Lecture 5 - Linguistic Structure: Dependency Parsing
작성자 : 국민대학교 경영정보학과 & 빅데이터경영통계학과 김동현
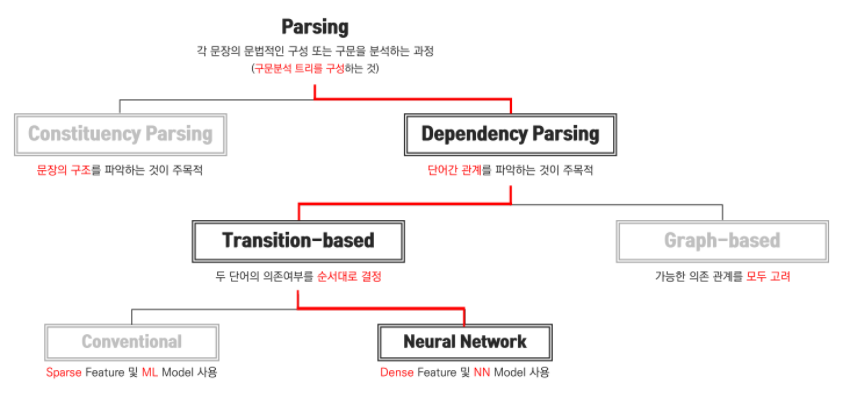
CS224n의 5번째 강의는 Linguistic Structure: Dependency Parsing이라는 주제로 각 문장의 문법적인 구성이나 구문을 분석하는 과정인 parsing에 대해 다루고 있습니다. parsing 중에서 Constituency parsing과 Dependency parsing을 소개하고, 강의에서는 Dependency parsing을 위주로 문장 구조를 분석하고 이해하는 방법을 설명합니다.
먼저 Constituency and Dependency parsing의 개념에 대해서 간략하게 보고 이 중에서 Dependency parsing에 대해서 자세히 알아보겠습니다. 그리고, Dependency parsing의 전통적인 방법인 transition-based dependency parsing의 개념과 parsing 과정에 대해서 자세하게 소개하며 마지막 목차에서는 neural network가 적용된 방법인 neural dependency parsing이 어떻게 문장 구조를 분석하는 지에 대해 설명합니다.
1. Syntactic Structure: Consitituency and Dependency
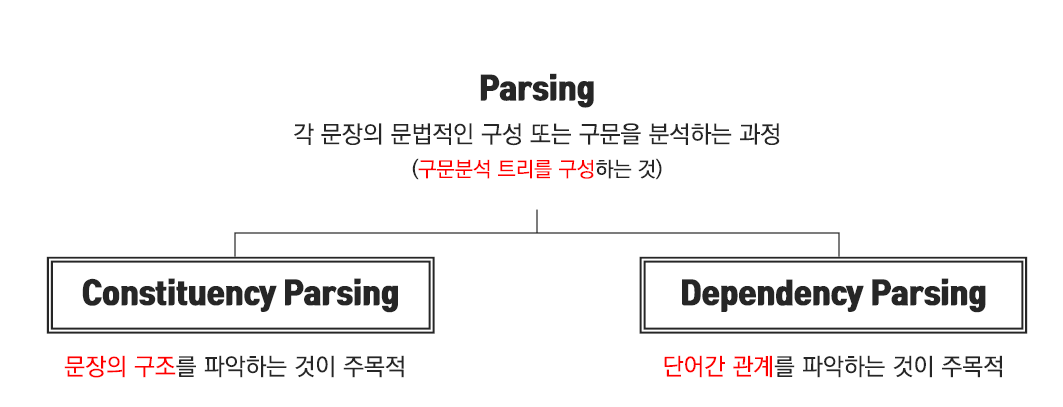
Parsing이란 각 문장의 문법적인 구성 또는 구문을 분석하는 과정이라고 할 수 있습니다. 주어진 문장을 이루는 단어 혹은 구성 요소의 관계를 결정하는 방법으로, parsing의 목적에 따라 Consitituency parsing과 Dependency parsing으로 구분할 수 있습니다.
Consitituency parsing은 문장의 구성요소를 파악하여 구조를 분석하는 방법이며, Dependency parsing은 단어간 의존 관계를 파악하여 구조를 분석하는 방법입니다.

Consitituency parsing은 문장을 중첩된 성분으로 나누어 문장의 구조를 파악하는 방법으로 영어와 같이 어순이 비교적 고정적인 언어에서 주로 사용합니다. 구성하고 있는 구(phrase)를 파악하여 문장 구조를 분석하며, 보통 각 단어들은 해당 단어의 문법적 의미를 가지고 있습니다.'the'는 '관형사(Det)', 'cat'은 '명사(N) 등을 예로 들 수 있습니다.
이렇게 각 문법적 의미를 가지고 있는 단어들은 단어끼리 결합해서 어떠한 구(phrase)를 구성할 수 있습니다. 그리고 구성된 구는 구와 또 결합하여 문장을 구성합니다.
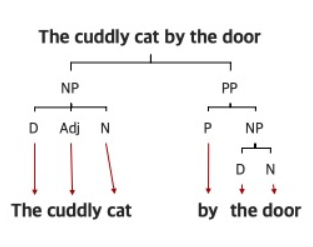
문장의 관점에서 보면 문장을 이루는 구(phrase)를 파악할 수 있으며, 구를 이루는 구, 혹은 구를 이루는 단어들을 최종적으로 분류할 수 있습니다.
'The cuddly cat by the door'에서는 명사구(Noun Phrase)인 'The cuddly cat'과 전치사구(Preprositional Phrase)인 'by the door'로 먼저 구분할 수 있으며 최종적으로는 각 단어가 가지는 문법적 의미까지 분해할 수 있습니다.
Dependency parsing은 문장보다는 문장에 존재하는 개별 단어 간 의존 또는 수식 방향으로 관계를 파악하여 문장 구조를 분석하는 방법입니다. 이는 문장을 이루는 단어 사이에 서로 영향을 미치는 어떠한 관계가 있음을 전제합니다. 한국어와 같이 자유 어순을 가지거나 문장성분이 생략 가능한 언어에서 선호하고 있습니다.
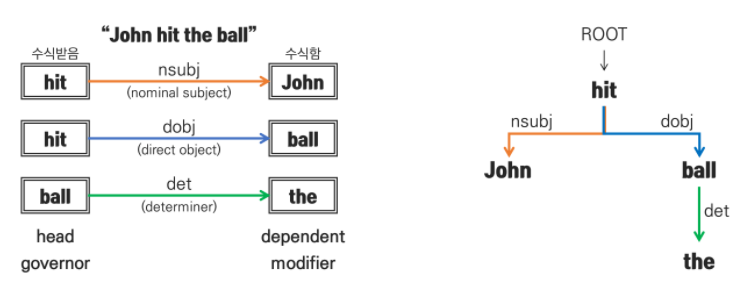
단어 간 존재하는 관계를 의존 관계 혹은 수식 관계로 표현할 수 있으며, 수식을 하는 단어는 'head' 혹은 'governor', 수식을 받는 단어를 'dependent' 혹은 'modifier'이라고 합니다.
이렇게 단어 간 관계를 정립하게 되면 우측과 같이 문장을 트리 구조로 표현해서 어떻게 화살표가 이동하고 어떤 단어가 수식을 받는지, 안받는지 파악할 수 있습니다.
정리하면 Consitituency parsing은 문장의 구조를 파악하는 것이 주목적이며, Dependency parsing은 단어간 관계를 파악하는 것이 주목적입니다.

이렇게 문장 구조를 parsing이라는 방법을 통해 분석해야하는 이유는 문장의 의미를 보다 정확하게 파악하기 위해서입니다. 인간은 복잡한 의미를 전달하기 위해 단어를 더 큰 단위로 조합하여 생각을 전달하기 때문에 우리는 단어끼리 어떻게 연결되어 있는지 파악해야 합니다.

문장 구조를 분석해야하는 이유로 해당 강의에서는 문장에서 발생하는 2가지 모호성(ambiguity)을 소개합니다.
먼저 Phrase Attachment Ambiguity는 형용사구, 동사구, 전치사구 등이 어떤 단어를 수식하는지에 따라 의미가 달라지는 모호성을 말합니다.
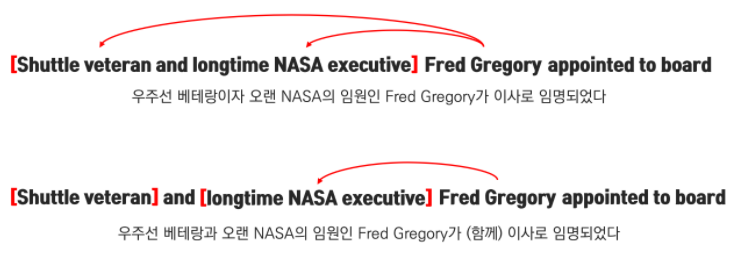
Coordination Scope Ambiguity는 특정 단어가 작용(수식)하는 대상의 범위가 달라짐에 따라 의미가 변하는 모호성을 말하며, 한국어에서는 '작용역 중의성'이라고 합니다.
정리하자면 문장은 많은 단어가 복잡한 관계로 이루어져 있기 때문에 앞서 본 것 처럼 모호한 해석을 올바르게 이해하기 위해서는 문장의 구성요소에 대한 분석과 이해가 요구됩니다. 즉, 무엇과 무엇이 연결되어 있는지에 대한 이해가 필요합니다.
2. Dependency Grammar and Treebanks

Dependency parsing에 대해서 자세히 알아보겠습니다. 먼저 'ROOT'라는 가상의 노드를 문장의 맨 처음에 추가함으로써, 최종 head를 'ROOT'를 설정하고 모든 단어가 1개의 dependent(의존 관계)를 가지도록 설정합니다.
- Dependency Structure는 sequence 형태와 tree 형태로 표현할 수 있으며, 2가지 형태의 결과는 정확히 동일한 output을 가져야 합니다.
- 화살표는 head(수식을 받는 단어)에서 dependent(수식을 하는 단어)로 향합니다.
- 화살표 위 라벨은 단어간 문법적 관계를 의미하며 수식 관계인 화살표는 순환하지 않습니다. 즉, 중복 관계는 형성되지 않습니다.

Dependecy parsing에서 고려되는 보편적인 특징은 다음과 같습니다.
- 두 단어 사이의 실제 의미가 드러나는 관계
- dependency의 거리는 주로 가까운 위치에서 dependent 관계가 형성
- 마침표, 세미콜론과 같은 구두점을 넘어 dependent 관계가 형성되지는 않음
- head의 좌우측에 몇 개의 dependents를 가질 것인가에 대한 특성
3. Transition-based dependency parsing
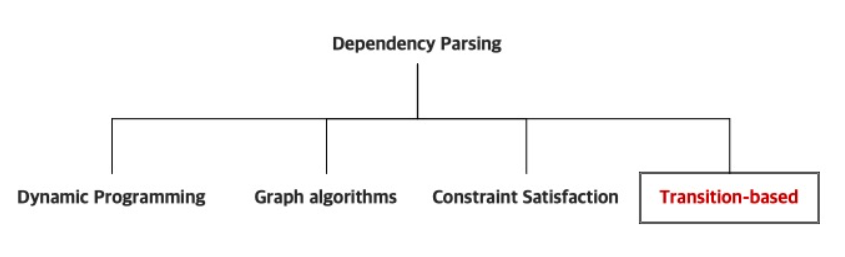
Dependecy parsing의 방법으로 강의에서는 4가지 방법이 있다고 소개합니다. 하지만 이번 강의와 목차에서는 Transition-based 방법에 대해서 보다 구체적이게 다루고자 합니다.
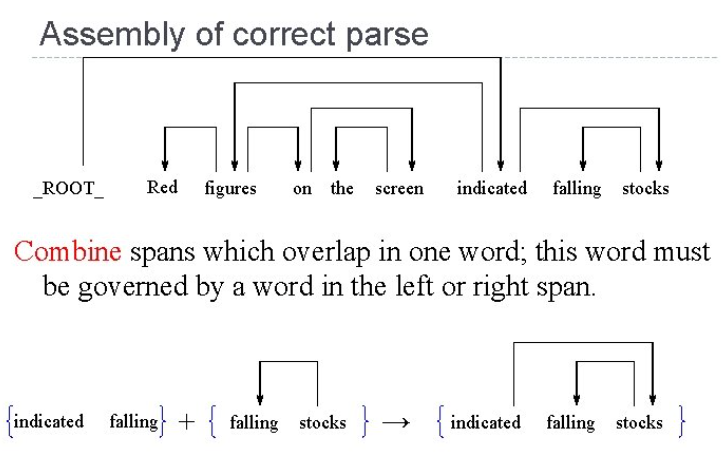
Dynamic programming은 동적 계획법 개념을 사용하는데 긴문장이 있으면 그 문장들을 몇 개로 나누어서 하위 문자열에 대한 하위 트리를 만들고 최종적으로 그것들을 다시 합치는 방법으로 parsing을 진행합니다.

Constraint Satisfaction은 문법적 제한 조건을 초기에 설정하고 그 조건을 만족하면 남기고, 만족하지 못하면 제거하여, 조건을 만족시키는 단어들만 parsing하는 방법이라고 합니다.
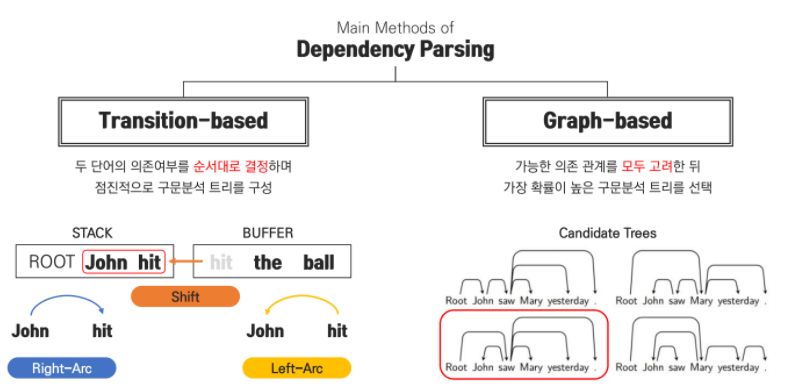
Transition-based dependency parsing은 두 단어의 의존 여부를 차례대로 결정해나가면서 점진적으로 dependency structure를 구성해나가는 방법입니다. 이와 달리 Graph-based는 가능한 의존 관계를 모두 고려한 뒤 가장 확률이 높은 구문 분석 트리를 선택하는 방법입니다.

Transition-based dependency parsing은 문장에 존재하는 sequence를 차례대로 입력하게 되면서 각 단어 사이에 존재하는 dependency를 결정해나가는 방법으로 'Deterministic dependecy parsing'이라고도 불립니다.
문장의 sequence라는 한 방향으로 분석이 이루어지기 때문에 모든 경우를 고려하지는 못합니다. 그렇기 때문에 분석 속도는 보다 빠를 수 있겠지만 낮은 정확도를 보이기도 합니다. 앞서 소개한 Graph-based는 모든 경우의 수를 다 고려해서 속도는 느리지만 정확도는 높다고 합니다.
그러나 2014년에 발표한 논문에 따르면 dense feature를 사용한 신경망 기반 transition-based parser를 제안하여 속도와 성능 모두를 향상 시켰다고 합니다. 하지만 이는 Graph-based parser에 비하면 낮은 성능을 기록하고 있습니다.
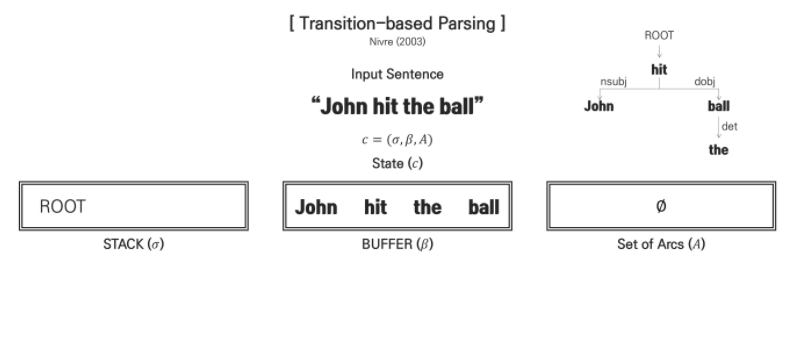
Transition-based dependency parsing이 진행되는 과정에 대해서 살펴보겠습니다. 먼저, parsing 과정에는 BUFFER, STACK, Set of Arcs라는 3가지 구조를 가지고 있습니다.
input으로 문장이 입력되면, 위 3가지 구조를 거침으로써 output이 도출되는 parsing 과정입니다. parsing 초기 상태에서 BUFFER에는 주어진 문장이 토큰 형태로 모두 입력되어 있는 상태이며, STACK에는 ROOT만이 존재하고 Set of Arcs에는 parsing의 결과물이 담기게 되어 현재는 공집합 상태입니다.
parsing 과정에 대해서 간단하게 설명하면 다음과 같습니다. BUFFER에 존재하는 문장의 토큰이 STACK으로 이동하게 되면서 어떠한 state를 형성하게 됩니다. 그리고 해당 state를 기반으로 Decision이라는 결정을 내리게 되고 output으로 결과가 이동하게 됩니다.
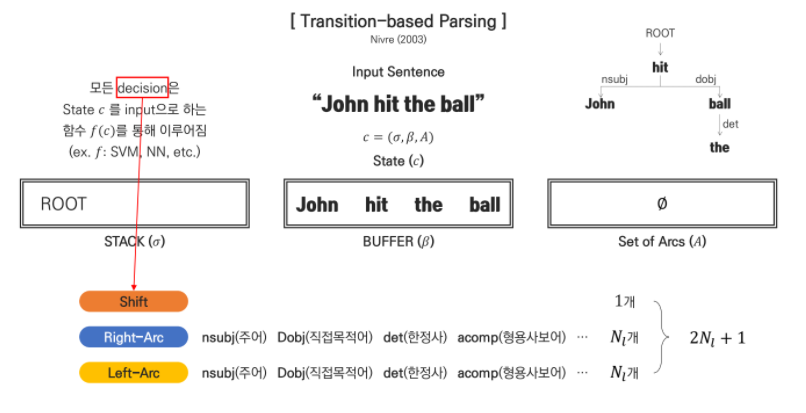
먼저 BUFFER에서 STACK으로 토큰이 이동하는 과정은 문장의 sequence를 따릅니다. 즉 BUFFER('John', 'hit', 'the', 'ball')가 존재한다면 문장의 첫번째 토큰인 'John'가 먼저 STACK으로 이동하게 됩니다.
그렇게 되면 STACK에는 'ROOT'와 'John'이 존재하게 되면서 어떠한 state를 형성하게 됩니다. 그 때, 이 state를 통해 Decision이라는 결정을 내리게 됩니다. Decision을 결정하는 방법으로는 단순히 함수와 같은 역할이라고 볼 수 있으며 강의에서는 SVM, Neural Network등의 모델이 적용될 수 있습니다.
STACK에서 토큰과 토큰의 존재로 다양한 state가 형성되겠지만 결정되는 Decision은 여기서 3가지를 소개합니다.
Shift: BUFFER에서 STACK으로 이동하는 경우
Right-Arc: 우측으로 dependency가 결정되는 경우
Left-Arc: 좌측으로 dependency가 결정되는 경우
STACK이라는 자료구조를 통해서 shift를 할지 left-arc나 right arc를 할지를 결정하는데 도와주기 때문에 사용하는 것 같습니다.
보통 Arc의 라벨 개수를 17개 또는 45개로 정하며, 이에 따라 총 경우의 수는 (2 x 17 + 1) or (2 x 45 + 1) = 35 or 91개 입니다.
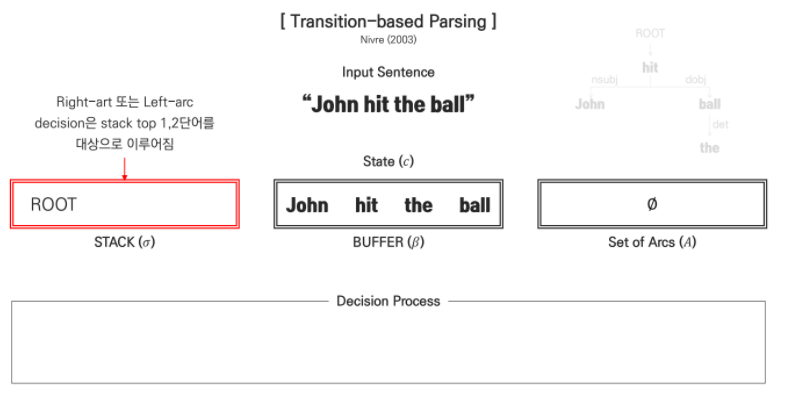
실제로 'John hit the ball.' 문장이 Transition-based 방법을 통해 parsing되는 과정을 알아보겠습니다.
초기 상태는 위에서 언급한대로 BUFFER에는 주어진 문장이 토큰 형태로 입력되어 있으며 STACK에는 ROOT만이 존재합니다.
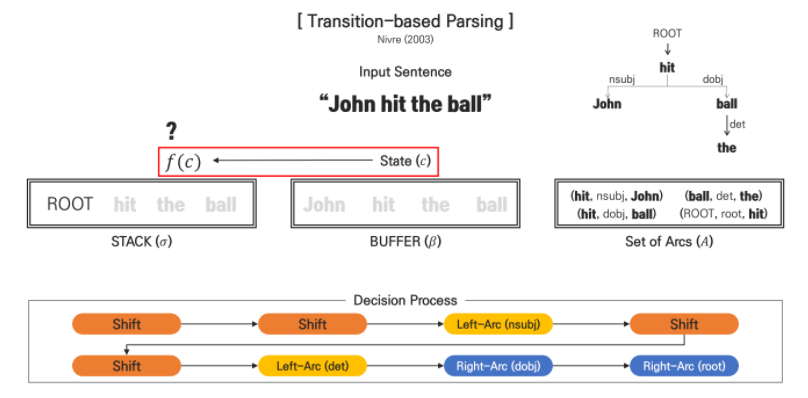
(1) STACK에 ROOT만이 존재하는 state는 'shift'라는 decision이 내려지게 되면서 'John'가 BUFFER에서 STACK으로 이동하게 됩니다.
(2) STACK에는 ROOT와 John 밖에 없기 때문에 Arc를 결정할 수 없어 state가 'shift'라는 decision이 내려지게 되고 'hit'가 BUFFER에서 STACK으로 이동하게 됩니다.
(3) STACK에는 ROOT, John, hit라는 state는 'hit'가 'John'를 수식하는 'Left-Arc'라는 decision이 내려지게 됩니다. 여기서 John의 위치를 2로 hit의 위치를 1로 생각해서 1에서 2로 왼쪽으로 가기 때문에 'Left-Arc'라고 생각하면 이해하기 쉽습니다.
이 때, 'hit'와 'John'이 관계가 형성되었기 때문에 해당 결과는 Set of Arcs로 이동하게 됩니다. 또한 dependent가 되는 단어(John)는 STACK에서 사라지게 됩니다.
(4) STACK에는 ROOT, hit라는 state가 Arc를 결정할 수 없는 상태이기 때문에 'shift'라는 decision이 내려지게 되면서 'the'가 BUFFER에서 STACK으로 이동하게 됩니다.
(5) STACK에는 ROOT, hit, the라는 state에서도 어떠한 관계가 형성되지 않는다고 판단했기에 'shift'라는 decision이 내려지게 되고 'ball'이 BUFFER에서 STACK으로 이동하게 됩니다.
(6) STACK에는 ROOT, hit, the, ball이라는 state에서 'ball'이 'the' 수식하는 'Left-Arc'라는 decision이 내려지게 되고 해당 결과(ball, det, the)는 Set of Arcs로 이동하게 됩니다. 이때도 위에서 처럼 오른쪽부터 순서를 매기면 hit(3), the(2), ball(1)로 1에서 2로 왼쪽으로 수식하기 때문에 'Left-Arc'라고 생각하면 됩니다.
(7) STACK에는 ROOT, hit, ball이라는 state에서 'hit'가 'ball'을 수식하는 'Right-Arc'라는 decision이 내려지게 되고 해당 결과(hit, dobj, ball)는 이동합니다. 이때도 hit(2), ball(1)로 2에서 1로 오른쪽으로 수식하기 때문에 'Right-Arc'라고 생각하면 됩니다.
(8) STACK에는 ROOT, hit라는 state에서 BUFFER에 토큰이 존재하지 않기 때문에 'shift'가 발생할 수 없습니다. 하지만 모든 토큰은 하나의 dependent를 가진다는 dependency parsing의 특징으로 'ROOT'가 'hit'를 수식하는 'Right-Arc'라는 decision이 내려지게 되고 해당 결과(Root, root, hit)는 이동합니다.
이렇게 문장의 모든 토큰이 BUFFER와 STACK을 통해 어떠한 관계가 결정되고 형성됨으로써 output으로 트리 형태로 표현이 가능해집니다.
앞서 언급했듯이, STACK에서 발생하는 어떠한 state를 기반으로 Decision을 결정하기 위해서는 SVM, NN, maxnet과 같은 모델이 적용됩니다. 이 과정에서 state를 모델이 input으로 받기 위한 state 임베딩 과정이 필요하게 됩니다.
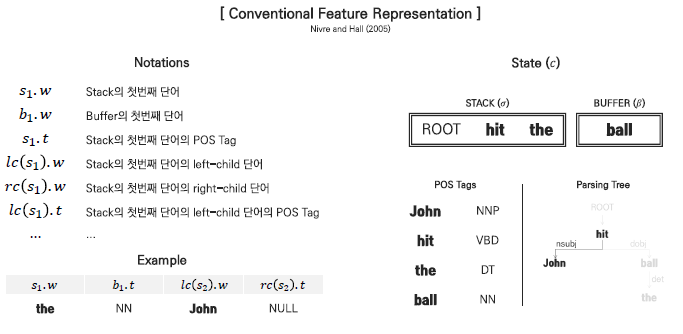
state를 임베딩하는 방법으로 2005년에 발표된 Nivre and Hall의 논문인 MaltParser: A Data-Driven Parser-Generator for Dependency Parsing의 feature representation을 살펴볼 수 있습니다.
먼저 (4)와 같은 state일 때, 해당 state가 임베딩되는 과정에 대해서 설명하겠습니다. 임베딩 과정을 알아보기에 앞서 임베딩을 위한 feature를 표현하기 위해서 notation을 확인할 수 있습니다. 이 때, 각 토큰의 tag를 활용하기도 합니다.
해당 state에 알맞은 notation 결과는 다음과 같습니다. s1xW는 the, b1xW는 ball, s1xt는 DT, lc(s2)xW는 John, rc(s1)xW는 Null로, 보여지는 notation은 일부분을 예시로 보여준 것으로 STACK의 두번째 단어 'hit'와 같은 notation을 추가적으로 뽑아낼 수 있습니다. 그리고 해당 notation의 결과를 찾아볼 수 없을 때에는 그냥 NULL을 부여하게 됩니다.
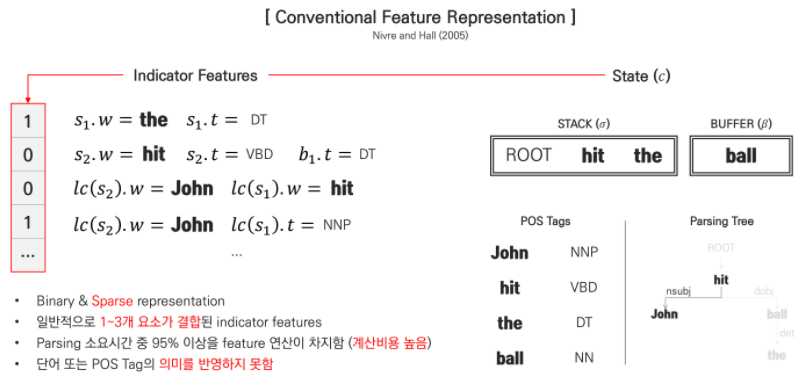
그렇다면 이러한 notation 기반으로 indicator features라는 조건을 설정함으로써 state를 임베딩할 수 있습니다.
예시를 보게 되면 STACK의 첫번째 단어가 'the'이고 STACK의 첫번째 태그가 'DT'면 1 아니면 0 이라는 값이 부여지게 됩니다. 이러한 조건들로 하여금 해당 state를 10^6, 10^7 차원의 벡터로 표현하게 되는 것이 state를 임베딩하는 방법이라고 합니다.
이렇게 state를 임베딩하는 방법은 1과 0인 binary로 표현되게 됩니다. 그렇기 때문에 sparse한 형태의 특징을 가지게 됩니다.
일반적으로 notation의 1~3개의 조합으로 indicator feature의 조건을 설정하며, 차원을 모두 계산해야 하기 때문에 Parsing 소요시간 중 95% 이상을 feature 연산이 차지하여 계산 비용이 높습니다. 이 과정에서 단어 또는 단어의 태그의 의미를 반영하지 못하는 단점이 있습니다.
4. Neural Denpendency parsing
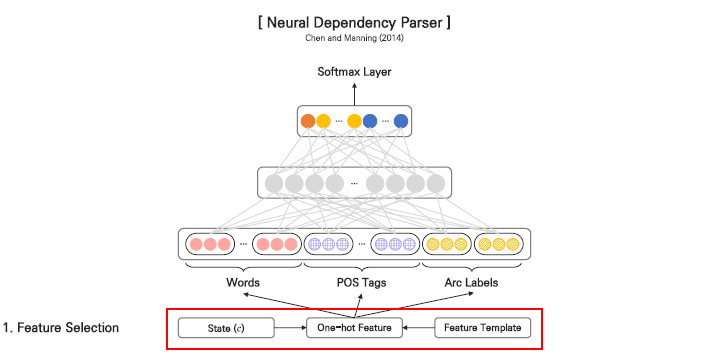
최근에는 신경망 기반의 방법론들이 발전하게 되면서 neural network가 적용된 Dependency Parsing에 대한 방법론도 제기되었습니다. 모델 구조는 기본적인 neural network 형태를 가지고 있습니다.
이 때, input으로 들어가는 state를 representation하는 방법에 대해서 보다 구체적이게 다루도록 하겠습니다.
input으로 들어가는 feature는 words 부분, POS tag(태그), arc labels 부분 3가지로 구분할 수 있습니다.
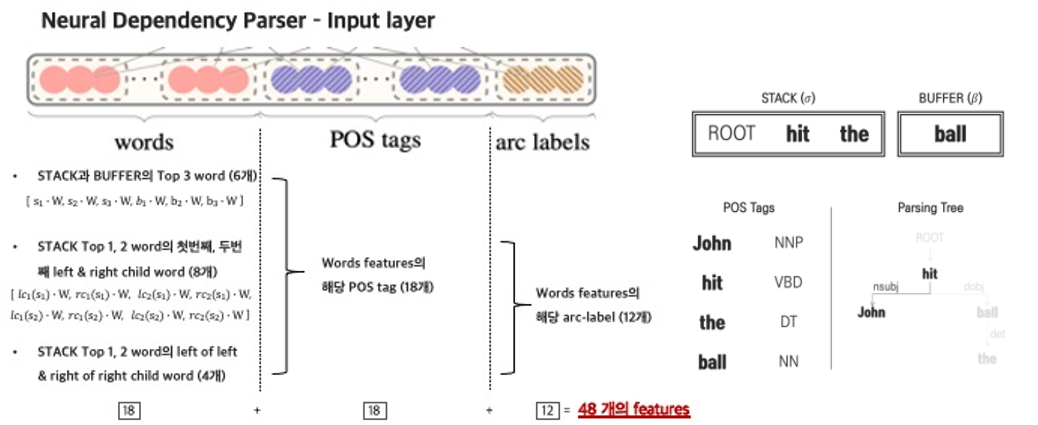
먼저 words feature로 들어가게 되는 데이터는 총 18개로 구성되어 있습니다.
- STACK과 BUFFER의 TOP 3 words (6개)
- STACK TOP 1, 2 words의 첫번째, 두번째 left & right child word (8개)
- STACK TOP 1,2 words의 left of left & right of right child word (4개)
다음 POS tags feature로 들어가게 되는 데이터는 words feature에서 들어가는 데이터의 태그를 의미하기 때문에 똑같이 18개가 됩니다.
마지막으로 arc labels에서는 STACK과 BUFFER의 TOP 3 words 6개를 제외한 12개의 label(dependent 관계 표시) 데이터로 구성되게 됩니다.
(4)의 state일 때의 input layer의 데이터를 확인하게 되면 각 feature별로 다음과 같이 확인할 수 있습니다. 이 feature에 해당하는 데이터들을 원핫으로 표현할 수 있게 됩니다.
- words feature는 (18 x 단어의 총 개수)
- POS tag feature는 (18 x POS tag 총 개수)
- Arc-label feauture는 (12 x label 총 개수)
이 때, 일반적으로 POS tag의 개수는 45개 정도라고 말합니다.
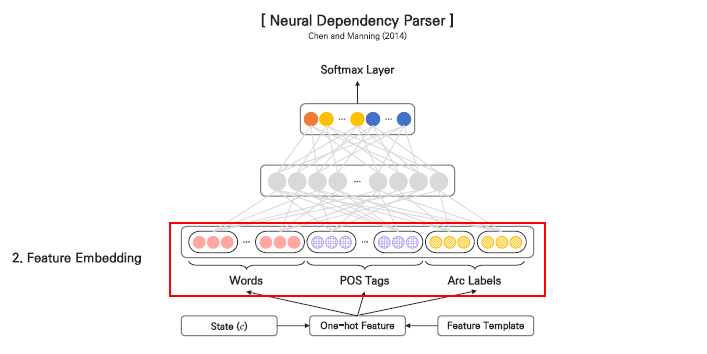
이렇게 포함된 데이터를 원핫으로 표현한 후에 word embedding matrix를 참고하여 해당 토큰의 벡터를 가져올 수 있습니다. 그렇다면 각 토큰별로 벡터가 있는 상태에서 모두 concat한 뒤에 input layer에 들어가게 됩니다.
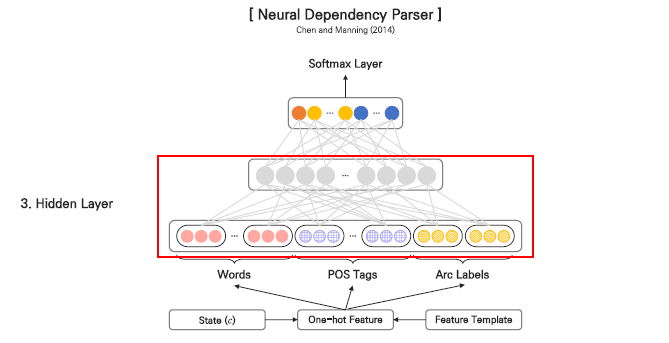
각 feautre별로 임베딩된 벡터가 input layer를 입력된 이후에 hidden layer에서는 Embedding Vector와 weight matrix를 곱한 뒤 bias vector를 더하는 일반적인 feed forward network의 계산이 진행됩니다.

이 때, 신경망에서 보통 쓰이는 ReLU, Sigmoid, Tanh과 같은 activation function을 사용하지 않고 word, POS tag, arc-label간 상호작용을 반영할 수 있는 cube function을 사용하게 됩니다. 엄밀한 수학적 증명을 하지는 않았으나 실험 결과 다른 비선형 함수 대비 우수한 성능을 기록한다고 합니다.
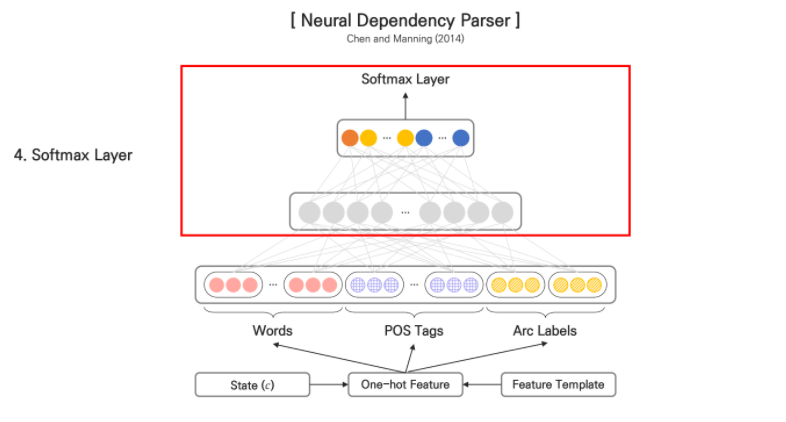
마지막으로 output layer에서 Decision이 결정되는 과정은 다음과 같습니다.
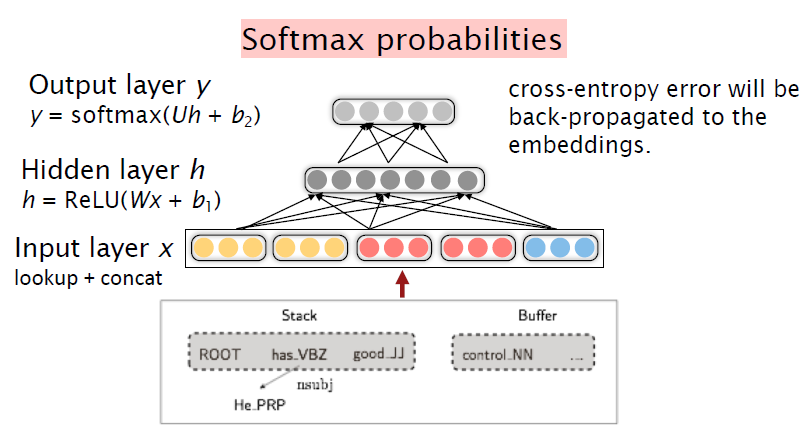
Input layer에서 입력 받은 vector를 Hidden layer에서 ReLU 함수를 통해 Hidden vector를 생성합니다. 그리고 만들어진 Hidden vector를 Softmax layer에서 Softmax 함수를 통해서 Output을 만들게 됩니다.
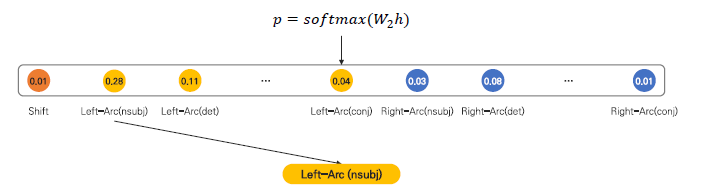
Hidden layer를 거친 feature vector를 linear projection(이동) 후 softmax 함수를 적용하여 Deicision으로 나타날 수 있는 모든 경우의 수의 확률을 구하게 됩니다. Shift, Left-Arc, Right-Arc 중 가장 확률값이 높은 경우의 수를 output으로 산출합니다. 위의 예시에서 해당 state에서는 nsubj의 관계를 가지는 Left-Arc의 경우가 Decision으로 선택되게 됩니다.
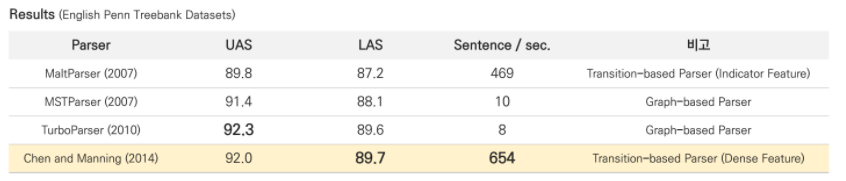
Neural Dependency parsing을 evaluation하는 방법으로는 Arc 방향만을 예측하는 UAS evaluation과 Arc 방향과 관계 label까지 예측하는 LAS가 있습니다.
각 parsing 방법에 따른 성능을 비교해보자면 목차 3에서 다뤘던 conventional features representation이 적용된 Transition-based parser(첫번째 parser)의 경우 모든 경우의 수를 체크하는 Graph-based parser보다 훨씬 빠르지만 성능이 조금 낮은 것을 확인할 수 있습니다. 하지만 Neural Network를 적용함으로써 Transition-based parser와 Graph-based parser보다 빠르고 좋은 성능을 이끌 수 있게 됩니다.
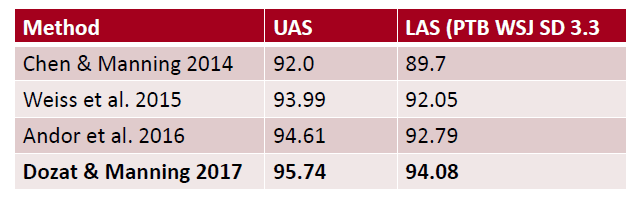
이후로는 greedy algorithms(Weiss et al. 2015)이 적용된 parser와 beam search(Andor et al. 2016)가 적용된 parser가 발표되었고 최근에 Graph-based와 Neural Network가 결합한 Neural graph-absed(Dozat & Manning 2017)가 적용된 parser가 굉장히 성능이 좋은 것을 확인할 수 있습니다.
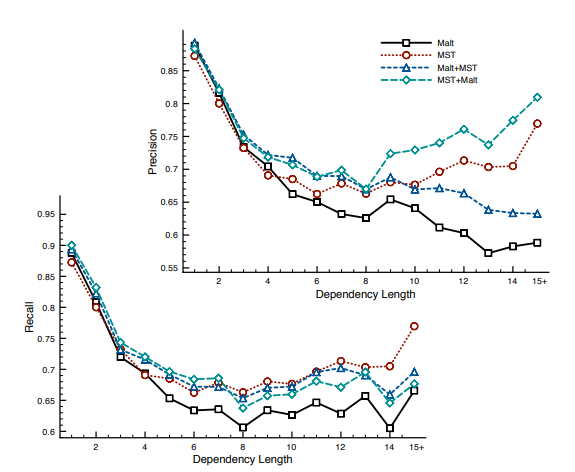
long-term dependeny에 관한 문제점은 다양한 결합 방법이 시도되고 있는데 Graph-based와 Transition-based parser를 결합하여 long-term dependency 문제를 어느 정도 해결할 수 있다고 합니다.
<요약>
참고자료
- http://dsba.korea.ac.kr/seminar/?mod=document&uid=42
- https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture05-dep-parsing.pdf
- https://gnoej671.tistory.com/5
- https://velog.io/@tobigs-text1314/CS224n-Lecture-5-Linguistic-Structure-Dependency-Parsing
- A Fast and Accurate Dependency Parser using Neural Networks, Chen & Manning, 2014
- Integrating Graph-Based and Transition-Based Dependency Parsers, Joakim Nivre & Ryan McDonald, 2008. (https://www.aclweb.org/anthology/P08-1108.pdf)

12개의 댓글

투빅스 14기 한유진
- 각 문장의 문법적인 구성 또는 구문을 분석하는과정인 parsing에 대해서 배웠습니다. 그중에서도 문장보다는 개별 단어간의 관계가 중점인 Dependency parsing에 대한 내용입니다.
- Dependency parsing의 방법중 Transition-based는 BUFFER, STACK, Set of Arcs 구조를 통해 이루어집니다. input sentence가 buffer에 담겨 stack으로 이동하며 발생하는 state를 기반으로 decision을 결정하기위한 모델들은 state임베딩을 input으로 받게됩니다.
- NN이 적용된 Dependency parsing은 input으로 들어가는 words, Pos tag, arc labels를 원핫으로 표현되고, hidden layer에서 임베딩벡터와 W를 곱하고, 마지막 layer에서 softmax를 통해 output을 내뱉습니다. 이를 평가하기 위한 방법에는 UAS, LAS가 있습니다.
parsing과정에 대해서 상세하게 알 수 있었던 강의였습니다. 좋은 강의 감사합니다!

투빅스 15기 조준혁
- 각 문장의 구성이나 문법을 분석하는 과정을 Parsing이라고 합니다. Parsing은 Constituency Parsing과 Dependency parsing 두 가지가 존재합니다.
- Constituency Parsing은 문장의 구조를 파악하는 것을, Dependency Parsing은 단어간의 관계를 파악하는 것을 주목적으로 합니다.
- Dependency parsing에서 고려되는 보편적인 특징은 두 단어 사이의 실제 의미가 들어나는 관계, Dependency의 거리는 주로 가까운 위치에서 dependent 관계가 형성, 마침표, 세미콜론 등으로는 dependent 관계가 형성되지 않음, head의 좌우측에 몇 개의 dependents를 가질 것인가에 대한 특성입니다.
- Dependenct Parsing에도 크게 두 가지 기법이 있는데, 두 단어의 의존여부를 순서대로 결정하는 Transition-based 기법과 가능한 의존 관계를 모두 고려하는 Graph-based 기법이 존재합니다.
Dependency Parsing에 대한 기본 개념을 잘 배울 수 있었던 강의였습니다. 감사합니다.

투빅스 14기 이정은
- Parsing은 문장의 구성과 구문을 분석하는 방법으로, 문장을 중첩된 성분으로 나눠 구조를 파악하는 Constituency parsing과 개별 단어 간의 관계를 파악하는 Depenency parsing이 존재합니다.
- Dependency parsing 중 Transition-based는 두 단어의 의존 여부를 차례로 결정하는 점진적인 방법입니다. Buffer, Stack, Set of arcs를 통해 buffer에 있는 토큰이 stack으로 이동하면서 state/right-arc/left-arc 등의 decision을 내리게 됩니다.
- Transition-based에서 state의 embedding은 sparse하게 표현이 되는데, 이를 해결한 방법이 Neural Dependency parsing입니다. 이는 words / pos tag / arc labels를 dense하게 concat하여 학습을 진행하고, softmax를 거친 후 decision을 선택합니다.
Transition-based의 parsing 과정을 자세히 설명해주셔서 정말 좋았습니다! 감사합니다 : )

투빅스 14기 정재윤
Dependency Parsing에 대해서 집중적으로 진행한 강의였습니다.
-
Parsing에는 크게 두 가지 방식이 있는데 하나는 문장의 구성을 바탕으로 파악하는 Constituency parsing과 단어들의 의존성에 기반하여 분석하는 Dependency parsing이 있다. 최근에는 Dependency parsing이 관심을 받고 주목받고 있다.
-
Dependency parsing은 크게 Transition-based와 Graph-based 2가지 방식으로 진행할 수 있다. Transition based의 경우, 분석 속도는 빠르지만 정확도는 떨어지지만 반대로 Graph based의 경우, 분석속도는 느리지만 정확도가 좋다고 한다.
-
최근에는 Neural Dependency parsing 방법이 만들어지면서 다시 한 번 발전하게 됐다. 위의 두 가지 방식의 장점들을 모두 가진 모델로 기본적인 Neural Network의 구조를 가지고 있다. 또한 word, POS tag, arc-label간 상호작용을 반영할 수 있는 cube function을 사용지만 이는 엄밀히 수학적 증명이 이루어지진 않았다.

투빅스 15기 조효원
언어학적인 개념이 어떻게 자연어처리에서 사용되는지 보여주는 대표적인 예시였습니다.
context-free grammar처럼 사전에 있는 통사 규칙을 이용해 탑다운 방식으로 구를 나누는 constituency parsing과 bottom-up 방식으로 특정 구와 다른 구의 관계를 고려해 단위를 엮어나가는 Dependency parsing을 배웠습니다. 이때 dependency parsing의 대표적인 방법은 transition-based dependency parsing으로, 점진적으로 의존 관계를 결정해 트리를 만들어갑니다. 그러나 이 방법은 일방향으로 진행되기에 모든 경우를 다 고려할 수 없으며, 따라서 빠르지만 정확도가 낮습니다. 이러한 문제들은 신경망을 이용함으로써 해소됩니다.

투빅스 15기 강재영
각 문장의 문법적인 구성이나 구문을 분석하는 과정인 Parsing에 대해 이해할 수 있었던 시간이었습니다.
Parsing의 대표적 방법으로 Dependency Parsing과 Constituency Parsing 두가지가 있습니다.
- Constituency Parsing은 문장의 구조를 파악하는 것이 주목적이며, 명사/형용사 등 문장구성요소를 파악하는 것이 초점입니다.
- Dependency Parsing은 단어간 의존관계를 파악하여 구조를 분석하는 방법입니다.
- Dependency Parsing에는 네가지 방법이 있습니다.
- Dynamic programming
- Graph algorithms
- Constraint Satisfaction
- Transition-based
- Transition-based 는 두 단어의 의존여부를 차례대로 결정해나가면서 점진적으로 의존관계를 구성해가는 방법이며, Graph-based는 가능한 의존관계를 모두 고려한 후 확률적으로 가장 높은 트리를 선택하는 방법이다.
- Transition-based는 속도가 빠르지만, 정확도가 Graph-based에 비하면 낮음
- Neural Dependency parsing는 Transition-based보다 정확하고 Graph-based보다 빠른 방법
- Dense Feature 및 NN Model을 적용한 Parsing 방법
- 특이점으로는 ReLU, Sigmoid, Tanh가 아닌 Cube Function을 사용함 ( word, POS tag, arc-label간 상호작용을 반영하기 위해서 )

투빅스 15기 이수민
Parsing은 각 문장의 문법적인 구성 또는 구문을 분석하는 과정으로, 목적에 따라 두 가지로 나눠집니다
- Constituency Parsing은 문장을 중첩된 성분으로 나누어 문장의 구조를 파악하는 것이 목적인 파싱 방법입니다.
- Dependency Parsing은 전체적인 구조보다는 개별 단어의 관계를 파악하는 것에 중점을 둔 방법입니다.
Dependency Parsing을 하는 두 가지 방법
- Transition-based 방법은 두 단어의 의존여부를 순서대로 결정하는 것이 핵심이며, 상대적으로 속도는 빠르지만 정확도는 낮은 방법으로 알려져 있습니다.
- Graph-based 방법은 가능한 dependency 구조들 중 가장 확률이 높은 구문분석 트리를 선택하는 것으로, 가능한 의존 관계들을 모두 고려하기 때문에 정확도가 높습니다.
Neural Dependency Parsing
- 일반적인 feed-forward network 구조와 같지만 feature definition과 activation에서 차이가 있습니다.
- ReLU, Sigmoid, Tanh과 같은 activation function을 사용하지 않고, cube function만을 사용합니다.

투빅스 14기 박준영
이번강의는 parsing에 관한 강의였습니다.
- parsing은 각 문장의 문법적인 구성 또는 구문을 분석하는 과정으로 문장의 구조를 파악하는 consituency parsing, 단어간 관계를 파악하는 Dependency parsing으로 나뉩니다.
- parsing을 통해 모호한 문장을 올바르게 이해하기 위해 필요합니다.
- Dependency parsing는 Dynamic programming, Graph algorithms, constraint satisfaction, transition-based기법이 있다.
- Transition-based dependency parsing은 Buffer, stack, set of arcs의 구조를 가지고 있다. 초기에 buffer에는 주어진 문장이 토큰 형태로 들어가 있으며 토큰들이 stack으로 이동하며 state를 형성한다. 이 state를 통해 Decision(svm, NN) 모델을 적용하여 set of Arcs에 결과물이 담기게 된다.
- 이때 state를 모델 input으로 받기 위해 state 임베딩 과정이 필요하게된다.
- 최근에는 NN이 적용된 Dependency parsing 방법론도 있다. 이때 input feature로 words, pos tag, arc labels 3가지가 들어간다.
- 그 후에 words, pos tags, arc labels 들을 concat한 뒤에 input으로 들어가서 softmax를 통과하여 동작하는 모델이다.
Dependency parsing에 대해 자세히 배울 수 있었던 강의였습니다. 감사합니다.

투빅스 14기 강의정
Lecture 5 - Linguistic Structure: Dependency Parsing를 주제로 발표해주셨습니다.
- parsing은 문장의 구조를 파악하는 것이 주 목적인 Consitituency parsing과 단어간 관계를 파악하는 것이 주 목적인 Dependency parsing이 있습니다.
- Transition-based dependency parsing은 Dependency parsing의 방법 중 하나로 두 단어의 의존여부를 파악하며 점진적으로 구성하는 방법입니다.
- BUFFER, STACK, Set of arcs 세가지의 구조를 갖고 있으며 BUFFER에 있는 토큰을 STACK으로 이동하며 state를 갖고 state에 따른 결정을 합니다.
- Neural Denpendency parsing은 Dependency Parsing에 neural network를 적용한 것으로 앞서 제시되었던 방법보다 성능이 좋습니다.
투빅스 15기 이윤정
- Parsing이란 문장 속 단어 혹은 구성 요소의 관계를 결정하는 방법으로 목적에 따라 consitituency와 dependency parsing으로 구분되어집니다. 이때, consitituency parsing은 어순이 비교적 고정적인 언어에서 주로 사용되며 dependency parsing은 어순이 자유롭거나 문장성분이 생략 가능한 언어에서 주로 사용되고 있습니다.
- dependency parsing은 root라는 가상의 노드를 통해 모든 단어가 1개의 의존 관계를 갖도록 설정합니다. 이때, 중복 관계는 형성되지 않으며 두 단어 사이의 실제 의미가 드러나는 관계에 대해 고려되어집니다. 이때, 의존 여부를 순서대로 결정하는 Transition-based와 모든 의존 관계를 고려하는 Graph-based 방법이 존재합니다.
dependency parsing에 대해 자세히 배울 수 있는 유익한 시간이었습니다. 감사합니다.
투빅스 14기 정세영
Dependency Parsing에 대한 전반적인 개념을 잘 짚어주신 강의였습니다.
Dependency Parsing이란 모든 단어가 1개의 dependency를 가지도록 분석하는 것을 의미
Transition-based parsing
Neural Dependency parsing