
작성자 : 투빅스 13기 이예진
Contents
- Intro
- 1d Convolution for Text
- CNN for Classification
- 추가 & 정리
- Deep CNN for Text
1. Intro
기존 RNN의 문제와 CNN
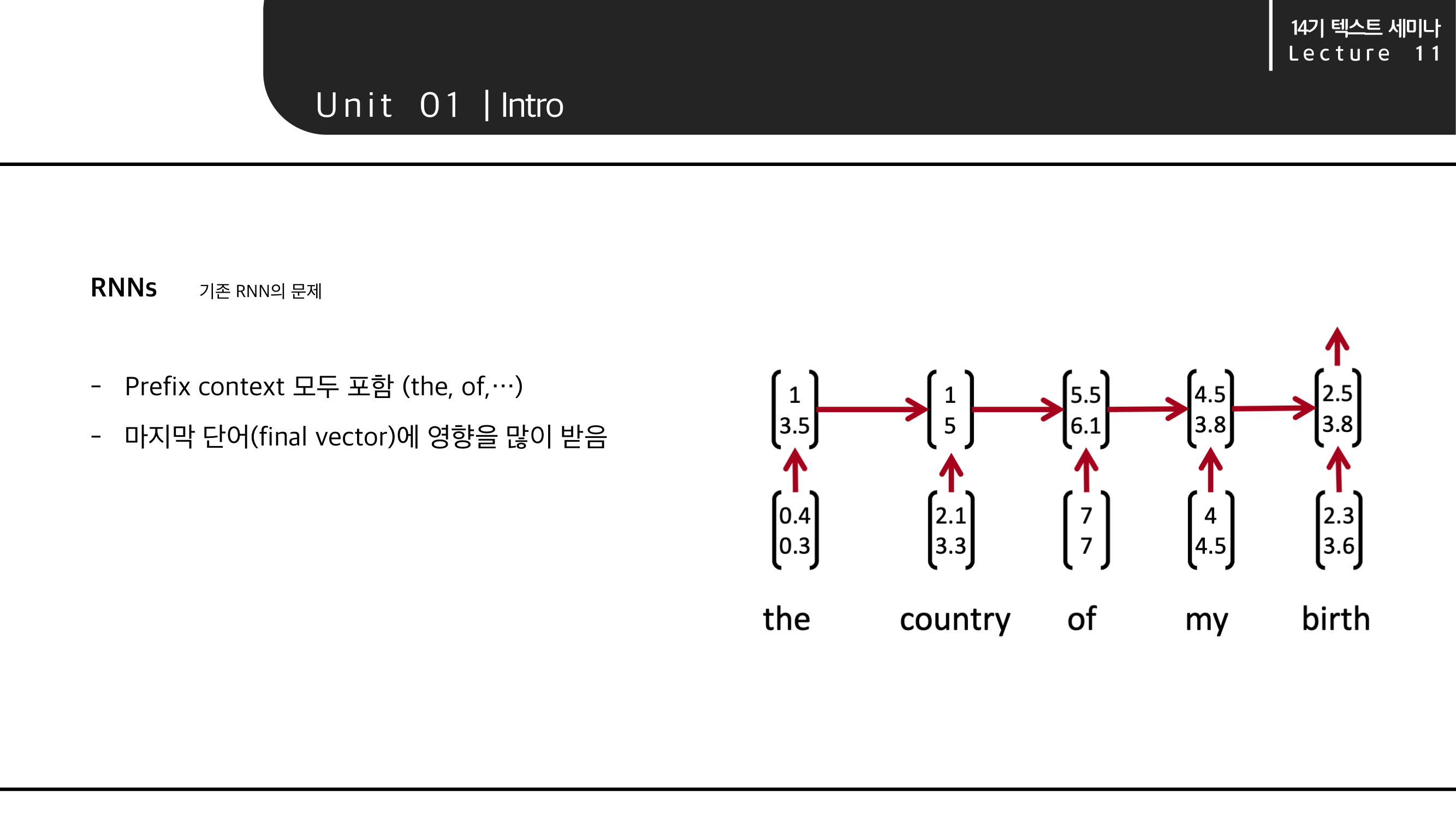
기존 RNN계열의 모델은 the, of,..등의 필요 없는 단어들을 포함하고 마지막 단어(벡터)의 영향을 많이 받는 문제가 있었습니다. 이를 해결하고자 CNN의 개념을 text에도 도입했습니다.

CNN을 텍스트에 도입하면 위와 같은 장단점이 있습니다.
2. 1d Convolution for Text
1d Convolution 계산
filter의 이동 방향이 위아래 밖에 없기 때문에 1d convolution 이라고 부릅니다.
다음과 같이 'tentative deal reached to keep government open' 이라는 문장을 계산해보겠습니다.
convolution 계산

각 단어는 4차원으로 임베딩 되어있는 벡터이고 필터 사이즈(kernel_size)는 3을 사용한다고 가정했을 때, filter 가 움직이면서 dot product(내적) 값을 계산하면 오른쪽 표와 같이 7*4의 문장이 5*1로 계산됩니다.

필터 갯수 : 이 때 크기3의 필터를 3개 사용한다면 5*3 의 matrix로 계산됩니다.

필터 크기 : 필터 크기를 조정해서 n-gram의 다양한 feature를 만들 수 있습니다.
다양하고 많은 filter를 사용해서 output의 차원을 늘릴수록, feature를 많이 사용할 수록, 기존 문장에 대한 정보량이 커지게 됩니다.
pooling 계산

pooling은 다음과 같이 Max pooling, average pooling, k-max pooling 등을 사용할 수 있습니다. 다만 NLP에서는 max pooling을 선호합니다. 정보가 모든 token에 골고루 있는 것이 아니라 sparse하게 있기 때문입니다.
stride, local max pooling, dilation 계산

stride는 기존 이미지에서 사용되는 CNN의 개념과 동일하게 건너뛰는 칸의 크기 입니다.
이 때 stride=2와 local max pooling을 같이 사용하면, 2개씩 보면서(striding) pooling을 하는 것입니다. 하지만 이 방법은 NLP에서 잘 사용하지 않습니다.
dilation 에 대한 내용은 이해를 돕기 위한 움직이는 이미지가 잘 첨부되어 있는 링크를 첨부합니다.
https://zzsza.github.io/data/2018/02/23/introduction-convolution/
3. CNN for Classification
classification을 위한 CNN에 대한 설명으로는 Yoon Kim의 논문 Convolution Neural Networks for Sentence Classification 을 살보겠습니다.
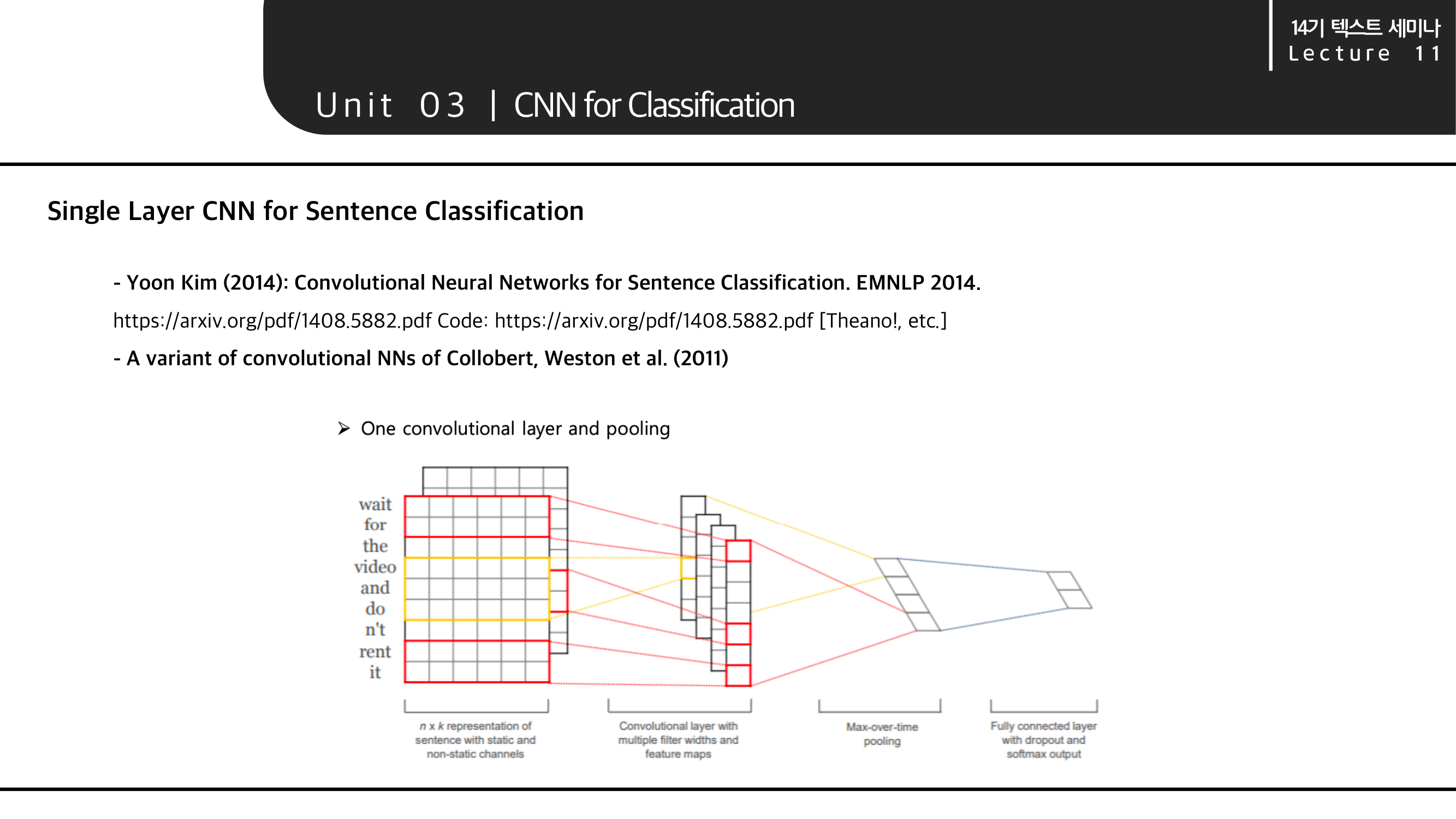
전체적인 convolution layer와 pooling layer의 구조입니다.
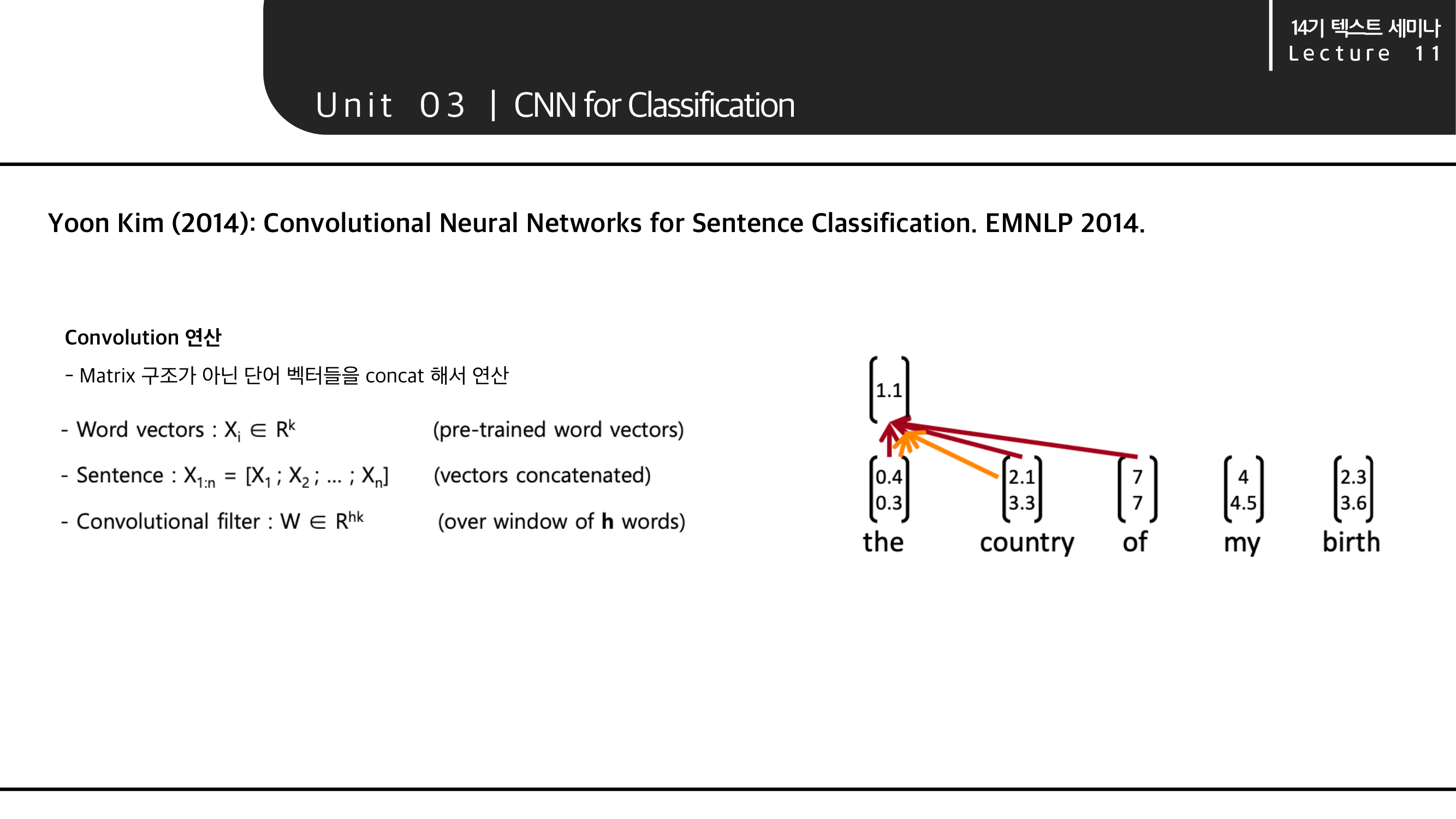
파라미터 및 표현은 위와 같습니다. convolustion 연산에서는 각 단어들을 matrix 구조가 아니라 단어 벡터를 단순히 concat 해서 연산한다고 합니다.

따라서 식으로 나타내면 다음 C_i 와 같이 표현 할 수 있습니다.
피쳐맵 결과는 c로 n-h+1의 차원이 됩니다. 이는 n개의 단어로 이루어진 문장이 있고 h 크기의 window 를 가질 때의 결과입니다.

pooling 연산에서는 피쳐맵 결과인 c를 max pooling 합니다.
max pooling을 함으로써 filter 들의 변화와 다양한 문장 길이에 대해 대처 가능합니다. 본문에서는 filter size 3,4,5 의 필터를 각각 100개씩 feature map 으로 사용했다고 합니다.

input으로 넣는 것은 워드 임베딩으로 임베딩 된 벡터를 넣었습니다. 기존의 pre-trained word vectors(word2vec of GloVe) 로 초기화 시켰고, fine tunning 한 것(static)과 fine tunning 하지 않은 것(non-static)을 둘 다 사용했습니다.
CNN layer를 통과시킨 후 pooling한 최종 벡터(z)를 soft max 를 통해 classification을 수행했습니다. 이 전반적인 과정이 이해가 안가신다면 다시 위의 아키텍처 이미지를 보시면 이해가 수월하실 듯 합니다.
4. 추가 & 정리
Gated units used vertically
cs224n 이번 강의에서는 전반적인 text cnn 내용뿐만 아니라 다음과 같은 추가내용(some toolkit)들이 나옵니다.
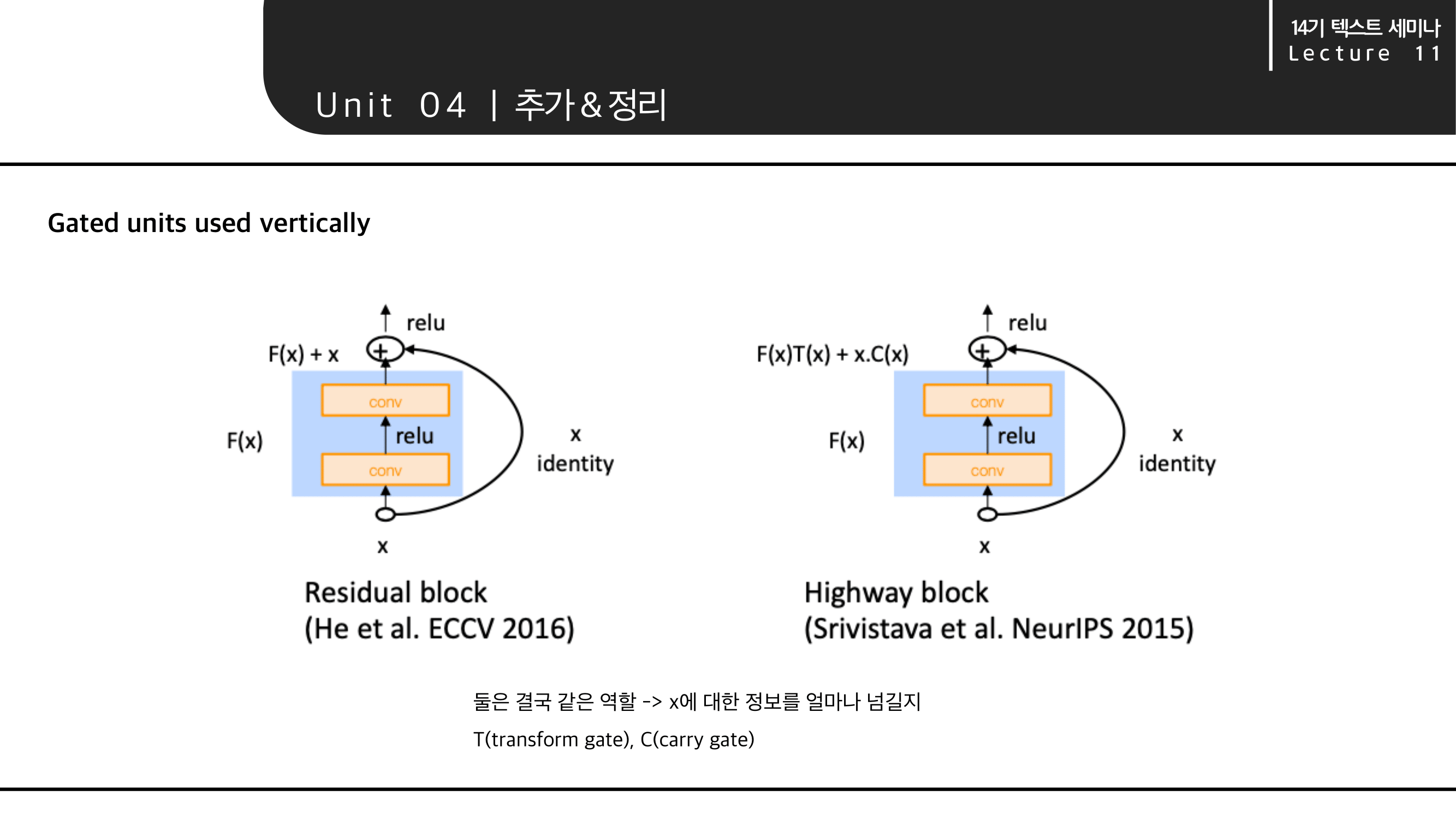
Residual block & Highway block
ResNet에서 나온 Residual block과 Highway block을 비교하며 소개합니다. 두 가지 모두 Shortcut Connection의 개념입니다. 즉 결국 같은 역할로 x에 대한 정보를 얼마나 넘겨줄지 의 개념입니다.
Residual block에서는 F(x) + x 를 사용하고, Highway block은 F(x)T(X) + x.C(x)를 사용하는 점만 차이가 있습니다.
Highway block 식의 T는 transform gate를 의미하고, C는 carry gate를 의미합니다.
Batch Normalization (BatchNorm) & 1x1 Convolutions

Batch Norm 이라고 불리는 Batch Normalization과 1x1 convolustion을 소개합니다. 각 방법은 위와 같은 이유로 사용한다고 합니다.
CNN for NLP

자연어처리, NLP에서의 CNN을 정리하면 위와 같습니다.
- 뉴럴네트워크가 피쳐를 포착하는 순서는 tokens -> multi-word -> expressions -> phrases -> sentence 순입니다. (Captures k-grams hierarchically)
오른쪽 그림과 같이 문장에 대해 CNN layer를 여러 층으로 쌓을 경우를 생각해보면 알 수 있습니다.
즉 '열심히 공부하는 투빅스 입니다'를 CNN layer를 통과하면서 포착한다고 했을 때, 처음에는 열심히 를 포착하고, 다음에는 열심히 공부하는 까지, 그리고 다음에는 열심히 입니다 까지 포착할 수 있습니다. - CNN의 최대 장점은 구현이 굉장이 잘 되어 있어서 사용하기 편하다는 것입니다. 다양한 분야에서 사용되기 때문에 이미 구현체가 많이 존재합니다. 따라서 가져다가 사용하기만 하면 됩니다.
- 하지만 CNN으로만 레이어를 쌓고자 한다면 첫 단어와 마지막 단어를 잘 포착하기 뒤해서 많은 convolution layer가 필요합니다.
- 그리고 너무 전체를 보는 RN(Realation Network)과 너무 local하게 포착하는 CNN의 장점을 합쳐서 나오게 된 것이 Self Attention입니다.
모델 분류

NLP모델은 위와 같이 분류됩니다.
5. Deep CNN for NLP

이미지나 다른 분야에서는 레이어를 정말 'Deep'하게 쌓고는 합니다. 따라서 이 강의에서도 NLP 분야에도 깊은 모델이 있다는 것을 소개합니다.
VD-CNN은 Text Classificaion을 위해 깊은 CNN 네트워크를 사용한 논문입니다.
회색 박스와 같이 구성된 block을 쌓아서 오른쪽 그림의 아키텍처로 이루어져 있습니다. 이미지 분야의 VGG-Net 이나 ResNet을 닮았지만 그렇게 깊지 않습니다.
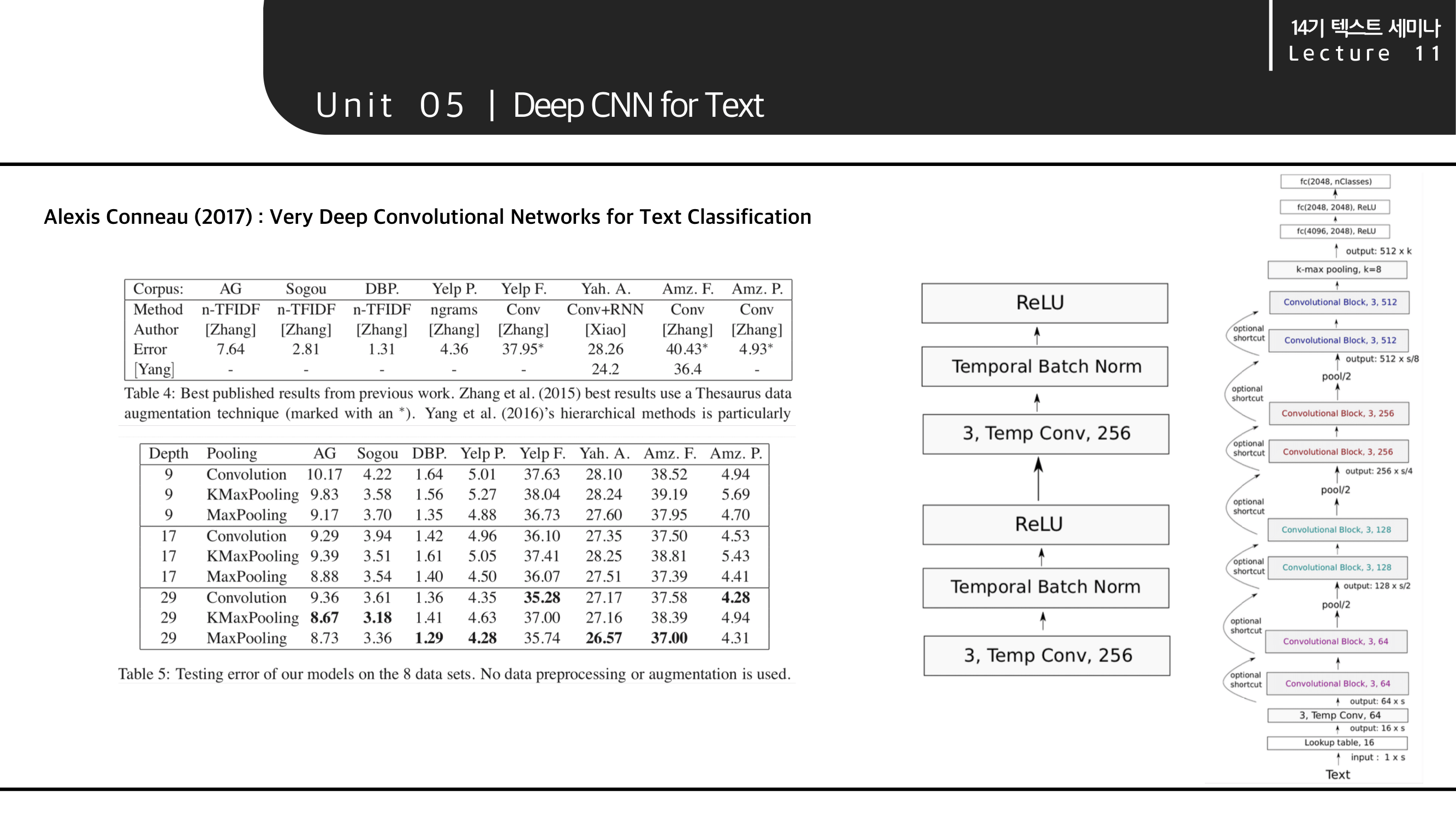
VD-CNN의 다양한 데이터에 대한 실험 결과를 보여줍니다. 대체로 29 layer 이상의 깊이로 쌓은 것에서 성능이 좋아진 모습을 볼 수 있습니다.
Reference
- CS224N : Natural Language Processing with Deep Learning Stanford, Winter 2019
- DSBA 연구실 CS224N 세미나 강의 자료
- 건국대학교 컴퓨터공학부 인공지능 수업
- 조경현 교수님의 딥러닝을 이용한 자연어처리
