
작성자 : 투빅스 13기 최혜빈
Contents
- Vanishing gradient problem
- LSTM
- GRU
- More fancy RNN variants
Vanishing gradient problem
Remark) Backpropagation for RNNs
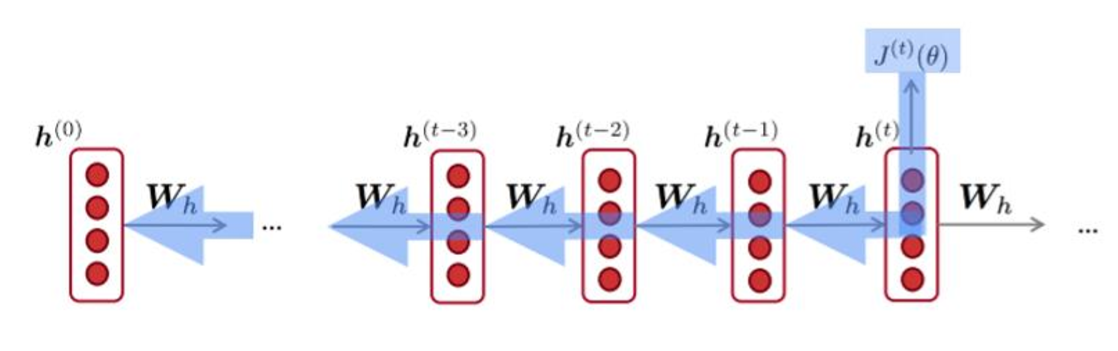
RNN 네트워크를 학습하는 것은 기존의 backpropagation과는 살짝 다른 BPTT를 사용합니다.
RNN의 recurrent한 부분을 시간에 대해 펼쳐서 forward pass로 activation 값을 내고, target과의 차이로 error를 계산하고, 이 error를 각 node로 편미분함으로써 backpropagation을 진행합니다.

BPTT에서 중요한 점은 각 레이어마다의 weight가 동일한 weight이어야 하므로 모든 update가 동일하게 이루어져야 한다는 점입니다.
다시 말해, 각 레이어마다 동일한 위치의 weight에 해당하는 모든 error 미분값을 다 더한 다음, 그 값을 backpropagation하여 weight를 한 번 업데이는 하는 방법이 RNN에서의 BPTT라고 합니다.
1. Vanishing gradient intuition
- Gradient Problem : RNN backpropagation 시 gradient가 너무 작아지거나, 반대로 너무 커져서 학습이 제대로 이뤄지지 않는 문제
수식으로 자세히 살펴보겠습니다.
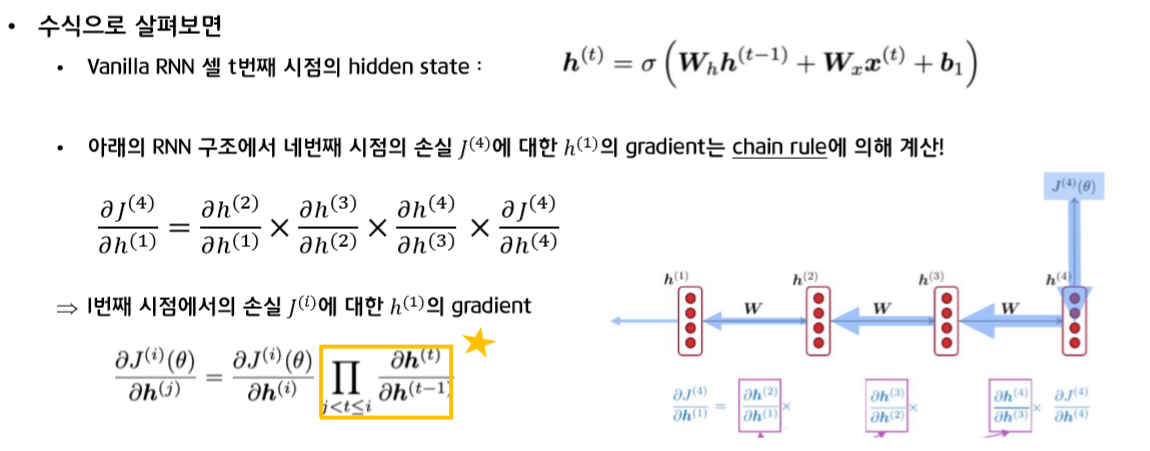
RNN cell의 t번째 시점의 hidden state는 직전 시점의 hidden state와 t시점의 입력값 x값을 받아 갱신이 됩니다.
위 그림의 오른쪽 부분을 보면, 4번째 시점의 loss값에 대한 h1의 gradient는 chain rule에 의해 계산됩니다. 즉, 파란색 화살표에 해당하는 gradient를 순차적으로 곱한 값이 됩니다.
이 식을 일반화하여 i번째 시점의 손실에 대한 j번째 hidden state의 gradient를 표현하면 다음과 같이 되고, 노란색 박스 부분이 우리가 주목해야 할 부분입니다.
chain rule에 의해 graient가 "계속 곱해지면서 이 값(노란색 부분)이 커지는가 작아지는가"가 중요한 문제가 됩니다.

t번째 시점에서의 hidden state의 정의를 이용해서 t번째 hidden sate에 대한 t-1번째 hidden state의 gradient를 정의하면 다음과 같습니다.

위에서 구한 정의를 이용하여 대입하면 다음과 같이 되고, 이 식은 norm의 성질에 의해 부등식이 성립하게 됩니다.
부등식의 의미 : matrix의 L2 norm이 결국 의 가장 큰 eigenvalue값이라는 것
- 부등식을 통해, RNN 역전파 시 chain rule에 의해 지속적으로 곱해짐으로써 완성되는 i번째 시점에서의 손실에 대한 hidden state의 gradient의 L2 norm은 절대적으로 의 L2 norm의 크기에 달려있다는 것을 확인할 수 있습니다
- 의 가장 큰 고유값이 1보다 작다면, 1보다 작은 값이 계속해서 곱해지는 것이기 때문에 gradient가 빠르게 사라져버리는 문제가 발생하는 것입니다. = Vanishing gradient problem !!
+) backpropagation과 관련한 gradient 문제와 별개로 activation function의 종류에 따라 vanishing gradient문제가 발생하기도 합니다
2. Why is vanishing gradient a problem?
gradient의 값이 매우 작아지는 현상이 RNN에 어떤 문제를 발생시킬까요?
1) 파라미터들이 가까이 위치한 dependency에 맞게 학습을 하고, 멀리 떨어진 dependency에 대해서는 학습을 하지 못하게 됩니다.
- 다시말해, weight는 long-term effects보다 near effects에 관해 update됩니다.
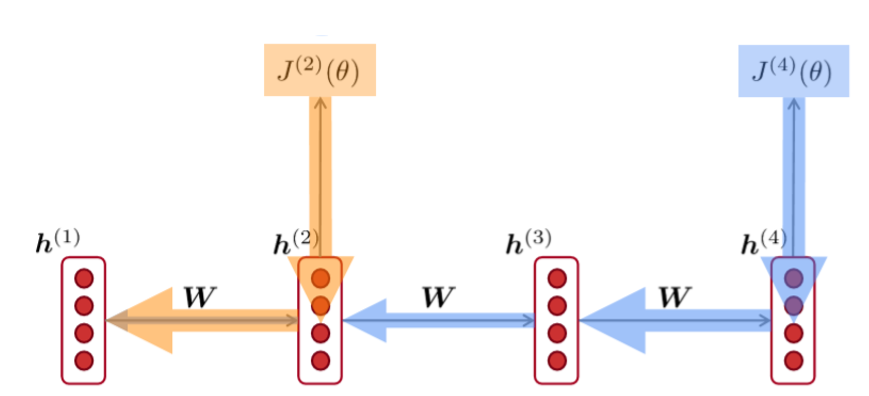
2) Gradient는 미래에 과거가 얼마나 영향을 미치는지에 대한 척도.
- gradient값이 너무 작아져서 0에 가까워져 소실되어 버리는 경우, 결과적으로 판단하기에 이 값이 <정말로 미래에 과거가 영향을 미치지 않아서 gradient값이 0이 된건지>, <파라미터 값이 잘못 설정되어서 gradient가 0으로 소실되어 버린건지> 구분할 수 없습니다.
3. Effect of vanishing gradient on RNN-LM
강의자료에 있던 실제 language model task에 적용하는 경우 발생하는 문제의 예시를 살펴보면,
Ex 1)

긴 문장이 input으로 들어왔을 때, 마지막에 올 단어가 ticket이라는 것을 첫번 째 줄의 ticket으로 유추할 수 있지만, "vanishing gradient" 문제로 멀리 떨어진 단어들과의 dependency를 학습하지 못하게 되고, ticket이 아닌 가까이 있는 printer로 잘못 유추해버리는 예시입니다.
Ex 2)

이 예시도 역시, writer와의 dependency를 학습하지 못하고 are이라는 잘못된 결과를 제공하는 예시입니다.
+ Exploding gradient problem
vanishing gradient 문제 말고도, exploding gradient 문제도 존재합니다.
이 문제를 Gradient clipping이라는 방법으로 간단히 해결할 수 있습니다.
Gradient Clipping
- gradient가 일정 threshold를 넘어가면 gradient값의 L2 norm값으로 나눠주는 방식
- 쉽게 말해, 파라미터를 update할 때, gradient가 정상적인 값보다 너무 크다고 판단되었을 때, scale down을 해주는 방법

+ Is vanishing/exploding gradient just a RNN problem?
Q. RNN에서의 gradient문제는 RNN만의 문제일까요?
A. 당연히 아닙니다. 이 문제는 feed-forward, convolutional을 포함한 모든 NN에서의 문제로, 대부분의 domain에서, backpropagation을 할 때 점점 gradient가 작아져 lower layer에서는 update가 잘 되지 않아 학습하기 어려운 문제가 발생합니다.
gradient vanishing 문제를 해결하는 몇몇 방법을 살펴보면,
1) Residual connections "ResNet"
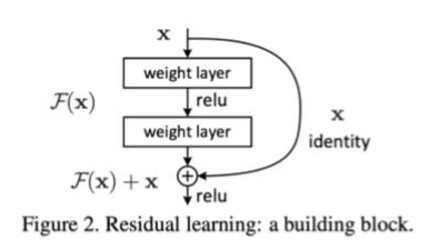
- =skip-connections
- input x 에 convolutional layer을 지나고 나온 결과를 더해줌으로써, 과거의 내용을 기억할 수 있도록 합니다.
- 과거의 학습 내용 보존 + 추가적으로 학습하는 정보 => gradient 사라지는 문제 해결
2) Dense connections "DenseNet"
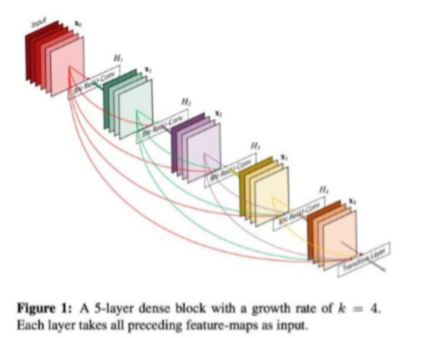
- 이전 layer들의 feature map을 계속해서 다음 layer의 입력과 연결하는 방식
- +) ResNet과 비교
ResNet : feature map끼리 '더하기'를 해주는 방식
DenseNet: feature map끼리 'Concatenation' 시키는 방식
3) Highway connections "HighwayNet"
- Residual connections과 비슷
- T: transform gate, C: carry gate => output이 input에 대해 얼마나 변환되고 옮겨졌는지 표현함으로써 해결하는 방식 (LSTM에서 영감을 받은 모델!)
이처럼 Vanishing gradient문제는 여러 분야에서 매우 general한 문제이지만, 특히 RNN과 같이 동일한 weight matrix를 반복적으로 곱하는 모델은 특히 더 불안정하므로, 더욱 심각한 문제라고 할 수 있습니다. 다음으로 이를 해결하기 위해 제시된 모델인 LSTM, GRU 모델을 살펴보겠습니다.
LSTM
LSTM(Long Short-Term Memory)
: RNN의 vanishing gradient문제로 발생하는 장기 의존성 문제를 해결하기 위해 RNN에서 메모리를 분리하여 따로 정보를 저장함으로써 한참 전의 데이터도 함께 고려하여 output을 만들어내는 모델
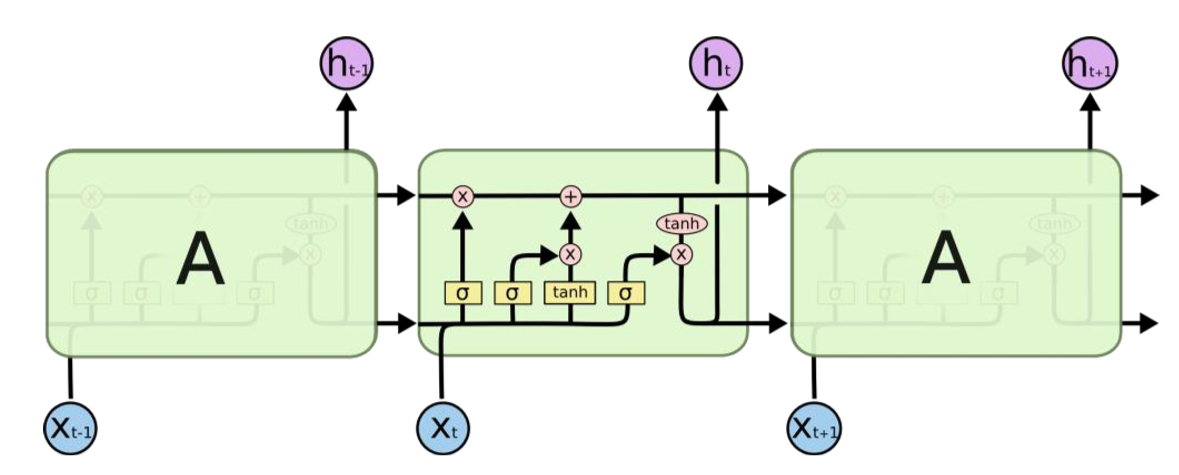
LSTM의 핵심 아이디어
- 이전 단계의 정보를 memory cell에 저장해서 흘려보내는 것 => cell state
- 현재 시점의 정보를 바탕으로 과거의 내용을 얼마나 잊을 지 곱해주고, 그 결과에 현재 정보를 더해서 다음 시점으로 정보를 전달하는 것
Cell state
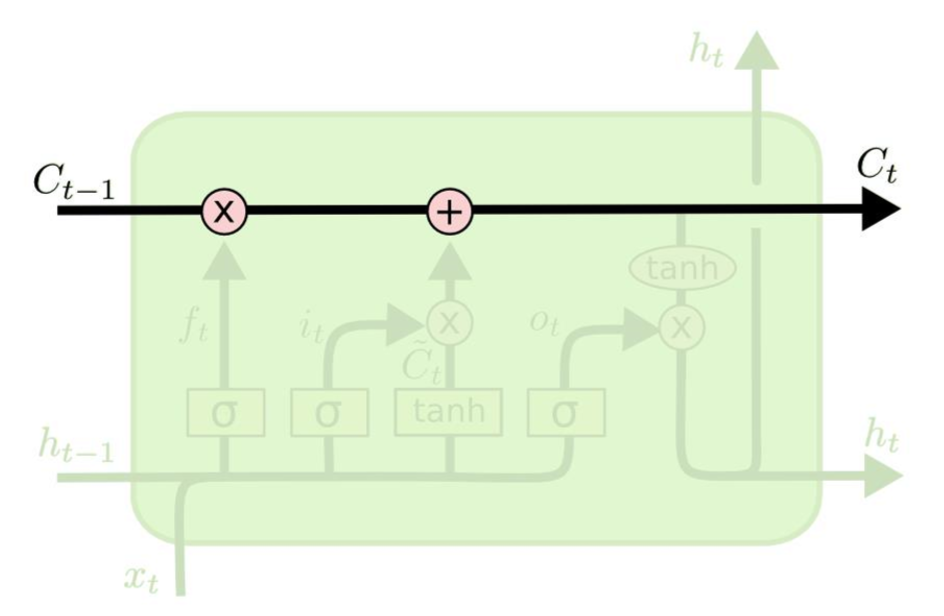
- LSTM의 핵심적인 부분
- cell state는 input, forget, output 세 개의 gate들을 이용하여 정보의 반영여부를 결정합니다.
각각 세개의 gate는 어느 정보를 쓰고, 읽고, 잊을 것인지를 결정하는데, 이를 단계별로 살펴보겠습니다.
LSTM 단계
1) Forget gate layer
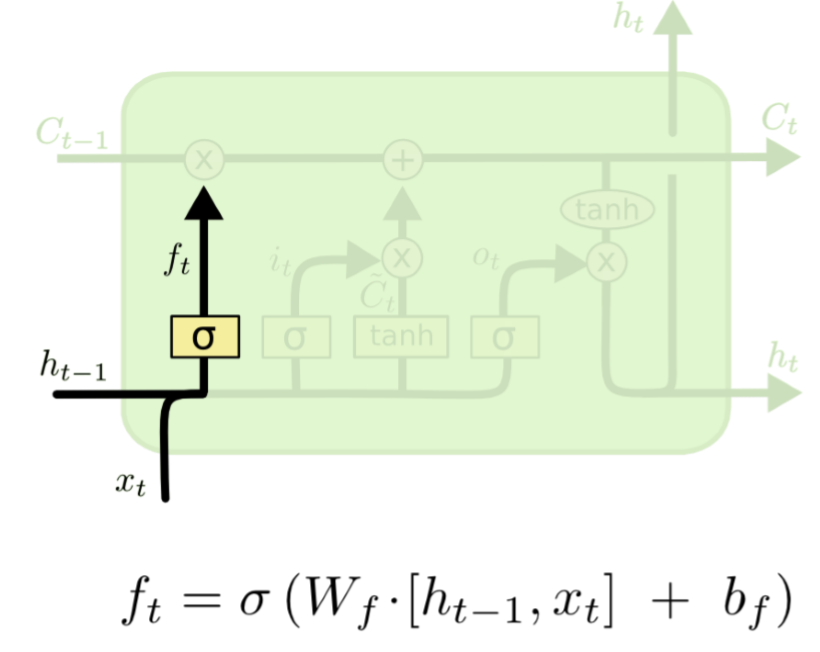
forget gate : 어떤 정보를 잊고 어떤 정보를 반영할지에 대한 결정을 하는 gate
- t번째 시점에서의 x값과 t-1시점에서의 hidden state를 입력값으로 받아 sigmoid activation function을 통해 0에서 1사이의 값을 출력합니다.
- 출력한 값이 만약 0에 가깝게 나온다면 불필요한 정보들을 다 지워버린다는 것이고, 1에 가까울수록 이 정보에 대해 반영을 많이 한다는 의미입니다.
2) input gate layer
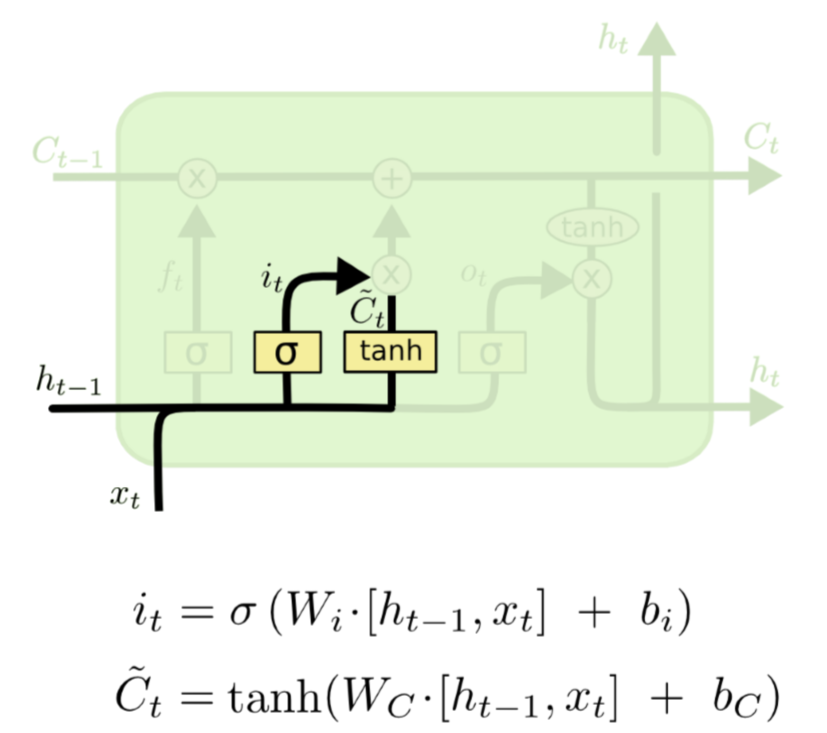
input gate: 새로운 정보가 cell state에 저장될지를 결정하는 gate
- forget gate와 마찬가지로, input으로 와 를 받습니다.
- 두 layer가 존재하는데,
- input gate : sigmoid 함수에 의해 0에서 1사이의 값으로 출력하는 부분 -> 현재의 정보를 반영할 지를 결정합니다
- update gate: cell state에 더해질 후보값들의 벡터를 만드는 layer
결국은, 이 두 gate에서의 output값이 곱해짐으로써 현재의 정보를 반영할 것인지를 결정합니다.
3) Update Cell state
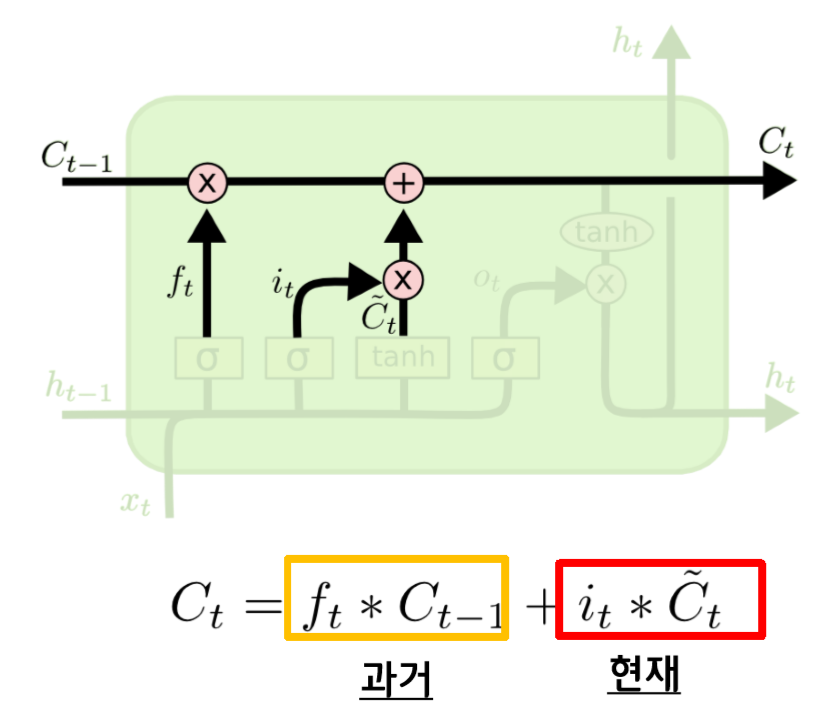
최종적으로는 과거의 정보는 삭제될 것인지, 유지될 것인지를 forget gate를 통해 결정하고, 현재 input 값이 반영되는지 안되는지는 input gate에서 결정이 됩니다.
이 두 값이 더해져서 다음 cell state의 입력값으로 들어가게 되고, 이렇게 cell state가 update 됩니다.
4) Output Gate Layer
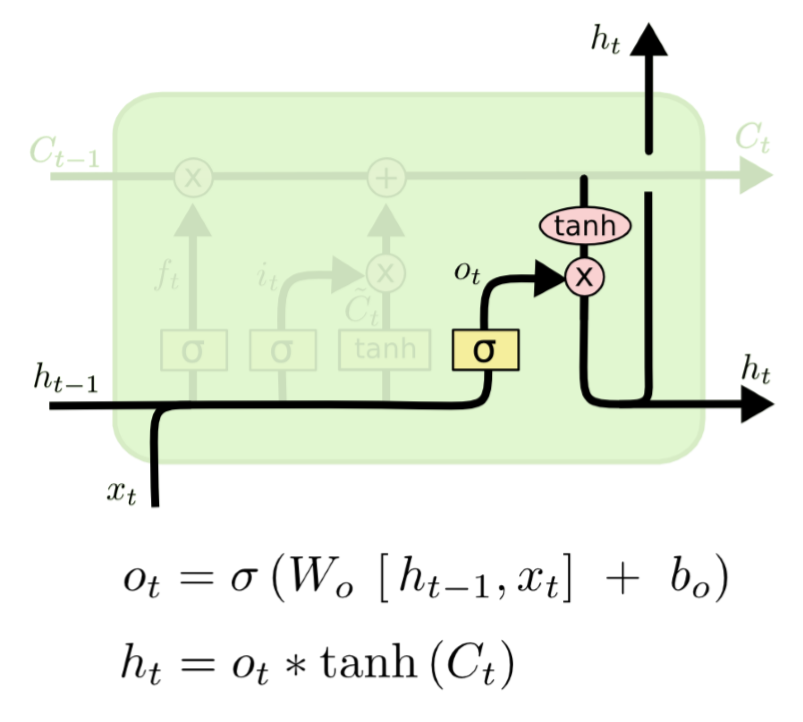
마지막으로, 출력값을 반환하는 Output gate가 존재하고, 최종 output은 cell state를 바탕으로 필터링을 한 값이 됩니다.
- 먼저 sigmoid 함수에 input들이 들어가 0에서 1사이의 값을 출력합니다 -> cell state의 어느 부분을 output으로 내보낼지를 결정합니다
- 다음, cell state가 tanh에 들어가서 나온 출력값과 output gate에서 나온 값이 곱해져서 t시점에서의 hidden state가 나오게 됩니다. -> 최종 output 값 & 다음 state의 input값!
=> LSTM
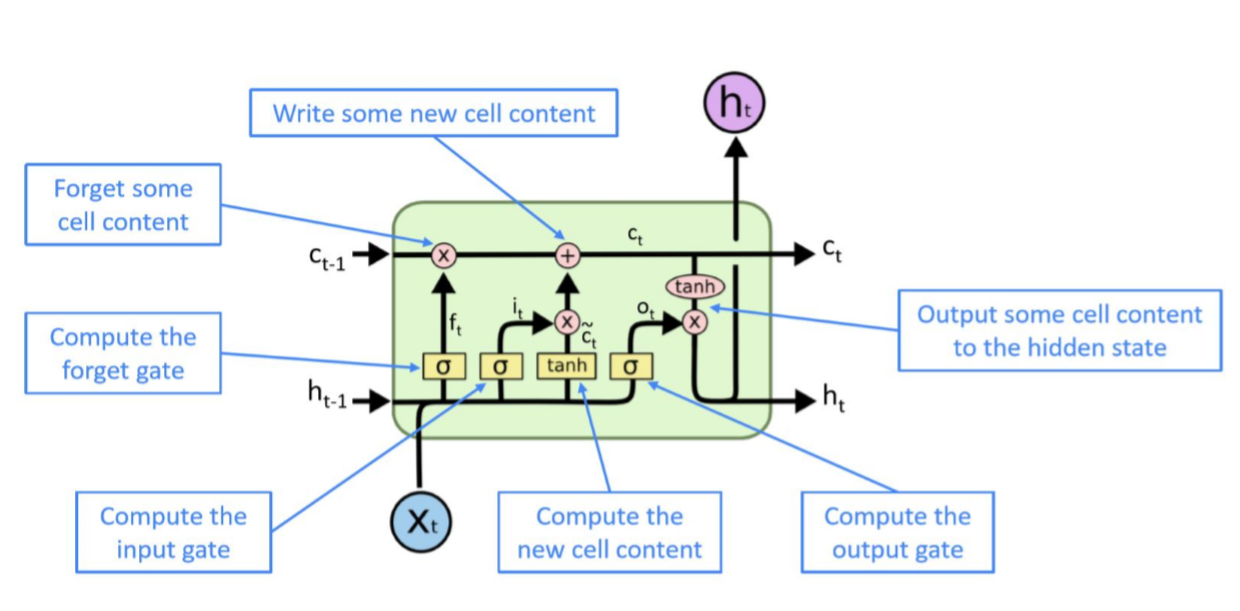
정리된 그림을 살펴보면 다음과 같습니다.
이 때, 1) 모든 state와 gate는 길이가 n인 벡터이고, 2) 모든 gate는 sigmoid를 통과해서 0과 1사이의 숫자로 나오고, 3) lstm은 전 hidden state와 현재 input context를 기반으로 계산되므로 dynamic한 모델입니다.
How does LSTM solve vanishing gradients?
이 LSTM이 어떻게 gradient vanishing 문제를 해결했는지를 간단하게 수식으로 생각해보면,
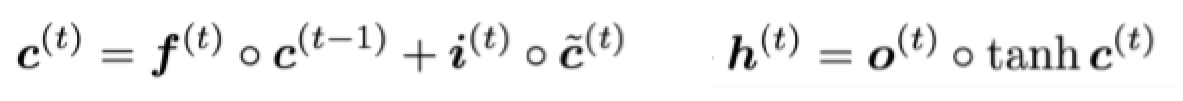
만약 forget gate가 1로 설정, input gate가 0으로 설정하면, t시점에서의 cell state는 이전의 정보가 완전히 보존되는 채로 hidden state를 update하기 때문에 cell의 정보가 완전하게 보존될 것입니다. => 장기 의존성 문제 해결!!
+) 하지만, LSTM도 vanishing/exploding gradient문제가 아예 없다고 보장할 수 는 없다고 합니다.😥
GRU
GRU(Gated Recurrent Units)
: LSTM의 강점을 가져오되, 불필요한 복잡성을 제거한 모델
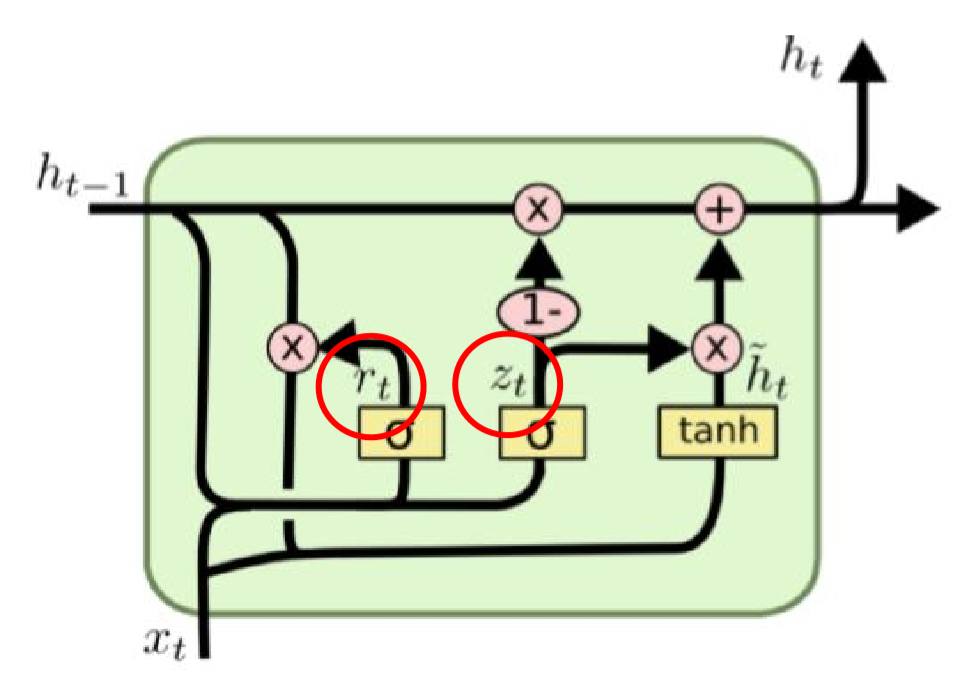
- 매 time step t마다 input 과 hidden state 는 있지만, cell state는 존재하지 않고, 사실상 hidden state에 합쳐집니다.
- 이 모델도 LSTM처럼 gate들을 통해서 정보의 흐름을 통제하는데, update gate와 reset gate가 있습니다. 각각을 수식과 함께 살펴보면 다음과 같습니다.

GRU 단계
전체적인 수식으로 순서를 이해해보면,
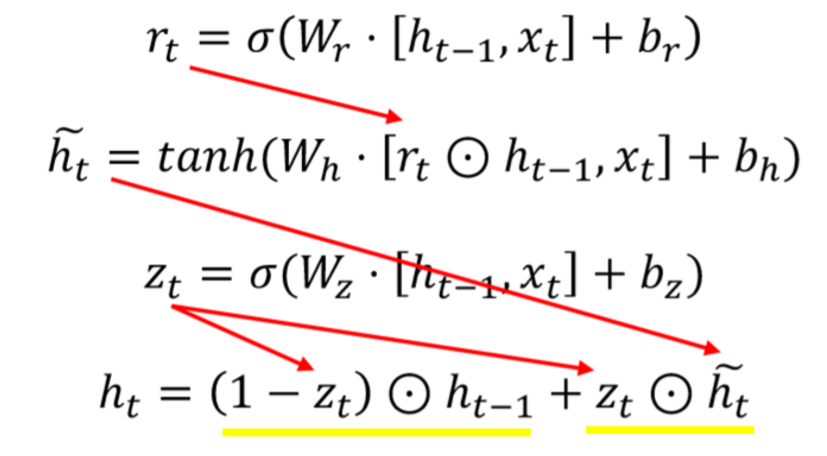
1. 먼저 reset gate를 통해 임시적인 hidden state를 만들고,
->직전의 hidden state에 곱함으로써 직전의 hidden state값을 그대로 이용하지 않고 reset을 해서 이 값과, 현시점의 x값을 통해 현시점의 candidate를 계산합니다
2. update gate를 통해 구한 현시점과 과거 시점의 정보양 비율을 결정하고,
3. 에 이전 hidden state값을 곱하고 에 현시점의 candidate값을 곱해서 최종 hidden state를 계산합니다.
+) GRU도 LSTM과 비슷한 방식으로 확인해보면, update gate로부터 나온 값을 0으로 설정하면 이전 hidden state state의 값이 계속 보존된다는 의미로, gradient vanishing 문제를 어느정도 해결했다고 볼 수 있습니다.
More fancy RNN variants
Bidirectional RNNs
Bidirectional RNN : left, right 두 방향으로 모두 정보를 이용하기 위한 방법
- 분리된 weight를 가지고 있는 forward RNN과 backward RNN을 학습한 후 각 hidden state를 concat해서 최종적인 representation을 형성합니다.
- forward RNN : 정방향으로 입력받아 hidden state 생성 / backward RNN: 역방향으로 입력받아 hidden state 생성 -> 두 hidden state 연결해서 전체 모델의 hidden state로 사용!

Multi-layer RNNS
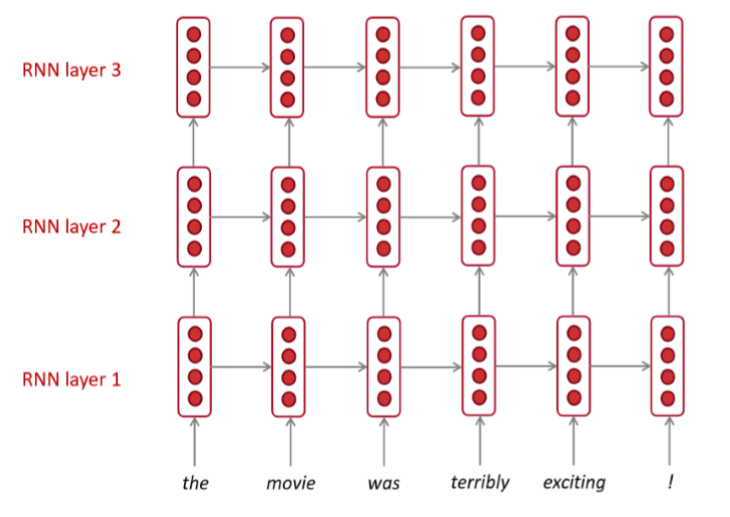
Multi-layer RNN : RNN을 여러층으로 사용한 모델
- 여러 개의 층으로 구성된 RNN은 더 복잡한 특성을 학습할 수 있습니다
- lower RNN에서는 lower level의 feature들을, higher RNN에서는 higher level의 feature들을 학습할 수 있습니다
+) 보통 2~4개 정도의 layer을 쌓는다고 합니다.
Reference
- Stanford CS224n Lecture 7 강의 & 강의자료
- 13-14기 정규세션 13기 이예지님 모델심화2 강의자료
- https://excelsior-cjh.tistory.com/89
- https://ratsgo.github.io/deep%20learning/2017/10/10/RNNsty/
- https://jeongukjae.github.io/posts/cs224n-lecture-7-vanishing-gradients-fancy-rnns/
- https://yjjo.tistory.com/18?category=881892
