[CS224n] Lecture 10 : Pertaining transformer
목차
1. Motivations of pretraining transformer
2. Three ways of pretraining
3. In-context learning
부록. Parameters and datasets
1. Motivations of pretraining transformer
- Subword
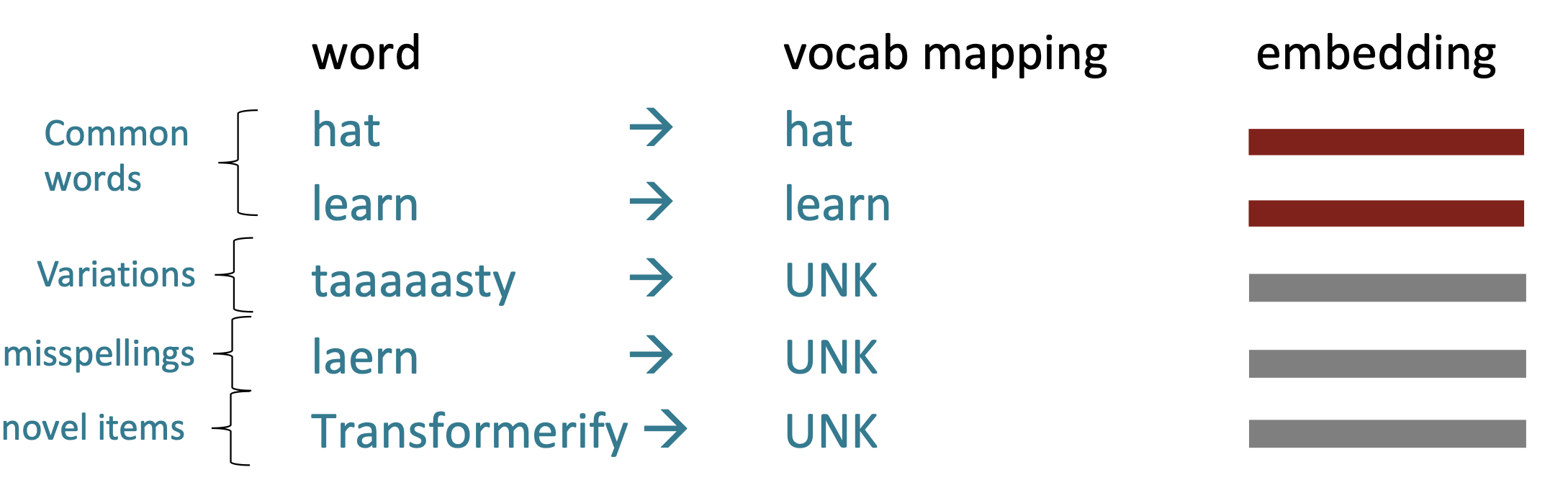
빈도수가 높게 사용되는 단어들은 임베딩하기 쉽지만 빈도수가 높지 않은 은어, 오타 및 신조어는 Word2Vec 기반의 기계를 이용해서 임베딩 하는 것은 현실적으로 불가능하다.
또한, 영어 외에 아프리카의 소수 민족의 언어나 영어보다 복잡한 언어는 기계를 이용한 학습이 더 어렵다.
한국어와 NLP
1. 교착어

접사에 따라 문법적 기능이 매우 달라진다.
예) '사과가', '사과는', '사과를', '사과에게'
2. 유연한 어순
어순에 관계 없이 맥락을 이해하는 데에 어려움이 없고 문법적으로 오류가 없다.
3. 평서문과 의문문
주어를 생략한 문법 구조 때문에 평서문과 의문문이 문법적으로 차이가 없다.
< 출처 : https://media.fastcampus.co.kr/knowledge/data-science/nlp-korean-4reasons/ >


 그래서, 아무리 거대한 데이터셋을 이용해서 학습을 했어도 접해보지 못 한 단어(UNK)가 나오기 마련이다.
그래서, 아무리 거대한 데이터셋을 이용해서 학습을 했어도 접해보지 못 한 단어(UNK)가 나오기 마련이다.
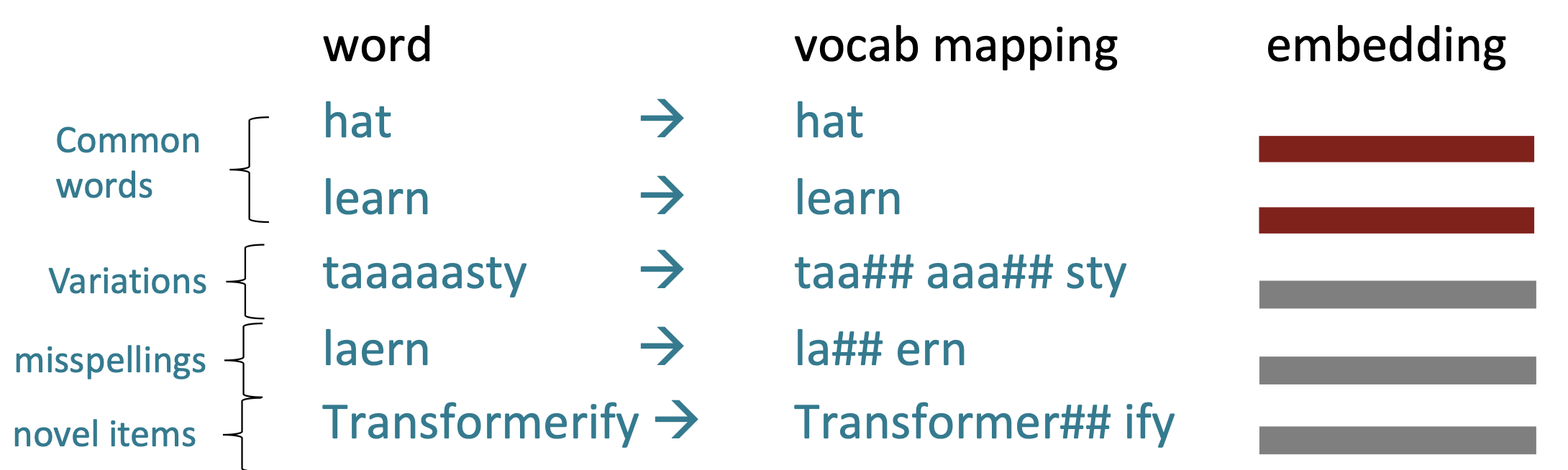
이런 접해보지 못 한 단어들을 subword로 분해해서 임베딩하는 이해하려는 시도를 subword segmentation이라 한다.
Byte Pair Embedding(BPE)는 이런 subword segmentation 해결하기 위해 NLP 분야에서 많이 사용되고 있다.
BPE algorithm
연속으로 '가장 많이' 등장한 글자를 하나의 글자로 병합하는 것을 반복하는 알고리즘
다음과 같은 단어들이 주어졌을 때를 생각하자.
low : 5
lower : 2
widest : 6
newest : 30회
l o w : 5
l o w e r : 2
w i d e s t : 6
n e w e s t : 3
vocabulary : [l, o, w, e, r, i, d, s, t, n]1회 (빈도수 9회의 e와 s를 통합)
l o w : 5
l o w e r : 2
w i d es t : 6
n e w es t : 3
vocabulary : [l, o, w, e, r, i, d, s, t, n, es]2회 (빈도수 9회의 es와 t를 통합)
l o w : 5
l o w e r : 2
w i d est : 6
n e w est : 3
vocabulary : [l, o, w, e, r, i, d, s, t, n, es, est]3회 (빈도수 7회의 l과 o를 통합)
lo w : 5
lo w e r : 2
w i d est : 6
n e w est : 3
vocabulary : [l, o, w, e, r, i, d, s, t, n, es, est]10회
low : 5
low e r : 2
newest : 6
widest : 3
vocabulary : [l, o, w, e, r, n, w, s, t, i, d, es, est, lo, low, ne, new, newest, wi, wid, widest]
<출처 : https://wikidocs.net/22592 >
<참고 : https://github.com/Huffon/nlp-various-tutorials/blob/master/korean-bpe.ipynb?fbclid=IwAR10PD96wB4GDMby5VxKABpkKqwY4tpVI_wdv9mweAPzO8I2lj6GDWs_q08 - 한국어 BPE>
1. Motivations of pretraining transformer
- Importance of context
" 원룸 풀옵션 몸만들어오세요. "
위의 문장을 방금 배웠던 BPE로 subword화 하고 기계 영어 번역 한다면 전혀 다른 두 개의 의미로 해석될 수 있다.
기계가 '원룸'과 '풀옵션'을 문맥적으로 고려하지 않으면 기계는 잘 못 된 결과를 도출할 수 있기 때문이다.
번역 뿐만 아니라 모든 NLP에서는 이런 문맥의 흐름을 고려한 워드 임베딩이 필요하다.
Transformer는 positional encodding과 attention mechnism을 이용해서 문장 전체의 어순을 보존하면서도 단어 간의 상관 관계를 파악하기 때문에 문맥의 흐름을 고려한 임베딩 및 학습이 가능하다.
그렇기 때문에 NLP에선 transformer를 활용한 사전학습에 관한 연구가 많이 발전됐고 우수한 성능을 보여주고 있다.
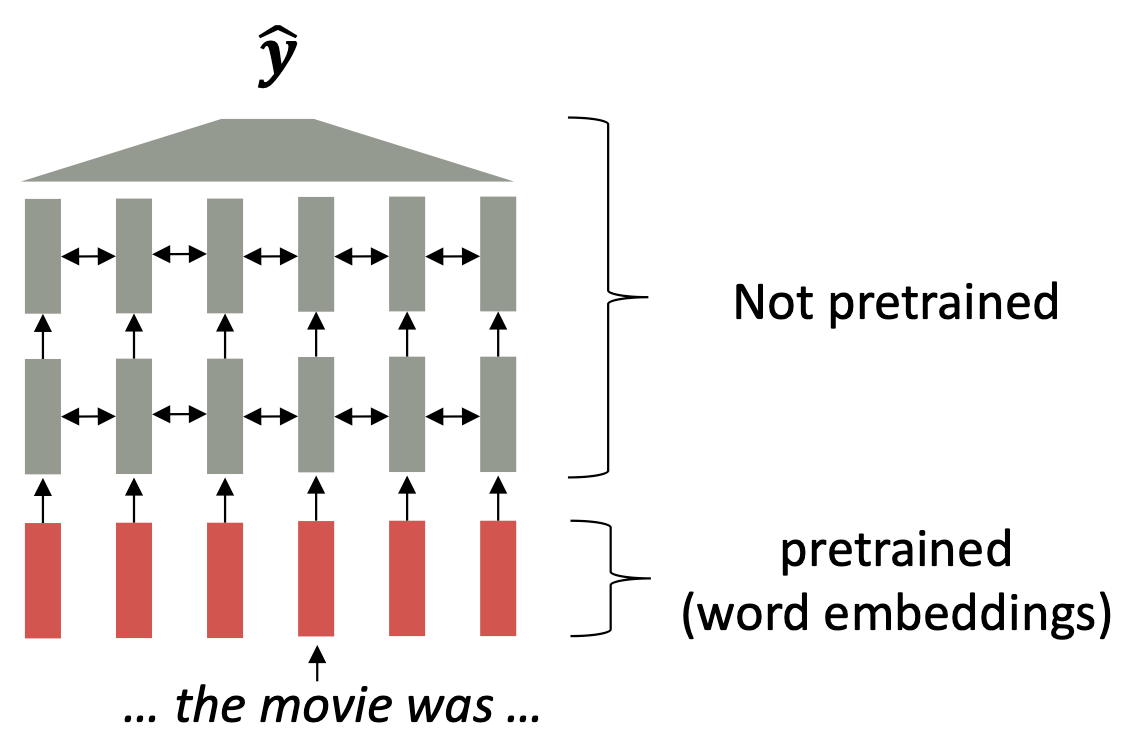 당시(2017년)의 pretraining은 임베딩 층만 사전 학습하고 나머지 층은 랜덤한 가중치를 이용해서 downstream task를 수행했다.
당시(2017년)의 pretraining은 임베딩 층만 사전 학습하고 나머지 층은 랜덤한 가중치를 이용해서 downstream task를 수행했다.
하지만, 일반적으로 downstream task는 라벨 갯수가 상대적으로 매우 적기 때문에 랜덤하게 초기화된 나머지 층들의 가중치가 편향되게 학습될 수 있다.
편향된 학습은 특정한 과업을 수행하기 위한 방향으로 가중치가 학습되기 때문에 문맥의 흐름을 파악하는 것에 취약할 수 있다.
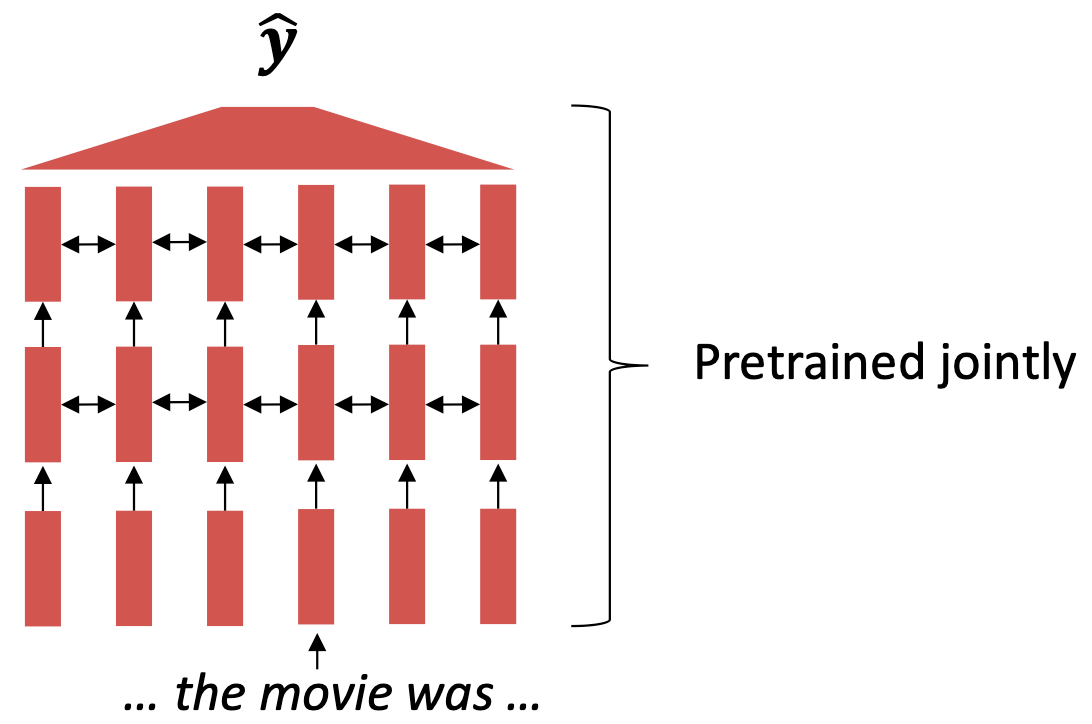 이를 해결하기 위해서 모델 전체를 문맥을 파악하는 사전 학습을 통해서 학습하는 연구가 많이 발표됐다.
이를 해결하기 위해서 모델 전체를 문맥을 파악하는 사전 학습을 통해서 학습하는 연구가 많이 발표됐다.
이런 사전 학습 방법은 언어의 특징을 잘 파악하고 문맥의 흐름을 잘 파악해서 우수한 성능을 보여준다.
대표적인 transformer 기반 사전 학습 모델은 GPT, BERT 그리고 T5가 있다.
2. Three ways of pretraining
- Decoder
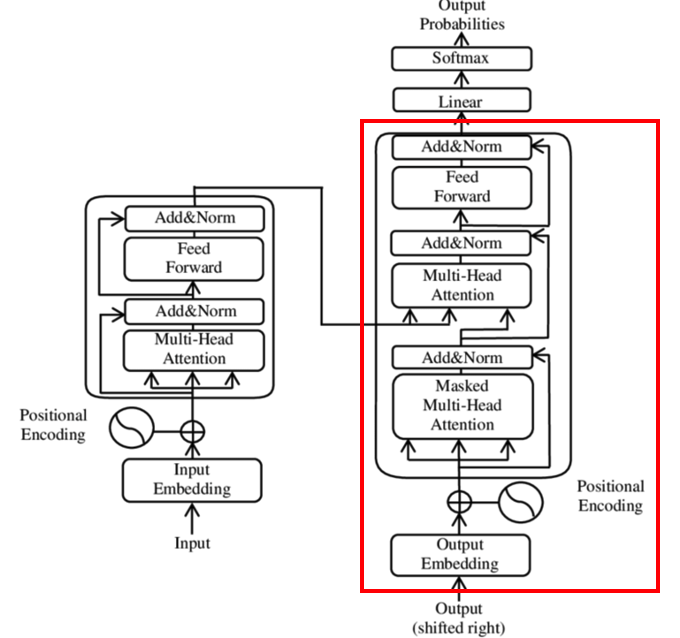 직관적으로 이해하기 쉬운 방식이고 가장 많이 연구되어 왔던 방식이다.
직관적으로 이해하기 쉬운 방식이고 가장 많이 연구되어 왔던 방식이다.
Transformer의 decoder부분을 pretrain해서 과업을 수행한다.
대표적인 모델로는 GPT가 있다.
How to?
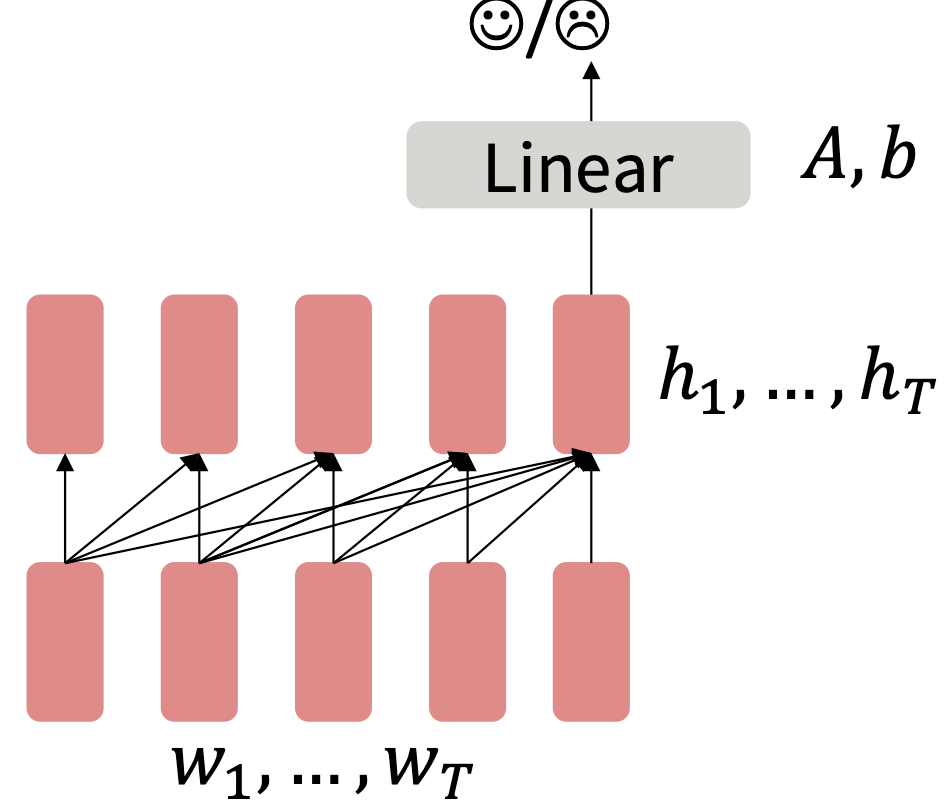 Downstream task를 할 때는 마지막 층을 학습하지 않고 랜덤하게 초기화된 가중치들을 이용해서 원하는 과업에 적응하도록 학습한다.
Downstream task를 할 때는 마지막 층을 학습하지 않고 랜덤하게 초기화된 가중치들을 이용해서 원하는 과업에 적응하도록 학습한다.
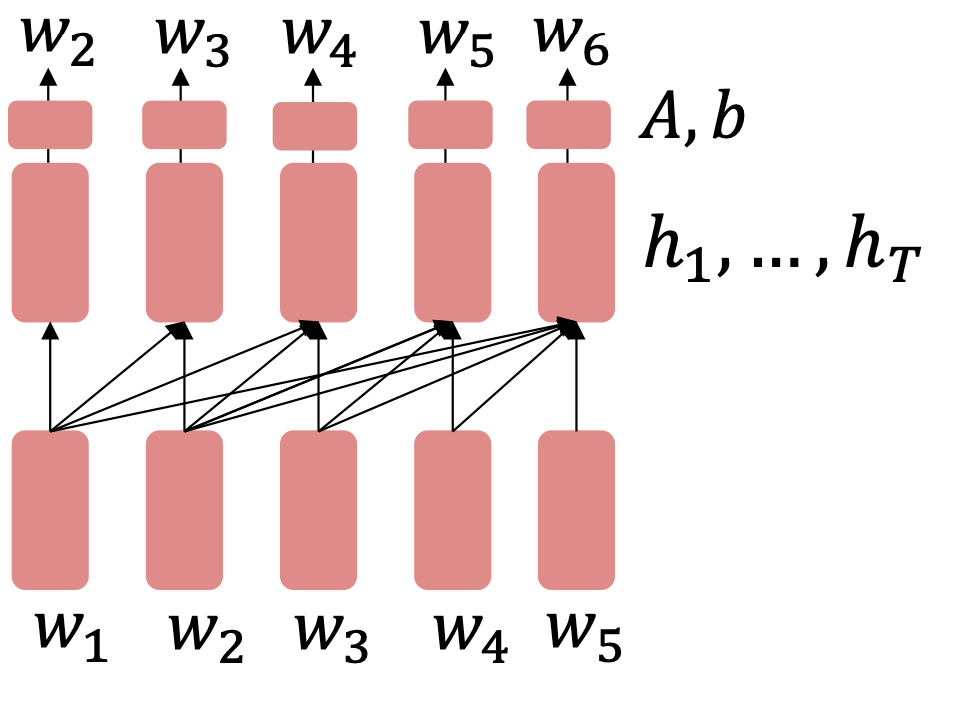 Seq2Seq의 경우 모델 전체를 사전 학습하고 원하는 전이 학습을 통해서 원하는 과업에 적응 하도록 한다.
Seq2Seq의 경우 모델 전체를 사전 학습하고 원하는 전이 학습을 통해서 원하는 과업에 적응 하도록 한다.
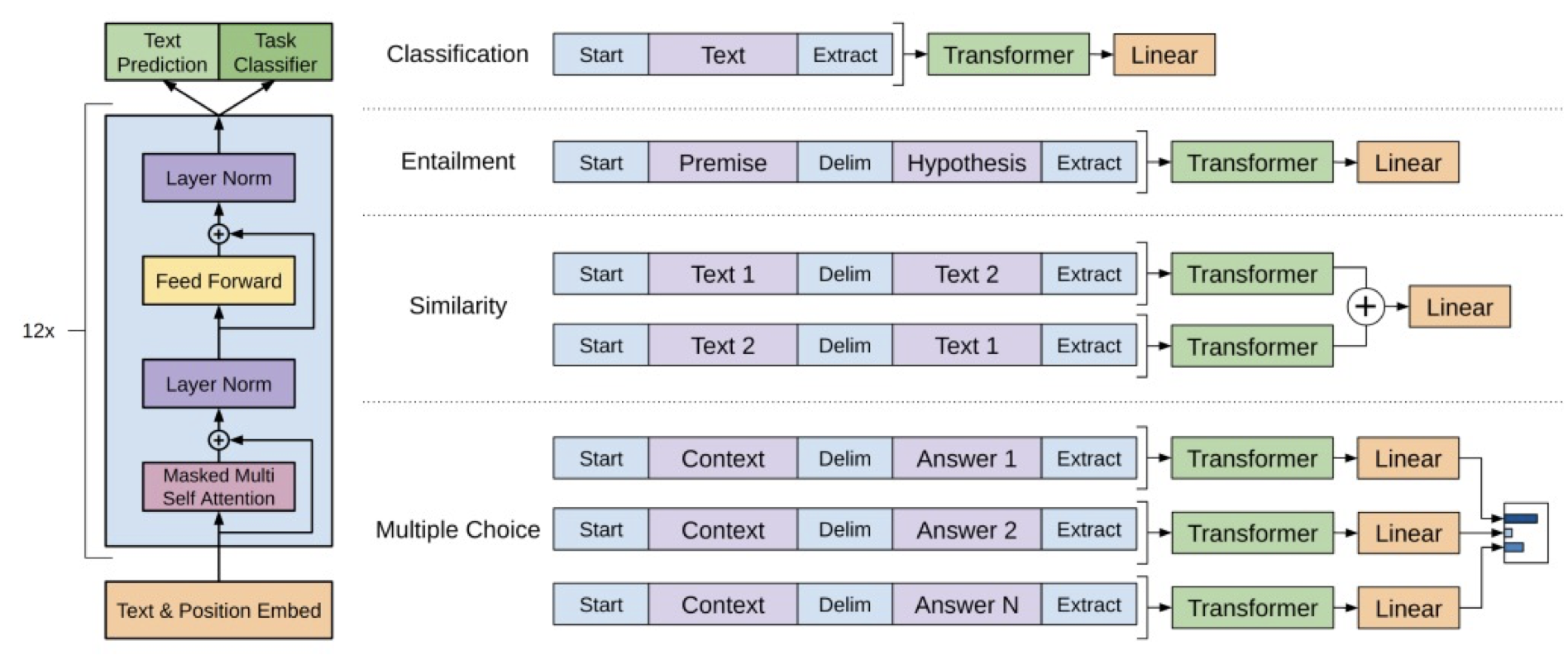
Special tokens of GPT
[START] : 한 문장 혹은 두 문장의 시작을 나타내는 토큰
[DELIM] : 두 문장의 분절을 나타내는 토큰
[EXTRACT] : 한 문장 혹은 두 문장이 끝났을 때 추출을 나타내는 토큰
< 출처 : https://www.youtube.com/watch?v=FeEmmylAF0o >
Where to?
1. Classification
문장이 주어졌을 때 어떤 라벨에 속하는지 분류하는 과업 - downstream
예) [START], 나는행복하다, [EXTRACT] -> 긍정
2. Natural language inference
두 문장이 주어졌을 때 두 문장의 모순과 일치를 판단하는 과업
예) [START], 나는아침을먹었다., [DELIM], 나는아침을먹지않았다., [EXTRACT] => 모순
3. Semantic similarity
두 문장이 주어졌을 때 두 문장이 비슷한 지 판단하는 과업
예) [START], 나는게임을좋아한다., [DELIM], 나는롤을좋아한다., [EXTRACT] => 일치
4. Question answering
두 문장이 주어졌을 때 질문에 답하는 과업
예) [START], 나는매주술을마신다., [DELIM], 내가좋아하는것은?, [EXTRACT] => 나는음주를좋아한다.
2. Three ways of pretraining
- Encoder
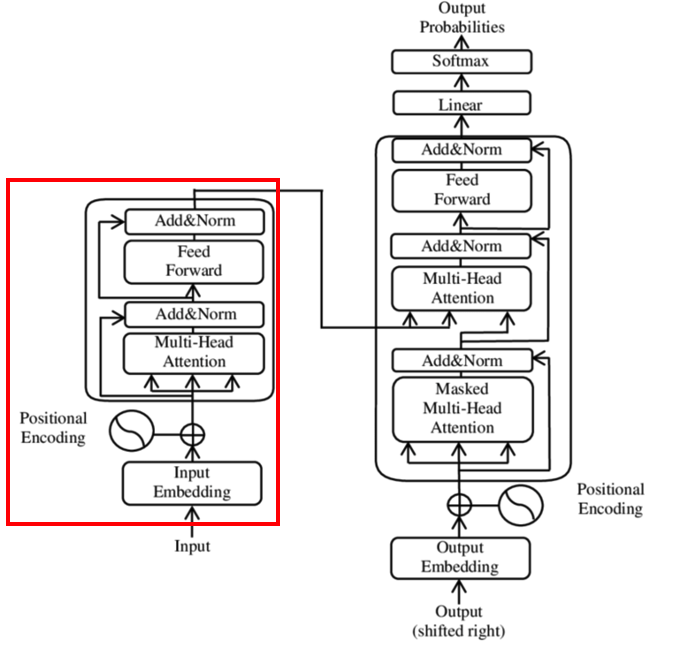 Transformer의 encoder를 이용해서 학습하는 방식이다.
Transformer의 encoder를 이용해서 학습하는 방식이다.
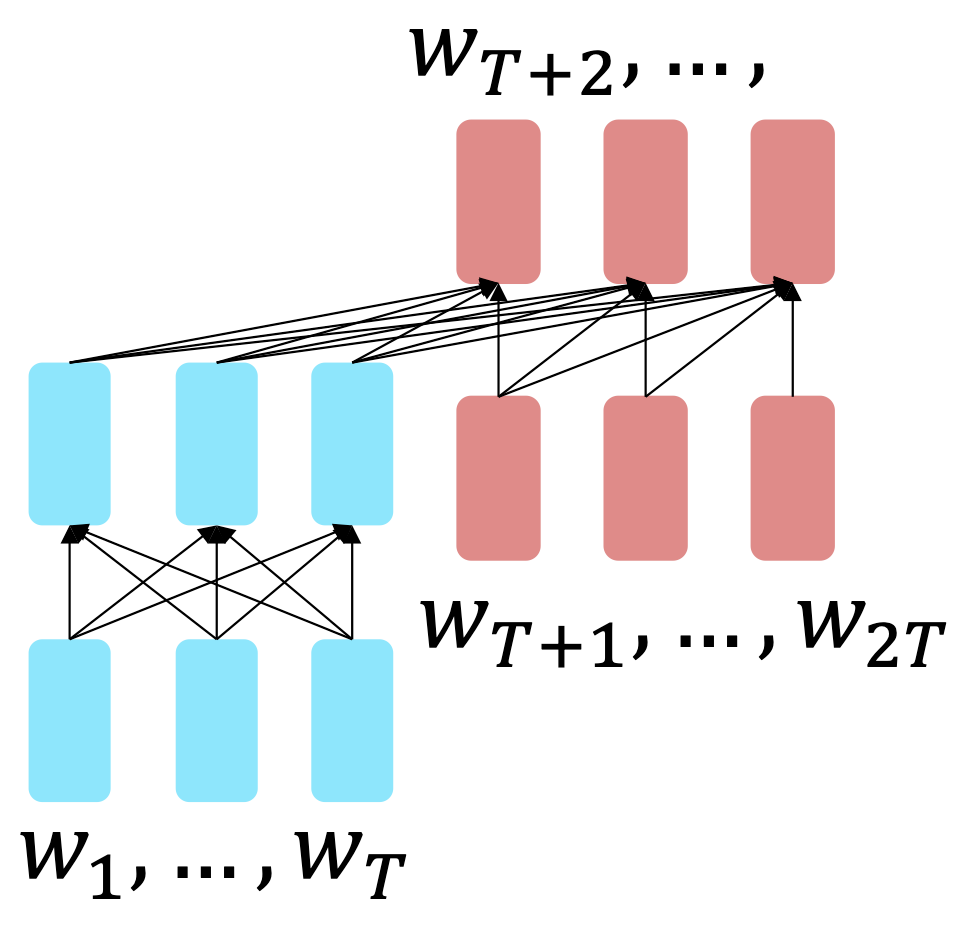
Transformer는 학습할 때 문장 전체를 인풋으로 받아서 미래의 단어를 예측하면서 양방향 학습을 한다.
그렇기 때문에, encoder를 이용한 사전 학습은 미래의 단어로 미래의 단어를 예측하는 학습을 하게 되고 data leakage에 의해 language modeling이 불가능하다.
How to?
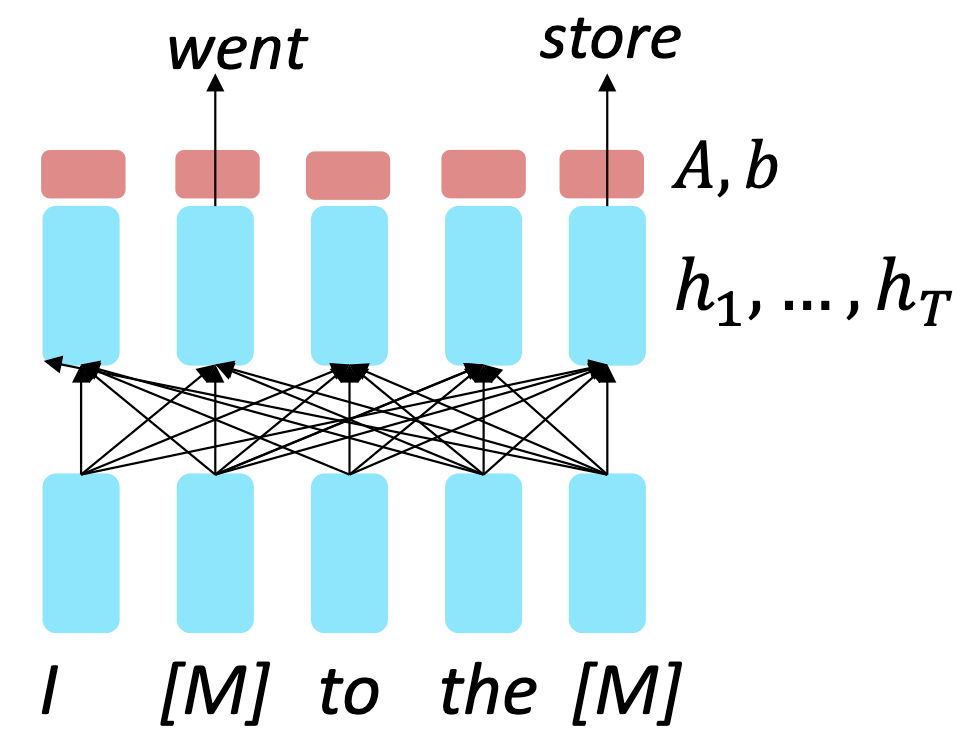 Bi-directional Encoder Representations from Transformers(BERT)는 [MASK] 스페셜 토큰으로 이를 극복한다. [MASK] 토큰은 전체 토큰의 15%를 차지한다.
Bi-directional Encoder Representations from Transformers(BERT)는 [MASK] 스페셜 토큰으로 이를 극복한다. [MASK] 토큰은 전체 토큰의 15%를 차지한다.
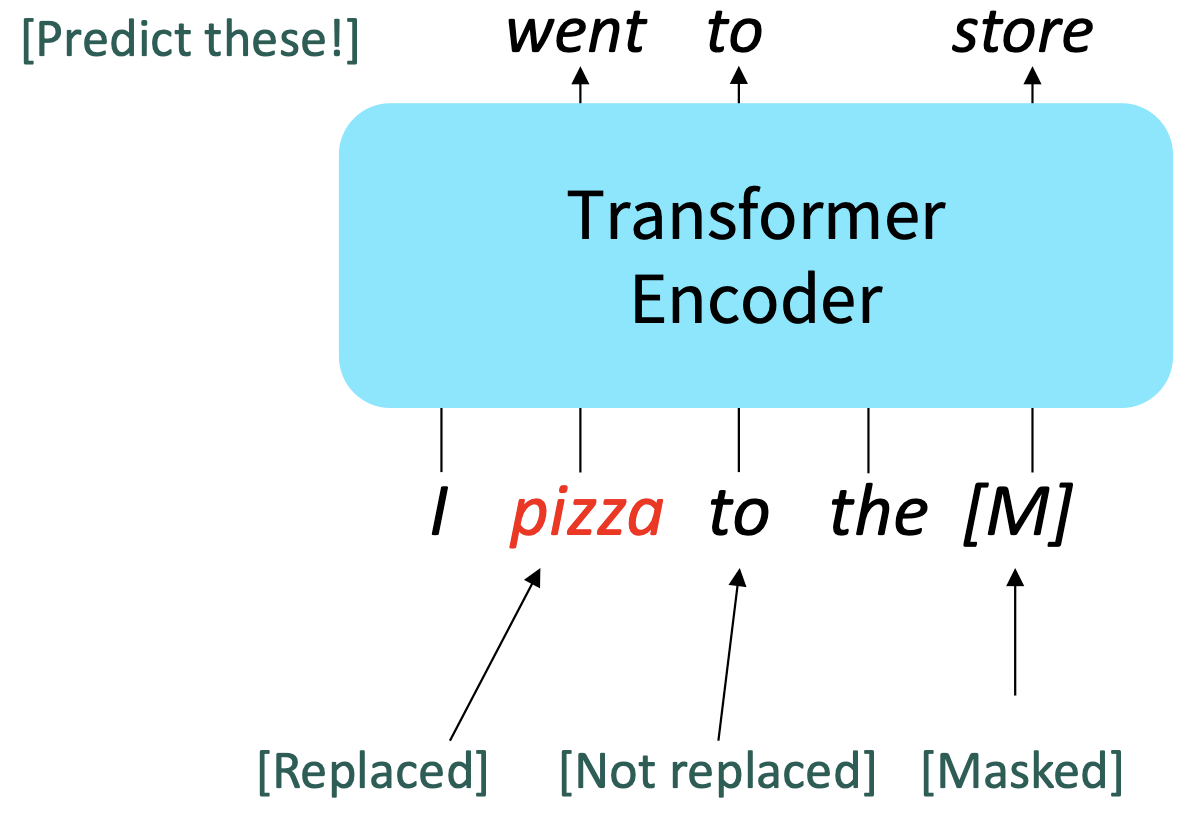 [MASK] 토큰의 80%는 [M], 10%는 랜덤한 단어로 대체하고, 나머지 10%는 기존의 단어로 유지하지만 예측하게 한다.
[MASK] 토큰의 80%는 [M], 10%는 랜덤한 단어로 대체하고, 나머지 10%는 기존의 단어로 유지하지만 예측하게 한다.
WHY) 모든 [MASK]토큰을 [M]으로 둔다면, 모델은 [M]을 볼 때만 예측을 잘하게 학습될 것이다. 하지만 실제 과업을 수행할 때는 [M] 토큰 없이 예측을 해야하기 때문에 성능이 떨어질 위험이 있다.
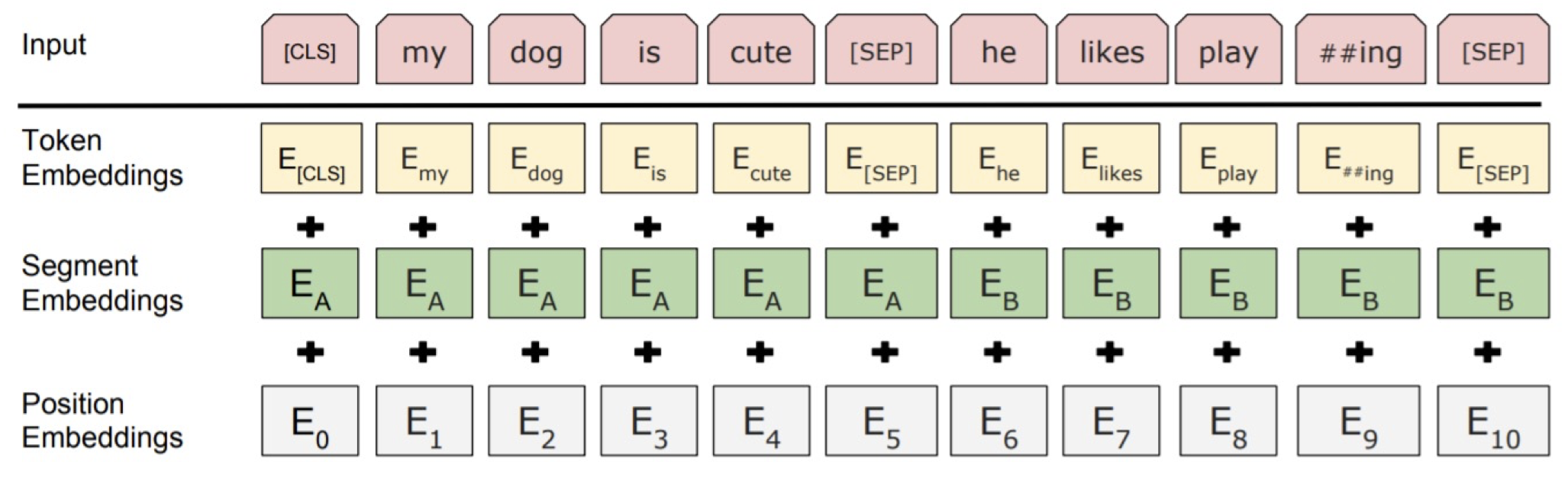 BERT는 [MASK] 토큰의 예측 외에도 [CLS] 토큰을 이용해서 문맥의 흐름을 학습한다.
BERT는 [MASK] 토큰의 예측 외에도 [CLS] 토큰을 이용해서 문맥의 흐름을 학습한다.
Special tokens of BERT
[CLS] <사전학습> : 사전 학습 때 문장 A와 문장 B가 이어지는 문장인 지 분류하는 토큰
[CLS] <분류과업> : 문장의 0과 1(긍정과 부정)을 분류할 수 있게 해주는 토큰
[CLS] <추론과업> : 두 문장이 주어졌을 때 두 문장의 모순과 일치를 판단하는 과업을 수행할 수 있게 해주는 토큰
[SEP] : 문장의 분절을 분류해주는 토큰
< 출처 : https://moondol-ai.tistory.com/463 >
Where to?
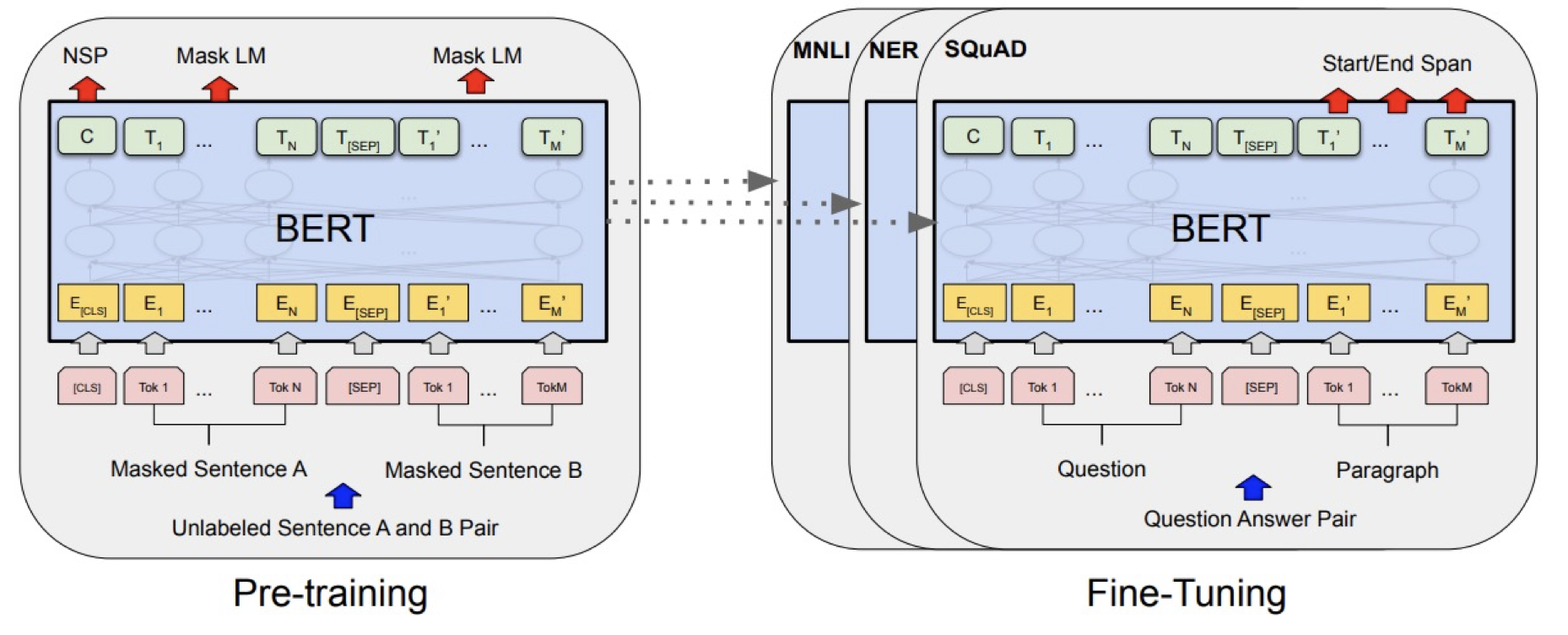 BERT는 넓은 범위에서 우수한 성능을 보여준다.
BERT는 넓은 범위에서 우수한 성능을 보여준다.
질의 응답, 자연어 추론, 감정 분석, 문법 감정, 문장 유사성 검사 등 다양한 분야에서 높은 점수를 보여줬다.
Limitations of BERT
많은 NLP분야에서 좋은 성능을 보여주며 만능의 성능을 보여줄 거 같은 BERT지만, 여러 개의 [M]토큰을 동시에 예측하는 과업에서 약한 모습을 보여준다.
BERT는 하나의 [M]을 예측하는 것에 적응했기 때문으로 여겨진다.
예) 나는 [M][M] 안양동에 살고 있다. => 나는 경기도 안양시 안양동에 살고 있다.
2. Three ways of pretraining
- Encoder & decoder
 Text to text transfer transformer(T5)는 transformer의 encoder와 decoder를 모두 사용해서 사전 학습한 Language Model(LM)이다.
Text to text transfer transformer(T5)는 transformer의 encoder와 decoder를 모두 사용해서 사전 학습한 Language Model(LM)이다.
Basic transformer가 decoder나 encoder만을 사용한 사전 학습한 LM보다 성능이 가장 좋음을 보여 주었다.
또한, multitask learing이 pretrain 학습 만큼 우수할 수 있음을 보여 주었다.
How to?
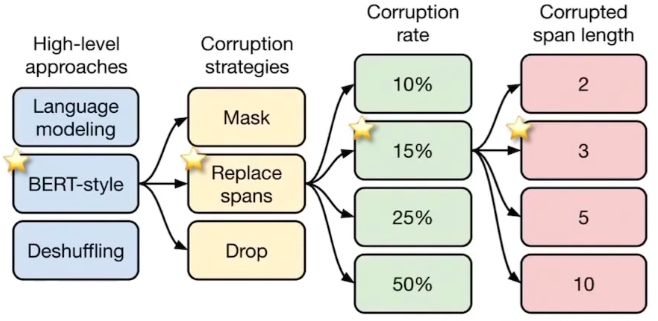 T5는 다양한 조건에서 성능을 비교하며 가장 우수한 사전 학습 방법을 제안했는데, 그 결과는 위의 그림과 같다.
T5는 다양한 조건에서 성능을 비교하며 가장 우수한 사전 학습 방법을 제안했는데, 그 결과는 위의 그림과 같다.

Special tokens of T5
[X] : 첫 번째 sentinel token
[Y] : 두 번째 masked sentinel token
[Z] : 마지막 sentinel token
[.] : 문장의 끝을 가리키는 special token
< 출처 : https://www.youtube.com/watch?v=Axo0EtMUK90 >
Where to?
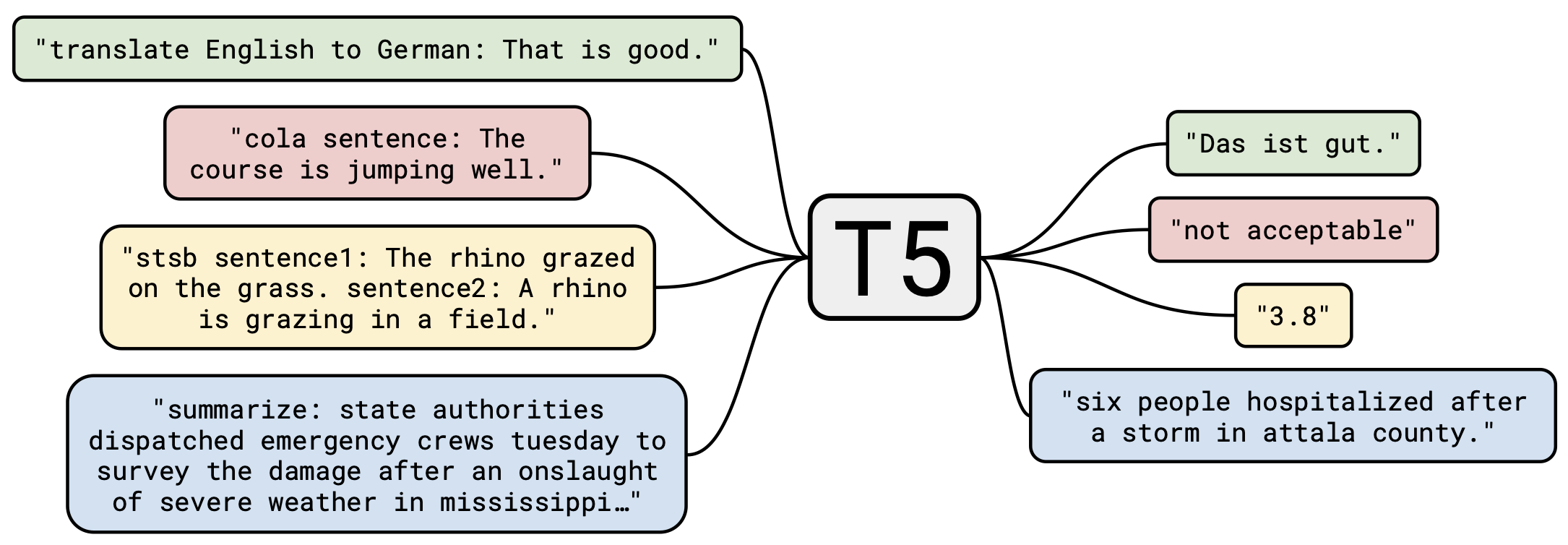 T5는 모든 과업의 결과를 텍스트 형태로 처리하고 학습한다.
T5는 모든 과업의 결과를 텍스트 형태로 처리하고 학습한다.
그렇기 때문에 모든 과업에 대해 적용할 수 있는 LM이고 성능 또한 우수하다.
3. In-context learning
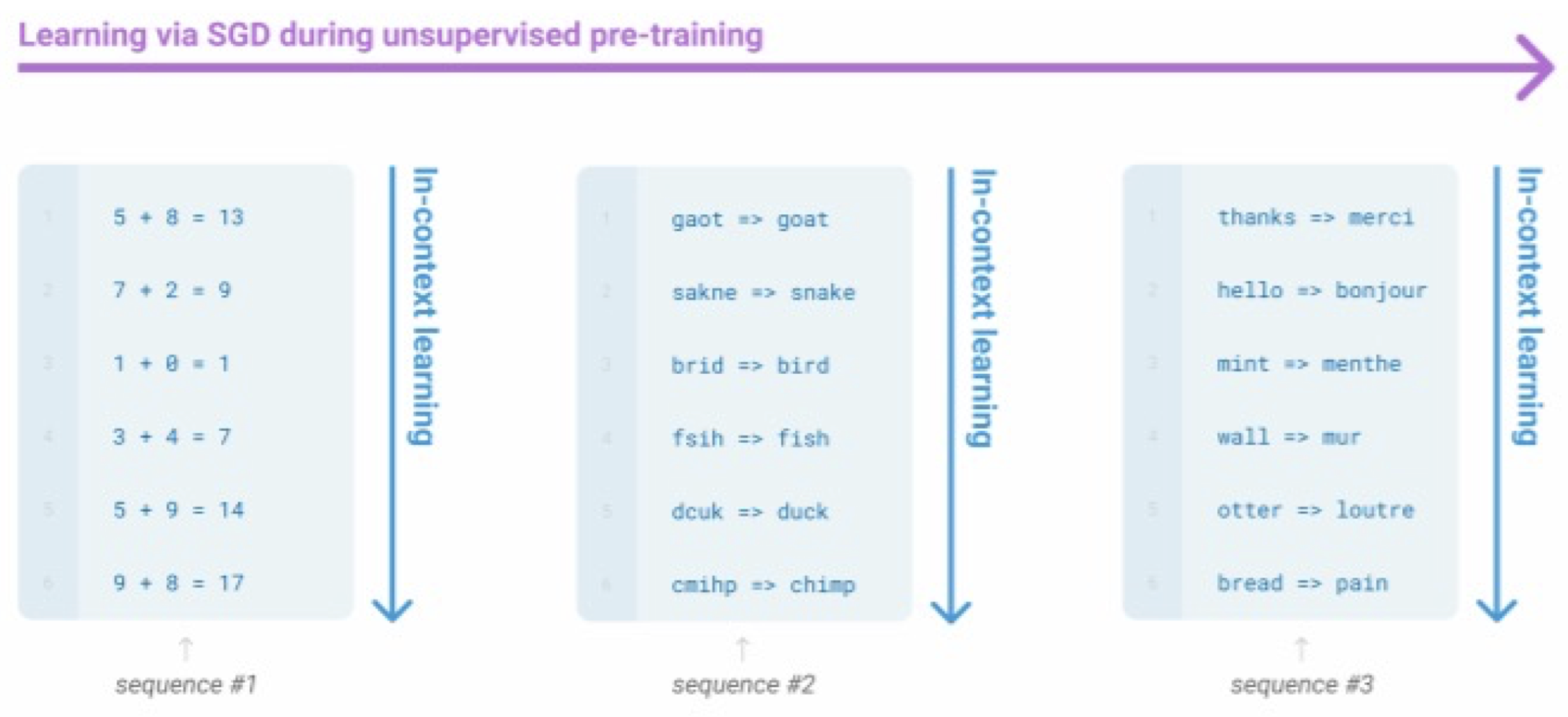 GPT-3와 같이 규모가 아주 큰 모델은 gradient step 없이 주어진 context 안에서 학습을 하는 것을 확인할 수 있는데 이를 in-context learning이라 한다.
GPT-3와 같이 규모가 아주 큰 모델은 gradient step 없이 주어진 context 안에서 학습을 하는 것을 확인할 수 있는데 이를 in-context learning이라 한다.
In-context learning은 task를 묘사하는 인풋과 아웃풋의 쌍을 반복적으로 보여줌으로써 기계가 gradient step 없이 스스로 task를 유추하는 학습을 말한다.
< 참고 : https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html >
< 참고 : https://www.youtube.com/watch?v=pC4zRb_5noQ >
부록. Parameters and datasets
GPT-1
Parameters
12layers, 117M parameters, 64 batch sizes
Datasets
BookCorpus : 800M words
GPT-2
Parameters
48layers, 1.5B parameters, 512 batch sizes
Datasets
BookCorpus : 800M words
BERT
Parameters
BERT -base : 12layers, 12 attetion heads, 110M parameters
BERT -large : 24layers, 16 attetion heads, 340M parameters
Datasets
BookCorpus : 800M words
English Wikipedia : 2.5B words
T5
Parameters
T5-Base : 12layers each, 220M paramters, 12 attention heads
T5-Large : 24layers each, 770M parameters, 16 attention heads
T5-XL : 24layers each, 3B parameters, 32 attention heads
T5-XXL : 24layers each, 11B parameters, 128 attention heads
Datasets
Colossal Clean Crawled Corpus : 34B tokens
GPT-3
Parameters
96layers, 175B parameters, 3.2M batch sizes
Datasets
Common Crawl : 410B BPE tokens
WebText2 : 19B BPE tokens
Books1 : 12B BPE tokens
Books2 : 55B BPE tokens
Wikipedia : 3B BPE tokens
Total : 500B BPE tokens
