
작성자 : 투빅스 14기 이혜린
Contents
- Word2vec
- Co-occurrence matrix
- GloVe
- Evaluation
1. Word2Vec
텍스트 모델의 핵심은 텍스트를 컴퓨터가 인식할 수 있도록 숫자 형태의 벡터 또는 행렬로 변환하는 것입니다. 이 과정은 대표적으로 두 가지 방식으로 이루어집니다.
- One Hot Encoding (Sparse representation)
- Word Embedding (Dense representation)
One Hot Encoding은 단어 벡터가 0 또는 1의 값으로 구성되어 과정이 단순하다는 장점이 있지만, 텍스트 분석에서 중요한 부분 중 하나인 단어 간의 유사성을 반영하지 못한다는 단점이 존재했습니다.
이를 보완하는 방법으로 Word Embedding이 등장하게 되었고, 현대의 대부분의 자연어 처리 기법들은 (ex. Word2vec, GloVe, FastText…) Word Embedding 방식을 기반으로 발전하였습니다.
본 강의에서는 앞 강의에서 다뤘던 단어 임베딩 방식을 기반으로 한 자연어 처리 기법인 Word2vec을 간단하게 리뷰한 후, 강의를 이어나갈 예정입니다.
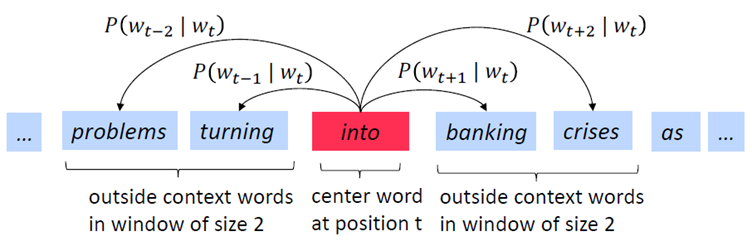
위 그림은 Word2vec의 전체적인 과정을 잘 보여주는 그림입니다. 주요 feature로는 중심 단어(center word), 맥락 단어(context word), 그리고 윈도우(window)가 있습니다. 의미적으로 유사성을 가진 단어들은 서로 가까운 위치에 존재한다는 아이디어를 이용하여, 중심 단어를 기준으로 양쪽으로 윈도우 크기만큼의 단어를 맥락 단어로 설정합니다. 그리고 원-핫 인코딩을 이용해 중심 단어 벡터와 맥락 단어 벡터를 생성한 후, 이를 입력 벡터와 출력 벡터로 사용합니다. 맥락 벡터는 기본적으로 윈도우 개수의 2배만큼 생성됩니다.
이 때 맥락 벡터가 입력, 중심 벡터가 출력인 경우를 CBOW 방식, 그리고 중심 벡터가 입력, 맥락 벡터가 출력인 경우를 Skip-gram 방식이라고 합니다.
1) CBOW (Continuous Bag of Words)
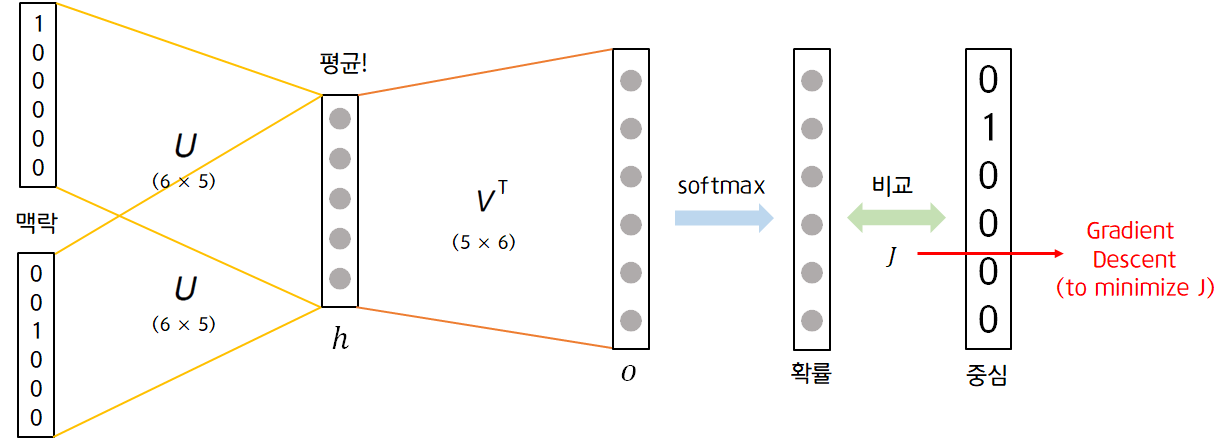
CBOW 방식은 입력 벡터가 맥락 벡터, 출력 벡터가 중심 벡터입니다. 여기서 입력 벡터는 맥락 벡터이기 때문에 입력 벡터의 수도 윈도우 크기의 2배입니다.
맥락 벡터와 hidden layer 사이에 있는 가중치 와 입력 벡터인 맥락 벡터를 곱하면 여러 개의 결과 벡터가 생성되게 되는데, hidden layer에선 이 결과들을 요소별로 평균 내어 hidden layer의 값으로 사용합니다.
또한 중심 벡터 사이에 있는 가중치 와 hidden layer의 벡터를 곱하여 만든 output layer의 벡터에 softmax함수를 적용하여 이 값을 확률 값으로 만든 후, 중심 벡터와 비교하여 모델의 Loss를 계산합니다. Loss를 최소화하는 모델을 구하기 위해 Gradient Descent를 이용하여 가중치를 계속적으로 업데이트 합니다.
2) Skip-gram
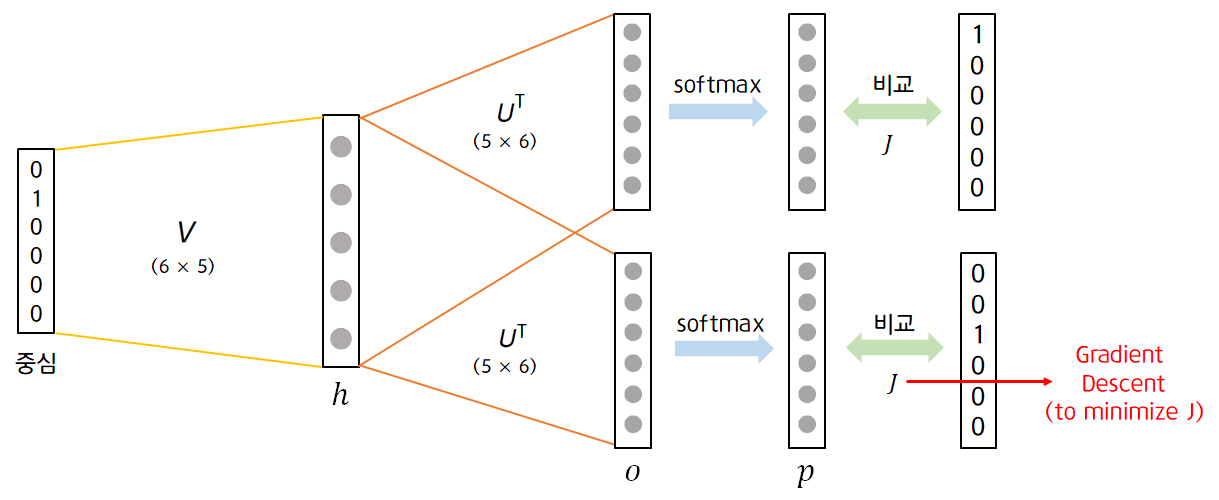
Skip-gram 방식은 입력 벡터가 맥락 벡터, 출력 벡터가 중심 벡터입니다. 여기서 출력 벡터는 맥락 벡터이기 때문에 출력 벡터의 수도 윈도우 크기의 2배입니다. 본 게시물에서는 Word2vec Skip-gram을 기반으로 설명을 이어나가도록 하겠습니다.
3) Word2vec의 효율성을 높이는 법
- Stochastic Gradient Descent
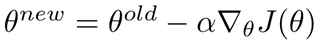
앞서 Loss를 최소화하는 Parameter(, )를 찾기 위해 Gradient Descent를 사용한다고 말씀드렸습니다. 허나 Gradient Descent는 전체 데이터에 대해 계산이 이루어지기 때문에 계산량이 너무 많다는 단점이 있습니다. 그래서 많은 사람들은 대신 Stochastic Gradient Descent (또는 mini-batch) 를 사용하기도 합니다.
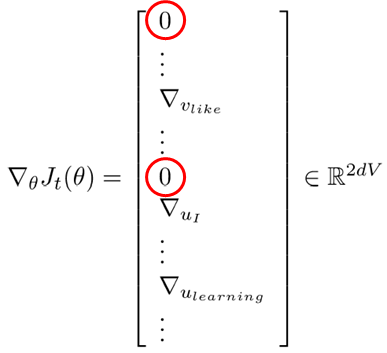
하지만 One-Hot Encoding, 혹은 Word2vec의 입·출력 벡터로 사용되는 0과 1으로 이루어진 Sparse한 vector는 이처럼 stochastic gradient descent를 사용했을 때 문제가 발생합니다. 0에 해당되는 위치에서는 계산이 이루어지더라도 계속해서 0이기 때문에 실제로 gradient가 update되지 않는데, 불필요하게 계산이 이루어지기 때문입니다.
- Negative Sampling
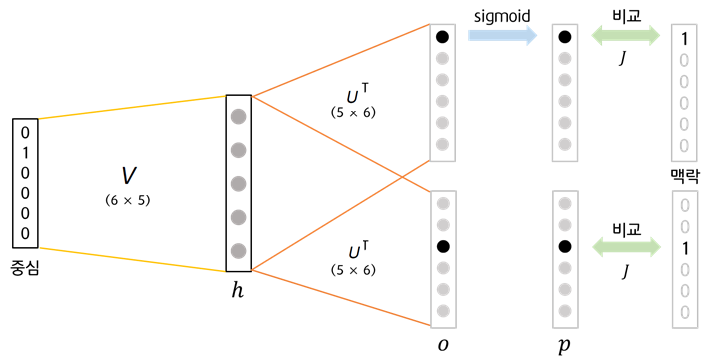
Skip-gram을 예시로 Negative Sampling을 설명하도록 하겠습니다. 앞서 말씀드렸던 것처럼 word2vec을 사용할 때 sparsity로 인한 문제는 계속해서 발생합니다. Negative Sampling은 이를 해결하기 위해 실제로 등장한 (=값이 0이 아닌) 행에 대해서만 gradient 계산하고 sparse한 matrix를 add, subtract 함으로써 gradient를 update하는 방식을 채택합니다. 이는 기존의 다중분류를 이진분류로 근사시켜 모델을 효율적으로 만드는 데에 기여합니다.
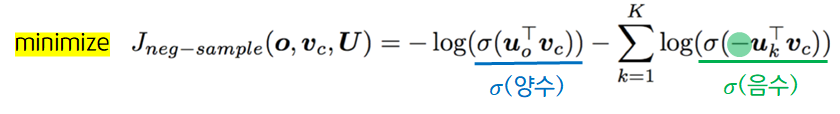
다음은 negative sampling의 목적함수 입니다.
: 중심 벡터
: 맥락 벡터
: 노이즈 벡터 (랜덤하게 선택된 벡터. 실제 맥락벡터가 아님.)
: 중심 벡터와 hidden layer 사이의 가중치
: 맥락 벡터와 hidden layer 사이의 가중치
는 중심 벡터와 맥락 벡터간 코사인 유사도를 의미합니다. 이를 이용하여 위 목적함수를 해석해보면 True pair (중심 벡터, 맥락 벡터)의 경우 코사인 유사도가 클수록 확률이 높고, Noise pair (중심 벡터, 맥락 벡터)의 경우 코사인 유사도가 작을수록 확률이 높다고 해석할 수 있습니다.
즉 True pair는 중심 벡터와 맥락 벡터가 가까이 있을수록(코사인 유사도가 클수록) 손실이 0에 가깝고, Noise pair는 중심 벡터와 노이즈 벡터가 멀리 있을수록(코사인 유사도가 작을수록) 손실이 0에 가까움을 의미합니다. 이는 이치에 맞는 해석이라고 판단할 수 있습니다.
- Subsampling Frequent words
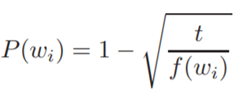
Subsampling frequent words는 등장빈도가 클수록 업데이트 될 기회가 많으므로, 말뭉치에서 자주 등장하는 단어는 학습량을 확률적으로 감소시키는 기법입니다. 여기서 는 해당 단어 빈도 / 전체 단어 수 , 즉 단어가 corpus에 등장한 비율을 의미합니다.
2. Co-occurrence matrix
Skip-gram은 중심 단어를 기준으로 맥락 단어가 등장할 확률을 계산합니다. 그러므로 윈도우 개수를 아무리 크게 늘려도, global co-occurrence statistics (ex. 전체 단어의 동반출현 빈도수)와 같은 통계 정보는 내포할 수 없습니다. 벡터의 값들은 중심 단어가 given일 때 각 값의 개별적인 등장 확률을 의미하기 때문입니다. 그래서 등장한 것이 count-based의 Co-occurrence matrix입니다.
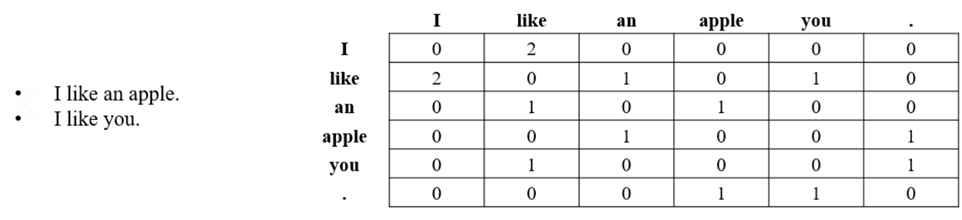
1) Window based co-occurrence matrix (단어-문맥 행렬)
word2vec과 비슷한 방식입니다. 한 문장을 기준으로 윈도우에 각 단어가 몇 번 등장하는 지를 세어 구성합니다. Syntatic (POS; post (noun) post office (noun) other synonyms), semantic 정보를 얻을 수 있습니다.
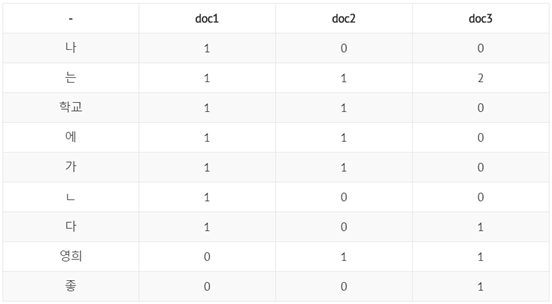
2) Word-Document matrix (단어-문서 행렬)
한 문서를 기준으로 각 단어가 몇 번 등장하는 지를 세어 구성합니다. 문서에 있는 많은 단어들 중 빈번하게 등장하는 특정 단어가 존재한다는 것을 전제합니다. LSA (Latent Semantic Analysis; 잠재적 의미 분석)를 가능하게 하는 기법입니다. (ex. 문서 간 유사도 측정 등)
그러나 이와 같은 count-based matrix는 단어의 개수가 증가할수록 차원이 폭발적으로 증가합니다. 그래서 SVD 또는 LSA 등을 이용하여 차원을 축소시킨 후 사용합니다. 이는 대부분의 정보를 작은 차원의 행렬안에 포함시킬 수 있는 결과를 낳습니다.
3) SVD (Singular Value Decomposition; 특이값 분해)
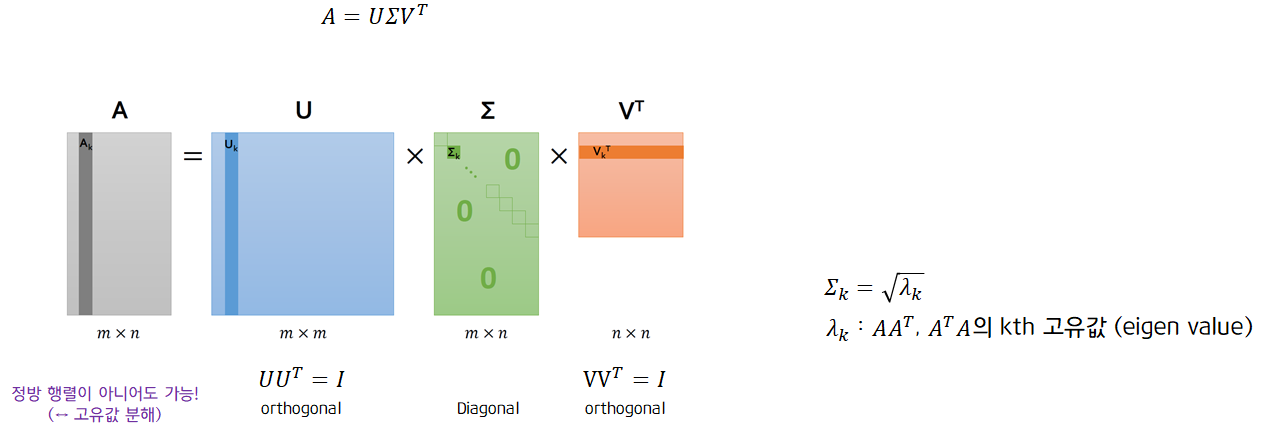
특이값 분해는 다음과 같이 행렬을 분해합니다. 고유값 분해와 비슷해보이지만 다른 점은 특이값 분해는 분해할 행렬이 정방 행렬이 아니여도 분해 가능하다는 점에서 차이점을 가집니다.
특이값 분해를 실제 데이터에 적용해봄으로써 분해 후 정보를 어떻게 활용할 수 있는지 확인해보겠습니다.
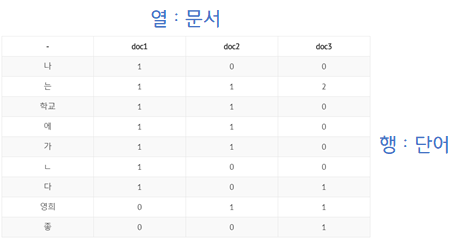
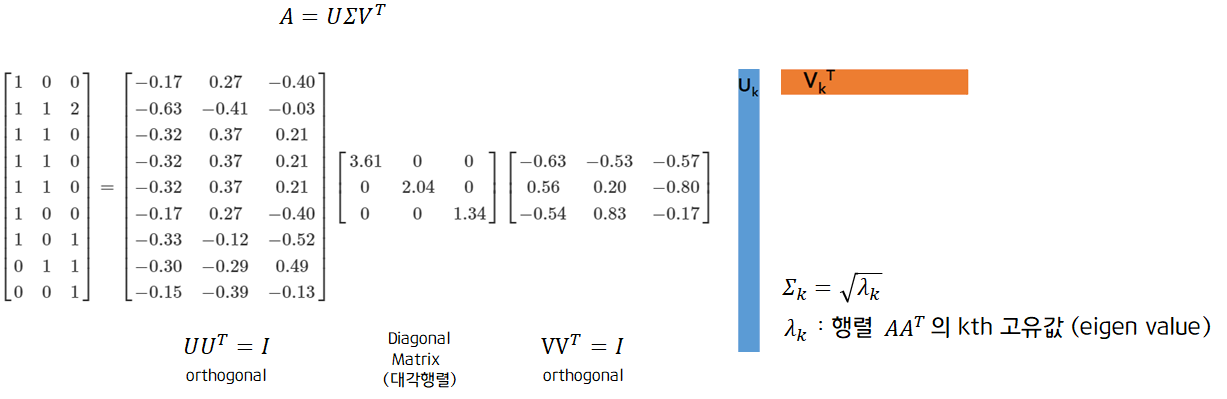
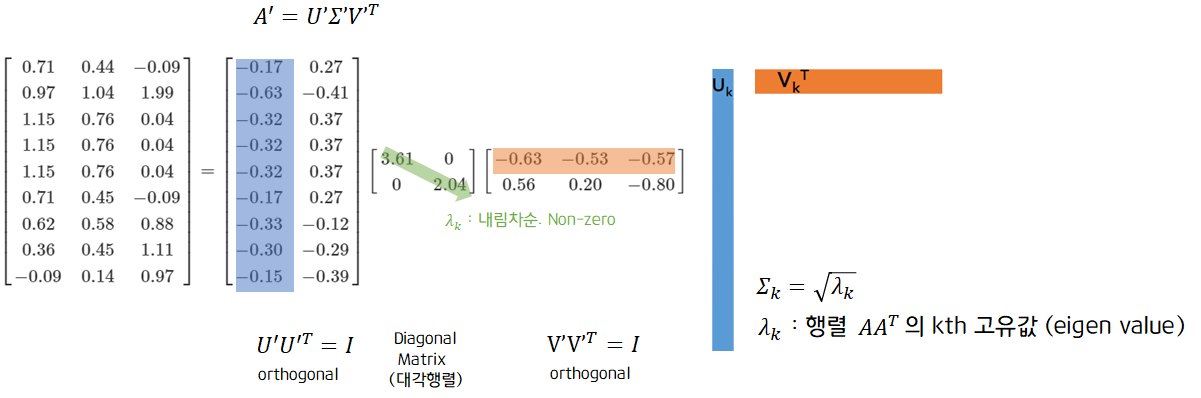
특이값 분해를 적용한 후, 에서 상위 2개의 열벡터만을 선택하여 새로운 를 만들어내고 본 데이터인 를 를 만들어낸 것을 truncated SVD라고 합니다. 이 결과를 통해 문서(열)를 기준으로 한 새로운 벡터 와 단어(행)을 기준으로 한 새로운 벡터 를 생성할 수 있습니다.
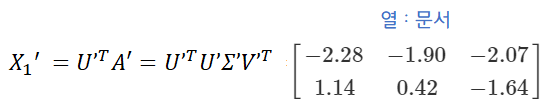
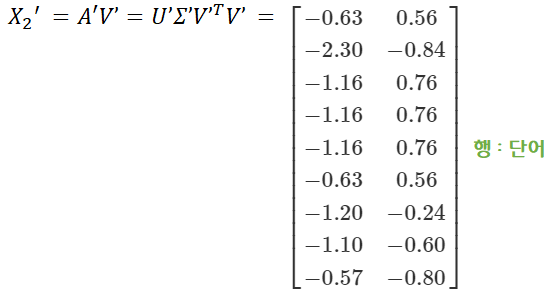
이렇게 동시등장행렬(co-occurrence matrix)를 단어 또는 문서를 기준으로 차원을 축소한 후 각 기준별로 잠재적인 의미를 분석하는 방법을 LSA라고 합니다. 이렇게 동시등장행렬을 SVD, LSA 등의 기법을 통해 차원축소 한 후 분석하는 방법을 실제 데이터를 이용하여 확인해볼 수 있었습니다.
3. GloVe (Global Vectors for Word Representation)
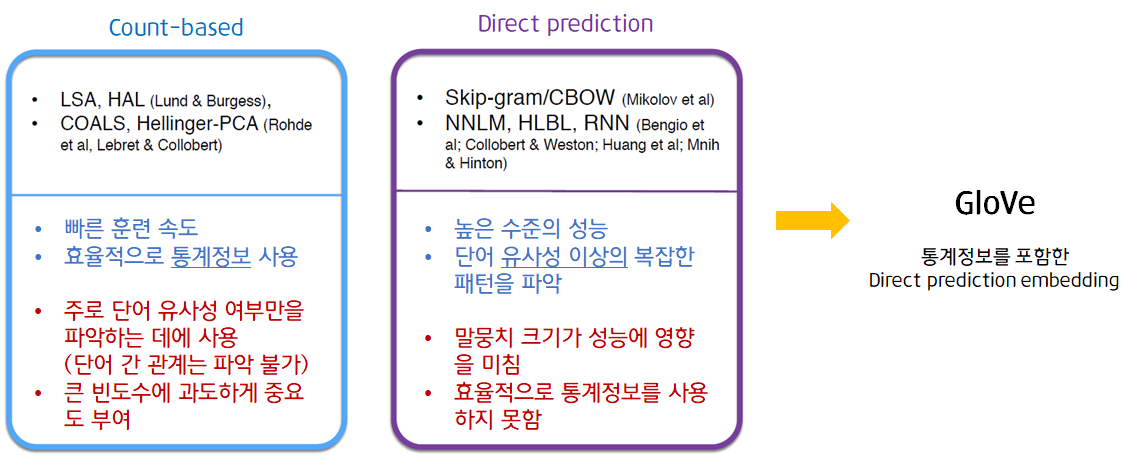
지금까지 Count-based 기법과 Direct prediction 기법에 해당되는 여러가지 방법들을 살펴보았습니다. 각 방법은 뚜렷한 장단점이 존재하였고, 각 기법들의 장점만을 갖춘 새로운 방법이 등장하였는데 이것이 바로 GloVe입니다.
Glove의 기본 아이디어는 다음과 같습니다.
- 임베딩된 단어벡터 간 유사도 측정을 수월하게 하면서 (word2vec의 장점)
- 말뭉치 전체의 통계 정보를 반영하자! (co-occurrence matrix의 장점!)
또한 GloVe의 목적함수를 도출하기 위한 주요 인사이트는 다음과 같습니다.
- 임베딩된 두 단어벡터의 내적이 말뭉치 전체에서의 동시 등장확률 로그값이 되도록 목적함수를 정의
; 전체 말뭉치 중 사용자가 정한 window 내에, 번째 단어와 번째 단어가 동시에 등장하는 횟수
= ; 전체 말뭉치 중 사용자가 정한 window 내에, i번째 단어가 등장하는 횟수
= 𝑃(𝑘│𝑖) = ; 번째 단어 (context word) 주변에 번째 단어가 등장할 조건부 확률

위처럼 계산한 동시 발생 확률들을 가지고 목적함수를 도출해보도록 하겠습니다.
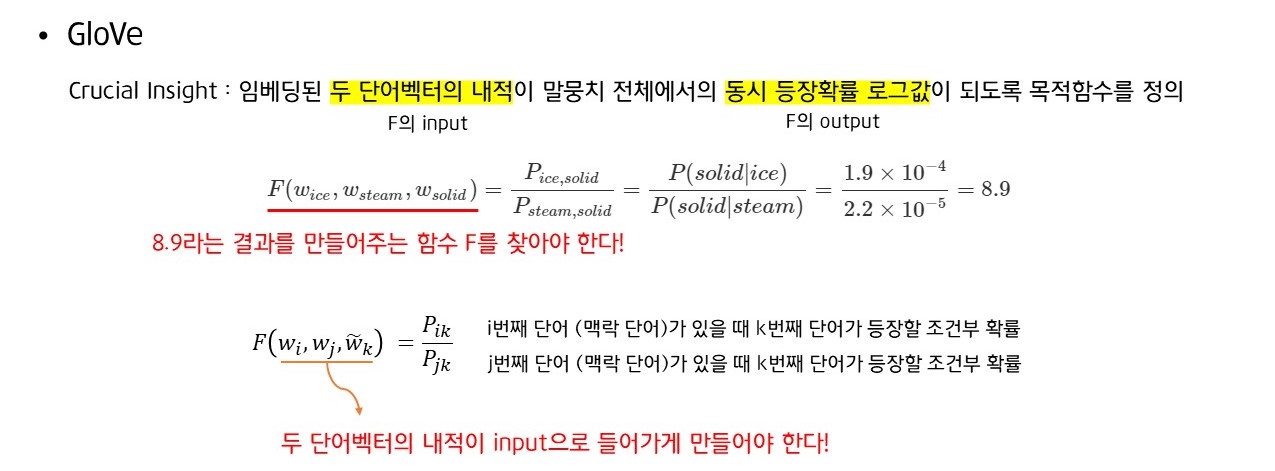
동시 발생 확률의 비를 라는 함수의 결과값이라고 생각하면 다음과 같이 표현할 수 있습니다. 이 때 input은 단어 벡터 3개로 구성되어 있지만, 두 단어벡터의 내적이 input으로 들어가야 하므로 다음과 같이 식을 정의합니다.

이처럼 동시 발생 확률의 비를 두 맥락 단어벡터의 차와 중심 벡터의 내적값으로 변환하여 단어 벡터 스페이스 내에 선형으로 표현하게 되었습니다. 즉 우리가 첫번째로 해내야했던 조건인 "input은 두 단어벡터의 내적"을 만족하게 된 것입니다.

동시 발생 확률을 함수에 대한 식으로 다시 정의했을 때 함수 의 조건식을 도출할 수 있고, 이 조건에 맞는 함수 는 지수함수임을 알 수 있습니다.

위 식의 좌변을 두 단어벡터의 내적값으로 두면 우변은 가 됩니다. 그리고 처음 input값이었던 co-occurrence matrix가 준동형()형을 만족하기 때문에 함수 F의 결과 또한 준동형을 만족해야 하는데, 실제 값을 계산해보면 그렇지 않으므로 이를 보정하기 위해 상수항 을 더해줍니다.

그 결과 라는 식을 도출할 수 있고 이 때 좌변은 unknown parameter로 이루어진 추정값, 그리고 우변은 실제값이라고 할 수 있습니다. 즉 좌변과 우변의 차이에 제곱을 취한 값이 바로 GloVe의 손실함수입니다.

또한 특정 단어가 지나치게 빈도수가 높아 가 튀는 현상을 방지하기 위해 함수를 손실에 곱함으로써 최종적으로 손실 함수를 완성시켰습니다.
GloVe는 속도가 빠르며, 말뭉치 크기가 성능에 미치는 영향을 제한할 수 있으며, 그렇기 때문에 작은 말뭉치나 작은 벡터에서도 좋은 성능을 가진다는 장점이 있습니다.
Results
GloVe 모델을 여러 데이터에 적용한 결과를 보여드리도록 하겠습니다.
- Frog

이처럼 frog와 형태적으로 또는 의미적으로 비슷한 단어를 잘 선택합니다.
- opposite
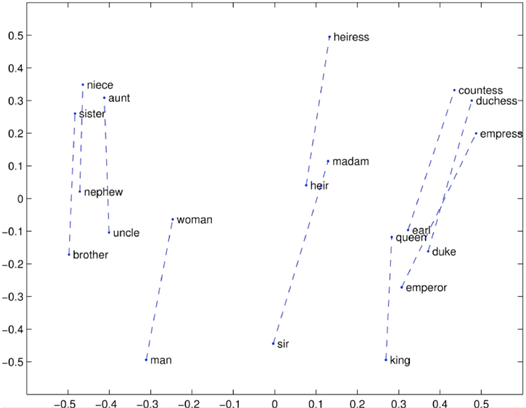
반의어 관계에 있는 여러 단어쌍들이 비슷한 간격으로 2차원의 공간 내에 위치하고 있음을 볼 수 있습니다. (brother와 sister간 거리, 그리고 uncle과 aunt간 거리가 비슷합니다.)
- company - CEO
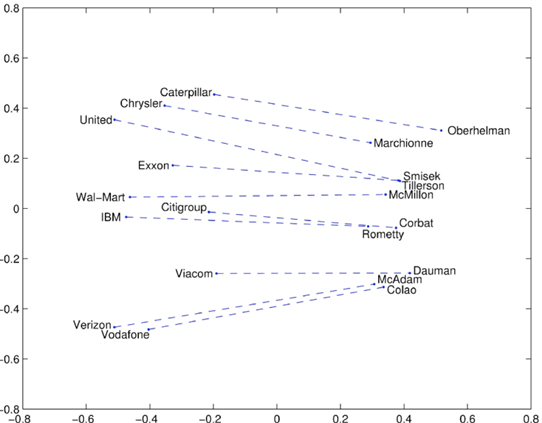
company 집단에 속하는 단어는 좌측에, CEO 집단에 속하는 단어는 우측에 몰려있음을 볼 수 있습니다. 또한 company단어와 CEO단어의 거리는 각 쌍마다 비슷합니다.
- superlatives
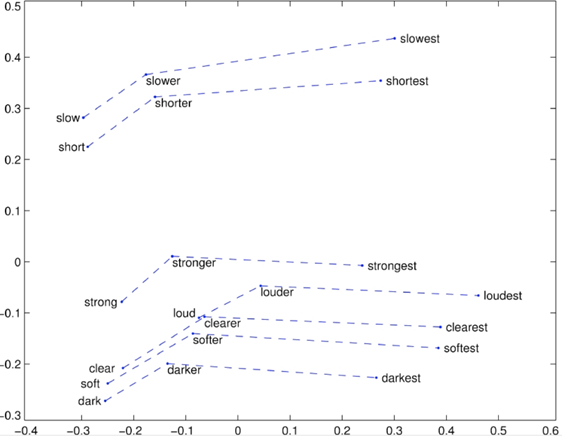
단어의 원형 - 비교급 - 최상급을 2차원 공간에 표현한 후 선을 그어 이었을 때의 형태는 유사합니다.
+ FastText, ELMo
추가적으로 Word2vec, GloVe 외의 단어 임베딩 모델을 소개해드리도록 하겠습니다.
1) FastText (2016)
- word2vec과 유사합니다. But 그러나 단어를 부분 단어(subword)로 표현한다는 차이가 존재합니다.
- word2vec은 단어를 쪼갤 수 없는 것으로 생각하지만, FastText는 하나의 단어도 부분 단어로 쪼갤 수 있다고 생각합니다.
- 학습하지 않은 단어에 대해서 유사한 단어를 찾아낼 수 있습니다.
2) ELMo (2018)
- 단어의 의미는 전에 오는지, 후에 오는지에 따라서도 변화한다는 특성을 반영한 모델입니다.
- 전체 문장을 한 번 훑고, 문장 전체를 고려한 word embedding을 진행
같은 단어라도 문맥에 따라 뜻이 달라지는 동적인 모델입니다. - 다의어로 인한 어려움을 해결할 수 있습니다.
4. Word embedding Evaluation
단어 임베딩 모델에 대한 설명은 끝났습니다. 이제는 이런 단어 임베딩 모델들을 어떤 방식으로 평가할 수 있는지 설명하려 합니다.
우선 내적 평가와 외적 평가의 정의와 내용은 다음과 같습니다.
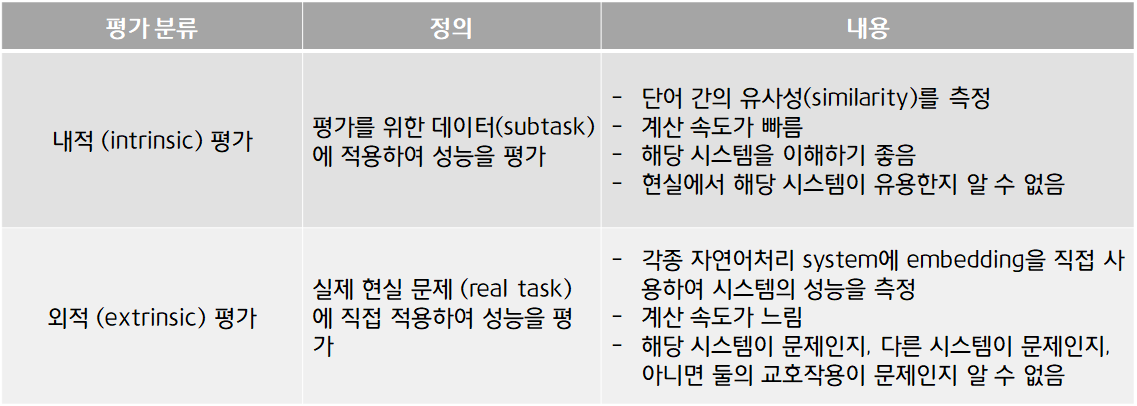
1) Extrinsic Evaluation
실제 현실 문제 (real task)에 직접 적용하여 성능을 평가하는 방식입니다. Glove는 외적 평가에서 좋은 성능을 보입니다.
2) Intrinsic Evaluation : word analogy
analogy는 유사를 의미합니다. 즉 a:b :: c:? 에서 ?에 들어갈 단어를 유추하는 문제입니다. ex. man:woman :: king:?
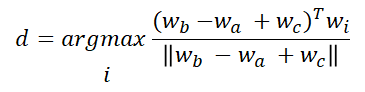
식으로 표현하면 다음식을 만족하는 d를 찾는 문제라고 얘기할 수 있습니다.
내적 평가의 예는 다음과 같습니다.
- Semantic examples : city-state
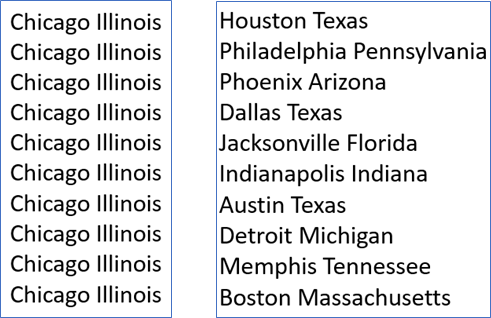
하나의 도시가 여러 개의 이름을 갖는 경우 적절히 임베딩하기 어렵습니다. (semantic은 단어의 의미적인 부분을 의미합니다.)
- Syntactic examples : gram4-supelative

syntatic은 단어의 순서적인 부분을 의미합니다.
- several models
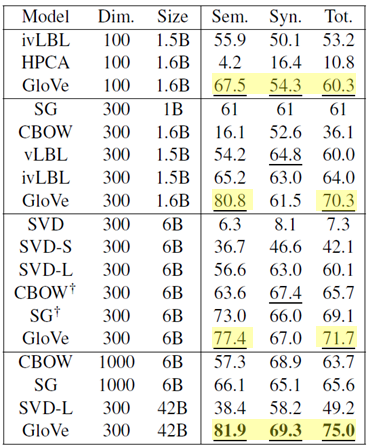
Dimension, corpus size 등을 다르게 하면서 여러 임베딩 모델에 대해서 analogy 분석을 진행해본 결과, GloVe는 좋은 성능을 보였습니다.
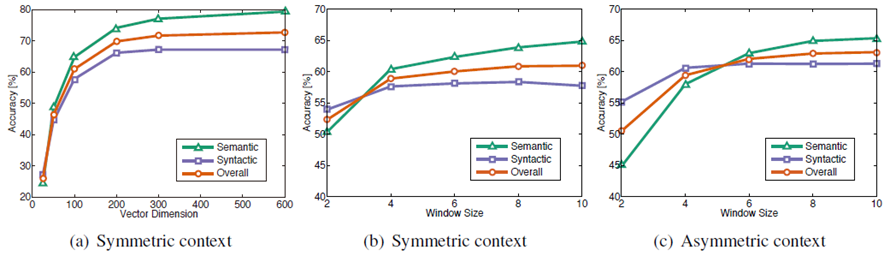
a. symmetric : window가 양방향 ; asymmetric : window가 중심단어 기준 왼쪽
b. window size가 10개일 때, dimension은 300으로 두는 게 accuracy가 best입니다.
c. 맥락 단어를 중심 단어기준 양방향에서 찾았을 때 성능이 더 좋습니다. (왼쪽에서만 찾으면 성능이 좋지 않습니다.)
d. (b) (c) : dimension이 100일 때, window size는 8개가 best입니다.
- over-parametrization
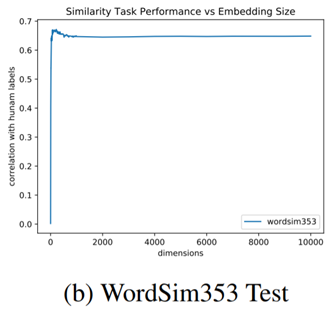
GloVe는 dimension이 크게 증가해도 모델 성능이 크게 떨어지지 않는다는 장점이 존재했습니다.
- bias-variance trade-off in dimensionality

a. PIP Loss : 단어 임베딩 사이의 dissimilarity를 나타내는 지표
b. p% sub-optimal interval : dimension이 k이고, k가 interval 안에 존재하면, k차원 임베딩의 PIP loss는 최적 임베딩에 비해 p% 커지는 것을 의미합니다.
- Training Time
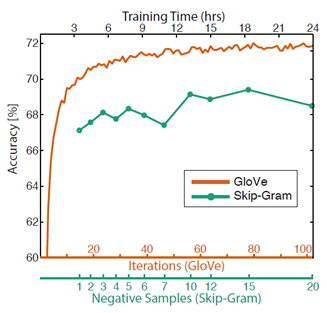
훈련을 오래시킬수록 성능이 향상했습니다.
- Informations in Text
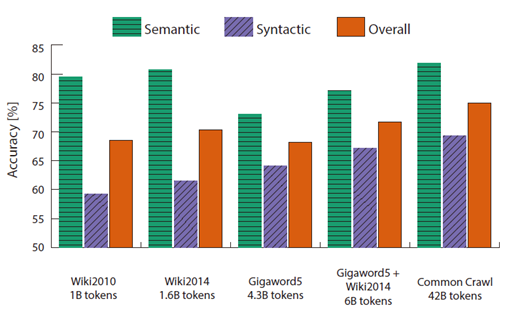
a. Gigawords는 article, Wiki는 일종의 dictionary입니다.
b. 텍스트 내에 정보가 많은 Wiki data를 활용했을 때 성능이 좋음
3) Intrinsic Evaluation : Correlation
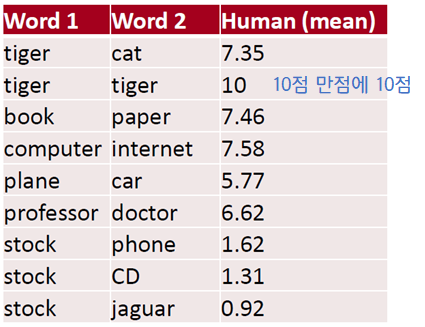
일련의 단어 쌍을 미리 구성한 후에 사람이 평가한 점수와, 단어 벡터 간 코사인 유사도 사이의 상관관계를 계산해 단어 임베딩의 품질을 평가하는 방식입니다.
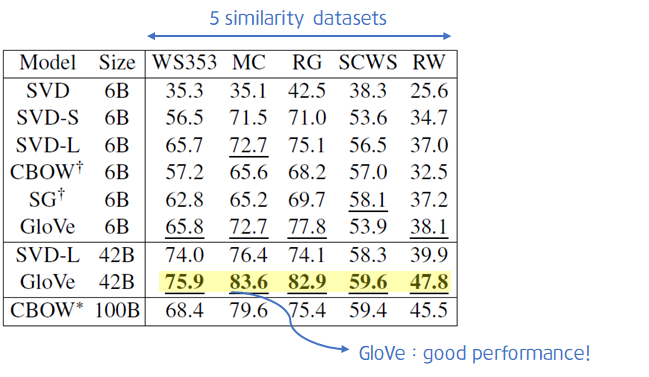
이 때 GloVe는 좋은 성능을 가집니다.
4) Word senses and word sense ambiguity

다의어를 해결하는 방법은 다음과 같습니다.
Sol1. Improving Word Representations Via Global Context And Multiple Word Prototypes (Huang et al. 2012)
Sol2. Linear Algebraic Structure of Word Senses, with Applications to Polysemy (Arora, …, Ma, …, TACL 2018)
- Sol1. Improving Word Representations Via Global Context And Multiple Word Prototypes (Huang et al. 2012)

특정 단어의 윈도우들을 클러스터링 (ex. bank1, bank2, bank3 …) 한 후, 단어들을 bank1, bank2, bank3 를 중심으로 다시 임베딩합니다.
- Sol2. Linear Algebraic Structure of Word Senses, with Applications to Polysemy (Arora, …, Ma, …, TACL 2018)
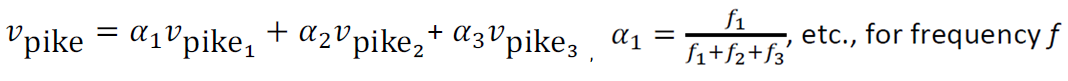
각 의미에 가중치를 부여하고 선형결합을 통해 새로운 단어 벡터를 생성합니다. 이 단어벡터를 가지고 유사 단어들 끼리 clstering 했을 때 상당히 결과가 좋았습니다. 즉 내적인 의미까지 잘 파악해서 분류했음을 의미합니다.
