Lecture 6 - Natural Language Processing with Deep Learning

발표자 : Tobig's 13기 이혜민

Contents
1.Language Modeling
2.N-gram Language Model
3.Neural Language Model
4.RNN Language Model
5.Perplexity
1. Language Modeling
많은 사람들이 자동완성 기능, 인터넷 검색과 같은 Language Model을 일상생활에서 사용합니다.
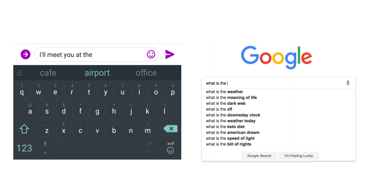
- Language Modeling : 현재까지 주어진 문장의 다음 단어를 예측하는 것
- Language Model : 주어진 문장의 다음 단어를 예측하는 것을 수행하는 모델

- 문장에 이미 주어진 단어 x(1)부터 x(t)가 주어졌을 때, 다음에 올 단어 x(t+1)의 확률을 나타낼 수 있습니다. => 특정 문장에 확률 할당 가능
- 특정 문장의 확률(좌변)을 식의 우변과 같이 연속된 조건부확률로 풀어 쓴 이후에, LM을 통해서 알아낼 수 있는 값들(두번째 줄)을 통해서 확률을 계산할 수 있습니다.
2. N-gram Language Model
(1) Definition
Q : How to learn a Language Model?
A : (pre-deep learning) Learn n-gream Language Model
n-gram : a chunck n consecutive words (연이은 단어들의 덩어리)
n-gram 모델은 카운트에 기반한 통계적 접근을 사용하고 있기 때문에 SLM의 일종입니다. 하지만 이전에 등장한 모든 단어를 고려하는 것이 아니라, 일부 단어만 고려하는 접근 방법을 사용합니다.
'일부 단어를 몇 개 보느냐'를 결정하는 것이 n-gram에서의 n이 가지는 의미입니다.
IDEA : Collect statistics about how frequent diffrent n-grams are, and use these to predict next word (n-그램의 빈도에 대한 통계를 수집하고 이를 다음 단어를 예측하는데 사용)
예) The students opened their __
- unigrams : the, students, opened, theirs
- bigrams : the students, students opened, opened their
- trigrams : the students opened, students opened their
- 4-grams : the students opened their
Markov Assumption : X(t+1)은 n-1개의 단어에만 영향을 받는다라는 가정
-> 다음 단어를 예측하기 위해서 확률을 계산하는 것이 아니라 여기서는 some large corpus of text에서 count해서 근사화하는 값을 계산합니다.

(2) Problems
ex) 4-gram Language Model로 다음 단어 예측하기
As the proctor started the clock, the students opened their __
n-gram 언어 모델은 언어 모델링에 바로 앞의 n-1개의 단어만 참고합니다.
4-gram 언어 모델이라고 가정하여 위 문장을 가지고 앞서 배운 n-gram 언어 모델링을 하는 방법을 알아보겠습니다. 모델은 바로 앞 3개의 단어만 참고하며 더 앞의 단어들은 무시합니다.
위 예제에서 다음 단어 예측에 사용되는 단어는 students, opened, their입니다.
P(w|boy is spreading)=count(boy is spreading w)count(boy is spreading)
그 후에는 훈련 코퍼스에서 (n-1)-gram을 카운트한 것을 분모로, n-gram을 카운트한 것을 분자로 하여 다음 단어가 등장 확률을 예측했습니다. 예를 들어 갖고있는 코퍼스에서 students opened their가 1,000번, students opened their books가 400번, students opened their exams가 100번 등장했다면 각 확률은 아래와 같습니다.
P(books|students opened their=0.4
P(exams|students opened their)=0.1
1. 희소 문제 (Sparsity problems)
문장에 존재하는 앞에 나온 단어를 모두 보는 것보다 일부 단어만을 보는 것으로 현실적으로 코퍼스에서 카운트 할 수 있는 확률을 높일 수는 있었지만, 여전히 n-gram 모델에 대한 희소 문제가 존재합니다.
- 훈련 코퍼스에 'students opened their '라는 단어 시퀀스가 존재하지 않으면 n-gram 언어 모델에서 해당 단어 시퀀스의 확률 P(students opened their exams)는 0이 되버립니다.
- 언어 모델이 예측하기에 students opened their 다음에는 books이란 단어가 나올 수 없다는 의미이지만 해당 단어 시퀀스는 현실에서 실제로는 많이 사용되므로 제대로 된 모델링이 아닙니다.
n을 작게 선택하면, 훈련 코퍼스에서 카운트는 잘 되겠지만 근사의 정확도는 현실의 확률분포와 멀어집니다. 그렇기 때문에 적절한 n을 선택해야 합니다. 앞서 언급한 trade-off 문제로 인해 정확도를 높이려면 n은 최대 5를 넘게 잡아서는 안 된다고 권장되고 있습니다.
2. 저장 문제 (Storage Problems)

n이 커지거나 corpus가 증가하면, 모델 사이즈가 커진다는 문제점도 있습니다. 기본적으로 코퍼스의 모든 n-gram에 대해서 카운트를 해야 하기 때문입니다.
(3) Process
앞의 개념을 통해서 예시로 n-gram 동장 방식을 알아보겠습니다.

- 3-gram으로 정하면 n-1인 2개의 단어(today, the)만 남게 됩니다.
- 해당 단어들을 기반으로 확률 분포를 얻어내면, 가능성이 있는 단어들이 분포로 나오게 됩니다.
- 분명히 희소성의 문제가 보이지만 이를 무시하고 본다면 나쁘지 않은 결과입니다.

- 이전의 과정과 같이 codition (조건 선택) -> sampling (확률 분포에서 제일 확률이 높은 단어를 선택하는 것) -> condition (조건 선택) -> ... -> 새로운 확률 분포를 얻고 샘플링하는 과정을 반복하면서 해당 텍스트를 생성해 낼 수 있습니다.
- 생각보다 문법적인 결과입니다. 하지만, 전체적인 의미에서 일관성이 없고 n을 늘리게 되면 우려되는 희소성 때문에 n-gram의 한계점을 볼 수 있습니다.
3. Neural Language Model
이전 n-gram Language Model 문제점에 대한 대안으로 대체적으로 성능이 우수한 인공 신경망을 이용한 언어 모델이 많이 사용되고 있습니다.
n-gram 언어 모델은 충분한 데이터를 관측하지 못하면 언어를 정확히 모델링하지 못하는 희소 문제(sparsity problem)가 있었습니다. 희소 문제는 기계가 단어 간 유사도를 알수 있다면 해결할 수 있는 문제입니다.
언어 모델 또한 단어의 유사도를 학습할 수 있도록 설계한다면, 훈련 코퍼스에 없는 단어 시퀀스에 대한 예측이라도 유사한 단어가 사용된 단어 시퀀스를 참고하여 보다 정확한 예측을 할 수 있을 겁니다. 이런 아이디어를 가지고 탄생한 언어 모델이 신경망 언어 모델 NNLM입니다.
Window-based Neural Network Language Model (NNLM)
- "Curse of dimensionality (차원의 저주)"를 해결하기 위해 제안된 신경 기반 Language Model
- Language Model이면서 동시에 단어의 "distributed representation"을 학습
- NNLM은 n-gram 언어 모델과 유사하게 다음 단어를 예측할 때, 앞의 모든 단어를 참고하는 것이 아니라 정해진 n개의 단어만을 참고합니다. 이 범위를 윈도우(window)라고 합니다.

-> window size : 4
- input : 단어들의 시퀀스
- output : 다음 단어에 대한 확률 분포
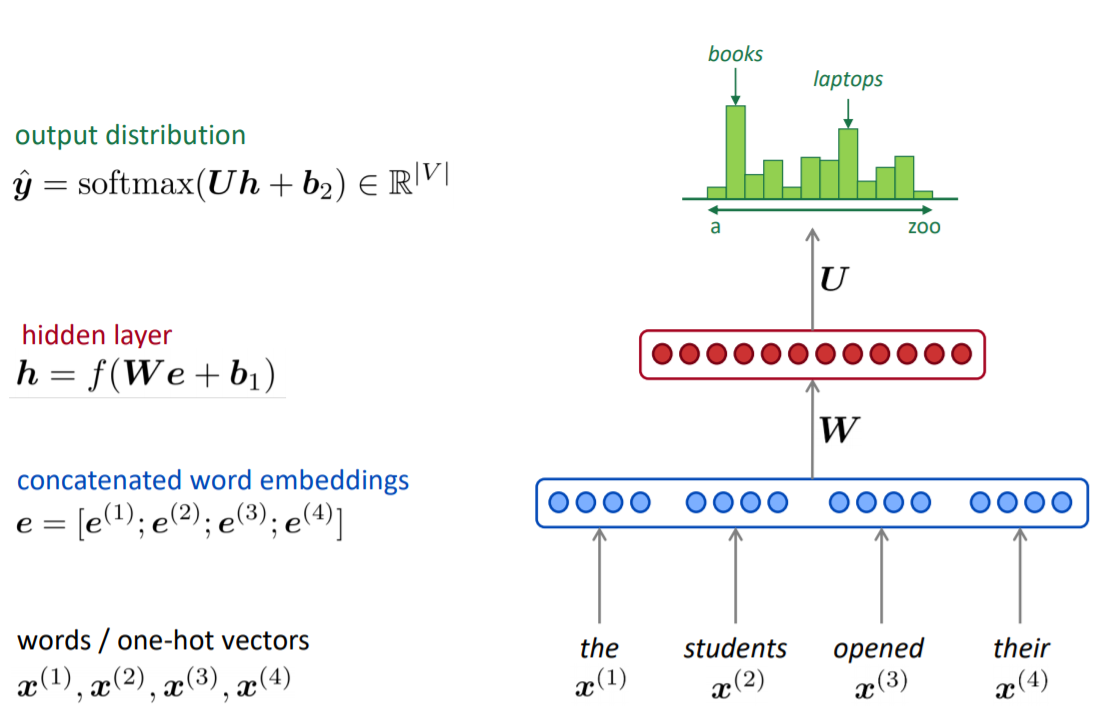
Input 단어 x의 시퀀스를 window 사이즈 만큼 입력하여, one-hot vector를 거쳐 임베딩 합니다.
임베딩 한 벡터 값들을 concatenate하여 가중치 값과 연산하여 hidden layer를 거치게 됩니다. 최종적으로 softmax 함수를 통해 확률 분포를 output 할 수 있으며 해당 분포를 통해서 제일 가능성이 높은 다음 단어를 예측하게 됩니다.
< Improvements >
- 단어의 embedding을 통해 n-gram이 없을 확률에 대한 희소성 문제가 없습니다.
- 관측된 모든 n-gram을 저장할 필요가 없습니다.
< Problems >
- Fixed window is too small
- Window가 커질수록 가중치 W도 커집니다. (Window 크기의 한계)
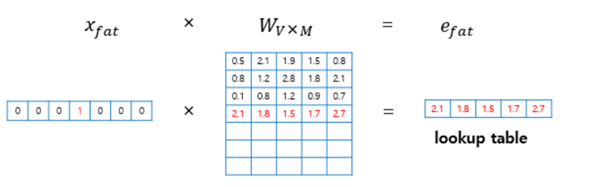
- 룩업 테이블(lookup table) : 원-핫 벡터의 특성으로 인해 i번째 인덱스에 1이라는 값을 가지고 그 외의 0의 값을 가지는 원-핫 벡터와 가중치 W 행렬의 곱은 사실 W행렬의 i번째 행을 그대로 읽어오는 것과(lookup) 동일하다는 개념입니다.
- 룩업 테이블 작업을 거치면 V의 차원을 가지는 원-핫 벡터는 이보다 더 차원이 작은 M차원의 단어 벡터로 맵핑됩니다. 테이블 룩업 과정을 거친 후의 이 단어 벡터를 임베딩 벡터(embedding vector)라고 합니다.
- 해당 벡터와 가중치 metrix에서의 연산에서는 각각의 벡터들이 각각 다른 W 가중치 섹션을 곱하게 되면서 단어와 단어 간의 'No Symmetry'하게 되는 문제점을 가지게 됩니다.
4. Recurrent Neural Network(RNN) Language Model
(1) Recurrent Neural Network(RNN)
기존의 뉴럴 네트워크 알고리즘은 고정된 크기의 입력을 다루는 데는 탁월하지만, 가변적인 크기의 데이터를 모델링하기에는 적합하지 않습니다.
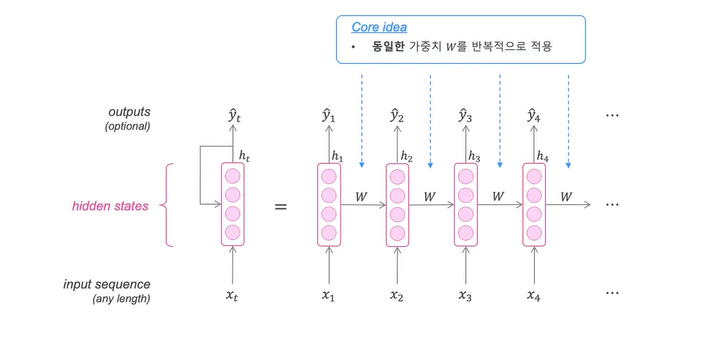
RNN(Recurrent Neural Network, 순환신경망)은 시퀀스 데이터를 모델링 하기 위해 등장으며, 기존의 뉴럴 네트워크와 다른 점은 ‘기억’(hidden state)을 갖고 있다는 점입니다.
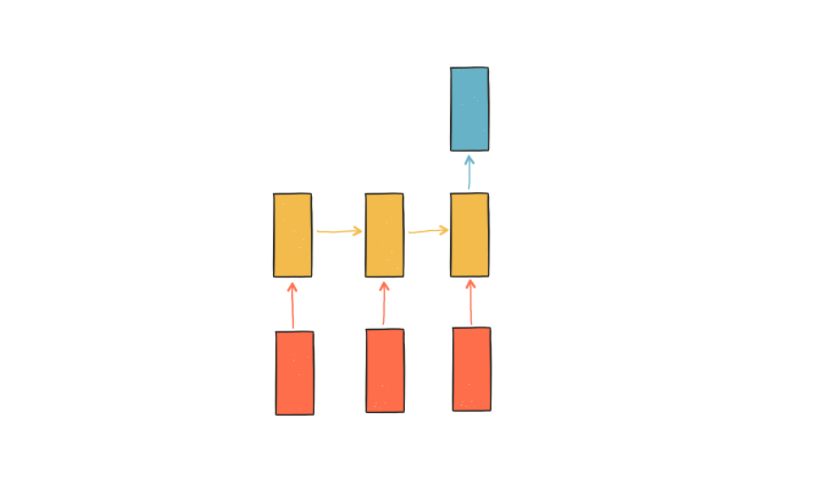
- 위 다이어그램에서 빨간색 사각형은 입력, 노란색 사각형은 기억, 파란색 사각형은 출력을 나타냅니다.
- 첫번째 입력이 들어오면 첫번째 기억이 만들어집니다. 두번째 입력이 들어오면 기존의 기억과 새로운 입력을 참고하여 새 기억을 만듭니다.
- 입력의 길이만큼 이 과정을 얼마든지 반복할 수 있으며, RNN은 이 요약된 정보를 바탕으로 출력을 만들어 냅니다.
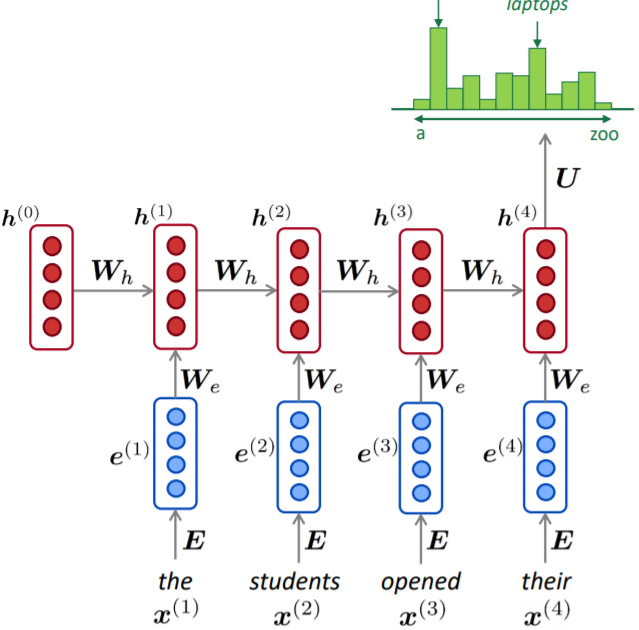
는 t 시간 스텝에서의 입력 벡터, 는 t 시간 스텝에서 RNN의 기억을 담당하는 hidden state, 는 출력 벡터입니다. U, W, V는 모델의 파라미터입니다.
첫 다이어그램에 없던 은 hidden state의 초기값으로, 구현을 위해 필요한 부분이며 일반적으로 0으로 초기화 합니다.

은닉층 :
네트워크의 기억에 해당하는 hidden state 는 입력 x와 과거의 기억 을 조합하여 만들어집니다. 조합하는 방식은 파라미터 U와 W에 의해 결정됩니다. U는 새로운 입력이 새로운 기억에 영향을 미치는 정도를, W는 과거의 기억이 새로운 기억에 영향을 미치는 정도를 결정한다고 볼 수 있습니다. 비선형함수로는 tanh나 ReLU가 주로 사용됩니다. 여기에서는 tanh를 쓰겠습니다.
출력층:
출력, 즉 예측값은 마지막 hidden state 로부터 계산됩니다. 와 V를 곱하는데, 여기서 V는 hidden state와 출력을 연결시켜주며 출력 벡터의 크기를 맞춰주는 역할을 합니다. 마지막으로 출력을 확률값으로 변환하기 위해 softmax 함수를 적용합니다. softmax 함수는 모든 출력값을 0 ~ 1 사이로 변환하고, 출력값의 합이 1이 되도록 합니다.
RNN의 핵심 : 반복적으로 같은 가중치 W를 적용하는 것
- 은닉상태 h(t)는 이전 은닉 상태 h(t-1)와 해당 단계의 입력 x(t)의 구성이다.
#python code
hidden_state_t = 0 # 초기 은닉 상태를 0(벡터)로 초기화
for input_t in input_length: # 각 시점마다 입력을 받는다.
output_t = tanh(input_t, hidden_state_t) # 각 시점에 대해서 입력과 은닉 상태를 가지고 연산
hidden_state_t = output_t # 계산 결과는 현재 시점의 은닉 상태가 된다.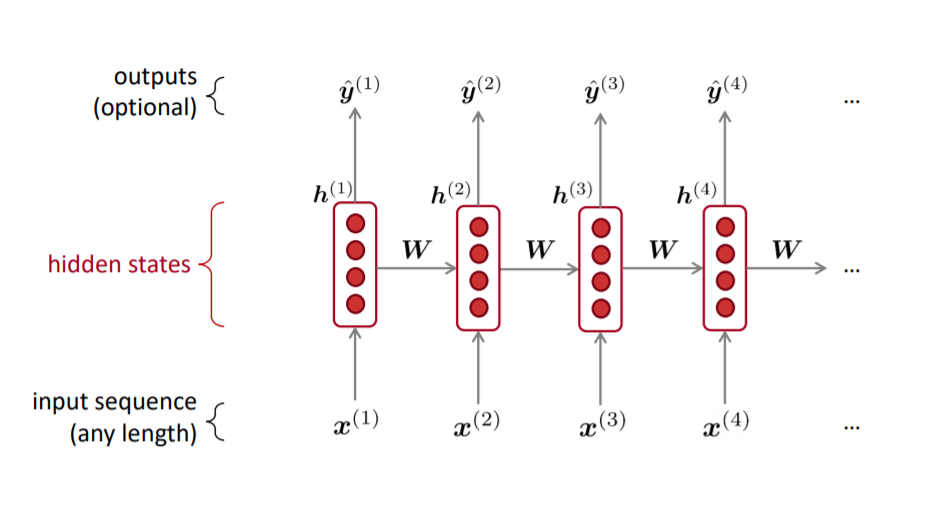
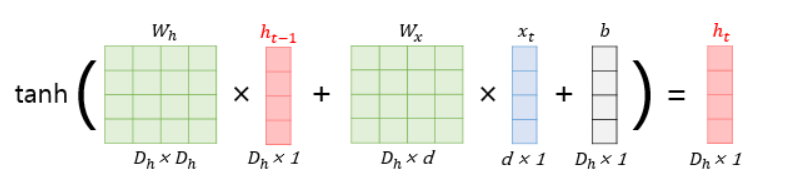
<각 벡터와 행렬의 크기>
Xt : (d×1)
Wx : (Dh×d)
Wh : (Dh×Dh)
ht−1 : (Dh×1)
b : (Dh×1)
단어 벡터의 차원 : d, 은닉 상태의 크기 : Dh
(2) Improvements & Disadvantages
< Improvements >
- 모든 길이의 입력을 처리할 수 있다.
- 단계 t는 이론적으로 여러 이전 단계의 정보를 사용할 수 있다.
- 아무리 입력이 길어도 모델의 크기가 증가하지 않는다. (모델의 크기는 WH와 WE로 고정되어 있다.)
- 모든 time step에 동일한 가중치를 적용한다.
- 각 입력에 동일한 변환을 적용한다. 따라서 하나의 입력을 처리하는 좋은 방법을 배우면 시퀀스의 모든 입력에 적용된다.
< Disadvantages >
- 이전 은닉 상태를 기반으로 다음 은닉 상태를 계산해야 하기 때문에 순차적인 계산이 필요하다. 따라서, 반복하는 과정에서 매우 계산이 느립니다.
- 여러 단계에서 정보에 액세스하는 것이 매우 어렵습니다.
- 큰 단점은 시퀀스 중 중요한 입력과 출력 단계 사이의 거리가 멀어질 수록 그 관계를 학습하기 어려워진다는 점입니다.
- 신경망이 깊어질수록 Vanishing gradient로 인해, 문장 초반부의 단어가 결과에 미치는 영향이 적어집니다.
+) 이점을 극복하기 위해 RNN의 여러 변형 모델들이 제안되고 있으며, 대표적인 변형 모델로는 LSTM, attention 기반 모델이 있습니다.
(3) Training a RNN Language Model
- x1에서 xT까지의 단어 시퀀스가 있는 텍스트 코퍼스 모음을 얻습니다.
- RNN 모델에 단어 시퀀스를 입력한 다음, 모든 단계 T에 대한 출력 분포인 Y(T)를 계산합니다. (모든 단계에서의 다음 단계에 대한 확률을 계산합니다.)
- 예측 확률 분포 Y(T)와 사실 두 벡터 사이에 대한 교차 엔트로피를 이용하여에 손실 함수를 정의합니다.
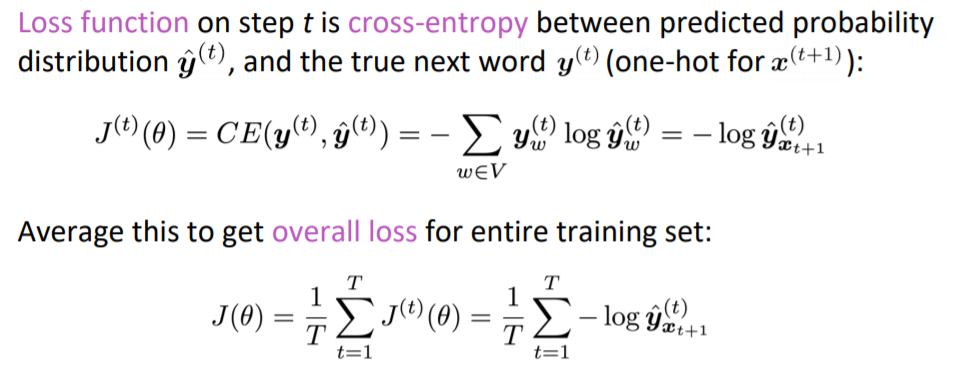
- 최종적으로, 모든 단계에서의 loss 평균으로 T의 모든 훈련 셋의 전체 loss를 구합니다.
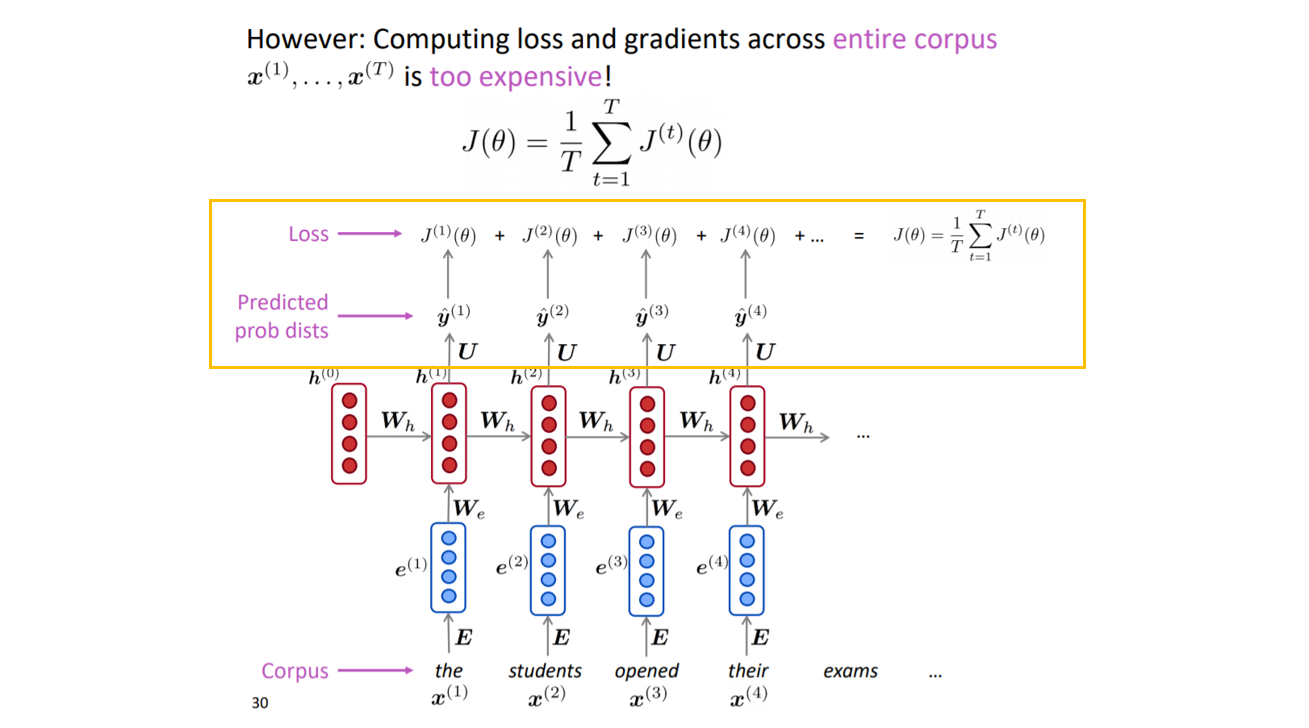
- 다만 실제 RNN-model을 학습할 경우, 위의 그림과 같이 계산을 하게 되면 많은 양의 계산이 필요하기 때문에 문장 혹은 문서 단위로 입력을 주게 되며, SGD를 통해서 Optimize하는 것도 하나의 방법이라고 합니다.
(4) Backpropagation for RNNs
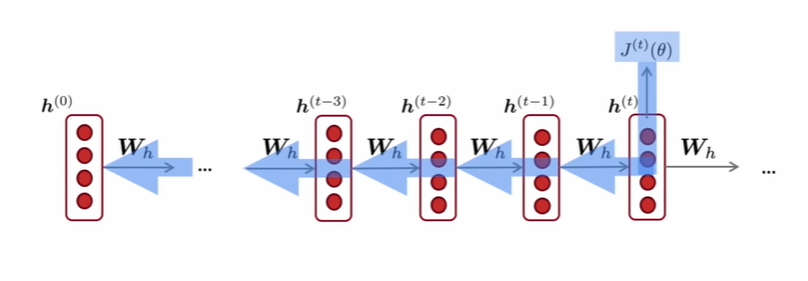
- RNN을 학습하는 것은 기존의 신경망 모델을 학습하는 것과 매우 유사합니다. 그러나 기존의 backpropagation과 다르게 순환 신경망은 계산에 사용된 시간, 시점의 수가 영향을 주어Backpropagation Through Time (BPTT) '시간에 따른 역전파'라는 약간 변형된 알고리즘을 사용합니다.
- 각 출력 부분에서의 gradient가 현재 시간 스텝에만 의존하지 않고 이전 시간 스텝들에도 의존합니다.
- 만약, 예시로 t=2의 시점에서 발생한 손실을 역전파 하려면 손실을 입력과 은닉층 사이의 가중치로 미분하여 손실에 대한 각각의 비중을 구해서 업데이트 해야 합니다. 이 연산 과정에서 은닉층의 '이전 시점의 값들'이 연산에 포함되는데 이전 시점의 값은 세부적으로 (가중치, 입력값, 이전 시점의 값들의 조합)으로 이루어져 있다. 순환 신경망은 각 위치별로 같은 가중치를 공유하기 때문에 t=2 시점의 손실을 역전파 하기 위해서는 t=0 시점의 노드 값들에도 '모두 영향을 주어야' 한다.
BPTT(Backpropagation Through Time) : 각 레이어마다의 weight는 실제론 동일한 웨이트여야 하므로 모든 업데이트도 동일하게 이루어져야 한다. 따라서 각 layer마다 동일한 위치의 weight에 해당하는 모든 derivative error를 다 더한다음 (더하는 거나 평균 내는거나 사실상 같은 의미) weight를 1번 업데이트 해준다.
(어차피 edge하나를 펼친거니까 k스텝으로 펼쳐서 k개의 에러를 구한다음, 에러를 하나로 합치고 이 edge에 대해 업데이트 해주면 끝) 사실상 이것이 BPTT의 핵심적인 부분이다.
(5) what can RNNs do?
RNN의 입력과 출력은 우리가 네트워크에게 시키고 싶은 것이 무엇이냐에 따라 얼마든지 달라질 수 있습니다.
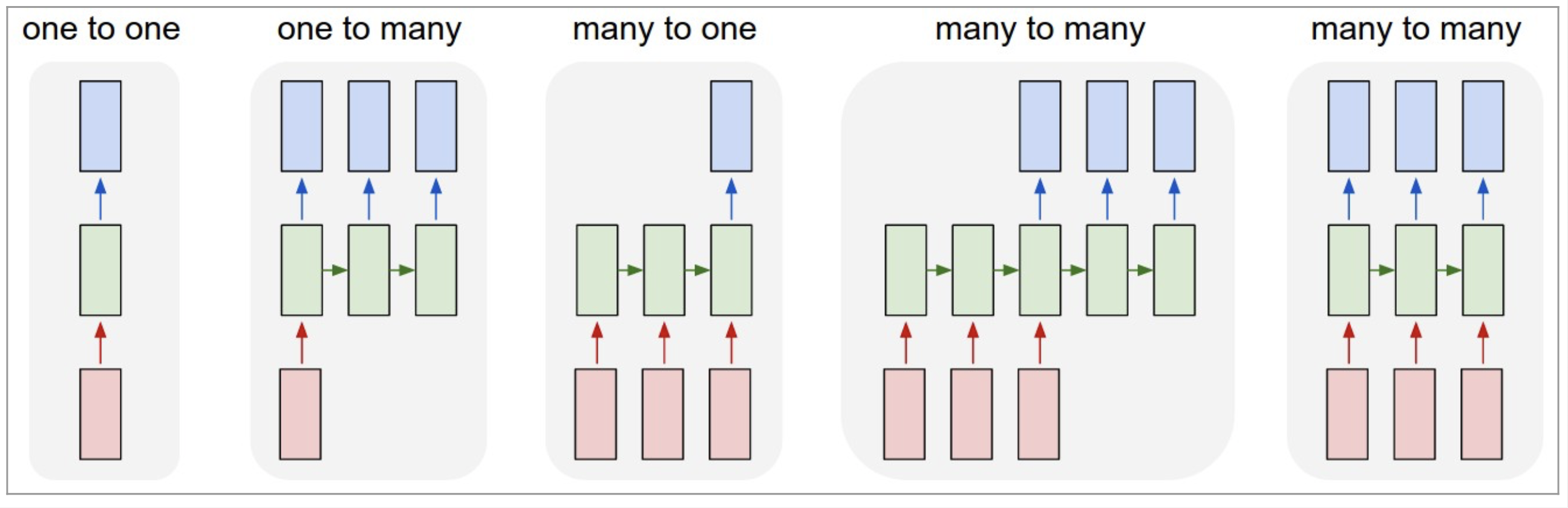
1. 고정크기 입력 , 고정크기 출력
-> 순환적인 부분이 없기 때문에 RNN이 아닙니다.
2. 고정크기 입력 & 시퀀스 출력
-> 예)이미지를 입력해서 이미지에 대한 설명을 문장으로 출력하는 이미지 캡션 생성
3. 시퀀스 입력 & 고정크기 출력
-> 예) 문장을 입력해서 긍부정 정도를 출력하는 감성 분석기
4. 시퀀스 입력 & 시퀀스 출력
-> 예) 영어를 한국으로 번역하는 자동 번역기
5. 동기화된 시퀀스 입력 & 시퀀스 출력
예) 문장에서 다음에 나올 단어를 예측하는 언어 모델
다양한 RNN 활용
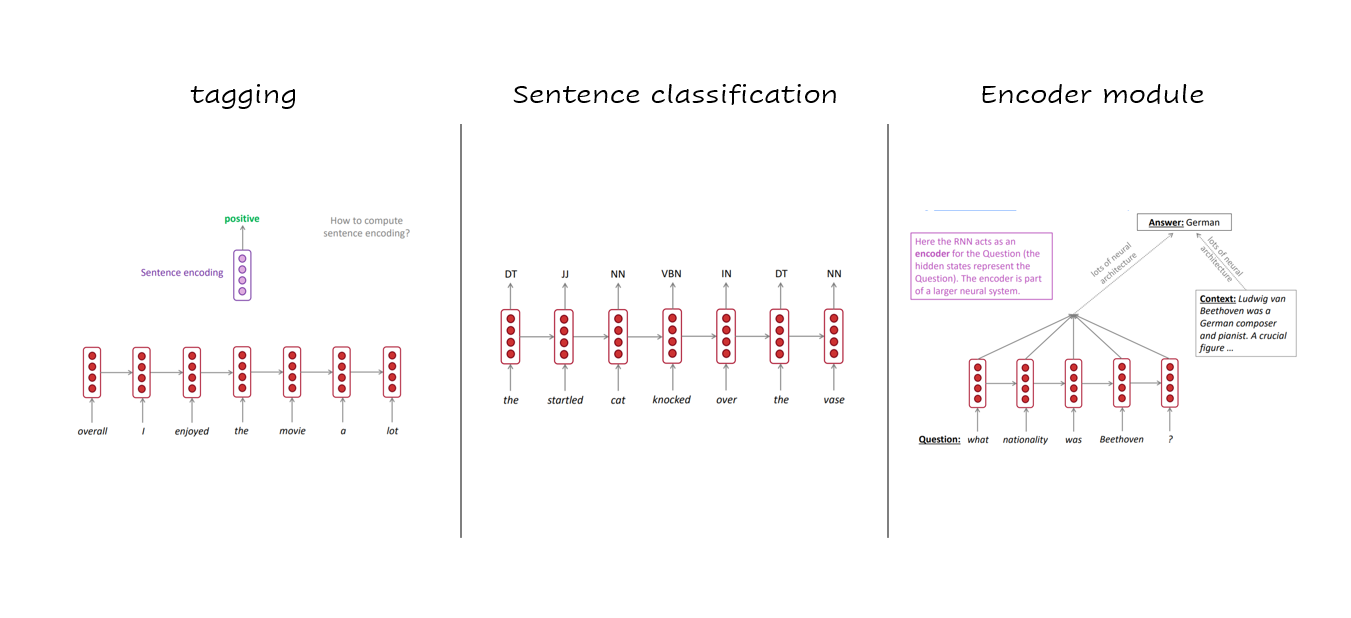
- RNN은 Tagging, Sentence classification, Encoder Module에도 활용이 많이 되고 있습니다.
5. Perplexity
Evaluating Language Models : Perplexity
언어 모델의 성능을 평가하는 척도인 perplexity(PPL)를 측정하는 방법은 정량 평가/extrinsic evaluation 방법의 하나입니다. PPL은 문장의 길이를 반영하여 확률값을 정규화한 값이라고 할 수 있습니다. PPL을 이용하여 언어 모델에서 테스트 문장들의 점수를 구하고, 이를 기반으로 언어 모델의 성능을 측정합니다.
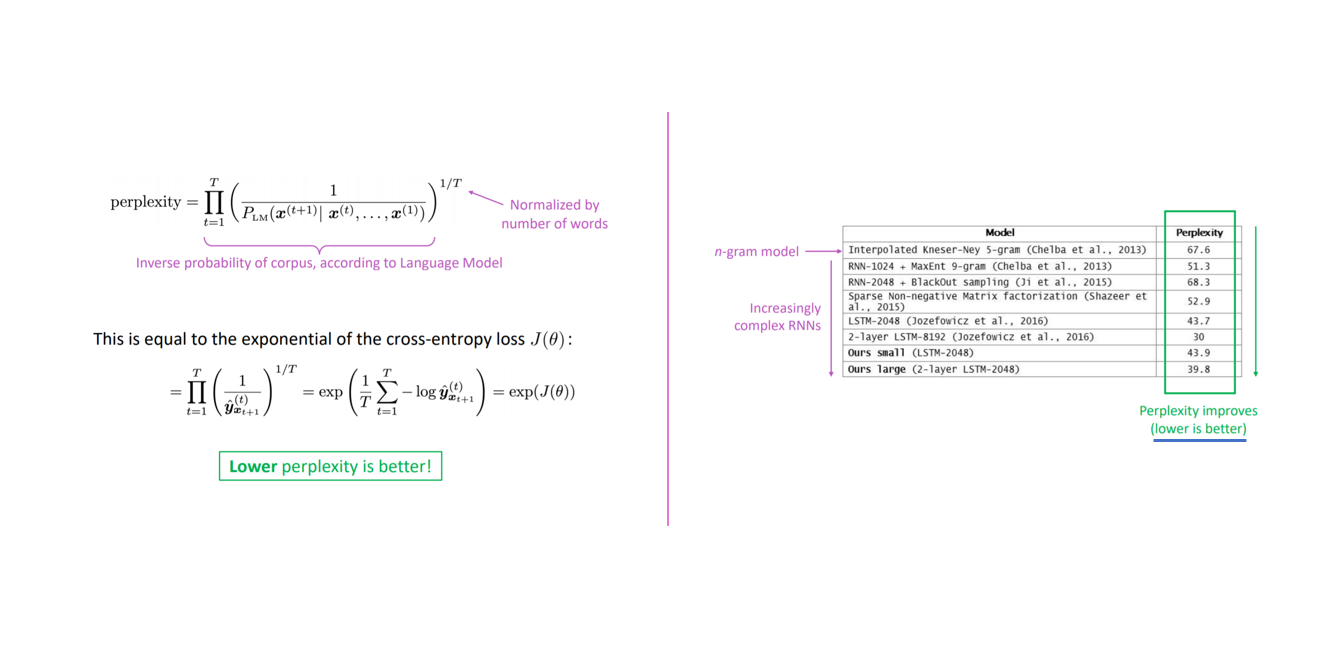
- Perplexity는 Language Model의 성능을 측정하는 척도입니다.
- Language model을 통해 예측한 corpus의 inverse를 corpus 길이로 normalize 해준 값 입니다.
- cross-entropy에다가 로그 씌우고 exponential을 씌어서 구할 수 있으며, perplexity가 낮을 수록 좋은 Language Model이라고 할 수 있습니다.
최근 Perplexity가 감소하고 있음을 확인할 수 있는데, 해당 값이 낮을 수록 좋습니다.
6. 출처
- https://www.youtube.com/watch?v=iWea12EAu6U&list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z&index=6
(강의 자료 : 2019 Winter CS224N - Lecture 6) - https://wikidocs.net/21692 (n-gram language model)
- https://blog.naver.com/dmsquf3015/222055564808
- https://mystudyplace.tistory.com/22 (NNLM model)
- https://wikidocs.net/22886 (RNN model)
- https://newsight.tistory.com/94 (backpropagation vs BPTT)
- https://kh-kim.gitbook.io/natural-language-processing-with-pytorch/00-cover-8/03-perpexity#perplexity (perplexity)

13개의 댓글

투빅스 14기 한유진
- 주어진 문장의 다음 단어를 예측하는 모델인 Language Model에 대해서 배웠습니다.
- 딥러닝전에는 일부 단어(N개) 빈도의 통계를 사용하여 다음단어를 예측하는 N-gram language model을 사용했습니다. 하지만 n을 작거나 크게 설정하면 생기는 문제인 희소문제와 저장문제 때문에 Neural language Model이 등장합니다.
- window based인 NNLM은 모든단어가 아니라 정해진 window내의 단어만 참고하기 때문에 희소성과 저장문제를 해결할 수 있지만, window size의 한계때문에 symmetry하지 않다는 문제점이 발생하게 됩니다.
- 이렇게 등장하게 된 RNN은 hidden state(기억)을 가지고 있기에, 입력 길이만큼 과정을 반복하면서 요약된 정보를 가지고 output을 내뱉을 수 있다는 장점이 있습니다. 핵심은 반복적으로 같은 W를 적용한다는 것 입니다. RNN의 backprop은 시간,시점들이 영향을 주어 변형된 BPTT를 사용합니다. 현재 시간스텝뿐아니라 이전 시점의 세부적인 값들이 합쳐져 현재 gradient가 계산되는 것 입니다.
RNN이 등장하게 된 배경과 학습이 이루어지는 과정을 잘 설명해주셔서 많은 도움이 되었습니다. 좋은 강의 감사합니다!

투빅스 15기 조준혁
- Language Model은 주어진 문장의 다음 단어를 예측 수행하는 모델이며 많은 사람들이 자동완성 기능이나 인터넷 검색등에 일상생활에서 이미 많이 활용합니다.
- Language Model을 학습시키기 위해서는 이전에 등장한 모든 단어가 아닌 일부 단어만 고려하는 N-gram 방식이 활용될 수 있습니다.
- N-gram을 활용한 Language Model은 희소 문제와 저장 문제를 가지고 있으며 이를 해결하기 위해 Neural Network를 활용한 Language Model을 사용하게 됩니다.
- 순환신경망을 의미하는 RNN은 시퀀스 데이터를 모델링 하기 위해 처음 등장했고, 기존의 뉴럴 네트워크와 다른점은 hidden state를 가지고 있다는점입니다. RNN의 핵심은 반복적으로 같은 가중치 W를 적용하며 학습을 진행해 나갑니다.
Language를 활용한 모델 설계에 대한 기초를 배울 수 있는 강의였습니다. 감사합니다.

투빅스 14기 이정은
- Language model은 다음 단어를 예측하는 모델입니다.
- N-gram Language model은 카운트에 기반한 통계적 접근 방식을 가진 모델로, 특정 위치의 단어는 바로 앞의 n-1개의 단어에만 영향을 받는다는 가정을 가집니다. 이는 sparsity와 storage문제가 있고, 이를 해결하기 위해 Neural Language model이 등장합니다.
- Neural Language model은 단어의 embedding을 통해 sparsity와 storage 문제를 해결합니다. 다만, window의 크기에 한계가 있고, 각 벡터들이 각각 다른 가중치의 섹션과 곱해져 단어 간의 no symmetry한 문제가 발생합니다.
- RNN은 hidden state를 가지고 있어 긴 시퀀스를 모두 고려할 수 있고, 반복적으로 같은 W를 적용해 학습을 진행합니다. 다만 시퀀스 내 단어 간의 거리가 멀어질수록 그 관계를 학습하기가 어렵다는 단점을 가지고 있습니다. 이를 극복하기 위해 LSTM, attention 기반의 모델이 존재합니다.
Language model에 대한 전반적인 내용을 이해할 수 있는 강의였습니다. 감사합니다 : )

투빅스 15기 김동현
Language Model과 RNN에 대해서 잘 설명해주셨습니다.
N-gram Language Model
- N-gram은 연속된 N개의 단어 덩어리
- N-gram 문장이 나타날 확률과 (N-1)-gram이 나타날 확률을 이용하면, 현재 문장이 주어졌을 때 다음 단어가 올 확률을 계산
- N-gram은 N개의 이전 단어만 가지고 보기 때문에 문장의 문맥을 담기에는 한계가 존재
- N-gram의 count 정보를 저장하기 위해 model의 크기가 지나치게 커지는 문제
- 문맥을 충분히 반영하지 못하는 문제
RNN Language Model
- 각 input마다 다른 가중치를 부여한 Neural Language Model과 다르게, 동일한 가중치를 반복적으로 사용
- 먼 곳에 위치한 단어도 고려할 수 있어 context를 반영
- vanishing gradient problem등의 문제가 있어 context가 반영되지 않는 경우 존재

투빅스 14기 정재윤
Language Model과 RNN에 대해서 전반적으로 설명해주신 강의였습니다.
-
Language Model은 다음에 나올 단어를 예측하는 모델로 대표적으로 N-gram Model이 있습니다. 여기서 n-gram이란 빈칸 앞에 등장한 n개의 단어를 고려하여 예측하는 방식입니다. 하지만 이 방식은 훈련 데이터에 동일한 형식이 등장하지 않으면 제대로 예측할 수 없다는 희소문제와 모든 데이터들이 저장되어야 한다는 저장문제를 가지고 있습니다.
-
이 후 발전된 형태로 나온 것이 Neural Language Model이었으며 더 나아가서 RNN이 만들어지게 됩니다. RNN에서 가장 중요한 점은 같은 가중치를 적용한다는 점입니다. 또한 n개만을 보는 것이 아닌 모든 길이의 입력을 모두 고려한다는 점입니다. 하지만 단점 역시 존재하는데 반복적인 계산으로 시간이 오래 걸린다는 점과 vanishing gradient가 발생해서 오래전에 입력된 단어들의 의미는 점차 사라진다는 점이 있습니다. 이 점들을 개선한 lstm, gru 등의 모델은 추후의 강의에 나옵니다.
-
Perplexity는 언어모델을 평가하는 방법 중 하나로 정량적인 평가 방법입니다. Perplexity는 문장의 길이를 반영하여 확률값을 정규화한 값으로 이 값이 낮으면 낮을수록 모델의 성능이 좋습니다.

투빅스 15기 조효원
언어모델(Language model)은 단순하게 말하자면, 주어진 단어 set이 있을 때 다음에 가장 나올 법한 단어를 모델링하는 것입니다. 딥러닝 이전에는 n-gram 단위로 통계를 이용해 모델링을 시도했습니다. 그러나 count-based 접근은 sparsity 문제와 저장의 문제가 있었습니다. 신경망 기반 접근법들이 발달하면서 해당 문제들은 사라집니다. 하지만 여전히 문제들은 남아있었습니다. 특히 window based 신경망 언어모델의 경우, window size의 한계 때문에 문제가 발생합니다. 이러한 문제점 속에서 등장한 것이 RNN으로, 순차적인 정보에 특화된 모델입니다. 시간 스텝을 고려하여, 과거의 기억을 계속 가진 상태로 학습을 진행합니다. 자연스럽게 과거의 기억은 잊혀집니다.

투빅스 14기 강재영
주어진 문장 다음 단어를 예측하는 ' Language Model ' 들에 대해서 배웠습니다.
N-gram Language Model
- 딥러닝이 도입되기 이전에 주로 사용된 Language Model
- N-gram이란, 연속된 N개의 단어 덩어리를 의미
- 다음 단어는 오직 직전의 N-1개의 단어에만 영향을 받는다는 아이디어 기반
- Sparsity Problems, Storage Problems, Incoherence problems 등의 한계를 지님
Neural Language Model
- NER에 적용했던 Window-based Neural Net은 중심단어 앞뒤로 Window를 정했지만, 이번에는 이전 순서에만 Window를 고정
- Softmax 덕분에 희소성 문제해결 / Counting 값을 저장할 필요가 없어서 저장 문제해결
- 여전히 N-gram처럼 문맥반영 못하고 / 단어 위치에 따라 곱해지는 가중치가 다르기 때문에 비슷한 내용을 여러번 학습하게 되는 비효율 발생
따라서 이러한 문제를 해결하기 위해 나타난 RNN - LM
- 핵심 아이디어는 동일한 가중치를 반복해서 사용하는 것!
- Window를 지정하지 않기 때문에 문맥을 반영하지 못했던 한계를 해결함
- 하지만 실제로는 Vanishing Gradient 문제로 문맥을 반영하지 못하는 경우가 많고, 계산이 병렬적이라 느림

투빅스 15기 이수민
- Language Model은 주어진 단어의 sequence에 대해서 다음에 나타날 단어가 어떤 것인지 확률을 이용하여 예측하는 작업을 수행하는 모델입니다.
- N-gram Language Model은 예측에 사용할 앞 단어들의 개수를 정하여 모델링하는 방법입니다. N-gram은 n개의 연이은 단어 chunk를 의미하며, 이전에 등장한 모든 단어들이 아닌 일부 단어들만 고려하여 예측을 진행합니다. 이 모델은 n이 커질수록 sparsity 문제와 storage 문제가 발생한다는 문제점을 가집니다.
- 위의 문제점을 보완하기 위해 Neural Network Language Model이 제안되었습니다. 다음 단어 예측 뿐만 아니라 각 단어에 대한 distributed representation을 학습할 수 있다는 특징을 가지며 관측된 값을 저장할 필요가 없기 때문에 sparsity와 storage 문제를 해결합니다. 다만 window 크기에 한계가 있고 단어와 단어 간 symmetry하지 않다는 문제점이 발생합니다.
- RNN의 핵심은 반복적으로 동일한 가중치를 적용하는 것입니다. 입력 길이에 제한이 없다는 장점을 가지지만, 이론과 다르게 실제로는 vanishing gradient problem으로 인해 문맥을 반영하지 못 할 수 있기 때문에 이를 극복하기 위한 LSTM, Attention 기반의 모델들이 존재합니다.

투빅스 14기 박준영
이번강의는 Natural Language Processing with Deep Learning에 관한 강의였습니다.
-
N-gram Language Model : n개의 단어를 가지고 단어의 빈도를 기반으로한 통계적 model
하지만 n개의 단어를 보기때문에 sparsity 문제가 발생할 수 있다. 훈련 셋에 단어가 존재하지 않으면 확률이 0이 된다.
n이 커지거나 corpus가 증가하면 모델 사이즈가 커져 storage 문제점 발생 -
NNLM: n-gram 모델의 희소성문제를 해결하기위해 단어의 유사도를 학습할 수 있게했습니다. window 사이즈를 입력하고, one-hot벡터를 커쳐 임베딩한뒤에 NN을 통과하여 softmax를 통해 가능성이 높은 단어를 예측
희소성 문제를 해결했으며 모든 n-gram을 저장하지 않아도되서 storage문제도 해결했습니다. 하지만 window의 사이즈가 클수록 가중치가 커져 window 사이즈를 줄일 수 밖에 없습니다. -
RNN : 시퀀스 데이터를 모델링하기 위한 모델입니다. hidden state를 이용하여 이전 정보를 기억합니다. 이를 통해, 길이의 입력을 처리할 수 있고, 입력 size가 커져도 모델크기가 증가하지 않습니다. 하지만 계산이 느리고 vanishing gradient 문제가 발생되어 거리가 멀어질수록 초반부의 단어가 결과에 미치는 영향이 적어진다.
-
language model을 평가하는데 정량평가 하나로 perplexity방법이 있습니다. 예측한 corpus의 inverse를 corpus 길이로 normalize해준 값이다. perplexity가 낮을수록 좋은 language model이라 할 수 있습니다.
Language model에 대해 배울수 있는 좋은 강의였습니다. 좋은강의 감사합니다.

투빅스 14기 강의정
Lecture 6 - Natural Language Processing with Deep Learning를 주제로 발표해주셨습니다.
- Language Model은 주어진 문장의 다음 단어를 예측하는 모델입니다.
- N-gram Language Model은 n개의 단어 덩어리를 고려합니다. n을 몇으로 설정하는지에 따라 희소문제 또는 저장문제가 일어납니다.
- Window-based Neural Network Language Model은 윈도우의 범위에 있는 단어들 만을 고려합니다. 희소성의 문제도 없고 모든 n-gram을 저장하지 않아도 되는 장점이 있지만 window가 커질 수록 가중치의 크기가 매우 커지게 됩니다.
- RNN Language Model은 길이의 제한없이 처리가 가능하며 앞서 처리된 정보를 기억할 수 있습니다. 하지만 계산과정이 느리고 Vanishing gradient이 발생하는 문제가 있어 LSTM, attention모델이 제안되었습니다.
투빅스 15기 이윤정
- language model은 주어진 문장의 다음 단어를 예측하는 모델입니다.
- N-gram language model은 카운트에 기반한 모델로 일부 단어만 고려하는 통계적 접근 방법을 사용하고 있습니다. 한계점으로는 희소 문제와 저장 문제가 존재합니다.
- Neural Network language model(NNLM)은 n-gram language model의 희소 문제를 해결하기 위해 등장한 언어 모델로 language model이지만 동시에 단어의 distributed representation을 학습한다는 특징이 존재합니다.
- RNN은 가변적 크기의 데이터를 다루는 데 한계가 존재하는 NNLM의 대안으로 등장하였습니다. RNN은 시퀀스 데이터를 모델링하기 위해 hidden state를 가지고 있기 때문입니다. 하지만 vanishing gradient로 인해 문장 초반부의 단어가 결과에 미치는 영향이 적어지며 대안으로 등장한 모델로는 LSTM, attention 기반 모델이 있습니다.
투빅스 14기 정세영
Language Model과 RNN의 큰 틀을 잘 설명해주셔서 쉽게 이해할 수 있었던 강의였습니다.
Language Model이란, 다음 단어를 예측하는 모델
n-gram Language Model
Neural Network Language Model (NNLM) (window-based)
RNN Language Model
-> 각 시점의 gradient가 그 이전 시점들에도 의존하기 때문에 하나의 edge를 펼쳐 구한 여러 loss들을 합쳐서 업데이트해주는 것