
작성자 : 투빅스 14기 고경태
Contents
- Machine Translation
- Sequence to sequence
- Neural technique: Attention

목차의 흐름은 전 목차 주제에서의 한계점을 극복하고 발전하는 방향으로 진행됩니다. 즉, 기계 번역의 한계를 RNN을 이용한 sequence to sequenc모델이 극복 해주고, sequence to sequenc의 가장 큰 한계점인 병목현상을 극복 해주는 방법인 Attention모델을 설명하는 방식으로 강의가 진행됩니다.
1. Machine Translation

Machine translation 이란 말 그대로 기계를 통해 번역을 하는 문제입니다. 정확히 말하면 어떤 언어의 input sentence를 다른 언어의 output sentence로 만드는 task입니다. 기계번역은 시대에 따라서 번역을 하는 방법이 계속해서 바뀌어 왔는데, 어떤 방식으로 진행해 왔는지 알아보겠습니다.

Machine Translation이 처음 나온 것은 1950년대입니다. 시대적으로 기계번역이 나온 역사적 이유가 있습니다. 이 시기는 냉전 시기로 소련과 미국은 항상 서로의 통신이나 기밀 문서들을 자동으로 번역해서 해석하기를 원했는데, 이를 위해 Machine Translation이 처음 도입된 것입니다. 따라서 이 당시의 machine translation은 주로 영어, 러시아어 번역이 대부분이었습니다.
그리고 이 당시의 번역은 주로 rule-based 방식이었습니다. 즉 두 개의 언어의 사전을 통해 각 단어가 대응되는 것을 찾아서 번역하는 가장 단순한 방식이라고 합니다.
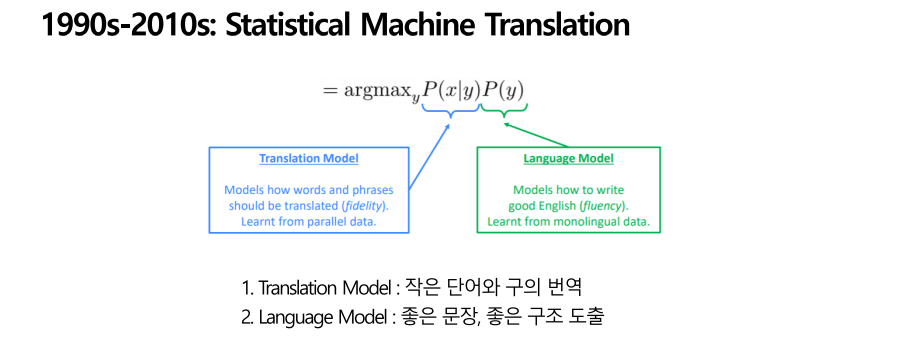
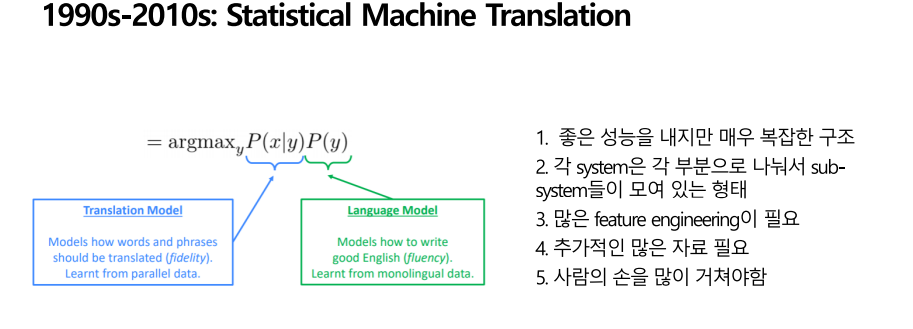
기존의 rule-based 방식이 아닌 data를 통해서 번역하는 방식이 처음으로 사용되었습니다. 이때의 방식을 통계적 기계번역이라 부르는데, 데이터를 통해 확률 분포를 학습하는 방법입니다. 데이터를 통해 확률을 가장 높이는 방법으로 번역합니다. 즉 특정 언어 input sentnece x에 대해서 또 다른 언어 output sentence인 y로 번역할 때 다음의 확률이 가장 높은 sentence를 선택하게 됩니다. 그리고 실제로 사용할 때는 위의 수식을 bayes theorem을 사용해 다음과 같이 번형 해서 두 개의 부분을 계산하는 방식으로 수행합니다.
위 식을 보면 P(x|y)P(x|y)와 P(y)P(y)로 두 개의 부분으로 나뉘는데, 앞부분은 Translation Model이라 부르고 parallel 데이터를 통해서 확률을 계산하고 뒷부분은 Language Model으로 monolingual 데이터를 통해서 계산 합니다. 즉 일종의 분업인 형태인데, 왼쪽 translation model은 작은 단어나 구를 번역하는 역할을 하고 오른쪽에 있는 언어 모델은 좋은 문장이나 좋은 구조를 뽑아내는 역할을 합니다. 왼쪽 transtation model은 병렬데이터 즉, 문장들이 두 개의 언어 모두로 표현되어 있는 데이터입니다. 따라서 한 문장에 대해 두가지 언어표현을 통해 한 언어에 대한 다른 언어로 바꿨을 때의 확률을 계산할 수 있게 합니다. 그리고 단일 언어 데이터란 하나의 언어만 있는 데이터로 이 데이터를 통해 언어의 특성을 확률 값으로 계산합니다.
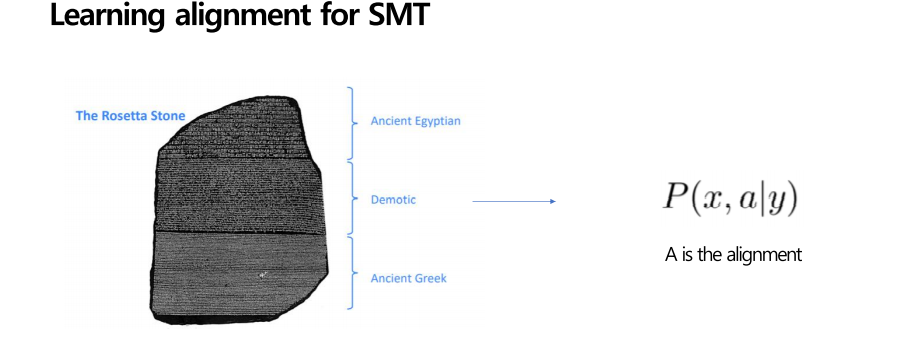
그럼 우선 많은 양의 병렬 데이터가 필요합니다. 왼쪽 그림과 같이 고대 고대 이집트 언어를 병렬처리하듯 병렬 데이터를 얻는 것이 중요하게 됩니다. 또한 그 p(x|y) 즉 조건부확률을 만들어주는 translationmodel을 어떻게 학습시키는가도 중요한데, 이때 필요한 방법이 바로 정렬입니다. 어떻게 영어 문장과 프랑스 문장에 어떤 대응을 하는지 정렬을 통해 알아보겠습니다.

정렬은 우선, 두 문장 병렬처리된 문장에서 특정 단어쌍들의 대응 관계를 말합니다. 하지만, 정렬에서 가장 큰 문제는 두 개의 언어는 각각 특성이 달라서 단어들의 순서나 품사의 순서가 다르고 1대1대응이 어려울 수 있다는 것이 문제입니다. 한번 살펴보겠습니다. 첫 번째는 한 단어가 하나의 단어로 왼쪽을 보면 japan이 오른쪽에서 LE라는 가짜 단어가 추가되며 1 대 1 대응이 안되는 것을 볼 수 있습니다.
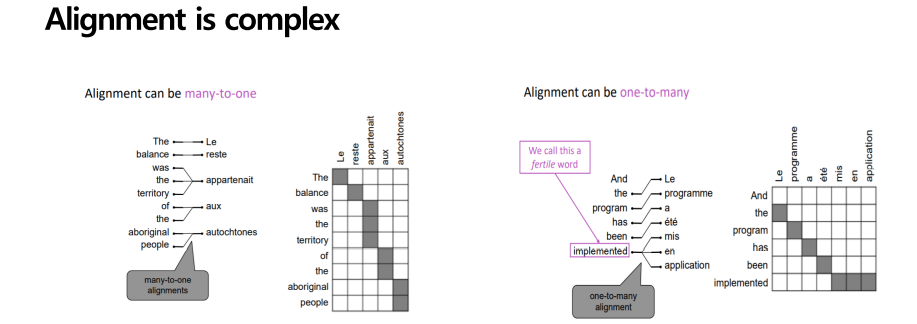
정렬 문제는 큰데, 왼쪽그림을 보면, 정렬이 many to one 즉, 여러 단어가 하나의 단어로 정렬될 수도 있습니다. 오른쪽 그림을 보면, one to many 정렬이 하나의 단어가 여러 단어로 정렬될 수도 있습니다.

물론 many- to – many 즉 많은 단어가 많은 단어로 정렬되는, 계속 혼잡한 상황이 발생하고 1대1로 잘 정렬이 되지 않는 경우가 문장에서 많이 존재합니다. 이렇게 많은 혼란스러운 상황에서 정렬을 어떻게 학습시킬 수 있을까요?
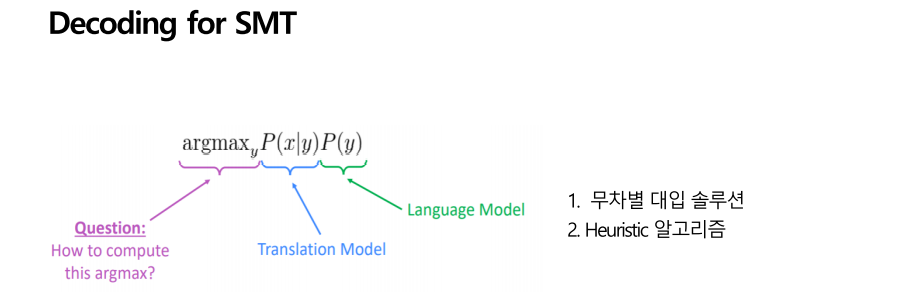
첫번째 방법은 무차별 대입 솔루션입니다. 가능한 모든 y를 열거해서 모든 확률을 계산해 보는 것입니다. 하지만 이 방법은 느낌으로도 굉장히 오래 걸리며 비용이 많이 소모될 것 같습니다. 또다른 방법은 Heuristic 알고리즘으로 너무 낮은 확률들은 계산하지 않고 높은 확률 위주의 가지들로 다른 가지들은 쳐내면서 가는 방식입니다. 이게 process를 decoding이라고 부른다 합니다.
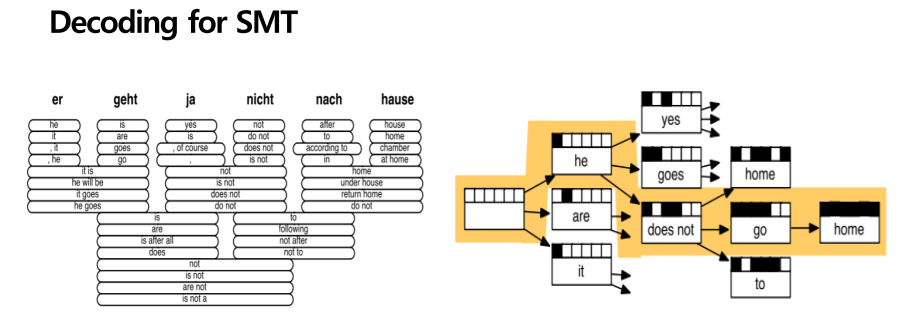
Heuristic 알고리즘이 어떻게 진행되는지 알아보면, 우선 왼쪽에서 hause로 써져있는 단어를 여러 개의 단어들로 분류를 합니다. 그중 가장 확률이 높은 home을 선택하겠죠. 그다음 모든 구문을 유지하면서 가는게 아니라, 확률이 너무 낮은 것은 제거하며 갑니다. 다양한 가설들을 세우고 나무를 가지 치는 것처럼 너무 낮은 확률을 가지는 버리면서 높은 확률로 가는 형식입니다. Decoding 후반부에 더 자세하게 설명을 드리겠고, 디코딩이 이따가 나올 신경 기계번역에서(seq to seq)에서 어떻게 사용되는지 설명드리겠습니다.
2.Neural Machine Translation (Sequence to Sequence)
위에서의 한계점을 극복하게 된 방법은 바로 신경 기계 번역입니다. 딥러닝이 nlp 분야에서 굉장히 기여를 많이 하는 직접적인 계기가 된 신경 기계번역 즉 sequence to sequence를 알아보겠습니다.
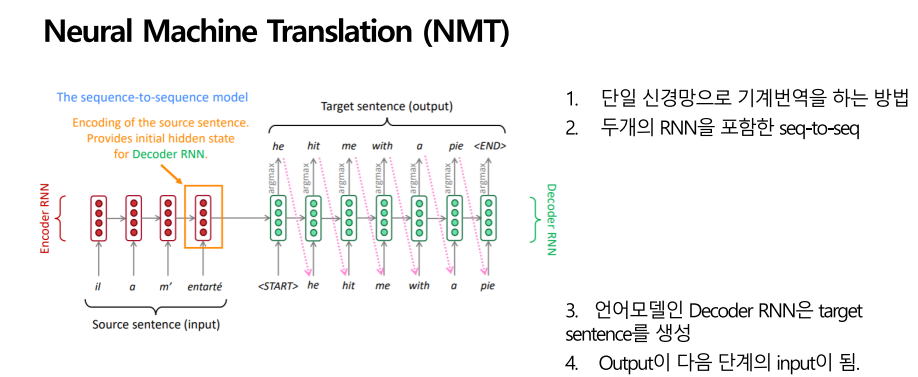
신 경기계번역은 단일 신경망으로 기계번역을 하는 방법입니다. 시퀀스 투 시퀀스의 신경망 아키텍처는 두 개의 RNN 즉 인코더 RNN과 디코더 RNN을 포함합니다. 한 시퀀스를 다른 시퀀스로 매핑하는 방법으로, 왼쪽 그림과 함께 설명드리겠습니다.
먼저 왼쪽 그림에서 소스 문장을 마지막에 encoding시켜 decoder rnn에 넘겨줍니다. 그는 파이로 나를 때렸다는 문장이 소스 문장이며 이를 encoder rnn에 우선 넣었습니다. Rnn은 단방향, 양방향, lstm등 다 될 수 있다고 합니다. 인코더 rnn에 넣고, 일종의 인코딩을 생성해서 디코더 rnn으로 전해집니다. 디코더 rnn은 조건부 언어 모델이라고 합니다. 인코딩에 따라 첫번째 출력을 얻고 다음에 나올 단어의 확률분포 argmax를 취합니다. 다음 단계에서 디코더에 전 단계에서 단어를 넣고 다시 피드백하여 argmax를 취하고 단어를 맞춥니다.
이런 방법을 계속 반복을 하며 목표 문장을 찾습니다. 디코더가 종료 토큰을 생성하면 중단합니다.
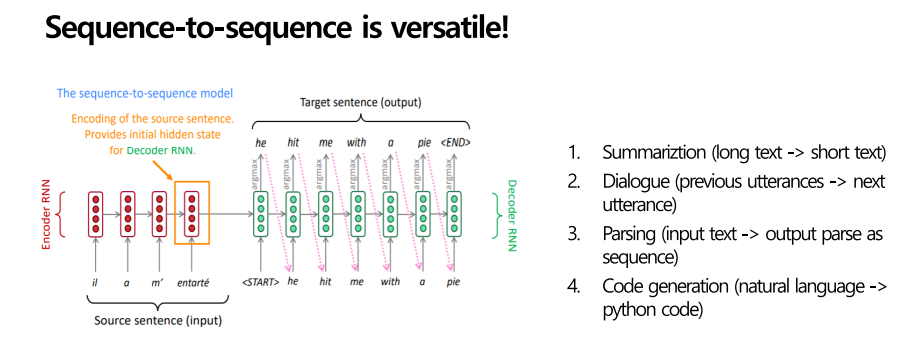
시퀀스 투 시퀀스는 기존 기계번역보다 훨씬더 유용합니다. 첫 번째는 긴 텍스트를 짧은 텍스트로 요약이 가능하다는점, 두 번째는 전의 단어가 다음 단어로 이어지며 문맥적인 것을 파악할 수 있다는 점, 세 번째는 자연어를 코드로 생성할 수도 있는 등 다양한 유용한 점을 제공한다고 합니다.

시퀀스 투 시퀀스 모델을 요약하자면 한마디로 조건부 언어 모델입니다. 디코더가 다음 타깃을 계측하는 조건부 언어 모델로 확률을 직접 계상합니다. X가 주어지면 y를 뽑아내고 그 첫 번째 y를 x와 다시 input으로 넣고 계속 반복하며 conditioning을 겁니다. 이제 드는 궁금증은 어떻게 NMT 모델을 학습하느냐인데 답은 바로 아까 우리가 배웠던 병렬 말뭉치로 학습을 시키는 것입니다.
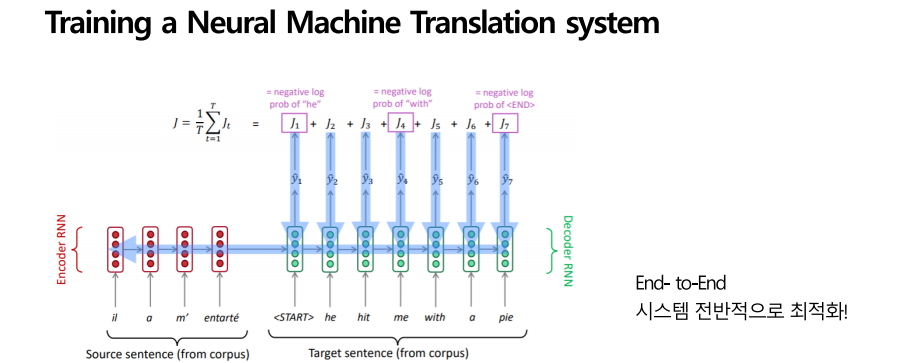
학습을 하는 방법은 시스템을 전반적으로 최적화한다는 것으로 요약됩니다. 우선 인코더 RNN에 문장을 넣고, 디코더 RNN의 모든 단계에서 다음에 올 확률분포 Y HAT의 손실을 계산합니다. 손실은 교차 엔트로피 등으로 계산할 수 있겠습니다. 그렇게 손실들을 모두 얻고 더해 단계 수로 나누어 최종 LOSS 값을 구합니다. 역전파는 전체 시스템에 걸쳐 흐릅니다. 시스템을 전체적으로 최적화하는 것이 학습의 포인트입니다. 개별적으로 학습하는 것은 좋지 않고 END-TO-END 방식으로 학습하는 것이 문장 요소를 모두 고려해 좋은 결과물을 도출한다고 합니다. 미리 정의된 최대길이 에서 최대한 짧은 문장을 채우는 방법으로 진행된다고 합니다.
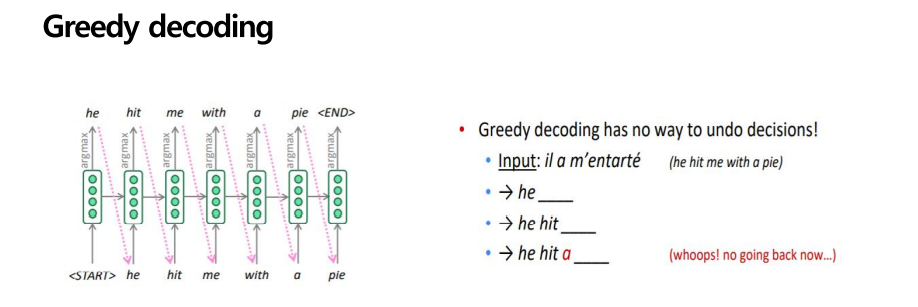
여기서도 문제점이 발생하는데, 바로 greedy decoding 문제가 발생한다는 것입니다. 가장 확률이 높은 단어를 각 단계에서 도출하다 보니 결정을 수정할 수 없다는 것입니다. 각 단계에서 목표 단어를 선택하게 되면 다시 수정할 수 없으며 돌아갈 수 없다는 것입니다. He hit me with a pie라는 문장이 정답인데, hit 다음에 a 가 나오게 되면 틀린 문장임에도 불구하고 돌아가서 수정하지 못한다는 것이며 계속 a 다음으로 문장을 써 내려가야 한다는 뜻입니다. 어떻게 이를 해결할 수 있을까요?

첫 번째 방법은, 철저하게 가능한 모든 언어 번역 공간을 검색하는 방법입니다. 모든 개별 확률 분포의 곱으로 나타내며, 디코더의 각 단계 t에서 가능한 부분 번역의 거듭제곱으로 v를 취적해야 합니다. V는 어휘의 크기이며, v 복잡도의 지수는 너무 커서 굉장히 비용이 많이 듭니다. 한마디로 모든 경우의 수를 다 게산한다는 것입니다.
그래서 두 번째 방법 일종의 검색 알고리즘인 빔 검색 디코딩 방법이 대안이 되게 됩니다. 디코더의 각 단계에서 k 개의 가장 가능성이 높은 부분 번역을 선택하여 가지치기 하는 방식으로 진행이 됩니다. K는 빔의 크기가 되며 k를 증가시킬수록 각 단계에서 더 많은 것을 고려하게 됩니다. 간단하게, k 개의 가장 가능성이 높은 번역, 가설의 점수가 가장 높은 번역을 찾는 것이 핵심입니다. 빔 검색 방법이 최적의 솔루션을 찾아주는 것은 보장하진 못하지만, 전부 다 계산하는 것보다는 훨씬 효율적입니다.

여기 beam search decoding의 예시가 있습니다. K=2이며 start에서 he 와 I 두개로 출발했습니다. 그 두개 에서 또 2개의 가지를 뽑아냈습니다. He 에서는 hit과 struck, i에선 was와 got 그럼 경우의 수가 4개가 되는데 이 4개에서 다시 2개를 선택해야합니다. 그럼 어떤 가지를 선택하게 될까요?
당연히 확률 값이 높은, he hit 가지와 I was가지를 선택하게 되겠죠? (-1.7,-1.6)
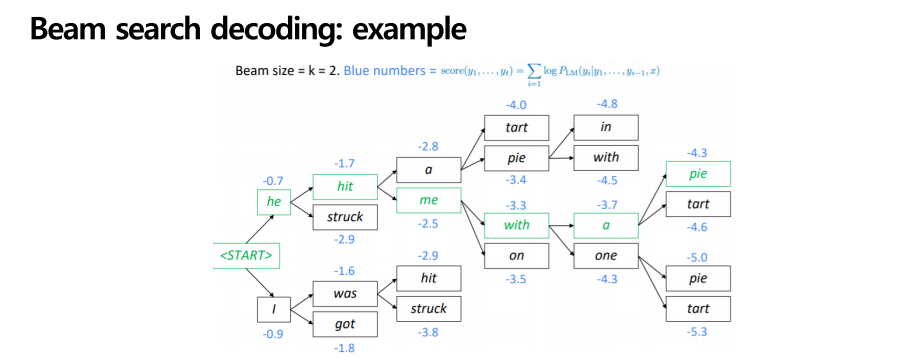
이런 식으로 k=2임을 생각하며 반복을 하면 최종적으로 확률 값이 가장 높은 줄기인 he hit me with a pie 가지가 나오게 될 것입니다.
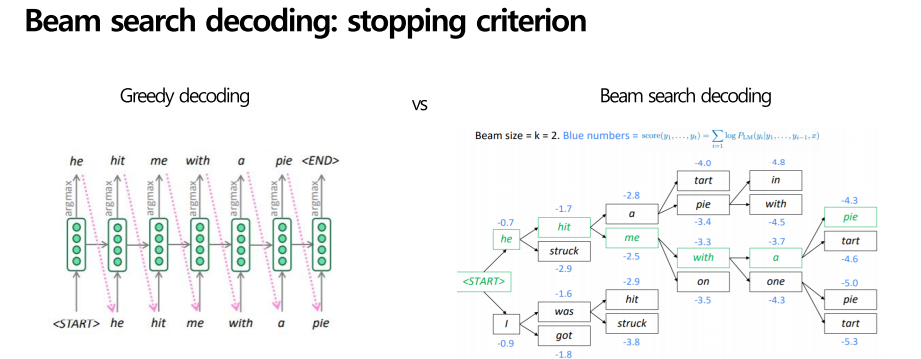
Greedy decoding 과 beam search decoding을 비교해보면, greedy decoding은 모델 이 end token을 생성할 때까지 decode를 진행합니다.
하지만 beam search decoding은 한 가설이 end 토큰을 생성하고 끝이 나면 그것은 따로 두고, 다시 다른 가설들을 탐색하기 시작합니다. 그렇게 다시 돌아올 수 없어 수정할 수 없는 문제를 해결하는 것입니다.
Beam search도 무한정 가설을 세울 수 없기에 한계를 정해줘야 하는데 방법은 두 가지 입니다. 첫 번째는 미리 정한 시간 단계 t에 도달하면 멈추기 하는 법, 두번 째는 n 개의 완료된 가설을 만들면 중지하는 방법입니다.

이렇게 완성된 가설 모음 중 가장 높은 점수를 받은 것을 선택합니다. 문제는 긴 가설일수록 낮은 점수를 받게 되어서 기준이 애매하다는 것입니다. 설명을 드리면 앞에서 오른쪽으로 갈수록, 가설이 길수록 –값을 계속 더하기 때문에 어쩔 수 없이 정확하지 않더라도 짧은 가설을 채택하는 경우가 생깁니다. 이를 해결하는 방법은 간단하게 t(time step) 수로 나누어 평균을 구하여 최상위를 선택하면 됩니다.

NMT의 장단점을 정리해보면, NMT의 장점으로는 더 나은 성능을 제공한다는 것입니다. 기존 기계번역보다 sequence를 고려하기 때문에 좀 더 유차하고 문맥을 고려하며 단어와 구 사이의 유사성을 잘 이용한다는 특징이 있습니다.
두 번째는 single neural network가 처음부터 끝까지 전반적인 시스템을 가지고 optimized된다는 것입니다. 하부구조가 개별적으로 optimized 되어야 하는 기존 기계번역과 달리 아까 말씀드렸듯이 역전파가 전 시스템을 거쳐서 진행되기 때문에 단순하고 편리합니다.
세 번째는 인간 공학적 노력이 덜 필요하다는 것입니다. Feature 엔지니어링이 필요가 없으며, 모든 언어쌍에 같은 방법으로 동일한 아키텍쳐로 적용이 가능합니다. 그저 병렬 말뭉치만 찾으면 됩니다.
단점도 존재합니다.
단점으로는 NMT가 debug 즉 어디서 오류가 발생했는지 오류를 표시하는 것이 어렵다는 것입니다. 기존 기계번역은 하위 구조가 있기 때문에 디버그가 가능합니다. 하지만 NMT는 하부구조가 없고 쭉 흘러가는 형태이기 때문에 가능합니다. 두 번째는 제어하기 어렵다는 것입니다. 특정 오류를 하고 발견했을 때 이를 수정하고 제어할 사후규칙을 만들기가 어렵다는 것입니다. 만약 글을 번역하다가, 번역에 나쁜 말을 집어넣지 않도록 컨트롤하고자 했는데, 이것만을 못하도록 전반적으로 제어하기가 어렵다는 것입니다. 기존 기계번역은 하부구조가 있다면 그 부분만 따로 떼어와서 제어하게끔 만들 수 있는데 NMT 같은 경우에는 FLOW가 전반적으로 흘러가기 때문에 특정 부분만을 수정하기가 어렵기 때문입니다.

machine translation이 제대로 이뤄졌는지 확인하는 대표적인 지표는 ‘BLUE’ 점수입니다. 이 방법 외에도 다양한 방법이 있지만 아직까지는 대부분 BLUE 점수를 통해서 모델을 평가합니다. BLUE(Bilingual Evaluation Understudy)란 기계에 의해 번역된 문장과 사람이 작성한 문장을 비교해서 유사도를 측정해서 성능을 측정하는 지표입니다.
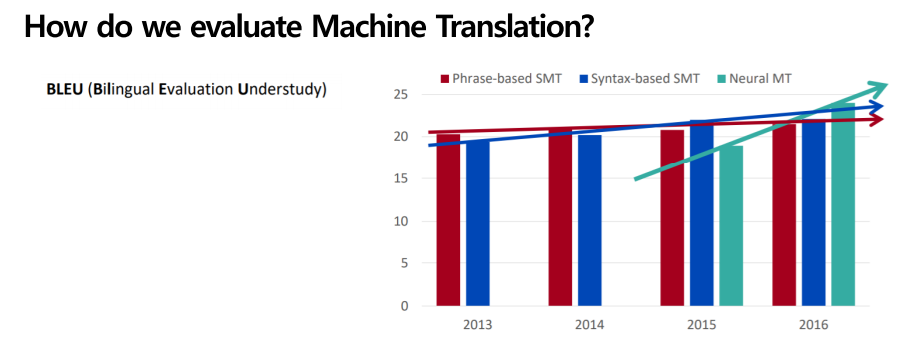
Bleu에 대한 설명보다는 다음 그래프가 중요한데, NMT의 성능이 굉장히 가파르게 증가했다는 것이 중요합니다. 기존 SMT 기계번역은 3년 동안 그 증가 추세의 기울기가 완만했지만, NMT 즉 신경망 기계번역은 그 점수 추세가 가파르게 증가했다는 것입니다. NMT의 성능은 연구를 진행할수록 가파르게 증가함을 보여주고 현재까지도 연구가 진행 중이라고 합니다.

현재까지도 NMT는 NLP 분야에서 딥러닝이 적용된 가장 큰 성공 사례 입니다. 그 예시로, 구글이 번역 시스템을 2년 만에 SMT에서 NMT로 전환하여, 지난 수년간 수백 명의 엔지니어가 한 작업들을 NMT로는 소수의 엔지니어로 몇 달 만에 더 나은 성과를 냈습니다. 하지만 기계번역의 모든 한계점이 없어진 것은 아닙니다.
한계 점으로는, 단어의 범위를 초과하면 그 목표 단어를 만들어 낼 수가 없다는 것입니다. 즉 학습을 시킬 때 없었던 단어는 만들어 낼 수가 없다는 것입니다. 두 번째는 학습데이터와 test데이터 사이에 domain이 일치하지 않으며 성능이 떨어진다는 것입니다. 세 번째는 한 문장을 encoding하는 것이기 때문에 긴 text의 경우 context를 계속 유지하여 오류가 생길 수 있으며 네 번째는 리소스가 부족한 언어 쌍의 경우, 성능이 떨어질 수 있다는 문제가 있습니다.
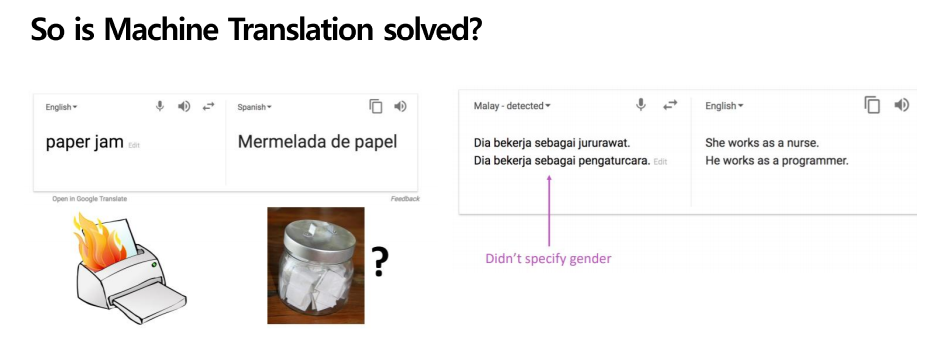
더 많은 문제점이 존재합니다. 왼쪽 그림을 보시면 paper jam은 종이가 프린트기에 끼였다는 의미인데, 이를 직역하여 종이가 들어있는 jam으로 번역을 하게 됩니다. 즉, 관습적인 언어, 상식에 대한 개념이 없다는 것입니다. 두 번째는 굉장히 편향되게 번역을 할 수 있다는 것입니다. 왼쪽 문장에서는 어떠한 성별도 문장에 들어있지 않지만, 오른쪽에서는 간호사의 주어를 she(여성) 프로그래머의 주어를 he(남성)으로 자기 마음대로 할당하였습니다. 여성 간호사와 남성 프로그래머의 학습이 많았기에 발생한 결과인데, 소스 문장에는 없는 정보를 구성하여 성 역할을 전파하는 문제가 생겼습니다.
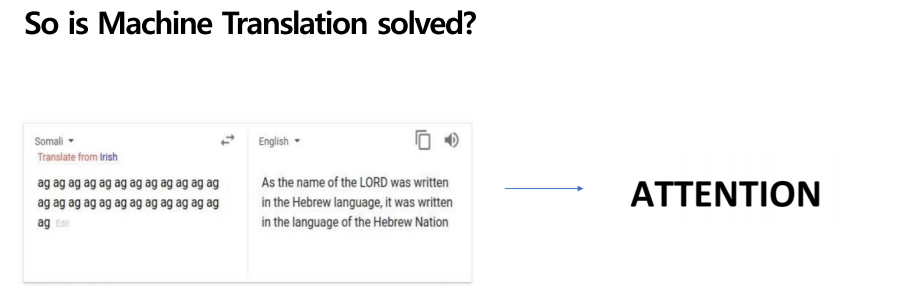
이렇게 단순하게 ag를 반복한 문장을 멋대로 해석하는 문제가 발생하기도 합니다. 이는 학습 데이터 때문에 그저 반복하는 문장을 자기 멋대로 해석한 결과입니다. 이렇듯 시퀀스 투 시퀀스도 한계점을 드러내게 되고 이를 보완하기 위해 나온 방법이 마지막으로 배울 Attention 이라는 개념입니다.
3. ATTENTION
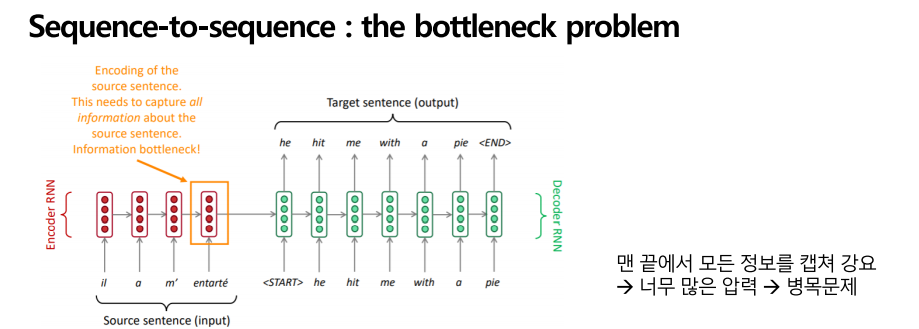
Seq to seq에서는 소스 문장의 인코딩이 중요합니다. 여기서 문제는 단일 벡터 전체가 소스 문장 전체의 인코딩이라는 문제이며, 문장의 정보가 끝에서 다 인코딩 되어버리는 즉, 정보가 쏠려버리는 병목현상이 나타나게 됩니다. 소스 문장에 대한 모든 정보를 끝에서 다 캡처하도록 강조하며, 여기서 너무 많은 압력이 가해집니다. Attention은 단계별로 집중을 하게 만들어 한꺼번에 집중이 가해지는 이 병목현상을 해결해 줍니다. 디코더의 각 단계에서 인코더에 직접 연결을 하여 소스 시퀀스의 특정 부분마다 집중을 하게 만드는 작업을 하는데 다음에서 더 자세하게 설명을 드리겠습니다.
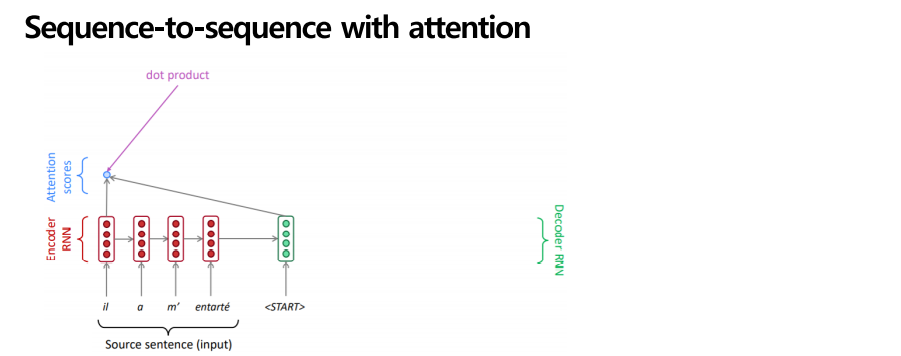
디코더의 첫 단계에서 인코더의 첫 단계와 내적을 시켜서 스칼라 값을 뽑아 attention score를 구합니다. 어텐션 스코어란 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현시점의 은닉 상태 states와 얼마나 유사한지를 판단하는 스코어 값입니다.

그렇게 4개의 attention score를 가져와서 소프트맥스에 넣고 확률 분포를 얻습니다. Barchart로 알아본 결과, 대부분의 확률 질량이 첫번째 단어로 갔음을 알 수 있습니다. 그렇게 he라는 단어를 먼저 만들게 됩니다.
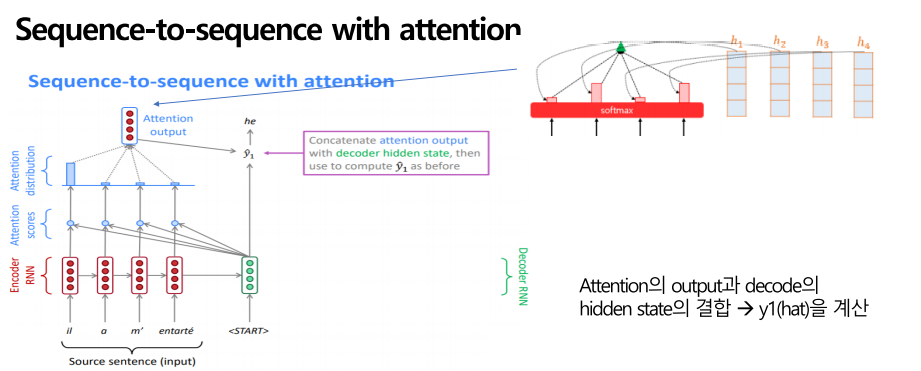
그렇게 얻은 attention 분포는 인코더의 hidden states의 가중치가 됩니다. Attention 분포와 인코더의 hidden states를 가중 합하여 attention output을 뽑고, 그리고 그 attention output과 디코더의 hidden state를 결합하여 y1(hat)이라는 결과 he를 도출하게 됩니다.
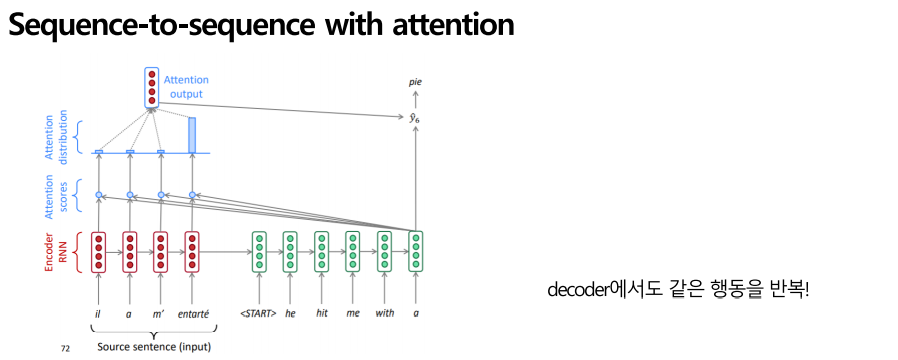
Attention 출력을 사용하여 다음 단어에 영향을 주고 그런 식으로 두 번째 디코더에서도, 세 번째 디코더에서도 같은 것을 반복합니다. 각 단어에는 분포가 있으며, 기존 NMT보다 훨씬 더 유연하고 부드러운 정렬과 사고를 하게 됩니다. 기존 인코딩 방법으로는 마지막에 압력을 가해서 정보의 병목현상이 일어났는데, ATTENTION을 사용하여 각 인코딩의 각 단계마다 집중을 해주어 정보의 흐름을 마지막에 집중시키지 않고 각 단계마다 부드럽게 풀어준다고 생각하시면 쉬울 것 같습니다.

방정식은 지금까지 그림으로 봤던 것을 식으로 풀어내면 방정식은 끝이 납니다. 아까 봤듯 인코더 hidden states와 디코더 hidden states를 결합하여 attention score 값을 뽑고, 여기에 softmax적용해서 attention 확률분포 뽑고, 여기다가 encoder hidden states의 가중 합을 구해 attention output 값을 뽑고, 이 output 값과 decode의 hidden state와 결합하여 최종 y hat을 구하는 과정입니다.
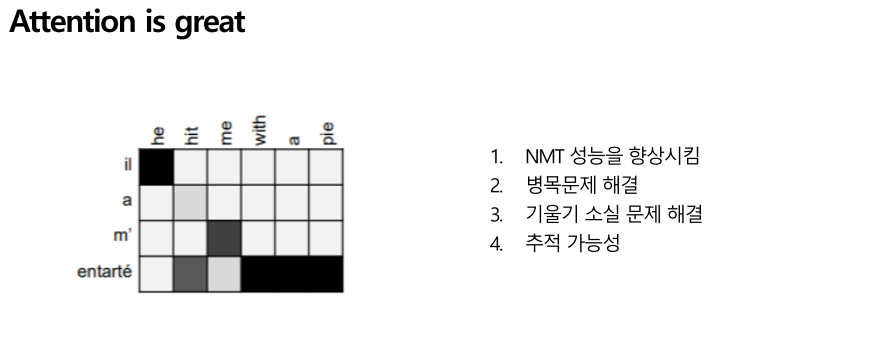
Attention의 효과는 놀라웠습니다.
첫 번째는 attention은 기존 신경망 기계 번역의 성능을 훨씬 향상시켰습니다. Decoder가 소스 문장 부분마다 집중을 하여 가능해진 일입니다. 두번째는 병목현상을 해결하였습니다. 아까 그 이유를 설명드렸습니다. 세 번째는 기울기 소실 문제를 해결하였다는 것입니다. 문장이 길어질수록 뭔가 길이가 길어질수록 기울기 소실 문제가 발생하는데, attention은 각 단계마다 집중을 할 수 있어 소실문제를 해결하였습니다. 네 번째는 추적 가능성입니다. NMT는 하부구조가 없고 flow가 전반적으로 진행되기 때문에 어디서 오류가 발생했는지 추적하기 어렵지만 attention은 encoding의 각 단계마다 집중하여 보면서 어디서 오류가 발생했는지 확인할 수 있습니다. 이렇게 NMT의 문제점들을 효과적으로 해결했습니다.
참고자료
