Lecture 8 – Translation, Seq2Seq, Attention

작성자 : 성균관대학교 소비자학과 김재희
Pre-Neural Machine Translation
- 기계번역(Machine Translation): 특정 언어의 문장을 다른 언어의 문장으로 번역하는 태스크.
1. Rule Based(1950s)
최초의 시도는 1950년대 초반 러시아어를 영어로 번역하여 냉전에서 우위를 점하려던 영국에서 시작되었습니다. 이때의 시스템은 원시적으로 구성되었습니다. 단순한 규칙 기반 방법론으로, 러시아어-영어 사전을 구축하고, 이를 이용해 러시아어에 매칭되는 영어 단어를 찾는 방식이었습니다. 이후에도 문법을 중심으로 번역하는 규칙 기반 방법론이 개발되었지만, 어마무시한 비용이 투입되어야 했습니다.
2. Statistical Machine Translation(1990s ~ 2010s)
딥러닝이 발전하기 전의 기계번역은 주로 통계기반 기계 번역이 주를 이루었습니다. 프랑스어 -> 영어 번역을 예시로 들어봅시다.
우리가 모델을 통해 달성하고자 하는 것을 영어 문장(y), 프랑스어 문장(x)를 이용해 식으로 표현해보면 다음과 같습니다.
즉, 프랑스어 문장이 주어지면, 이에 가장 적절하고 그럴듯한 영어 문장 y를 찾는 것입니다. 그리고 위의 식을 베이지안 룰을 이용해 풀어보면 다음과 같이 바뀌게 됩니다.
위 식은 두 항으로 이루어져 있습니다.
- (Translation Model): 이 항은 영어 문장이 주어졌을 때, 프랑스어 문장의 확률분포를 생성하는 번역 모델을 이루는 항입니다. 이때, y는 기존의 영어 문장에 비해 짧은 단위로 구나 절, 혹은 단어로 되어 있습니다. 번역 모델은 동일한 뜻의 영어와 프랑스어 문장이 짝을 이루고 있는 병렬 말뭉치(pharallel data)를 통해 학습시킬 수 있습니다.
- (Language Model): 이 부분은 우리가 이전의 강의들에서 배웠던 Langage Model을 통해 표현되는 항입니다. 즉, 현재 y의 문장이 얼마나 영어 문장으로서 자연스러운지 확률분포를 통해 표현하게 됩니다. Language Model은 이전에도 배웠듯이, 단일 언어 데이터로 학습시킬 수 있습니다.
우리가 이전에 Language Model을 배웠으니 항은 어떻게 학습시킬 수 있는지 알고 있습니다. 그런데 어떻게 항을 학습시킬 수 있을까요?
2-1. Learning for SMT
번역 모델을 학습시키기 위해선 병렬 데이터가 필요하다고 했습니다. 병렬 말뭉치는 사람이 직접 작성한 동일 내용에 대한 두 언어의 문장 대 문장 혹은 문단 대 문단의 데이터입니다.

그리고 이를 이용할 때, 한가지 개념이 더 추가됩니다. "정렬"입니다. 정렬은 단어 단위의 두 언어 간의 동치 관계를 의미합니다.
정렬을 식에 삽입하면, 다음과 같습니다.
: y 문장이 주어졌을 때, x가 a의 정렬로 되어 있을 확률을 의미합니다.
2-1-1. Alignment

프랑스어 -> 영어 예시로 돌아오자면, 영어 문장과 프랑스어 단어는 위와 같이 거의 1대 1 대응 관계를 보이고 있습니다. 그래서 오른쪽 표에서 한칸씩 아래로 내려가며 정렬된 것을 알 수 있습니다. 여기서 프랑스어 Le는 영어에 대응되는 단어가 없습니다. 이를 가짜(spurious) 단어라고 합니다.
하지만 모든 번역이 이렇게 1대 1 대응관계를 통해 이루어지지 않습니다.
Many to One
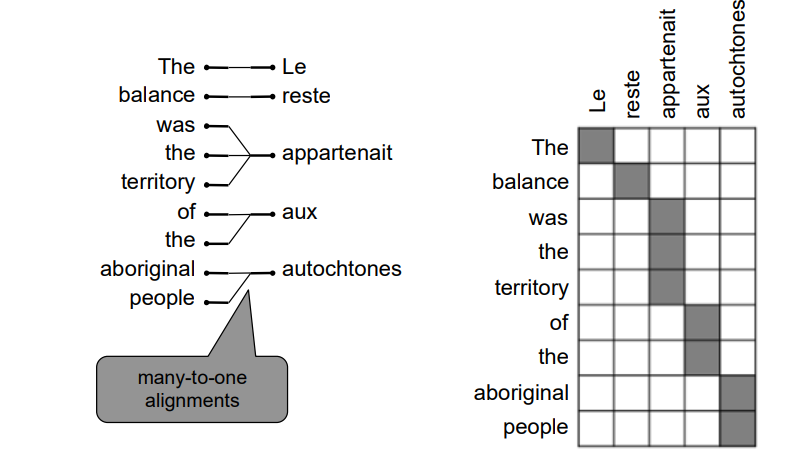
위에서 여러 영어 단어가 하나의 프랑스어 단어에 대응되는 모습을 보이고 있습니다. 이러한 경우를 many-to-one이라고 합니다.
One to Many
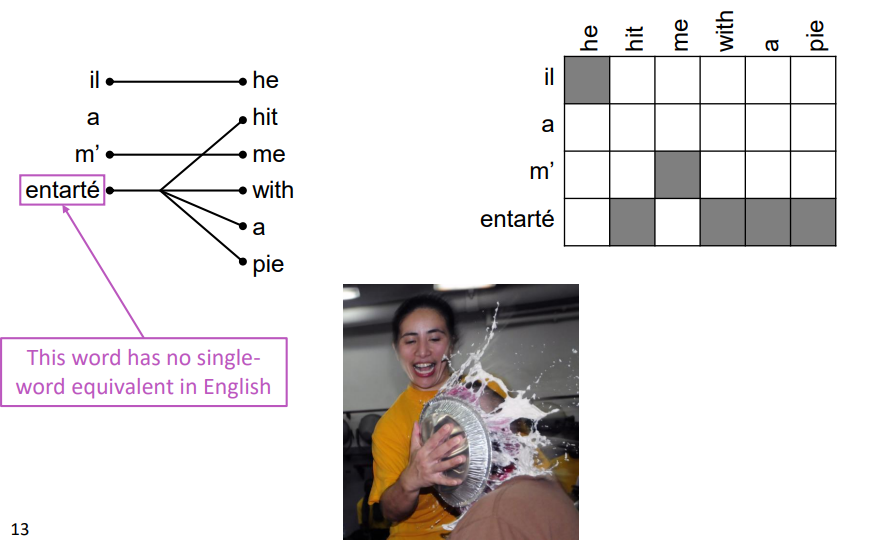
반대로 하나의 프랑스어가 여러 영단어의 뜻을 내포하고 있을 때도 있습니다. entarte라는 단어는 "파이로 어떤 사람을 때리다"라는 뜻이라고 합니다. 하지만 이를 뜻하는 영어 단어는 없고, "hit with a pie"라는 구로 대체되어야 합니다. 이럴 때, one에 해당하는 단어를 번역 시 여러 단어로 나눠진다는 의미에서 fertile word라고 합니다.
Many-to-Many
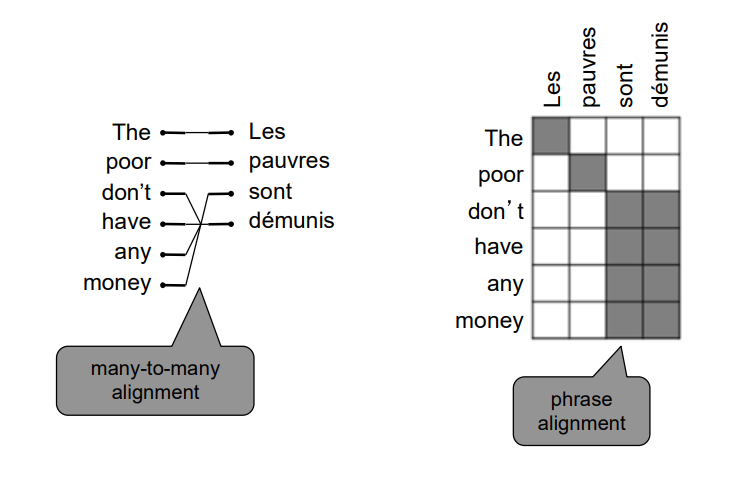
영어의 여러 단어가 프랑스어의 여러 단어와 대응되는 경우도 있습니다.
이처럼 번역은 단순히 단어끼리의 매칭으로 해결할 수 없습니다. 단어의 위치와 다른 단어와의 관계도 살펴야 합니다. 조금 상상해봐도 쉽게 모델이 학습할 수 있지 않아 보입니다. 어떻게 이러한 정렬 관계를 학습시키는 걸까요?
다시 식으로 돌아오면
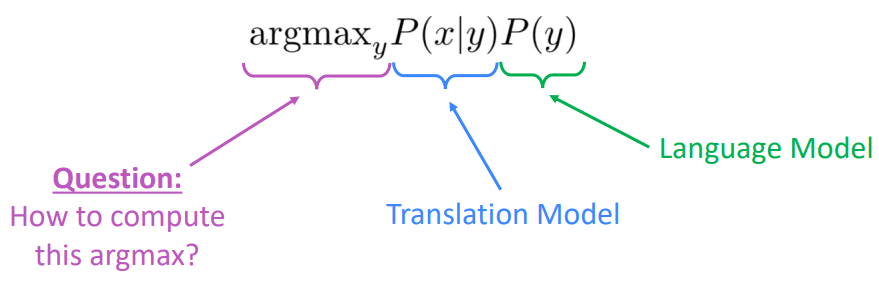
우리가 프랑스어에서 영어로 번역할 때, 영어의 어떠한 단어들이 등장해야 그럴듯한 번역문이 될지 계산하는 것이 위의 식입니다.
가장 단순한 방법은, 모든 경우의 수를 모두 계산하는 것입니다. 100만개의 영어 단어가 있다면, 매 시점마다 100만개의 단어가 나타날 조합을 계산합니다. 하지만 이렇게 된다면 정말정말 계산량이 많아지고 비효율적일 수 밖에 없습니다.
다른 방법으론 휴리스틱 알고리즘을 사용하는 것이 있습니다. 시점마다 확률이 너무 낮은 단어들은 제외하고 경우의 수를 계산하게 됩니다. 그리고 이를 decoding이라고 합니다.
decoding은 나중에 좀 더 자세히 설명하기로 하고, 단순하게 설명하자면 다음과 같습니다.
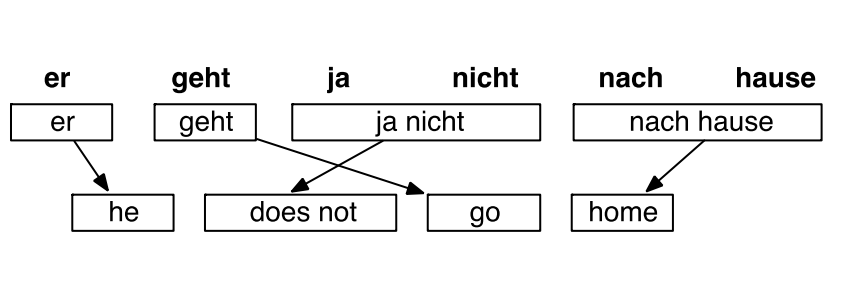
독일어 -> 영어 번역 태스크에서 위와 같이 번역되어야 할때,
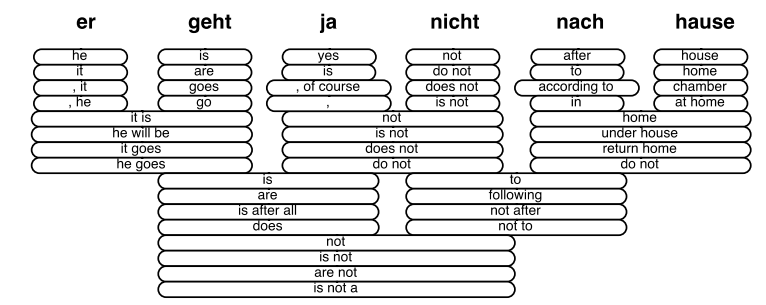
각 독일어 단어는 위와 같은 영어 단어로 번역될 수 있습니다. 가장 오른쪽의 hause는 house, home, chamber, at home으로 번역 될 수 있습니다. 이 중에, 가장 확률이 높은 house를 선택합니다. 그렇다면, 이제 house 외에 home, chamber, at home으로 번역될 가능성은 계산하지 않습니다. 트리구조로 생각하면, house 외의 노드를 prunning하는 것으로 볼 수 있습니다. 그리고 nach와 house의 뜻으로 사용될 경우의 hause를 고려하면 home이 가장 확률이 높으므로 나머지 영어 단어 후보들은 계산에서 제외합니다.
이 방식을 반복하여 사용하게 됩니다.
2-1-2. Summary
통계기반 기계 번역을 요약하면 다음과 같습니다.
- 2010년대까지 기계 번역에서 주류를 이루던 연구 분야였습니다.
- 가장 좋은 성능을 보였지만 너무 복잡한 구조를 가지고 있었습니다.
- 수많은 요소들이 사용되었습니다.
- 사람이 직접 feature engineering을 하여 자원이 많이 투입될 수 밖에 없었습니다.
- 유지 보수에 있어서도 각각의 언어 짝(영어-프랑스어, 영어-독일어, 한국어-영어)마다 다르게 적용되기 때문에 많은 자원이 투입될 수 밖에 없었습니다.
Nerual Machine Translation
신경망 기계 번역이 2014년 등장하게 됩니다. 이는 하나의 신경망 네트워크를 이용해 번역 작업을 수행해보려는 시도였습니다. 이때 사용했던 모델은 seq2seq으로 불립니다. seq2seq은 입력된 시퀀스와 다른 도메인의 시퀀스를 출력하는 태스크에 사용되는 모델입니다. 자연어 처리에선 문장을 입력받아 다른 문장을 생성하는 태스크라고 볼 수 있을 것 같습니다.
당시 사용된 모델 구조는 인코더 단의 rnn 하나, 디코더 단의 rnn 하나로 아주 단순한 모델이었습니다.
1. Model Architecture
모델 구조는 다음과 같습니다. 프랑스어 -> 영어 번역을 예시로 하겠습니다.
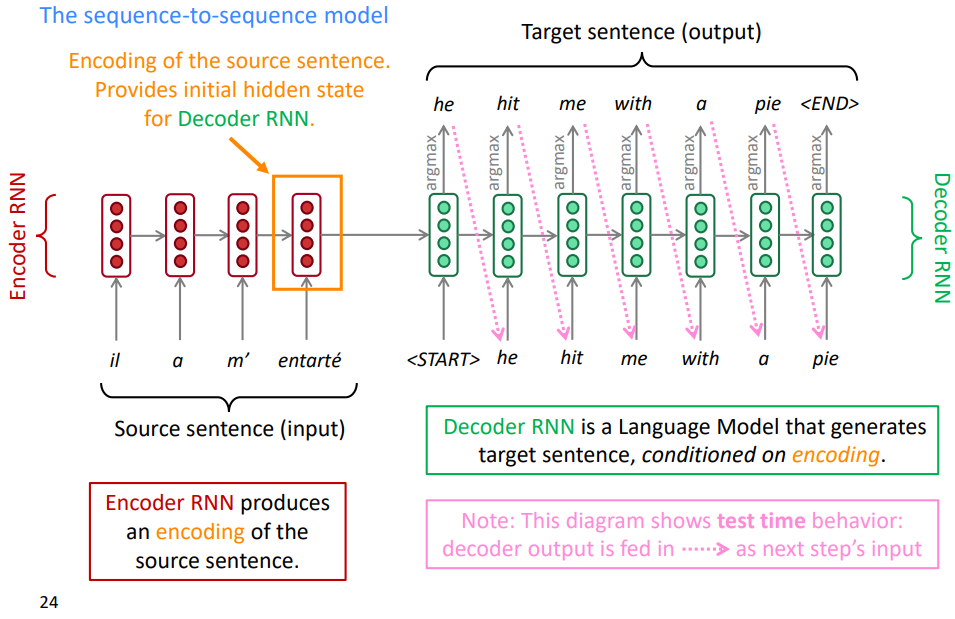
1-1. Encoder
왼쪽의 인코더 단에는 번역에 사용될 프랑스어 문장이 입력됩니다. 이때, 각 단어의 임베딩 벡터가 각 시점마다 입력값으로 사용되게 됩니다. 이는 bidrectional rnn, LSTM, GRU등 rnn류의 모델이면 무엇이든 사용할 수 있습니다. 마지막 시점의 hidden state는 프랑스어 문장의 정보를 담고 있는 벡터가 되어 디코더 단의 hidden state로 정보를 전달하게 됩니다.
1-2. Decoder
오른쪽의 디코더 단의 첫번째 입력값은 문장의 시작을 의미하는 start 토큰입니다. 인코더의 마지막 hidden state에서 넘어온 프랑스어 정보와 문장의 시작을 의미하는 입력값을 받아 디코더는 첫번째 번역 단어인 he를 내놓게 됩니다. 그리고 번역 태스크는 문장 생성 태스크이므로, 다음에 올 단어를 예측하기 위해, 첫번째 시점의 예측값인 he가 두번째 시점의 입력값으로 사용되게 됩니다. 이런 식으로 이전 시점의 예측값이 현재 시점의 입력값으로 반복하여 사용되게 됩니다. 만약 디코더가 문장의 마지막을 의미하는 end 토큰을 출력한다면, 예측은 끝나게 됩니다.

이를 식으로 표현하면 위와 같이 표현할 수 있습니다. 번역하고자 하는 문장이 인코딩된 벡터 x가 주어졌을 때 우리가 생성하고자 하는 y y의 확률분포는 x와 이전 시점까지 생성된 가 주어졌을 때 해당 시점의 토큰 확률의 곱입니다.
이는 디코더가 인코딩이라는 조건을 가지고 있는 언어 모델임을 의미합니다. 즉, 디코더는 인코딩을 조건으로 가지는 조건부 언어모델입니다.
위의 내용은 예측 과정을 보여주고 있습니다. NMT의 훈련 과정은 예측과 다른 과정으로 진행됩니다. 이는 나중에 보여드리도록 하겠습니다.
Application
seq2seq은 단순히 기계 번역 태스크에만 사용되지 않습니다. 다음 태스크를 포함하여 매우 다양한 분야에서 사용되고 있습니다.
- 요약 : 긴 텍스트를 입력받아 내용은 유지하되 길이가 짧은 텍스트를 생성하는 태스크입니다.
- 대화 : 맥락을 파악하여 입력받은 말과 자연스레 이어지는 말을 생성하는 태스크입니다.
- 파싱 : 이전에 배웠던 파싱입니다. 파싱을 하나의 시퀀스로 보고 생성하게 됩니다.
- 코드 생성 : 우리가 자연어로 원하는 과정을 입력하면, 자동으로 코드를 만들어주는 태스크입니다.
1-3. Conditional Language Model
위에서 디코더는 인코더를 조건으로 가지는 조건부 언어 모델이라고 했습니다. 이를 좀더 생각해보면 다음과 같습니다.
- 디코더는 이전에 생성한 단어를 기반으로 다음에 나타날 단어 분포를 생성하는 언어 모델입니다.
- 디코더는 시작 언어의 인코딩을 조건으로 단어를 생성하는 조건부 모델입니다.
2. Training a NMT system
위에서 본 예시는 NMT의 예측 과정이라고 했습니다. 그렇다면 어떻게 학습을 시킬까요?
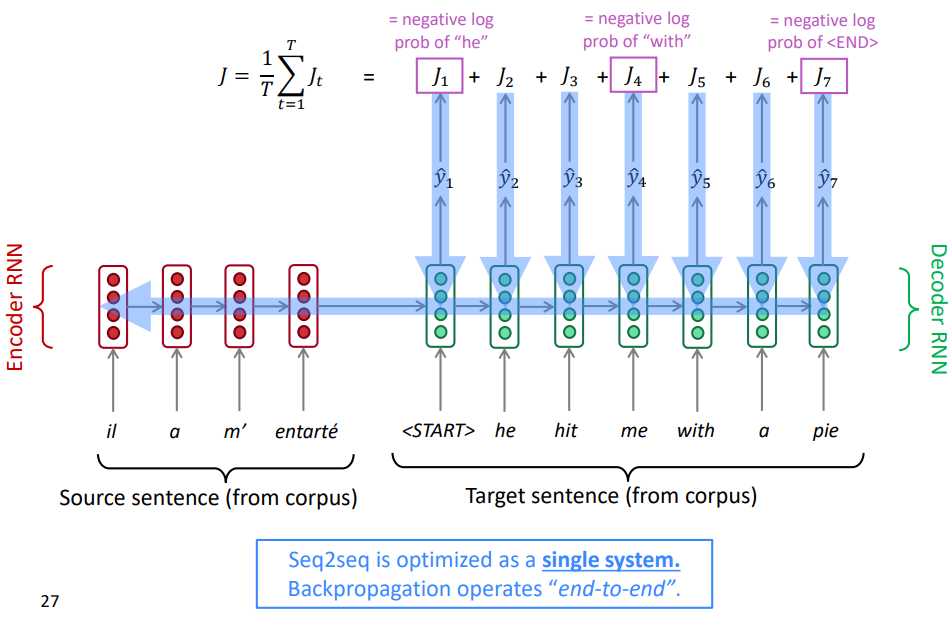
2-1. Forward Propagation
모델 훈련의 순전파 시 예측과 다른 점은, 디코더에도 고정된 입력값이 있다는 것입니다. 예측에서는 직전 시점의 예측 단어가 현재 시점의 입력값으로 사용되었습니다. 하지만, 훈련 과정에선 정확하게 각 시점의 단어를 알고 있어야 학습이 가능해집니다. 랜덤한 초기 파라미터에서 제대로 된 단어를 예측할 수 없기 때문입니다. 그래서 위와 같이 start 토큰부터 pie에 이르기까지 본래 병렬 말뭉치에 존재하는 이전 시점의 영어 단어를 입력값으로 넣어주게 됩니다. 또한, 출력의 마지막 단어는 무조건 end 토큰이어야 합니다.
2-2. Backward Propagation
역전파 과정은 기존의 언어 모델과 비슷합니다. 각 시점의 예측값과 실제값 사이의 손실함수를 계산하고, 이를 평균내어 최종 손실값으로 사용합니다. 이를 인코더 단까지 역전파하여 파라미터를 업데이트 하게 됩니다.
이와 같이 손실값부터 모델의 입력값까지 한번에 역전파가 일어나는 방식을 end-to-end 방식이라고 합니다. end-to-end는 우리가 원하는 태스크의 입력부터 출력까지 하나의 모델로 구성하는 것을 의미합니다. end-to-end 방식을 이용하게 되면, 인코더와 디코더가 해당 태스크에 적합하도록 학습시킬 수 있다는 장점이 있습니다. 다만, 우리가 구축할 인코더 혹은 디코더보다 기존에 사전학습된 언어 모델이 더욱 좋다면 이를 모델에 붙이고 freeze하거나 fine-tuning하여 사용할 수도 있습니다.
3. Generation
모델 구조와 학습 방법까지 살펴봤습니다. 이제 실제로 모델이 번역하는 과정을 살펴보도록 하겠습니다. 이때, 인코더 단에서 발생하는 것은 RNN류의 모델이 hidden state를 전달하는 과정과 다를 것이 없습니다. 그래서 디코더 단에서 발생하는 일에 집중해보도록 하겠습니다.
3-1. Greedy Decoding
이전에 디코더를 설명하면서 이전 시점의 예측 단어가 현재 시점의 입력값으로 사용된다고 이야기 했습니다. 이는 아직 전체 문장의 확률분포를 알고 있지 않음에도 이전 시점에 가장 확률이 높은 단어가 최적의 선택지라고 가정하고 다음 단어를 예측하는 과정입니다. 탐욕 알고리즘이 디코더에 적용된 것이라고 볼 수 있을 것 같습니다. 그래서 이를 greedy decoding이라고 부릅니다.
I'd like to see the world on the giant's shoulder
난
난 거인의
난 거인의 어깨
난 거인의 어깨 위에 있는
난 거인의 어깨 위에 있는 세상이다.
하지만 탐욕 알고리즘의 한계로 인해 greedy decoding은 문제점을 가지고 있습니다. 이전에 예측한 단어가 틀렸을 경우 이후의 예측은 전혀 엉뚱한 결과물을 내게 됩니다. 위의 문장은 "난 거인의 어깨 위에서 세상을 보고 싶다"라고 번역되어야 합니다. 하지만 "어깨 위에서" 대신에 "어깨 위에 있는"이라고 단어를 예측하여 이후 문장이 어색하게 되었습니다.
특히 문장 생성은 이전 시점의 정보만 이용해서 생성되기 때문에 한가지 문장의 경우만 생성하게 되면 의미가 이상해질 위험에 있습니다. 여러 후보 문장을 생성한 다음, 후보 문장들의 완성도를 확인하고 최적의 문장을 선택할 필요가 있습니다.
exhaustive search

디코딩은 위와 같은 식으로 표현될 수 있다고 이야기했습니다. greedy decoding의 문제점을 해결하기 위해서는 정해진 시퀀스 길이 T에 대해 각 시점마다 모든 토큰 조합의 확률을 계산하고 이 중 최대값을 가지는 토큰 조합을 최종 생성 문장으로 선택해야 합니다. 하지만 이는 시간복잡도가 너무 커지게 되어 비효율적입니다. 번역 시 인간이 일부 단어 조합만 고려하여 번역한다는 것을 생각하면 더욱 그렇습니다.
3-2. Beam Search Decoding
그래서 beam search decoding은 beam search algorighm을 이용하여 greedy decoding을 개선하면서 적절한 문장 후보를 고려하고자 고안되었습니다.
beam search decoding은 각 시점마다 가장 그럴듯한 k개의 문장 후보를 탐색합니다. 이 떄 k를 beam size라고 합니다. 각 문장 후보(hypothesis)는 위의 디코딩 식을 이용한 스코어를 가지게 됩니다.
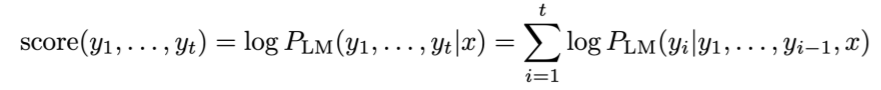
t 시점까지 생성된 문장 후보 y의 스코어는 Language 모델을 이용해 계산한 조건부 확률의 로그 값입니다. 로그 값이기 때문에 그럴듯한 문장일 수록 높은 값(0에 가까운 값)을 가지게 됩니다.
3-2-1. Process
Beam Search Decoding의 과정을 설명하면 다음과 같습니다. 이때 k = 2입니다.
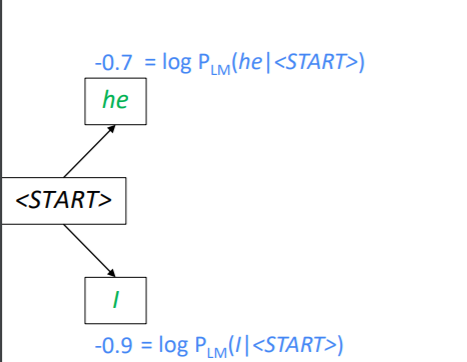
우선 시작 토큰과 인코딩된 hidden state만 이용하여 첫번째 시점의 두가지 가설을 생성합니다. 그리고 이 가설의 스코어를 계산합니다. 이때 he는 -0.7, I는 -0.9로 he가 좀 더 그럴듯해 보입니다.
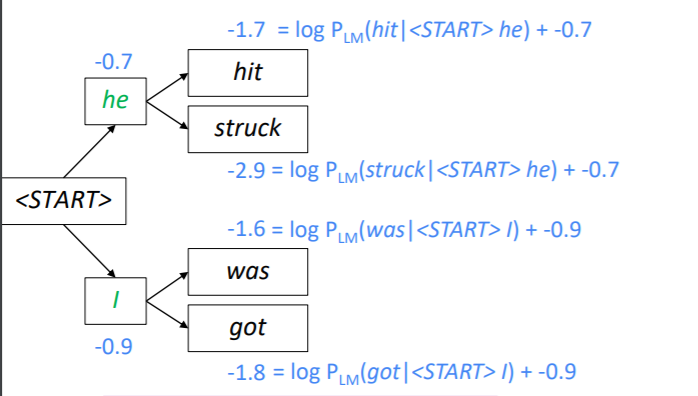
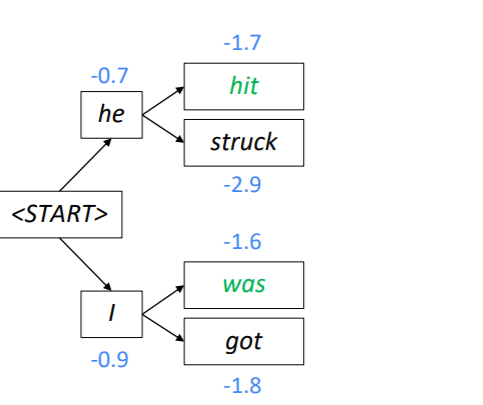
앞서 만든 두 가지 가설에 각각 두 개씩 토큰을 예측하고 스코어를 계산합니다. 이때는 현재 생성된 토큰의 스코어와 이전에 생성된 토큰의 스코어를 더하여 사용하게 됩니다. 그리고 총 네개의 가설 중 k개의 가설만 유지해야 하기 때문에 스코어가 높은 2개의 가설만 남깁니다. 위의 사진에서는 he hit과 I was가 -1.7과 -1.6으로 가설로 살아남았습니다.
위의 과정을 다시 반복해 두 가지 가설에 다시 두 개씩 토큰을 예측하고 스코어를 계산합니다.
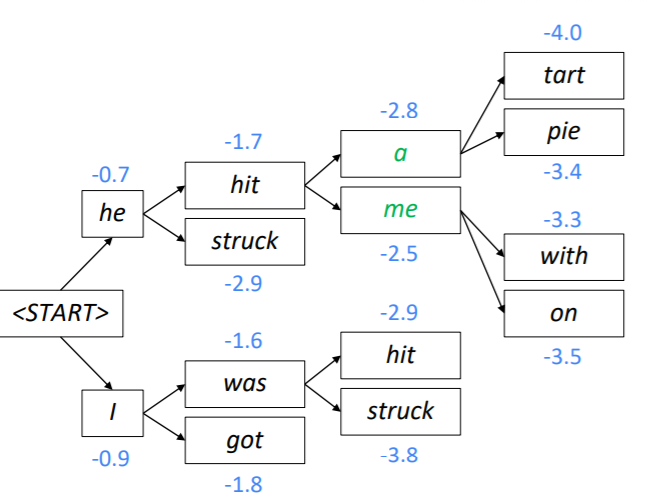
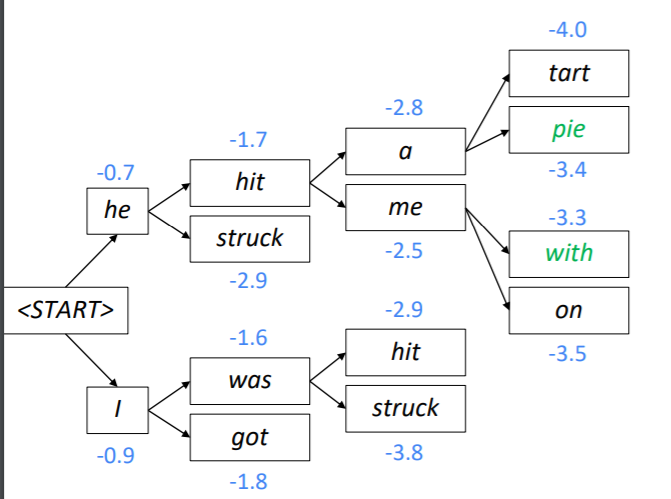
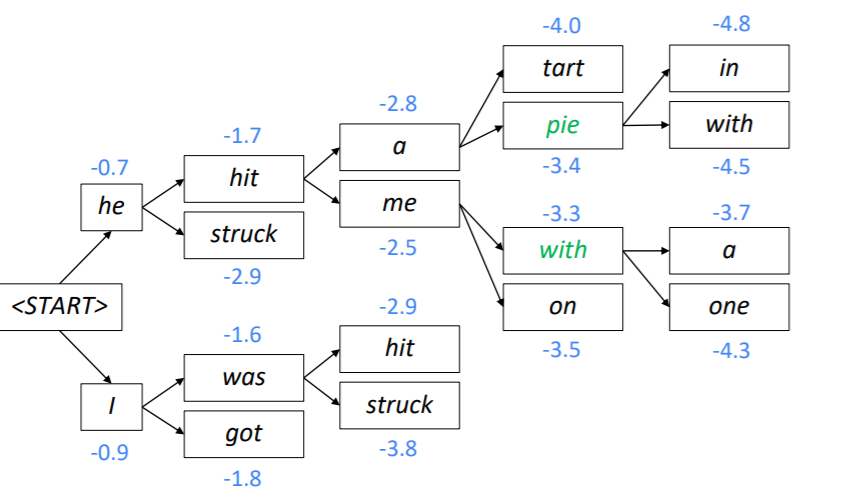
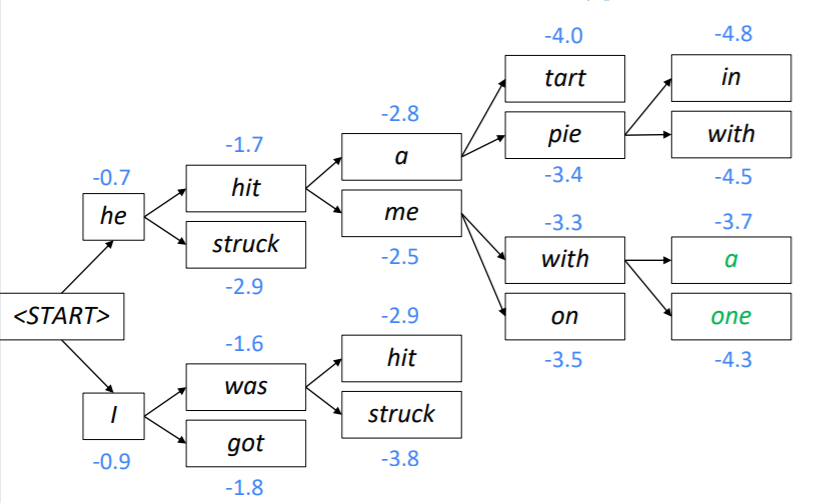

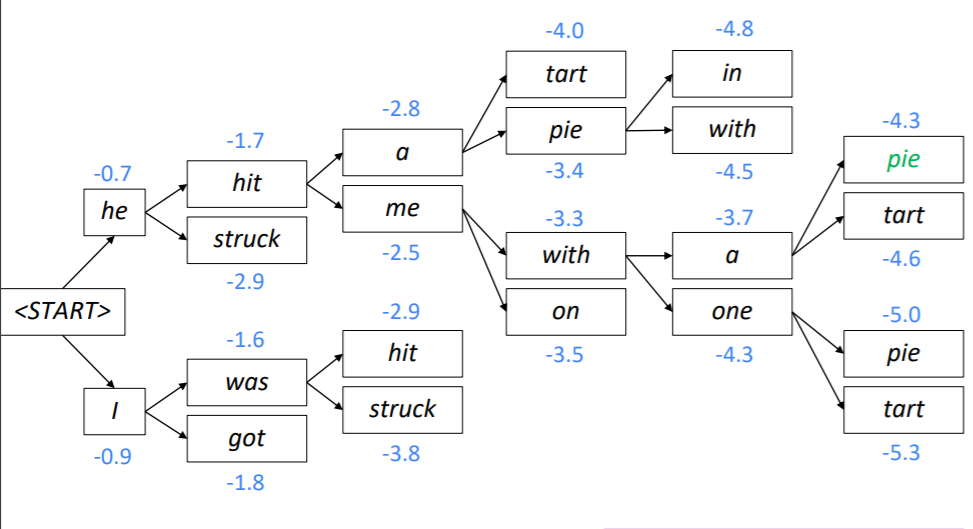
모든 생성이 종료되면 마지막 시점에 가장 스코어가 큰 노드의 경로를 다시 거슬러 올라가면서 문장을 생성하게 됩니다.
greedy encoding에선 모델이 end 토큰을 생성하면 문장 생성을 멈췄습니다. 하지만 beam search decoding에선 하나의 가설이 end 토큰을 생성하더라도 다른 가설이 계속 탐색을 이어가게 되기 때문에 문장 생성이 종료되지 않습니다. 그렇다면 어떻게 문장 생성을 멈추게 할까요? 다음과 같은 두가지 방법이 있습니다.
- 최대 문장 길이 T를 설정하여 T만큼의 깊이만 탐색하고 문장을 선택합니다.
- n개의 문장이 end 토큰을 생성하면 생성을 종료하고 end 토큰을 생성한 문장 중에 최종 문장을 선택합니다.
하지만 이렇게 할 경우 문제가 발생합니다. end 토큰이 생성된 시점이 다르기 때문에 각 가설의 길이는 모두 다를 수 밖에 없습니다. 그리고 스코어는 계속해서 더해지기 때문에 문장의 길이가 길어질수록 스코어가 작아질 수 밖에 없습니다. 이로인해 문장의 길이가 짧은 문장이 자주 선택되는 편향이 발생하게 됩니다. 이는 문장이 그럴듯한 정도와 관계 없이 문장의 길이로 인해 발생하는 편향입니다.
이를 해결하는 방법은 간단합니다. 스코어를 문장의 길이로 나눠주어 nomalize하면 됩니다. 이를 이용하여 최종적인 스코어 식은 다음과 같습니다.

4. Advantages and Disadvantages
NMT가 SMT에 비해 가지는 장점과 단점은 무엇일까요?
장점은 다음과 같습니다.
- 성능이 훨씬 좋다. : NMT는 SMT에 비해 훨씬 자연스러운 문장을 만들어 줍니다. 이는 RNN을 이용하기 때문에 문맥을 고려하고, 단어가 조금 달라진다하더라도 의미적으로 비슷한 문장이라면 비슷하게 해석할 수 있기 때문입니다.
- 관리하기 쉽다. : end-to-end 모델의 특징은 관리가 편리하다는 점입니다. 데이터를 꾸리고 모델을 학습시키면 feature engineering이나 번역을 위한 사소한 일에 투입되는 자원을 줄일 수 있습니다.
단점은 다음과 같습니다.
- 블랙박스 모델이다. : 모든 단점은 블랙박스 모델이라는 점에 기인합니다. 어떠한 원리로 이렇게 번역했는지 알 수 없기 때문에 문제가 발생해도 수정하기 쉽지 않고, 사회적 물의를 일으킬 수 있는 혐오 표현이나 욕설 등의 번역을 관리하는 것이 쉽지 않습니다.
4. BLEU(Bilingual Evaluation Understudy Score)
번역 태스크를 평가할 수 있는 지표로는 BLEU가 있습니다. BLEU는 인간이 번역한 문장과 기계 번역의 문장이 얼마나 유사한지 평가하는 지표입니다. BLEU는 높을수록 성능이 좋습니다. BLEU는 동일한 문장에 대해 여러 사람이 번역한 문장을 이용해 평가할 수 있습니다. 이때 모델이 생성한 문장을 candidate/ca, 사람이 번역한 문장을 reference/ref라고 하겠습니다. BLEU의 계산 방식을 차례대로 살펴보도록 하겠습니다.
4-1. n-gram precision
우선 가장 간단하게는 cadidate에 등장한 단어들이 reference에도 등장했다면, candidate은 정확히 예측했다고 볼 수 있을 것입니다.
n-gram을 이용하여 candidate의 단어가 reference에 얼마나 등장했는지 측정하는 방식입니다.
- candidate : I am a boy who likes summer
- reference 1 : I am just a boy who love sunny days
- reference 2 : I like hot days
위와 같은 candidate과 reference가 있을 때, cadidate의 단어들이 reference에서 등장했다면 이는 옳바른 번역이라고 볼 수 있을 것 입니다. unigram의 경우 summer를 제외한 모든 단어가 reference에 등장했으므로 다음과 같이 계산될 수 있습니다.
하지만 이렇게 계산하면 다음과 같은 문제가 발생합니다.
- candidate : am am am am am am am
- reference 1 : I am just a boy who love sunny days
candidate은 말도 안되는 문장이지만 unigram precision은 referece에 am가 등장했으므로 1이 나와 버립니다. 이를 해결하기 위해서는 candidate과 reference에서 중복을 고려하여 계산할 필요가 있습니다.
4-2. modified n-gram precision
이를 위해 이전 n-gram precision 식에서 분자를 수정해야 합니다. 이때 각 n-gram에 대해 다음과 같은 작업을 수행한다고 합니다.
이를 통해 uni-gram이 ca나 ref에 중복하여 등장하여도 이를 어느정도 완화할 수 있게 됩니다. ref에 자주 등장하지 않은 n-gram인데 ca에 자주 등장했다면, 이는 잘못 번역한 것이라 볼 수 있기 때문에 precision을 낮게 주어야 합니다. 위의 식은 이를 수행하고 있습니다.
하지만 여기서도 문제가 생깁니다.
ref : I don't know how to make BLEU equation.
ca1 : I don't equation how make BLEU to know.
ca2 : make BLEU equation I don't tell how to.
ca1과 ca2 모두 ref의 단어의 순서만 뒤바꾸어 놓았습니다. 이때 n이 얼마이냐에 따라 두 ca에 대한 평가가 달라지게 됩니다.
- unigram : ca1 - 1 / ca2 -
- bi-gram : ca1 - ca2 -
즉, n의 크기에 따라 같은 문장이라도 점수가 판이하게 달라질 수 있습니다. 이를 고려해서 BLEU가 만들어집니다.
4-3. BLEU
: n-gram에 대한 가중치
: modified n-gam precision
위의 식을 통해 다양한 n에 대한 n-gram precision을 종합할 수 있습니다. 하지만 여전히 문제는 있습니다. 위와 같은 경우 만약 ca의 문장이 짧다면 점수가 높게 나오는 경향이 있기 때문입니다. precision에서 분모가 ca의 count이기 때문입니다. 문장이 짧을 수록 패널티를 주는 항이 필요합니다.
4-4. Brevity Penalty
c : cadidate의 길이
r : cadidate과 길이가 가장 비슷한 reference의 길이
ca가 ref보다 길이가 길다면 정상적으로 번역된 길이일 수도 있기 때문에 패널티를 주지 않습니다. 하지만 ca가 길이가 비슷한 ref보다 짧다면 번역이 미완성된 상태일 수 있기 때문에 패널티를 주어 BLEU 점수를 낮춥니다.
4-5. Advantages & Disadvantages
BLEU는 계산 속도도 빠르고 비교적 성능을 잘 대표하는 지표로 사용되고 있습니다. 특히 BLEU는 병렬 데이터를 정렬하는데 사용될 수 있어 활용성이 높습니다.
하지만 실제 번역은 동일한 단어를 사용하지 않아도 좋은 번역이 될 수 있습니다. 병렬 코퍼스의 경우 번역의 표준화 등을 이유로 직역을 기본으로 합니다. 하지만 초월번역 등 우수한 번역의 경우 단순히 단어 단위로 번역하기 보다 그 맥락을 파악하여 전혀 엉뚱한 단어가 등장할 수도 있습니다. BLEU는 이러한 경우 그 성능을 제대로 측정할 수 없다는 단점을 가지고 있습니다.
5. Conclusion
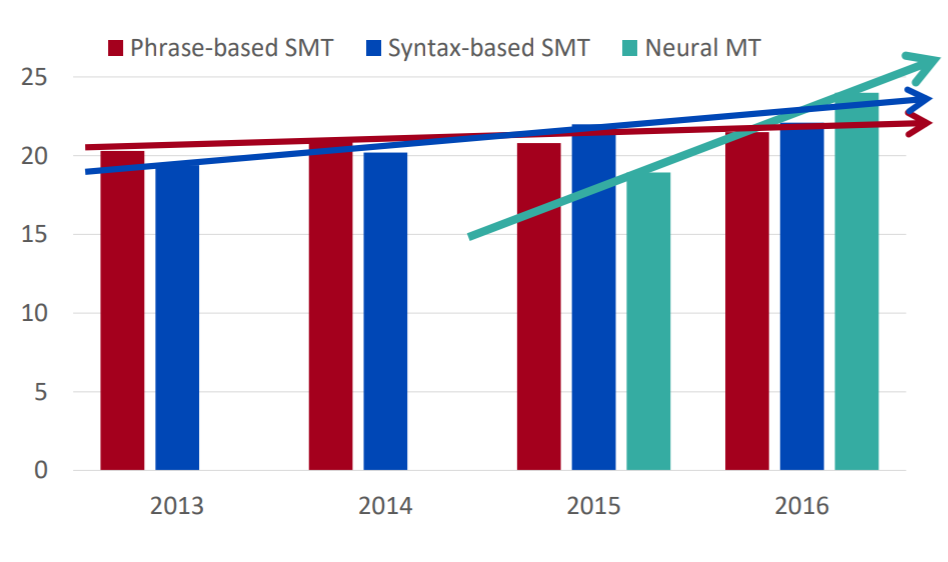
RNN을 이용한 NMT는 기계 번역 분야에서 엄청난 발전을 이뤄냈습니다. SMT가 수많은 feature engineering이 필요하여 장시간 축적된 기술임에도 NMT가 등장한지 2년 만에 SMT의 성능을 넘어섰습니다.
그럼에도 불구하고 NMT는 여전히 문제점이 많았습니다.
-
Out of Vocabulary : 만약 학습 데이터에 존재하지 않는 단어가 입력될 경우 이를 적절히 처리하지 못했습니다.
-
Domain mismatch : 학습 데이터가 위키피디아, 논문, 신문 기사 등 문어체가 주를 이룰 경우 문어체 번역에 애를 먹었습니다.
-
Context : NMT는 맥락을 저장하고 이를 활용하는데 애를 먹습니다. 기사 전문이나 책을 번역하려고 한다면 정말 긴 시간의 정보가 문장 단위를 넘어서 전달되어야 하지만 그렇지 못했습니다.
-
Low Resource Language pairs : NMT 학습을 위해선 방대한 병렬 코퍼스가 필요하지만 이를 구축하는 것은 쉬운 일이 아닙니다.
-
Common Sense is not trained well

프린터가 종이를 먹다 라는 표현은 프린터가 종이에 막혔을 경우에 사용되지만, 이러한 관용적인 표현은 문장에 드러나 있지 않습니다. 사회적 관습이나 활용을 학습해야 하지만 NMT는 이러한 학습이 쉽지 않습니다. -
Social bias
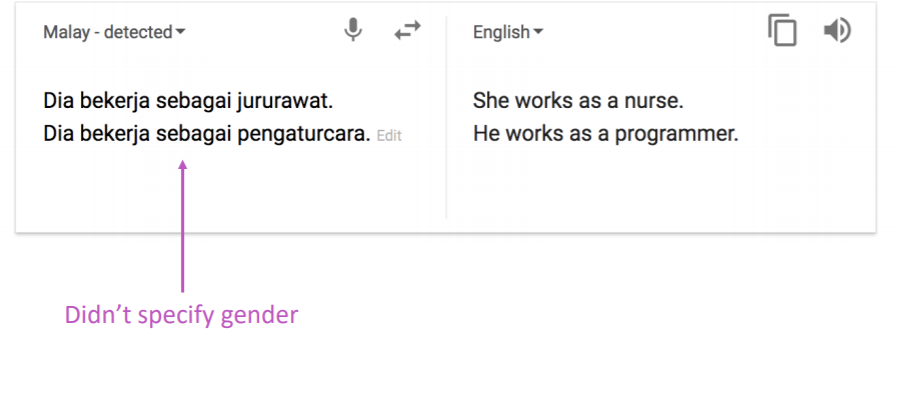
인터넷 상에 존재하는 수많은 문서에는 암묵적인 사회적 편향이 담겨 있습니다. 이는 그대로 NMT에도 학습되게 됩니다. 프로그래머는 주로 남자이고, 간호사는 주로 여자이기 때문에, 이를 학습한 NMT는 성별 중립적인 표현을 입력하여도 자연스레 성별이 편향된 표현으로 번역하게 됩니다.
하지만 NMT는 상당히 어려운 작업이며 NMT를 구축하는 과정에서 새로운 모델이 많이 탄생하게 됩니다. 이제 배울 Attention 역시 이 과정에서 탄생했습니다.
Attention
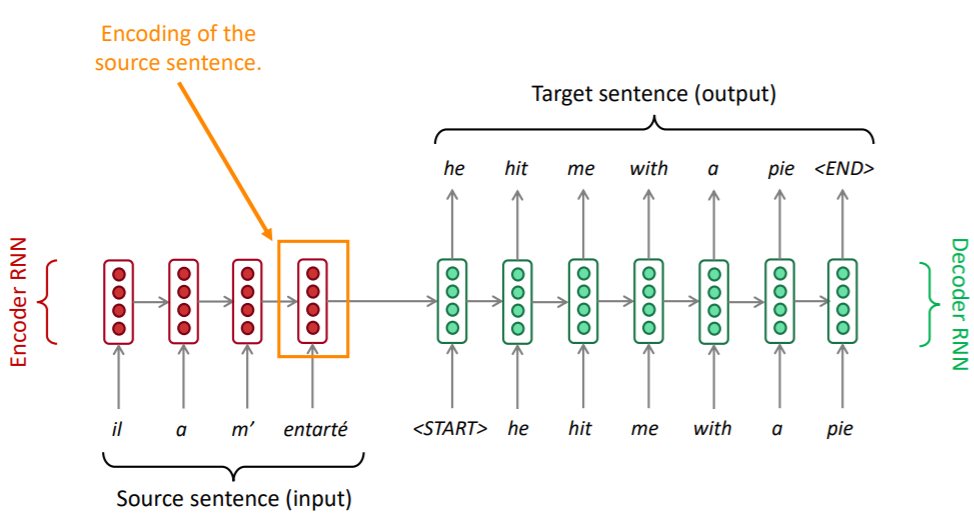
seq2seq의 구조는 위와 같다고 했습니다. 인코더의 마지막 hidden state는 번역하고자 하는 문장의 인코딩입니다. 이는 번역하고자 하는 문장의 정보가 인코더의 마지막 hidden state에 담겨있다고 했습니다.
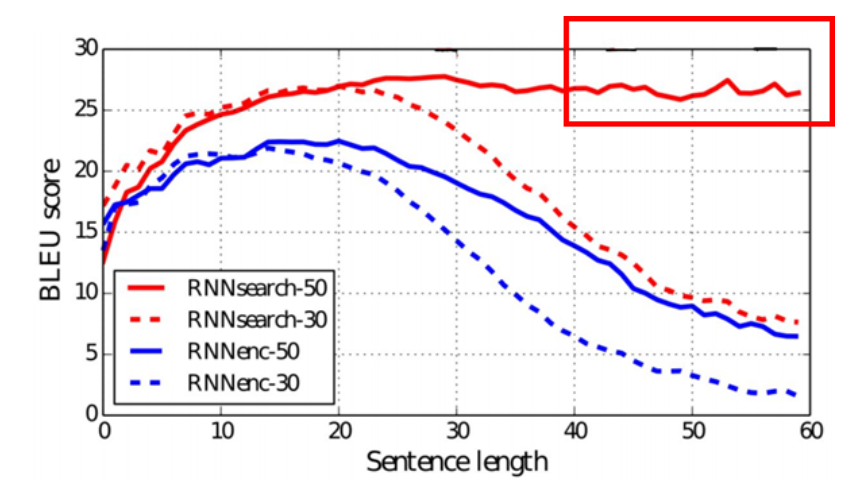
하지만 정말 그렇게 될까요? 만약 인코더의 길이가 50이 된다고 해봅시다. 그렇다면 초기 시점의 정보가 마지막 시점까지 잘 전달되지 못할 것입니다. 이는 초기 시점의 단어들을 번역하는데 어려움을 겪게 합니다. 이를 타게할 방안은 무엇일까요?
SMT에서 alignment가 각 단어간 대응관계를 표현한다고 했습니다. 그리고 SMT는 이 대응 관계를 이용해 번역합니다. 이를 NMT에 활용할 수 없을까요? 그래서 attention 번역된 문장을 생성할 때, 각 문장과 대응되는 원래 단어를 찾아서 활용하는 방안을 고안했습니다.
1. Model Architecture
attention 알고리즘은 다음과 같은 순서로 진행됩니다.
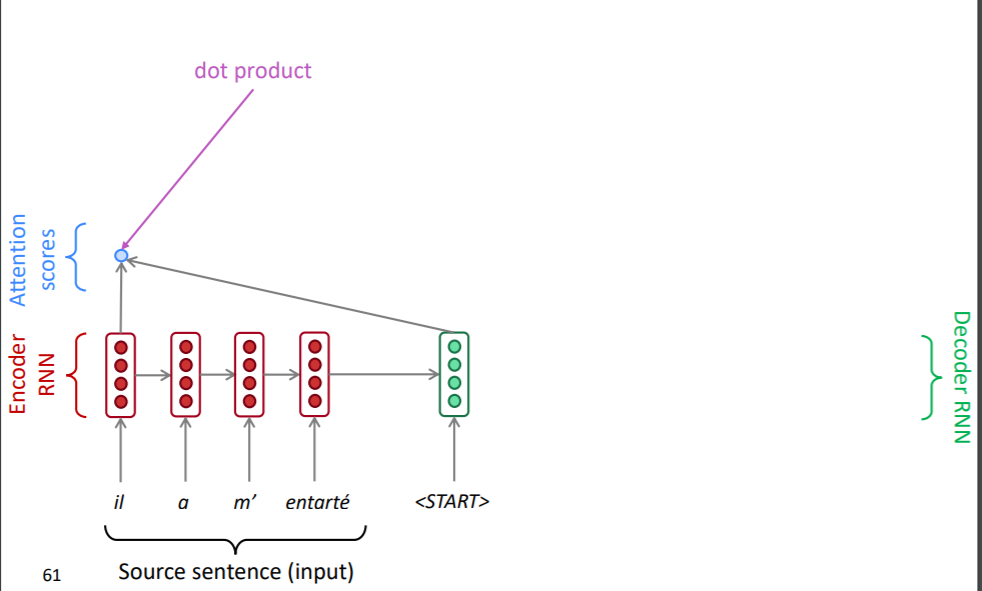
우선 디코더의 hidden state와 인코더의 hidden state를 내적하여 attention score라는 것을 구합니다. 내적은 두 벡터 간 유사도를 구할 때 사용됩니다. 즉, attention score는 현재 시점의 디코더의 정보와 인코더의 매 시점의 정보의 유사도를 의미하고 있습니다.
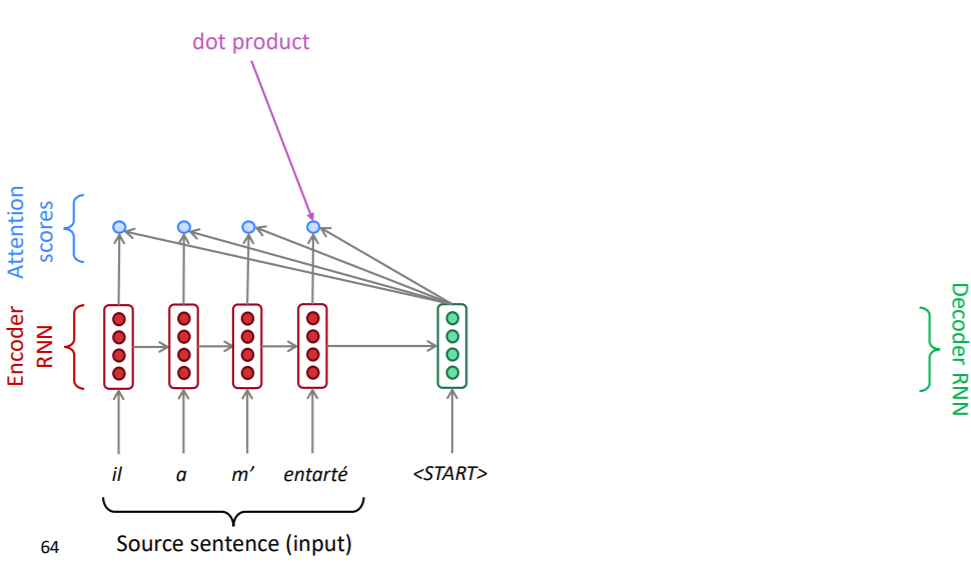
attention score는 인코더의 매 시점마다 계산되게 됩니다.
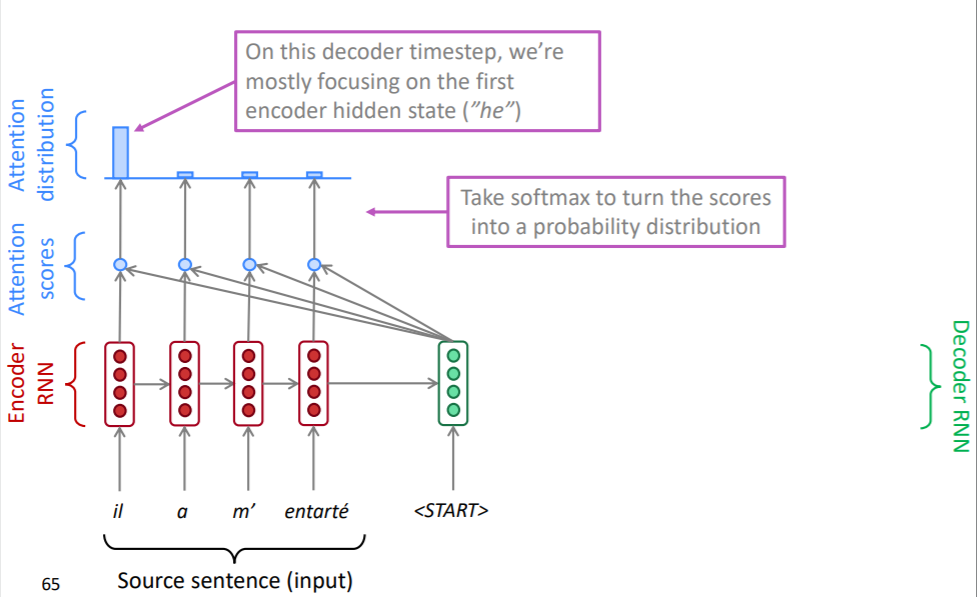
이렇게 구한 attention score를 softmax 함수에 통과시켜 확률 분포를 생성합니다. 이 시점에선 il이라는 단어에 가장 집중하고 있는 것을 볼 수 있습니다. 문장의 시작에선 il이라는 단어가 가장 유사한 정보를 가지고 있는 것입니다.
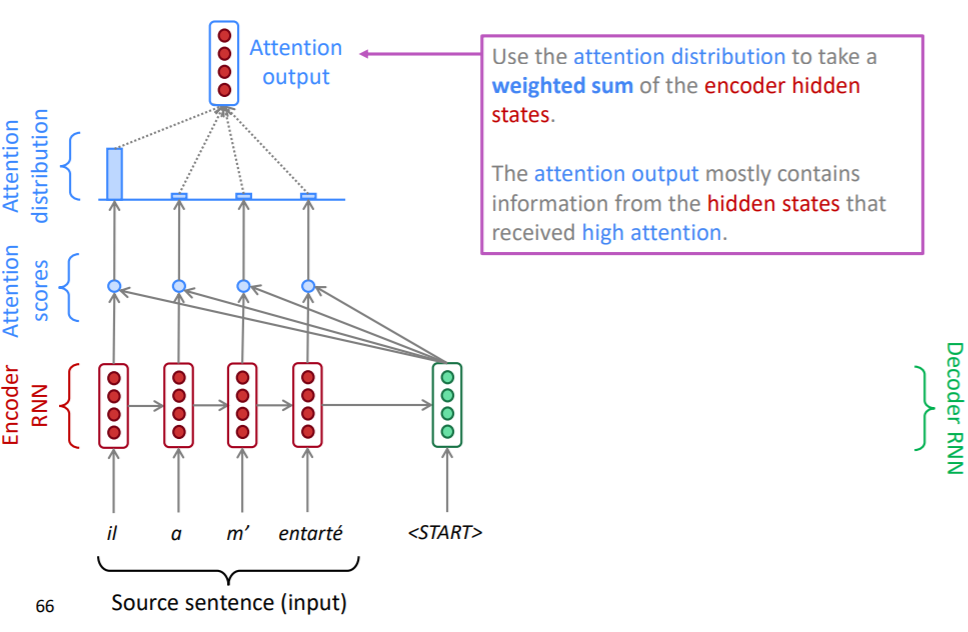
위에서 구한 확률 분포를 가중치로 하여 인코더 각 시점의 hidden state를 가중합해줍니다. 이를 attention output이라고 합니다. 이는 SMT의 aligment와 유사하면서 보다 유연한 사용이 될 수 있습니다. SMT의 aligment는 대응관계를 이진 분류로 표현하기 때문에 완전히 대응되거나, 완전히 고려할 필요가 없다고 여기지만, attention score는 디코더의 정보에 활용될만한 정도를 고려하여 인코더의 정보를 취합했기 때문입니다.
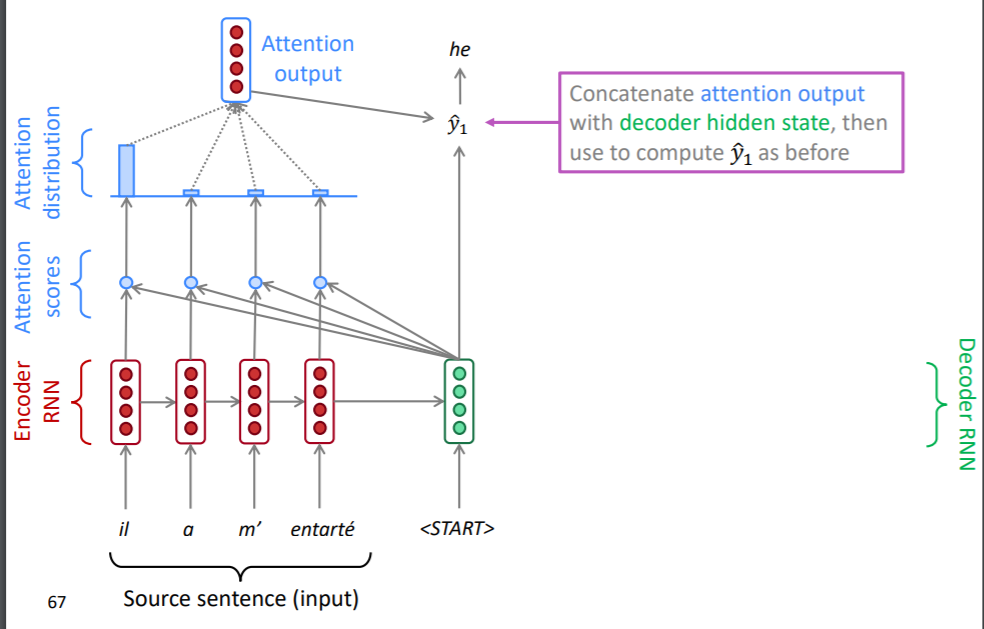
attention output은 디코더의 hidden state와 concat되어 예측값을 산출할 때 사용됩니다. 이때 DNN, softmax 등의 구조를 사용하게 됩니다.
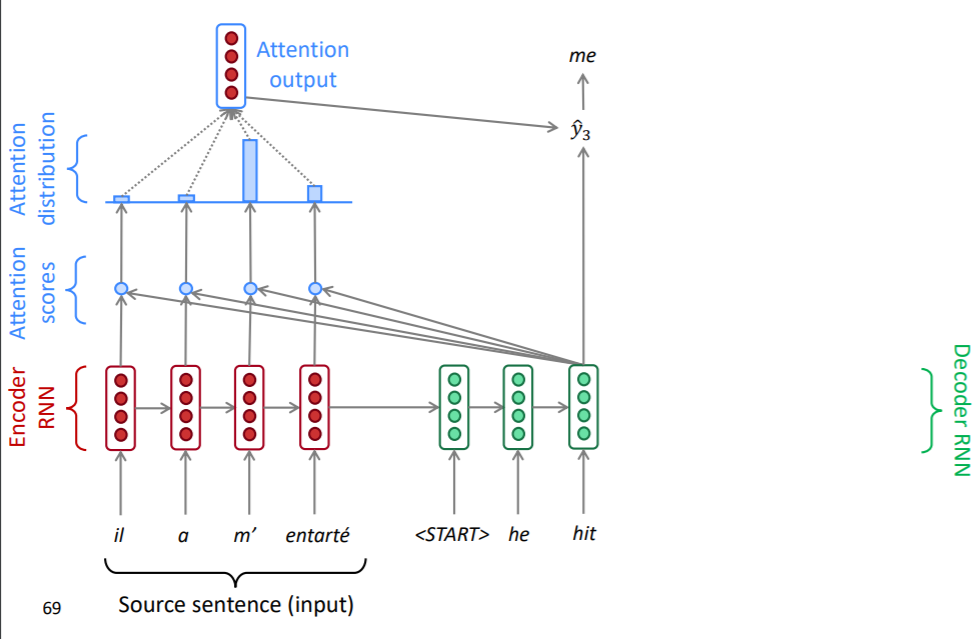
위의 attention 과정은 디코더의 매 시점마다 반복되어 실행됩니다.
2. Equation
- encoder hidden state
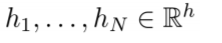
- t 시점의 decoder hidden state
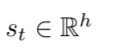
- attention score

- attention dist.
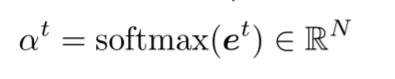
- attention output
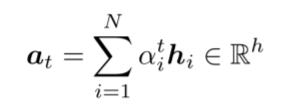
- t 시점의 예측을 위해 사용되는 벡터
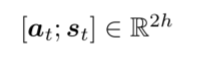
3. Advantages
- NMT 성능을 비약적으로 향상시켰습니다.
- 병목현상을 해결했습니다. seq2seq에선 인코더의 정보가 마지막 hidden state에 집중되어 제대로 전달되지 못하는 병목현상이 발생했지만, attention은 디코더가 직접 인코더의 모든 시점에서 정보를 가져오게 함으로써 이를 해결했습니다.
- vanishing gradient problem을 완화했습니다. attention은 디코더와 인코더를 직접 연결한 구조입니다. 이는 그래디언트가 인코더의 마지막 시점과 디코더의 첫 시점의 연결 뿐 아니라 인코더와 디코더의 각 시점으로 직접 흘러가도록 만들어 vanishing gradient problem을 완화했습니다.
- 모델을 어느정도 해설할 수 있게 만들어줍니다. attention score를 분석하면 모델이 각 시점마다 어디에 집중하고 있는지 알 수 있습니다.
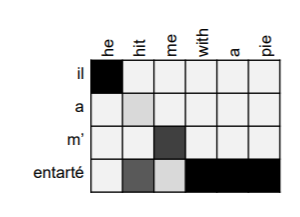
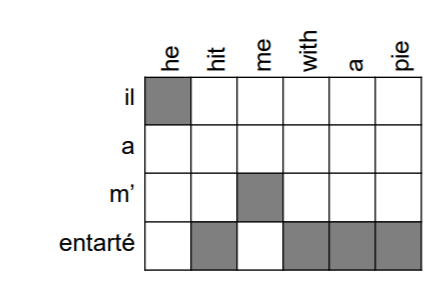
위 사진은 seq2seq with attention에서 attention score를 시각화 한것입니다. 아래 사진은 본래 alignment입니다. 두 도표는 매우 유사한 것을 볼 수 있습니다. SMT의 alignment는 직접 사람이 작성해야 하는 수고가 발생하는 것에 비해 attention은 모델이 직접 구축하고, 보다 유연한 형태라는 점에서 더 우수하다고 할 수 있습니다.
4. Generalization
attention은 단순히 seq2seq에만 사용되지 않고, 많은 모델에서 사용됩니다. 그래서 좀 더 확장된 버전의 attention 정의가 필요합니다. 원문을 가져오자면
Given a set of vector values, and a vector query, attention is a technique to compute a weighted sum of the values,dependent on the query.
즉, 벡터인 value들의 집합과 하나의 벡터인 query가 있을 때, attention은 query를 이용해 value들의 가중합을 구하는 방법론입니다.
그리고 종종 논문 등에서 query attends to the values 와 같은 표현을 볼 수 있는데, 이것이 바로 attention 메커니즘을 설명하고 있는 것입니다.
이렇게 확장할 경우 attention을 다음과 같이 해석할 수 있습니다.
- attention output은 query가 집중하고자 하는 value의 요약된 정보입니다.
- attention은 고정된 벡터 사이즈를 통해 query가 value들의 정보에 접근하는 방식입니다.

참고
https://blog.naver.com/PostView.nhn?blogId=sooftware&logNo=221809101199&from=search&redirect=Log&widgetTypeCall=true&directAccess=false
https://wikidocs.net/31695
https://en.wikipedia.org/wiki/BLEU
https://tech.kakaoenterprise.com/50

10개의 댓글

투빅스 14기 한유진
- seq2seq : 신경망 기계번역(특정 언어의 문장을 다른 언어의 문장으로 번역하는 task)으로 입력된 시퀀스와 다른 도메인의 시퀀스를 출력하는 task에 사용되는 모델입니다. encoder에 번역하고 싶은 문장을 input으로 넣으면 각 단어의 임베딩 벡터가 각 시점마다 입력값으로 사용되어 진행되다가 encoder의 마지막 시점의 hidden state에 담겨있는 정보가 decoder로 들어가게 됩니다. 이와 함께 문장의 시작을 의미하는 입력값을 받아서 첫번째 번역 단어를 내놓게 되고 계속 반복하여 end를 출력하게되면 예측은 끝나게 됩니다. 역전파를 통해 학습하는 과정은 기존의 언어 모델과 비슷합니다. 신경망 기계번역은 통계기반방식보다 성능이 뛰어나고 관리하기 쉽다는 장점이 있지만 모델 설명력이 좋지 않습니다. 인간이 번역한 문장과 기계번역의 문장의 유사도를 평가하는 BLEU지표는 높을수록 성능이 좋음을 의미합니다.
- Attention : 신경망 기계번역에는 많은 문제점들이 존재하고, 구축하는 과정이 어렵기 때문에 새로운 모델이 많이 만들어지는데 그 중 하나가 Attention입니다. decoder의 hidden state와 encoder의 hidden state를 내적하여 attention score를 encoder의 매 시점마다 계산되어 확률분포를 생성합니다. 이를 가중치로 하여 encoder 각시 점의 hidden state를 가중합해준 attention output을 내뱉습니다. 이 값을 decoder의 hidden state와 합쳐 예측값을 산출할때 사용됩니다. 이 과정이 decoder의 매시점마다 반복되는 것 입니다. Attention은 seq2seq에서 발생한 병목현상을 해결하였고 vanishing gradient 문제도 완화시켰습니다. 확장된 Attention의 정의는 value들의 집합과 하나의 query가 있을 때, Attention은 query를 이용해 value들의 가중합을 구하는 방법론이라 할 수 있습니다.
쉽지 않은 내용을 기초부터 차근히 설명해주시고, 잘 적어놓아주셔서 다시 읽어보며 이해하기 좋았습니다. 좋은 강의 감사합니다!

투빅스 15기 이수민
- SMT는 주어진 병렬 데이터로부터 확률 모델을 구축하는 방법론으로, 2010년 초반까지는 machine translation 분야에서 활발하게 사용되었습니다. 다만 병렬 데이터가 충분히 있어야지만 제대로 학습이 가능하고, 구조가 매우 복잡하며 사람들이 직접 feature engineering을 진행하기 때문에 사람의 노력이 많이 들어간다는 한계점을 가집니다.
- 인공신경망 기반의 기계 번역인 NMT 모델은 위에서 언급된 SMT의 단점들을 어느 정도 해결하였습니다. Seq2Seq 모델은 Encoder RNN과 Decoder RNN 파트가 연결되어 구성되어 있으며, 학습 과정에서 두 파트가 연결된 하나의 시스템으로 최적화됩니다. NMT는 기존 SMT 방식에 비해서 매우 높은 성능을 보여주고 있으며, end-to-end 모델이기 때문에 관리가 용이하다는 장점이 있습니다.
- BLEU (Bilingual Evaluation Understudy Score): 번역 태스크를 수행한 후의 결과를 평가할 수 있는 지표로, 인간 번역과 기계 번역 간의 유사도를 측정하는 방법입니다. 활용도가 높고 계산 속도가 빠르다는 장점을 가지고 있어 대표적인 지표로 사용되지만, 실제로 이 지표만을 가지고 번역 태스크를 평가하기에는 한계가 있습니다.
- 각 단어의 대응 관계를 활용하여 기계 번역을 진행하는 SMT의 방법을 NMT에 활용하기 위해 등장한 Attention은 Seq2Seq에서 발생한 병목 현상을 해결하고 vanishing gradient 문제 또한 완화했습니다.
기계 번역의 발전에 따라 나타난 방법론들과 모델에 대해 자세하게 설명해 주셔서 잘 이해할 수 있었습니다. 감사합니다 :)

투빅스 15기 강재영
첫 기계번역의 시도는 각 사전마다 매칭되는 단어를 찾는 Rule Based 방식으로 이루어졌습니다.
하지만 비용이 굉장히 많이 들었고 실제로 단어는 일 대 다로 대응되는 경우가 많아서 ,다른 모델이 필요했습니다.
이를 해결하기 위해 도입된 방법이 Statistical Machine Translation입니다.
- SMT는 확률의 개념을 도입하여 어떤 단어로 번역해야 가장 매끄러울지에 대한 경우의 수를 계산하여 번역을 시도합니다.
- 모든 조합을 고려하는건 비효율적이기 때문에 알고리즘을 사용하여 확률이 낮은 경우는 고려하지 않습니다.
14년에 SMT의 뒤를 이어 NMT(Neural Machine Trainslation)이 등장합니다.
- 모델의 구조는 RNN 구조의 인코더 , RNN 구조의 디코더로 이루어졌었습니다.(Seq2Seq)
- 이는 단순히 기계번역 Task에만 사용되는 것이 아닌 요약, 대화(생성), 파싱, 코드생성 등에 활용되었습니다.
- 기존에 사용됐던 Greedy decoding의 경우, 이전 예측값이 틀렸을 경우 이후의 예측도 실제값과 전혀 다른 결과가 나온다는 한계가 있었습니다. 이를 개선하여 Beam Search decoding이 사용되었습니다.
- 따라서 NMT는 SMT에 비해 1) 성능이 훨씬 좋다(보다 자연스러운 문장생성) 2) End-to-End 모델로서 관리가 용이함 등의 장점을 얻게되었습니다.
- 하지만 신경망 모델의 한계점인 블랙박스를 벗어나지는 못했습니다.
RNN 혹은 깊은 신경망 모델에서는 항상 Vanishing Gradient 문제가 따라오게 됩니다. NMT에서도 초반부에 입력된 단어를 나중에가서 잊게되어 맥락을 파악하지 못하는 문제가 발생하게 됩니다.
이를 해결하려고 고안된 모델이 Attention 입니다.
- Gradient가 인코더의 마지막 시점과 디코더의 첫 시점에 연결되게 하고, 각 시점으로 직접 흘러가도록하여 Vanishing Gradient를 완화했습니다.
- 뿐만 아니라 Attention Score를 분석하여 모델 해설이 용이하도록 만들었기에 블랙박스라는 한계점에서 조금은 벗어날 수 있게 됐습니다.

투빅스 15기 김동현
번역이 어떻게 이루어지는지 알 수 있었고, Sequence-to-sequence와 Attention에 대해 자세하게 설명해주신 강의였습니다.
- 초기 번역은 주로 rule-based 방식, 두 개의 언어의 사전을 통해 각 단어가 대응되는 것을 찾아서 번역하는 가장 단순한 방식
- Sequence-to-sequence은 두 개의 RNN 즉 인코더 RNN과 디코더 RNN을 포함합니다. 소스 문장을 마지막에 encoding시켜 decoder rnn에 넘겨줍니다. encoder rnn에 우선 넣었습니다. 인코더 rnn에 넣고, 일종의 인코딩을 생성해서 디코더 rnn으로 전해집니다. 디코더 rnn은 조건부 언어 모델이라고 합니다. 인코딩에 따라 첫번째 출력을 얻고 다음에 나올 단어의 확률분포 argmax를 취합니다. 다음 단계에서 디코더에 전 단계에서 단어를 넣고 다시 피드백하여 argmax를 취하고 단어를 맞춥니다.
- Exhaustive search decoding: 철저하게 가능한 모든 언어 번역 공간을 검색하는 방법
- Beam search decoding: 디코더의 각 단계에서 k 개의 가장 가능성이 높은 부분 번역을 선택하여 가지치기 하는 방식으로 진행됩니다. k 개의 가장 가능성이 높은 번역, 가설의 점수가 가장 높은 번역을 찾는 것이 핵심입니다. 최적의 솔루션을 찾아주는 것은 보장하진 못하지만, 전부 다 계산하는 것보다는 훨씬 효율적입니다.
- 소스 문장에 대한 모든 정보를 끝에서 다 캡처하도록 강조하며, 여기서 너무 많은 압력이 가해집니다. Attention은 단계별로 집중을 하게 만들어 한꺼번에 집중이 가해지는 이 병목현상을 해결합니다.

투빅스 15기 조준혁
- SMT는 통계적 모형으로 Translation 모형과 Language Model의 확률 분포를 이용한 모델입니다. 데이터가 병렬적으로 있어야지만 학습이 가능하고, 구조가 다소 복잡해 사람이 직접 변수를 가공해야한다는 어려움이 존재합니다.
-Seq2Seq 모델은 Encoder 와 Decoder를 연결하여 구성됩니다. 학습 과정에서 두 파트가 하나로 연결되어 학습이 진행되며 기존 SMT 기법에 비해 Neural Network를 사용한 모델인 Seq2Seq이 매우 높은 성능을 보여줍니다. - Attention은 디코더의 hidden state와 인코더의 hidden state를 내적하여 attention score를 구합니다. 내적을 통해 벡터간의 유사도를 얻게되며 attention score는 현재 시점의 디코더 정보 & 인코더의 매 시점의 정보 유사도를 의미합니다. 이를 softmax에 통과시켜 확률 분포를 생성하고 가중치를 주어 인코더 각 시점의 hidden state를 가중합합니다. 이를 attention output이라 하며 이는 디코더의 hidden state와 concat되어 예측값을 산출할 때 사용됩니다.
Machine Translation의 발전에 따라 사용되는 기법에 대한 정리를 할 수 있었고 Seq2Seq과 Attention 에 대한 개념을 다질 수 있었습니다.

투빅스 14기 정재윤
-
SMT는 Translation Model과 Language Model의 확률분포로 접근하는 방식이다. 하지만 정말 많은 자원이 투자되어야 한다는 단점을 가지고 있습니다.
-
이 후, NMT가 등장하게 됩니다. NMT로 등장한 Seq2Seq은 Encoder단의 RNN과 Decoder단의 RNN이 연결된 구조이며 이전의 SMT보다 훨씬 성능이 좋지만 블랙박스 모형이라는 단점이 있습니다.
-
특히 번역 분야는 정량적인 평가를 진행할 때 BLEU라는 지표를 보편적으로 사용하지만, 여전히 많이 부족한 부분이 있는 지표이다.
-
최근에는 Attention 기법이 나오면서 번역분야에서 꽤나 성공적인 성과를 얻었다.
투빅스 15기 이윤정
- 통계 기반 모델인 SMT의 경우 번역 모델과 언어 모델의 확률 분포로 접근하는 방식으로 높은 성능을 지녔으나 그만큼 많은 feature engineering을 필요로 하였다.
- 신경망 기반 모델인 NMT 중 Seq2Seq 모델의 경우 encoder RNN과 decoder RNN이 연결된 구조이다. 학습 과정에서 하나의 시스템으로 최적화되며 매우 높은 성능을 보인다. 다만, NMT의 경우 문어체 번역 혹은 맥락 활용이 어렵다는 문제점이 존재한다.
- Attention 모델은 초기 시점의 정보가 마지막 시점까지 전달되지 못한다는 Seq2Seq 모델의 문제점을 보완한다. attention 모델은 encoder와 decoder의 hidden state를 내적하여 구한 attention score를 구하여 확률 분포를 생성한 후, 이를 가중치로 한 각 시점 encoder의 hidden state의 가중합을 구한다. 이때, attention score를 분석 시 모델이 각 시점에서 어디에 집중하는 지 알 수 있다.
SMT부터 NMT까지 각 방법론의 장점과 단점, 그리고 단점을 보완하는 모델까지 기계번역의 흐름에 따라 설명해주셔서 더욱 이해하기 좋았던 것 같습니다.

투빅스 15기 조효원
기계번역과 관련된 방대한 정보들을 빠짐없이 깔끔하게 전달한 명강이었습니다.
- 신경망 이전에 적용되던 통계 기반 기계 번역 방식은 Translation Model과 Language Model을 사용한다. Translation model에서는 alignment 개념을 이용해 한 언어의 단어 혹은 구가 다른 언어의 단어와 어떻게 매칭되는지 파악하고 변환한다. 그 뒤 language model에서 타겟 언어에 적절한 순서로 바꾸어준다. 이러한 방식은 몇 가지 문제가 있었는데, 첫번째 문제는 align이 되지 않는 경우고 두 번째는 방대한 비용이 든다는 것이다.
- 이러한 문제들은 신경망이 사용되면서 모두 해소되었다. 기계번역에 특화된 모델인 Seq2Seq은 Encoder와 Decoder의 두 파트로 이루어진 모델로, 각각은 RNN 모델로 구성되어 있다. Encoder는 번역할 문장을 context vector로 나타내어 decoder로 넘겨주고, decoder는 번역을 시행한다.
- 그러나 여전히, RNN 계통의 고질적인 기울기 소실 문제와 구조정보를 반영할 수 없다는 문제가 있었다. 뿐만 아니라, Encoder가 decoder에게 단 한번만 벡터를 넘겨주기에 병목현상이 일어나기도 하였다. 이를 해결하기 위해 도입된 개념이 Attention이다. Attention은 alignment에서 차용된 개념으로, 어떠한 토큰이 어떠한 토큰과 깊은 관계를 가지는지 표현해준다.

투빅스 14기 강의정
Lecture 8 – Translation, Seq2Seq, Attention를 주제로 발표해주셨습니다.
- 기계번역은 처음 문법을 중심으로 번역하는 Rule Based로 시작되었습니다.
- 이후 통계를 기반으로 하는 Statistical Machine Translation로 주를 이뤘습니다.
- SMT를 학습할 때에는 번역의 대상 언어와 번역하려는 언어의 단어를 정렬하여 사용합니다. 이때 각 단어는 1:1 매칭뿐 아니라 many to one, one to many, many to many의 형태를 가질 수 있습니다.
- 한 단어에 매칭되는 여러 단어가 있을 경우 확률이 낮은 경우를 제외한 모든 경우의 수를 계산합니다.
- 그 당시 높은 성능을 보였으나 많은 인력이 투입되어야 한다는 단점이 있습니다.
- Nerual Network를 이용한 seq2seq 모델이 등장하며 초기에는 Encoder, Decoder에 RNN이 하나씩 들어가는 형태로 구성되었습니다.
- Encoder에 번역의 대상 언어로 이루어진 문장이 입력되면 Decoder에서 start 토큰으로 번역을 시작한 뒤 마지막에 end 토큰을 출력합니다.
- seq2seq는 기계 번역 태스크뿐만 아니라 요약, 대화, 파싱, 코드 생성의 태스크에서도 사용됩니다.
- 번역하는 과정에서 Decoder에 탐욕 알고리즘을 적용한 Greedy Decoding이 있습니다. 전체를 보고 확률을 구하기보다 이전의 값을 기준으로 가장 확률이 높은 단어를 선택하여 예측하기 때문에 한번 잘못된 단어를 선택하게 된다면 이후 모든 예측이 잘못될 수 있다는 단점이 있습니다.
- Greedy Decoding을 개선한 Beam Search Decoding은 각 시점에서 확률이 높은 여러개의 후보를 선정하여 스코어를 계산해 예측합니다.
- 번역이 잘 되었는지를 평가하는 지표로 BLEU(Bilingual Evaluation Understudy Score)가 있습니다.
- 단순히 정답 문장에 있는 단어인지로 평가하는 n-gram precision 방식은 평가에 헛점이 있어 중복하여 등장하는 경우를 고려하는 modified n-gram precision이 등장하였습니다. 하지만 이도 성능을 제대로 측정한다고 할 수는 없습니다.
- seq2seq의 경우 문장의 길이가 길어지면 초기 정보가 전달되지 않는 문제점이 있어 Attention이 등장했습니다.
- 현재 시점의 디코더 정보와 인코더 매 시점 정보를 모두 활용합니다.
- 기존 NMT와 비교하여 성능이 크게 향상되고, vanishing gradient 문제를 완화했습니다.
투빅스 14기 정세영
번역 task의 기본부터 Seq2Seq과 Attention까지 전반적인 내용을 빠짐없이 잘 담아주신 강의였습니다.