
작성자 : 투빅스 13기 김미성
Contents
- Motivation & History
- Standford Question Answering Dataset(SQuAD)
- QA model
1. Motivation & History

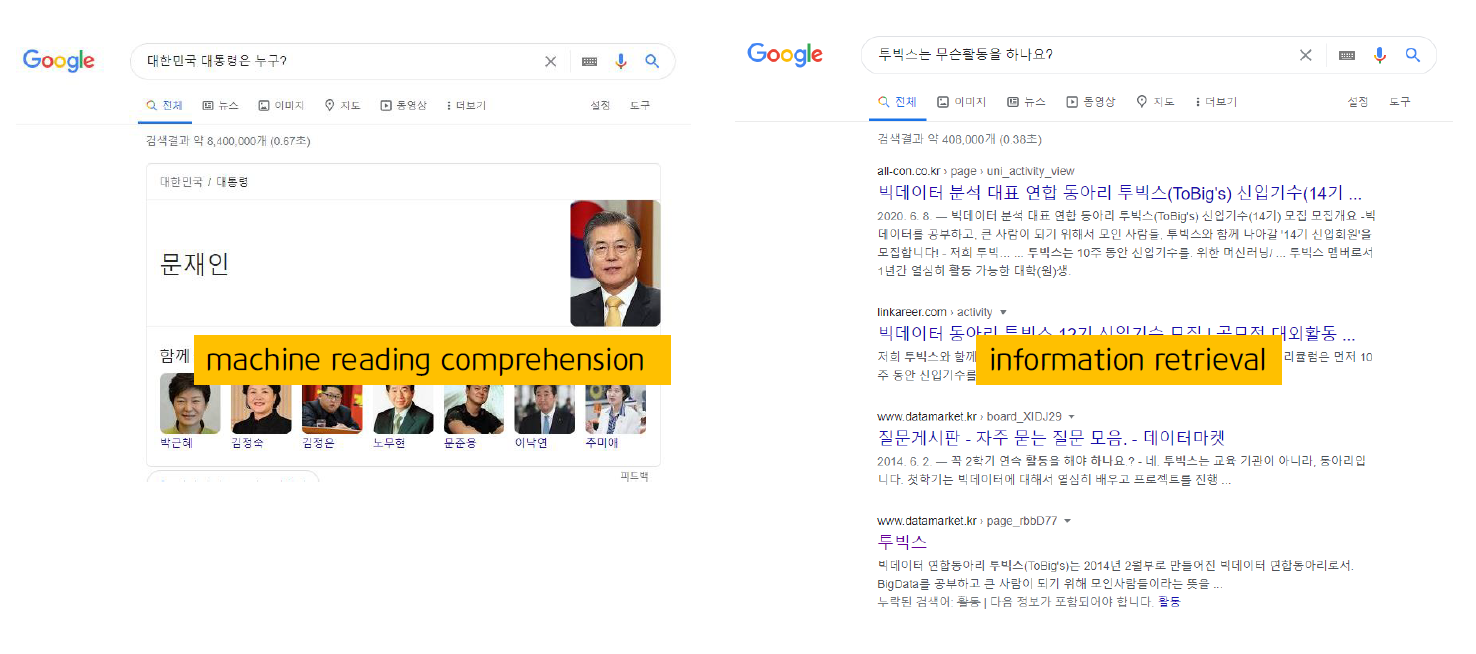
우리는 종종 질문에 대한 답을 원합니다. 그래서 구글에 우리나라 대통령은 누구인가? 투빅스는 무슨 활동을 하는 동아리인지? 등을 검색하곤 합니다.
그랬을 때, 구글은 우리에게 2가지 정도의 형식으로 답을 해줍니다.
- Finding documents that contain an answer (정답을 포함하고 있는 문서 찾기)
- 기존의 정보 검색 (information retrieval = IR) IR)/ 웹 검색으로 처리할 수 있는 사항
- Finding an answer in a paragraph or a document (문서에서 정답 찾기)
- 이 문제를 흔히 읽기 이해 (machine reading comprehension = MRC) 라고 한다.
- 오늘날 우리가 중심적으로 다룰 사항
이렇게 질문에 대한 답의 유형을 분류할 수 있고, 지금부터는 MRC(machine reading comprehension) 에 대해서 더 알아보도록 하겠습니다.
2. Stanford Question Answering Dataset(SQuAD)
1. Types of questions

먼저 질문은 다음과 같이 분류할 수 있습니다. SQuAD는 이중에서 1번인 Factoid type questions 에 해당합니다.
2. SQuAD(1.1)
QA dataset은 어떻게 구성되어있을까요? QA data는 다음과 같이 3가지 부분으로 구성되어있습니다.
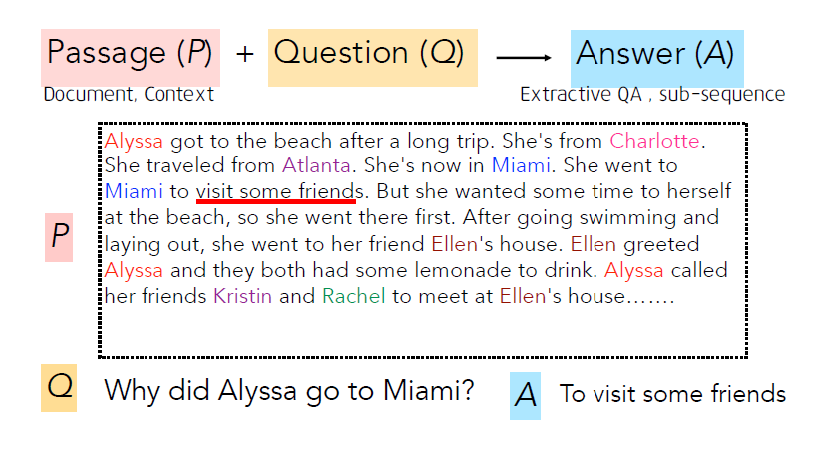
QA model의 발전에 큰 영향을 미친 SQuAD dataset(1.1)도 다음과 같은 형태로 되어있는데요, 이때 알아둘 점은 질문에 대한 Answer은 항상 Passage 속 하위 sequence로 구성이 되어있다는것입니다.

그렇다면 이 데이터셋의 answer(=gold answer)은 누가 작성한걸까요? SQuAD dataset은 위키피디아 문서를 바탕으로 크라우드소싱 인력들이 해당하는 질문과 답변을 생성했다고 합니다. 그리고 그림에서 볼 수 있듯이 한 질문에 대해 3가지 답변을 sampling 합니다.
그럼 데이터의 평가 방법에 대해서도 궁금하실 것 같은데요, 이런 SQuAD dataset을 이용한 평가 방법으로는 exact match 방법과, f1 score를 이용하는 방법이 있습니다.
- exact match : 예측한 답과 실제 답이 정확히 일치하면 1, 그렇지 않으면 0.
- f1 score : 예측된 답과 실제 답의 중첩토큰을 계산. 더 안정적인 평가방법.
3. SQuAD(2.0)
현재 SQuAD dataset은 2.0 까지 나온상태 입니다. 그럼 1.1 에서 2.0 으로 데이터셋이 발전하면서 어떤 부분이 바뀌었는지 살펴보겠습니다.
바로 added unanswerable question 입니다. SQuAD 2.0 에서는 답이 없는 질문들이 추가 되었습니다!
현존하는 reading comprehension 데이터셋들은 주로 ‘answerable(대답 가능한)’ 질문들에 초점을 맞추거나 쉽게 판별이 가능한 가짜 ‘unanswerable(대답 불가능한)’ 질문들을 자동 생성해 왔습니다. SQuAD 2.0에서는 이런 약점을 보완하게 됩니다.
- 기존 데이터셋(SQuAD 1.1)에 새로운 5만 개 이상의 unanswerable questions(응답 불가능한 질문)를 병합
- unanswerable question은 온라인의 crowd worker들이 직접 생성(즉, 기계적으로 생성된 것이 아니라 진짜 인간이 생성했으므로 질이 더 높음)
- worker들에 의해 생성된 unanswerable question은 응답 가능한 질문들과 유사하여 기계적으로 판별이 어려움
그렇다면 No answer 을 모델은 어떻게 처리할수 있을까요?
-
임계값을 사용한다.
: 임계값 이상의 결과에 대해서만 answer을 예측하고, 임계값 이하의 결과에 대해서는 no answer 로 예측하는 방식. -
Machine Reading Comprehension with Unanswerable Questions (2019 AAAI)
- Read then verify 시스템을 제안
- Passage 에 대한 question 에 대한 정답과 no answer 확률을 각각 도출함
- 이렇게 도출한 정답이 적절한지 확인을 한다
ex ) 질문 : 프랑스는 어떤 지역입니까
답변 : 노르망디는 프랑스의 지역입니다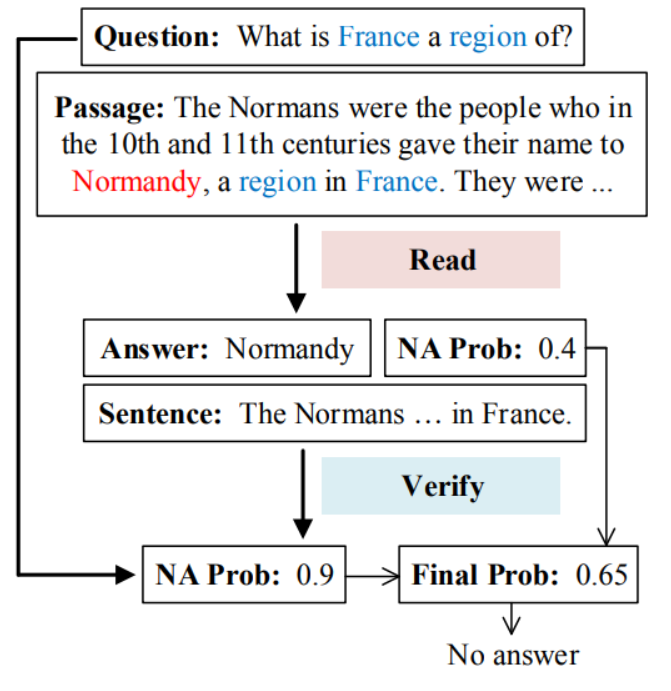
4. SQuAD Limitations
- span-based answers 만 존재
- passages 내에서만 정답을 찾도록 하는 질문 구성
- 여러 문서들을 비교하여, 진짜 정답을 찾아낼 필요가 없음.
- 실제 마주하게 될 질문 - 답변 보다 잘 정립된 문법구조
- 동일 지시어 문제를 제외하고는 Multi fact 문제, 문장 추론문제가 거의 없음.
그럼에도 불구하고, SQuAD is well-targeted , well-structured, clean dataset
- QA 문제를 푸는데 있어 가장 많이 사용되고, 경쟁하고 있는 데이터셋
- 실제 시스템을 개발하기 위한 유용한 start point 이다.
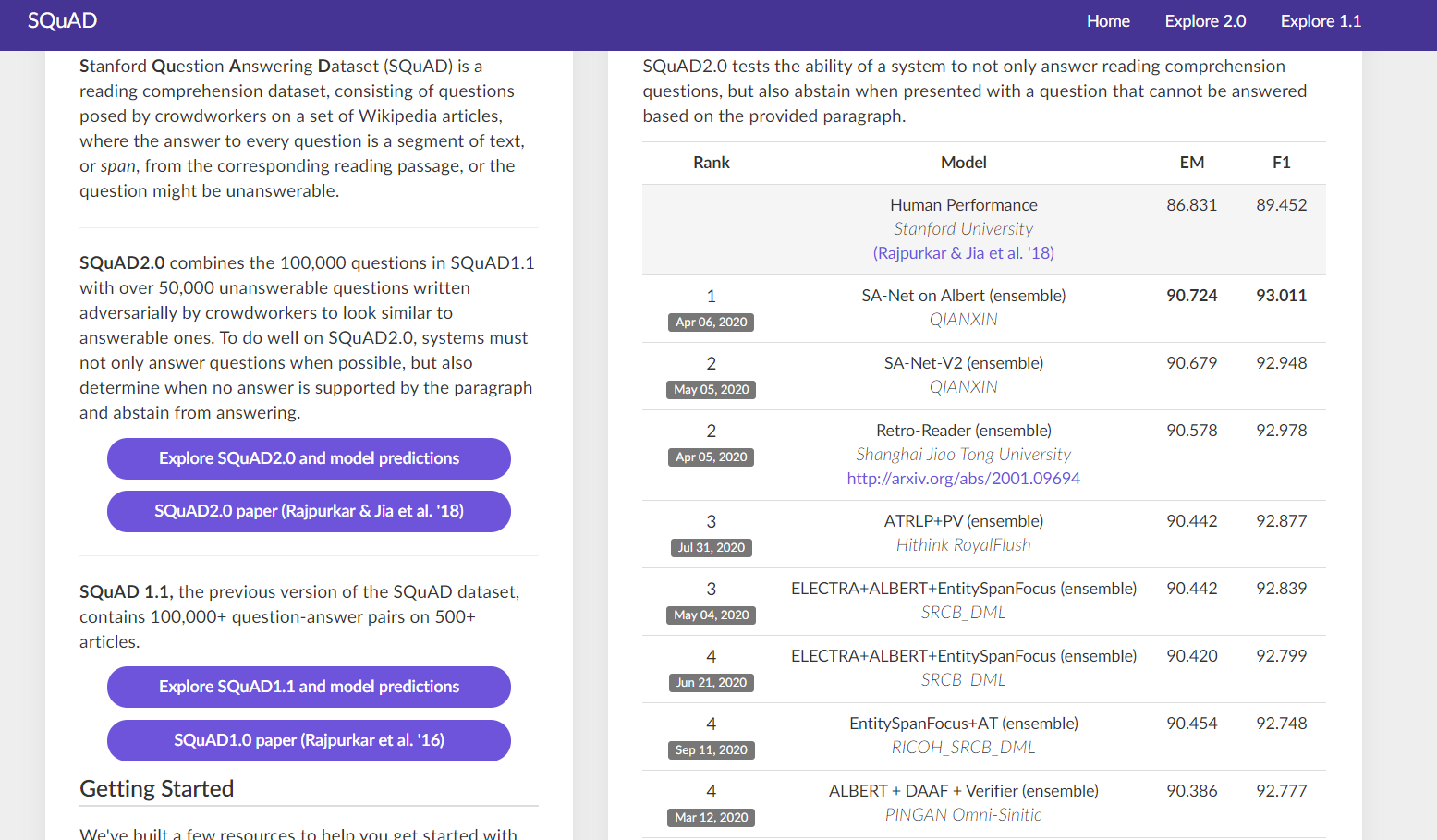
5. SQuAD leader board
6. KorQuAD (2.0)👍
- 한국어 위키백과를 대상으로 대규모 MRC 데이터 구축
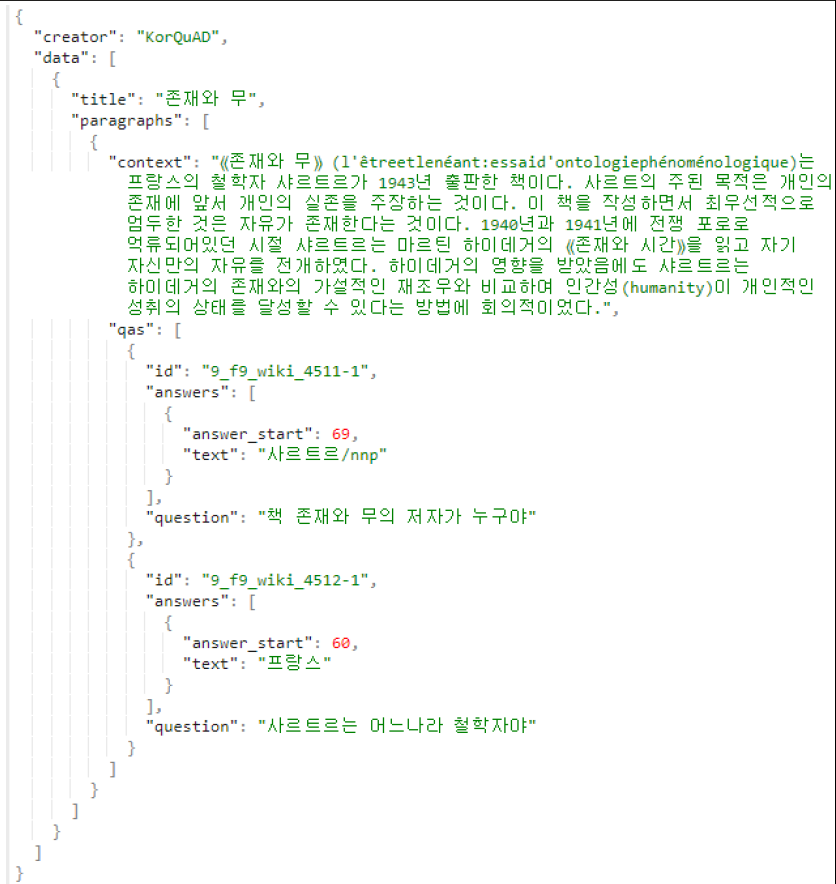
KorQuAD dataset 내부를 보게되면 다름과 같이 구성되어있습니다.
이를 보면 answer_start 라고 해서 정답의 sequence가 시작되는 위치 정보도 제공하고 있음을 알수 있습니다.
3. QA model
1. Standford Attentive Reader
-
질의에 대한 응답을 찾는 모델을 구축하는데 Bi LSTM with attention을 적용함.
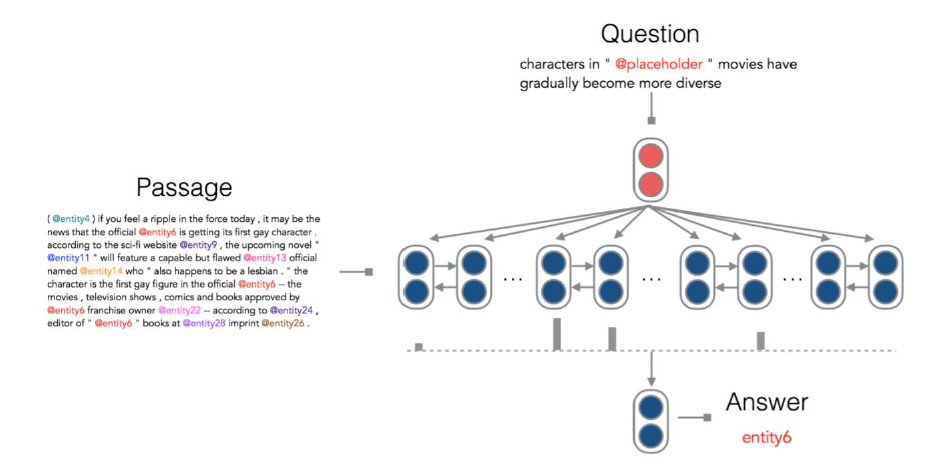
-
standford attentive model 은 다음과 같이 세 부분으로 나누어져 있습니다. 한부분씩 살펴보도록 하겠습니다.
- Question vector 생성
- Passage vector 생성
- Attention
1. Question vector 생성
먼저 question 에 대한 vector 를 생성하는 부분인데요,
주어진 문장에 있는 단어들의 embedding을 사전에 학습된 glove 에서 가져와 one-layer BiLSTM 에 넣습니다.
BiLSTM의 각 방향 마지막 hidden state를 concat 하여 question vector를 얻습니다.
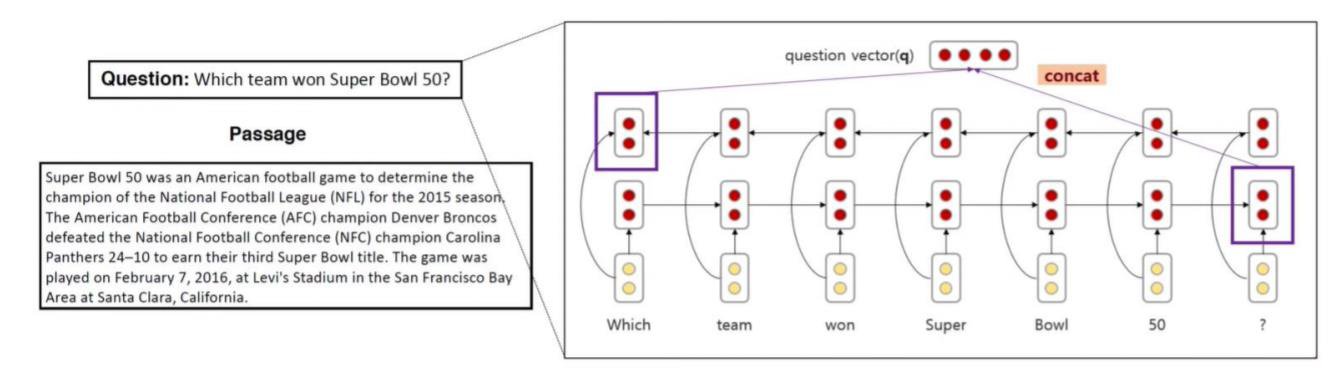
2. Passage vector 생성
두번째로는 passage 에 대한 vector를 생성하는 부분인데요,
여기서도 마찬가지로 주어진 문장에 있는 단어들의 embedding을 사전에 학습된 glove 에서 가져와 one-layer BiLSTM에 넣습니다.
그리고 각각의 포지션에서 BiLSTM의 hidden state를 concat 하여 문장 내 단어 개수 만큼의 passage vector를 생성합니다.
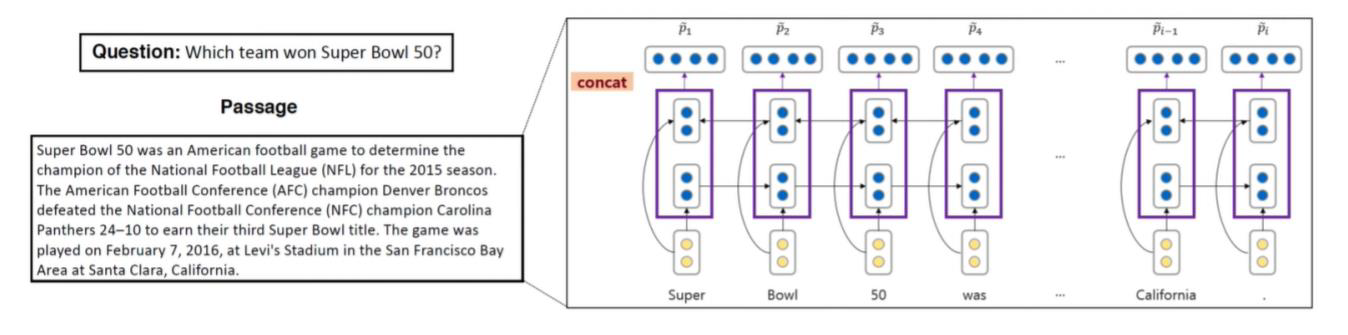
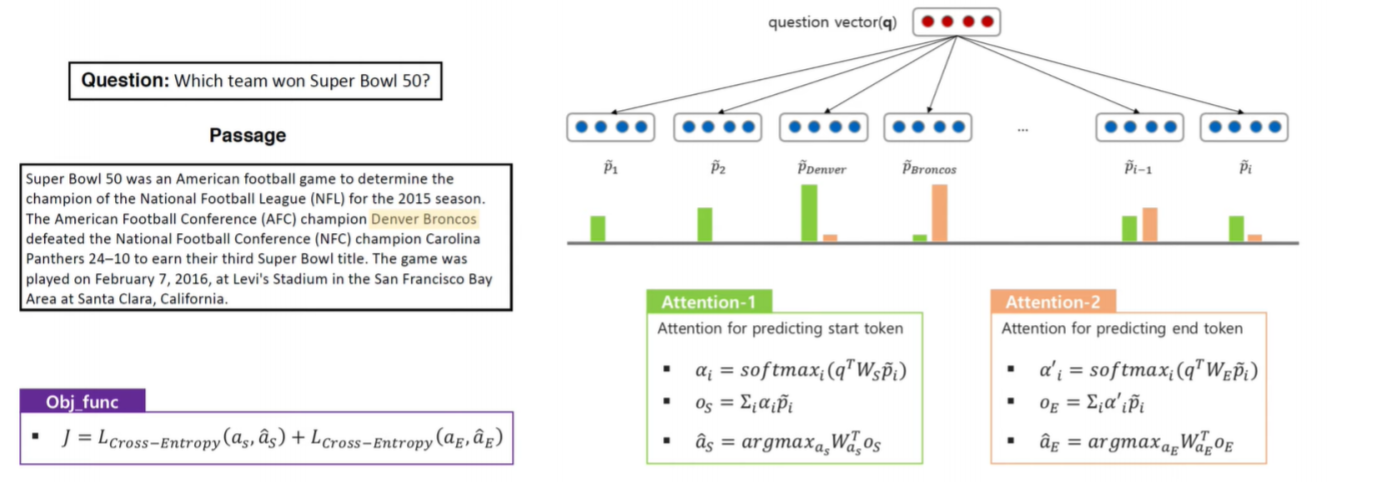
3. Attention
- 𝛼𝑖: i 개의 p 벡터와 한 개의 q 벡터를 이용하여 어텐션을 적용한 후 소프트맥스를 취함.
- 𝑜𝑠: 𝛼𝑖와 pi 벡터를 곱하여 모두 더함
- 𝑎𝑠: 𝑜𝑠에 linear transform 을 취함
-> 이렇게 start token 과 end token 을 구합니다.
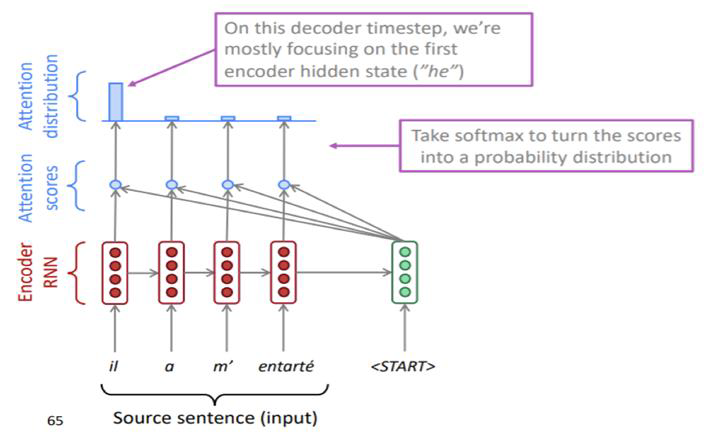
🙋참고
attention 의 계산 과정
2. Standford Attentive Reader++
-
앞서 살펴본 Stanford attentive reader 과 차이점을 살펴보면, Standford Attentive Reader++ 에서는 one layer BiLSTM 이 아닌 3 layer BiLSTM을 사용하게 되었습니다.
-
또한 Question vector를 구성할때, 각 방향 마지막 hidden state를 concat이 아닌, BiLSTM state를 포지션별로 concat 후 weighted sum을 하여 구성합니다.
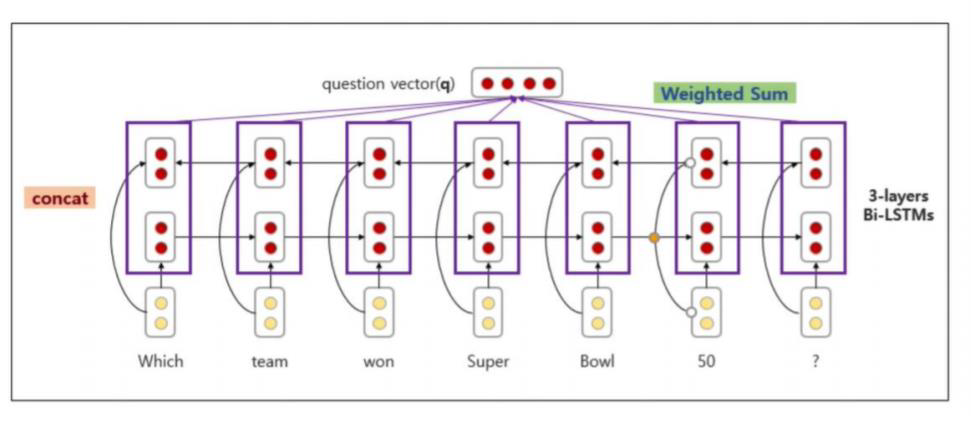
-
Passage vector를 구성할때의 차이점도 발생하는데요, 단어의 embedding 값만 사용하지 않고, extra feature 들을 더 추가하여 passage vector를 구성합니다.
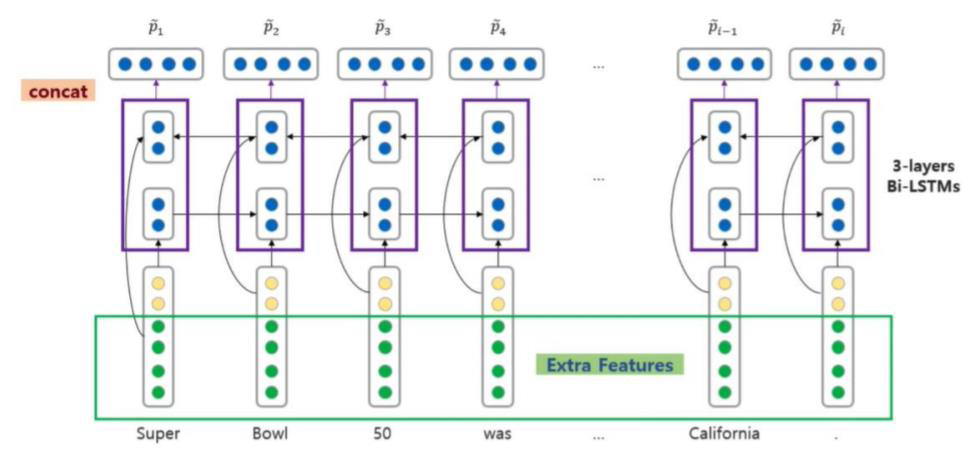
-
이때 추가되는 extra feature 에는 다음과 같은것들이 있습니다.

3. BiDAF : Bi-Directional Attention Flow for Machine Comprehesive
- 이 모델은 Question 에서 Passage 로 한 방향으로만 진행되는 Standford Attentive reader 와 달리 attention 이 양방향 으로 적용된 모델입니다.
- Question <-> Passage
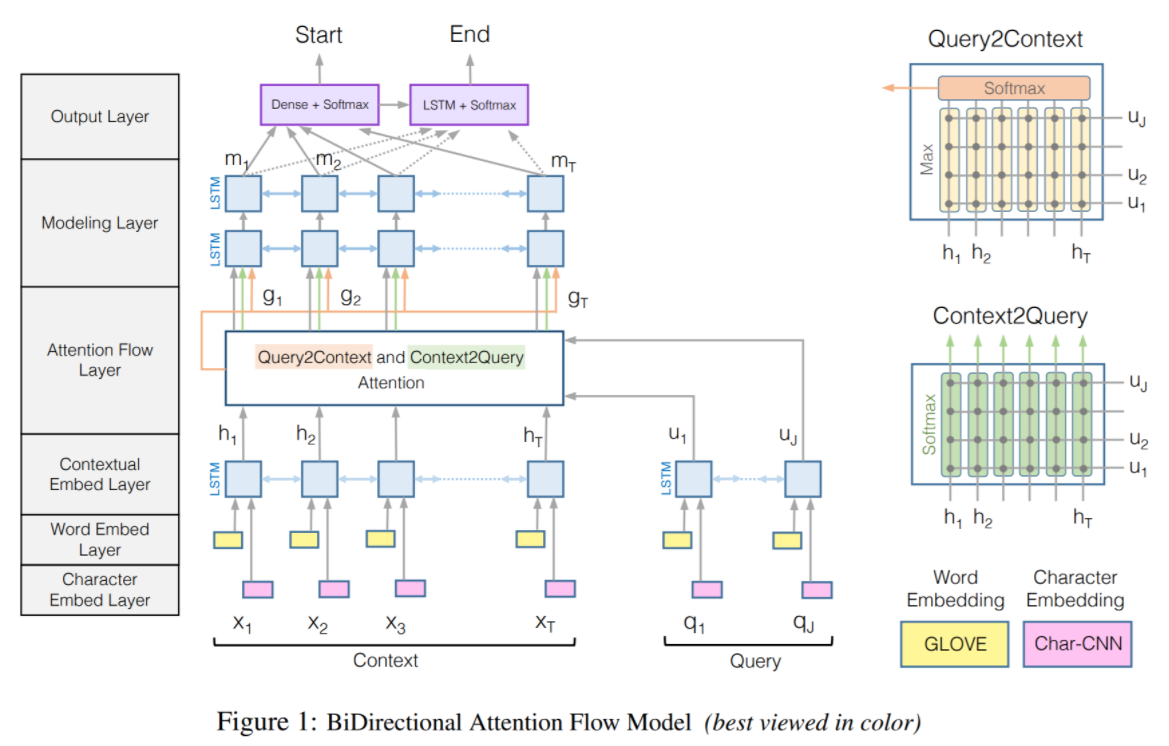
- 이 모델은 총 6단계로 이루어져 있는데요, 하나씩 살펴보겠습니다.
- Character Embedding Layer
- Word Embedding Layer
- Contextual Embedding Layer
- Attention Flow Layer
- Modeling Layer
- Output Layer
먼저 Character Embedding Layer 에서는 charCNN 을 사용하여 각 단어를 vector space 에 mapping합니다. 그리고 Word Embedding Layer 에서는 pre-trained word embedding model을 사용하여 각 단어를 vector space 에 mapping 하게 됩니다.
이 두 결과를 concat(그림속 빨간 네모) 하고 BiLSTM 에 넣기전, two-layer highway-network 를 거쳐 d-dimension vector로 만들어줍니다.
그리고 BiLSTM 에 넣어 2d-dimension vector를 생성하게 됩니다.
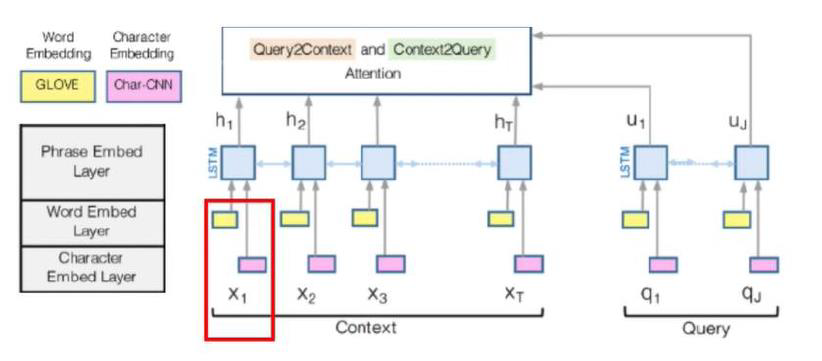
그러면 Attention 을 하기위한 준비는 다 마쳤습니다! 이제 attention layer 에 대해 살펴보겠습니다.
Attention layer 에서는 Query to Context, Context to Query 이렇게 양방향으로 attention 이 일어나게 됩니다. 즉, Query와 Context 를 쌍으로 묶어서 Attention 을 학습하는곳입니다.
- Query to Context : Context의 어떤 정보다 Query 와 관련이 있는지
- Context to Query : Query 의 어떤 정보가 Context 와 관련이 있는지
이전에 본 Stanford Attentive reader 와 달리, query 와 context(=passage) 를 single feature vector로 요약하지 않고, query 와 context 를 연결시킨다는 특징이 있습니다.

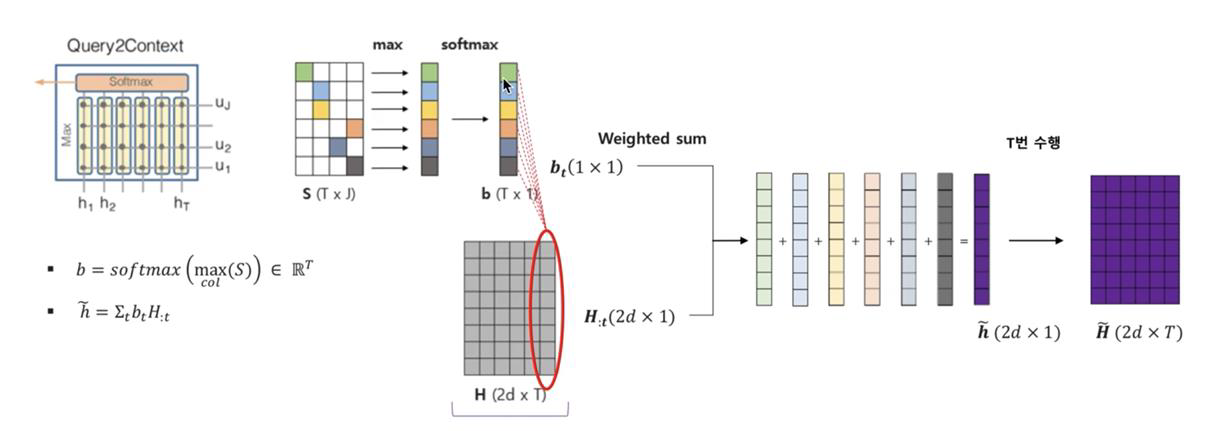
그렇다면 이 attention은 어떻게 양방향으로 일어날수 있을까요? 이 양방향 attention을 위해 shared matrix S를 이용합니다. shared matrix는 Ht 와 Uj에 α라는 function 거쳐 계산됩니다.

- Context2Query Attention
- St 에 대해 softmax 를 취하고, 이렇게 나온 at와 U를 이용해 t번째 context word 입장에서 유사성이 높은 query 의 특성을 알게됩니다.

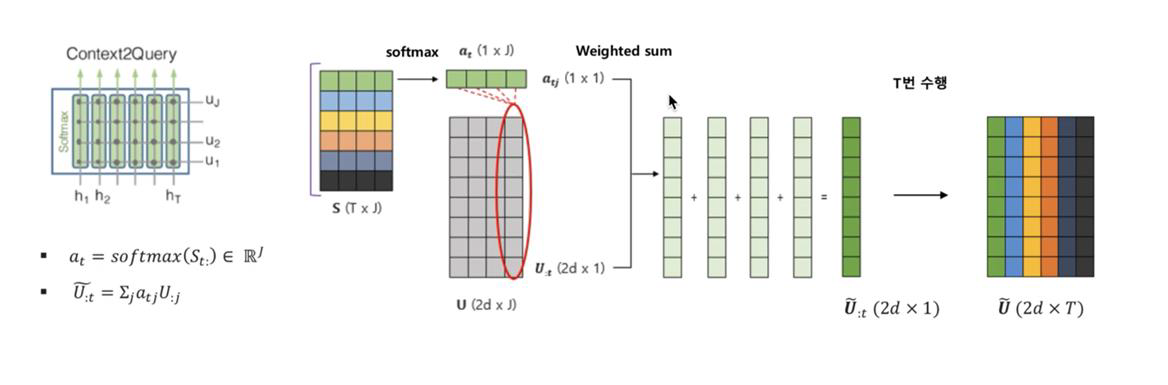
- Query2Context Attention
- S에서 maxcol을 통해 가장 큰 값을뽑아 softmax를 취하고, 이렇게 나온 b 와 H 를 이용하여 query 입장에서 중요한 word를 알게됩니다.

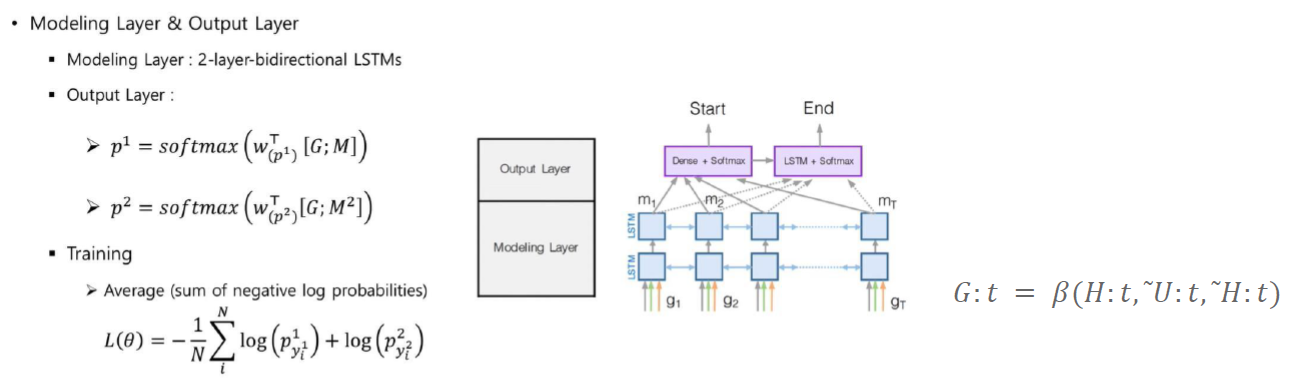
마지막으로 modeling 과 output layer 입니다.
앞서구한 G(H와 U를 이용하여 구함)를 2-layer BiLSTM을 거쳐 M을 만들고, M과 G를 concat 하여 linear transform과 softmax를 취해 start, end token을 예측합니다.
최종적으로 sum of negative log probabilities 의 average를 최소화 하는 방향으로 학습이 이루어집니다.
참고자료
-
CS224n 강의
-
https://hwkim94.github.io/deeplearning/rnn/lstm/attention/nlp/paperreview/2018/02/23/BiDAF1.html
-
https://www.youtube.com/watch?v=yIdF-17HwSk&list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z&index=10
-
https://www.youtube.com/watch?v=7u6Ys7I0z2E&list=PLetSlH8YjIfVdobI2IkAQnNTb1Bt5Ji9U&index=8
-
https://hwkim94.github.io/deeplearning/rnn/lstm/attention/nlp/paperreview/2018/02/23/BiDAF1.html
