
작성자 : 성신여자대학교 통계학과 정세영
우리가 매일같이 사용하는 Question Answering 예시: 구글링
Motivation
과거에는 수많은 웹문서 중에 관련 있는 문서 리스트를 반환해주는 정도였음
내 question에 더 구체화된 answer를 반환해줬으면 좋겠다 : Question Answering!
Question Answering의 기본적인 두 단계
Finding documents that contain an answer
: 기존의 검색 기반 시스템으로 굉장히 큰 데이터에 확장 가능
Finding an answer in the documents (Reading Comprehension)
: 위 검색 기반으로 좁혀진 document candidates에서 정답 search
Reading Comprehension의 역사
Machine Comprehension (Burge 2013) : MCTest corpus를 가지고 "답은 지문에 있어. 찾아봐" 하는 task (진전은 없었음)
 이후 매우 크게 구축한 train corpus와 신경망 구조를 통해 성능이 향상됨. 특히 SQuAD dataset이 굉장히 정교하게 구축되어 크게 기여하였고 지금까지 널리 사용되고 있음.
이후 매우 크게 구축한 train corpus와 신경망 구조를 통해 성능이 향상됨. 특히 SQuAD dataset이 굉장히 정교하게 구축되어 크게 기여하였고 지금까지 널리 사용되고 있음.
※ 과거 QA 모델은 주로 NER 기반으로 접근, 수작업이 굉장히 많이 들어가고 복잡함

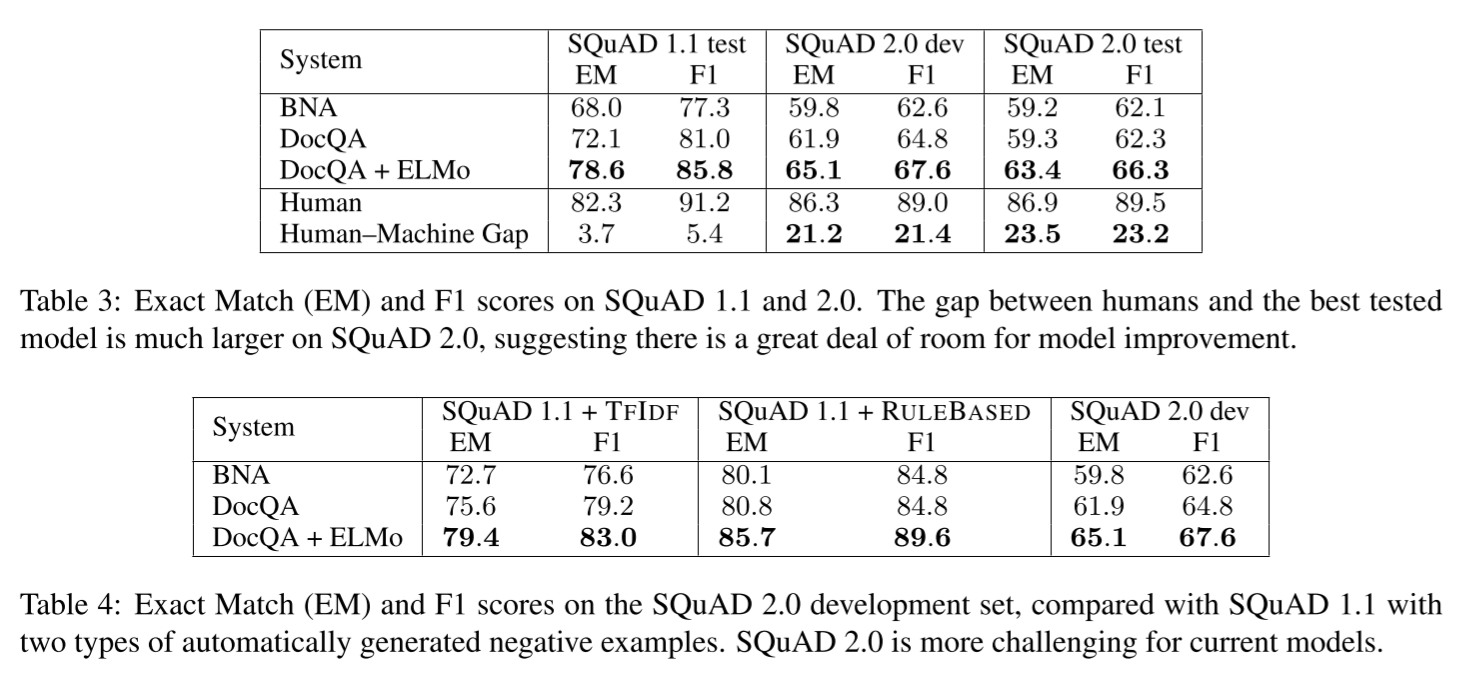
SQuAD (Stanford Question Answering Dataset)
"답은 지문에 있어. 찾아봐" 
(v1.1)
- 3 gold answers : answer의 변형에도 모델을 견고히 하기 위해 세 사람에게 답변을 얻음
- 평가 지표
- Exact match : 3개 중에 하나로 나왔으면 1, 아니면 0으로 binary accuracy
- F1 : 단어 단위로 구한 F1-score 3개 중에 max one을 per-question F1-score로 두고 전체 macro average
- punctuation과 a, an, the는 무시
(v2.0)
- v1.1에서는 모든 question에 항상 answer가 존재하다보니 passage 안에서 문맥을 이해하지 않고 단순히 ranking task로 작동하는 문제점을 발견
- v2.0에서는 dev/test 데이터 절반은 passage에 answer가 포함되어 있고 절반은 포함되어있지 않음
- 평가 시 no answer를 no answer라고 해야 맞게 예측한 것
- threshold를 두고 그 이하일 때는 예측한 answer를 뱉지 않음 (no answer)
- leaderboard를 보면 v1.1때보다 평가수치는 떨어졌지만 v1.1보다 더 정교하게 맥락을 파악하고 있다는 결과
https://arxiv.org/pdf/1806.03822.pdf
https://dos-tacos.github.io/paper%20review/SQUAD-2.0/
온라인의 crowd worker들이 unanswerable question 직접 생성(즉, 기계적으로 생성된 것이 아니라 진짜 인간이 생성했으므로 질이 더 높음)
SQuAD 1.1에 자동 생성된 응답 불가능 질문들을 병합해 테스트한 결과 SQuAD 2.0의 dev셋보다 약 20% 가량 성능이 높아져, 상대적으로 SQuAD 2.0의 task가 더 어려운 것임을 확인
SQuAD의 한계
- only span-based answers
- 현실의 본문-질문 (실제 마주하게 될 데이터)보다 쉽게 답변을 찾을 수 있는 구조 (우리가 현실에서 생각하는 질문과 구글링할 때 검색하는 질의문이 다른 것처럼)
- 하지만 그럼에도 지금까지 QA 모델에 가장 많이 사용된 well-structured, clean dataset
KorQuAD (2.0)
한국어 위키백과로 데이터 구축
 https://www.slideshare.net/LGCNSairesearch/korquad-v20?ref=https://www.slideshare.net/LGCNSairesearch/slideshelf
https://www.slideshare.net/LGCNSairesearch/korquad-v20?ref=https://www.slideshare.net/LGCNSairesearch/slideshelf
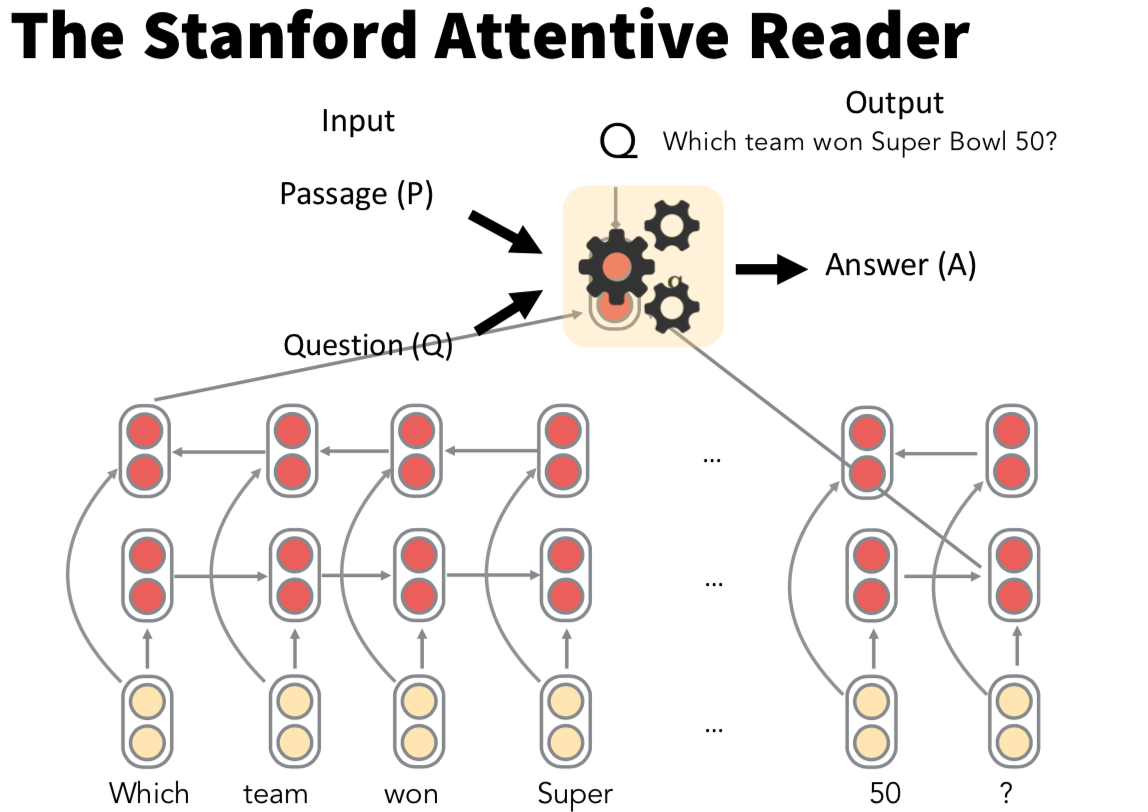
Stanford Attentive Reader
-
simplest neural question answering system
-
Bi-LSTM 구조를 사용하여 각 방향의 최종 hidden state 둘을 concat하여 question vector로 사용
-
passage의 각 단어 vector들도 똑같이 Bi-LSTM을 사용하여 각 단어 시점의 두 방향 hidden state를 concat하여 passage word vector로 사용
-
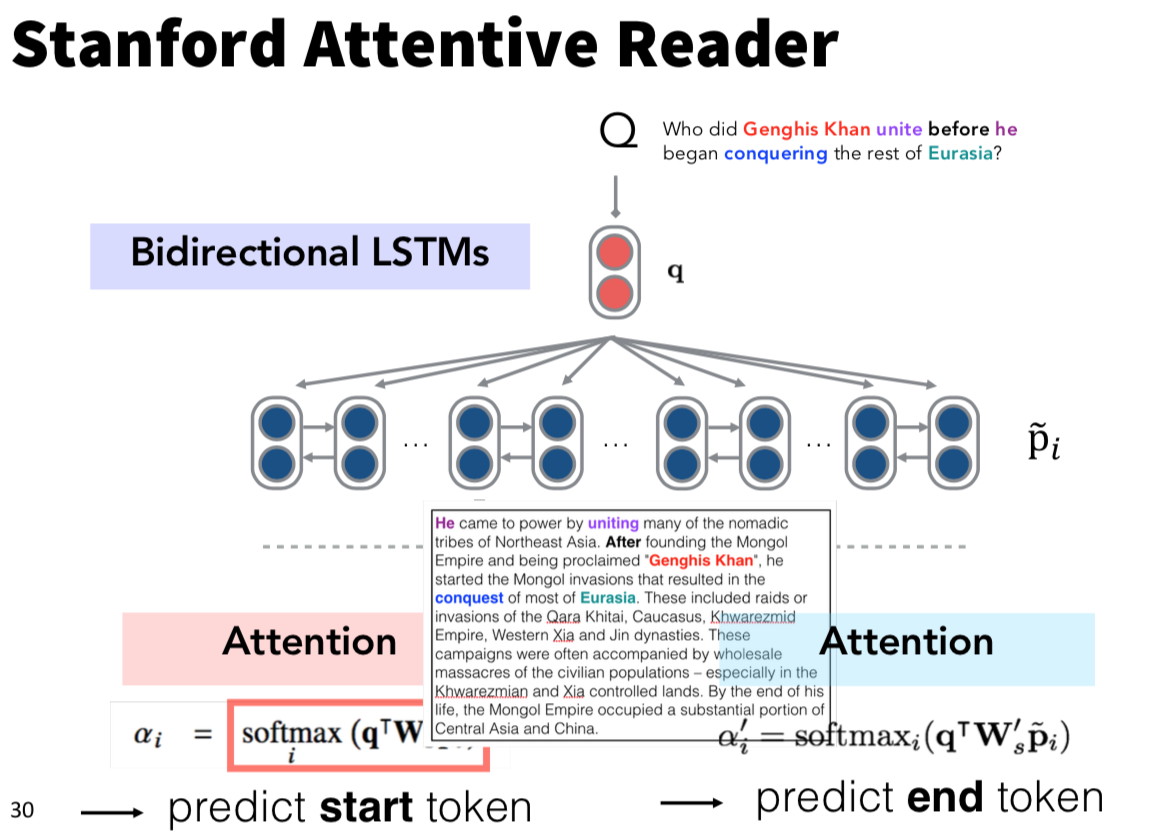
question vector를 모든 시점의 passage word vector와 attention을 구해서 passage에서 어디가 answer의 시작이고 끝인지를 학습하는 방식 (start token attention과 end token attention의 식이 학습시키는 가중치행렬만 다르고 구조가 똑같은 걸 볼 수 있는데, 이는 일반적으로 RNN에서 식의 구조는 똑같지만 forget gate나 input gate가 서로 다른 역할을 하는 것과 같은 이치라고 이해하면 된다.)
Stanford Attentive Reader++
- 아까는 최종 hidden state만 가져왔던 걸 지금은 question의 모든 단어 시점 hidden state의 attention을 구해서 그 가중합을 question vector로 사용

- 3 layer Bi-LSTM 사용
- passage word vector는 [기존 embedding vector + POS & NER tag one-hot encoding + frequency + question에 등장 여부, 단어간의 유사도] concat
BiDAF (Bi-Directional Attention Flow for Machine Comprehension)
- Query(question)과 Context(passage) 사이에 attention flow layer가 bi-directional(양방향)으로 동작하는 게 핵심
각각의 question word와 passage word 서로 간의 유사도 기반

: context word(i)와 query word(j)의 유사도 matrix
Context-to-Question attention : context word에 가장 관련있는 question word는?

Question-to-Context attention : question word에 가장 관련 있는 context word는?
유사도가 큰 context word만 살아남게 되므로 question 입장에서 관련있는 context word 정보만 모은 것

output of this layer
:
Reference
- https://www.youtube.com/watch?v=yIdF-17HwSk&list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z&index=12
- https://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture10-QA.pdf
- https://velog.io/@tobigs-text1314/CS224n-Lecture10-Question-Answering
- https://jeongukjae.github.io/posts/cs224n-lecture-10-question-and-answering/
- https://arxiv.org/pdf/1806.03822.pdf
- https://dos-tacos.github.io/paper%20review/SQUAD-2.0/
- https://www.slideshare.net/LGCNSairesearch/korquad-v20?ref=https://www.slideshare.net/LGCNSairesearch/slideshelf

9개의 댓글

투빅스 15기 조준혁
- 포털 사이트를 통한 검색은 대표적인 QA의 예시로 우리의 일상속에서 자연스럽게 활용하는 개념입니다.
- QA는 기본적으로 답을 포함한 문서를 찾는것과 문서의 후보군을 추려 정답을 찾는 것 두 단계가 존재합니다.
- Stanford Attentive Reader는 뉴럴넷을 사용한 간단한 QA 시스템이며 Bi-LSTM 구조를 사용해 양 방향의 hidden-state를 concat하여 Question Vector로 활용합니다. Passge의 간 단어 vector들도 마찬가지로 Bi-LSTM을 써서 Passage word vector로 사용하고 passage에서 어디가 answer의 시작이고 끝인지를 학습하게 됩니다.
- BiDAF는 question과 passage 사이에 question word와 passage word 서로 간의 유사도를 바탕으로 attention flow layer가 양방향으로 동작하는것이 핵심인 방식입니다.
평소에 자연스럽게 사용하는 QA모델에 대한 구조와 동작과정에 대해서 잘 알 수 있었던 강의였습니다.

투빅스 15기 김동현
- SQuAD 모델은 현실의 본문-질문보다 쉽게 답변을 찾을 수 있는 구조이지만 그럼에도 지금까지 QA 모델에 가장 많이 사용된 well-structured, clean dataset입니다.
- Stanford Attentive Reader는 question vector를 모든 시점의 passage word vector와 attention을 구해서 passage에서 어디가 answer의 시작이고 끝인지를 학습하는 방식이고, 이를 발전시켜 최종 은닉층에만 가져왔단걸 모든 질문의 모든 단어 시점 은닉층의 attention을 구해서 가중합으로 question vector로 사용합니다.

투빅스 14기 정재윤
-
QA란 Question Answering에 대한 개념으로 우리가 일반 포털 사이트에서 검색을 하는 것이 대표적인 예시이다. 이러한 연구를 위해 MCTest corpus를 만들었으나 이를 사용한 연구에서는 큰 진전이 보이지 않았다. 이 후, Stanford에서는 SQuAD를 만들었다. 이 데이터셋은 잘 정제되고 깨끗한 데이터여서 지금까지도 사용되는 데이터이나 현실과의 괴리감 ( 현실에 적용하는 다른 최적의 방법이 있을 것이다.)라는 단점이 있다.
-
Stanford Attention Reader는 뉴럴넷을 사용한 QA시스템 중 하나로 Bi-LSTM을 사용한 구조이다. Bi-LSTM을 통해 각 방향의 최종 hidden state 둘을 concat하여 question vector로 사용하고, passage의 각 단어 vector들도 똑같이 Bi-LSTM을 사용하여 각 단어 시점의 두 방향 hidden state를 concat하여 passage word vector로 사용한다. question vector를 모든 시점의 passage word vector와 attention을 구해서 passage에서 어디가 answer의 시작이고 끝인지를 학습하는 방식을 통해 모델을 구하는 것이다.

투빅스 15기 조효원
- QnA task는 기본적으로 답에 해당하는 부분을 지문에서 찾는 것에서 시작되었다. 대표적인 QnA 벤치마크인 SQuAD의 첫번째 버전은 지문 내에 답이 있는 문제로만 구성되어있었다. 하지만 모든 question에 항상 answer가 존재하다보니 지문의 문맥을 이해하지 않고 단순히 해답의 후보군에 대한 ranking task로 변질된다는 단점이 있었다. 따라서 SQuAD의 두번째 버전은 절반은 지문에 답이 포함되어있지 않도록 구성했다.
- 신경망을 이용한 가장 단순한 QnA model은 Attentive Reader 모델로, 양방향 LSTM을 이용해 학습을 진행한다. 이 모델은 지문 내에서 정답 부분이 시작하는 부분과 끝나는 부분을 포착해낸다.
- BiDAF 모델은 질문과 지문 사이의 attention이 양방향으로 동작한다는 특징이 있다.

투빅스 15기 이윤정
- Question Answering은 문서 검색 단계와 정답 탐색 단계(reading comprehension)로 이루어져있다.
- Reading Comprehension의 가장 정교한 train corpus는 SQuAD이다. SQuAD의 v2.0은 v1.1보다 평가수치는 떨어져도 맥락은 더 정교하게 파악하고 있다.
- Stanford Attentive Reader는 Bi-LSTM 구조를 통해 각 방향의 최종 hidden state들을 concat하여 question vector로 사용한다. passage word vector와 attention을 구하여 passage에서 어디가 answer의 시작과 끝인지 학습하는 방식이라고 볼 수 있다.
- BiDAF는 각 question/passage word 사이의 유사도를 기반으로 한다. 따라서, 유사도가 큰 context word만 살아남기 때문에 question 입장에서 관련있는 context word 정보만 모은 것이라고 볼 수 있다.
투빅스 15기 이수민
- Question Answering은 정답을 포함하고 있는 문서를 찾는 단계와 문서에서 정답을 찾는 단계로 이루어진다.
- QA 데이터셋은 Passage + Question → Answer 형태로 구성되어 있다.
- SQuAD 데이터셋은 여러 한계점들이 존재함에도 불구하고 QA 모델에서 가장 많이 사용되고 있는 데이터셋이다.
- Stanford attentive Reader: Bi-LSTM 구조를 사용하여 앙 방향의 최종 state를 concat하여 question vector로 활용하고, question vector를 모든 시점의 passage word vector와 attention을 구해서 학습하는 방식이다.
- Stanford Attentive Reader ++: one layer Bi-LSTM을 사용하던 이전 모델과 다르게 3 layer Bi-LSTM을 사용하게 되고, question vector 구성 시에 최종 hidden state만 가져오는 것이 아닌 question의 모든 시점의 hidden state의 attention을 구하고 weighted sum을 하여 구성한다.
- BiDAF: question과 answer 사이의 attention flow layer가 양방향으로 동작한다는 특징이 있다.

투빅스 15기 김재희
QA에 대해 처음 접하였는데, 설명을 쉽게 해주셔서 이해가 잘 되었던 것 같습니다. 감사합니다.
- QA는 기본적으로 정보가 담겨져 있는 Passage, 정보를 원하는 Question, 정답인 Answer의 구조로 이루어져 있습니다.
- 표준적인 QA 데이터셋으로서 SQuAD가 있습니다.
- Stanford Attention Model은 QA에 NN을 결합하였습니다. question 벡터와 모든 passage 벡터의 어텐션을 이용해 정답의 시작지점과 끝지점을 구하는 방식을 사용합니다.
- 이후 Stanford Attnetive Reader++에선 question과 passage의 모든 시점에 대해 양방향으로 attention을 구하여 이용합니다.

투빅스 14기 박준영
- QA는 qustion에 구체적인 answer를 반환해주는 것이다.
- 과거 QA의 모델은 Ner 기반으로 접근하고 수작업이 들어가 복잡했지만, 큰 train corpus와 신경망 구조를 통해 성능이 향상되었고 SQuAD dataset이 널리 쓰이고 있다.
- SQuAD는 실제 데이터보다 더 쉽게 답변을 찾을 수 있는 데이터 셋으로 이루어져있다는 한계가 있다.
- simplest neural question answering system 인 Stanford Attentive Reader는 Bi-LSTM 구조를 사용하여 각 방향의 hidden state를 concat하여 question vector로 사용한다.
- question vector의 모든 시점의 passage word vector와 attention을 구해서 passage의 어디가 answer의 시작이고 끝인지 학습하는 방식이다.
- 최종 hidden state만 사용했던 Stanford Attentive Reader와는 달리 Stanford Attentive Reader++는 모든 단어 시점의 hidden state의 attention을 구해서 가중합을 question vector로 사용한다.
- BiDAF는 question과 passage 사이에 attnetion flow layer가 양방향으로 동작하는 구조이다.
덕분에 QA의 모델의 구조들과 QA의 연구과정에 대해 배울수 있었습니다. 좋은 강의 감사합니다!!
투빅스 14기 한유진
QA모델 구조 사진들을 통해 동작과정을 잘 설명해주셔서 이해하기 수월했습니다. 좋은 강의 감사합니다!