[CS224N] Lecture 11 : Question Answering
1. Question Answering
1) Qusteion Answering 이란

QA는 사람의 언어로 된 질문에 자동적으로 답할 수 있는 시스템을 만드는 것
ex. 구글에 질문을 검색했을 때, 그에 알맞는 답을 하는 것
2) Qusteion Answering : a taxonomy
- QA가 만들어지는 정보소스는 어떤 문단, 웹 문서, 이미지가 될 수도 있음
- QA의 질문유형
- 누구인지, 무엇인지 등을 묻는 Factoid 질문 vs 그렇지 않은 non-factoid
- Open domain vs closed domain
- Compositional 한 질문 vs Simple 한 질문
- 답 유형은 문단의 일부분, 리스트 형태, yes/no의 형태로 나타날 수도 있음
3) Question Answering in deep learning era
대부분의 SOTA QA 시스템들은 end-to-end train과 pre-train된 language model 위에 build하게 됨
4) Beyond textual QA problems
오늘날에는 text뿐만 아니라 unstructured text에 기반한 질문에 답하고자 함
대량의 데이터베이스에 대해서 QA를 구축하고자 하는 ‘knowledge based QA’가 있고, 이미지에 기반한 ‘Visual QA’도 존재함
2. Reading Comprehension
1) Reading Comprehension

텍스트로 이루어진 문단을 이해하고, 해당 내용에 대한 질문에 답을 하고자 하는 것
→ 문단과 질문이 있으면 그에 알맞은 답을 반환하는 것
- 컴퓨터가 얼마나 사람의 언어를 잘 이해하는지 평가할 수 있는 testbed이므로 중요
- 또다른 많은 NLP task도 reading comprehension 문제로 단순화가 가능하기 때문에 중요
- ex. Information Extraction task(정보 추출 태스크)에서 어떤 정보를 추출하고자 할 때, 정보를 질문으로 바꾸어서 생각해볼 수 있음

2) Standford Question Answering Dataset (SQuAD)

- SQuAD : (passage, question, answer)의 쌍으로 이루어진 약 100K개의 데이터셋
- passage : wiki-pedia에서 100~150개의 단어로 이루어진 문단들
- question : 사람들이 문단을 읽고 질문과 그에 알맞은 답을 만드는 방식으로 만들어짐
- answer : 모든 질문에 대해 unique한 답이 없을 수 있기 때문에, 질문에 대한 3개의 가능한 답을 넣어줌 (short segment of text, 즉 span)
- 의의 : large-scale-supervised dataset인데, 이러한 데이터셋은 reading comprehension을 위한 nueral model들을 train하는데 굉장히 중요한 요소로 작용하기 때문에 의의가 있음
- 한계 : answer가 passage의 일부여야 한다는 한계가 있음
- 평가지표
- Exact Match (EM) : 3개의 answer에 대해 span 존재여부에 따라 0과 1 accuracy 값 획득
- F1 score
- 평가방법(예시)
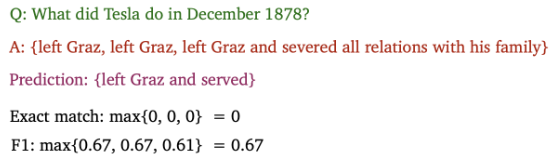
예측값을 정답(gold answer)과 비교하며 EM과 F1을 계산(a, an, the. .(구두점) 제거)
→ Max Score 계산 → 모든 example에 대해 EM과 F1의 평균을 계산해 평가\
3) How can we vuild a model to solve SQuAD?
SQuAD의 reading comprehension을 위한 neural model을 어떻게 build 해야하는지에 대해 살펴봄

- input : 어떤 문단과 질문 (Context & Query)
- context는 n개의 token으로 이루어져 있고, query는 m개의 token으로 이루어져 있음
- context의 토큰 개수는 100~200개이고, query의 토큰 개수는 10~15개
- 따라서, query가 context보다 짧은 구조를 이루게 됨
- output : 답 (Answer)
- answer은 context의 일부분이기 때문에 context의 토큰개수 1부터 n까지 중에 start와 end point를 찾아내어 답을 산출하게 됨
- SQuAD를 푸는 2가지 종류의 neural model
- 1. LSTM 기반 모델
- 2. BERT 기반 모델
4) seq2seq model with attention
모델을 살펴보기에 앞서, machine translation(기계번역)과 reading comprehension(독해)을 비교
-
Machine Translation
- Source, Target 문장
- decoder가 단어 하나하나씩 target sentence를 generate 해야하므로 auto-regressive 해야함
- 알고자 하는 것 : Source 문장의 어떤 단어가 현재 Target 단어와 가장 관련이 있을까?
-
Reading Comprehension
- Passage, Question (길이 다를 수 있음)
- generate 하지 않기 때문에 answer의 start, end의 위치를 예측하는 classifier 2개만 학습하면 됨
- 알고자 하는 것 : Passage의 어떤 단어들이 Question의 어떤 단어와 가장 관련 있을까?
⇒ 이것들에 대해 알고자 할때, ‘Attention’이 굉장히 중요한 요소로 작용
4-1)
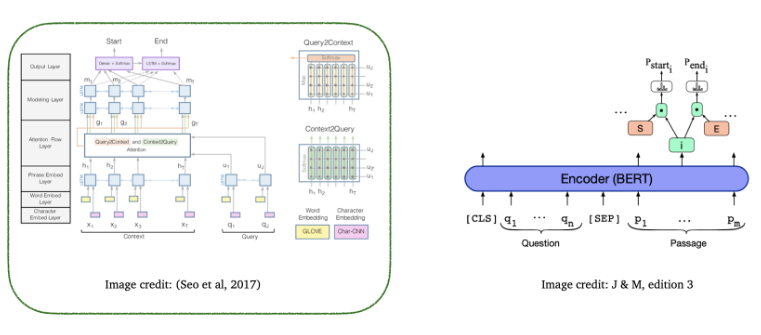
[1] The Bidirectional Attention Flow model (BiDAF) ⇒ LSTM based
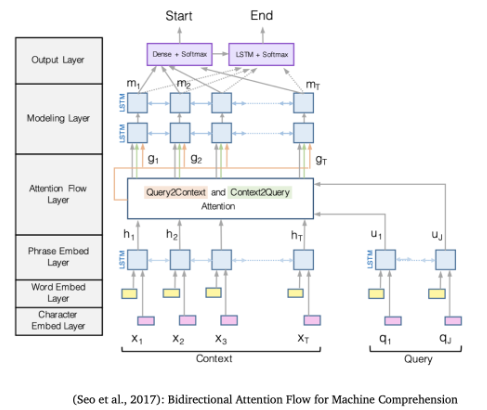
- BERT가 나오기 전, SQuAD datatset에 대한 reading comprehension task에서 SOTA 였음
- attention이 question에서 paragraph로, paragraph에서 question으로 양방향으로 적용된다는 점이 주목할만한 점임
- Embedding layer

word embedding : Glove 이용해서 각 단어를 벡터 공간에 임베딩 함
character embedding : character level로 CNN을 적용해서 벡터 공간으로 매핑시킴
- context와 query의 각 단어에 대해 word embedding과 character embedding을 구한 다음 concat
- concat한 벡터를 LSTM에 넣기 전에 2-layer highway network를 거침
- contextual embedding 생성을 위해 context와 query에 대해 각각 bi-directional LSTM을 거쳐 양방향 hidden state를 concat
- : representation / : 두 방향의 hidden representation을 concat한 것
- Attention flow layer → 가장 핵심적인 구조
- 목표 : query와 context 사이의 interaction을 capture
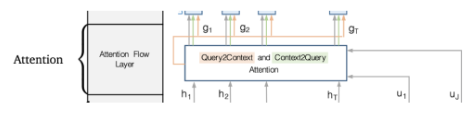
- Attention Flow Layer는 2가지 단계로 이루어져 있음
- (, ) 쌍에 대해 유사도를 계산 (양방향 어텐션을 가능하게 하기 위해 shared matrix S를 사용함)
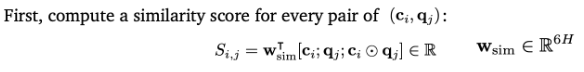
→ 와 의 element wise multiplication을 conat한 것과 w를 이용해서 유사도를 계산 ⇒
- 2가지의 attention을 계산
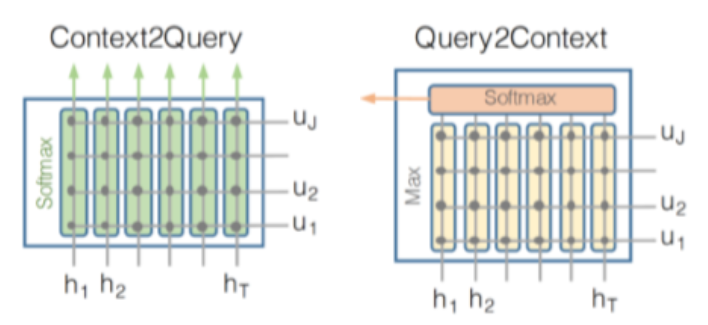
→ context-to-query attention (질문의 어떤 단어들이 문단 단어들()과 관련 있는지)과 query-to-context attention(문단에서 어떤 단어들이 질문 단어들()와 관련 있는지)를 연산 - 1. Context-to-Query Attention

- 각각의 context 단어에 대해 가장 연관된 query 단어를 찾음 (각 문단 단어에 어떤 질문 단어들이 더 관련있는지)
- ex. context의 버락 오바마는 query에서 who와 가장 유사함

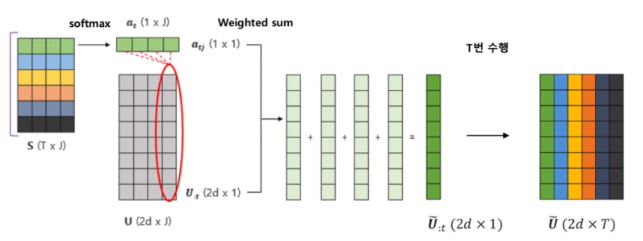
T는 i, a는 , U는 q, 는 a라고 생각하기
- = → i x j 의 shared matrix S에서 i번째 행에 대해 softmax를 취한 것
- = → 의 j번째 element 값
- = → question에 대한 bi-LSTM output 중 i번째 벡터
- = → 와 weighted sum을 한 값
: 앞서 구한 유사도 → softmax를 취해서 를 구함
→ 는 i번째 context 단어에 대해서 각각의 query의 단어들의 attention weight가 됨
→ 와 contextualized vector인 의 weighted sum을 해서 a matrix를 구하게 됨
- 2. Query-to-Context Attention

- query 단어 중 하나와 가장 관련 있는 context 단어들을 선택함 (하나의 질문 단어에 대해 어떤 문단 단어들이 가장 유사도가 높은지)
- ex. query의 gloomy는 context에서 gloomy cities와 가장 관련있음

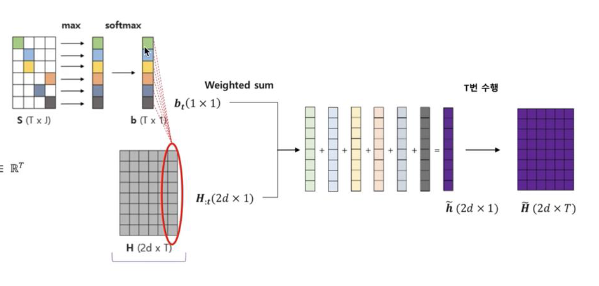
- = → i번째 element 값
- = → context 내에 bidirection한 output 중 i번째 벡터
- = b → 랑 weighted sum한 값
를 구할 때는 앞서 를 구할 때와 다르게, 행별로 max 값만 가져와서 별도의 벡터를 구성하고, 이에 대해 softmax 값을 취해주어 (ix1) 사이즈의 벡터 를 구함
→ 값은 다른 context 단어에 비해서 이 단어가 얼마나 중요한지를 나타내게 됨
→ 와 contextualized vector인 를 wieghted sum해서 b를 구하게 됨

⇒ : final output → , , 와 의 element wise multiplication, 와 의 element wise multiplication를 모두 concat한 값
- Modeling and Output layers
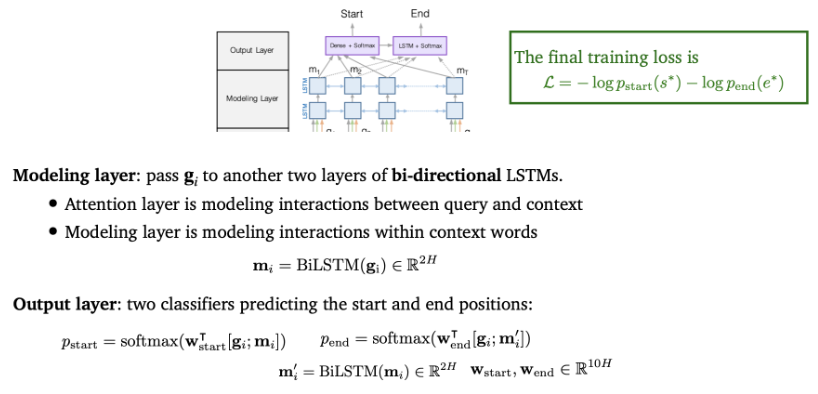
- Modeling layer : context words 사이의 interaction을 cature
-앞에서 구한 를 또다른 bidrectional LSTM의 2개의 layer로 전달해서 을 뽑음
- Attention layer에서 query와 context 사이의 interaction을 모델링했다면, Modeling layer에서는 context 단어들 사이의 interaction을 모델링함
- Output layer : 2가지의 classifier로써, start/end position을 예측하는 레이어
- answer의 start, end point 위치를 예측하는 classifier가 존재
- 와 를 concat하고 w와 dot product 한 것에 softmax를 해서 시작점과 끝 점을 구함
- Final training loss는 시적점과 끝점의 negative log likelihood를 최소화하도록 구성됨
➡️ BiDAF : Performance on SQuAD

결과적으로 BiDAF가 SQuAD에 대해서 어떤 성능을 보였는지 살펴보면,
- BiDAF는 2가지 attention을 사용 → 2가지 중 하나를 빼게 되면, 2가지를 모두 사용했을 때보다 성능이 떨어짐
- 다른 모델들과 비교했을 때, BiDAF는 굉장히 좋은 성능을 보임
➡️ Attention Visualization
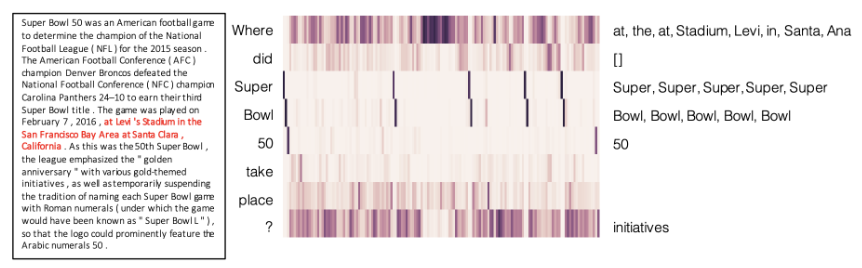
- 실제로 context와 question 사이의 유사도를 capture할 수 있는지 보여주는 attention visualization
- 왼쪽 : query의 각 단어들 / 오른쪽 : context word 중 가장 높은 점수를 갖는 단어들
- 각각의 칼럼들 : attention score
- where라는 query 단어에 가장 잘 align되는 단어들은 at, the, at ~~ 단어들
4-2)
[2] BERT for reading comprehension ⇒ BERT based
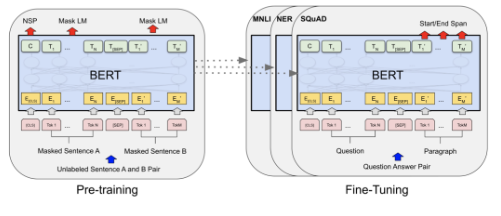
- reading comprehension에서 BERT 모델들이 어떻게 활용되는지 살펴보기
[BERT]
- BERT는 대량의 text에 pretrain된 Deep Bidirectional Transformer Pretrained Encoder임
- BERT에는 BERT_base와 BERT_large가 있는데, 각각 레이어와 파라미터의 차이가 존재
- 2가지의 pretraining objective가 존재
- Masked language model (MLM)
- 입력 토큰 중 일부를 마스킹해서 가리고, 가려진 토큰이 어떤 것인지 예측하는 태스크
- Next sentence prediction (NSP)
- 두 개의 문장이 이어지는 문장인지 모델이 맞추도록 하는 태스크
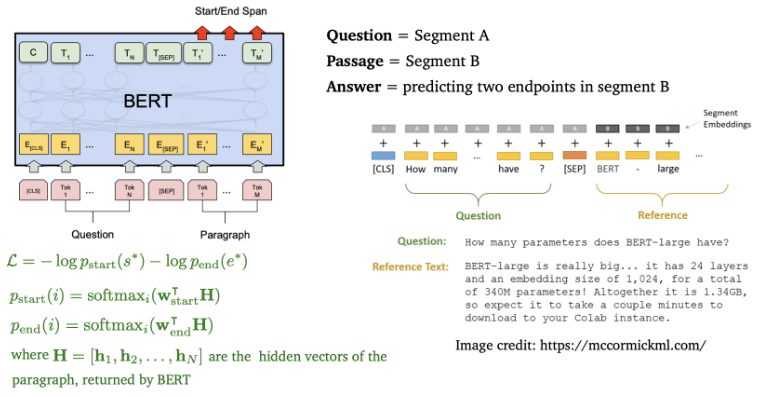
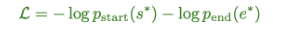
- NSP에서는 2가지의 segment를 사용
- Question 질문
- Passage 문단
- Answer 정답은 Passage의 일부이기 때문에 passage에서 시작과 끝점을 예측하는 것 (segment B의 2개의 endpoint를 에측하는 것)
- Question 토큰과 passage token을 [sep] 토큰을 경계로 concatenate 함
- Final training loss는 시작점의 negative log likelihood와 끝점의 negative log likelihood로 계산
4-3) Comparisons between BiDAF and BERT models
-
BiDAF
- ~2.5M 파라미터
- 다수의 bidirectional LSTM 위에 build
- Glove 위에 build
-
BERT
- 110M or 330M 파라미터(훨씬 더 많음)
- transformer 위에 build
- pretrain되는 특징
-
question과 passage 사이의 interaction을 모델링하고자 함
-
BiDAF에 passage에 대한 self-attention layer를 추가하면 성능이 좋아짐
4-4) Can we design better pre-training objectives?
- BERT에는 2가지의 pretraining objective가 있었음 (MLM, NSP)
- 조금 더 나은 pretraining objective를 고안한 모델 → SpanBERT
[3] SpanBERT : Improving Pre-training by Represneting and Prediction Spans
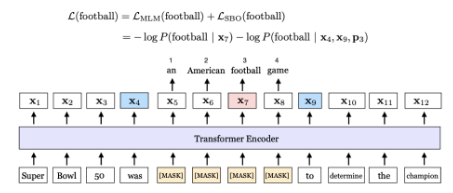
- 핵심 아이디어 2가지
- MLM task를 할 때, 각 단어를 15%의 랜덤 단어로 마스킹하는 것이 아닌, 인접한 단어의 span을 마스킹하자
- endpoint 사이에 있는 마스크된 단어들을 예측하기 위해 2개의 endpoint에 span의 정보를 압축하여 넣자 → 2개의 endpoint를 이용해 endpoint 사이의 모든 masked span을 예측하자
ex. 노란색 부분처럼 마스킹된 부분들이 있을 때, 파란색 부분의 endpoint를 이용하자는 아이디어
- endpoint 사이에 있는 마스크된 단어들을 예측하기 위해 2개의 endpoint에 span의 정보를 압축하여 넣자 → 2개의 endpoint를 이용해 endpoint 사이의 모든 masked span을 예측하자
→ span 안에 있는 모든 단어들을 예측하려고 하기 때문에 SpanBERT라고 부름 + 성능이 훨씬 좋아짐
4-5) Is reading comprehension is solved?
- SQuAD 데이터셋에 대해 모델들은 인간보다 뛰어낸 성능을 나타내지만, reading comprehension이 이미 해결된 문제라 볼 수는 없음
- 문제점
- Adversarial example에 대해 낮은 성능을 보임
- context와 관련없는 문장에 대해 낮은 성능을 보임

- Out-of-domain distribution의 example에 대해 낮은 성능을 보임
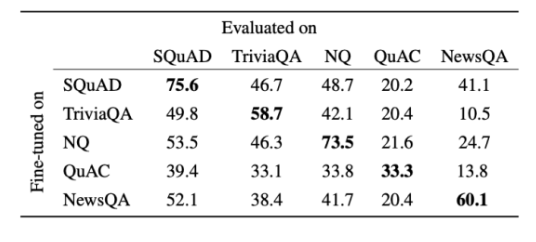
- 한 데이터셋에 대해 train된 시스템들은 다른 데이터셋으로 일반화되지 못함
- SQuAD로 파인튜닝된 모델은 SQuAD로 평가할 때는 성능이 높지만, 다른 데이터셋에 대해서는 낮은 성능을 보이는 문제
3. Open-domain question answering
1) Open-domain question answering
- Closed-domain : 특정 분야 또는 도메인을 다루는 것
- Open-domain : 특정 분야에 국한되지 않고 모든 분야를 다루는 것
- Reading Comprehension과 다르게, Passage가 주어져 있다고 가정하지 않음
- 대신, 다량의 document에 접근이 가능함 (ex. wikipedia)
- 정답이 어디에 위치해 있는지 모름
- 목표 : 어떠한 open-domain 질문에도 답하자!
- 훨씬 어렵지만 더 practical함
2) Retriever-reader framework

- 2017 reading wikipedia to answer open-domain question이라는 논문에서 Open-domain question answering 문제를 retrieval-reader framework를 이용하여 해결할 수 있다고 발표함
- 핵심 아이디어 : Question의 text에 대해 retrieve하고, 관련있는 모든 document를 모두 찾아보는 방식으로 해결하자
→ Open-domain question answering는 Document retriever과 Document Reader의 2부분으로 구성됨
[1] Reading Wikipedia to Answer Open-Domain Questions (ACL 2017)

- 1. Document Retriever : 질문 관련 문서를 검색하는 부분
- input : 질문과 여러가지 web document들
- output : 질문과 관련있는 문장들이 나옴
- 통계 기반의 전통 information-retrieval 모델로, 이 부분은 학습시키지 않음
- standard TF-IDF (fixed module)
- 2. Document Reader : 정답을 추출하는 부분
- input : 질문과 retriever에서 반환된 질문과 관련된 document들
- output : 정답
- RNN에 기반한 딥러닝 모델이며, 이 부분은 학습을 시킴
- 학습시킬 때, SQuAD, Distantly supervised data를 이용해 학습시킴
- reading comprehension model과 관련
3) We can train the retrever too
- 앞에서는 retriever를 학습시키지 않는다고 말함
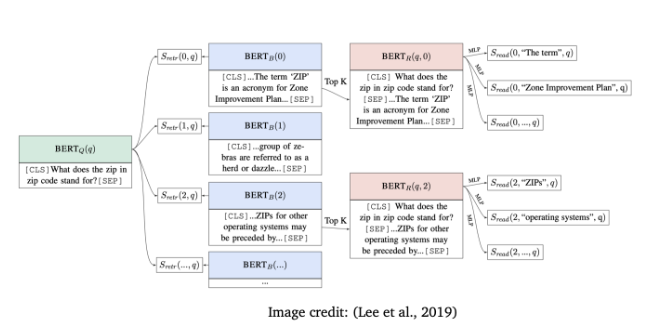
[2] Latent Retrieval for Weakly Supervised Open Domain Question Answering
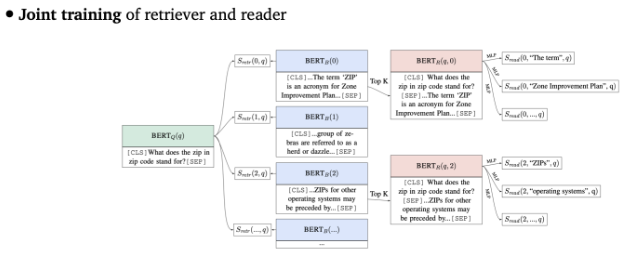
- retriever part 또한 학습할 수 있다고 제안 → retriever를 어떻게 학습시킬 수 있는지 방법 소개
- question과 passage는 BERT를 이용해 encode될 수 있음
- retrieval score를 이용하여 question과 passage사이의 유사도를 계산하여 retriever를 학습
- question representation과 passage representation 사이의 dot product 계산값
- 단점 : passage 수가 많을 때는 모델링이 쉽지 않음
[3] Dense Passage Retrieval for Open-Domain Question Anwering
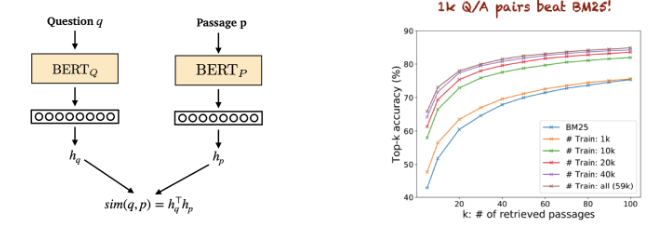
- retriever를 학습시킬 수 있는 또 다른 방법, 훨씬 더 간단한 방법
- Dense passage retrieval(DPR)를 이용하면, (Question, Answer) 쌍을 이용해 retriever를 학습 가능하다고 제안
4) Without an explicit retrieval stage
[4] How Much Knowledge Can You Pack Into the Parameters of a Language Model? (T5)
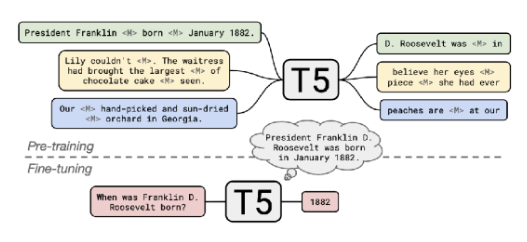
- 명백한 retriever stage가 없어도, 매우 큰 모델을 사용하면 open-domain QA가 가능하다고 설명
- pretrain된 T5모델을 가지고 파인튜닝해서, open-domain QA를 수행
- input : 질문
- output : 답
5) Maybe the reader model is not necessary too
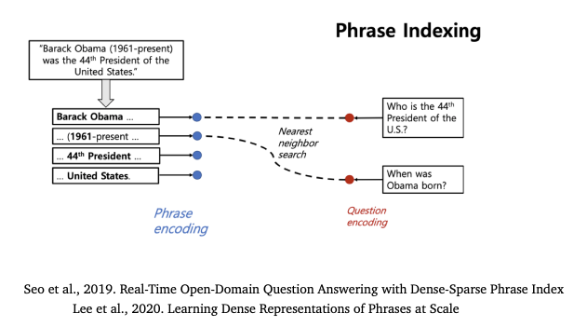
[5] Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
Learning Dense Representations of Phrases at Scale 49 DensePhrases : Dem
- reader 모델 자체도 필요없을 수 있다고 제안 → reader 단계가 없어도, open-domain QA를 잘 수행할 수 있다고 설명
- Dense 벡터만을 이용해서 wikipedia에 있는 60M개의 모든 구문(phrase)들을 인코드할 수 있다고 제안
- Inference time에 BERT 모델 없이, nearest neighbor search(최근접 이웃 탐색)를 하자는 아이디어 제공
4. References
https://www.youtube.com/watch?v=NcqfHa0_YmU
https://www.youtube.com/watch?v=iR2Rpp9_YEo
https://changhyeonnam.github.io/2022/02/04/cs224n_lec11.html
https://blog.naver.com/PostView.naver?blogId=skchajie&logNo=222085253962&from=search&redirect=Log&widgetTypeCall=true&directAccess=false
