은 동의어, 상하관계 언어의 집합입니다.
2) 단어 의미 간의 유사도와 관계를 얻기 어렵습니다.
3) 주관적인 판단 기준, 뉘앙스를 파악하기 어렵습니다.
4) 신조어 생성, 관리에 지속적 인력 투입이 필요합니다.
2. One-Hot Vector

1) 단어의 개수가 곧 Vector의 차원으로, Vector의 차원이 아주 많이 필요합니다.
2) 이 역시 단어 간의 관계를 파악하려면 차원이 제곱이 되며 어려워집니다
3. Distributional Semantics

1) 위 두가지의 문제점을 해결한 것으로, 단어의 문맥을 고려한 방법입니다.
2) fixed size window를 통해 단어를 표현할 때 주위(context)를 살펴, 비슷한 문맥에서 나타나는 비슷한 단어들끼리 유사한 벡터를 가집니다.
3) Word Embeddings, Word Representations 라고도 불립니다.
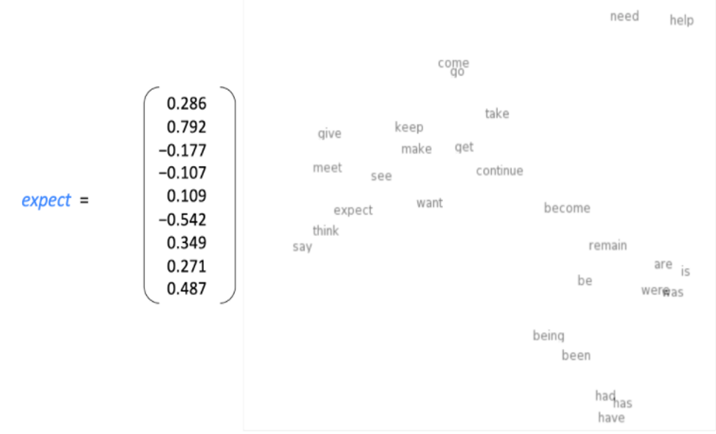
4) Vector space: 각 vector들의 배치를 2D 공간에 투영한 것. 정확히 투영되지는 않지만 유사한 단어가 유사한 위치에 있음을 확인할 수 있습니다.
Word2Vec
- 개념
1) Word Vector을 학습에 쓰이는 프레임워크입니다.
2) 충분한 양의 corpus를 바탕으로, Random Vector에서부터 시작하여 각 단어를 잘 표현하는 Vector 값을 찾습니다.
3) 단어 벡터간의 유사도를 이용해 맥락에서 특정 단어가 나타날 확률을 계산합니다.
- 과정
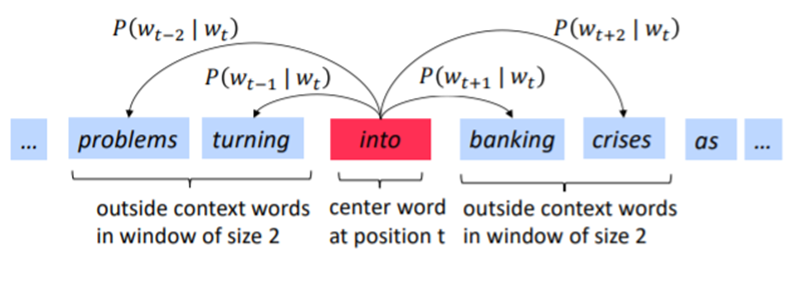
1) 현재 위치 t에 있는 단어를 , 주변에 있는 단어를 , 이라고 할 때 , 를 구합니다.
2) , 를 최대화하는 vector를 찾습니다.
3) corpus 안의 모든 단어에 대해 1~2를 거칩니다.
- 계산법
1) L(𝜽), Likelihood
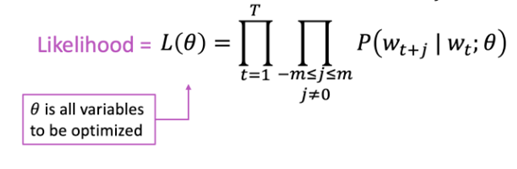
word vector 𝜽(parameter)가 주어졌을 때, window 내의 context word가 해당 위치에 나타날 확률의 곱입니다.
2) J(𝜽), Objective function
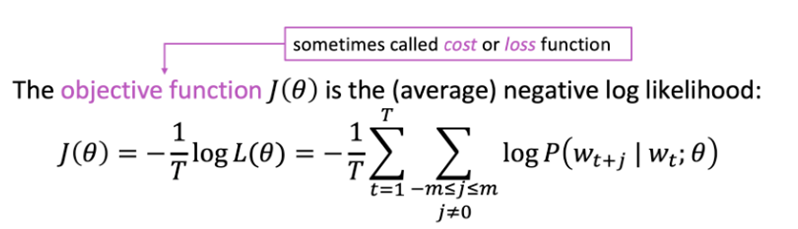
negative log likelihood 를 거쳐 objective function을 만든 후, 이를 최소화 하는 𝜽(parameter)를 구합니다. 이처럼 objective function을 최소화 하는 과정을 통해 predictive accuracy를 최대화할 수 있습니다.
3) P(o|c)
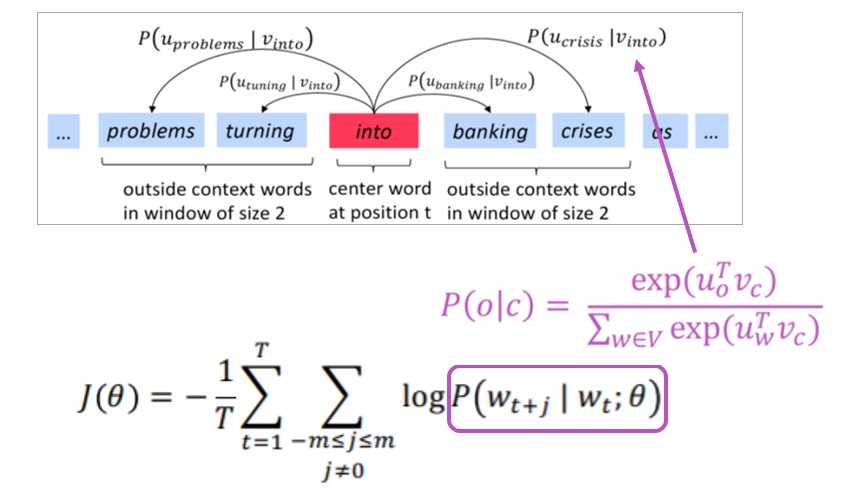
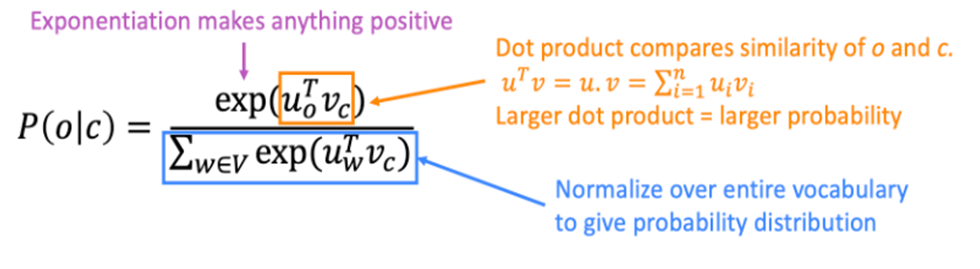
word마다 두개의 vector를 학습하는데 이때 는 x가 center word인 것을 는 x가 context word인 것을 의미합니다. 내적을 통해 유사도를 측정하며, 이후 Softmax 과정을 거쳐 P(o|c)를 구합니다.
- Optimization
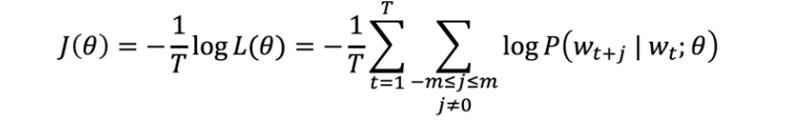
Optimization을 통해 목적함수를 최소화 하는 파라미터 𝜽, 즉 u와 v (word를 나타내는 두 vector)를 찾습니다.
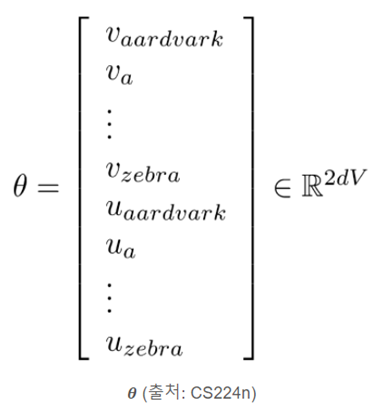
V개의 단어가 존재하고 𝜽가 d-dimension vector일 때, word vector는 u, v를 포함하므로 2dV 차원을 갖습니다.
- 종류
1) Skip Gram: center word로 context word를 예측합니다.
2) CBOW: context word로 center word를 예측합니다.
Derivations of Gradient
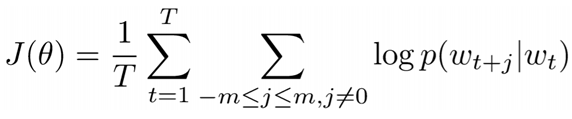
목적함수의 최소값을 구하기 위해
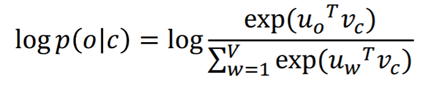
이 식을 center word, context word로 각각 미분합니다.
아래는 미분 과정입니다.
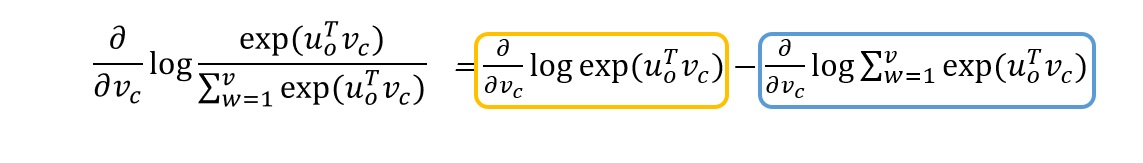
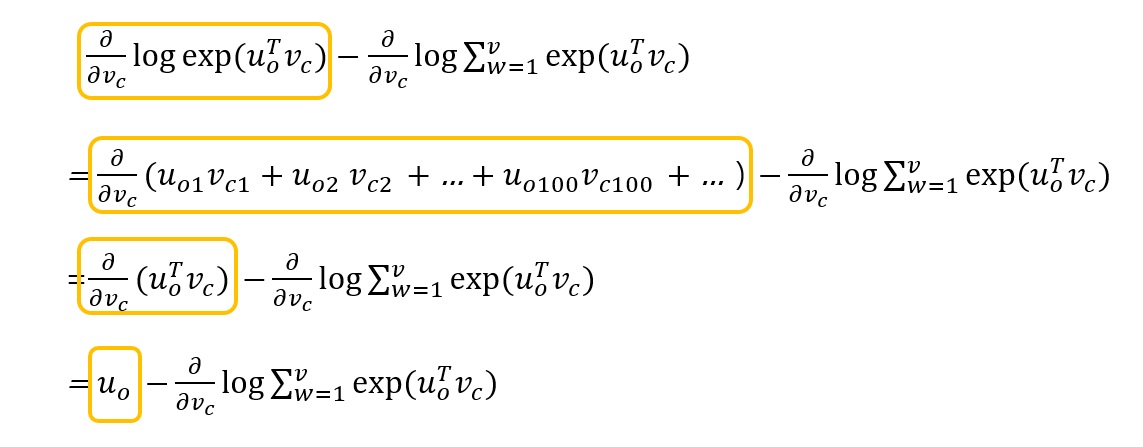
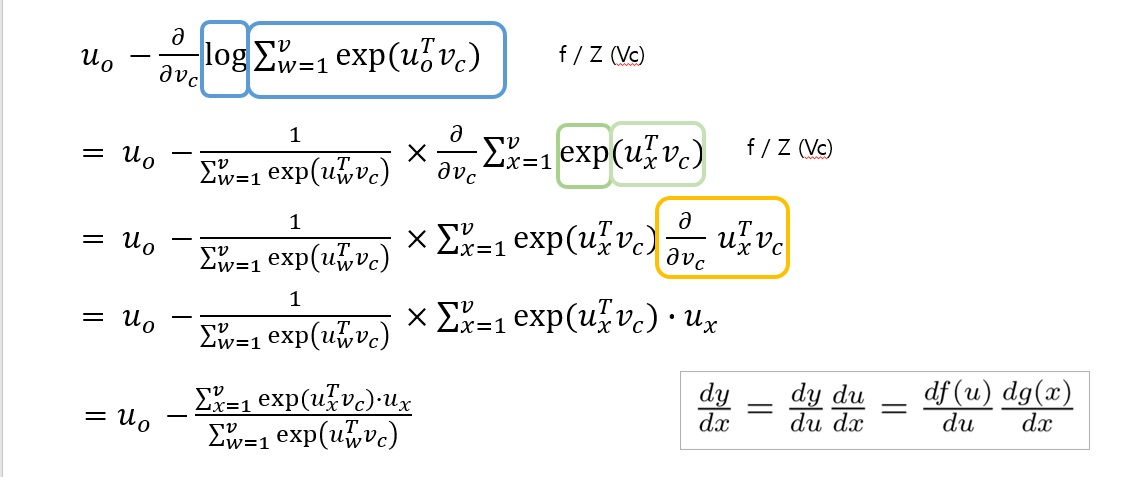

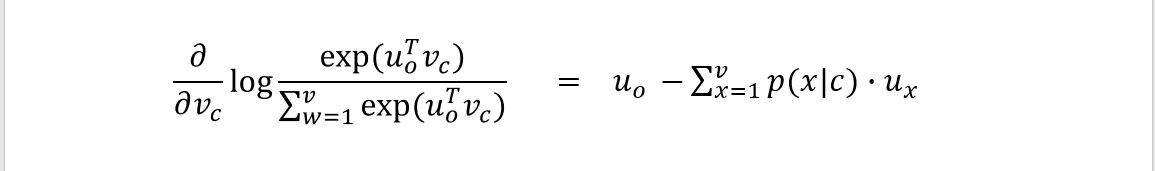
이처럼 목적함수를 편미분한 것은 실제 단어와 예측한 단어와의 차이와 같습니다. 따라서 gradient descent를 통해 실제에 더 가깝게 예측할 수 있음을 알 수 있습니다.
자료 출처: CS224n 2019 - lecture01(wordvec1) slides (https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture01-wordvecs1.pdf)
